1.计算机网络
1. 属于子网89.32.0.0/12的地址是?
32 = 0010 0000
/12 暂用了4位 主机地址就是 0010 0000 00000000 00000001 ~ 0010 1111 11111111 11111110 也即 89.32.0.1 ~ 89.47.255.254
在早期的IPv4设计中,IP地址被划分为 A、B、C、D、E 五类。其中 A、B、C 类用于单播通信,D 类用于组播,E 类保留。
| 类别 | 首位比特 | 网络号长度 | 主机号长度 | 默认子网掩码 | 网络数量 | 每个网络主机数(理论最大) | IP地址范围 |
|---|---|---|---|---|---|---|---|
| A | 0 | 8 位 | 24 位 | 255.0.0.0 | 126 | 2²⁴ − 2 = 16,777,214 | 1.0.0.0 -- 126.255.255.255 |
| B | 10 | 16 位 | 16 位 | 255.255.0.0 | 16,384 | 2¹⁶ − 2 = 65,534 | 128.0.0.0 -- 191.255.255.255 |
| C | 110 | 24 位 | 8 位 | 255.255.255.0 | 2,097,152 | 2⁸ − 2 = 254 | 192.0.0.0 -- 223.255.255.255 |
| D | 1110 | --- | --- | --- | --- | --- | 224.0.0.0 -- 239.255.255.255(组播) |
| E | 1111 | --- | --- | --- | --- | --- | 240.0.0.0 -- 255.255.255.255(保留) |
注:每个网络减去2是因为全0(网络地址)和全1(广播地址)不能分配给主机。
📌 OSI 七层模型总览
| 层级 | 名称 | 主要功能 | 数据单位(PDU) | 常见协议/标准 | 典型设备 |
|---|---|---|---|---|---|
| 7 | 应用层 | 为用户提供网络服务接口(如网页浏览、邮件等),直接面向用户应用 | 数据(Data) | HTTP, FTP, SMTP, POP3, DNS, DHCP, Telnet | 网关、终端、主机 |
| 6 | 表示层 | 负责数据格式转换、加密解密、压缩解压,确保不同系统间的数据可理解 |
数据(Data) | JPEG, GIF, MPEG, ASCII, SSL/TLS, DES | 网关 |
| 5 | 会话层 | 建立、管理和终止应用程序之间的会话(对话控制、同步点设置) | 数据(Data) | RPC, SQL, NFS, NetBIOS | 网关 |
| 4 | 传输层 | 提供端(端口)到端(进程到进程)的 TCP可靠或UDP不可靠数据传输,负责差错控制与流量控制 |
段(Segment) (TCP) 或 数据报(Datagram)(UDP) | TCP, UDP, SCTP | 网关、防火墙(部分功能) |
| 3 | 网络层 | 点到点(相邻节点间),负责逻辑寻址、路由选择、分组转发和拥塞控制 |
包(Packet) | IP, ICMP, IGMP, ARP, RARP | 路由器、三层交换机 |
| 2 | 数据链路层 | 在物理链路上提供可靠的数据帧传输,处理物理地址(MAC)、差错检测与流量控制 | 帧(Frame) | Ethernet (IEEE 802.3), PPP, HDLC, STP, ATM, Frame Relay | 网桥、交换机(二层) |
| 1 | 物理层 | 在物理介质上传输原始比特流,定义电气、机械、功能和规程特性 | 比特(Bit) | RS-232, RS-449, V.35, RJ-45, FDDI, 10BASE-T | 中继器、集线器(Hub) |
🌐 TCP/IP 四层模型详解
| 层级 | 名称 | 主要功能 | 对应 OSI 层 | 常见协议/技术 | 典型设备或组件 |
|---|---|---|---|---|---|
| 4 | 应用层(Application Layer) | 为用户提供各种网络服务和应用接口(如网页、邮件、文件传输等) | 应用层 + 表示层 + 会话层 | HTTP, HTTPS, FTP, SMTP, POP3, DNS, DHCP, Telnet, SSH | 主机、服务器、客户端 |
| 3 | 传输层(Transport Layer) | 提供端到端(进程到进程)的可靠或不可靠数据传输,负责流量控制、差错控制 | 传输层 | TCP, UDP | 主机(操作系统内核) |
| 2 | 网络层(Internet Layer) | 负责逻辑寻址(IP 地址)、路由选择、分组转发,实现跨网络的数据传输 | 网络层 | IP, ICMP, IGMP, ARP* | 路由器、三层交换机 |
| 1 | 网络接口层(Network Interface Layer) (也称链路层或网络访问层) | 负责在物理网络上传输数据帧,处理硬件地址(MAC)、介质访问控制、成帧等 | 数据链路层 + 物理层 | Ethernet, Wi-Fi (802.11), PPP, HDLC, FDDI | 网卡、交换机、集线器 |
💡 注:ARP(地址解析协议)在功能上属于网络层(用于 IP → MAC 解析),但其报文封装在数据链路层帧中传输,因此有时被归入网络接口层。
-
网络层协议:
- IP:网络层最重要的核心协议,在源地址和目的地址之间传送数据报,无连接、不可靠。
- ICMP:因特网控制报文协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。
- ARP和RARP:地址解析协议,ARP是将IP地址转换为物理地址,RARP是将物理地址转换为IP地址。
- IGMP:网络组管理协议,允许因特网中的计算机参加多播,是计算机用做向相邻多目路由器报告多目组成员的协议,支持组播。
-
传输层协议:
- TCP:整个TCP/IP协议族中最重要的协议之一,在IP协议提供的不可靠数据数据基础上,采用了重发技术,为应用程序提供了一个可靠的、面向连接的、全双工的数据传输服务。一般用于传输数据量比较少,且对可靠性要求高的场合。
- UDP:是一种不可靠、无连接的协议,有助于提高传输速率,一般用于传输数据量大,对可靠性要求不高,但要求速度快的场合。
-
应用层协议:
基于TCP的FTP、HTTP等都是可靠传输。基于UDP的DHCP、DNS等都是不可靠传输- FTP:可靠的文件传输协议,用于因特网上的控制文件的双向传输。
- HTTP:超文本传输协议,用于从WWW服务器传输超文本到本地浏览器的传输协议。使用SSL加密后的安全网页协议为HTTPS。
- SMTP和POP3:简单邮件传输协议,是一组用于由源地址到目的地址传送邮件的规则,邮件报文采用ASCI格式表示。
- Telnet:远程连接协议,是因特网远程登录服务的标准协议和主要方式。
- TFTP:不可靠的、开销不大的小文件传输协议。
- SNMP:简单网络管理协议,由一组网络管理的标准协议,包含一个应用层协议、数据库模型和一组资源对象。该协议能够支持网络管理系统,泳衣监测连接到网络上的设备是否有任何引起管理师行关注的情况。
- DHCP:动态主机配置协议,基于UDP,基于C/S模型,为主机动态分配IP地址,有三种方式固定分配、动态分配、自动分配。
- DNS:域名解析协议,通过域名解析出IP地址。
-
协议端口对照表
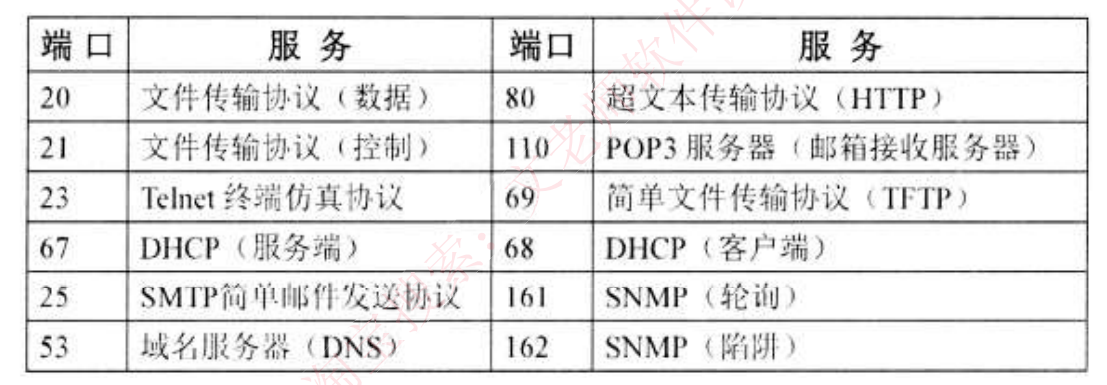
端口 20 和 21 都属于 FTP(文件传输协议),它们均基于 TCP 协议
- 冲突域和广播域
冲突域和广播域:路由器可以阻断广播域和冲突域,交换机、网桥只能阻断冲突域
- 报文交换方式
| 交换方式 | 连接类型 | 是否可靠 | 时延 | 链路利用率 | 典型应用 |
|---|---|---|---|---|---|
| 电路交换 | 面向连接 | 可靠 | 低且固定 | 低 | 传统电话 |
| 报文交换 | 无连接 | 可靠 | 高 | 中 | 已淘汰 |
| 分组交换(数据报) | 无连接 | 不可靠 | 中(可变) | 高 | Internet (IP) |
| 分组交换(虚电路) | 面向连接 | 可靠 | 中(固定路径) | 高 | X.25, Frame Relay |
| 信元交换 | 面向连接 | 可靠 | 低 | 高 | ATM 网络 |
- 技术标准
线局域网WLAN技术标准: IEEE 802.11
以太网规范IEEE 802.3 是重要的局域网协议
2.计算机
2.0 原码 反码 补码
1. 原码 (Sign-Magnitude)
核心思想:最高位表示符号(0正1负),其余位表示绝对值。
- 正数:符号位0,数值位为真值的二进制绝对值
- 负数:符号位1,数值位为真值的二进制绝对值
例子(8位表示):
+18→ 原码:0001 0010-18→ 原码:1001 0010
特点:
- 直观易懂,符合人类习惯
- 存在+0和-0 :
0000 0000和1000 0000都表示0 - 加减运算复杂:需要判断符号位,硬件实现麻烦
2. 反码 (Ones' Complement)
核心思想:正数的反码等于原码,负数的反码是原码的符号位不变,其余位按位取反。
- 正数:与原码相同
- 负数:符号位保持1,数值位全部取反
例子(8位表示):
+18→ 原码:0001 0010→ 反码:0001 0010-18→ 原码:1001 0010→ 反码:1110 1101
特点:
- 存在+0和-0 :
0000 0000和1111 1111都表示0 - 加减法稍微简化,但仍有循环进位问题
- 补码出现前的过渡方案,现已基本不用
3. 补码 (Two's Complement) ✅ 最重要!现代计算机标准
核心思想:正数的补码等于原码,负数的补码等于反码加1。
- 正数:与原码相同
- 负数:符号位保持1,数值位取反后加1
例子(8位表示):
-
+18→ 原码:0001 0010→ 补码:0001 0010 -
-18:原码:1001 0010 取反:1110 1101 (反码) 加1:1110 1110 (补码)
特点:
- 只有一个0 :
0000 0000 - 范围不对称 :n位补码范围是
-2ⁿ⁻¹到+(2ⁿ⁻¹ - 1)- 8位:-128 到 +127
- 加减运算统一:减法可转换为加法,硬件实现简单
- 现代计算机几乎全部使用补码
8位二进制一共能提供256个独立编码,补码体系中0仅需要00000000这一个编码,而原码体系中原本存在冗余的"-0"编码10000000。为了不浪费这个编码空间,补码将这个冗余编码重新定义为最小的负数-128,刚好让8位补码的取值范围落在-128~+127,符合n位补码-2^(n-1) ~ 2^(n-1)-1的通用范围公式。
从 10000000 (-128) 到 11111111 (-1),一共 128 个数(即 2^7 个)
快速求负法:从右向左找到第一个1,这个1及其右边的位保持不变,左边的位全部取反。
-18的补码1110 1110→ 从右第一个1在倒数第二位,保留10,左边取反得1110 11,即1110 1110
2.1 CPU的组成
- 在CPU的组成中,不包括什么?
CPU 主要由运算器、控制器、寄存器和内部总线等组件组成
跟踪下一条要执行指令地址的寄存器是PC
1. 运算器:执行者
它的任务就是算数 和逻辑判断。
- 核心部件:算术逻辑单元
- 比喻:大脑里专门负责计算的**"神经元"**。你让它加它就加,让它比较大小它就比较。
- 记忆口诀 :算 数逻辑单元(ALU)。
2. 控制器:发号施令者
它的任务就是指挥,告诉运算器去哪里拿数据、算什么、算完放哪。
- 核心部件:程序计数器
- 比喻:你的**"书签"**。你正在读一本书(程序),读到第10页,书签就夹在第10页。CPU执行完一条指令,PC就自动加1,指向下一条指令的地址。
- 记忆口诀 :程 序计 数器(PC ),就像书签记页码。
- 核心部件:指令寄存器
- 比喻:你从书(内存)里翻到的那一页内容,现在摊开放在你眼前,告诉你现在要干什么。
- 记忆口诀 :指 令寄 存器(IR ),专门寄 放当前要执行的指令。
3. CPU内部的"草稿纸":寄存器
寄存器是CPU内部速度最快的存储单元,但数量极少,容量极小。它们都在运算器和控制器里面。
根据刚才的分工,我们把寄存器分成三类来记:
| 类别 | 寄存器名称 | 英文缩写 | 比喻 | 记忆要点 |
|---|---|---|---|---|
| 属于控制器 | 程序计数器 | PC | 书签 | 存下一条指令的地址 |
| 属于控制器 | 指令寄存器 | IR | 摊开的书页 | 存当前正在执行的指令 |
| 属于运算器 | 累加寄存器 | AC | 计算器屏幕 | 最忙的寄存器,用来暂存中间结果,比如算累加和 |
| 属于运算器 | 通用寄存器 | 通用 | 草稿纸 | 给运算器随便写写画画的地方 |
| 属于运算器 | 状态字寄存器 | PSW | 心情/脸色 | 存计算结果的状态(结果是否为0?有没有溢出?) |
-
Cache-主存
速度最快 ↑ CPU寄存器 → 容量极小,成本极高 ↓ 高速缓存(L1, L2, L3) → 您提到的 Cache-主存 级 ↓ 主 存(DRAM) → 核心工作区 ↓ 固态硬盘(SSD) → 现代辅存/外存 ↓机械硬盘/网络存储/磁带 → 容量巨大,成本极低
↓
速度最慢
Cache-主存结构的主要作用是解决主存与CPU的速度差距。
这恰恰是分级思想的具体体现,但目标略有不同:
A. Cache-主存层次
- 目的 :解决CPU与主存之间的速度差距(Speed Gap)。
- 实现方式 :由硬件自动管理,对程序员完全透明。
- 关键技术:缓存行、映射策略、替换算法(如LRU)。
- 效果:让CPU在绝大多数时间都能以接近Cache的速度访问到所需的数据,从而提升整体运算速度。
B. 主存-辅存层次(虚拟存储体系)
- 目的 :解决主存容量不足的问题,为程序员提供一个比实际物理内存大得多的、统一的地址空间。
- 实现方式 :由操作系统(硬件辅助) 管理,对应用程序透明。
- 关键技术:分页、分段、页面置换算法(如Clock算法)、缺页中断。
- 效果:程序可以像拥有超大内存一样编写和运行,无需担心物理内存的实际大小。将不常用的数据暂存到低速但大容量的辅存中。
Cache(高速缓存)的地址映射方式
这三种方式的核心区别在于"主存里的数据,具体可以放在Cache的哪个位置"。下面是它们的核心对比:
1. 直接映射方式
主存的每个块只能映射到Cache中唯一固定的位置。
- 映射规则 :
Cache块号 = 主存块号 % Cache总块数 - 地址结构 :标记位 | Cache索引 | 块内偏移
- 优点:硬件简单、查找速度快(只需比较一个标记)
- 缺点 :冲突率高(容易反复替换)
案例真题
主存容量为 4MB,块大小为 64B,Cache 采用直接映射,Cache 容量为 32KB。
问:主存共分为多少块?Cache 有多少行?主存块号 1000 映射到哪一行?
