作者:来自 Elastic Mary Gouseti

Elasticsearch 下采样现在为你提供了一种选择:用于最大化存储节省的最后值采样,或用于精确速率计算和计数器重置的聚合采样,两者都可以在 ES|QL 中完全查询。
Elasticsearch 允许你以快速且灵活的方式为数据建立索引。你可以在云端免费试用,或在本地运行它,亲自体验索引是多么简单。
Elasticsearch 下采样(downsampling)在我们的 OTel 基准测试中将时间序列存储减少了 94%,并且从 9.4 开始,它已经可以在 ES|QL 中完全查询。现在,对于每种指标类型,你可以选择:最后值采样为每个 bucket 保留一个观测值,以实现最大的存储节省;聚合采样则保留 min/max/sum/count,并保留计数器重置,以实现准确的速率计算。这两种方法都支持直方图。任何基于原始时间序列数据构建的 ES|QL 仪表板,都可以无需修改地运行在下采样数据之上;对应的权衡是使用每个 bucket 的平均值,而不是原始值。
下采样(自 Elasticsearch 8.7 起可用)通过将数据点汇总到更宽的时间 bucket 中,来缩减你的时间序列数据占用空间。它能够释放存储空间,并将查询速度提升数个数量级。最近,我们的工程重点已经从单纯优化底层下采样引擎,转向扩展它的能力。这些新特性让你能够更好地控制数据的汇总方式。
在这篇文章中,我们将探索新的下采样特性,包括:
- 在两种不同采样方法之间进行选择:轻量级的最后值采样 (用于最大化存储节省)以及高保真的聚合采样(用于精确的数学准确性,例如计数器重置)。
- 扩展对新指标类型的支持,包括直方图。
- 对下采样 gauge 的完整 ES|QL 支持。
首先,下面是对时间序列数据流(TSDS)相关术语的快速回顾:
- 指标( Metrics )是随时间变化的实际测量值,例如 CPU 使用率。
- 维度( Dimensions )是与测量值相关联的标识名称和值,它们共同决定唯一的时间序列 ID( _tsid )。
- 时间戳( timestamp )标记了测量发生的准确时间。
- 最后,(下采样)bucket 表示在指定时间区间内,对单个 _tsid 的指标值进行缩减后的结果。
下采样是如何工作的?
下采样过程通过 downsample API 启动,并且可以使用 ILM( Index Lifecycle Management )或数据流生命周期自动化执行。在索引完成写入后,它们会对索引进行下采样,并替换原始数据索引。
由于下采样是在整个 backing index 上运行的(该索引必须是只读的),并且时间序列数据的 backing index 本身具有时间边界,因此系统能够基于单个索引中的数据生成下采样 bucket。
下采样任务针对效率进行了优化:它会按照时间序列维度以及时间戳降序来读取所有文档。这种特定的排序方式确保属于同一个时间序列 bucket 的所有数据点会被连续收集,而不会与其他时间序列数据交错。一旦读取完所有属于某个 bucket 的文档,其字段值就会被收集并进行汇总。
在本文中,我们将使用以下数据来展示下采样的效果。这些数据表示两个节点每 10 秒上报一次它们的 CPU 使用率以及请求数量。
# Original data
{ "@timestamp": "2025-09-08T21:25:01.930Z", "node": "node-0001", "cpu.usage": 49.9, "requests": 3 }
{ "@timestamp": "2025-09-08T21:25:11.920Z", "node": "node-0001", "cpu.usage": 39.9, "requests": 6 }
{ "@timestamp": "2025-09-08T21:25:21.940Z", "node": "node-0001", "cpu.usage": 59.9, "requests": 2 }
{ "@timestamp": "2025-09-08T21:25:13.780Z", "node": "node-0002", "cpu.usage": 19.9, "requests": 100 }
{ "@timestamp": "2025-09-08T21:25:23.870Z", "node": "node-0002", "cpu.usage": 29.9, "requests": 102 }让我们看看下采样(截至 9.3 版本)在使用 10 分钟间隔时,会从这些数据中生成什么结果:
# Downsampled data
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0001", "cpu.usage": {"min": 39.9, "max": 59.9, "sum": 149.7, "value_count": 3}, "requests": 2 }
