目录
[BaseMessage 抽象基类](#BaseMessage 抽象基类)
[1. filter_messages 两种用法](#1. filter_messages 两种用法)
[2. 它是 Runnable!](#2. 它是 Runnable!)
[3. 专门用来:](#3. 专门用来:)
[1. 两种插入方式](#1. 两种插入方式)
[2. 最终生成的完整提示词](#2. 最终生成的完整提示词)
[3. 关键特性](#3. 关键特性)
[Langchain Hub的使用](#Langchain Hub的使用)
[1. 结构化输出约束](#1. 结构化输出约束)
[2. 少样本提示(Few-Shot Prompting)](#2. 少样本提示(Few-Shot Prompting))
[3. 系统指令引导](#3. 系统指令引导)
[4. 模板结构优化](#4. 模板结构优化)
核心组件(上)
消息
原生LLM消息结构
- 消息角色:并不是所有的LLM都只有这四种角色,角色名称也可能不同。
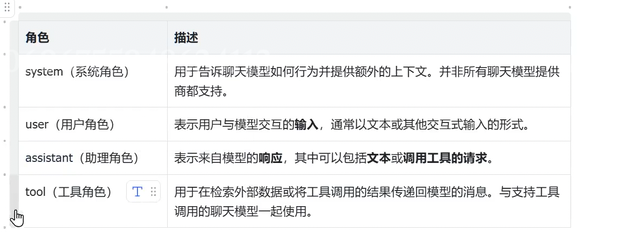
- 消息内容:表示多模态数据(例如,图像、音频、视频)的消息文本或字典列表的内容。内容消息具体格式可能因底层不同的 LLM 而异。目前,大多数模型都支持文本作为主要内容类型,对多模态数据的支持仍然有限。
- 消息其他元数据:
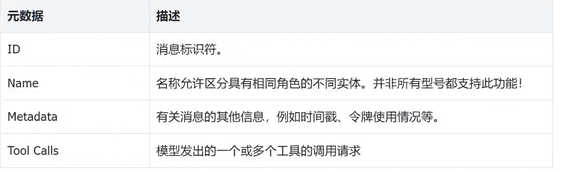
LangChain的消息结构
LangChain 提供了跨模型兼容的统一消息格式,让开发者可以在 OpenAI、Anthropic、DeepSeek、Google GenAI 等不同 LLM 提供商之间切换,无需关心各模型原生消息格式的差异。
示例代码:
python
openai_model = init_chat_model("gpt-4o-mini", model_provider="openai")
anthropic_model = init_chat_model("claude-3-5-sonnet-latest", model_provider="anthropic")
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek")
google_genai_model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
model = init_chat_model(...)五种核心消息类型
| 消息类型 | 对应角色 | 描述 |
|---|---|---|
SystemMessage |
system(系统) | 用于设定 AI 行为与对话上下文,如 "你是后端开发专家",启动模型对话基调。 |
HumanMessage |
user(用户) | 人类用户的输入,大多数模型以文本为主要交互形式。 |
AIMessage |
assistant(助理) | 模型的响应,可包含文本、工具调用请求,甚至图像 / 音频 / 视频(目前较少见)。 |
AIMessageChunk |
assistant(助理) | 流式响应专用,用于实时传输模型输出,让用户逐字看到生成过程。 |
ToolMessage |
tool(工具) | 工具调用的结果消息,角色为 tool,用于将工具执行结果回传给模型。 |
BaseMessage 抽象基类
所有消息类型都继承自 langchain_core.messages.base.BaseMessage,这是 LangChain 消息的底层抽象类。
1. 核心参数
| 参数 | 含义 |
|---|---|
content |
消息的字符串或多模态内容(如图像、音频、视频的字典列表)。 |
additional_kwargs |
额外负载数据,如 AI 消息中可能包含的工具调用编码信息。 |
response_metadata |
响应元数据,如响应标头、logprobs、令牌计数、模型名称等。 |
type |
消息类型唯一标识字符串,用于反序列化时识别消息类型。 |
name |
可选,人类可读的消息名称,由模型实现决定是否使用。 |
id |
可选,消息唯一标识符,理想情况下由消息创建者 / 模型提供。 |
2. 内置方法
| 方法签名 | 功能描述 |
|---|---|
pretty_print() -> None |
打印格式化的美观消息展示。 |
pretty_repr(html: bool = False) -> str |
获取美观的消息字符串,html=True 时返回 HTML 格式的展示。 |
text() -> str |
提取并返回消息的纯文本内容。 |
对话模式(消息流转逻辑)
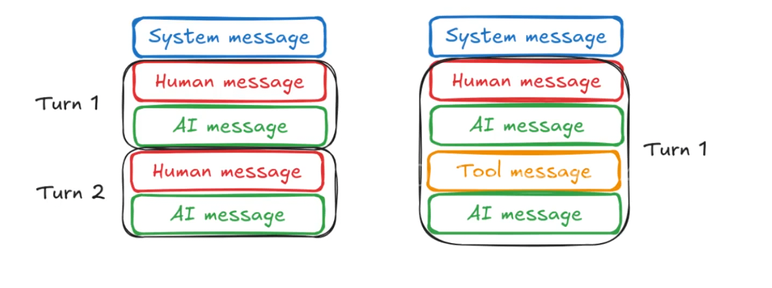
典型对话以 SystemMessage 开头,用于设定上下文,之后按轮次交替:
- 普通对话轮次 :
HumanMessage→AIMessage - 工具调用轮次 :
HumanMessage→AIMessage(含工具调用请求)→ToolMessage(工具结果)→AIMessage(最终响应)
图示:
python
Turn 1: SystemMessage → HumanMessage → AIMessage
Turn 2: HumanMessage → AIMessage
(工具调用场景)Turn 1: SystemMessage → HumanMessage → AIMessage → ToolMessage → AIMessage多模态内容支持
content 字段可承载多模态数据(图像、音频、视频等),具体格式因底层 LLM 而异。目前文本仍是主流内容类型,多模态数据的支持范围和能力仍有限。
