
文章目录
这里是think的博客
希望可以一起交流知识,一起think
今天我们来学习**指针(3)**吧
一起来think吧
数组名的理解
c
//测试环境:X86
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}
我们发现数组名和数组首元素的地址打印出的结果⼀模一样,数组名就是数组首元素(第⼀个元素)的地址。
例外:sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址。(整个数组的地址和数组首元素的地址是有区别的)
好的,这个是常规的讲法,那么我把我学习中体会的理解说一下:
- 实际上数组名就是整个数组,在定义的时候
int arr[]={1,2,3};这个时候arr就是整个数组,这个时候arr没有退化,因为逻辑上没人使用也就不用退化。 - 当sizeof(数组名),&数组名的时候这个时候数组名也不退化,为什么?因为逻辑上这个时候sizeof要的就是数组的大小,&也要的就是整个数组的地址,那么就不用退化。
- 什么时候数组名的意义会从整个数组退化到数组首元素的地址呢?
- 下标索引,正常单独使用arr等大部分情况,那么为什么要退化? 为了保证逻辑通顺,在大多数情况下,arr的意义会退化为首元素的地址。
- 举个例子,
int a = arr[i];,实际上arri也就是*(arr+i),arr是首元素的地址的话,是不是刚刚好就可以索引到对应位置,找到对应的值了。 - 如果不退化的话,你很难去思考怎么利用整个数组这个概念去找到数组中对应的值的,所以数组退化为了保证表达式逻辑通顺、语言使用简洁。
- 再举一个例子如果arr不退化为首元素地址的话,还是整个数组的话,那么arr打印出来是什么?显然逻辑上是不清楚的。
再来谈谈下一个话题,关于arr和&arr的区别,一个是首元素的地址,一个是整个数组的地址,他们两个到底有什么区别?
