0.总结分析:
反向传播目的是 进行参数更新,利用损失函数 Error,从后往前,结合梯度下降算法 (公式:w新 = w旧 -学习率*梯度),链式求导(依次求得各个参数的偏导),进行参数更新:
损失函数 --》学习损失函数;
梯度下降算法 ---》网络优化方法(梯度下降优化、学习率衰减策略);
0.1 激活函数:
1️⃣ 激活函数作用 :给神经元注入非线性因素使得神经元可做分类问题;如果没有激活函数,整个神经网络虽然看起来复杂,其本质上只是一种线性模型;
2️⃣ 激活函数种类:Sigmoid,Tanh ,ReLU,Softmax;
(输出层的 二分类一般用: Sigmoid,多分类用:Softmax;回归 用:恒等;
中间隐藏层 一般优先用 ReLU - - > LeakyReLU - - >PReLU - - > Tanh - - > Sigmoid)
0.2 损失函数:
1️⃣ 损失函数概念 :损失函数(Loss function)又叫目标函数(Objective function)、代价函数(Cost function)、误差函数(Error function),就是用来衡量 模型好坏(模型拟合情况)的;
2️⃣ 损失函数种类:多分类损失 CrossEntropyLoss, 二分类损失 BCELoss,MAE,MSE, Smooth L1;
(分类问题:多分类交叉熵损失:CrossEntropyLoss; 二分类交叉熵:BCELoss;
回归问题:MAE:Mean Absolute Error 平均绝对误差; MSE:Mean Squared Error 均方误差; Smooth L1:结合上述两个的特点做的升级、优化;)
0.3 网络优化方法:
1️⃣ 网络优化方法 :梯度下降优化算法中,可能会碰到以下情况:碰到平缓区域,梯度值较小,参数优化变慢1.2.碰到"鞍点",梯度为0,参数无法优化碰到局部最小值,参数不是最优3;对于这些问题,出现了一些对梯度下降算法的优化方法:
2️⃣ 优化方法:Momentum,AdaGrad,RMSProp,Adam;
SGD -- Momentum 动量法:用 指数加权平均法 优化梯度; AdaGrad:用 累积平方梯度 优化;RMSProp:用 指数加权平均 的 累积平方梯度 优化学习率; Adam:Adam = SGD + RMSProp:用 指数加权平均法 分别 优化梯度 和 学习率;
3️⃣ 学习率衰减策略 :学习率越小,梯度下降越慢;学习率越大,梯度下降越快,可能会越过最小值,造成震荡,甚至不收敛(梯度爆炸);
4️⃣ 学习率衰减策略种类:等间隔学习率衰减方法,指定间隔学习率衰减方法, 指数间隔学习率衰减:;
0.4 正则化:
1️⃣ 正则化目的 :避免或降低 模型过拟合,L1正则化特点:可以让权重变为0,相当于降维,使得模型变得的简单;L2正则化让权重无限趋向于0,但不能为0;还有 DropOut随机失活 ,BN批量归一化等方法;
2️⃣ DropOut 随机失活 ;BN(Batch Normalization)批量归一化等方法;
1. 需求 & 分析