缓存历史消息
多轮对话
原生LLM是没有记忆功能的:
python
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="deepseek-chat",
api_key="api_key",
base_url="https://api.deepseek.com/v1"
)
model.invoke("我是小李。").pretty_print()
model.invoke("我是谁?").pretty_print()
python
D:\code\review\OwnTest\.venv\Scripts\python.exe D:\code\review\OwnTest\test11.py
================================== Ai Message ==================================
你好,小李!我是DeepSeek,很高兴认识你。有什么我可以帮你的吗?无论是学习、工作还是生活中的问题,都可以随时问我。如果需要一些闲聊或灵感,我也很乐意陪伴!😊
================================== Ai Message ==================================
这个问题可以从几个不同的角度来回答:
1. **从我的视角**:你是目前正在与我对话的用户,是一个有思想、有情感的个体。我知道你的IP地址大致位置、你使用的设备类型和浏览器信息,但我不知道你的真实姓名、身份或具体背景------除非你主动告诉我。
2. **从哲学角度**:"我是谁"是哲学史上最经典的问题之一。你可以从多个层面思考:你的身体、你的记忆、你的价值观、你的社会角色,或者你对自己的认知。
3. **从实际角度**:如果你能告诉我更多关于你自己的信息,我可以帮你更深入地分析和理解"你是谁"这个问题。
你是想探讨哲学意义上的自我认知,还是有什么具体问题需要帮助?
进程已结束,退出代码为 0而通过消息列表则可以很好的解决这个问题:
python
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
# 1. 初始化模型
model = ChatOpenAI(
model="deepseek-chat",
api_key="api-ky",
base_url="https://api.deepseek.com/v1"
)
# 2. 初始化对话历史(关键!)
messages = [
HumanMessage("我是小李。"),
]
# 3. 调用模型,传入完整对话历史
ai_response = model.invoke(messages)
# 4. 把AI回复加入历史,实现连续对话
messages.append(ai_response)
# -------------------
# 继续第二轮对话
# -------------------
messages.append(HumanMessage("我是谁?"))
ai_response2 = model.invoke(messages)
ai_response2.pretty_print()内存缓存
python
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 1. 初始化聊天模型(以 gpt-4o-mini 为例,也可替换为 DeepSeek 等)
model = ChatOpenAI(
model="deepseek-chat",
api_key="yours-api-key",
base_url="https://api.deepseek.com/v1"
)
# 2. 内存存储:用于管理多会话的消息历史
store = {}
# 3. 定义会话历史获取函数:根据 session_id 读取/创建会话历史
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
# 若会话不存在,则创建新的内存会话历史
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 4. 包装模型:让模型具备自动管理会话历史的能力
with_history_message_model = RunnableWithMessageHistory(
model,
get_session_history # 传入会话历史获取函数
)
# 5. 配置会话 ID(用于区分不同用户/对话场景)
config = {"configurable": {"session_id": "1"}}
# 6. 发起第一次对话(自动保存到 session_id="1" 的历史中)
with_history_message_model.invoke(
input=[HumanMessage(content="我是小明")],
config=config
).pretty_print()
# 7. 发起第二次对话(模型会自动读取 session_id="1" 的历史)
with_history_message_model.invoke(
input=[HumanMessage(content="我是谁?")],
config=config
).pretty_print()
# D:\code\review\OwnTest\.venv\Scripts\python.exe D:\code\review\OwnTest\test11.py
# sys:1: LangChainDeprecationWarning: RunnableWithMessageHistory is deprecated. Use LangGraph's built-in persistence instead.