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0002", "cpu.usage": {"min": 19.9, "max": 29.9, "sum": 49.8, "value_count": 2}, "requests": 102}时间序列通过其维度值唯一标识,在我们的示例中即 node 字段。因此,被汇总到同一个 bucket 中的所有文档都会共享相同的维度值,这意味着每个 bucket 只需要存储一份维度值实例。
时间戳 和指标是每个文档中值会变化的字段。对于时间戳( @timestamp ),系统会执行舍入操作,以便将其对齐到 bucket 时间区间的起始位置。例如,在我们的示例中,生成的时间戳会被标准化为 2025-09-08T21:20:00.000Z( UTC )。
对于指标,在 9.3 之前,我们会根据其指标类型来执行下采样:对于 gauge( cpu.usage ),我们会存储遇到值的 min、max、sum 和 count;而对于 counter( requests ),则存储观察到的最后值。
正如你所看到的,在 9.3 之前,我们实际上对 counter 使用的是最后值采样方法,而对 gauge 使用的是聚合方法。从 9.4 开始,对于每种字段类型,两种采样方法都可用于所有指标类型,你可以根据你的数据以及可用系统资源,选择最适合的方法。
下采样采样方法是如何工作的
不同的使用场景需要不同的权衡。为了实现最大的存储压缩,最后值采样只保留每个 bucket 中最近的一次观测值。而为了获得准确的聚合结果,聚合方法会保留 min、max、sum 和 count。有些应用场景需要最大化存储压缩以及更快的下采样速度;而另一些场景则更重视结果尽可能忠实于原始数据,更优先考虑准确性,而不是纯粹的速度或空间节省。
因此,在 9.3 和 9.4 版本中,我们致力于提供两种不同的指标下采样方式。在 9.3 中,我们引入了一种新的采样方法,称为最后值;而在 9.4 中,我们进一步区分了 counter 的下采样方式,即最后值方法与聚合方法。
最后值采样方法
最后值方法会在所有字段类型上以一致的方式执行下采样。对于每个时间序列 bucket,它会创建一个单独的文档。该文档的时间戳为 bucket 的起始时间,并且所有字段都会保留该时间段内最后一次观察到的值。由于它只需要保留一个值,因此效率非常高,因为它不需要遍历所有值。结合我们之前的示例,下采样后的文档如下所示:
# 10 minute interval, last value method
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0001", "cpu.usage": 59.9, "requests": 2 }
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0002", "cpu.usage": 29.9, "requests": 102 }虽然这种方法会因为丢弃数据点而牺牲数据准确性,但它是时间序列解决方案中的一种标准实践。它的主要优势是在降低数据存储与查询成本的同时,保留长期趋势。它同样非常轻量,能够减少生成下采样数据所需的资源。
聚合采样方法
聚合采样方法不会跳过任何指标值,它会收集所有值,然后以合适的方式进行汇总。聚合方法会根据不同的指标类型采用不同的处理方式,具体如下所述。当我们的示例数据使用聚合方法进行下采样时:
# 10 minute interval, aggregate method
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0001", "cpu.usage": {"min": 39.9, "max": 59.9, "sum": 149.7, "value_count": 3}, "requests": 3 }
{ "@timestamp": "2025-09-08T21:25:11.920Z", "node": "node-0001", "requests": 6 }
{ "@timestamp": "2025-09-08T21:25:21.940Z", "node": "node-0001", "requests": 2 }
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0002", "cpu.usage": {"min": 19.9, "max": 29.9, "sum": 49.8, "value_count": 2}, "requests": 100}在接下来的章节中,我们将看到聚合方法是如何汇总每种指标类型的。
Gauge