解:
- 主存块数 = \\frac{4 \\text{MB}}{64 \\text{B}} = \\frac{4 \\times 2^{20}}{2^6} = 2\^{22 - 6} = 2\^{16} = 65536 块
- Cache 行数 = \\frac{32 \\text{KB}}{64 \\text{B}} = \\frac{2^{15}}{2^6} = 2\^9 = 512 行
- 主存块号 1000 → 映射到 Cache 行号 = 1000 \\bmod 512 = 1000 - 512 \\times 1 = 488
2. 全相连映射方式
主存的每个块可以映射到Cache中任意位置。
- 地址结构 :标记位 | 块内偏移(无索引字段)
- 优点:冲突率最低,空间利用率最高
- 缺点:查找速度慢(需比较所有标记),硬件成本高
3. 组相连映射方式
组组相连映像 :前面两种方式的结合,将Cache存储器先分块再分组,主存也同样先分块再分组,组间采用直接映像,即主存中组号与Cache中组号相同的组才能命中,但是组内全相联映像,也即组号相同的两个组内的所有块可以任意调换。
Cache分成若干组,每组有多个块(N路)。主存块映射到特定组 ,但可放在组内任意位置。
- 映射规则 :
组号 = 主存块号 % 组数 - 主存块号 :
主存地址/块大小 - 地址结构 :标记位 | 组索引 | 块内偏移
- 优点:折中方案,最常用
2.2 校验码
海明码 数据位n → 最小校验位k 精准对照表
公式逻辑:2k≥n+k+1\boldsymbol{2^k \ge n + k + 1}2k≥n+k+1
| 数据位 nnn | 最小校验位 kkk |
|---|---|
| 1 | 2 |
| 2~4 | 3 |
| 5~11 | 4 |
| 12~26 | 5 |
| 27~57 | 6 |
| 58~120 | 7 |
2.3 浮点数运算
N=−0.10112×2+3 N = -0.1011_2 \times 2^{+3} N=−0.10112×2+3
一步步算成十进制:
-
先算尾数:
0.10112=1×12+0×14+1×18+1×116=0.5+0+0.125+0.0625=0.6875 0.1011_2 = 1\times\frac12 + 0\times\frac14 + 1\times\frac18 + 1\times\frac{1}{16} = 0.5 + 0 + 0.125 + 0.0625 = 0.6875 0.10112=1×21+0×41+1×81+1×161=0.5+0+0.125+0.0625=0.6875 -
再乘上 (2^3):
0.6875×23=0.6875×8=5.5 0.6875 \times 2^3 = 0.6875 \times 8 = 5.5 0.6875×23=0.6875×8=5.5 -
加上数符(负):
−5.5 -5.5 −5.5
所以:
-0.1011_2 \\times 2\^{+3} 的十进制是 −5.5\boldsymbol{-5.5}−5.5
以浮点表示法为例:
- 数符:数的正负号(+ 或 −)
- 尾数:小数的有效数字部分
- 阶符:阶码的正负号
- 阶码:小数点移动的位数
通用形式:
N=数符×(尾数)×2阶符×阶码 N = \text{数符} \times (\text{尾数}) \times 2^{\text{阶符} \times \text{阶码}} N=数符×(尾数)×2阶符×阶码
1. 拆分各部分
- 数符 :负 → 记为 1(1 表示负,0 表示正)
- 尾数 :0.1011
- 阶符 :正 → 记为 0
- 阶码 :3 (二进制为 11)
2. 组合成浮点格式(简单版)
顺序:数符 | 阶符 | 阶码 | 尾数
1⏟数符0⏟阶符11⏟阶码1011⏟尾数 \underbrace{1}{\text{数符}} \quad \underbrace{0}{\text{阶符}} \quad \underbrace{11}{\text{阶码}} \quad \underbrace{1011}{\text{尾数}} 数符 1阶符 0阶码 11尾数 1011
即:
1 0 11 1011
3.浮点数加法运算流程(以单精度为例)
假设要计算:A + B
1. 对阶
目的: 使两个操作数的指数相同,才能将尾数相加。
方法: 比较两个数的指数大小,将小指数向大指数对齐,同时调整尾数(右移尾数,每右移一位指数加1)。
为什么小阶向大阶对齐? 因为如果大阶向小阶对齐,大阶数的尾数需要左移,可能会丢失高位的有效数字,造成严重误差。
2. 尾数相加
对阶后,两个尾数可以直接相加(包括隐藏的整数位1)。
注意:尾数运算是用原码加法(实际上符号位单独处理,或者用补码运算,但IEEE标准用符号-绝对值表示更方便硬件处理,实际多用补码加减)。
3. 结果规格化
相加后,尾数可能不在规格化范围 [1.0, 2.0) 内。
如果尾数 ≥ 2.0,需要右规:尾数右移一位,指数加1。
加法例子:1.5 + 2.25
1. 转成二进制浮点数(单精度简化)
- 1.5 =
1.1×2⁰
尾数=1.1,指数=0 - 2.25 =
10.01=1.001×2¹
尾数=1.001,指数=1
2. 三步计算
数A: 1.1×2⁰
数B: 1.001×2¹(1) 对阶(指数对齐)
小指数向大指数对齐:A的指数从0变成1
1.1×2⁰ → 0.11×2¹ (尾数右移1位)
(2) 尾数相加
0.110 (对齐后的A)
+ 1.001 (B)
--------
1.111(3) 规格化
结果1.111×2¹已经是规格化形式
最终:1.111×2¹ = 11.11(二进制)= 3.75 ✔
2.4 寻址
- 按字编址(寻址)
- 按字编址,意味着每个地址对应一个字(64 位 = 8 字节)。
- 所以,总的可寻址的地址个数 = 存储器总容量(字节) ÷ 每个字的字节数
- 机器字长为32位,一个容量为16MB的存储器,CPU按照半字寻址,其可寻址的单元数是?
- CPU按照"半字"进行寻址,意味着每一个地址编号对应一个"半字"大小的存储空间。
- 可寻址单元数 = 存储器总容量寻址单位大小\frac{\text{存储器总容量}}{\text{寻址单位大小}}寻址单位大小存储器总容量
- 存储器总容量 = 16MB=16×1024×1024 Bytes=16,777,216 Bytes16\text{MB} = 16 \times 1024 \times 1024\text{ Bytes} = 16,777,216\text{ Bytes}16MB=16×1024×1024 Bytes=16,777,216 Bytes
- 寻址单位大小 (半字) = 2 Bytes2\text{ Bytes}2 Bytes
单元数=16MB2B=16×2202=8×220=8M \text{单元数} = \frac{16\text{MB}}{2\text{B}} = \frac{16 \times 2^{20}}{2} = 8 \times 2^{20} = 8\text{M} 单元数=2B16MB=216×220=8×220=8M
或者用具体的数值计算:
单元数=16,777,2162=8,388,608 \text{单元数} = \frac{16,777,216}{2} = 8,388,608 单元数=216,777,216=8,388,608
结论
该存储器可寻址的单元数是 8M (或具体数值 8,388,608)。
2.5 流水线周期
- 流水线周期定义 :流水线中每个阶段推进一次所需的时间 ,也称为时钟周期。
- 决定因素 :等于所有流水段中最长一段的执行时间(加上寄存器延迟等小开销)。
- 流水线执行时间:1条指令总执行时间+ (总指令条数-1)*流水线周期。
2.6 存储器
| 存储器类型 | 典型设备 | 寻址/映射核心逻辑 | 存取时间特点 | 地址的作用 |
|---|---|---|---|---|
| 顺序存储器 | 磁带 | 必须按物理顺序逐个经过 | 随位置线性增加 | 仅表示相对偏移量 |
| 直接存储器 | 磁盘、光盘 | 直接定位磁道 + 旋转等待扇区 | 取决于磁道距离和旋转角度 | 指向具体的磁道和扇区 |
| 随机存储器 | 内存 (RAM) 固态硬盘(SSD) | 译码器直接选中唯一单元 | 恒定,与位置无关 | 直接对应电路开关状态 |
| 相联存储器 | Cache Tag, TLB | 并行比较内容关键字 | 恒定 (并行比较耗时固定) | 作为搜索的关键字 |
2.7 进程
前驱图是同步关系:A 执行完 → B 才能执行
- 互斥:P、V 对同一个信号量(如 P(S) V(S))
- 同步:P 在后继,V 在前驱,不同信号量
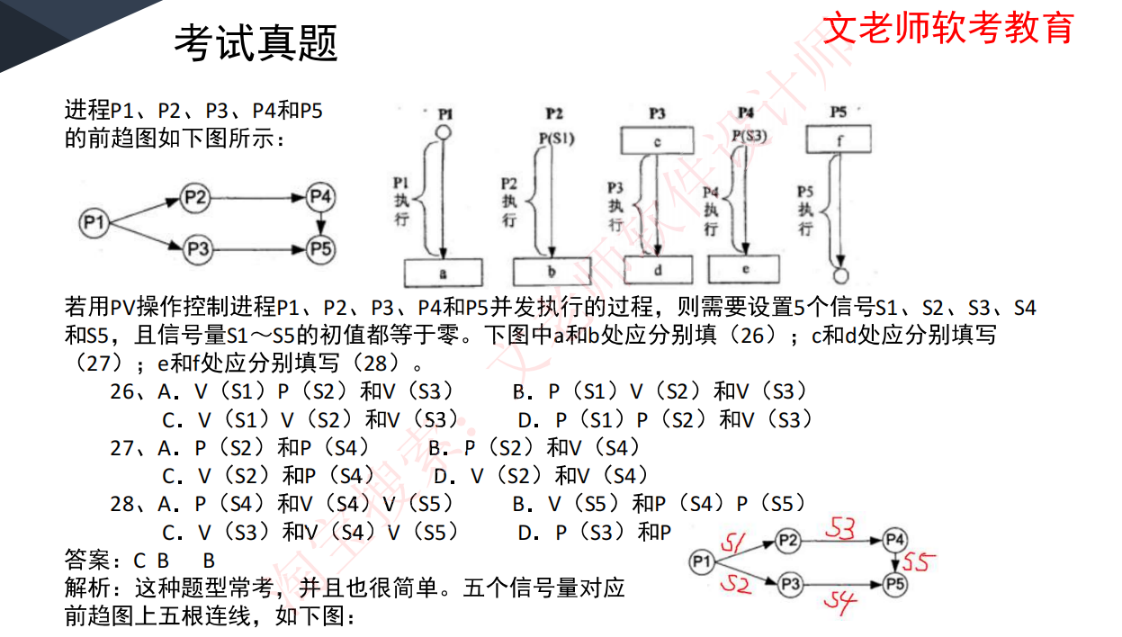
- 解题方法:
- 信号量数量:前驱图中每条箭头线对应一个信号量
- 编号规则:
按从上到下、从左到右顺序编号信号量 - 初值设置:前驱图信号量初始值通常为0
- 执行逻辑:
- 进程执行前:
需要P操作获取所有前驱箭头对应的信号量 - 进程执行后:
需要V操作释放所有后继箭头对应的信号量
- 进程执行前:
- 真题解析:
- P1执行后释放S1和S2(对应两个后继箭头)
- P2需要P(S1)才能执行,执行后释放S3
- P3需要P(S2)才能执行,执行后释放S4
- P4需要P(S3)才能执行,执行后释放S5
- P5需要P(S4)和P(S5)才能执行
- 答案验证:
- 通过代码中的P/V操作可以验证信号量编号假设
- 注意信号量编号要与箭头对应关系一致
- S=-1 表示什么?
- 临界资源:各进程间需要以互斥方式对其进行访问的资源。
- 临界区:指进程中对临界资源实施操作的那段程序。本质是一段程序代码
- 互斥信号量:对临界资源采用互斥访问,使用互斥信号量后其他进程无法访问,初值为1。
- 同步信号量:对共享资源的访问控制,初值一般是共享资源的数量
- S = 1:临界资源空闲,没有进程在使用。
- S = 0:临界资源正在被使用,有 1 个进程在临界区里,但没有进程在等待。
- S = -1:临界资源正在被使用,1 个进程在临界区,且有 1 个进程在阻塞等待。
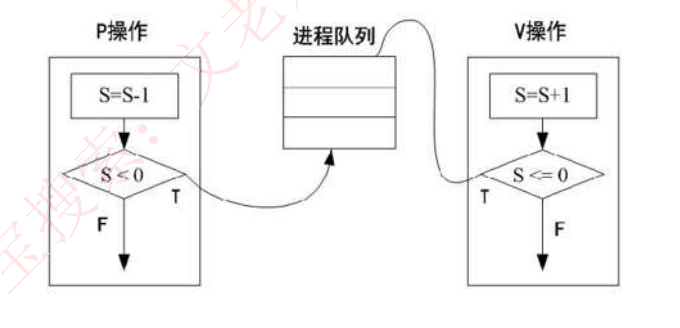
-
P操作(申请):
- 执行步骤:S=S-1→判断→继续执行或阻塞
- 阻塞条件:S<0时进程进入阻塞队列,|S|值表示等待进程数
- 示例:初值S=3时连续4次P操作会使S=-1,表示1个进程在等待
-
V操作(释放):
- 执行步骤:S=S+1→判断→唤醒阻塞进程或继续执行
- 唤醒机制:当S<=0时从阻塞队列唤醒最早等待的进程
- 如果原来有进程在等(S < 0)→ 释放的资源直接给等待者用 → 唤醒
- 如果原来没有进程在等(S ≥ 0)→ 释放的资源放入空闲池 → 不唤醒
2.8 分页机制找物理地址
想象一个图书馆:
- 虚拟地址 = 你手里的索书号(如 "3楼-2区-5架")
- 物理地址 = 书实际存放的具体书架位置
分页机制就像这个图书系统:
-
虚拟地址分成两部分:
- 页号 = 第几页(如 "3楼-2区")
- 页内偏移 = 这一页里的第几个字(如 "5架")
-
页表 = 索引目录:
- 每个进程都有自己的一张"地图"(页表)
- 页表记录:虚拟页号 → 物理页框号的映射
-
找物理地址的步骤:
虚拟地址 = [页号] + [偏移量] ↓ 查页表:页号 → 物理页框号 ↓ 物理地址 = [物理页框号] + [偏移量]
【题目】
某计算机系统,页大小为 4KB,虚拟地址空间为 32 位,物理内存为 4GB。进程 A 的页表项内容如下(部分):
| 虚拟页号 | 物理页框号 |
|---|---|
| 0 | 8 |
| 1 | 3 |
| 2 | 10 |
| 3 | 5 |
问:虚拟地址 0x1234 对应的物理地址是多少?
【解题步骤】
虚拟地址 (32位,假设页大小=4KB = 2^12=4096字节)
┌──────────────────┬──────────────┐
│ 页号(20位) │ 偏移量(12位) │
└──────────────────┴──────────────┘
↓ ↓
查页表 直接使用
↓ ↓
┌─────────┐ ↓
│ 页表 │ ↓
├─────────┤ ↓
│页号→物理│ ↓
│页框号 │ ↓
└─────────┘ ↓
↓ ↓
└──────────┬─────────┘
↓
物理地址 = [物理页框号 × 页大小] + 偏移量第1步:确定页大小和偏移量位数
- 页大小 4KB = 4096 字节 = 2^12 字节
- 所以偏移量占 12 位
第2步:拆分虚拟地址
0x1234 = 0001 0010 0011 0100 (二进制)
└─页号──┘└─偏移量─┘- 页号 = 0x1 = 1
- 偏移量 = 0x234 = 564
第3步:查页表
- 虚拟页号 1 → 物理页框号 3
第4步:计算物理地址
物理地址 = 物理页框号 × 页大小 + 偏移量
= 3 × 4096 + 564
= 12288 + 564
= 12852
在分页系统中,由于:
-
页面大小 = 2n2^n2n 字节(如 4KB = 2122^{12}212)
-
页内偏移正好占 低 n 位
-
物理块号表示的是"第几个页框",其对应的起始地址为
块号 × 2^n,即 块号左移 n 位- 页面大小 = 4KB = 2122^{12}212 → 偏移占 12 位
- 物理块号 = 2 → 二进制:
10 - 页内偏移 = 0xA7F =
1010 0111 1111(12 位)
虚拟存储器
虚拟存储器之所以能高效工作,其理论基础是程序运行的局部性原理。这意味着程序在一段时间内,往往只集中访问其地址空间中的一小部分。
- 时间局部性:如果一个数据项被访问,那么在不久的将来它很可能再次被访问(例如循环中的变量)。
- 空间局部性:如果一个数据项被访问,那么与它地址相邻的数据项也很可能很快被访问(例如数组遍历)。
基于这一原理,操作系统可以确信,在任意时刻,只需要将每个程序最"活跃"的那部分页面保留在物理内存中,就能保证系统高效运行。而那些"沉睡"的页面则可以安心地待在磁盘上。
页面过小,包含的页面个数就会过多,使得页表的体积过大,页表本身占据的存储空间过大,操作速度变慢。
页面很大时,页面个数变少,因此主存中的页面个数就会变少,导致页面调度频率变高(就会不断调入/调出页面),换页次数增加,降低操作速度。
2.9 位示图
位示图的工作方式
-
在位示图中,每一位(bit)对应一个磁盘物理块。
- 如果某一位是
1,通常表示对应的块已被使用; - 如果是
0,表示该块空闲(具体含义可自定义,但一一对应是关键)。
- 如果某一位是
-
系统字长为 32 位 → 每个"字"(word)能存储 32 个 bit。
-
因此,1 个字 = 32 位 = 可以记录 32 个物理块的使用状态。
每个字表示 32 个块,因此:
字编号=⌊物理块编号32⌋=⌊1638532⌋ \text{字编号} = \left\lfloor \frac{\text{物理块编号}}{32} \right\rfloor = \left\lfloor \frac{16385}{32} \right\rfloor 字编号=⌊32物理块编号⌋=⌊3216385⌋
若用8个字(字长32位) 组成位示图管理内存,假定用户归还一个块号为100号,它对应的位示图的位置为字号?位号?
