网站: https://bbs.qyer.com/
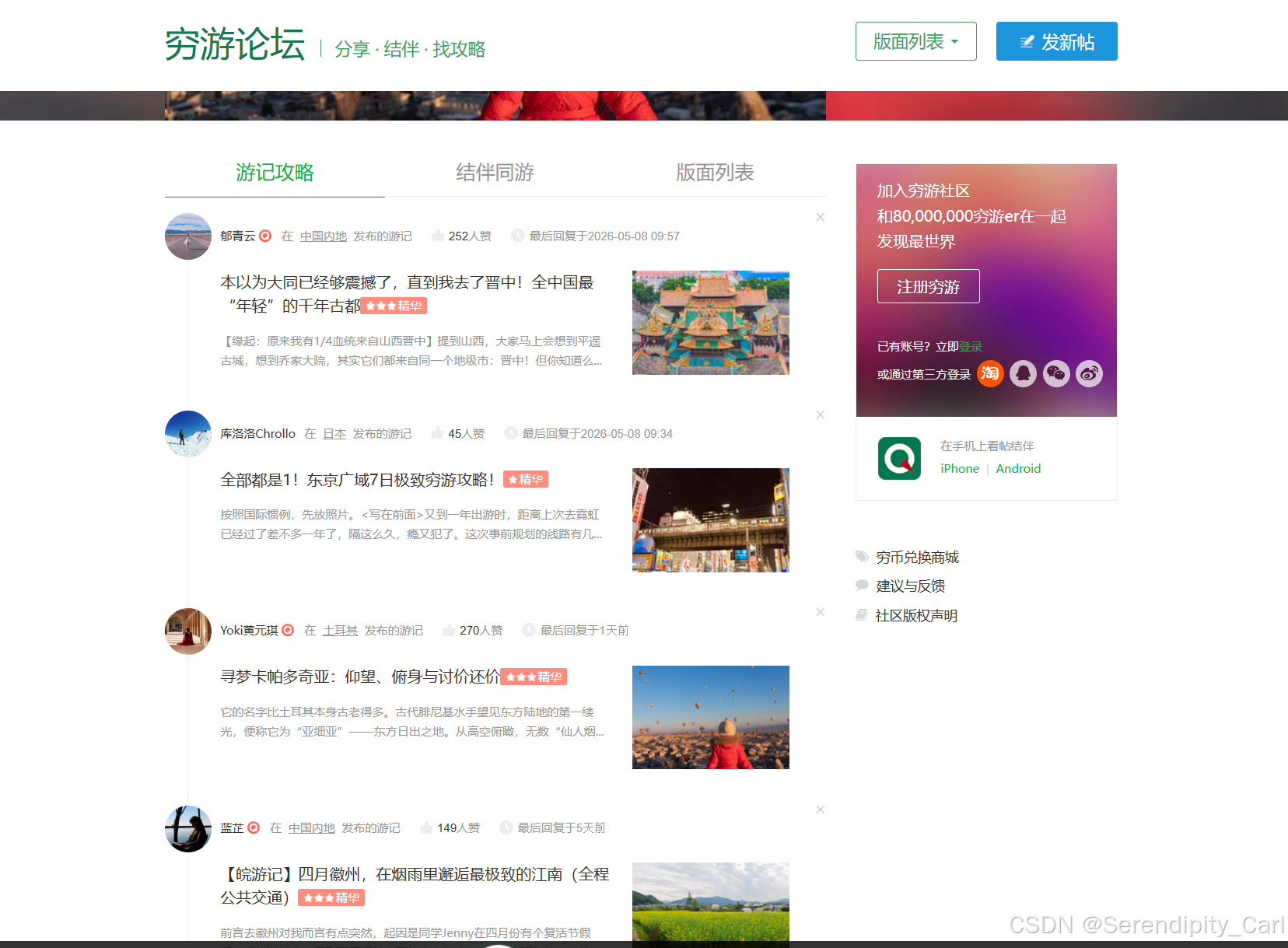
一、 确定目标与网页分析
我们的目标是获取穷游网论坛首页的游览贴列表(即"精选游记"部分)
-
打开目标页面 :https://bbs.qyer.com/
-
观察加载方式 :当我们在页面滑动或点击翻页时 发现页面没有整体刷新 只有游记列表部分更新了 这说明数据是通过 AJAX 异步加载的/ 或者Ctrl+u 打开页面的源代码 然后Ctrl+F搜索想要的数据 发现搜索不到 说明也是动态数据(反之则是静态数据)
-
以下图片中标记的内容为本次获取的内容
-
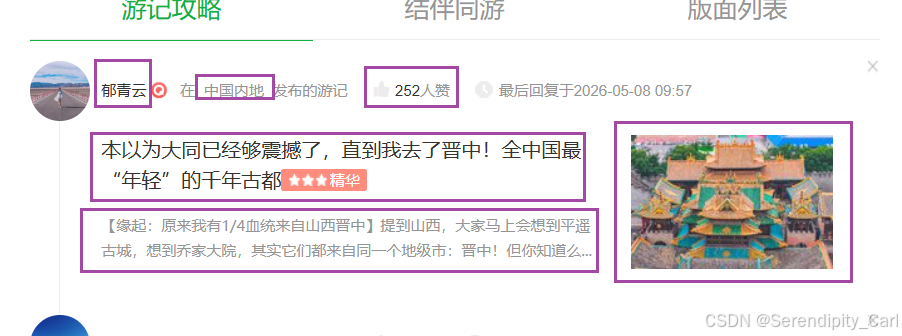
二、 抓包分析(核心步骤)
为了模拟浏览器的请求,我们需要找到后端真实的 API 接口
-
打开开发者工具 :在浏览器页面按下 F12 或右键点击"检查",切换到 Network (网络) 选项卡
-
筛选请求 :由于我们要找的是接口数据 点击 Fetch/XHR 过滤器
-
触发动作:向下滚至页面底部点加载更多或刷新当前页面(Ctrrl+r) 你会看到一个名为 index.php?action=getTravels&... 的请求 这个多半是我们要找的数据包了
-
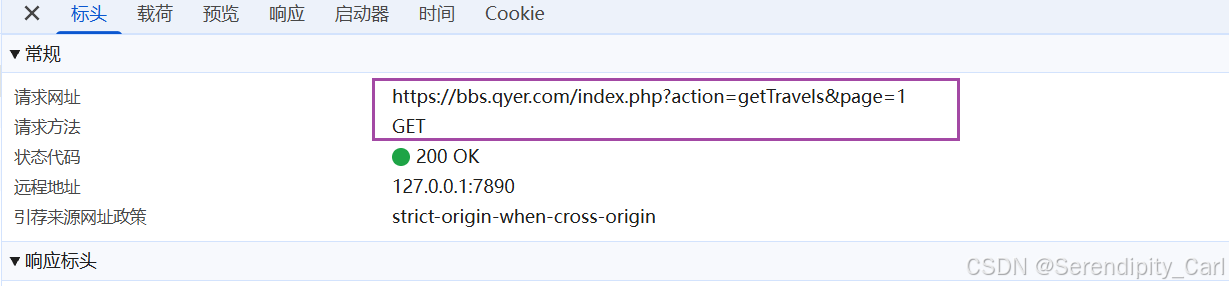
查看请求详情 (Headers):
-
Request URL: 发现请求地址为 https://bbs.qyer.com/index.php
-
Request Method: GET
-
Query String Parameters: 包含 action: getTravels 和 page: 1
-
-
查看预览 (Review):在 Preview 标签页可以看到返回的是格式整齐的 JSON 数据,包含了游记的标题、作者、封面图等
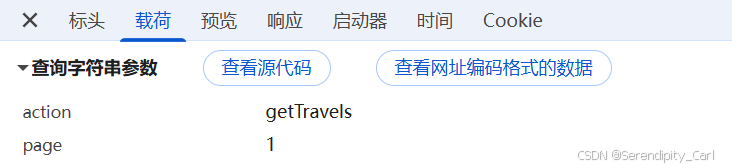
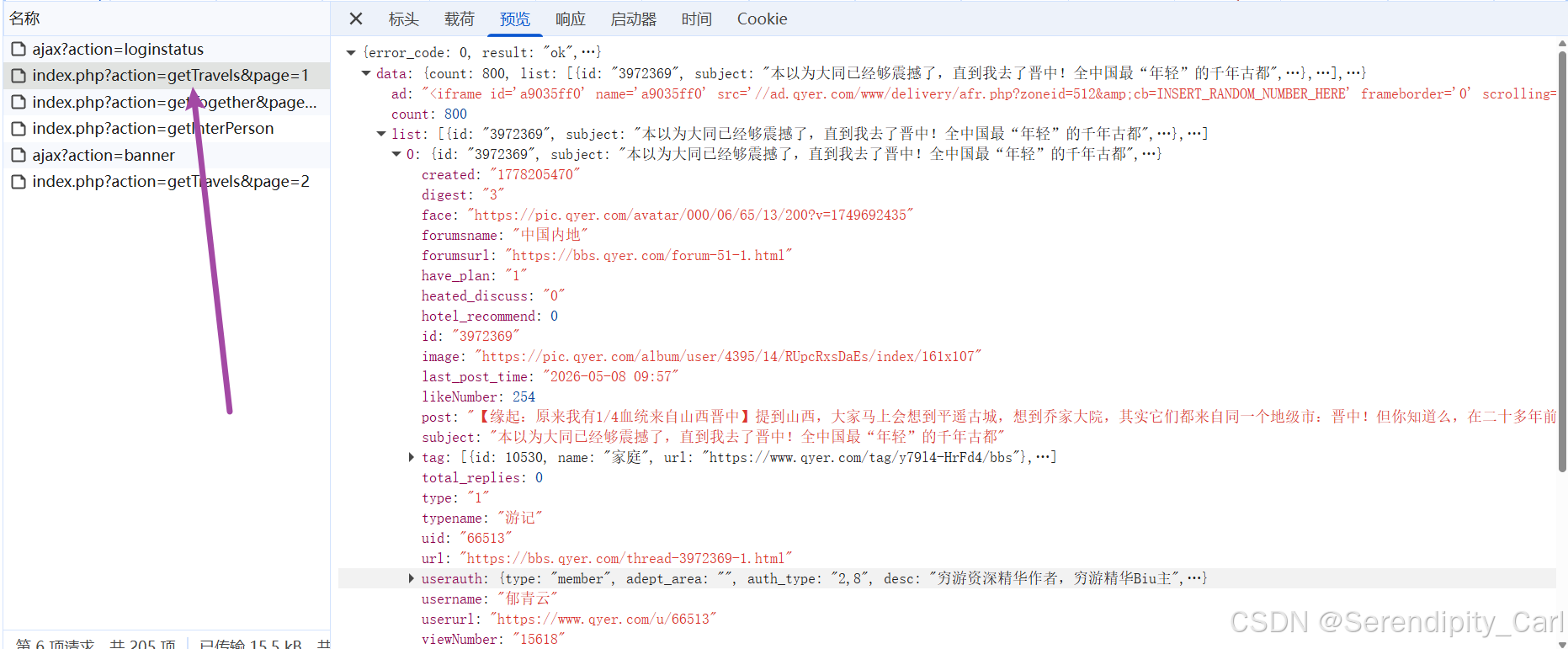
需要的数据都在里面 现在就可以开始写代码了
三、 代码实现逻辑
在编写代码时 我们需要关注三个要素:URL参数、Headers(请求头)、Cookies(身份标识)
1. 模拟请求头 (Headers)