Gauge 是一种基础指标类型。与 counter 或 histogram 不同,它的值既可以增加,也可以减少,用于反映系统组件的当前状态(在我们的示例中即 cpu.usage )。由于 gauge 的值会波动,因此每个 bucket 只保留一个值不足以保证 gauge 聚合的准确性。相反,我们会在每个下采样区间中跟踪多个统计聚合值:
- min 用于跟踪聚合区间内 gauge 记录到的最小值。
- max 用于跟踪聚合区间内 gauge 记录到的最大值。
- sum 是该区间内所有 gauge 读数的算术总和。
- value_count 用于跟踪参与该聚合区间的 gauge 测量值总数。
借助这四个统计值,我们可以精确回答直接聚合查询(因为我们掌握了真实的最小值、最大值、总和以及计数),并且可以通过 recorded sum 除以 value_count 来计算该区间的平均值。这种方法能够保留 gauge 随时间变化的行为特征,而不受下采样区间大小的影响。
在我们的示例中,我们可以看到 node-0001 的下采样文档以 aggregate metric double 的格式进行存储:
{"min": 39.9, "max": 59.9, "sum": 149.7, "value_count": 3}一些操作,例如值过滤或标准差计算,并不会被这些汇总统计信息覆盖。在 9.4 中,我们通过在 ES|QL 中使用平均值来解决这个问题。这是一个重要的里程碑,因为现在预聚合的 gauge 可以被 ES|QL 完全支持。任何基于原始数据构建的 ES|QL 仪表板,现在都可以直接使用下采样数据而不会报错,只是在使用每个下采样区间的平均值时会带来预期的精度损失。
我们选择平均值作为在每个下采样区间中对原始样本最具代表性的信号。例如,我们可以考虑如下查询:
FROM my-data | STATS stddev = std_dev(cpu.usage)
FROM my-downsampled-data | STATS stddev = std_dev(cpu.usage)第一个查询应用于原始数据,使用的是单个数据点。第二个查询应用于已聚合的 cpu usage 值,因此我们不再拥有单独的数据点。我们本可以使用 min 或 max,但这样会使结果偏向最小值或最大值。因此,我们决定使用平均值,因为它能够更好地捕捉一个区间内的整体数值分布。
Counters
Counters(在我们的示例中是 requests)是一种只会持续递增的测量值(对于累计时序语义而言),在下采样中看起来似乎很简单:只保留一个值就足够了。然而,当进程重启时,counter 的值会重置为 0。
counter 最常见的聚合方式是计算其变化率。如果在下采样过程中遗漏了 counter 重置,会严重扭曲该速率,从而导致监控结果不准确。因此,我们的下采样流程确保即使在分析下采样数据时,也能够检测到重置,从而保证速率计算算法的正确性。
当当前 counter 值低于上一次记录值时,速率算法会判定发生了重置。为了保证下采样数据的准确性,我们需要确保重置之前的最后一个值被保留,并且后续出现的值能够被正确对比。
因此,让我们看看在发生重置的情况下,下采样 bucket 中的 requests counter 会是什么样子:
# Main downsampled document
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0001", "requests": 3, "cpu.usage": ...}
# Pre-reset value
{ "@timestamp": "2025-09-08T21:25:11.920Z", "node": "node-0001", "requests": 6 }
# Post-reset value
{ "@timestamp": "2025-09-08T21:25:21.940Z", "node": "node-0001", "requests": 2 }主下采样 bucket 存储在该时间范围内观察到的第一个 counter 值。我们选择第一个值是因为它最接近 bucket 的起始时间戳。除此之外,当在该时间 bucket 内发生 counter reset 时,我们会存储带有其原始时间戳的辅助文档,用于保存这些值以保留 reset 事件:
- reset 之前的最后一个值会存储在一个辅助文档中。这记录了 counter 在 reset 事件之前达到的最大值。
- **reset 之后的值(条件性)**也可能存储在第二个辅助文档中。这是可选的,因为如果下一个下采样 bucket 的第一个值已经低于存储的 reset 前值,rate 算法可以在不需要这个中间数据点的情况下推断出 reset。
让我们考虑一个更复杂的示例,我们有一个 counter 值流在一个时间窗口内,模拟一次 reset:
Bucket 1: 1000 1003 1010 1040 1060 (reset) 20 30 40 70 80
Bucket 2: 90 ...
