本章节走通这条链路:在 Hugging Face / 魔搭上找到模型 → 下载或云端调用 → 用 transformers 与 datasets 在本地跑起来。
1. Hugging Face 模型探索与下载
1.1 平台是什么?
Hugging Face(简称 HF)是当前最流行的开源模型与数据集托管平台,核心入口包括:
| 入口 | 地址 | 用途 |
|---|---|---|
| Models | huggingface.co/models | 浏览、筛选、下载预训练模型 |
| Datasets | huggingface.co/datasets | 浏览、下载公开数据集 |
| Spaces | huggingface.co/spaces | 在线 Demo 与 Gradio 应用 |
1.2 模型探索与下载
以 Models 页面为例,常用筛选维度:
- Task(任务) :
text-generation(文本生成)、text-classification(文本分类)等 - Libraries :是否支持
transformers、PyTorch - Language :如
zh筛选中文模型
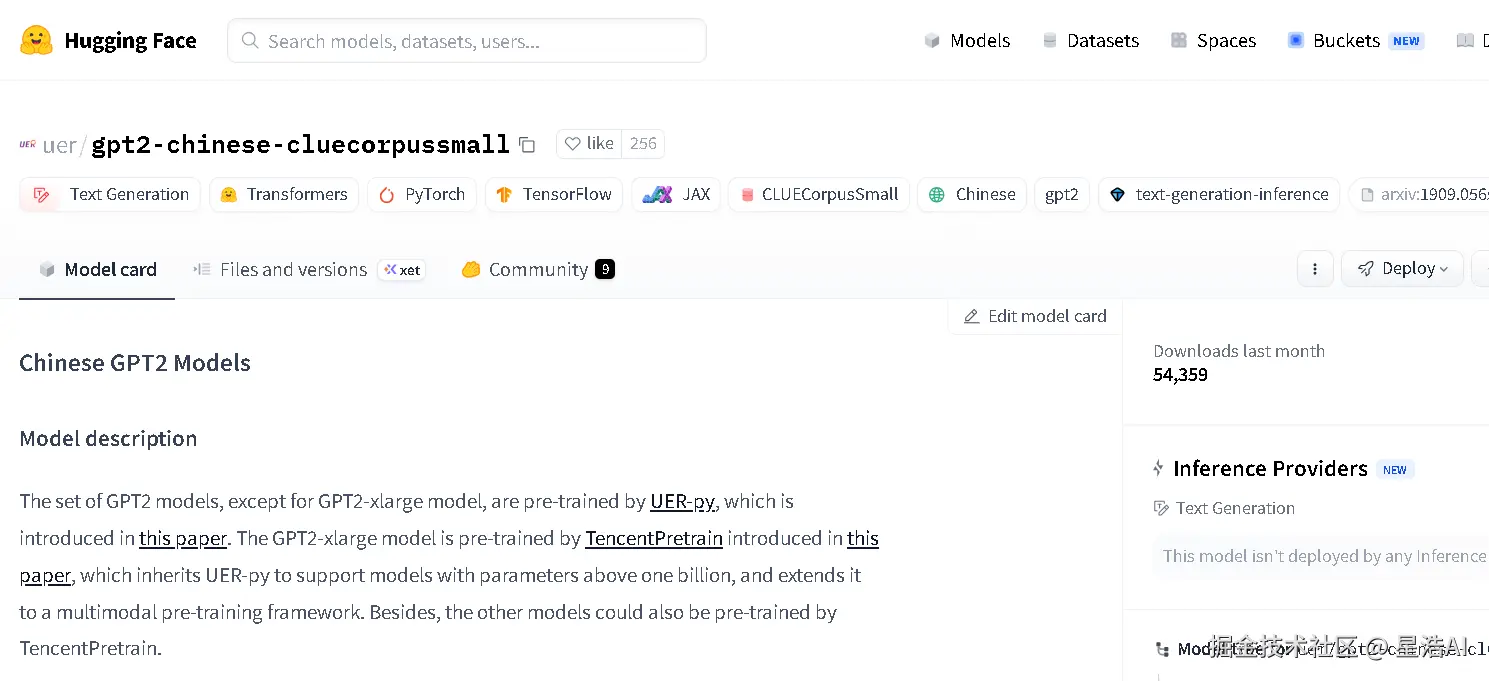
进入某个模型页(如 uer/gpt2-chinese-cluecorpussmall)后,建议关注:
- Model card:模型简介、训练数据、适用场景、引用方式
- Files and versions :权重文件(
pytorch_model.bin/model.safetensors)、config.json、分词器文件 - Use in Transformers :官方给出的
from_pretrained加载示例
1.3 下载模型的两种方式
访问 Hugging Face 通常需要科学上网;若网络不便,可改用 ModelScope 下载,用 transformers 本地调用。
方式 A:网页下载
在模型页的 Files and versions 中逐个下载文件,适合网络不稳定时手动拷贝。
方式 B:代码自动下载(推荐)
使用 from_pretrained,首次运行会自动拉取并缓存。需先安装 transformers:
pip install transformers
python
#将模型下载到本地调用
from transformers import AutoModelForCausalLM,AutoTokenizer
#将模型和分词器下载到本地,并指定保存路径
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = "D:/model/uer/gpt2-chinese-cluecorpussmall" # 不指定,默认C:\Users\DELL.cache\huggingface\hub
#下载模型