为了让我们的请求看起来像真实用户,必须携带 User-Agent 此外 由于该接口是异步接口 通常需要携带 x-requested-with: XMLHttpRequest
2. 处理 Cookie
部分网站会校验 Cookie 以防恶意采集 虽然对于公开列表页 有时不带 Cookie 也能访问 但为了稳定性 我们通常会带上浏览器中抓取到的基础 Cookie
3. 构造代码
我们将使用 Python 最流行的 requests 库
我就不手搓代码了 这里借助一个工具快速构建请求 爬虫工具库-spidertools.cn
选中数据包之后右击 复制cURL(bash)到上面这个网站中 选择cul转request 复制右边的代码即可
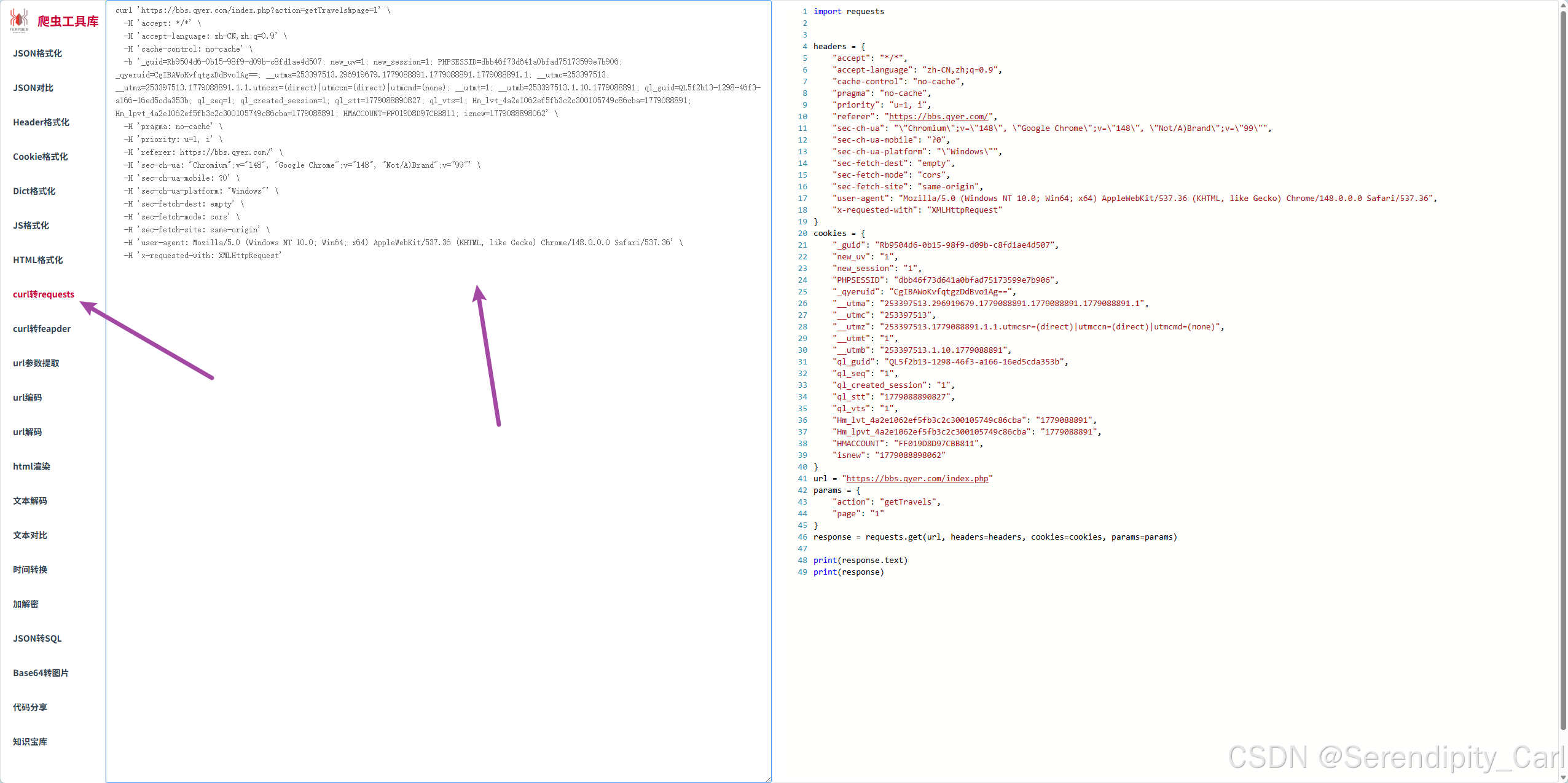
这里我们修改一下代码 将获取的文本改为json 虽然数据包里面并没有这个格式 但是我们之前看到返回的数据结构就是Json
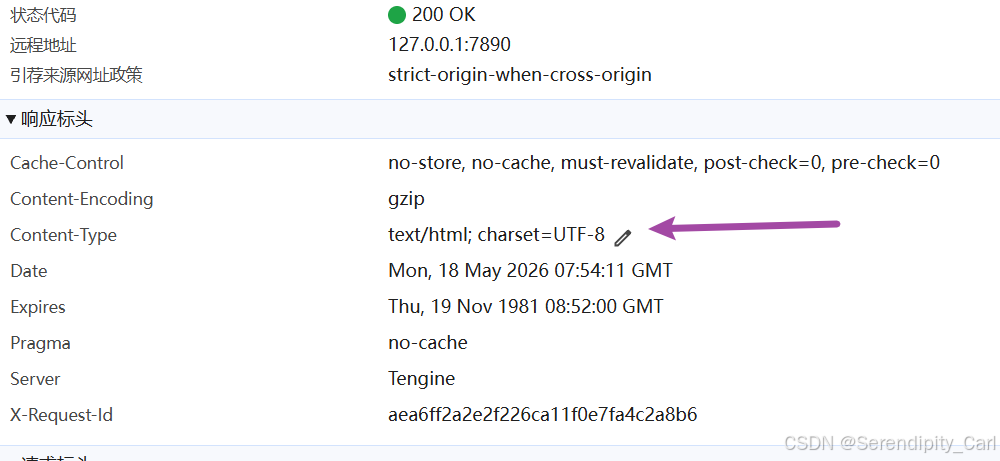
然后因为是Json格式的内容 我们可以使用pprint这个库(记得下载pip一下) 能够让我们的Json数据更有可读性
python
import pprint
import requests
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://bbs.qyer.com/",
"sec-ch-ua": "\"Chromium\";v=\"148\", \"Google Chrome\";v=\"148\", \"Not/A)Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
cookies = {
"这里粘贴你的cookie"
}
url = "https://bbs.qyer.com/index.php"
params = {
"action": "getTravels",
"page": "1"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
pprint.pprint(response.json())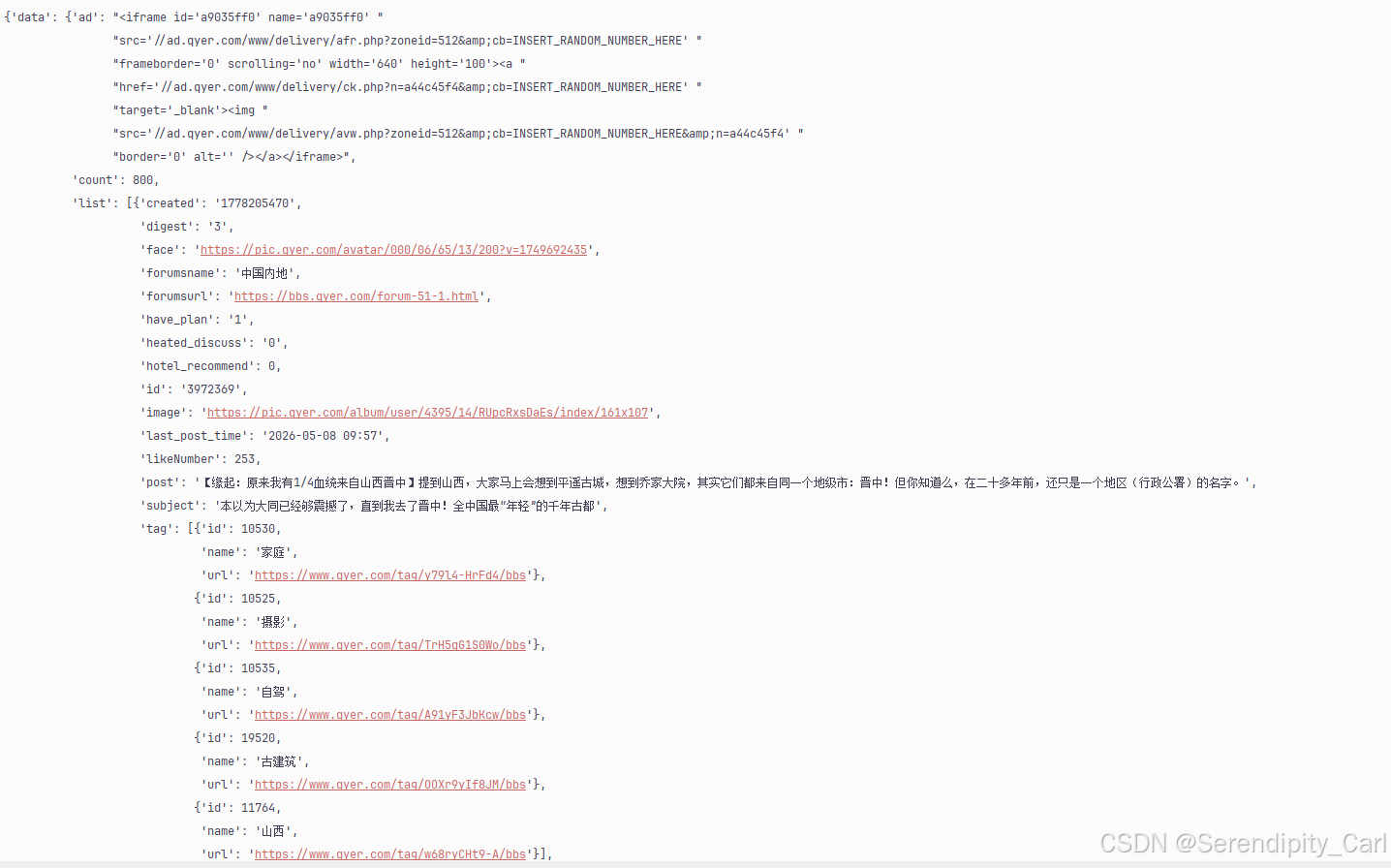
四、 解析数据
现在我们获取到了数据 开始要键值对取值了 拿到所有的数据 很简单了现在
