JuiceFS 社区版 1.4 增强了分层存储能力,支持以单文件或目录为粒度指定对象存储类型,使用户可以在文件系统语义下管理不同数据的存储层级。本文将围绕这一能力,介绍其应用背景、方案演进、使用模型、实现思路以及后续演进方向。
01 核心背景
在实际业务中,不同文件的访问频率和性能要求往往差异明显:一部分数据需要被频繁读取或写入,对访问延迟和吞吐较为敏感;另一部分数据写入后很少再被访问,更多关注长期保存成本。分层存储正是为了解决这一问题,即根据数据的访问特征,将其匹配到更合适的存储层,从而兼顾性能与成本。
通常可以根据访问特征将数据分为几类:
- 热数据:访问频繁,通常要求低延迟和较高吞吐;
- 低频数据:访问频率较低,但在需要时仍希望能够快速读取;
- 归档数据:主要用于长期保存,访问频率极低,可以接受一定的恢复等待时间,以换取更低的存储成本。
对象存储本身已经提供了类似的分层能力。以 Amazon S3 为例,S3 Standard 适合频繁访问的数据,S3 Standard-IA 适合低频访问但仍需要毫秒级读取的数据,而 Glacier / Deep Archive 更适合长期归档场景。不同存储类型在访问延迟、最低存储时长和费用模型上存在差异。
| Component | CPU cores | Memory | Network | Disk storage |
|---|---|---|---|---|
| JuiceFS metadata nodes (×3) | 32 cores | 60 GB | 10 Gbps | 500 GB |
| JuiceFS cache nodes (×8) | 104 cores | 200 GB | 10 Gbps | 2 TB × 5 |
| Clients for Windows (×N) | 8 cores | 16 GB | 10 Gbps | 500 GB |
对于构建在对象存储之上的 JuiceFS 来说,关键是将这些能力转化为文件系统层面的分层管理能力:用户按文件、目录或数据集设置存储层级,JuiceFS 负责映射到底层对象存储,并处理写入、迁移和归档恢复等操作。
02 JuiceFS 分层方案的演进
JuiceFS 分层能力的演进,本质上是从"被动不感知对象存储类型",逐步发展到"可在文件和目录粒度管理主动存储层级"。
在 v1.1 以前,JuiceFS 尚未提供存储类型配置能力。用户虽然可以在对象存储侧手动调整对象的 Storage Class,但这些变化不会被 JuiceFS 在文件系统层面统一感知和管理。对于标准层、低频层等支持实时访问的对象,通常不会影响正常读写;但如果对象被转入归档类存储,则可能因无法直接读取而导致访问异常。
从 v1.1 开始,JuiceFS 支持通过 --storage-class 设置对象存储类型。例如,可以在 format 时指定文件系统的默认 Storage Class,也可以在 mount 时覆盖当前挂载点写入数据所使用的存储类型。这使 JuiceFS 开始具备使用对象存储分层能力的基础,但配置粒度仍主要停留在文件系统默认值或挂载点级别,无法针对具体目录、单个文件或不同业务数据集进行精细化管理。