计算块号在位示图中的位置,结果取决于字号、位号和块号的起始编号(是从 0 开始还是从 1 开始)。这道题在操作系统中非常经典,根据不同的起始编号约定,会有两种常见的计算结果。
已知条件:字长为 32 位(即每个字可以管理 32 个内存块)。
以下是两种情况的详细计算过程:
字号、位号、块号均从 0 开始计数(最常见)
这是计算机底层最符合逻辑的计数方式(类似于数组下标)。
- 计算公式 :
- 字号 = 块号 ÷ 字长 (取整数商)
- 位号 = 块号 % 字长 (取余数)
- 代入计算 :
- 字号 = 100 ÷ 32 = 3 (余 4)
- 位号 = 100 % 32 = 4
- 结论 :对应的位置为 字号 3,位号 4。
2.10 索引文件地址
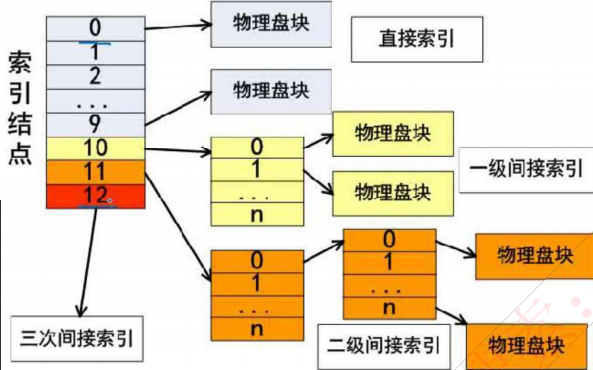
-
如图所示,系统中有13个索引节点,0-9为直接索引,即每个索引节点存放的是内容,假设每个物理盘大小为4KB,共可存4KB*10=10KB数据;
-
10号索引节点为一级间接索引节点,大小为4KB,存放的并非直接数据,而是链接到直接物理盘块的地址,假设每个地址占4B,则共有1024个地址,对应1024个物理盘,可存1024*4KB=4098KB数据
-
二级索引节点类似,直接盘存放一级地址,一级地址再存放物理盘快地址,而后链接到存放数据的物理盘块,容量又扩大了一个数量级,为102410244KB数据。
3.知识产权
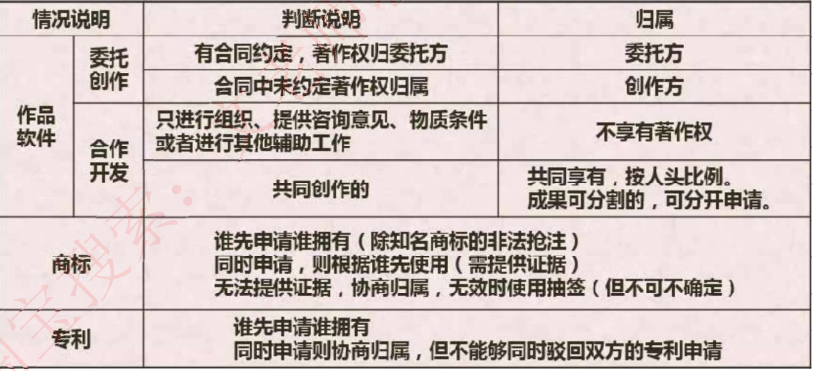
- 委托作品
- 与职务作品核心区别:
- 合同无约定时:
著作权默认归创作方个人(职务作品默认归单位)
- 合同无约定时:
- 合作开发规则:
- 仅提供辅助工作:不享有著作权
- 共同创作:按人头比例共有(可分割成果可分开申请)
- 知识产权
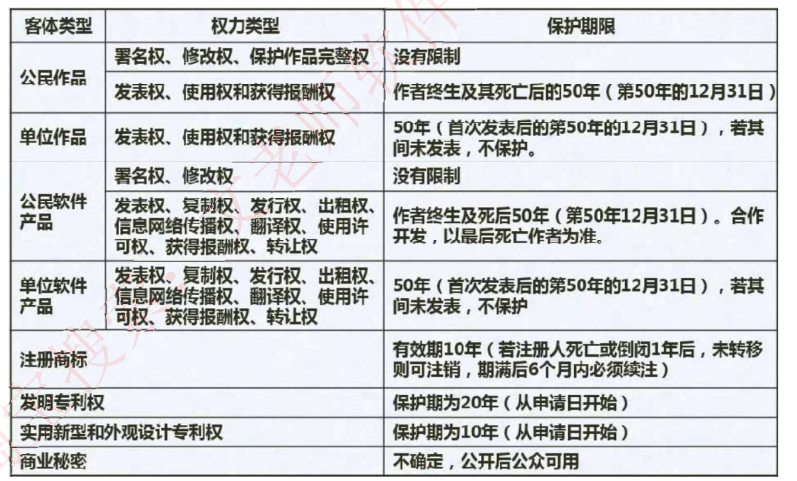
知识产权具有地域限制,保护期限各种情况如下表所示:
著作权从作品完成之日起开始产生
-
地域限制原则:知识产权保护具有地域性,各国法律对保护期限的规定不同
-
公民作品权利:
- 署名权、修改权、保护作品完整权:永久有效(如李白诗歌至今仍受保护)
- 发表权、使用权等财产性权利:作者终生及死后50年(截止第50年12月31日)
- 著作权是一个完整的权利包(整体),而署名权和修改权是这个权利包里的两项具体权利(部分),还有其它权利。
-
单位作品特点:
- 仅含发表权、使用权等财产性权利
- 保护期50年(自首次发表起算,未发表则不保护)
-
软件产品特殊规定:
- 公民软件:署名权永久,其他权利同公民作品
- 单位软件:全部权利保护期50年(合作开发以最后死亡作者为准)
-
商标权续注机制:
- 有效期10年,可无限续注(期满前6个月内需办理)
- 注册人死亡/倒闭1年内未转移则注销
-
专利分类保护:
- 发明专利:20年(从申请日起)
- 实用新型/外观设计:10年
-
商业秘密特性:保护期不确定,由权利人自主决定公开时间
-
商标权取得原则:
- 先申请原则(知名商标反抢注例外)
- 同日申请:按先使用证据判定→协商→抽签
-
专利权取得原则:
- 先申请原则(同日申请需协商,协商不成则双双驳回)
- 禁止抽签决定(与商标处理方式不同)
- 职务作品
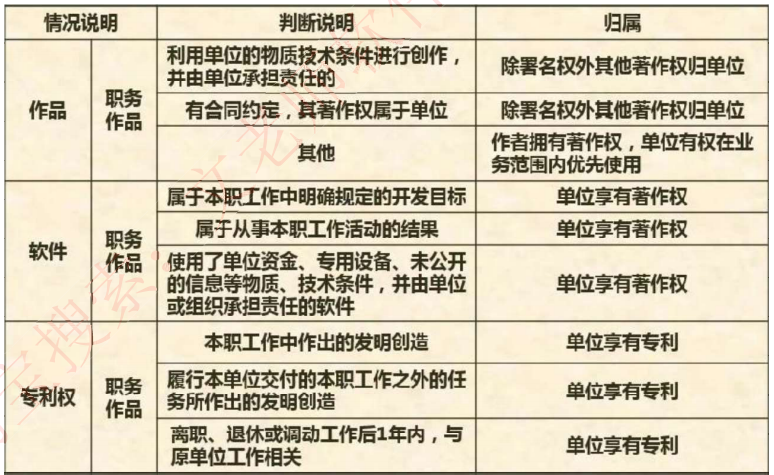
- 作品基本判定标准:
- 利用单位物质技术条件创作且由单位担责:除署名权外归单位
- 合同明确约定权属:按约定执行(无约定则默认归单位)
- 非职务相关创作:作者保留著作权(单位有业务优先使用权)
- 软件作品特殊情形:
- 本职工作明确目标/活动成果:单位享有著作权
- 使用单位资源开发:单位享有著作权
- 专利权特殊规则:
- 离职后1年内作出的与原工作相关发明:仍归原单位
- 本职/交付任务中的发明创造:单位享有专利
- 侵权判定

- 自动保护原则: 中国公民、法人或其他组织的作品,不论是否发表都自动享有著作权。登记仅为诉讼举证便利,非权利取得要件。
- 不受保护对象:
- 开发软件的思想、处理过程、操作方法或数学概念
- 法律文件及官方译文(如宪法)
- 时事新闻、历法、通用数表/表格/公式
- 合理使用情形:
- 个人学习研究(需注意"适当引用"标准,如论文查重率限制)
- 教学科研使用公开演讲内容
- 免费表演、公共场所艺术品临摹
- 汉语→少数民族语言/盲文翻译
著作权法不适用于下列情形:法律、法规、国家机关的决议、决定、命令和其他具有立法、行政、司法性质的文件,及其官方正式译文;时事新闻;历法、通用数表、通用表格和公式。
4.项目管理
你可以把项目中的多条路径想象成几条并行的流水线,而项目的总工期是由耗时最长的那条流水线(也就是关键路径)决定的。
-
非关键活动:就像是一条比较短流水线上的零件,它晚一点开始,只要不耽误最后组装,就不影响整个工厂的出货时间。所以它有浮动时间。
-
关键活动:就是那条最长流水线上的零件。因为这条路已经是最长的了,如果其中任何一个关键活动推迟了(比如晚了1天),那么整条流水线的完工时间就会顺延1天,直接导致整个项目的最终交付日期被迫推迟。
- 关键路径:是项目的
最短工期,但却是从开始到结束时间最长的路径(关键路径:指的是项目网络图中,所有从开始到结束的路径中,总持续时间最长的那一条路径。) - 关键路径上的活动自由时差和总时差通常为零
- 关键路径:是项目的
**项目活动图,某个活动最多可以晚多少天,是怎么计算的?
- 总浮动时间:在
不延误项目完工时间且不违反进度制约因素的前提下,活动可以从最早开始时间推迟或拖延的时间量,就是该活动的进度灵活性。正常情况下,关键活动的总浮动时间为零。 - 求某个活动的总浮动时间=
最迟开始LS-最早开始ES 或 最迟完成LF-最早完成EF 或 关键路径-非关键路径(包含某个活动的最长非关键路径)时长。
5.软件需求
- 需求
系统需求:从系统的角度来说明软件的需求,包括功能需求、非功能需求和设计约束等。
- 1)功能需求:也称为行为需求,规定了
开发人员必须在系统中实现的软件功能用户利用这些功能来完成任务,满足业务需要。 - 2)非功能需求:指
系统必须具备的属性或品质,又可以细分为软件质量属性(如可维护性、可靠性、效率等) 和性能需求(响应时间、吞吐量、并发用户数) 和安全性需求(身份认证与授权等)。 - 3)设计约束:也称为限制条件或补充规约,通常是对
系统的一些约束说明,例如必须采用国有自主知识产权的数据库系统,必须运行在UNIX操作系统之下等。
6.程序设计语言
- 中间代码
1. 三种表达式概述
| 表达式类型 | 别名 | 运算符位置 | 示例 | 对应树的遍历 |
|---|---|---|---|---|
| 前缀表达式 | 波兰式 | 运算符在操作数之前 | + a b |
先序遍历 |
| 中缀表达式 | 常见算式 | 运算符在操作数之间 | a + b |
中序遍历 |
| 后缀表达式 | 逆波兰式 | 运算符在操作数之后 | a b + |
后序遍历 |
常见考题,表达式 (a-b)* (c+d)的后缀式 (逆波兰式)是?