观察控制台打印的数据层级关系 先取data 然后取list 现在拿到的是个列表 我们每页的数据都在里面 是字典套列表的数据格式 后续再循环取值即可
python
json_data = response.json()
for i in json_data['data']['list']:
user_name = i['username']
address = i['forumsname']
like_num = i['likeNumber']
title = i['subject']
content = i['post']
image_url = i['image']
print(user_name, address, like_num, title, content, image_url)
break然后我们边写别求证 看数据是否获取正确 是否达到自己的要求 打印输出一下

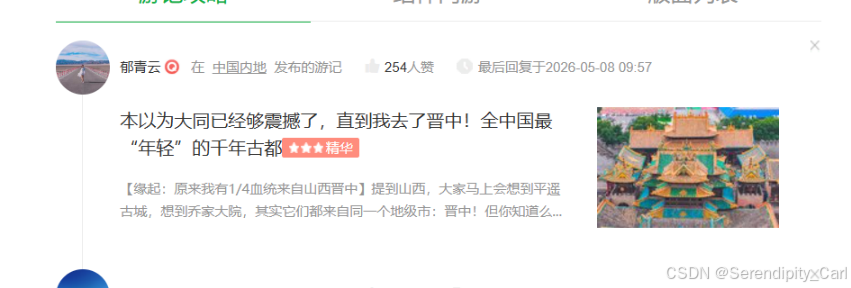
OK 和网页中的一样 我们就可以继续写

现在一页的数据已经获取到了 现在就是想要获取多页的一个数据 我们只需要修改请求参数中page的值即可
这里我们升级一下代码 封装函数(每个函数负责特定的功能)
python
def get_info(page):
url = "https://bbs.qyer.com/index.php"
params = {
"action": "getTravels",
"page": f"{page}"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
json_data = response.json()
lis = []
for i in json_data['data']['list']:
user_name = i['username']
address = i['forumsname']
like_num = i['likeNumber']
title = i['subject']
content = i['post']
image_url = i['image']
dit = {
"用户名": user_name,
"地址": address,
"点赞数": like_num,
"标题": title,
"内容": content,
"图片地址": image_url
}
lis.append(dit)