AutoModelForCausalLM.from_pretrained(model_name,cache_dir=cache_dir)
#下载分词工具
AutoTokenizer.from_pretrained(model_name,cache_dir=cache_dir)
# 实际含 config.json 的目录在 snapshots/<hash>/ 下,见 1.4 与第 4 节
print(f"缓存根目录:{cache_dir}")1.4 模型目录结构
在 Hugging Face Transformers 模型目录结构中,通常包含了一系列对模型加载和使用至关重要的文件。这些文件各自有不同的作用,下面列出了一些常见的文件及其功能:
config.json
包含了模型的配置信息,例如层数、隐藏层大小、注意力头数等超参数。它是用来初始化模型架构的。
pytorch_model.bin
保存了模型权重的文件。它包含了训练好的模型的所有参数,是模型能够进行推理或继续训练的基础。
tokenizer/ 或 vocab.txt
在 BERT 模型中,vocab.txt 文件定义了词汇表,即模型理解的单词列表。
对于一些更复杂的分词器,可能会有一个单独的 tokenizer 文件夹,里面可能包括 tokenizer.json, special_tokens_map.json, tokenizer_config.json 等文件,用于详细配置分词器的行为。
tokenizer_config.json
如果存在的话,这个文件会包含有关如何初始化分词器的额外信息,例如是否使用 BPE 分词等。
merges.txt
如果是使用 BPE (Byte Pair Encoding) 的分词器,那么这个文件定义了合并规则,用于将子词单元组合成完整的词语。
flax_model.msgpack , tf_model.h5
如果你下载的是跨框架支持的模型,可能会看到这些文件,分别对应于 JAX/Flax 和 TensorFlow 版本的模型权重。不过,在 PyTorch 项目中,通常只需要关注 pytorch_model.bin。
special_tokens_map.json
指定了特殊的标记(token),比如 CLS, SEP 等,在处理文本时需要特别注意的标记。
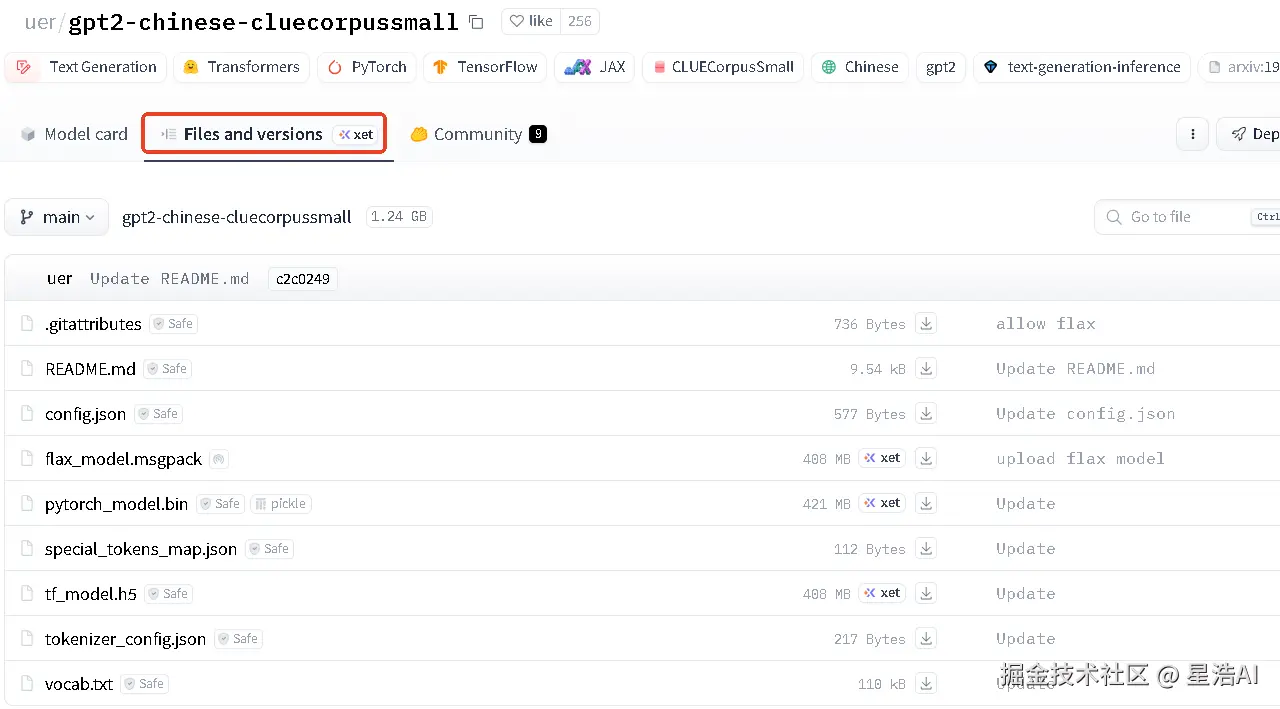
当你从 Hugging Face Model Hub 下载模型时,这些文件会被一起下载,并且通过 from_pretrained 方法自动处理。只要有了这些文件,就可以复现相同的模型环境,进行推理或者微调操作。
1.5 ModelScope(魔搭):国内一站式模型平台
无法稳定访问 Hugging Face 时,可使用 ModelScope 魔搭社区。二者都是「模型托管 + 下载 + 调用」平台,区别主要在于网络环境与中文模型资源。
1.5.1 平台定位