该序列会生成如下下采样文档:
- 下采样 bucket 1:存储第一个值(1000)。
- 辅助文档:存储 reset 前值(1060)。
- reset 后值:我们不需要存储值 20,因为下一个下采样 bucket 的起始值(90)已经低于 reset 前值(1060)。rate 计算可以通过比较 90 和 1060 正确检测 reset。
- 下一个下采样 bucket 2:存储第一个值(90)。
counter 值的总变化(delta)通过以下方式计算:
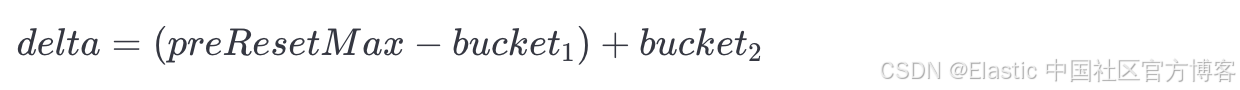
注意,在原始数据与聚合数据中它保持一致,因为我们在两个数据集中都能获取所有值:(1060−1000)+90=150。
相比之下,last value 方法会遗漏第一个 bucket 内的增长,只观察到 90 的增量,少了 40%。
虽然 delta 能被准确观测到,但最终的下采样 rate 可能不会与原始数据的 rate 完全一致,因为 rate 还涉及外推与插值。不过即便如此,该方法仍能在 counter reset 的情况下让结果尽可能接近原始 rate。
聚合方法如何处理 histogram 指标
聚合下采样方法会将 histogram 指标合并为每个 bucket 内的单一代表性 histogram,从而在减少数据量的同时保留分布形状。其处理过程取决于 histogram 类型。
对于 exponential histogram,它专为高效存储大范围数据而设计,其 values 和 counts 会被聚合并合并为一个代表性的 exponential histogram,从而保持原始数据集的比例分布与统计特性。
相反,对于旧版 histogram field 类型以及新版 tdigest field 类型,合并过程使用 TDigest 算法进行。这确保了从分布中派生的关键指标(例如中位数或第 95 百分位数)在下采样后仍然具有统计可靠性。
让我们来看一个 exponential histogram 的示例:
# Original data
{ "@timestamp": "2025-09-08T21:25:01.930Z", "node": "node-0001", "histogram": { "scale": 0, "sum": 7.0, "min": 1.0, "max": 4.0, "positive": {"indices": [0,1], "counts": [3,2]}}}
{ "@timestamp": "2025-09-08T21:25:11.920Z", "node": "node-0001", "histogram": { "scale": 0, "sum": 30.0, "min": 4.0, "max": 16.0,
"positive": {"indices": [2,3], "counts": [4,1]}}}
{ "@timestamp": "2025-09-08T21:25:21.940Z", "node": "node-0001", "histogram": { "scale": 0, "sum": 55.0, "min": 0.5, "max": 32.0, "zero": { "count": 2, "threshold": 0.5 }, "positive": {"indices": [1,4], "counts": [5,3]}}}
# 10 minute interval, aggregate method
{ "@timestamp": "2025-09-08T21:20:00.000Z", "node": "node-0001", "histogram": { "scale": 0, "sum": 92.0, "min": 0.5, "max": 32.0, "zero": { "count": 2, "threshold": 0.5 }, "positive": { "indices": [0,1,2,3,4], "counts": [3,7,4,1,3] }}}如你所见,下采样后的 histogram 捕获了三个 histogram 的值,而不是像 last value 方法那样只保留最后一个。