return lis获取数据存字典中然后在用列表包装 形成 {},{},{},{}的形式 然后作为函数的返回值
Explain: 因为后续我们要保存至excel文件中 这种"典列表"格式 Pandas 就能自动把字典的 Key 识别为列名 Value 识别为行数据
五、 保存数据
同样地 这里需要用到Pandas模块了 没有的话自己pip 镜像源改一下会快很多 不会的话可以看我之前的文章
python
def save_info(lis):
pd.DataFrame(lis).to_excel('Qy_info.xlsx', index=False)OK 现在我们所有的功能代码写完了 接下来就是写程序的入口了
python
if __name__ == '__main__':
# 定义一个变量 存储所有的数据
all_lis = []
# 爬取十页的数据
for page in range(1, 11):
# 这里合并 也可以用extend
all_lis += get_info(page)
save_info(all_lis)六、 查看保存的数据
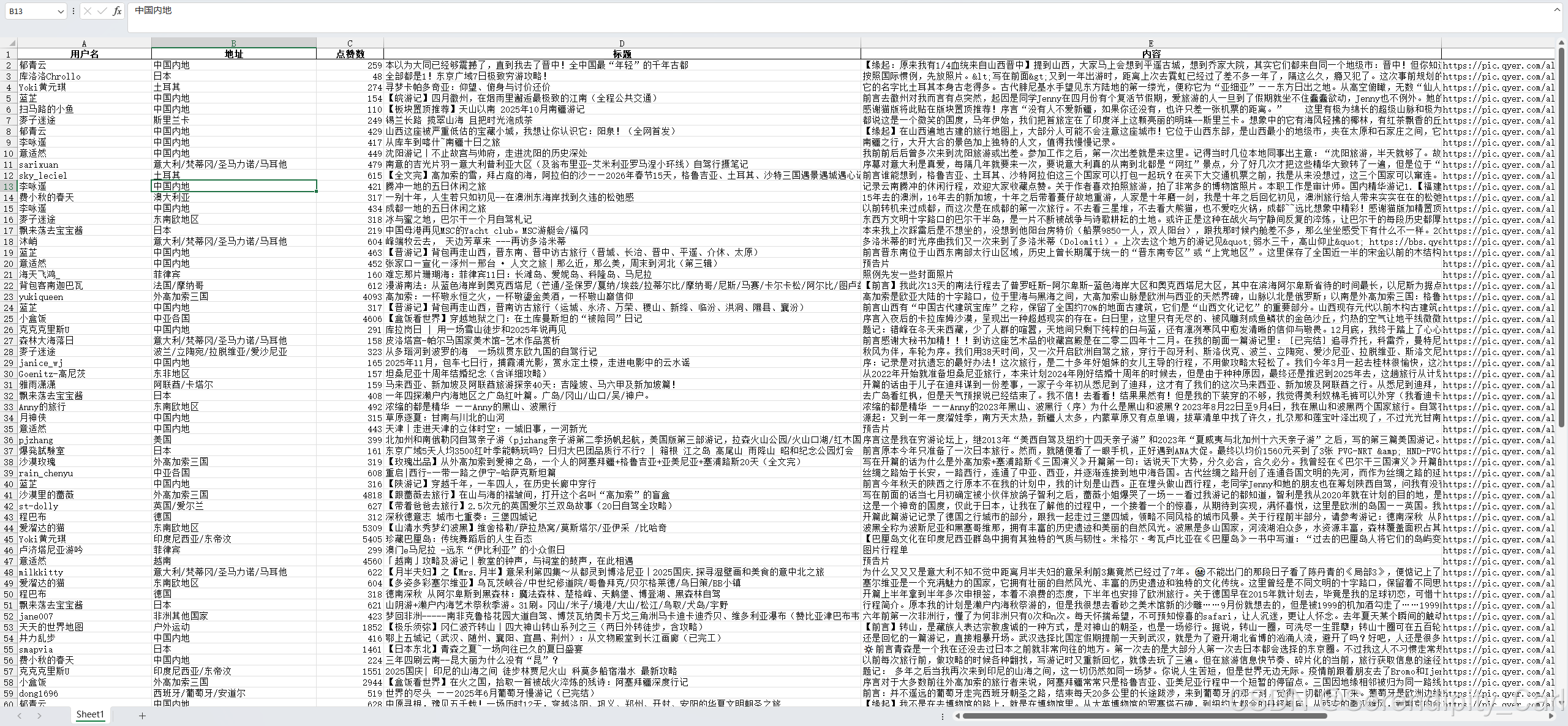
好的 接下来我们进行数据清洗的任务
二.数据清洗
读取Excel表格 我们写到新的py文件中
python
# 导入pandas库
import pandas as pd
# 设置显示所有列(不隐藏任何列)
# 设置显示宽度为1000字符 控制台能展示的列和高度是有限的 如果字段数据多的话看不全
# 目的是让DataFrame打印时完整显示所有列 避免被省略号替代
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
# 读取excel文件
df = pd.read_excel('./QY_info.xlsx')先查看文件的基本情况
python
df.info()
python
# 查看缺失值
print(df.isna().sum())
没有缺失值 这里 如果有的话可以如下写
python
# 哪一列有就写哪一列的列名 或者删掉subset参数
df.dropna(subset=['标题', '内容'], inplace=True)
python
# 随机抽样 抽取十条数据查看
print(df.sample(10))
python