ModelScope 由阿里达摩院推出,是开源的 模型即服务(MaaS) 平台,集成 约 300+ 面向中文场景优化的模型,覆盖 NLP / CV / 多模态 等任务。
| 入口 | 地址 | 用途 |
|---|---|---|
| 模型库 | www.modelscope.cn/models | 浏览、下载预训练模型 |
| 数据集 | www.modelscope.cn/datasets | 行业与开源数据集 |
| 创空间 | www.modelscope.cn/studios | 免环境配置在线体验模型 |
1.5.2 模型生态
- 国产 SOTA 模型 :如 Qwen 、DeepSeek 、InternVL2-26B(多模态)等,支持免费下载与微调。
- 行业数据集:提供电商等垂直领域数据,便于落地场景实验。
- 在线运行:部分模型可在创空间直接体验,无需本地配环境。
模型 ID 写法与 HF 类似,形如 Qwen/Qwen2.5-0.5B-Instruct;在模型详情页可复制 SDK 下载 代码。
1.5.3 下载模型(推荐国内用户)
安装 ModelScope 后,用 snapshot_download 将权重拉到本地(目录结构同样含 config.json、权重与分词器,可与下文第 4 节衔接):
python
pip install modelscope
python
from modelscope import snapshot_download
# 在魔搭模型页复制模型 ID;cache_dir 指定本机保存目录
model_dir = snapshot_download(
"Qwen/Qwen2.5-0.5B-Instruct",
cache_dir="D:/model/Qwen2.5-0.5B-Instruct",
)
print(f"模型已下载到:{model_dir}")1.5.4 ModelScope 推理 pipeline(了解)
ModelScope 也提供与 HF 类似的 pipeline 封装,但需从 modelscope.pipelines 导入(不要与 transformers.pipeline 混用):
python
from modelscope.pipelines import pipeline
# 与 1.5.3 下载示例同一小模型,便于本地跑通
text_gen = pipeline("text-generation", model="Qwen/Qwen2.5-0.5B-Instruct")
print(text_gen("什么是人工智能"))❝
说明 :此处
pipeline来自modelscope.pipelines,与第 3 节transformers.pipeline不是同一个函数。日常开发更推荐 第 3、4 节transformers,兼容性更好;超大模型(如 DeepSeek-R1)对显存要求很高,初学请用小模型。