这就是我上篇博客深入了解指针(2)所讲到的,解引用后可以改变的内存空间有多少?指针类型的差别就在±1的步子有多大?,这些就取决于指针类型
这里我们先不谈解引用,先来看看±1的步子的差别
c
//测试环境:X86
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
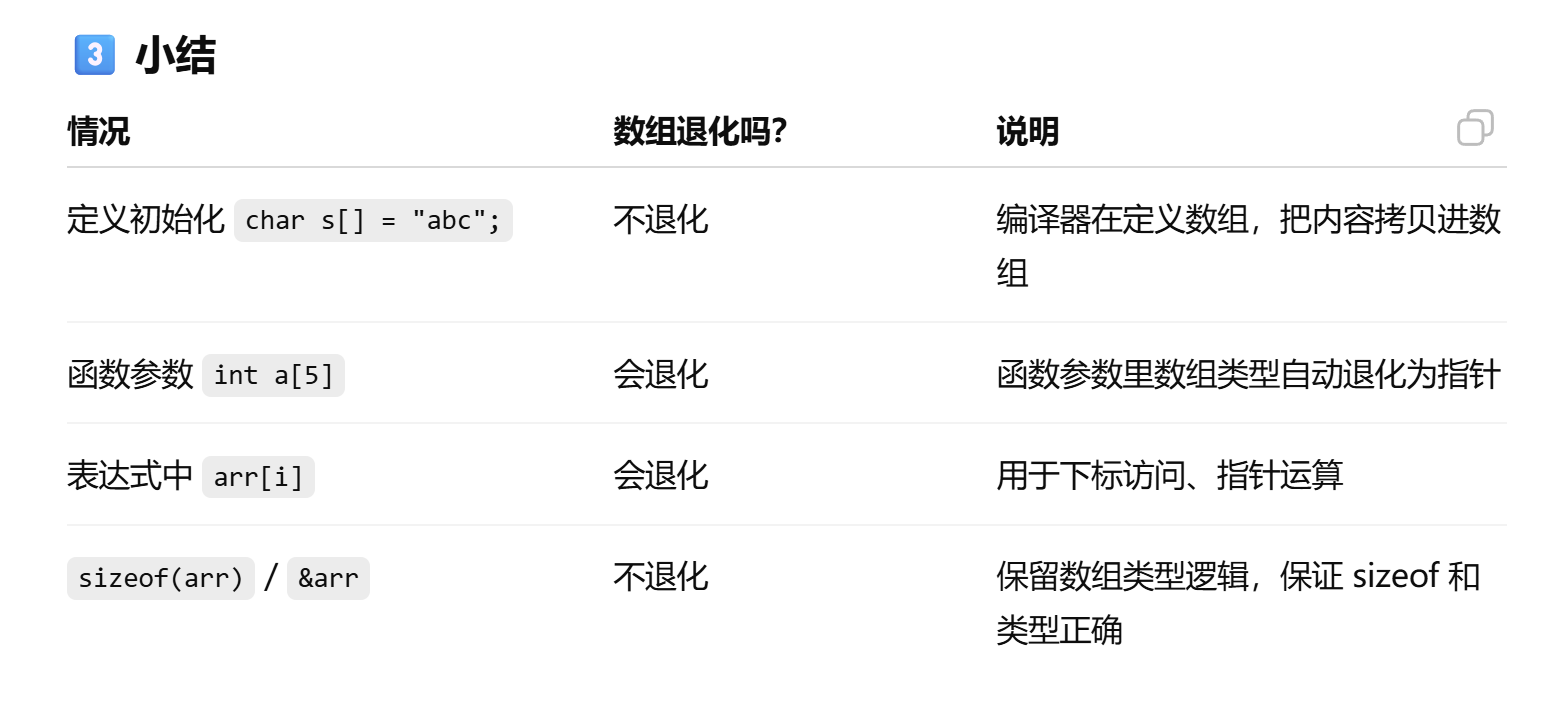
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0] + 1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr + 1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr + 1);
return 0;
}
明显看出首元素地址+1跳过4个字节,而&arr即整个数组地址+1,跳过40个字节。
对arri的理解
for(i = 0; i < sz; i++)
{
printf("%d ", arri);
}
for(i = 0; i < sz; i++){
printf("%d ", *(arr+i));
}
return 0;
通过这两个for循环可以很明白的看出arri其实就是*(arr+i)来的。所以其实iarr这种形式也是可以的哦,只是没有人会这么写。
一维数组传参的本质
c
#include <stdio.h>
//测试环境是x86
void test(int arr[])
{
int sz2 = sizeof(arr)/sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}
这里的这个int arr 是函数形参中的,其中arr会退化为首元素的地址,所以他的实际的形式就是int* arr,
如果 里面还有数字,编译器也是直接忽略的,会把它变为int*arr再往下编译。