# 去重重复度的数据 这样的数据不太可能重复
df.drop_duplicates(inplace=True)还有跟多的语法这里就不啰嗦了 可以看我之前相关的文章
数据类型转换
python
# 这里点赞数是int类型 但是为了练习语法我们还是将其转换成数据类型
df['点赞数'] = pd.to_numeric(df['点赞数'], errors='coerce')
# df['点赞数'] = df['点赞数'].astype('int')这里推荐用第一行代码 第二行如果存在NaN值会报错 功能少 不全面
接下来处理内容字段
将里面包含的特殊字符 HTML标签等等去除 保留纯文本
python
def clean_content(text):
# 删除所有HTML标签(如<div>, <p>等)
result = re.sub(r'<.*?>', '', text)
# 删除非所有字母、数字和中文字符
result = re.sub(r'[^a-zA-Z0-9\u4e00-\u9fa5]', '', text)
return result
df['内容'] = df['内容'].apply(clean_content)re.sub() 简单来讲就是截取字符串中的字符,将其替换 ^符号在正则中是取反的意思 类似not
地址标准化
python
def address_deal(address):
if '中国' in str(address):
return '中国'
else:
return address
df['地址'] = df['地址'].apply(address_deal)
# 打印查看前后的变化
print(df['地址'].head(10))特征工程
python
# 对标题进行长度统计 使用len()函数
df["标题长度"] = df["标题"].apply(len)
df["内容长度"] = df["内容"].apply(len)
# 对点赞数进行分类
df['点赞_等级'] = pd.cut(df['点赞数'], bins=[0, 100, 200, float('inf')], labels=['低', '中', '高'])
print(df.head())Explain:
- 这里使用的是pandas中分箱的操作 将"点赞数"划分为三个区间:0-100:标记为"低",101-200:标记为"中",200以上:标记为"高"