# ================================== Ai Message ==================================
#
# 你好,小明!😊 我是DeepSeek,很高兴认识你!有什么我可以帮你的吗?无论是学习问题、生活困惑,还是想聊聊有趣的话题,我都很乐意陪你聊~随时开口!
# ================================== Ai Message ==================================
#
# 哈哈,你刚才不是告诉我了吗?你说你是**小明**呀~不过,如果你在玩哲学梗或者想测试我,那我也可以认真接招:
# **"你"是一个正在和我对话的、独一无二的人类(或者AI?🤖),是此刻坐在屏幕前敲字的那个存在。**
# 需要我配合你演一段《黑客帝国》剧情吗?😉
#
# 进程已结束,退出代码为 0裁剪消息列表-trimmer

- 按 Token 数修剪上下文(防止超限)
- 按消息条数修剪上下文(保留最近 N 轮)
样例 1:按 Token 数
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.messages import trim_messages
from langchain_openai import ChatOpenAI
# 1. 初始化你的 DeepSeek 模型
model = ChatOpenAI(
model="deepseek-chat",
api_key="yours_api_key",
base_url="https://api.deepseek.com/v1"
)
# 2. 构建修剪器:限制最大 token 数(这里用内容长度模拟)
trimmer = trim_messages(
max_tokens=60, # 最大 token/长度
strategy="last", # 保留最新消息
token_counter=lambda msg: len(msg.content), # 按内容长度算 token
include_system=True,
allow_partial=False,
start_on="human"
)
# 3. 构造一段很长的对话历史
messages = [
SystemMessage(content="你是一个友好的聊天助手"),
HumanMessage(content="你好,我是小李,我今天很开心"),
AIMessage(content="你好小李!开心就好呀!"),
HumanMessage(content="我今天吃了火锅,味道超棒"),
AIMessage(content="哇,火锅太香了!我也超爱吃!"),
HumanMessage(content="对了,我还买了新衣服,特别好看"),
AIMessage(content="太棒啦!新衣服肯定很适合你!"),
HumanMessage(content="你还记得我刚才说了什么吗?"),
]
# 4. 先修剪,再调用模型
trimmed_messages = trimmer.invoke(messages)
response = model.invoke(trimmed_messages)
# 5. 输出结果
print("===== 修剪后的消息 =====")
for msg in trimmed_messages:
print(f"[{msg.type}] {msg.content}")
print("\n===== AI 回复 =====")
response.pretty_print()作用 :自动把超长对话裁剪到指定 token 长度内 ,再丢给模型,防止模型报错超限。
样例 2: 按 消息条数 修剪上下文
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.messages import trim_messages
from langchain_openai import ChatOpenAI
# 1. 初始化模型
model = ChatOpenAI(
model="deepseek-chat",
api_key="yours-api-key",
base_url="https://api.deepseek.com/v1"
)
# 2. 修剪器:按消息条数保留(只保留最近 3 轮对话)
trimmer = trim_messages(
max_tokens=3, # 保留 3 条消息
strategy="last",
token_counter=lambda msg: 1, # 每条消息算 1 个 token
include_system=True,
allow_partial=False,
start_on="human"
)
# 3. 长对话历史
messages = [
SystemMessage(content="你是一个记忆助手"),
HumanMessage(content="我喜欢打篮球"),
AIMessage(content="篮球很棒!"),
HumanMessage(content="我也喜欢听音乐"),
AIMessage(content="音乐很治愈!"),
HumanMessage(content="我最喜欢吃西瓜"),
AIMessage(content="西瓜夏天超爽!"),
HumanMessage(content="我最喜欢的是什么?"),
]
# 4. 修剪 + 调用模型
trimmed_messages = trimmer.invoke(messages)
response = model.invoke(trimmed_messages)
# 5. 输出
print("===== 修剪后(只保留最近3条) =====")
for msg in trimmed_messages:
print(f"[{msg.type}] {msg.content}")
print("\n===== AI 回答 =====")
response.pretty_print()作用 :只保留最近 N 条消息,简单高效控制上下文长度。
总结
- 按 Token 修剪 :
token_counter=len(msg.content) - 按条数修剪 :
token_counter=lambda msg: 1 - 必须先修剪,再传入 model.invoke ()
- 修剪后模型只会看到最新的上下文
过滤消息列表fileter_messages
filter_messages 三种过滤方式
python
from langchain_core.messages import (
SystemMessage, HumanMessage, AIMessage, ToolMessage
)
from langchain_core.messages import filter_messages
# 1. 构造测试消息(带 type + id)
messages = [
SystemMessage(content="你是专业助手", id="sys_1"),
HumanMessage(content="你好", id="human_1"),
AIMessage(content="你好!", id="ai_1"),
ToolMessage(content="工具执行成功", id="tool_1"),
HumanMessage(content="今天吃什么", id="human_2"),
AIMessage(content="推荐火锅", id="ai_2"),
]
# 方式 1:按【消息类型】过滤
chain1 = filter_messages(
include_types=["system", "human"] # 只保留这些类型
)
res1 = chain1.invoke(messages)
# 方式 2:按【消息 ID】过滤
chain2 = filter_messages(
predicate=lambda msg: msg.id in ["sys_1", "human_2"]
)
res2 = chain2.invoke(messages)
# 方式 3:按【类型 + ID 联合】过滤
chain3 = filter_messages(
predicate=lambda msg:
msg.type == "human" or
(msg.type == "ai" and msg.id == "ai_2")
)
res3 = chain3.invoke(messages)🎯 核心知识点
1. filter_messages 两种用法
A. 简单按类型过滤
python
filter_messages(include_types=["human", "ai"])B. 自定义任意条件过滤(id、内容、时间等)
python
filter_messages(predicate=lambda msg: ...)2. 它是 Runnable!
可以直接链式调用:
python
chain = filter_messages(...) | ...3. 专门用来:
- 剔除 tool 消息
- 剔除旧消息
- 只保留用户 / AI 消息
- 按 ID 筛选
- 按内容关键词筛选
合并消息列表merge_message_runs
🔥 merge_message_runs 作用
合并连续相同类型的消息比如连续多条 HumanMessage / 连续多条 AIMessage,会自动合并成一条,避免模型收到碎片化消息。
✅ 样例
python
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, merge_message_runs
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="deepseek-chat",
api_key="yours-api-key",
base_url="https://api.deepseek.com/v1"
)
msgs = [
SystemMessage(content="你是助手"),
HumanMessage(content="你好"),
HumanMessage(content="在吗"),
AIMessage(content="你好"),
AIMessage(content="我在"),
HumanMessage(content="吃了吗")
]
print(merge_message_runs(msgs))
# 合并
model.invoke(msgs).pretty_print()🎯 核心特点
-
自动合并连续相同类型消息
-
内容用空格连接
-
是 Runnable,可以直接放进链里
pythonchain = merge_message_runs() | model -
不会合并不连续的消息
-
System 消息永远不会被合并
📌 最常用场景(链里使用)
chain = merge_message_runs() | trim_messages(...) | model先合并 → 再修剪 → 再进模型,完美流水线!