注意:histogram 字段类型不会记录它是用哪种算法构建的。使用 TDigest 构建的 histogram 可以被聚合方法正确下采样。而使用 High Dynamic Range(HDR)构建的 histogram 则不行,因为聚合方法无法检测这一点。对于 HDR 数据,应使用 last value 方法。
如何配置 Elasticsearch 下采样方法
你可以通过 data stream lifecycle 或 ILM 来配置 time series data stream 的采样方法:
# Data stream lifecycle
PUT _data_stream/my-data-stream/_lifecycle
{
"data_retention": "7d",
"downsampling_method": "aggregate",
"downsampling": [
{
"after": "1m",
"fixed_interval": "10m"
},
{
"after": "1d",
"fixed_interval": "1h"
}
]
}
# ILM
PUT _ilm/policy/datastream_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover" : {
"max_age": "5m"
},
"downsample": {
"fixed_interval": "5m",
"sampling_method": "aggregate"
}
}
},
"warm": {
"actions": {
"downsample": {
"fixed_interval": "1h",
"sampling_method": "aggregate"
}
}
}
}
}
}注意:在同一个 ILM 策略中的所有下采样操作都应配置相同的采样方法。
如何切换下采样方法?
可以在不同采样方法之间进行切换,但一个已经下采样过的索引只能继续使用相同的采样方法进行进一步下采样。
data stream lifecycle 会自动处理这一点,因此如果你在 data stream lifecycle 配置中更改了采样方法,它会将其应用到原始索引上,但如果已经存在下采样索引,它会继续使用兼容的采样方法。
另一方面,如果你使用 ILM,并且策略中包含多个下采样操作,建议创建一个使用新采样方法的新策略。这样,现有索引会继续使用旧采样方法进行下采样,而新的索引则会切换到新的方法。更具体地,我们建议执行以下步骤:
- 复制 ILM 策略,并在下采样操作中更改采样方法。
- 更新相关 index template,使其使用新的 ILM 策略。
最后值(last-value)和聚合(aggregate)下采样如何对比?
现在让我们在更真实的数据上对两种方法进行比较。我们从一个 receiver 生成了一小时的 OTel metrics。这是通过 metricsgenreceiver 使用以下配置完成的:
- scenario: hostmetricsreceiver
- interval: 5s
接着,我们将数据按 10 分钟 bucket 进行下采样,并分别使用两种采样方法。然后我们对关键性能特征进行了对比,包括最终的文档数量、数据集大小(在强制 merge 成单个 segment 之后),以及下采样过程所花费的时间。
| 文档数量(Doc count) | 数据集大小(Data set size) | 持续时间(Duration) |
|---|---|---|
| 原始(Raw) | 11509670 | 176.2 MB |
| 聚合(Aggregate) | (-98.83%) 134370 | (-93.64%) 11.2 MB |
| 最后值(Last value) | (-98.89%) 127170 | (-94.72%) 9.3 MB |
两种下采样方法(最后值和聚合)都将最初的 151 万条文档显著减少了 98%。然而,聚合方法会保留稍多的文档,以用于处理 counter reset。
在整体数据集大小方面,两种方法相比原始数据都实现了大幅压缩,但两者之间出现了更明显的差异:最后值方法比聚合方法实现了更大的体积减少。这种差异不仅仅来自 counter reset,还因为聚合方法为了保证常见聚合的准确性,会在每个 gauge 上存储更详细的信息。
最后值下采样方法在速度上也更快,比聚合方法快 7% 完成处理。这种效率来源于最后值方法不需要收集所有值;一旦找到最后一个值,其余数据就会被忽略。