其中因为传参数的时候,就是传的首元素的地址,所以sz2就是1了,地址是4个字节,int也是4个字节,其中sz1是10,是因为arr是数组名,定义的时候没有退化,移到sizeof中的时候也没有退化,所以是sz1是10。
而这样的话,因为传递的是指针,所以函数内部就无法用sizeof来求大小了,只能外部传递。
二级指针
c
#include <stdio.h>
int main()
{
int a = 10;
int *pa = &a;
int** ppa = &pa;
return 0;
}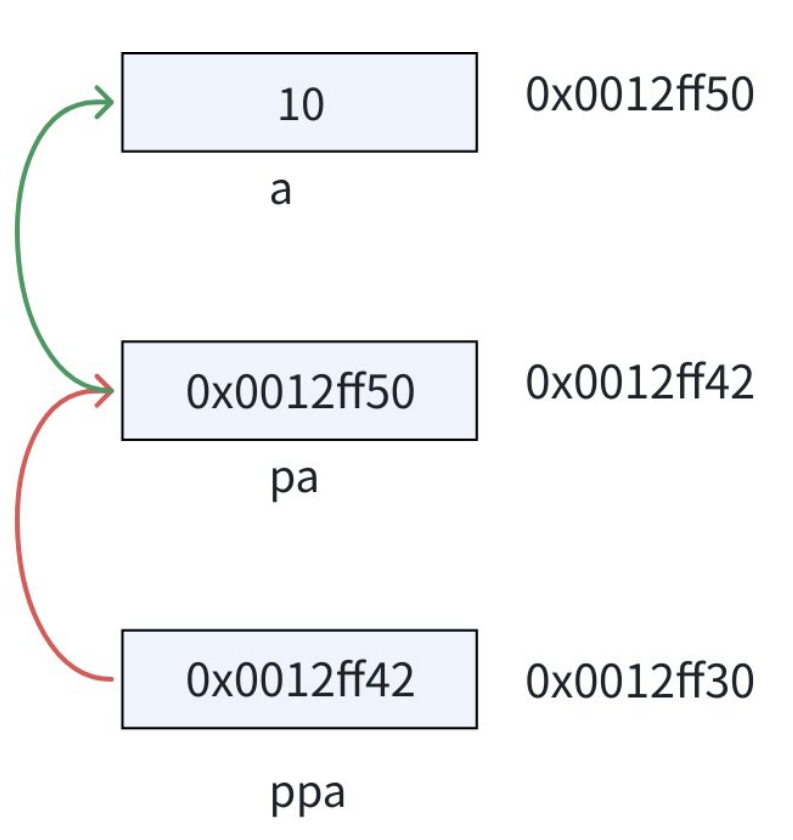
**ppa 先通过 *ppa 找到 pa ,然后对 pa 进行解引用操作: *pa ,那找到的是a。
指针数组
指针数组是一个数组,一个词的本质是它的最后第一个名词,那么指针数组的本质就是数组,正如整型数组和字符数组都是数组来类比得到的。
指针数组的用处
c
#include <stdio.h>
int main()
{
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
//数组名是数组⾸元素的地址,类型是int*的,就可以存放在parr数组中
int* parr[3] = {arr1, arr2, arr3};
int i = 0;
int j = 0;
for(i = 0; i < 3; i++)
{
for(j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}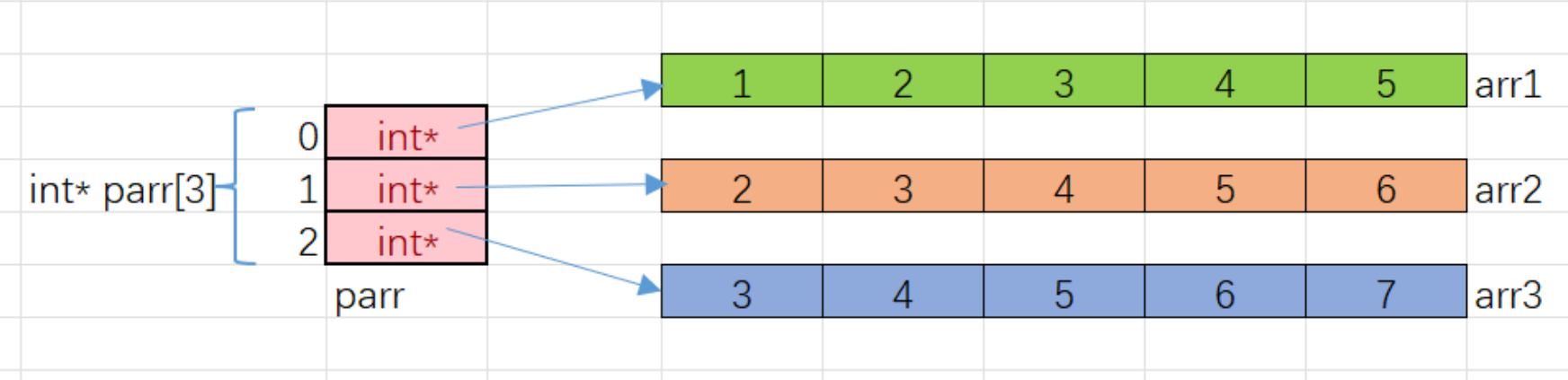
parri 是访问 parr 数组的元素, parri 找到的数组元素指向了整型类型的一维数组, parrij 就是整型类型的一维数组中的元素。
上述的代码模拟出二维数组的效果,实际上并非完全是二维数组,因为每一行并非是连续的。
总结
谢谢观看!