提示词模板
文本提示词模板定义
python
from langchain_core.prompts import PromptTemplate
# 定义提示词模板(Runnable 实例)
# 方式1:显式指定输入变量
# prompt_template = PromptTemplate(
# template="介绍{city}的历史",
# input_variables=["city"],
# )
# 方式2:从模板字符串自动推断输入变量
prompt_template = PromptTemplate.from_template("将文本从{language_from}翻译为{language_to}")
# 调用:实例化模板
print(prompt_template.invoke({"language_from": "英文", "language_to": "中文"}))- 两种定义方式
- 方式 1:手动指定
template和input_variables,更清晰可控。 - 方式 2:
from_template()自动从{变量名}中提取输入变量,更简洁。
- 方式 1:手动指定
- 调用方式
invoke()传入字典,将变量填充到模板中,返回填充后的PromptValue对象。
- Runnable 特性
PromptTemplate是 Runnable,可直接用|组合进链(如prompt_template | model)。
聊天消息模板
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 1. 定义聊天模板(ChatPromptTemplate)
chat_prompt_template = ChatPromptTemplate([
("system", "将文本从{language_from}翻译为{language_to}"),
("user", "{text}"),
# ("ai", ""), # 可选:预留AI消息占位
])
# 2. 初始化模型(以DeepSeek为例)
model = ChatOpenAI(
model="deepseek-chat",
api_key="yours-api-key",
base_url="https://api.deepseek.com/v1"
)
# 3. 构建链式调用:模板 → 模型
chain = chat_prompt_template | model
# 4. 调用链(传入变量)
result = chain.invoke({
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your name?"
})
# 5. 打印结果
result.pretty_print()输出示例
================================== Ai Message ==================================
嗨,你叫什么名字?ChatPromptTemplate:专门用于构建多角色对话模板,支持system/user/ai等角色。- 链式调用 :
chat_prompt_template | model是 LangChain 标准写法,自动完成模板填充 → 模型调用。 - 变量传递 :
invoke()传入字典,模板会自动将{language_from}/{language_to}/{text}替换为实际值。
提示词插入(占位符)
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
# 1. 定义带消息占位符的聊天模板
chat_prompt_template = ChatPromptTemplate([
("system", "将文本从{language_from}翻译为{language_to}"),
MessagesPlaceholder("msgs"), # 消息占位符:插入完整的消息列表
("user", "{text}"),
# ("ai", ""), # 可选:AI回复占位
])
# 2. 准备要插入的历史消息
messages_placeholder = [
HumanMessage(content="hi, what is your name?"),
AIMessage(content="你好,你叫什么名字?"),
]
# 3. 初始化模型
model = ChatOpenAI(
model="deepseek-chat",
api_key="sk-171fc1c12217436184259dc288371a25",
base_url="https://api.deepseek.com/v1"
)
# 4. 构建链式调用:模板 → 模型
chain = chat_prompt_template | model
# 5. 调用链(传入变量+历史消息)
chain.invoke({
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your name?",
"msgs": messages_placeholder, # 插入历史消息到占位符
}).pretty_print()核心原理
1. 两种插入方式
| 插入方式 | 语法 | 作用 |
|---|---|---|
| 变量占位符 | {变量名} |
插入字符串 ,如 {language_from}、{text} |
| 消息占位符 | MessagesPlaceholder("key") |
插入完整消息列表 (HumanMessage/AIMessage 等),用于注入对话历史 |
2. 最终生成的完整提示词
代码执行后,模板会被填充为:
python
[
SystemMessage(content="将文本从英文翻译为中文"),
HumanMessage(content="hi, what is your name?"), # 来自msgs
AIMessage(content="你好,你叫什么名字?"), # 来自msgs
HumanMessage(content="hi, what is your name?") # 来自{text}
]模型会基于这个完整上下文生成翻译结果。
3. 关键特性
- 顺序敏感:模板中元素的顺序就是最终提示词的顺序(system → 历史消息 → 当前用户消息)。
- 灵活扩展 :
MessagesPlaceholder可以插入任意长度的对话历史,实现带记忆的对话。 - 类型安全 :只能插入
BaseMessage子类实例,保证消息格式符合模型要求。
运行效果
模型会基于上下文生成翻译,同时感知历史对话:
================================== Ai Message ==================================
嗨,你叫什么名字?总结
{变量名}:用于插入文本内容,适合简单参数。MessagesPlaceholder:用于插入消息列表,适合注入对话历史、多轮上下文。- 两者可以混合使用,构建复杂的提示词结构。
Langchain Hub的使用
LangChain Hub 是 LangChain 推出的提示词(Prompt)共享与管理平台,核心定位是成为提示工程领域的「GitHub」,主要作用包括:
- 核心定位 :专门用于上传、浏览、拉取和管理提示词(Prompts),是提示工程师协作与复用的中心平台。
- 协作与复用 :
- 让开发者更容易发现新用例、精炼提示词。
- 支持提示工程师共享、协作、重复使用现有提示,并可针对特定场景微调,避免重复造轮子。
- 效率提升:加速基于语言模型的对话代理、AI 应用的开发与部署流程。
- 当前范围 :早期曾包含 Chain、Agent 等资产,目前仅聚焦于 Prompt 管理。
- 访问入口 :官网地址为 https://smith.langchain.com/hub/,登录后可探索所有公开提示词模板。
使用样例:
python
# 导入所需模块:OpenAI聊天模型、LangSmith客户端
from langchain_openai import ChatOpenAI
from langsmith import Client
# 初始化LangSmith客户端,用于拉取Hub上的提示词模板
client = Client()
# 从LangChain Hub拉取提示词模板
# prompt_identifier: 模板的唯一标识,格式为"用户名/模板名"
# include_model=True: 拉取模板时一并包含模板绑定的模型配置(如果有)
# 这里拉取的是"hardkothari/prompt-maker"模板,本质是一个Runnable实例,可直接用于链式调用
prompt = client.pull_prompt(prompt_identifier="hardkothari/prompt-maker", include_model=True)
# 初始化聊天模型(这里使用gpt-4o-mini,也可替换为其他兼容模型)
model = ChatOpenAI(model="gpt-4o-mini")
# 构建链式调用:提示词模板 → 模型
# 模板会先填充变量,再将结果传给模型生成回复
chain = prompt | model
# 循环对话,实现交互式输入
while True:
# 获取用户输入的任务描述
task = input("\n你的任务是什么?(输入 quit 退出聊天)\n")
# 输入quit则退出循环
if task == 'quit':
break
# 获取用户输入的对应提示词
lazy_prompt = input("\n你当前任务对应的提示词是什么?(输入 quit 退出聊天)\n")
if lazy_prompt == 'quit':
break
# 调用链:传入模板所需变量,执行并打印模型返回的漂亮格式结果
chain.invoke({"task": task, "lazy_prompt": lazy_prompt}).pretty_print()逻辑说明
- LangSmith Hub 拉取模板 :
client.pull_prompt()直接从线上 Hub 拉取共享的提示词模板,无需手动编写模板内容,实现模板复用。 - 链式调用 :
prompt | model是 LangChain 标准流水线,自动完成「变量填充 → 模型调用」。 - 交互式对话 :通过
while True循环持续接收用户输入,直到输入quit退出,适合做简单的交互式应用。
少样本提示
概念
少样本提示 ,就是在给大模型的提示词里,提前给出少量(几个)"输入‑输出" 示例 ,告诉模型任务格式、风格、规则,再让模型处理新问题。简单说:给几个例子,让模型照猫画虎。
对应概念区分:
- 零样本(Zero‑Shot):不给例子,直接让模型做任务
- 少样本(Few‑Shot):给 1~10 个示例(最常用)
- 多样本(Many‑Shot):给大量示例
作用
- 快速告诉模型任务规则、输出格式、语气,不用写复杂指令
- 提升模型在小任务、小众场景、格式敏感任务上的准确率
- 不用微调模型,纯靠提示词就实现任务对齐,成本极低
结构
python
【系统指令:简单说明任务】
示例1:
输入:xxx
输出:xxx
示例2:
输入:xxx
输出:xxx
用户问题:
输入:【新问题】
输出:LangChain 实现方式
用 FewShotPromptTemplate,可以批量管理示例、动态抽取示例,是工程上标准写法。
python
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotChatMessagePromptTemplate
)
from langchain_openai import ChatOpenAI
# ----------------------
# 1. 定义少样本示例(翻译任务的输入输出对)
# ----------------------
examples = [
{"text": "hi, what is your name?", "output": "你好,你叫什么名字?"},
{"text": "hi, what is your age?", "output": "你好,你多大了?"},
]
# ----------------------
# 2. 定义示例的聊天模板(将每个示例转为 user-ai 消息对)
# ----------------------
examples_prompt_template = ChatPromptTemplate([
("user", "{text}"), # 示例中的用户输入
("ai", "{output}"), # 示例中的AI输出
])
# ----------------------
# 3. 构建少样本提示模板(自动把所有示例转为消息列表)
# ----------------------
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples, # 传入少样本示例列表
example_prompt=examples_prompt_template, # 传入单条示例的模板
)
# ----------------------
# 4. 构建最终聊天提示模板(系统指令 + 少样本示例 + 新用户问题)
# ----------------------
chat_prompt_template = ChatPromptTemplate([
("system", "将文本从{language_from}翻译为{language_to}"), # 系统指令
few_shot_prompt, # 插入少样本示例消息列表
("user", "{text}"), # 新用户输入的待翻译文本
])
# ----------------------
# 5. 调用模板并打印结果(验证格式)
# ----------------------
print(chat_prompt_template.invoke({
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your favourite food?",
}))
# ----------------------
# 6. 结合模型链式调用(可选)
# ----------------------
model = ChatOpenAI(model="deepseek-chat", api_key="你的API密钥", base_url="https://api.deepseek.com/v1")
chain = chat_prompt_template | model
chain.invoke({
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your favourite food?",
}).pretty_print()增强信息提取能力
python
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List, Optional
# ----------------------
# 1. 定义提取结构
# ----------------------
class Person(BaseModel):
name: Optional[str] = Field(description="姓名")
hair_color: Optional[str] = Field(description="头发颜色,不知道则为null")
skin_color: Optional[str] = Field(description="肤色,不知道则为null")
height_in_meters: Optional[str] = Field(description="身高,不知道则为null")
class Data(BaseModel):
people: List[Person] = Field(description="人员列表")
# ----------------------
# 2. 少样本示例
# ----------------------
examples = [
{
"input": "海洋是广阔的、蓝色的。它有两万多英尺深",
"output": Data(people=[])
},
{
"input": "小明在跳舞,1米78的身高看起来很灵活",
"output": Data(people=[
Person(name='小明', hair_color=None, skin_color=None, height_in_meters='1.78')
])
}
]
# ----------------------
# 3. 少样本模板
# ----------------------
example_prompt = ChatPromptTemplate.from_messages([
("user", "{input}"),
("ai", "{output}"),
])
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
# ----------------------
# 4. 最终提示词
# ----------------------
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
few_shot_prompt,
("user", "{text_input}")
])
# ----------------------
# 5. 模型 + 结构化输出
# ----------------------
model = ChatOpenAI(
model="deepseek-chat",
api_key="你的KEY",
base_url="https://api.deepseek.com/v1"
)
structured_llm = model.with_structured_output(schema=Data)
# ----------------------
# 6. 链式调用
# ----------------------
chain = prompt | structured_llm
result = chain.invoke({
"text_input": "篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫挚友李明,完成一记绝杀。"
})
print(result)如何增强信息提取能力?