中缀转后缀算法(括号法) 核心步骤:
- 表达式已经是完全括号化:( ( a - b ) * ( c + d ) )
- 第一层:*
- 第二层:左边 ( a - b ),右边 ( c + d )
- 把每个运算符移到它所在括号的后面(将符号移到本表达式括号外面):
- 对于 ( a - b ):把 - 移到括号后面 → ( a b ) -
- 对于 ( c + d ):把 + 移到括号后面 → ( c d )+
- 对于最外层 ( ( a - b ) * ( c + d ) ):
- 现在是 ( ( a b) - * ( c d ) + )
把 * 移到括号后面 → ( ( a b )- ( c d ) + ) *
- 去掉所有括号:a b - c d + *
2.正规式
| 运算 | 正则表达式符号 | 含义 |
|---|---|---|
| 并集 | ` | ` |
| 连接 | (无符号) | ab 表示 {ab} |
| 克林闭包 | * |
a* 表示 {ε, a, aa, aaa, ...} |
| 正闭包 | + |
a+ 表示 {a, aa, aaa, ...} |
示例转换:
正则表达式 (a|b)c* 对应的集合:
{a, b} · {c}* = {a, b} · {ε, c, cc, ccc, ...}
= {a, ac, acc, accc, ..., b, bc, bcc, bccc, ...}-
DFA:每个状态对每个输入都有唯一确定的后继。
-
NFA:一个状态对同一个输入可能有多个后继,或者有空转移(ε)。
3. 状态机
状态转移图要素:
-
圆圈:表示状态。
-
带箭头的弧线:表示在
某个输入符号下,从一个状态转移到另一个状态。 -
单线圆圈:起始状态。
-
双线圆圈:接受状态(或最终状态)
考试:一般就是根据状态图,识别哪些字符串
从初始状态到结束状态,识别哪些字符串,初始s0,结束s3,从开始到结束根据箭头(字符),有哪些路径,也就知道了那些字符串
4. 汇编 编译 解释
1. 汇编(Assembly)
- 输入 :汇编语言源程序(使用助记符如
MOV,ADD,JMP等) - 处理工具 :汇编器(Assembler)
- 输出 :目标程序(机器码) ,通常是
.obj或.o文件,可进一步链接成可执行文件。 - 特点 :
- 一对一映射:一条汇编指令通常对应一条机器指令。
- 汇编后生成的是机器可直接执行的代码(需链接),不依赖运行时环境。
- 执行效率高,但可移植性差。
2. 编译(Compilation)
- 输入:高级语言源程序(如 C、C++、Go)
- 处理工具 :编译器(Compiler)
- 输出 :独立的可执行文件(如
.exe, ELF 文件) - 特点 :
- 一次性将整个源程序翻译成目标代码(机器码或中间码)。
- 生成的可执行文件可脱离源代码和编译器独立运行。
- 运行速度快,适合发布产品。
- 调试困难(需额外调试信息),运行时无法直接干预源代码逻辑。
3. 解释(Interpretation)
- 输入:高级语言源程序(如 Python、JavaScript、BASIC)
- 处理工具 :解释器(Interpreter)
- 输出 :不生成独立的目标程序或可执行文件
- 特点 :
- 逐行(或逐语句)读取、分析、执行源代码。
- 运行时始终需要解释器和源代码。
- 便于调试和动态修改(可随时中断、查看变量、修改代码)。
- 执行效率较低,因为每次运行都要重新解析源码。
- 有些现代解释器结合了即时编译(JIT) 技术(如 Python 的 PyPy、JavaScript 的 V8),在运行时将热点代码编译为机器码以提升性能。
- 过程:解释器在运行时监控代码执行频率。将频繁执行的"热点代码"即时编译成机器码,后续直接执行机器码。
- 优点:极大地提升了长期运行程序的效率,结合了解释的灵活性和编译的高性能。
典型的编译器由以下六个逻辑阶段组成:
源程序
↓
[1. 词法分析] → 记号(Token)流
↓
[2. 语法分析] → 语法树(Parse Tree / AST)
↓
[3. 语义分析] → 带注解的语法树 + 符号表
↓
[4. 中间代码生成] → 三地址码、四元式、SSA 等
↓
[5. 代码优化] → 更高效/更短的中间代码
↓
[6. 目标代码生成] → 汇编代码 或 机器码
↓
可执行文件(可能需链接)语义规则是一个程序的意义
- 编译程序对高级语言源程序进行编译的过程中,要不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,并将其存入符号表中,编译过程如下:
-
词法分析:是编译过程的第一个阶段。这个阶段的任务是从左到
右一个字符一个字符地读入源程序,即对构成源程序的字符流进行
扫描然后根据构词规则识别单词(也称单词符号或符号)。 -
语法分析:是编译过程的一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如
"程序","语句","表达式"等等语法分析程序判断源程序在结构上是否正确. -
语义分析:是编译过程的一个逻辑阶段.语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查,进行类型审查。如
类型匹配、除法除数不为0等。又分为静态语义错误(在编译阶段能够查找出来) 和动态语义错误(只能在运行时发现) -
中间代码和目标代码:中间代码是根据语义分析产生的,需要经过优化链接最终生成可执行的目标代码。引入中间代码的目的是进行与机器无关的代码优化处理。常用的中间代码有后缀式 (逆波兰式) 、三元式(三地址码) 、四元式和树等形式。需要考虑三个问题(一是如何生成较短的目标代码,二是如何充分利用计算机中的寄存器,减少目标代码访问存储单元的次数;三是如何充分利用计算机指令系统的特点,以提高目标代码的质量)。
前缀表达式:+ab 中缀表达式:a+b 后缀表达式:ab+ 主要掌握上述三种表达式即可,其实就是树的三种遍历,一般正常的表达式是中序遍历,即中缀表达式,根据其构造出树,再按题目要求求出前缀或后缀式 简单求法:后缀表达式是从左到右开始,先把表达式加上括号,再依次把运算符加到本层次的括号后面。
-
7.结构化开发
结构化方法的分析结果由以下几部分组成:一套分层的数据流图、一本数据词典、一组小说明(也称加工逻辑说明) 、补充材料。
- 核心特征:面向数据流的传统方法,以数据流为中心构建分析模型和设计模型,采用"自顶向下,逐层分解"思想
- 完整流程:包含结构化分析(SA)、结构化设计(SD)和结构化程序设计(SPD)三个阶段
- 语言对应:结构化程序设计使用C语言,面向对象程序设计使用C++/Java
- 分析产出:
- 三大模型:
功能模型(数据流图)、行为模型(状态转换图)、数据模型(ER图) - 补充材料:数据词典、加工逻辑说明(小说明)、补充资料
- 三大模型:
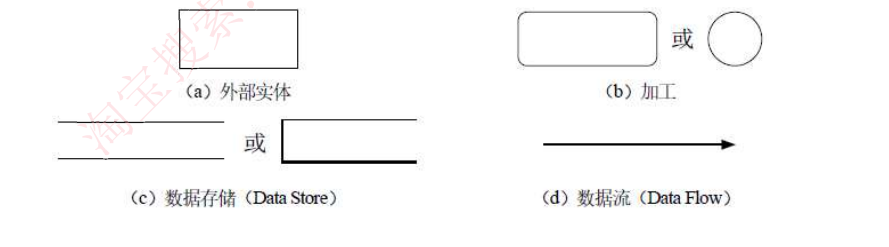
数据流图DFD
基本图形元素:外部实体、加工、数据存储、数据流
- 数据流原则:
- 数据守恒:输出必须来自输入或加工产生(加工对于输入流不一定进行转换)
- 加工守恒:输入/输出数据流名称必须不同
- 加工1.有输入但是没有输出,称之为"黑洞"。
- 加工2.有输出但没有输入。称之为"奇迹"。
- 加工3.中输入不足以产生输出,我们称之为"灰洞"。
- 加工必有输入输出(至少有一个输入和输出)
- 数据流必须经过加工(禁止:外部实体↔外部实体/数据存储↔数据存储)
- 平衡验证:
- 子图输入输出必须与父图对应加工一致
- 典型考点:问"如何保持父/子图平衡
- 衡量标准:模块内部元素间的关联程度,越高越好
- 偶然内聚:元素间无直接关系(记忆:偶然相遇无关联)
- 逻辑内聚:执行逻辑相似功能,由参数决定具体功能(例:根据参数类型执行不同相加操作)
- 时间内聚:需同时执行的动作组合(记忆:强调时间同步性)
- 过程内聚:按指定过程顺序执行任务(记忆:类似流程图顺序)
- 通信内聚:所有元素操作同一数据结构(例:共用全局结构体变量)
- 顺序内聚:元素顺序执行且前序输出是后续输入(记忆:类似数据流图)
- 功能内聚:所有元素共同完成单一功能(最强内聚,缺一不可)
记忆:功能>顺序(数据流图)>通信>过程(流程图)>时间>逻辑>偶然
- 衡量标准:模块间的关联程度,越低越好
- 无直接耦合:模块间无任何关系(最理想状态)
- 数据耦合:传递简单数据值(例:函数参数传值调用,简单数据类型(int, float, char等))
- 标记耦合:传递数据结构(复杂数据结构(结构体、对象、字典等))
- 控制耦合:传递控制变量选择执行模块内的某一功能(例:信号量控制)
- 外部耦合:通过外部环境关联(记忆:依赖I/O设备,第三方库等)
- 公共耦合:共享公共数据环境(记忆:类似全局变量区)
- 内容耦合:直接使用对方内部数据(最高耦合,应避免)
记忆:内容>公共>外部>控制>标记>数据>无直接
8.软件工程
8.1. 软件过程模型
8.1.1. 瀑布模型
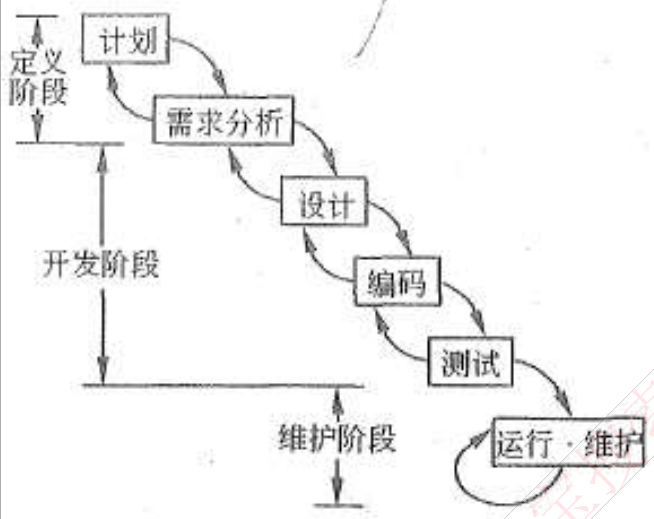
瀑布模型(SDLC):瀑布模型是一个经典的软件生命周期模型一般将软件开发分为:可行性分析 (计划)、需求分析、软件设计 (概要设计、详细设计)、编码(含单元测试)、测试、运行维护等几个阶段。
瀑布模型特点
- (1)从
上一项开发活动接受该项活动的工作对象作为输入 - (2)利用这一输入,
实施该项活动应完成的工作内容 - (3)给出该项活动的
工作成果,作为输出传给下一项开发活动。 - (4)对
该项活动的实施工作成果进行评审。若其工作成果得到确认,则继续进行下一项开发活动:否则返回前一项,甚至更前项的活动。尽量减少多个阶段间的反复。以相对来说较小的费用来开发软件 - (5) 软件开发中常采用结构化生命周期方法。
8.1.2 螺旋模型
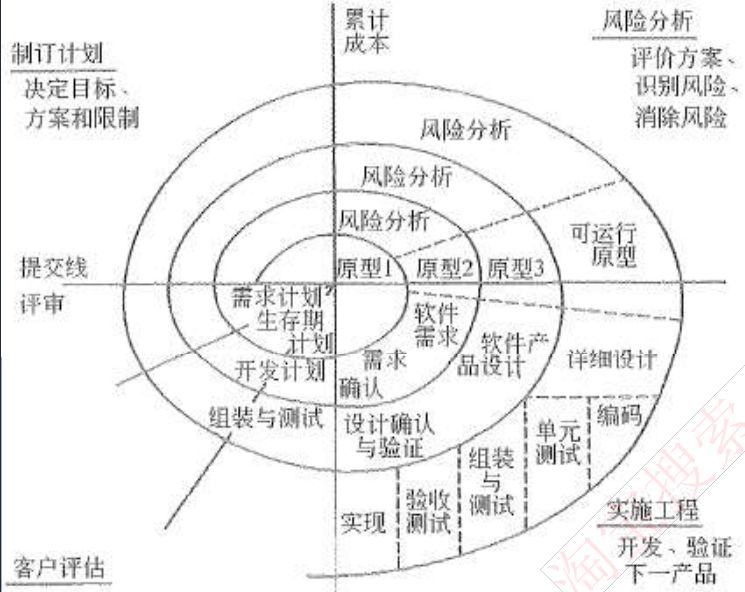
-
螺旋模型是一个
演化软件过程模型,将原型实现的迭代特征与线性顺序(瀑布) 模型中控制的和系统化的方面结合起来。在螺旋模型中,软件开发是一系列的增量发布 -
开发过程具有
周期性重复的螺旋线状。四个象限分别标志每个周期所划分的四阶段:制订计划、风险分析、实施工程和客户评估。螺旋模型强调了风险分析,特别适用于庞大而复杂的、高风险的系统
8.1.3 原型化模型
原型化模型第一步就是创建一个快速原型,
户可以与原型进行交互,再通过与相关千系人进行充分的讨论和分析,最终弄清楚当前系统的需求,进行了充分的了解之后,在原型的基础上开发出用户满意的产品。
原型法认为在很难一下子全面准确地提出用户需求的情况下,原型应当具备的特点如下。
(1)实际可行
(2具有最终系统的基本特征
(3)构造方便、快速,造价低原型法的特点在于原型法对用户的需求是动态响应、逐步纳入的。
8.1.4 增量模型
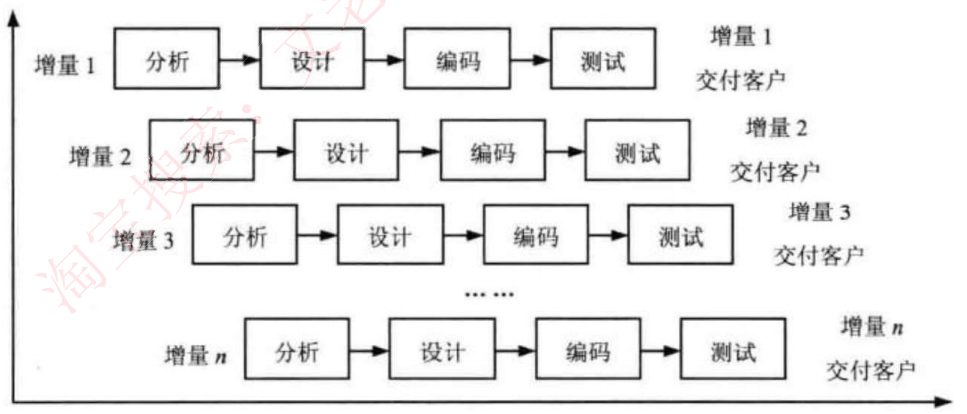
增量模型:首先开发核心模块功能,而后与用户确认,之后再开发次核心模块的功能,即每次开发一部分功能,并与用户需求确认,最终完成项目开发,优先级最高的服务最先交付。
特点:但由于并不是从系统整体角度规划各个模块,因此不利于模块划分难点在于如何将客户需求划分为多个增量。与原型不用的是增量模型的每一次增量版本都可作为独立可操作的作品,而原型的构造一般是为了演示。
8.1.5 喷泉模型
喷泉模型:是一种以用户需求为动力,以对象作为驱动的模型,适合于面向对象的开发方法。使开发过程具有迭代性和无间隙性
8.1.6 基于构件的开发模型CBSD
基于构件的开发模型CBSD: 利用预先包装的构件来构造应用系统。构件可以是组织内部开发的构件,也可以是商品化成品软件构件。特点是增强了复用性,在系统开发过程中,会构建一个构件库,供其他系统复用,因此可以提高可靠性,节省时间和成本。(前端界面开发,组件库)
8.1.7 v模型
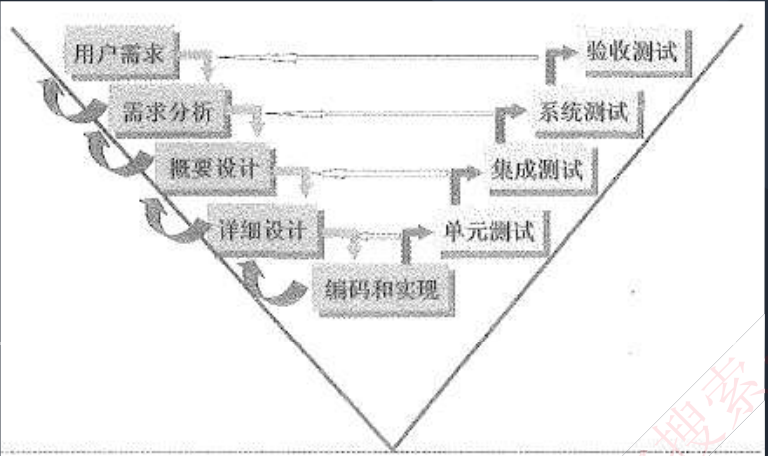
v模型从整体上看起来,就是一个V字型的结构,由左右两边组成。左边的下画线分别代表了需求分析、概要设计、详细设计、编码。右边的上画线代表了单元测试、集成测试、系统测试与验收测试。V模型的特点如下:
- (1)
单元测试的主要目的是针对编码过程中可能存在的各种错误(在详细设计阶段就要进行制定单元测试计划,但是是在编码和实现阶段执行) - (2)
集成测试的主要目的是针对详细设计中可能存在的问题(在概要设计阶段就要进行制定集成测试计划,但是是在详细设计阶段执行) - (3)
系统测试主要针对概要设计,检查系统作为一个整体是否有效地得到运行;(在需求分析阶段就要进行制定系统测试计划,但是是在概要设计阶段执行) - (4)
验收测试通常由业务专家或者用户进行,以确认产品能真正符合用户业务上的需要。(在需求分析阶段执行) - (5)V模型用于
需求明确和需求变更不频繁的情形
8.1.8 形式化方法模型
形式化方法模型:建立在严格数学基础上的一种软件开发方法,主要活动是生成计算机软件形式化的数学规格说明。
8.2 测试
- 测试用例
黑盒测试用例:将程序看做一个黑盒子,只知道输入输出,不知道内部代码
由此设计出测试用例,分为下面几类:-
等价类划分:把所有的数据按照某种特性进行归类,而后在每类的数据里选取一个即可(0-100 可以分成优(90-100),良(80-89),及格(60-79),不及格(0-59),有效等价类就是正确的(0-100),无效等价类指错误的(<0或>100)) 。等价类测试用例的设计原则:设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖的有效等价类,重复这一步,直到所有的有效等价类都被覆盖为止;设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步,直到所有的无效等价类都被覆盖为止。为了避免程序因检测到首个错误而停止检查从而产生"屏蔽现象",必须为每个无效等价类单独设计测试用例,确保每次只包含一个错误输入,以精准验证系统对各类异常的独立处理能力,如果将多个无效等价类测试用例写进了同一条测试用例,会导致后面的错误被"屏蔽"了
-
边界值划分:将每类的边界值作为测试用例,边界值一般为
范围的两端值以及在此范围之外的与此范围间隔最小的两个值,如年龄范围为0-150,边界值为0.150,-1,151四个。
-
错误推测:没有固定的方法,凭经验而言,来推测有可能产生问题的地方
作为测试用例进行测试
-
因果图:由一个结果来反推原因的方法,具体结果具体分析,没有固定方法
-
白盒测试用例:知道程序的代码逻辑,按照程序的代码语句,来设计覆盖代码分支的测试用例,覆盖级别从低至高分为下面几种:
(1)语句覆盖SC:逻辑代码中的所有语句都要被执行一遍,覆盖层级最低,因
为执行了所有的语句,不代表执行了所有的条件判断。
(2)判定覆盖DC:逻辑代码中的所有判断语句的条件的真假分支都要覆盖一次
(3)条件覆盖CC:针对每一个判断条件内的每一个独立条件都要执行一遍真和 假。
(4)条件判定组合覆盖CDC:同时满足判定覆盖和条件覆盖
(5)路径覆盖:逻辑代码中的所有可行路径都覆盖了,覆盖层级最高(简单来说,路径覆盖在理论上包含了判定覆盖,但不一定包含条件覆盖。) 流程图的所有路径条数 = 满足完全路径覆盖的测试用例数
8.3 敏捷开发方法
-
结对编程:
一个程序员开发,另一个程序在一旁观察审查代码,能够有效的提高代码质量,在开发同时对代码进行初步审查,共同对代码负责。
-
自适应开发:强调开发方法的
适应性(Adaptive)。不象其他方法那样有很多具体的实践做法,它更侧重为软件的重要性提供最根本的基础,并从更高的组织和管理层次来阐述开发方法为什么要具备适应性。 -
水晶方法:
每一个不同的项目都需要一套不同的策略、约定和方法论。 -
特性驱动开发:是一套
针对中小型软件开发项目的开发模式。是一个模型驱动的快速迭代开发过程,它强调的是简化、实用、易于被开发团队接受,适用于需求经常变动的项目。 -
极限编程XP:核心是
沟通、简明、反馈和勇气。因为知道计划永远赶不上变化,XP无需开发人员在软件开始初期做出很多的文档。XP提倡测试先行,为了将以后出现bug的几率降到最低。 -
并列争球法SCRUM:是一种
迭代的增量化过程,把每段时间 (30天) 一次的迭代称为一个"冲刺",并按需求的优先级别来实现产品,多个自组织和自治的小组并行地递增实现产品。
- 度量法
McCabe度量法:又称为环路复杂度,假设有向图中有向边数为m,节点数为n, 则此有向图的环路复杂度为m-n+2
针对一个程序流程图,每一个分支边(连线)就是一条有向边,每
一条语句(语句框)就是一个顶点。
- 路径覆盖原则:每条独立路径对应一个测试用例
- 计数技巧:
- 始终遵循箭头方向
- 合并节点不代表路径交叉
- 实际考试中常见4条基础路径
- McCabe计算:
- 顶点数:11个(所有语句框和判断框)
- 边数:13条(所有箭头连线)
- 复杂度:13-11+2=4
- 易错点:
- 边数统计时容易漏计反向循环边
- 误将合并节点视为新路径起点
- 公式误记为"节点数-边数"导致符号错误
9.面向对象
面向对象的分析方法主要有三大模型:
- 对象模型是基础,定义了系统的静态结构
- 动态模型依赖对象模型,描述对象的交互行为
- 功能模型描述了系统的功能需求和数据变换,为对象模型和动态模型提供功能需求来源(用例图)
1.多态
多态:不同的对象收到同一个消息时产生完全不同的结果。包括参数多态(不同类型参数多种结构类型)、包含多态(父子类型关系)、过载多态(类似于重载,一个名字不同含义)强制多态(强制类型转换) 四种类型。多态由继承机制支持,将通用消息放在抽象层,具体不同的功能实现放在低层。
2.面向对象的设计原则:
(1) 单一责任原则。就一个类而言,应该仅有一个引起它变化的原因。即,当需要修改某个类的时候原因有且只有一个,让一个类只做一种类型责任
(2) 开放一封闭原则。软件实体 (类、模块、函数等) 应该是可以扩展的,即开放的;但是不可修改的,即封闭的。
(3)里氏替换原则。子类型必须能够替换掉他们的基类型。即,在任何父类可以出现的地方,都可以用子类的实例来赋值给父类型的引用。
(4)依赖倒置原则。抽象不应该依赖于细节,细节应该依赖于抽象。即,高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
(5)接口分离原则。不应该强迫客户依赖于它们不用的方法。接口属于客户不属于它所在的类层次结构。即:依赖于抽象,不要依赖于具体,同时在抽象级别不应该有对于细节的依赖。
3.uml关系
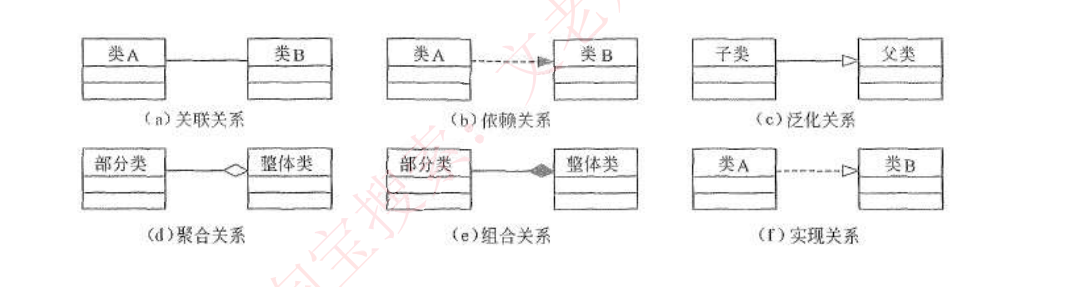
uml关系:依赖 <关联 <聚合 <组合 < 实现 =泛化(关系的强弱)
- 依赖关系
- 定义:一个事物的语义依赖于另一个事物的语义变化而变化
- 图形表示:虚线加实心箭头
- 举例:人类依赖于空气和水生存,当空气和水变化时,人类状态也会变化
- 关联关系
- 定义:结构关系,描述对象之间的连接,如老师与学生,丈夫与妻子
- 图形表示:一条直线(可能带有数字表示多重度)
- 特殊类型:
- 聚合:部分和整体关系,生命周期不绑定(空心菱形)
- 举例:雁群和大雁,大雁可以脱离雁群
- 组合:更强的部分和整体关系,具有共同生命周期(实心菱形)
- 举例:人和大脑,人不存在时大脑也不存在
- 泛化关系
- 定义:一般/特殊关系,即父类和子类关系
- 图形表示:实线加空心箭头
- 举例:学生(一般)与研究生(特殊)、图书(一般)与教材(特殊)
- 实现关系
- 定义:一个类元实现另一个类元定义的契约
- 图形表示:虚线加空心箭头
- 代码对应:类实现接口的关系
UML类图如下:
3.1 静态图
1.用例图:
用例图:静态图,展现了一组用例、参与者以及它们之间的关系。用例图中的参与者是人、硬件或其他系统可以扮演的角色;用例是参与者完成的一系列操作,用例之间的关系有扩展、包含、泛化。如下:
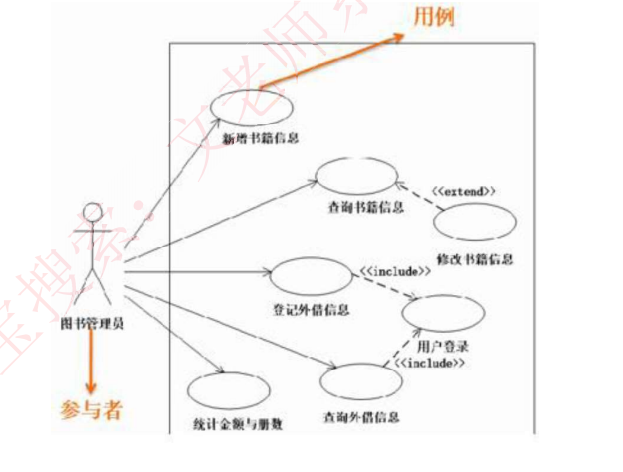
-
参与者
- 本质定义: 与系统交互的人、硬件或外部系统角色
- 识别特征:
- 名词性实体(如图书管理员)
- 参与系统交互过程
- 典型示例: 图书馆管理系统中的"图书管理员"参与者
-
用例
- 核心概念: 参与者完成的系列操作,对应系统功能
- 表现形式:
- 椭圆图形表示(如"新增书籍信息")
- 可理解为加工过程或功能模块
- 建模要点: 每个参与者对应多个用例(如管理员可进行查询、登记等操作)
-
用例之间的关系
-
箭头方向别搞反:
- 包含:基 → 包含用例
- 扩展:扩展 → 基
- 泛化:子 → 父
-
包含 ≠ 扩展:包含是"必须做",扩展是"可做可不做"
-
泛化用空心三角箭头 ,不是
<<extends>>
-
3.2 动态图
通信图:是顺序图的另一种表示方法,也是由对象和消息组成的图,只不过不强调时间顺序
只强调事件之间的通信,而且也没有固定的画法规则,和顺序图统称为交互图。
主要考察填对象名、填消息
通信图:动态图,即协作图,强调参加交互的对象的组织。如下
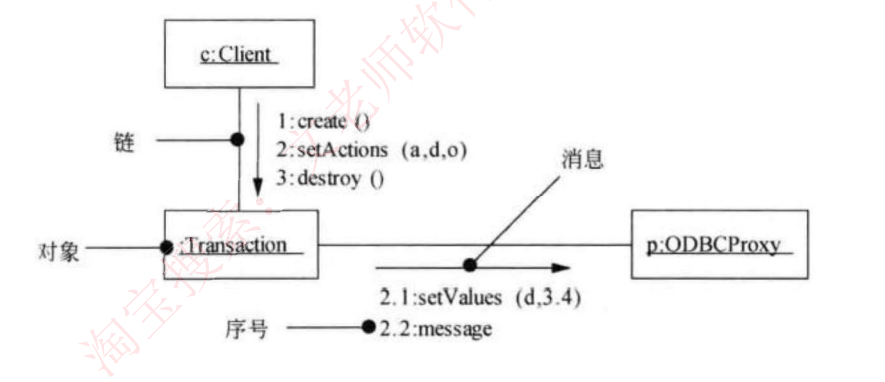
- 核心特征:
- 对象组织: 强调交互对象的空间组织结构
- 链(link): 对象间的连接线(非类关系)
- 消息编号: 每个消息前标注执行序号(如1: create())
- 与序列图区别:
不强调时间顺序,而是通过编号体现执行次序可包含嵌套序号(如2.1、2.2表示消息的层次关系)- 示例中展示的消息链:create→setActions→setValues→destroy
- 元素表示:
- 对象:矩形框表示(如:Transaction)
- 消息:沿链标注的带序号文本(如3: destroy())
- 典型应用: 展示复杂系统中对象间的协作关系
- 考试重点:
- 通过编号消息和对象链识别通信图
- 理解与序列图在表示方法上的本质差异
4.设计模式
4.1 创建者模式
| 模式 | 核心目的 | 关键特征 | 典型应用 |
|---|---|---|---|
| Singleton | 唯一实例 | 私有构造,静态获取 | 配置中心、连接池 |
| Prototype | 复制对象 | clone() 方法 |
对象初始化成本高时 |
| Factory Method | 子类决定实例 | 继承 Creator,重写工厂方法 | 框架扩展点 |
| Abstract Factory | 创建产品族 | 接口定义一族产品,具体工厂实现 | UI 主题切换、跨平台组件 |
| Builder | 分步构建复杂对象 | 链式调用 (setX().setY()) |
构造参数多且复杂的对象 |
4.2 结构者模式
| 模式 | 核心关键词 | 解决什么问题 | 典型例子 |
|---|---|---|---|
| Adapter | 转换 | 接口不兼容 | 电源适配器、旧系统迁移 |
| Bridge | 解耦 | 多维变化导致类爆炸 | 形状 x 颜色、平台 x 实现 |
| Composite | 树形 | 统一处理单个和组合对象 | 文件系统、UI 组件树 |
| Decorator | 包装 | 动态添加功能,避免子类爆炸 | Java IO 流、咖啡加料 |
| Facade | 简化 | 子系统太复杂,难使用 | 启动电脑、框架入口 |
| Flyweight | 共享 | 对象太多,内存占用大 | 文本字符、游戏地图元素 |
| Proxy | 控制 | 控制访问、增加额外逻辑 | 权限校验、RPC 调用、懒加载 |
4.3 行为者模式
| 模式 | 核心关键词 | 解决问题 | 典型应用 |
|---|---|---|---|
| Chain of Resp | 传递 | 多个对象处理请求,解耦发送接收 | 审批流、异常处理链 |
| Command | 封装 | 请求参数化、撤销/重做 | 菜单项、事务日志 |
| Interpreter | 语法 | 定义语言文法并解释执行 | SQL 解析、规则引擎 |
| Iterator | 遍历 | 统一访问集合,隐藏内部结构 | Java Collection 框架 |
| Mediator | 协调 | 多对多交互变一对多,降低耦合 | 聊天室、UI 控件交互 |
| Memento | 快照 | 保存和恢复对象状态 | 游戏存档、编辑器撤销 |
| Observer | 通知 | 一对多依赖,状态变更自动通知 | 事件驱动、MVVM |
| State | 状态 | 对象行为随状态改变,消除 if-else | 订单状态机、TCP 连接 |
| Strategy | 替换 | 封装算法族,自由切换 | 排序算法、支付策略 |
| Template Method | 骨架 | 定义流程骨架,子类实现细节 | 框架生命周期、Servlet |
| Visitor | 分离 | 数据结构稳定,操作多变 | 编译器 AST 分析、报表生成 |
10.数据库
分布式数据库透明:
| 透明性类型 | 隐藏了什么细节? | 用户的感知 | 层次 |
|---|---|---|---|
| 分片透明 | 数据是否被分割、如何分割 | 就像在操作一张完整的表 | 最高 |
| 位置透明 | 数据存放在哪个物理站点/机房 | 知道数据分了块,但不用管在哪 | 中间 |
| 复制透明 | 数据是否有副本、副本在哪里 | 感觉数据只有一份,不用担心同步 | 中间 |
| 逻辑透明 | 局部站点用的是什么数据库/模型 | 不用管底层是MySQL还是Oracle | 最低 |
1.求候选键字的方法
候选键: 由于每一行的属性值都是确定的,而候选键能唯一确定一行,因此它必然能函数决定(推导出)该表中的所有其他属性。
1. 识别必选属性(左部属性)
- 在函数依赖集F中,从未出现在右边 的属性,必须出现在候选键中
- 这些属性称为左部属性,记作L
2. 识别可选属性(中间属性)
- 既出现在左边,又出现在右边的属性,记作N
3. 识别不必要属性(右部属性)
- 只出现在右边,从未出现在左边的属性,记作R
4. 求候选键的步骤
- 计算闭包:计算L的闭包 L⁺
- 判断是否覆盖 :
- 如果 L⁺ 包含所有属性,则L就是候选键
- 如果不包含所有属性,则需要从N中选择属性组合添加到L中
5. 选择候选键
- 尝试将N中的属性逐个或组合添加到L中,计算闭包
- 目标是找到最小的属性集合K,使得 K⁺ = 所有属性
- K就是候选键
示例说明
例1: 关系R(A,B,C,D),函数依赖F = {A→B, B→C, C→D}
- L = {A}(只出现在左边)
- N = {B, C}(既出现在左也出现在右)
- R = {D}(只出现在右边)
计算:
- A⁺ = {A,B,C,D} ✓
- 所以{A}是候选键
例2: 关系R(A,B,C,D),函数依赖F = {AB→C, C→D, D→A}
- L = {B}(只出现在左边)
- N = {A, C, D}(既出现在左也出现在右)
- R = ∅
计算:
- B⁺ = {B},不包含所有属性
- 尝试组合:
- AB⁺ = {A,B,C,D} ✓
- BC⁺ = {A,B,C,D} ✓
- BD⁺ = {A,B,C,D} ✓
- 候选键:AB、BC、BD
关键要点
- 左部属性必须包含在候选键中
- 候选键是最小的,去掉任一属性就不再是超键
- 可能有多个候选键
- 闭包计算是关键工具
候选键的判断标准(必须同时满足):
- 决定性:能够函数决定所有属性( K\^+ = U )
- 最小性 :不存在真子集也能函数决定所有属性
这种方法的数学依据是:候选键必须能函数决定所有属性,且是最小集。左部属性由于不被任何属性决定,所以必须包含在候选键中。
2.求第几范式
求范式的题目,第一步就是要求候选键,因为知道候选键了,才能知道,主属性和非主属性,从而判断有没有部分依赖和传递依赖
我们一步步分析。
1. 已知条件
- 关系模式 R(E,N,M,L,Q)R(E, N, M, L, Q)R(E,N,M,L,Q)
- F = { E \\to N,\\ EM \\to Q,\\ M \\to L }
2. 求候选键
步骤1:找出只在左边出现的属性(L类)
E 出现在左边(E→N),不出现在右边 ✅
M 出现在左边(EM→Q 和 M→L),不出现在右边 ✅
(检查右边属性:N, Q, L,E 不在右,M 不在右)
L类 = {E, M}
N类(左右都出现)= 无
R类(只出现在右边)= {N, Q, L}
步骤2:计算 {E, M}+
{E, M}
E→N ⇒ {E, M, N}
M→L ⇒ {E, M, N, L}
EM→Q ⇒ {E, M, N, L, Q} ✅ 已包含所有属性。
步骤3:检查最小性
- 去掉 E:{M}+ = {M, L} ≠ U
- 去掉 M:{E}+ = {E, N} ≠ U
所以 {E, M} 是候选键,且是唯一候选键 。
主属性:E, M
非主属性:N, L, Q
3. 判断范式级别
3.1 检查 1NF
1NF 要求属性不可再分(原子性),默认满足。
3.2 检查 2NF
2NF:非主属性必须完全函数依赖于候选键,不能存在部分函数依赖。
候选键:EM(指{E, M}这个组合)
非主属性:
- N:依赖 E → N
- E 是候选键的真子集 ⇒ 这是部分函数依赖 (N 依赖于候选键的一部分 E)
⇒ 不满足 2NF。
- E 是候选键的真子集 ⇒ 这是部分函数依赖 (N 依赖于候选键的一部分 E)
由此已可确定:至少违反 2NF。
但我们继续看别的:
- L:依赖 M → L
- M 是候选键的真子集 ⇒ 部分函数依赖 ⇒ 违反 2NF
- Q:依赖 EM → Q
- EM 是整个候选键 ⇒ 完全依赖,满足 2NF
所以至少有两个非主属性(N, L)部分依赖于候选键。
4. 结论
违反 2NF ⇒ 最高满足 1NF。
最终答案:
$
\boxed{1NF}
$
范式定义
第一范式(1NF:First Normal Form)
表中的每个属性都是原子的(不可再分),且每一行是唯一的。
第二范式
满足 1NF,并且所有非主属性都完全函数依赖于每一个候选键(不能存在部分依赖)。 也即是如果一张表的主键是由多个字段组成的(复合主键),那么表里的其他字段必须依赖"整个主键",不能只依赖其中一部分。
第三范式
满足 2NF,并且所有非主属性都不传递依赖于候选键。
🔑 核心概念:传递依赖
- 如果
A → B且B → C,而B ↛ A(B 不决定 A),那么A → C是传递依赖。 - 在 3NF 中,
非主属性不能通过其他非主属性间接依赖于候选键。
❌ 反例(违反 3NF):
员工表:
| 员工ID | 姓名 | 部门ID | 部门名称 |
|---|
- 候选键:
员工ID - 函数依赖:
员工ID → 部门ID部门ID → 部门名称- 所以
员工ID → 部门名称(传递依赖!)