1.5.5 Hugging Face 与 ModelScope 怎么选?
| 对比项 | Hugging Face | ModelScope |
|---|---|---|
| 访问网络 | 通常需稳定外网 | 国内直连,下载更快 |
| 模型覆盖 | 全球模型最全 | 中文与国产模型丰富 |
| 常用下载方式 | from_pretrained |
snapshot_download |
| 本地推理 | transformers + 本地目录 |
下载后同样用 transformers(第 4 节) |
| 云端快速试用 | Inference API(第 2 节) | 创空间 / 平台 API(按需查阅官网) |
建议 :能访问 HF 时以 Hub 为主;国内网络或偏重中文模型时,用 ModelScope 下载,再统一走 transformers 本地调用。
2. 使用 Hugging Face API 调用模型
不下载权重、不把模型跑在本机时,可通过 Inference API(推理 API)在云端调用 Hub 上的模型,适合快速验证效果。
2.1 准备工作
-
注册 Hugging Face 账号:huggingface.co/join
-
创建 Access Token:Settings → Access Tokens → New token
-
安装客户端库:
pip install huggingface_hub
2.2 使用 InferenceClient
python
from huggingface_hub import InferenceClient
# 将 hf_xxx 替换为你的 Token;model 填写 Hub 上的模型 ID
client = InferenceClient(
model="uer/gpt2-chinese-cluecorpussmall",
token="hf_xxxxxxxx",
)
text = client.text_generation(
"今天天气很好,",
max_new_tokens=50,
)
print(text)文本分类可换用对应任务接口(模型需支持该任务):
python
client = InferenceClient(
model="uer/roberta-base-finetuned-cluener2020-chinese",
token="hf_xxxxxxxx",
)
result = client.text_classification("李白是唐朝著名诗人")
print(result)2.3 使用 HTTP 直接请求(了解即可)
部分场景下也可直接 POST 到推理端点(若官方调整端点,以 Hub 模型页与 HF 推理文档 为准):
python
import requests
API_URL = "https://api-inference.huggingface.co/models/uer/gpt2-chinese-cluecorpussmall"
headers = {"Authorization": "Bearer hf_xxxxxxxx"}
payload = {"inputs": "今天天气很好,", "parameters": {"max_new_tokens": 50}}
response = requests.post(API_URL, headers=headers, json=payload)
print(response.json())2.4 API 与本地调用的对比
| 对比项 | Inference API | 本地调用 |
|---|---|---|
| 是否需要 GPU | 否(算力在云端) | 建议有 GPU,大模型 CPU 较慢 |
| 数据隐私 | 文本需上传到 HF 服务器 | 数据不出本机 |
| 适用场景 | 快速试用、Demo | 生产、定制、敏感数据 |
注意:免费 Inference API 有速率与排队限制;部分模型需等待「冷启动」。生产环境更常见做法是 本地部署 或 Dedicated Endpoint(付费专属推理端点)。
3. 核心组件:transformers 与 datasets
Hugging Face 生态中,与日常开发最密切的两个 Python 库是 transformers (模型)和 datasets(数据集)。
3.1 安装
bash
pip install transformers datasets tokenizers3.2 transformers:加载模型与统一推理
核心能力 :用统一 API 加载 Hub 上的数千个预训练模型,并用 pipeline 封装常见 NLP 任务。
| 概念 | 说明 |
|---|---|
| AutoTokenizer | 按模型配置自动选择分词器 |
| AutoModelForCausalLM | 因果语言模型(GPT 类,用于生成) |
| AutoModelForSequenceClassification | 序列分类模型(BERT 类) |
| pipeline | 一行代码完成「分词 → 推理 → 后处理」 |
典型加载方式:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)pipeline 将模型与分词器打包,按任务类型调用:
python
from transformers import pipeline
generator = pipeline("text-generation", model=model_id, device="cpu")
print(generator("你好,", max_new_tokens=20))常见 pipeline 任务类型:text-generation、text-classification、question-answering、summarization 等。
3.3 datasets:加载与处理公开数据集
核心能力 :用 load_dataset 从 Hub 一键下载数据集,返回统一的 Dataset / DatasetDict 结构,便于与 transformers 训练流程衔接。
python
from datasets import load_dataset
# 示例:加载中文情感分析数据集的前 10 条
ds = load_dataset("seamew/ChnSentiCorp", split="train[:10]")
print(ds)
print(ds[0])查看数据集结构:
python
print(ds.column_names) # 字段名