- float('inf') 表示正无穷大(infinity) 这里表示"大于200的所有值"都归为"高"等级
还可以自定义函数来实现 个人推荐第一种写法
python
# method_2
def likes_deal(likes):
# 强转int类型
likes = int(likes)
if likes < 100:
return '低'
elif 100 <= likes <= 200:
return '中'
else:
return '高'
df['点赞_等级'] = df['点赞数'].apply(likes_deal)最后我们保存清洗完之后的文件即可
python
# 将清洗的数据保存
df.to_excel('cleaned_Qy_info.xlsx', index=False)三.数据可视化
新建文件 用于数据可视化 数据清洗前面几行代码可以复用
直方图
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
df = pd.read_excel('./cleaned_Qy_info.xlsx')
plt.figure(figsize=(10, 6))
plt.hist(df['点赞数'].tolist(), bins=10, edgecolor='black', alpha=0.7, color='skyblue')
# 添加均值线
mean_value = df['点赞数'].mean()
plt.axvline(mean_value, color='red', linestyle='--', linewidth=2, label=f'均值: {mean_value:.2f}')
# 添加中位数线
median_value = df['点赞数'].median()
plt.axvline(median_value, color='blue', linestyle='--', linewidth=2, label=f'中位数: {median_value:.2f}')
plt.legend()
plt.title('点赞分布直方图', fontweight='bold', fontsize=16, pad=10)
plt.xlabel('点赞数', fontweight='bold', fontsize=12)