部门名称是非主属性,且传递依赖于主键
问题:
- 同一部门的员工重复存储部门名称 → 冗余
- 修改部门名称要改很多行 → 更新异常
✅ 修正(满足 3NF):
拆分:
员工表(Employee)
| 员工ID | 姓名 | 部门ID |
|---|
部门表(Department)
| 部门ID | 部门名称 |
|---|
3.自然连接
自然连接(Natural Join)
📌 关系代数符号:
R⋈S R \bowtie S R⋈S
🔍 含义:
自然连接是一种特殊的等值连接(Equi-Join),它会:
- 自动找出两个关系 RRR 和 SSS 中具有相同属性名的列(称为"公共属性");
- 在这些公共属性上进行等值匹配(即值相等);
- 结果中只保留一份公共属性列(不是"全部属性列都显示两遍"!);
- 只保留那些在公共属性上值相等的记录组合。
✅ 简单说:按同名列的值相等进行连接,并去重同名列。
🧩 举个例子(关键!)
假设有两张表:
表 Student
| id | name | dept_id |
|---|---|---|
| 1 | 张三 | 10 |
| 2 | 李四 | 20 |
表 Department
| dept_id | dept_name |
|---|---|
| 10 | 计算机 |
| 30 | 物理 |
✅ 自然连接:Student ⨝ Department
- 公共属性:
dept_id - 连接条件:
Student.dept_id = Department.dept_id - 结果中
dept_id只出现一次
结果:
| id | name | dept_id | dept_name |
|---|---|---|---|
| 1 | 张三 | 10 | 计算机 |
✅ 注意:
- 没有"显示全部属性列(重复)"------
dept_id只有一列;- 不是"属性相同且值相同的记录"------而是在公共属性上值相等的记录才被保留;
- 李四(dept_id=20)和物理系(dept_id=30)因为不匹配,不会出现在结果中。
❓ 回答你的原话:
"自然连接的结果显示全部的属性列"
🔴 错误 。
✅ 正确:显示所有属性列,但公共属性列只保留一份(不是 R 的列 + S 的列,而是合并同名列)。
"关系模式中属性相同且值相同的记录"
🔴 表述不清/误导 。
✅ 正确:只有当两个关系在公共属性上的值相等时,对应的记录才会被连接成一条新记录 。连接有一对一以以及、一对多以以及多对多以进行连接。连接后数量关系=M*N
| 条件 | 是否会导致结果中某些字段值重复? |
|---|---|
| 两表连接字段是 一对一(1:1) | ❌ 不会 |
| 两表连接字段是 一对多(1:N) | ✅ 会("一"方字段重复) |
| 两表连接字段是 多对多(M:N) | ✅ 会(双方字段都可能重复) |
| 无论使用 INNER / LEFT / RIGHT / FULL JOIN | ⚠️ 只要发生多匹配,就会重复 |
💡 关键结论:重复是由"数据关系"决定的,不是由 JOIN 类型决定的。
只要连接键在任一表中不唯一,任何类型的 JOIN 都可能产生重复字段值。
💡 对应 SQL 写法
标准 SQL 中,没有直接的 NATURAL JOIN 语法在所有数据库中都推荐使用(因其隐式依赖列名,易出错),但 MySQL 支持:
sql
SELECT *
FROM Student
NATURAL JOIN Department;⚠️ 但更安全、清晰的做法是显式写 JOIN ... ON:
sql
SELECT *
FROM Student s
JOIN Department d ON s.dept_id = d.dept_id;注意:
NATURAL JOIN会自动匹配所有同名列 ,如果表中有多个同名列(如id,name,dept_id都相同),它会全部用于等值连接,可能产生意外结果!
✅ 总结:自然连接的关键点
| 特性 | 说明 |
|---|---|
| 连接依据 | 所有同名属性(自动识别) |
| 连接条件 | 同名属性的值必须相等 |
| 结果列 | 所有属性,但同名属性只出现一次 |
| 结果行 | 仅保留满足连接条件的记录组合 |
| 与笛卡尔积区别 | 自然连接是带条件的、去冗余的连接,不是全组合 |
4. 选择(Selection 和 投影(Projection)以及 笛卡尔积
4.1 选择(Selection)------ σ(sigma)
✅ 关系代数符号:
σcondition(R) \sigma_{\text{condition}}(R) σcondition(R)
- R :一个关系(即一张表)
- \\text{condition} :一个逻辑条件,由属性、常量和比较运算符(=, >, 相当于 SQL 中的
WHERE子句。 选择条件是一个逻辑表达式,只要能对每一行返回 TRUE/FALSE,就可以作为选择条件- 关系代数中的 选择(Selection,记作 σ) 操作中,条件(condition)不仅可以比较列与常量,也可以比较两个列之间的大小、相等性等关系;列比较可在单表内完成;投影只选列,不涉及条件;
📌 示例:
设关系 \\text{Student}(id, name, age, major)
σage>20(Student) \sigma_{age > 20}(\text{Student}) σage>20(Student)
→ 返回所有年龄大于 20 的学生记录,包含全部四列。
从关系 R (即表)中筛选出满足条件的行(元组),列结构不变。
-
只过滤行,不改变列。
-
条件可以是等值、比较、逻辑组合等
SELECT *
FROM Student
WHERE age > 20;
📌 示例:
假设有一张员工表 Employee:
| id | name | base_salary | bonus |
|---|---|---|---|
| 1 | 张三 | 8000 | 2000 |
| 2 | 李四 | 5000 | 6000 |
| 3 | 王五 | 9000 | 9000 |
需求:找出 奖金大于基本工资 的员工
SELECT * FROM Employee WHERE bonus > base_salary;结果:
| id | name | base_salary | bonus |
|---|---|---|---|
| 2 | 李四 | 5000 | 6000 |
4.2 投影(Projection)------ π(pi)
✅ 关系代数符号:
πA1,A2,...,Ak(R) \pi_{A_1, A_2, \dots, A_k}(R) πA1,A2,...,Ak(R)
- R :一个关系
- A_1, A_2, \\dots, A_k ::: R 中的属性(列)名
🔍 含义:
从关系 R 中提取指定的属性列 ,组成一个新关系,并自动去除重复元组(因为关系是集合)。
相当于 SQL 中的
SELECT col1, col2(注意:SQL 默认不去重,需加DISTINCT才等价)。
📌 示例:
πname,major(Student) \pi_{name, major}(\text{Student}) πname,major(Student)
→ 只保留学生的姓名和专业两列,并去掉重复的(name, major)组合。
SELECT DISTINCT name, major
FROM Student;4.3 笛卡尔积(Cartesian Product)------ ×
✅ 关系代数符号:
R×S R \times S R×S
- 保留所有列,若有同名属性会同时存在
- R 和 S :两个关系(表)
- 要求: R 和 S 的属性名不能有重复(否则需先重命名)两个关系进行笛卡尔积时,如果存在同名属性,必须通过重命名来区分。R 和 S 都有属性 A 规范地表示为 R.A 和 S.A。
自然连接看作是笛卡尔积的一个"优化精简版"。在数据库的底层逻辑中,自然连接的实际运算过程可以拆解为以下三步:
- 先做笛卡尔积:把两张表的所有数据强行组合在一起。
- 做筛选(选择):自动找出两张表中所有名字相同的字段,只保留这些字段值相等的行。
- 做去重(投影):把那些用来匹配的重复字段删掉一份,只留一个。
🔍 含义:
将 R 中的每一条元组 与 S 中的每一条元组进行拼接,形成所有可能的组合。
- 新关系的属性 = R 的属性 + S 的属性
- 新关系的元组数 = \|R\| \\times \|S\|
相当于 SQL 中的
CROSS JOIN。
📌 示例:
设
- R = \\text{Dept}(dno, dname)
- S = \\text{Emp}(eno, ename)
Dept×Emp \text{Dept} \times \text{Emp} Dept×Emp
→ 结果包含 (dno, dname, eno, ename),共 \|\\text{Dept}\| \\times \|\\text{Emp}\| 行。
例如:若 Dept 有 2 行,Emp 有 3 行,则结果有 6 行。
SELECT *
FROM Student
CROSS JOIN Course;或旧式写法
SELECT * FROM Student, Course;5.三级模式和二级映射
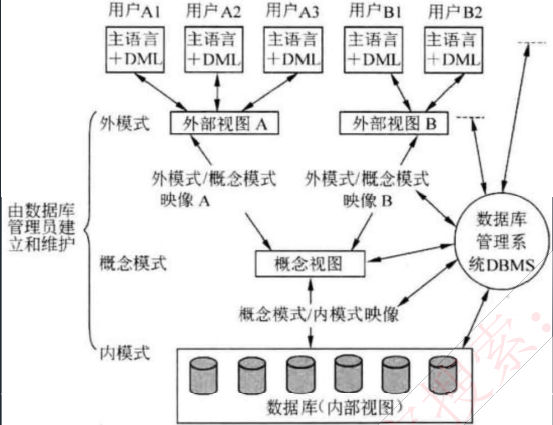
1. 三级模式
- 外模式(External Schema):面向用户或应用程序的视图,描述用户看到的数据结构。
- 概念模式(Conceptual Schema):全局逻辑结构,描述整个数据库的实体、关系、约束等(如 ER 图或关系模式)。
- 内模式(Internal Schema):物理存储结构,描述数据如何在磁盘上存储(索引、文件组织等)。
2. 两级映射
- 外模式/概念模式映射 :实现逻辑数据独立性。当概念模式改变时,只需调整映射,外模式可不变。
- 概念模式/内模式映射 :实现物理数据独立性。当存储结构改变时,概念模式不受影响。
在数据库理论中,三级模式 是:外模式 (用户视图)、概念模式 (逻辑结构)、内模式 (物理存储)。二级映射用于保证数据的逻辑独立性和物理独立性。
为了让你看得更清楚,我们基于一个简单的电商系统来构建例子。
第一步:定义背景与基础表
假设我们有一个商品表,在概念模式中,逻辑上定义为:
sql
-- 这部分属于:概念模式 (全局逻辑视图)
CREATE TABLE Products (
ProductID INT PRIMARY KEY, -- 商品编号
ProductName VARCHAR(100), -- 商品名称
Price DECIMAL(10,2), -- 价格
Stock INT -- 库存数量
);概念模式告诉用户:"数据库里有一个叫 Products 的表,里面有这四列"。它不关心数据是存在 SSD 还是机械硬盘里(那是内模式的事)。
第二步:外模式:为用户定制视图(SQL 视角)
外模式解决的是:不同的用户想看不同的数据。我们用 SQL 的 VIEW(视图) 来实现。
-
场景 1:客服人员
客服需要看价格和库存,但不需要关心数字编号(ProductID)有多长,看着乱。而且客服不应该修改价格(只能改库存)。
-
场景 2:财务人员
财务只关心商品卖了多少钱(价格),完全不关心仓库里还剩多少货(Stock)。
SQL 实现外模式:
sql
-- 外模式 1:客服视图 (隐藏了 ID 列,不允许改价格)
CREATE VIEW CustomerService_View AS
SELECT ProductName, Price, Stock
FROM Products;
-- 外模式 2:财务视图 (只关心价格,隐藏了库存)
CREATE VIEW Finance_View AS
SELECT ProductID, ProductName, Price
FROM Products;- 效果 :当客服执行
SELECT * FROM CustomerService_View时,他看到的是 3 列(名字、价格、库存),仿佛这张表天生就只有 3 列。这就是外模式。
第三步:内模式:物理存储(SQL 视角)
内模式解决的是:数据在硬盘上是怎么存的。虽然标准 SQL 不直接操作物理块,但现代数据库通过存储引擎参数 和索引来体现内模式。
SQL 实现内模式(以 MySQL 的 InnoDB 引擎为例):
sql
-- 内模式指令:告诉数据库,这张表的数据按 "Price" 列的顺序物理存放 (聚集索引)
-- 实际上是在定义主键时的存储方式
ALTER TABLE Products ADD INDEX idx_price (Price);
-- 内模式指令:把商品名压缩存储,节省空间
ALTER TABLE Products ROW_FORMAT=COMPRESSED;- 效果 :如果概念模式 不变,但 DBA(数据库管理员)把索引从
idx_price换成了idx_name,客服和财务写的 SQL 一句都不用改。这就是内模式的作用。
第四步:二级映射(关键!)
映射就是"翻译官"。如果没有映射,数据就无法在三层之间流通。
1. 外模式 / 概念模式 映射
作用:当你查外模式(视图)时,数据库怎么知道要去查哪个真实表?
SQL 示例(数据库内部做的翻译):
-
用户输入(外模式):
sql-- 客服只认识外模式里的 "ProductName, Price, Stock" SELECT * FROM CustomerService_View WHERE ProductName = '鼠标'; -
数据库内部自动翻译(映射):
sql-- 数据库查到定义后,实际执行的逻辑(概念模式): SELECT ProductName, Price, Stock FROM Products -- 把 "CustomerService_View" 映射到了 "Products" 表 WHERE ProductName = '鼠标';
逻辑独立性 :即使你在 Products 表里加了一列 SupplierID(供应商ID),客服的视图没变,这个映射规则依然有效,客服的 SQL 运行结果正常。
2. 概念模式 / 内模式 映射
作用:当你操作逻辑表(概念模式)时,数据库怎么知道数据在硬盘的哪个物理位置?