最后值方法在数据体积和速度上更有优势;而聚合方法在查询准确性上更强,这是它的主要优势。
下一部分将通过三个 ES|QL 查询示例来展示这一点,这些示例使用了最近引入的 TS 命令,该命令采用 time series 语义,使我们可以使用 time series 聚合来观察时间序列的变化。这些查询将作用于所有三个索引(原始、最后值和聚合),以对比下采样数据与原始数据在查询准确性上的差异。
Gauges
对于 gauge 的下采样,我们将比较以下 time series 聚合:
-
min_over_time 的最小值
-
max_over_time 的最大值
-
avg_over_time 的平均值
-
last_over_time 的标准差(std_dev)
-
avg_over_time 的标准差(std_dev)
TS | STATS
min = MIN(MIN_OVER_TIME(system.cpu.logical.count)),
max = MAX(MAX_OVER_TIME(system.cpu.logical.count)),
avg = AVG(AVG_OVER_TIME(system.cpu.logical.count))TS | STATS stddev = std_dev(last_over_time(system.cpu.logical.count))
TS | STATS stddev = std_dev(avg_over_time(system.cpu.logical.count))
| 指标 | 最小值(min) | 最大值(max) | 平均值(avg) | 最后值标准差(std_dev of last value) | 平均值标准差(std_dev of avg) |
|---|---|---|---|---|---|
| 原始数据(Raw data) | 0 | 55 | 23.3369 | 0.79372 | 0.04318 |
| 聚合(Aggregate) | 0 | 55 | 23.3369 | 0.13253 | 0.04318 |
| 最后值(Last value) | 0 | 41 | 18.5261 | 0.79372 | 0.46364 |
聚合采样方法在大多数结果上都能保持准确性,例如 min、max 和 average,因为它使用的是来自 bucket 的预聚合数据。除了"最后值的标准差"之外,这些数据对所有指标都能准确反映原始数据。
由于预聚合数据不包含原始的最后一个值,系统在计算时间序列上的 last value 时,会默认使用 bucket 的平均值进行替代。这种替代会降低整体方差,因此与原始数据相比,标准差也会变小。
相反,仅基于 last value 的计算会在 min、max 和 average 上丢失准确性,因为它忽略了部分数据点。但这种方法在"最后值标准差"的查询上仍然保持准确,因为两者都依赖于 bucket 内的同一个单一最后值。
Counters
对于 counter,我们将只关注 rate,因为它是最实用的聚合方式。具体来说,我们将查询时间序列中观测到的最小和最大 rate。
TS <data> | STATS
min_rate = min(rate(system.disk.io)),
max_rate = max(rate(system.disk.io))| 最小 rate(Min rate) | 最大 rate(Max rate) |
|---|---|
| 原始(Raw) | 332214509.24 |
| 聚合(Aggregate) | 322801874.77 |
| 最后值(Last value) | 11.78 |
两种采样方法中,观察到的最大 rate 都与原始数据非常接近。然而,检测到的最小 rate 差异明显,因为 last value 方法会丢失所有 reset 信息,从而计算出明显更低的值。
选择合适的下采样方法
正如我们在前面章节中所展示的,无论使用哪种采样方法,下采样都能显著减少数据规模并提升查询性能。默认的采样方法仍然是聚合方法,因此默认情况下会优先保证准确性。然而,如果你的主要关注点是在下采样过程及其结果数据中降低资源消耗,那么现在你可以选择在接受一定精度损失的前提下,换取更高的资源效率。
Elasticsearch 下采样的下一步是什么?