1. 结构化输出约束
- 用
Pydantic定义严格的 Schema(如Person/Data),强制模型输出固定格式。 - 配合
model.with_structured_output(),让模型直接返回可解析的对象,避免自由文本歧义。 - 字段描述(
description)能引导模型精准理解每个属性的含义。
2. 少样本提示(Few-Shot Prompting)
- 提供「文本 → 结构化结果」的示例,让模型学习提取规则和格式。
- 示例中明确展示了:
- 未知属性填
null(如hair_color=None) - 身高单位统一为米(如
1.78) - 多人物场景如何封装为列表
- 未知属性填
- 示例越多、覆盖场景越全,模型提取准确率越高。
3. 系统指令引导
- 明确角色:
你是一个提取信息的专家 - 明确规则:
只从文本中提取相关信息、不知道则返回null - 避免模型编造信息,保证提取结果的严谨性。
4. 模板结构优化
- 顺序:
系统指令 → 少样本示例 → 新输入,让模型先学习规则再处理新数据。 - 用
MessagesPlaceholder动态插入示例,便于扩展和维护。
示例
在大模型应用开发中,信息提取是高频场景 ------ 从文本中抽取出姓名、身高、实体关系等结构化数据,直接决定后续业务能否自动化处理。本文将结合一段完整代码,拆解如何通过「少样本提示 + 工具调用格式 + 结构化输出」三重手段,打造工业级可靠的信息提取能力。
我们的目标是:从任意文本中提取人物信息(姓名、发色、肤色、身高),并保证输出格式严格可控、结果准确不编造。
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List, Optional
# ----------------------
# 1. 定义结构化输出 Schema
# ----------------------
class Person(BaseModel):
name: Optional[str] = Field(description="姓名")
hair_color: Optional[str] = Field(description="头发颜色,不知道则为null")
skin_color: Optional[str] = Field(description="肤色,不知道则为null")
height_in_meters: Optional[str] = Field(description="身高,不知道则为null")
class Data(BaseModel):
people: List[Person] = Field(description="人员列表")
# ----------------------
# 2. 准备少样本示例
# ----------------------
examples = [
(
"海洋是广阔的、蓝色的。它有两万多英尺深",
Data(people=[]),
),
(
"小明在跳舞,1米78的身高看起来很灵活",
Data(people=[
Person(name='小明', hair_color=None, skin_color=None, height_in_meters='1.78'),
]),
),
]
# ----------------------
# 3. 工具示例转消息函数
# ----------------------
def tool_example_to_messages(txt, tool_calls, ai_response):
messages = []
messages.append(HumanMessage(content=txt))
messages.append(AIMessage(content=ai_response, tool_calls=tool_calls))
return messages
# ----------------------
# 4. 示例转消息列表(少样本提示核心)
# ----------------------
example_messages = []
for txt, tool_call in examples:
if tool_call.people:
ai_response = "检测到人"
else:
ai_response = "未检测到人"
example_messages.extend(
tool_example_to_messages(
txt=txt,
tool_calls=[tool_call],
ai_response=ai_response
)
)
# ----------------------
# 5. 构建提示词模板
# ----------------------
prompt_template = ChatPromptTemplate(
[
SystemMessage(content="你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
MessagesPlaceholder("example_messages"),
("user", "{new_message}"),
]
)
# ----------------------
# 6. 模型与结构化输出绑定
# ----------------------
model = ChatOpenAI(
model="deepseek-chat",
api_key="你的API密钥",
base_url="https://api.deepseek.com/v1"
)
structured_llm = model.with_structured_output(schema=Data)
# ----------------------
# 7. 链式调用与执行
# ----------------------
chain = prompt_template | structured_llm
result = chain.invoke({
"example_messages": example_messages,
"new_message": "篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫李明,完成一记绝杀。"
})
print(result)重点
1. 少样本提示:模型规则
少样本提示(Few-Shot Prompting)是不微调模型、快速对齐任务的核心手段,我们通过「示例 → 消息列表」的转换,让模型直观学习提取规则。
-
示例设计 :每个示例是
(输入文本, 期望输出)元组:- 无人物文本 → 输出空列表
Data(people=[]) - 有人物文本 → 输出完整
Person列表,未知属性填None覆盖「正例 / 反例」,让模型学会判断是否存在人物、如何提取属性。
- 无人物文本 → 输出空列表
-
示例转消息 :通过
tool_example_to_messages函数,将示例转换为对话消息对:pythondef tool_example_to_messages(txt, tool_calls, ai_response): messages = [] messages.append(HumanMessage(content=txt)) # 用户输入 messages.append(AIMessage(content=ai_response, tool_calls=tool_calls)) # AI 回复(含结构化数据) return messages最终
example_messages是这样的对话序列:python用户:海洋是广阔的... AI:未检测到人(附带空列表工具调用) 用户:小明在跳舞... AI:检测到人(附带小明的结构化数据)模型会模仿这个序列,对新输入执行相同逻辑。
2. 工具调用格式:让输出更贴近真实交互
这段代码的进阶之处,是引入了工具调用(Tool Calling)风格的示例:
AIMessage(content=ai_response, tool_calls=tool_calls):content:给用户看的自然语言总结(如「检测到人」)tool_calls:给系统用的结构化数据(Data对象)
- 这种格式模拟了真实业务场景:模型先「调用工具提取数据」,再「生成自然语言回复」,让模型学会区分「用户可见输出」和「系统可用数据」。
总结
想要打造可靠的信息提取能力,记住这三个核心知识点:
- Schema 锁格式:用 Pydantic 定义输出结构,让模型输出可解析的数据。
- 示例教规则:用少样本示例告诉模型「怎么提取、什么情况返回什么」。
- 结构化输出绑定 :用
with_structured_output强制模型遵循格式,避免自由文本。
此示例代码就是这三板斧的完美实践 ------ 既保留了代码的简洁性,又实现了工业级的提取可靠性,非常适合作为信息提取场景的模板代码。
示例选择器
背景:
当拥有大量示例数据集时,若全部放入提示词会导致:
- 提示词过长 → 成本上升、延迟增加
- 示例过多 → 反而混淆模型、降低性能因此需要动态筛选示例,而非全量使用。
作用:
在 LangChain 中,示例选择器 是从示例集合里,按特定策略自动筛选出最相关 / 最优的示例子集,用于构建高效少样本提示。
关键权衡:
- 更多示例通常能提升模型性能,但过长提示会推高成本与延迟。
- 模型能力越强,所需精准示例越少;最佳实践是通过实验验证不同示例数量的效果。
- 目标:在「性能」和「成本 / 延迟」之间找到平衡。
流程:
示例数据集 → 示例选择器(策略筛选) → 输出「高质量示例子集」+「排除冗余示例集」,最终用子集构建少样本提示。

长度
python
import re
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
# ----------------------
# 1. 反义词示例集合
# ----------------------
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# ----------------------
# 2. 示例模板(定义单条示例的格式)
# ----------------------
example_prompt = PromptTemplate.from_template(
"Input: {input}\nOutput: {output}"
)
# ----------------------
# 3. 长度-based 示例选择器(核心组件)
# ----------------------
example_selector = LengthBasedExampleSelector(
examples=examples, # 传入全部示例
example_prompt=example_prompt, # 示例格式化模板
max_length=25, # 格式化后示例的最大允许长度(单词数)
# 可选:自定义长度计算函数(默认按空格/换行分割单词计数)
get_text_length=lambda x: len(re.split(r"\n| ", x))
)
# ----------------------
# 4. 少样本提示模板(整合选择器)
# ----------------------
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 使用示例选择器动态选示例
example_prompt=example_prompt, # 单条示例格式
prefix="给出每个输入的反义词:", # 提示前缀(任务说明)
suffix="Input: {adjective}\nOutput:", # 后缀(新输入占位)
input_variables=["adjective"], # 最终输入变量
)
# ----------------------
# 5. 测试调用
# ----------------------
if __name__ == "__main__":
# 传入新输入,示例选择器会自动筛选符合长度限制的示例
prompt = few_shot_prompt.invoke({"adjective": "big"})
print(prompt.text)知识点讲解
LengthBasedExampleSelector是什么?
它是 LangChain 提供的按「文本长度」筛选示例的选择器,核心目标是:
- 控制最终提示词的总长度,避免因示例过多导致Token 超限、成本上升、延迟增加。
- 自动从示例库中挑选尽可能多但不超过长度上限的示例,平衡「示例数量」和「提示长度」。
- 参数解析
| 参数 | 作用 |
|---|---|
examples |
完整的示例数据集 |
example_prompt |
单条示例的格式化模板,用于计算示例渲染后的长度 |
max_length |
格式化后所有选中示例的总长度上限(默认按「单词数」计量) |
get_text_length |
自定义长度计算函数,默认按 \n 或空格分割字符串计数单词 |
-
工作流程
-
遍历所有示例,用
example_prompt格式化每条示例。 -
用
get_text_length计算格式化后示例的长度。 -
按顺序累加示例长度,直到即将超过
max_length时停止。 -
最终返回「不超过长度上限」的示例子集,用于构建少样本提示。
-
与
FewShotPromptTemplate的配合
FewShotPromptTemplate不再直接接收examples,而是接收example_selector。- 调用时,
example_selector会动态筛选示例 ,再和prefix/suffix拼接成最终提示词。 - 这种设计让提示词长度可控且自适应,避免固定示例数量导致的冗余或不足。
运行示例
当 max_length=25 时,最终提示词可能为:
python
给出每个输入的反义词:
Input: happy
Output: sad
Input: tall
Output: short
Input: energetic
Output: lethargic
Input: big
Output:选择器会自动挑选刚好不超过长度限制的示例,保证提示词紧凑且有效。
适用场景
- 示例库较大,需要严格控制提示词 Token 数的场景。
- 对成本、延迟敏感,希望避免过长提示的生产环境。
- 任务简单,少量示例即可让模型学习规则的场景(如反义词、简单分类)。
对比:固定示例 vs 长度选择器
| 方式 | 优点 | 缺点 |
|---|---|---|
| 固定示例 | 简单直观,无需额外组件 | 可能过长 / 过短,难以适配不同输入 |
| 长度选择器 | 自适应控制长度,避免 Token 超限 | 需要配置参数,逻辑稍复杂 |
语义相似
1. 本质
语义相似性是衡量文本在含义层面的接近程度,而非表面文字相似度:
- 表面不同但含义相近:如「我喜欢猫」和「我讨厌狗」,都表达对动物的态度,语义相似。
- 表面相同但含义不同:如「苹果很甜」和「苹果市值创新高」,前者指水果,后者指公司,语义不相似。
- 核心价值:能解决一词多义、表面文字差异大的场景,更贴近人类对文本含义的理解。
2. LangChain 实现原理
LangChain 通过嵌入向量 + 余弦相似度来实现语义相似性示例选择:
- 将输入文本和所有示例文本转换为向量嵌入(Embedding)。
- 计算输入向量与每个示例向量的余弦相似度。
- 选择相似度最高的若干示例,用于构建少样本提示。
3. 特点
- 更精准:按「含义」而非「字面」匹配示例,避免字面差异导致的示例选择偏差。
- 更高效:只选择和当前输入最相关的示例,减少无关示例对模型的干扰,提升任务性能。
- 更灵活:能适配复杂场景(如一词多义、抽象语义),比长度选择器更贴合业务语义需求。

组件讲解
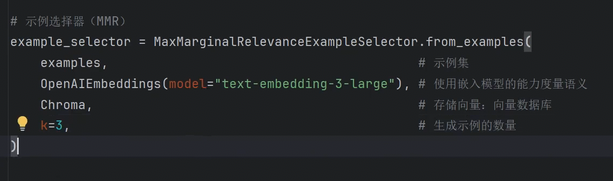
SemanticSimilarityExampleSelector是什么?