v1.4 进一步将分层能力推进到文件和目录粒度。用户可以根据数据冷热程度,为单个文件或目录设置对应的存储层级;当目录设置了特定层级后,后续在该目录下新建的文件和子目录也可以自动继承这一配置。相比此前的默认值或挂载点级设置,v1.4 更适合按项目、目录、数据集或文件冷热程度进行分层管理。
03 分层存储如何配置
JuiceFS v1.4 分层存储的关键在于:将对象存储的 Storage Class 转化为文件系统可管理的存储在使用层面,JuiceFS v1.4 分层存储可以理解为两个步骤:先建立 Tier ID 与对象存储 Storage Class 的映射关系,再将文件或目录设置到对应的 Tier ID。通过这一方式,用户可以按文件、目录或数据集组织分层策略,而不需要在每次写入时直接指定底层对象的存储类型。
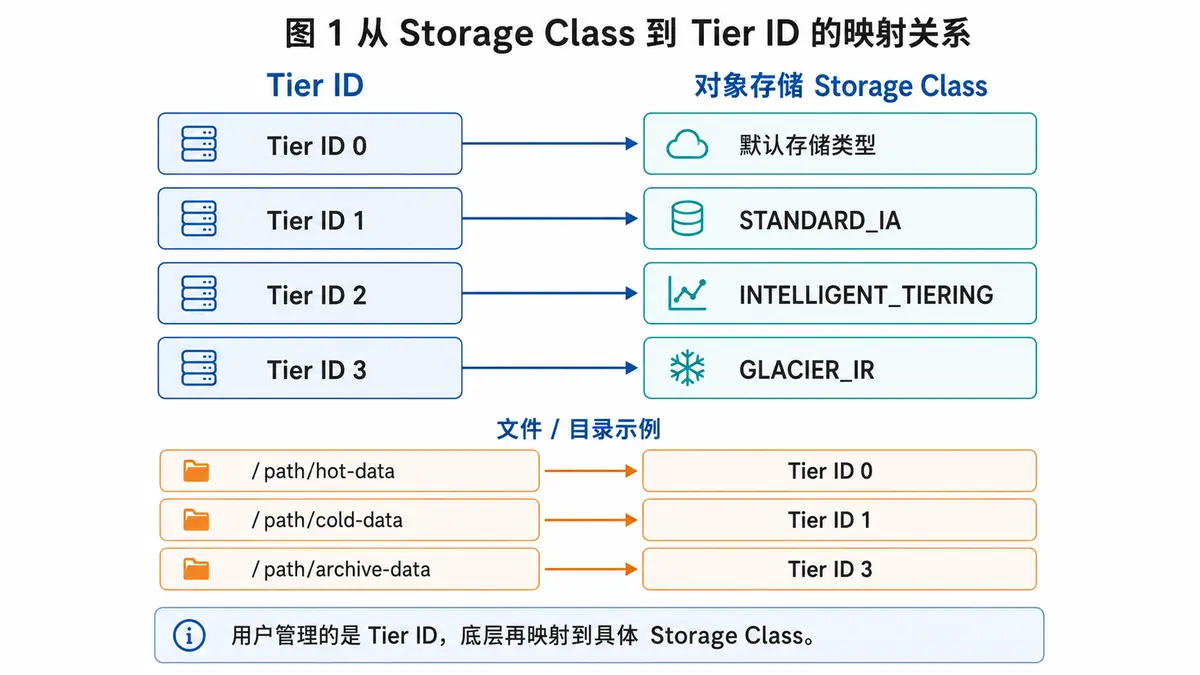
例如,可以将 Tier ID 1--3 分别映射到不同的对象存储类型:
shell
juicefs config redis://localhost --tier-id 1 --tier-sc STANDARD_IA -y
juicefs config redis://localhost --tier-id 2 --tier-sc INTELLIGENT_TIERING -y
juicefs config redis://localhost --tier-id 3 --tier-sc GLACIER_IR -y完成映射后,可以为单个文件或目录设置存储层级:
shell
juicefs tier set redis://localhost --id 1 /path/to/file
juicefs tier set redis://localhost --id 2 /path/to/dir目录级设置具有继承语义。为目录设置 tier-id 后,后续在该目录下新建的文件或子目录会自动继承父目录的存储层级;如果需要处理目录下已有的数据,则可以使用 -r 参数递归设置:

shell
juicefs tier set redis://localhost --id 2 /path/to/dir -r对于 Glacier 等归档类存储,读取前通常需要先发起恢复请求:
shell
juicefs tier restore redis://localhost /path/to/dir -r04 技术实现原理
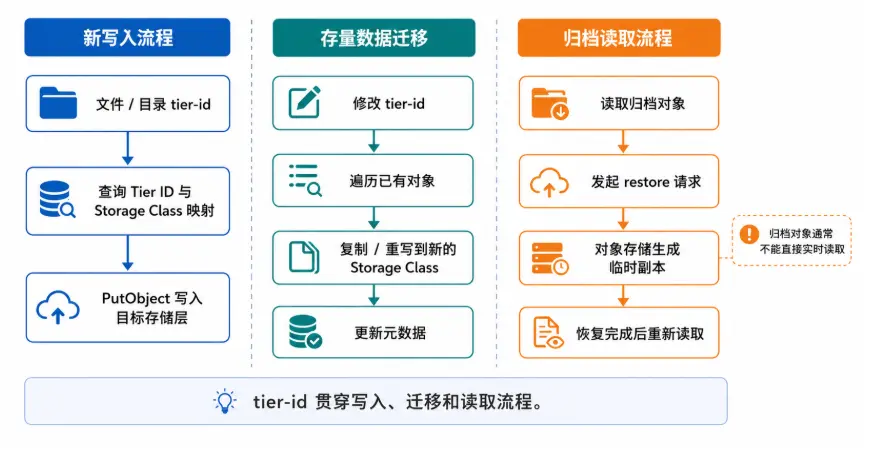
从实现角度看,JuiceFS v1.4 分层存储的关键,是将文件或目录的分层信息纳入元数据管理,并在写入、迁移和读取流程中根据 tier-id 选择相应的对象存储行为。
元数据设计
JuiceFS 使用 tier-id 记录文件或目录所属的存储层级。tier-id 取值为 0 时,表示使用默认存储层;取值为 1--3 时,则对应用户配置的对象存储 Storage Class。