plt.ylabel('频数', fontweight='bold', fontsize=12)
plt.grid(True, alpha=0.5)
plt.tight_layout()
plt.show()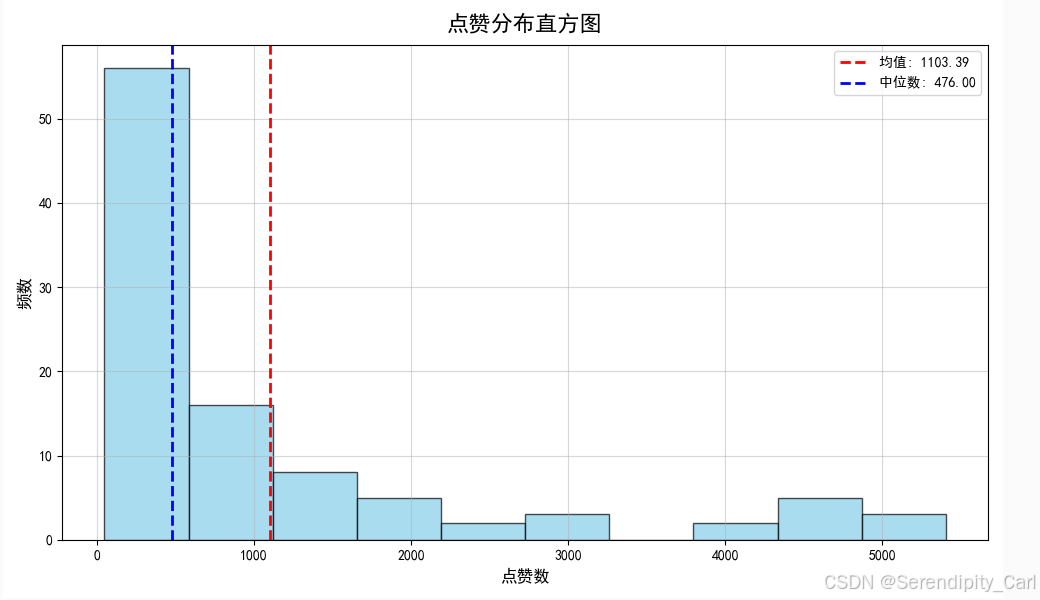
-
均值线和中位数线的位置关系可以判断价格分布的偏斜程度
-
如果均值 > 中位数,说明数据右偏(高点赞数拉高了平均值)
柱状图
各国家点赞对比图 根据这个国家分组 统计出各个国家的点赞情况
python
plt.figure(figsize=(12, 8))
# 使用viridis颜色映射生成30种渐变色,用于柱状图的不同柱子
vir = plt.get_cmap('viridis')
color = vir(np.linspace(0, 1, 30))
df.groupby('地址')['点赞数'].mean().round(2).plot(kind='bar', color=color) # pandas内置的绘图功能 kind='bar' 指定绘制柱状图
plt.title('各国家点赞对比', fontweight='bold', fontsize=16, pad=10)
plt.xlabel('国家', fontweight='bold', fontsize=12, labelpad=10)
plt.xticks(rotation=45, ha='right', fontsize=10)
plt.ylabel('平均点赞数', fontweight='bold', fontsize=12, labelpad=10)
plt.grid(True, alpha=0.5)
ax = plt.gca()
for a in ax.containers:
ax.bar_label(a, fmt='%.2f', padding=3, fontsize=9)
# 获取坐标轴对象:使用 plt.gca() 获取当前的 Axes对象
添加数值标签:使用 ax.bar_label() 方法为每个柱子添加数值标签
fmt='%.2f':格式化数值,保留两位小数
padding=3:标签与柱子顶部的间距
fontsize=9:标签字体大小
plt.tight_layout()
plt.show()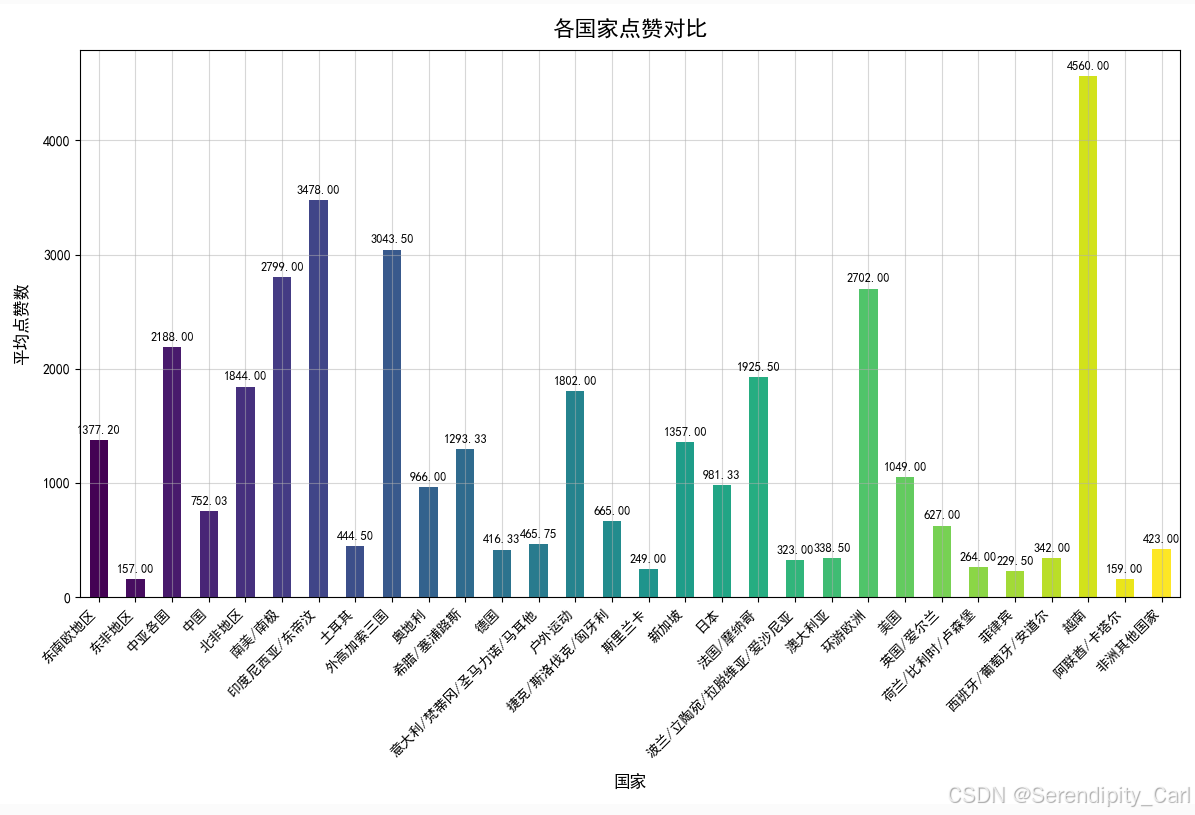
散点图
python