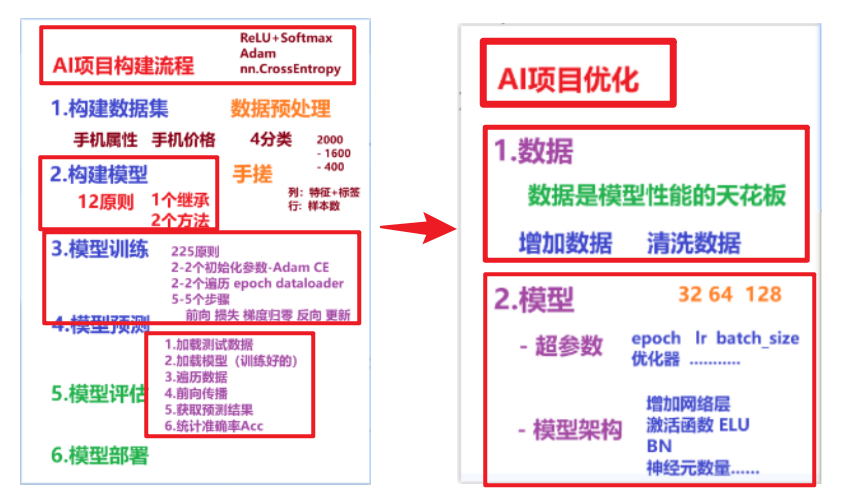
2. 构建数据集


3. 构建模型:(神经网络搭建)--12原则即 1个继承2个方法


4. 模型训练:225原则

5. 模型预测

6. 模型评估
7. 模型部署

8. 代码:
python
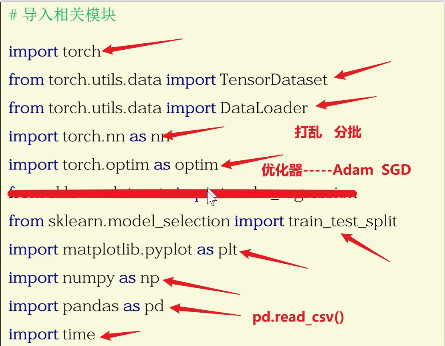
# 1.导入依赖包
import time
import torch
from torch import nn
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset, DataLoader
# 2.构建数据集
def create_datasets():
dataset = pd.read_csv('dataset/手机价格预测.csv')
x, y = dataset.iloc[:, :-1], dataset.iloc[:, -1]
# x = x.type(torch.float32)
# y = y.type(torch.int64)
x = x.astype(np.float32)
y = y.astype(np.int64)
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=666)
# 转换张量数据集
train_dataset = TensorDataset(torch.tensor(x_train.values), torch.tensor(y_train.values))
test_dataset = TensorDataset(torch.tensor(x_test.values), torch.tensor(y_test.values))
return train_dataset, test_dataset, x_train.shape[1], len(np.unique(y_train))
# 3.构建模型
class PhonePriceModel(nn.Module):
def __init__(self, in_dim=20, out_dim=4): # 构建网络层
super(PhonePriceModel, self).__init__()
self.linear1 = nn.Linear(in_dim, 128)
self.linear2 = nn.Linear(128, 256)
self.output = nn.Linear(256, out_dim)
def forward(self, x): # 串联网络层
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
output = self.output(x)
return output
# 4.模型训练
def train():
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
for i in range(50):
dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
# 计算损失
total_loss = 0.0
total_num = 1
start = time.time()
for train_x, train_y in dataloader:
# 1.前向传播
y_pred = model(train_x)
# 2.损失计算
loss = criterion(y_pred, train_y)
total_loss += loss.item()
total_num += 1
# 3.梯度归零
optimizer.zero_grad()
# 4.反向传播
loss.backward()
# 5.参数更新
optimizer.step()
avg_loss = total_loss / total_num
print(f'epoch:{i + 1} Loss:{avg_loss:.4f} Time:{time.time() - start:.2f}s')
# 模型保存
torch.save(model.state_dict(), 'model/PhonePriceModel.pth')
train_dataset, test_dataset, in_dim, out_dim = create_datasets()
model = PhonePriceModel(in_dim, out_dim)
# print(model)
# train()
# 5.模型预测
def test():
global model
# 5.1 获取测试数据
dataLoader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 5.2 加载模型
model = PhonePriceModel(in_dim, out_dim)
model.load_state_dict(torch.load('model/PhonePriceModel.pth'))
# 5.3 模型预测
# 遍历数据
correct = 0
for test_x, test_y in dataLoader:
# 前向传播
y_pred = model(test_x)
# 获取结果
y_pred_label = torch.argmax(y_pred, dim=1)
# 统计Accuracy
correct += (y_pred_label == test_y).sum()
Acc = correct.item() / len(test_dataset)
print(f'Accuracy:{Acc:.4f}')
test()
# 6.模型评估
# 7.模型部署