这样,存储层级不再只是对象存储侧的外部状态,而是成为 JuiceFS 可以在文件系统语义下感知和管理的元数据信息。后续写入新数据、迁移存量数据或检查文件状态时,JuiceFS 都可以基于这一元数据判断目标存储类型。
存量数据迁移
对于已有数据,修改存储层级不仅需要更新元数据中的 tier-id,还需要改变对象存储中已有对象的实际 Storage Class。递归设置目录时,JuiceFS 会处理目标目录下的文件和子目录,并通过对象存储的复制能力,将已有对象迁移到新的存储类型。
如果只是修改某个 tier-id 对应的 tier-sc 映射,已有对象的实际存储类型不会自动变化。此时需要使用 tier set --force 显式触发变更,使存量对象改为新的 Storage Class。
写入流程
新文件写入时,JuiceFS 会根据文件自身或父目录继承得到的 tier-id,确定数据应写入的对象存储类型。对于已经设置存储层级的目录,新建数据可以直接进入对应的存储层,避免先写入默认层后再迁移。
读取流程
对于标准层、低频层等支持实时访问的存储类型,读取过程对业务基本透明,JuiceFS 可以按正常流程从对象存储中读取数据。
对于 Glacier、Deep Archive 等归档类存储,对象通常不能直接实时读取。需要用 juicefs tier restore 命令先解冻文件,该命令会向对象存储服务发起恢复请求,对象能否读取以及何时可读,取决于云厂商的恢复机制;恢复完成后,业务再重新发起读取。
因此,归档层更适合长期保存、极低频访问的数据,不适合仍需随时在线读取的业务路径。实际使用时,需要同时评估存储成本、恢复时间和恢复成本。
05 后续演进方向
降低归档类存储的操作成本:归档类存储虽然具有较低的长期存储成本,但在写入、恢复、提前删除和生命周期转换等方面通常存在更复杂的成本模型。如果直接将数据写入归档类型,在频繁变更或批量迁移场景下,可能带来额外的操作成本。
后续,JuiceFS 可结合对象存储的生命周期管理机制,先将数据写入标准存储类型,并在对象上附加相应的 Object Tag。用户随后可以通过云厂商的生命周期规则,根据标签自动、批量地将数据转换到低频或归档存储层。这样既能保留 JuiceFS 在文件系统层面的分层管理能力,也可以利用对象存储原生的批量转换机制,降低批量归档和层级转换过程中的额外开销。
扩展到多桶、多云的分层管理:当前分层存储主要基于同一对象存储后端内的不同 Storage Class。后续,JuiceFS 也可以进一步将"层级"概念扩展到不同存储桶、不同对象存储服务,甚至不同云之间,使分层管理不再局限于单一存储后端。
例如,可以将热数据放置在以本地高性能 SSD 为后端的 MinIO 中,将冷数据或归档数据放置在云厂商的低成本归档存储桶中,并通过策略将数据从热层逐步迁移到冷层。通过这种方式,JuiceFS 有机会在统一文件系统命名空间下,实现跨桶、跨云、跨介质的数据分层管理。
我们希望本文中的一些实践经验,能为正在面临类似问题的开发者提供参考,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。