plt.figure(figsize=(12, 8))
plt.scatter(df['标题长度'], df['点赞数'], s=50, alpha=0.5, color='skyblue', edgecolors='black', linewidths=0.5)
z = np.polyfit(df['标题长度'], df['点赞数'], 1)
p = np.poly1d(z)
plt.plot(df['标题长度'], p(df['标题长度']), 'r--', linewidth=2, alpha=0.7, label='趋势线')
plt.title('标题长度与点赞数的关系', fontweight='bold', fontsize=16, pad=10)
plt.xlabel('标题长度', fontweight='bold', fontsize=12, labelpad=10)
plt.ylabel('点赞数', fontweight='bold', fontsize=12, labelpad=10)
plt.grid(True, alpha=0.5)
plt.tight_layout()
plt.show()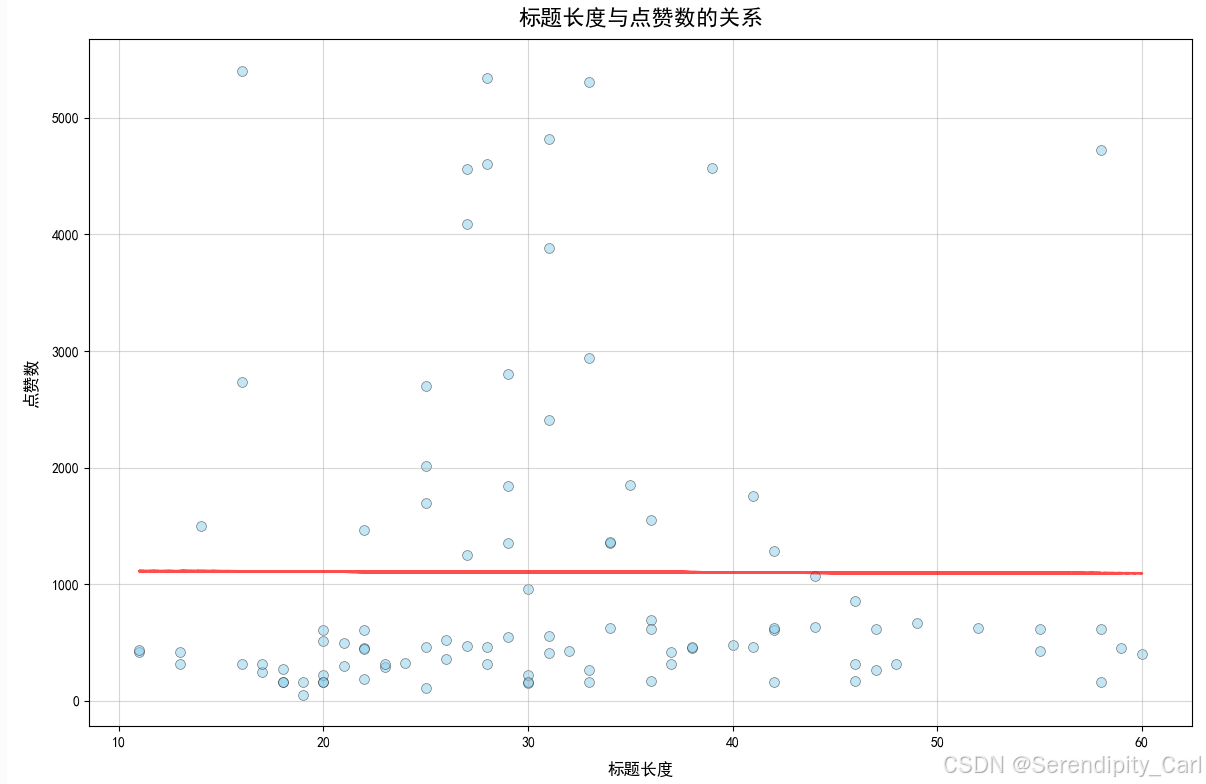
回归分析图
研究内容写得越长是不是越容易被点赞
使用Seaborn画图它会同时帮你画两样东西:
- ✅ 散点图(真实数据)
- ✅ 回归线(趋势线)
python
sns.regplot(x="内容长度", y="点赞数", data=df)
plt.title('内容长度与点赞数关系', fontweight='bold', fontsize=16, pad=10)
plt.xlabel('内容长度', fontweight='bold', fontsize=12, labelpad=10)
plt.ylabel('点赞数', fontweight='bold', fontsize=12, labelpad=10)
plt.grid(True, alpha=0.5)
plt.tight_layout()
plt.show()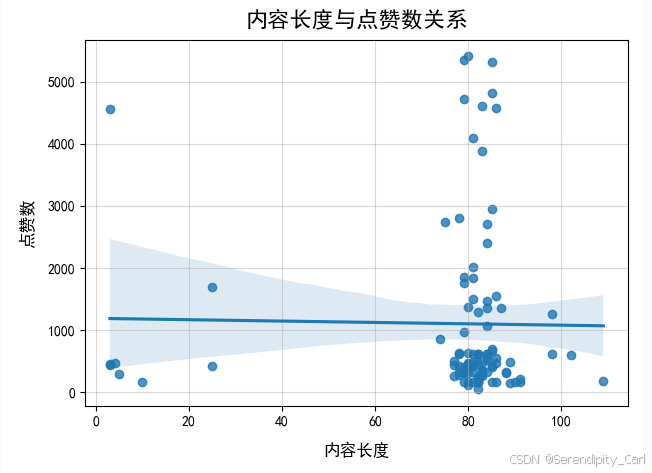
内容长度和点赞数没什么关系 数据波动很大,关系不稳定
OK 到此为止 本次的案例就结束啦 感谢大家的观看 你的点赞和关注是我更新的动力