print(len(ds)) # 样本数与 transformers 配合做微调时的典型流程:load_dataset → 分词 map → Trainer 训练(微调细节可在后续章节展开)。
3.4 两个库的关系
text
HF Hub / ModelScope ──下载──► 本地目录(config + 权重 + tokenizer)
│
Hub 上的数据集 ──datasets──► load_dataset / map ─────────────┤
▼
transformers:from_pretrained / pipeline ──► 推理或微调4. 本地模型调用
本地调用 = 将模型权重下载到本机,可参考之前的文章《(一)PyTorch 深度学习环境搭建与微调实战》(mp.weixin.qq.com/s/aPJwkeu9h...%25EF%25BC%258C%25E7%2594%25A8 "https://mp.weixin.qq.com/s/aPJwkeu9h3h2jfwEmSnD9Q)%EF%BC%8C%E7%94%A8") transformers 加载 本地路径 进行推理。
4.1 加载本地模型
model_dir 需指向包含 config.json 的目录 (绝对路径):
- HF 下载 :一般在
cache_dir/models--组织--模型名/snapshots/<hash>/下 - ModelScope 下载 :
snapshot_download返回的路径通常可直接使用,无需再找snapshots
python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
#设置具体包含config.json的目录,只支持绝对路径
model_dir = r"D:\model\Qwen\Qwen1.5-0.5B\models--Qwen--Qwen1.5-0.5B\snapshots\8f445e3628f3500ee69f24e1303c9f10f5342a39"
#加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_dir)
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=False, padding_side="left")4.2 文本生成(GPT / Qwen)
文本生成本质是 逐 token 填空:
根据 prompt 预测下一个词,直到达到 max_new_tokens。
关键参数:
- temperature
该参数控制生成文本的随机性。
值越低,生成的文本越保守;值越高,生成的文本越多样。
0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
- top_k
该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。
示例中 top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
- top_p
又称为核采样。限制模型生成时的词汇选择范围。
它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样,进一步增加生成的质量。(按概率从高到低排序再累加)。
python
#使用加载的模型和分词器创建生成文本的pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device="cuda")
#生成文本
# output = generator("你好,我是一款语言模型,",max_new_tokens=50,truncation=True,num_return_sequences=1)
output = generator(
"你好,我是一款语言模型,",#生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_new_tokens=50,#指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=1,#参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True,#该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.7,
top_k=50,
top_p=0.9,
clean_up_tokenization_spaces=True#该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为 False,因为它能更好地保留原始文本的格式。
)
print(output)执行后输出结果:
text
Loading weights: 100%|████████████████████| 291/291 [00:01<00:00, 256.77it/s]
[{'generated_text': '你好,我是一款语言模型,我可以回答你的问题,你有需要我回答的问题吗?'}] 
无 GPU 时将
device="cuda"改为"cpu";model_dir改为你本机实际路径。
4.3 文本分类模型
分类任务需使用带分类头、已在下游任务上微调的 checkpoint。
下面以分类模型为例,演示本地路径加载格式(model_dir 改为你本机实际路径):
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_dir = r"D:\model\你的模型目录\snapshots<hash>" # 含 config.json 的目录
model = AutoModelForSequenceClassification.from_pretrained(model_dir)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer, device="cuda")
result = classifier("李白是唐朝著名诗人")
print(result)执行后输出结果:
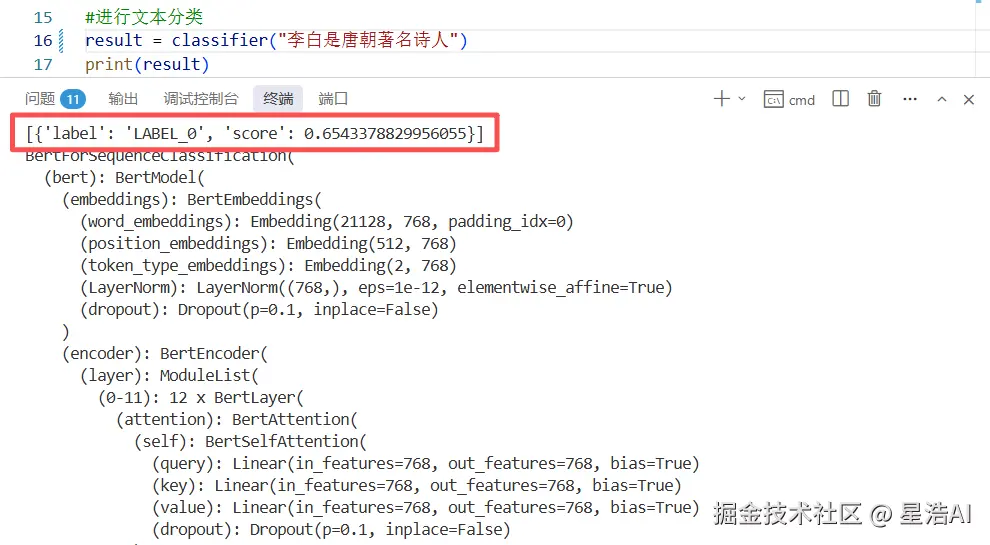
也可在下载时指定 Hub 模型 ID:uer/roberta-base-finetuned-cluener2020-chinese。
小结
本文介绍了从 Hugging Face Hub 与 ModelScope 获取模型,以及通过 API 或本地 pipeline 完成推理的基本流程。
记住两点即可:国内下载可优先用 ModelScope;文本分类要用已微调的 checkpoint,不能直接用纯预训练底座。