SQL 示例(数据库内部做的翻译):
-
用户输入(概念模式):
sql-- 用户说:把价格改一下 UPDATE Products SET Price = 99 WHERE ProductID = 1; -
数据库内部自动翻译(映射):
数据库的引擎(如 InnoDB)会查找内部字典:
"ProductID = 1 这条记录,存放在
products.ibd文件的第 3 号数据页,第 7 号偏移量位置。"然后数据库发起物理 I/O 操作 ,去那个硬盘扇区把
99这个数字写进去。
物理独立性 :假如 DBA 觉得硬盘不够快,买了一块新磁盘,把 products.ibd 文件从 /old_disk/ 移到了 /new_ssd/。用户执行的 UPDATE Products 语句完全不需要修改,照样运行。
总结对照表(含 SQL 对应物)
| 概念 | SQL 中的实现 | 一句话解释 |
|---|---|---|
| 外模式 | CREATE VIEW ... |
用户看到的虚拟表,可以是表的一部分或多张表拼接。 |
| 概念模式 | CREATE TABLE ... |
表长什么样(有哪些列,主键是什么)。 |
| 内模式 | CREATE INDEX ... ROW_FORMAT=... |
数据在硬盘上怎么存(索引、压缩、分区)。 |
| 外模式/概念映射 | 视图定义里 SELECT ... FROM 某表 |
视图是哪张表变的?数据怎么对上的? |
| 概念/内模式映射 | 存储引擎内部转换 | 逻辑的"行"对应硬盘上哪个物理"页"? |
现实中的 SQL 例子:
假设你要给财务做一个只看到价格的功能:
- 写外模式 :
CREATE VIEW Finance AS SELECT ProductName, Price FROM Products; - 物理优化(内模式) :
CREATE INDEX idx_price ON Products(Price);(让查价格更快) - 用户查询 :
SELECT * FROM Finance WHERE Price > 100; - 第一次映射 :
Finance->Products表 - 第二次映射 :
Products表 -> 利用idx_price索引在硬盘上快速定位数据
这就是三级模式二级映射在 SQL 世界里的完整运作过程。
6.事务
事务:由一系列操作组成,这些操作,要么全做,要么全不做,拥有四种特
性,详解如下:
- (操作) 原子性:要么全做,要么全不做
- (数据)一致性:事务发生后数据是一致的,例如银行转账,不会存在A账户转
出,但是B账户没收到的情况。 - (执行)隔离性:任一事务的更新操作直到其成功提交的整个过程对其他事务
都是不可见的,不同事务之间是隔离的,互不干涉。 - (改变)持久性:事务操作的结果是持续性的。
| 协议级别 | 核心加锁规则 | 解决的并发问题 |
|---|---|---|
| 一级封锁协议 | 修改前加 X 锁,事务结束释放 | 丢失修改 |
| 二级封锁协议 | 修改同上;读取前加 S 锁,读完立即释放 | 丢失修改、读脏数据 |
| 三级封锁协议 | 修改同上;读取前加 S 锁,事务结束释放 | 丢失修改、读脏数据、不可重复读 |
11. 数据结构
1. 栈和队列
- 队列、栈结构如下图
- 队列是先进先出,分队头和队尾:
- 栈是先进后出,只有栈顶能进出。
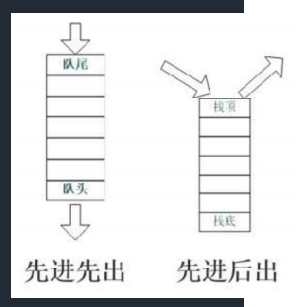
| 特性 | 队列 (Queue) | 栈 (Stack) |
|---|---|---|
| 核心原则 | 先进先出 (FIFO) | 后进先出 (LIFO) |
| 生活比喻 | 食堂排队打饭、隧道 | 叠盘子、弹夹、浏览器后退键 |
| 插入位置 | 只能在队尾插入 | 只能在栈顶插入 |
| 删除位置 | 只能在队头删除 | 只能在栈顶删除 |
| 典型操作 | 删除最老的(队头) | 删除最新的(栈顶) |
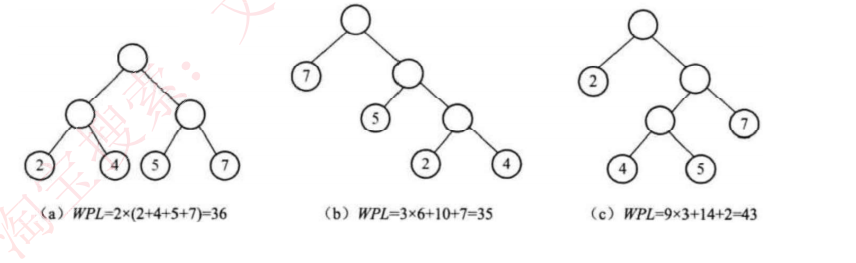
2. 哈夫曼树
核心概念(您已精确定义)
- 路径:树中一个结点到另一个结点之间的通路。
- 结点的路径长度 :从根节点到该结点的路径上的分支数目(即经过的边数)。
- 树的路径长度 :根节点到每一个叶子结点的路径长度之和。
- 权:为叶子结点赋予的一个有意义的数值(如字符频率、数据访问概率等)。
- 结点的带权路径长度 :
结点的路径长度 × 该结点的权值。 - 树的带权路径长度(WPL) :树中所有叶子结点 的带权路径长度之和。WPL是衡量二叉树"代价"的核心指标,哈夫曼树就是WPL最小的二叉树。
哈夫曼树求法
- 哈夫曼树只能是0度或者2度
- 哈夫曼树从下往上构建
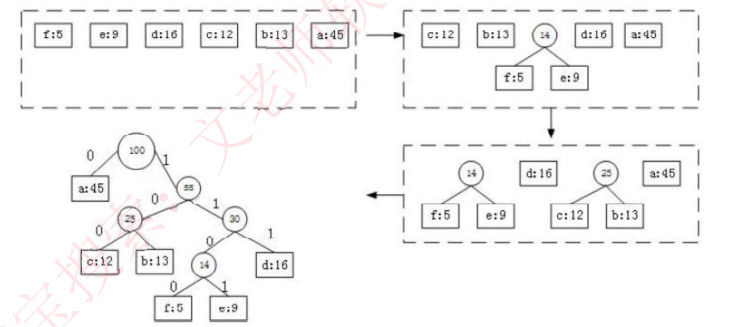
给定 n 个权值为 {w₁, w₂, ..., wₙ} 的叶子结点,构造哈夫曼树的步骤如下:
- 初始化 :将这
n个权值分别看作n棵仅有一个根节点的二叉树,组成一个森林F。每棵树的根节点权值即为给定的权值。 - 选取与合并 :
- 在
F中选取根节点权值最小的两棵二叉树。 - 以它们为左右子树(权值较小的通常作为左子树),构造一棵新的二叉树。新二叉树的根节点权值为其左右子树根节点权值之和。按照通用的**"左小右大"(权值小的放左边)和"左0右1"**的习惯
- 在
- 删除与加入 :
- 从
F中删除刚选取的两棵二叉树。 - 将新构造的二叉树加入
F。
- 从
- 重复 :重复步骤 2 和 3,直到森林
F中只剩下一棵 二叉树为止。这棵树就是哈夫曼树。
哈夫曼编码(数据压缩)
这是哈夫曼树最经典的应用,用于构造最优前缀码。
- 构建:将需要编码的字符作为叶子结点,其出现频率(或概率)作为权值,构造一棵哈夫曼树。
- 编码 :在哈夫曼树中,从根节点到每个叶子结点的路径上:
- 走向左子树标记为
0(或1)。 - 走向右子树标记为
1(或0)。 - 这样,每个叶子结点(字符)对应的路径上的
0/1序列就是其哈夫曼编码。
- 走向左子树标记为
- 优点 :
- 前缀码特性:任何一个字符的编码都不是另一个字符编码的前缀,解码时无二义性。
- 最优压缩 :由于高频字符(权值大)路径短,编码短;低频字符(权值小)路径长,编码长。这使得整个编码文件的平均码长最短,实现了无损数据压缩。
好的,我们先一步步构造哈夫曼树。
字符 a,b,c,d,e,f 对应出现的次数为 6,3,8,2,10,4,则各字符对应的哈夫曼编码是多少
** 构造哈夫曼树**
第一步: 选最小的两个 d(2) 和 b(3) 合并成 5
剩余:f(4), a(6), c(8), e(10), 新节点(5)
第二步: 选最小的 f(4) 和 5 合并成 9
剩余:a(6), c(8), e(10), 新节点(9)
第三步: 选最小的 a(6) 和 c(8) 合并成 14
剩余:e(10), 9, 14
第四步: 选最小的 9 和 e(10) 合并成 19
剩余:14, 19
第五步: 合并 14 和 19 成 33(根)
用文本画出来(左分支为 0,右分支为 1):
根(33)
/ \
0/ \1
(14) (19)
/ \ / \
0/ \1 0/ \1
a(6) c(8) (9) e(10)
/ \
0/ \1
f(4) (5)
/ \
0/ \1
d(2) b(3)对应编码路径(左 0 右 1):
- a: 左(14) → 左(6) → 00
- c: 左(14) → 右(8) → 01
- f: 右(19) → 左(9) → 左(4) → 100
- d: 右(19) → 左(9) → 右(5) → 左(2) → 1010
- b: 右(19) → 左(9) → 右(5) → 右(3) → 1011
- e: 右(19) → 右(10) → 11
需要我帮你把这个树画成更直观的图形(比如用 Mermaid 或手绘风格图)吗?
最终答案
\\boxed{a:00,\\quad b:1011,\\quad c:01,\\quad d:1010,\\quad e:11,\\quad f:100}
3. 二叉树
3.1 二叉树性质
计算技巧:
- 总节点数 = 所有节点的子节点数之和 + 1,等价于" 节点数= 边数 + 1" 也可以说节点数 = 树的总度数 + 1
树的总度数= 所有节点的子节点数(度)之和,比如5个度为4的节点(5*4=20),7个度为3的节点...,9个度为1节点,度为0的节点有x个(0乘以任何数还是0)
- :完全二叉树深度公式** (最小高度)
公式 :具有n个结点的完全二叉树的深度为⌊log₂n⌋ + 1
对于深度为k的完全二叉树:
- 最少结点数:
2^(k-1)(前k-1层满,第k层只有1个) - 最多结点数:
2^k - 1(满二叉树) - 所以:
2^(k-1) ≤ n ≤ 2^k - 1 - 取对数:
k-1 ≤ log₂n < k - 所以:
k = ⌊log₂n⌋ + 1
节点数是50,则深度为 ⌊log₂50⌋ + 1
- 计算对数:log₂50 约等于 5.64
- 向下取整:⌊5.64⌋ = 5
- 加上 1:5 + 1 = 6
-
对任何一棵二叉树,若其终端结点数(叶子)为n₀,度为2的结点数为n₂,则:
n₀ = n₂
设:
- n₀:叶子结点数(度为0)
- n₁:度为1的结点数
- n₂:度为2的结点数
- n:总结点数
推导过程:
- 总结点数:
n = n₀ + n₁ + n₂ - 总分支数(度数总和):
B = n₁ + 2n₂ - 二叉树性质:
总分支数 = 总结点数 - 1
(因为除了根结点,每个结点都有一个分支指向它) - 所以:
n₁ + 2n₂ = n₀ + n₁ + n₂ - 1 - 化简得:
n₀ = n₂ + 1
text
示例1: 示例2:
A A
/ \ / \
B C B C
/ \ /
D E D
n₀=3 (D,E,C) n₀=2 (D,C)
n₂=2 (A,B) n₂=1 (A)
3 = 2+1 ✓ 2 = 1+1 ✓3.2 二叉树排序
已知二叉树的后序 和中序 求前序,是软考和数据结构考试中的经典题型。其实只要掌握一个核心口诀和固定的步骤,完全可以在草稿纸上快速画出树,甚至直接口算出前序遍历。
核心解题口诀
"后序定根,中序分左右,前序先输出"
- 后序定根 :后序遍历的规则是"左->右->根",所以后序序列的最后一个元素,绝对是当前的根节点。
- 中序分左右 :中序遍历的规则是"左->根->右",找到根节点后,它左边的全是左子树,右边的全是右子树。
- 前序先输出 :前序遍历的规则是"根->左->右",所以我们每找到一个根,就立刻把它记下来,然后按顺序处理左子树和右子树。
实战解题步骤(附例题演示)
假设题目给出:
- 后序 :
D E B F G C A - 中序 :
D B E A F C G
求前序遍历。
第一步:找整棵树的根
看后序的最后一个字母,是 A。
- 技巧 :直接把 A 写下来(因为前序遍历第一个就是根)。
- 当前前序结果 :
A
第二步:在中序里分左右
在中序序列 D B E A F C G 中找到 A。
- A 的左边
D B E是左子树。 - A 的右边
F C G是右子树。
第三步:递归处理左子树(D B E)
回到后序序列,去掉已经用过的 A,剩下的后序是 D E B F G C。我们要从中找出对应左子树 D B E 的根。
- 看后序中属于
D B E的这三个字母,最后出现的是 B (后序为D E B ...)。所以 B 是左子树的根。 - 技巧 :把 B 接在 A 后面。
- 当前前序结果 :
A B - 再看中序的左子树部分
D B E,B 的左边是D(B的左孩子),右边是E(B的右孩子)。 - 左子树处理完毕,结构是:A的左孩子是B,B的左孩子是D,右孩子是E。
第四步:递归处理右子树(F C G)
回到后序序列,现在去掉 A 和 B,剩下的后序是 F G C。我们要从中找出对应右子树 F C G 的根。
- 看后序中属于
F C G的这三个字母,最后出现的是 C (后序为F G C)。所以 C 是右子树的根。 - 技巧 :把 C 接在 B 后面。
- 当前前序结果 :
A B C - 再看中序的右子树部分
F C G,C 的左边是F(C的左孩子),右边是G(C的右孩子)。 - 右子树处理完毕。
最终答案 :前序遍历为 A B D E C F G。
后序是DABEC 中序是DEBAC 则先序是?
已知正确的条件是:
- 后序 :
D A B E C - 中序 :
D E B A C
第一步:确定整体框架
根据后序遍历的最后一个字母 C ,我们确定 C 是整棵树的根 。
然后去中序遍历 D E B A C 里找 C,发现 C 的左边是 D E B A,右边是空的。这说明:这棵树没有右子树,D E B A 整体构成了 C 的左子树。
第二步:为什么 E 一定是根?
现在,我们的目光完全聚焦在 D E B A 这棵左子树上。
- 看后序 :在 C 的左子树部分
D A B E中,E 排在最后 。根据"后序定根"的铁律,E 绝对是这棵左子树的根节点(老大)。 - 看中序 :我们在中序遍历的左子树部分
D E B A中找到老大 E 。根据"中序分左右",E 的左边是D,右边是B A。- 这说明:D 是 E 的左孩子。
- B A 整体构成了 E 的右子树。
第三步:E 为什么"不可能是右节点"?
你的疑惑可能在于 E 在中序遍历里夹在中间,看起来像个"右节点"。但实际上:
- 在中序遍历
D E B A中,E 的右边确实有B A,这说明 E 确实拥有右子树(即 B 和 A 是 E 的右胳膊)。 - 但在后序遍历
D A B E中,E 必须排在最后。如果 E 只是某个节点的右孩子(比如假设 D 是根,E 是 D 的右孩子),那后序遍历的顺序就会变成"左 -> 右(E) -> 根(D)",E 就绝不可能排在最后。
总结一下这棵左子树的结构:
- 后序
D A B E:E 在最后,所以 E 是这棵子树的根。 - 中序
D E B A:E 在中间,所以 D 是 E 的左孩子,B A 是 E 的右子树。
所以,E 的身份是这棵局部子树的根节点(老大),同时它拥有右子树(B 和 A),但它自己绝不是谁的右节点。
为了帮你彻底理清,我把这棵树正确的完整结构画出来:
C
/
E
/ \
D B
\
A(按照正确的中序 DEBAC 和后序 DABEC 推导,A 其实是 B 的右孩子,而不是引用解答里说的 B 是 A 的右孩子。因为在中序 BA 中 A 在 B 右边,在后序 AB 中 B 在最后,说明 B 是根,A 是 B 的右孩子。)
按照这个正确的树结构,它的前序遍历(根左右)应该是:C E D B A。
软考极速解题技巧(草稿纸画图法)
在考试时,不用在脑子里硬想,建议在草稿纸上这样操作:
- 写两行:把后序和中序上下对齐写下来。
- 圈根节点:每次圈出后序的最后一个字母,这就是当前的"老大"(根)。
- 画竖线:在中序里找到这个"老大",画一条竖线把它左右隔开。左边的一堆归它的左胳膊(左子树),右边的一堆归它的右胳膊(右子树)。
- 重复操作:对左边那一堆和右边那一堆,重复上面的步骤。
- 直接读:你每圈出一个"老大",就按顺序把它写下来,最后连起来就是前序遍历!