目前有三个方向正在积极开发中:稀疏数据性能、分层下采样,以及取消只读索引的限制。
稀疏数据的性能改进
下采样在设计时做了优化,假设一个 time series data stream 中所有文档都具有相同的字段。例如,在包含节点指标的数据流中,我们预期所有节点都由同一组维度定义,并且所有文档都会包含关于这些节点的相同指标。
然而在实际中情况并非总是如此,time series data stream 中经常会出现由不同维度集合定义、并包含不同指标的测量文档。例如,同一个 data stream 可能同时包含 kubernetes 指标和应用程序指标。
这一点在最近的改进中得到了体现:自 9.3 起,time series 索引使用 doc values skippers(一种稀疏索引形式),而不是倒排索引和 BKD 树,从而在这种场景下能够更高效。基于这一方向,我们将重点优化下采样算法,使其能够利用这种数据结构带来的优化空间。
下采样的未来
我们认为上述改进已经使下采样能够适用于大多数 metrics 应用场景。但仍然有三个约束影响团队的使用方式:
- 下采样依赖 ILM 或 data stream lifecycle 来实现自动化,
- 要求源索引为只读状态,
- 并在完成后替换原始数据。
我们计划通过一个更灵活的下采样方案来解决这三个限制,该方案将基于多层下采样(multiple downsampling layers)。
这些 layers 将取消删除原始数据的要求,使你可以更早开始下采样,并且即使在最新数据上也能查询预聚合结果。
多个 layers 还允许你以不同粒度进行下采样,并分别管理每一层。例如,你可以更早将原始数据移动到 frozen tier,同时仅在 hot tier 保留预聚合数据,从而在每一层之间平衡成本与查询性能。
我们预计将在后续文章中分享设计细节以及分层模型的早期预览。
常见问题解答
如何降低 Elasticsearch 时间序列指标的存储成本?
使用 Elasticsearch 下采样,自 8.7 起可用。在我们的 OTel 基准测试中,它通过用聚合 bucket 替代单独的指标文档,将时间序列存储减少约 94%(从 176 MB 降至 11 MB)。从 9.4 开始,你可以在两种采样方法之间进行选择,以在存储与准确性之间做权衡。
下采样会破坏我的 ES|QL 查询或仪表盘吗?
不会。从 Elasticsearch 9.4 起,通过在 ES|QL 中用每个 bucket 的平均值替代原始值,downsampled gauges 得到完全支持。任何基于原始时间序列数据构建的 ES|QL 仪表盘都可以在下采样数据上不做修改地运行,只是会因为使用区间平均值而带来预期的精度损失。
Elasticsearch 中 last-value 和 aggregate 下采样有什么区别?
last-value 采样在每个 bucket 中只保留一个值(最新观测值),提供最大存储节省和更快的下采样速度。aggregate 采样则存储 min、max、sum、value_count,并保留 counter reset,从而提供更高的查询准确性,但存储成本略高。在 Elasticsearch 9.4 中,这两种方法对所有指标类型都可用。
Elasticsearch 在下采样时如何处理 counter reset?
aggregate 采样方法通过在主下采样 bucket 之外存储辅助文档来保留 counter reset:包括 reset 前的值,以及(如果下一个 bucket 的首个值并未已经更低)可选的 reset 后值。这使得即使 counter 在 bucket 中途发生 reset,rate 计算也能保持更高准确性。
什么时候应该选择 last-value 而不是 aggregate 下采样?
当存储成本和下采样速度比精确聚合更重要时,选择 last-value,例如长期趋势监控中不需要严格 bucket 统计的场景。选择 aggregate 则适用于 min、max、average 或 rate 计算需要尽可能接近原始数据的情况,尤其是 counter 经常 reset 的场景。
Elasticsearch 下采样可以处理 OpenTelemetry histogram 指标吗?
可以。从 9.4 起支持。aggregate 方法支持 exponential histogram 合并为单一代表性 histogram,而 tdigest field histogram 则使用 TDigest 算法合并。对于使用 High Dynamic Range(HDR)构建的旧 histogram field 类型,应使用 last-value 方法,因为 aggregate 方法无法合并 HDR histogram。
我可以在已有 time series data stream 上切换下采样方法吗?
可以。使用 data stream lifecycle 时,新方法会应用到原始索引,而已有的下采样索引会继续使用原方法。使用 ILM 时,如果策略包含多个下采样动作,建议创建新的策略并更新 index templates,而不是直接修改原策略。
这个内容对你有帮助吗?
原文:https://www.elastic.co/search-labs/blog/elasticsearch-downsampling-methods-esql