它是 LangChain 中按「语义相似度」筛选示例的选择器,核心目标是:
- 不再按「长度」或「顺序」选示例,而是优先选择和输入在含义上最接近的示例。
- 解决「字面差异大但含义相近」或「字面相同但含义不同」的场景,让模型学习更相关的规则。
2.参数解析
| 参数 | 作用 |
|---|---|
examples |
完整的示例数据集 |
embeddings |
嵌入模型(如 OpenAIEmbeddings),将文本转换为向量,用于度量语义相似度 |
vectorstore_cls |
向量数据库(如 Chroma),存储所有示例的向量,用于高效检索相似示例 |
k |
最终选择的最相似示例数量 ,比如 k=1 只选最像的 1 个 |
-
工作流程
-
向量化 :初始化时,将所有示例文本通过
embeddings转换为向量,存入Chroma向量库。 -
相似度检索 :调用时,将新输入文本也转换为向量,在向量库中查找余弦相似度最高 的
k个示例。 -
构建提示 :将选中的相似示例和
prefix/suffix拼接,生成最终少样本提示。
与长度选择器的对比
| 维度 | LengthBasedExampleSelector |
SemanticSimilarityExampleSelector |
|---|---|---|
| 选择依据 | 示例文本长度(控制提示词 Token 数) | 输入与示例的语义相似度(优先选最相关示例) |
| 适用场景 | 控制成本、延迟,避免 Token 超限 | 任务复杂,需要模型学习语义相关的规则 |
| 优点 | 简单直观,严格控制提示长度 | 更精准,避免无关示例干扰,提升模型性能 |
| 缺点 | 不考虑示例与输入的相关性,可能选到无关示例 | 依赖嵌入模型和向量库,实现稍复杂 |
运行示例
当输入 joyful 时,选择器会匹配最相似的示例 happy,最终提示词为:
python
给出每个输入的反义词:
Input: happy
Output: sad
Input: joyful
Output:模型会基于「happy → sad」这个最相关的示例,推理出 joyful 的反义词。
适用场景
- 任务语义复杂,需要按含义匹配示例(如情感分析、同义词 / 反义词、抽象概念提取)。
- 示例库较大,希望只给模型看最相关的示例,减少冗余信息。
- 对模型输出精度要求高,需要避免无关示例混淆模型。
MMR
- 定义
最大边际相关性(Maximal Marginal Relevance, MMR) 是一种重新排序算法 ,以语义相似性为基础,从候选集中选出一组既贴合查询主题、又彼此多样化的结果,平衡「相关性」与「多样性」。
- 与纯语义相似性的区别
| 维度 | 纯语义相似性 | 最大边际相关性(MMR) |
|---|---|---|
| 类比 | 面试官:给每个应聘者打分,选最匹配的单个候选人 | 团队经理:组建能力全面的团队,既要匹配要求,又要技能互补 |
| 目标 | 找最相关的单个 / 少数结果 | 找一组结果:既满足相关性,又避免冗余、保证多样性 |
| 策略 | 只看「与查询的匹配度」 | 先选最相关的,后续迭代选择「既相关又和已选结果差异大」的候选 |
- 特点
- 相关性:候选结果必须和查询主题匹配,满足基本要求。
- 多样性 / 新颖性:结果之间不能高度重复,要覆盖不同角度、场景或信息维度,避免信息茧房。
- 迭代逻辑:先选最相关的「核心结果」,再逐步加入「相关但和已有结果互补」的候选,最终形成全面且不冗余的集合。
- 典型使用场景
- 推荐系统:推荐与用户兴趣相关但类型不同的内容,避免「信息茧房」。
- 文档摘要:从长文本中选能代表主旨、且信息不重复的句子,提升摘要质量。
- RAG(检索增强生成):对知识库检索到的相关文档做去重 + 多样化筛选,减少 LLM 幻觉,提升答案全面性。
- 语义搜索:在高相关结果中,进一步筛选出覆盖不同维度的内容,避免结果同质化。
用例:
NGram
概念
- ngram :文本序列中连续的 n 个词 / 字符(如 unigram = 单个词、bigram = 连续 2 个词)。
- 传统 ngram 重叠 :通过统计两段文本完全相同的 ngram 数量 来衡量相似度,是表面字面匹配,无法处理同义词 / 近义词(如「苹果」和「iPhone」字面不同,传统 ngram 重叠度为 0)。
语义 ngram 重叠(核心升级)
不再比较词本身是否相同 ,而是比较词背后的语义向量(Embedding):
- 计算两个词在语义空间的向量相似度,若超过阈值,则视为「重叠」。
- 例子:「苹果」和「iPhone」字面不同,但向量相似度高达 0.95,会被判定为重叠;「很」和「非常」、「好用」和「不错」同理。
- 本质:把字面重叠 升级为语义层面的重叠,能捕捉「换词不改意」的相似性。
特点
- 解决传统 ngram 无法处理同义词 / 近义词的缺陷。
- 更贴合人类对文本含义的理解,精准识别「改写但保留核心思想」的相似文本。
使用场景
- 剽窃检测:发现更换词汇但保留核心思想的「智能剽窃」。
- 文本相似度评估:在语义层面衡量文本重复度,比传统 ngram 更精准。
- 少样本提示示例选择:筛选与输入在语义层面更贴近的示例,避免字面差异导致的匹配偏差。
样例