避坑提示:
- 一定要看清题目给的是"后序+中序"还是"前序+中序"。如果是前序+中序,根节点在前序的第一个,其他逻辑完全一样。
- 如果题目给出的节点有重复值(比如多个字母A),这种题在软考中通常不会出现,因为会导致树的结构不唯一。放心大胆地按唯一值处理即可。
3.查找二叉树(二叉排序树)
查找二叉树上的每个节点都存储一个值,且每个节点的所有左孩子结点值都小于父节点值,而所有右孩子结点值都大于父节点值,是一个有规律排列的二叉树,这种数据结构可以方便查找、插入等数据操作。
核心性质
- 有序性 :对于任意节点:
- 左子树中所有节点的值 < 节点值
- 右子树中所有节点的值 > 节点值
- 中序遍历有序 :对BST进行中序遍历,会得到一个升序序列
构建二叉排序树过程: 1.以第一个元素为根节点;2.后面的两个元素与根节点比较,小的放左边,大的放右边,如果都小,则把第二个元素放根节点左侧后,再把第二个元素后的两个元素与第二个元素比较,小的放左边,大的放右边,以此类推,直到所有元素都比较完。
4.图
4.1 邻接矩阵
邻接矩阵是表示图中顶点之间相邻关系的矩阵:
- 对于有 n 个顶点 的图,邻接矩阵是 n × n 的矩阵
- 矩阵元素 AijAijAij 表示顶点 i 到顶点 j 的边的关系
对于无向图,顶点 i 的度 = 第 i 行(或列)元素之和
对于有向图:
- 出度 = 第 i 行元素之和(从 i 出发的边数)
- 入度 = 第 i 列元素之和(指向 i 的边数)
- 度 = 出度 + 入度
4.2 哈希查找
- 哈希冲突 :不同的关键字可能被哈希函数映射到同一个地址(例如,工号
12345和22345用%100计算后地址都是45)。这是哈希表设计时必须处理的核心问题。 - 冲突解决策略 :
- 链地址法(开散列法):每个地址位置不是一个记录,而是一个链表(或其他容器)。冲突的记录都放在这个链表里。查找时,在计算出的地址的链表中进行顺序查找。
- 开放定址法(闭散列法):所有记录都放在主数组里。发生冲突时,按照某种探测规则(如线性探测、二次探测)寻找数组中的下一个空位。查找时也需要遵循同样的规则进行探测。
假设哈希表大小m=10,哈希函数H(key)=key mod 10
插入序列 :47, 67, 43, 87, 91
| 步骤 | 关键字 | H(key) | 冲突处理 | 最终位置 | 表状态 |
|---|---|---|---|---|---|
| 1 | 47 | 7 | 直接插入 | 7 | ...7:47 |
| 2 | 67 | 7 | 冲突,探测8 | 8 | ...7:47, 8:67 |
| 3 | 43 | 3 | 直接插入 | 3 | ...3:43, 7:47, 8:67 |
| 4 | 87 | 7 | 冲突,探测8,再冲突,探测9 | 9 | ...3:43, 7:47, 8:67, 9:87 |
| 5 | 91 | 1 | 直接插入 | 1 | 1:91, 3:43, 7:47, 8:67, 9:87 |
5.链表
1.单链表
你可以把单链表想象成**"一列火车"或者 "手拉手排队的一群人"**。每个车厢(或人)就是链表中的一个"结点",它们手里拿着一个号码牌(数据),并且用手指着(指针 next)下一个人。
插入元素:怎么把"新同学"插队进队伍?
假设队伍里原本有 A、B、C 三个人,手拉手排着(A 拉着 B,B 拉着 C)。现在你想在 A 和 B 之间,强行插进去一个新同学 S。
核心就两步(口诀叫"先连后断"):
- 新同学 S 先伸手拉住 B (
S->next = B)。 - A 松开原本拉着 B 的手,改去拉 S (
A->next = S)。
这样,队伍就变成了 A -> S -> B -> C,完美插队成功!
⚠️ 软考最容易挖坑的地方(顺序绝对不能反):
如果你先让 A 松开了 B 的手去拉 S(A->next = S),这时候 A 就只认识 S 了。紧接着你再让 S 去拉 A 的后面(S->next = A->next),因为 A 现在后面就是 S 自己,结果就变成了 S 拉 S,原本的 B 和 C 就彻底掉队找不到了(链表断裂) !
所以一定要记住:新来的先把手伸出去拉住后面的人,前面的人再松手去拉新来的。
删除元素:怎么把"讨厌的人"踢出队伍?
假设队伍里是 A、B、C 三个人(A 拉着 B,B 拉着 C)。现在你想把中间的 B 踢走。
核心也是一步(口诀叫"直接绕过"):
你只需要让 A 松开 B 的手,直接去拉 C (A->next = C)。
一旦 A 直接拉住了 C,B 就被孤立出来了。在 C 语言里,这时候我们还需要做一个收尾工作:把被孤立的 B 彻底赶走(free(q)),也就是释放内存,不然他就会一直占着茅坑不拉屎(内存泄漏)。
总结一下(软考答题要点)
- 找前驱(找前一个人): 不管是插队还是踢人,你都得先找到被操作位置的前一个人(比如要在第 3 个位置操作,你得先找到第 2 个人)。
- 插入要"先连后断": 新结点先指后面,前驱再指新结点。
- 删除要"绕过并释放": 前驱直接指向后驱,然后记得把删掉的结点释放掉。
删除最后一个节点
在普通的单链表(只带一个头指针)中,想要删除最后一个节点,确实必须从头开始遍历。
为什么要从头遍历?
你可以把单链表想象成**"单向的寻宝游戏"或者"传话游戏"**:
- 每个人(节点)只知道下一个人是谁。
- 但是,没有人知道上一个人是谁。
当你想要删除最后一个节点(比如叫 Z)时,你的任务是让倒数第二个节点(Y)的手松开 (把 Y 的 next 指针设为 NULL)。
可是,当你站在最后一个节点 Z 面前时,你根本不知道 Y 是谁,因为 Z 手里没有"上一个人"的线索。所以,你只能无奈地回到起点(头结点),一个一个往下问:"你是 Y 吗?你的下一个人是 Z 吗?"直到找到 Y 为止。
因此,删除单链表尾节点的时间复杂度是 O(n)。
删除第一个节点之所以不需要遍历,是因为它拥有独一无二的"特权"------我们手里天生就握着它的线索(头指针)。
6.排序算法
这是一个很经典的软考考点。我把常考的排序算法分成三类,用最通俗的方式解释,并附上复杂度。
一、简单理解类(代码好写,但慢)
1. 冒泡排序
- 通俗解释:像水里气泡往上冒。从左到右,相邻两个比较,大的就往后换。每轮会把最大的"冒"到最后。
- 时间复杂度:平均 O(n²),最坏 O(n²),最好 O(n)(已排序时)
- 空间复杂度:O(1)
冒泡排序(从前往后比较 - 标准版)
javascript
function bubbleSort(arr) {
const n = arr.length;
let swapped;
for (let i = 0; i < n - 1; i++) {
swapped = false;
// 每趟将最大的元素"冒泡"到最后
for (let j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换相邻元素
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
swapped = true;
}
}
// 如果没有交换,说明已经有序
if (!swapped) break;
console.log(`第${i + 1}趟排序后:`, [...arr]);
}
return arr;
}
// 测试
const arr1 = [64, 34, 25, 12, 22, 11, 90];
console.log("原始数组:", arr1);
console.log("冒泡排序结果:", bubbleSort([...arr1]));2. 选择排序
- 通俗解释:每次从剩余数里挑最小的,放到已排序末尾。就像从一堆牌里反复挑最小的那张。
- 时间复杂度:永远是 O(n²)(不管好坏)
- 空间复杂度:O(1)
选择排序的核心是 "先选择,后交换",每趟只做一次交换(如果需要),这与冒泡排序每趟可能多次交换形成鲜明对比。
好的!简单选择排序是最符合人类直觉的排序方法之一,我保证你一学就会。
核心思想(一句话)
"每次从剩下的数里挑最小的,放到前面去"
就像你在水果摊挑苹果:
- 第一次:从所有苹果中挑最小的,放第一个位置
- 第二次:从剩下的苹果中挑最小的,放第二个位置
- 重复直到全部挑完
生活类比(秒懂版)
老师按身高排队:
- 老师扫一眼全班,找出最矮的同学:"你站第一个!"
- 从剩下的人里再找最矮的:"你站第二个!"
- 继续这样挑,直到所有人都站好
就这么简单!不需要任何复杂的交换逻辑。
手把手演示
原始数组 :[29, 10, 14, 37, 13]
第1轮:找最小的放第1位
数组:[29, 10, 14, 37, 13]
↑ ↑ ↑ ↑ ↑
找出最小的:10(在索引1)
交换29和10:
结果:[10, 29, 14, 37, 13]
✅ 第1位已确定第2轮:找第2小的放第2位
只看剩下的:[29, 14, 37, 13]
↑ ↑ ↑ ↑
找出最小的:13(在原数组索引4)
交换29和13:
结果:[10, 13, 14, 37, 29]
✅ 第2位已确定3. 插入排序
- 通俗解释:打牌时整理手牌。每拿一张新牌,插到前面合适位置。
- 时间复杂度:平均 O(n²),最坏 O(n²),最好 O(n)(已排序时)
- 空间复杂度:O(1)
小提示:插入排序在数据量小或基本有序时,实际效果不错。
执行过程演示(以 [5, 2, 4, 6, 1, 3] 为例):
- 初始:
[5] | 2,4,6,1,3→ 前1个有序 - i=1(key=2):比较5>2 → 移动5 → 插入2 →
[2,5] | 4,6,1,3 - i=2(key=4):5>4 → 移动5;2≤4 → 插入 →
[2,4,5] | 6,1,3 - i=3(key=6):5≤6 → 直接放后面 →
[2,4,5,6] | 1,3 - i=4(key=1):6>1,5>1,4>1,2>1 → 全部后移 → 插入开头 →
[1,2,4,5,6] | 3 - i=5(key=3):6>3,5>3,4>3;2≤3 → 插入在2后 →
[1,2,3,4,5,6]
可能出现在最后一趟开始之前,所有元素都不在最终位置上。
二、高效进阶类(快,但需要理解)
4. 希尔排序
- 通俗解释:插入排序的改进版。先隔着很远的位置比较移动(形成"跳跃"),让数组大致有序,最后再用一次插入排序。
- 时间复杂度:取决于步长序列,一般 O(n^1.3) 左右,最坏 O(n²)
- 空间复杂度:O(1)
先想想插入排序的痛点
普通插入排序:打扑克时理牌,一张张往前比较插入。
- 问题:如果最小的牌在最后面,要移动很多次才能到前面
例子 :[9, 8, 7, 6, 5, 4, 3, 2, 1]
- 1要从最后移动到最前,需要比较8次,移动8次
- 太慢了!
希尔排序的核心思想
"先粗排,再细排" ------ 就像筛沙子,先用大筛子,再用小筛子。
具体做法:
- 先选一个间隔(比如间隔4),把数组分成几组
- 每组分别用插入排序(让小的数快速跳到前面)
- 缩小间隔(比如间隔2),再分组排序
- 最后间隔=1,做一次普通插入排序(此时数组已经基本有序)
手把手演示
原始数组 :[8, 9, 1, 7, 2, 3, 5, 4, 6]
第1轮:间隔=4(长度9的一半左右)
按间隔4分组,相同颜色的为一组:
索引:0 1 2 3 4 5 6 7 8
数值:8 9 1 7 2 3 5 4 6
组别:红 黄 绿 蓝 红 黄 绿 蓝 红- 红组 (索引0,4,8):
[8, 2, 6]→ 排序后[2, 6, 8] - 黄组 (索引1,5):
[9, 3]→ 排序后[3, 9] - 绿组 (索引2,6):
[1, 5]→ 排序后[1, 5] - 蓝组 (索引3,7):
[7, 4]→ 排序后[4, 7]
排序后 :[2, 3, 1, 4, 6, 9, 5, 7, 8]
- 小数字(1,2,3,4)已经跑到前面了!
第2轮:间隔=2
索引:0 1 2 3 4 5 6 7 8
数值:2 3 1 4 6 9 5 7 8
组别:红 蓝 红 蓝 红 蓝 红 蓝 红- 红组 (偶数索引):
[2, 1, 6, 5, 8]→ 排序后[1, 2, 5, 6, 8] - 蓝组 (奇数索引):
[3, 4, 9, 7]→ 排序后[3, 4, 7, 9]
排序后 :[1, 3, 2, 4, 5, 7, 6, 9, 8]
- 更加有序了!
第3轮:间隔=1(普通插入排序)
此时数组已经基本有序 :[1, 3, 2, 4, 5, 7, 6, 9, 8]
只需微调就能完成:
- 3和2交换 →
[1, 2, 3, 4, 5, 7, 6, 9, 8] - 7和6交换 →
[1, 2, 3, 4, 5, 6, 7, 9, 8] - 9和8交换 →
[1, 2, 3, 4, 5, 6, 7, 8, 9]
完成! ✅
5. 归并排序
- 通俗解释:分而治之。把数组分成两半,分别排好序,再合并成有序数组。类似两副排好序的牌合并。
- 时间复杂度:始终 O(n log n)(稳定且快)
- 空间复杂度:O(n)(需要额外空间)
- 分解(Divide)
- 将待排序的数组递归地一分为二,直到每个子数组只包含一个元素(或为空)。
- 单个元素的数组天然有序。
- 合并(Conquer / Merge)
- 将两个已排序的子数组合并成一个更大的有序数组。
- 合并过程使用双指针技术,依次比较两个子数组的首元素,取较小者放入结果中。
✅ 关键:"分而治之,再合而有序"
举个例子(升序)
原始数组:[38, 27, 43, 3, 9, 82, 10]
-
分解:
[38, 27, 43, 3, 9, 82, 10] → [38, 27, 43, 3] + [9, 82, 10] → [38, 27] + [43, 3] + [9, 82] + [10] → [38] [27] [43] [3] [9] [82] [10] -
合并:
[27, 38] + [3, 43] + [9, 82] + [10] → [3, 27, 38, 43] + [9, 10, 82] → [3, 9, 10, 27, 38, 43, 82]
6. 快速排序
- 通俗解释:选一个基准数(比如第一个),把比它小的放左边,比它大的放右边,然后左右递归重复。软考最常考。
- 时间复杂度:平均 O(n log n),最坏 O(n²)(基准选不好时,如已有序数组)
- 空间复杂度:O(log n)(递归栈)
JavaScript 实现(经典版本)
js
function quickSort(arr) {
// 基线条件:空数组或单元素数组已有序
if (arr.length <= 1) {
return arr;
}
// 选择基准(这里选中间元素,避免最坏情况)
const pivotIndex = Math.floor(arr.length / 2);
const pivot = arr[pivotIndex];
const left = []; // 小于 pivot 的元素
const right = []; // 大于 pivot 的元素
const equal = []; // 等于 pivot 的元素(处理重复值)
for (let element of arr) {
if (element < pivot) {
left.push(element);
} else if (element > pivot) {
right.push(element);
} else {
equal.push(element);
}
}
// 递归排序左右部分,并合并
return [...quickSort(left), ...equal, ...quickSort(right)];
}
// 示例
const data = [3, 6, 8, 10, 1, 2, 1];
console.log("原数组:", data);
console.log("快排结果:", quickSort(data));输出:
原数组: [3, 6, 8, 10, 1, 2, 1]
快排结果: [1, 1, 2, 3, 6, 8, 10]实际场景中,快速排序是综合最快的,但最坏情况要注意。
三、特殊场景类(有条件限制)
7. 堆排序
- 通俗解释:把数组看成完全二叉树,先建一个"堆"(父节点大于子节点),然后不断把堆顶(最大值)取出,调整剩余部分。
- 时间复杂度:始终 O(n log n)
- 空间复杂度:O(1)
堆排序的核心思想是:把数组想象成一棵完全二叉树,然后不断把最大值移到数组末尾。
通俗理解(3 步走)
假设数组是:[4, 10, 3, 5, 1]
第 1 步:把数组看成树
数组下标对应树的节点:
4(0)
/ \
10(1) 3(2)
/ \
5(3) 1(4)规则:父节点下标 i,左孩子 = 2*i+1,右孩子 = 2*i+2
第 2 步:建一个大顶堆
大顶堆:每个父节点 ≥ 子节点
调整过程(从最后一个非叶子节点开始):
- 节点 10(下标1):比孩子 5 和 1 大,不用动
- 节点 4(下标0):比 10 小,和 10 交换,得到
[10, 4, 3, 5, 1] - 但 4 换下去后比孩子 5 小,继续和 5 交换 →
[10, 5, 3, 4, 1]
建堆完成:堆顶 10 是最大值
第 3 步:重复"交换 + 调整"
- 堆顶 10 和末尾 1 交换:
[1, 5, 3, 4, 10],10 已归位 - 调整剩余
[1, 5, 3, 4]重新成堆 - 再把堆顶(当前最大)换到末尾
- 重复直到全部有序
最终得到 [1, 3, 4, 5, 10]
关键点图解(记这个就够了)
数组: [4, 10, 3, 5, 1]
建堆后: [10, 5, 3, 4, 1]
↑堆顶最大
第1次交换: [1, 5, 3, 4 | 10]
调整: [5, 4, 3, 1 | 10]
第2次交换: [1, 4, 3 | 5, 10]
调整: [4, 1, 3 | 5, 10]
第3次交换: [3, 1 | 4, 5, 10]
调整: [3, 1 | 4, 5, 10]
第4次交换: [1 | 3, 4, 5, 10]
完成: [1, 3, 4, 5, 10]竖线 | 左边是未排序区,右边是已排序区
8. 计数排序
- 通俗解释:类似统计身高频次。适合整数且范围不大。开个数组记录每个值出现次数,然后按顺序输出。
- 时间复杂度:O(n + k)(k 是数值范围)
- 空间复杂度:O(k)
9. 基数排序
- 通俗解释:先按个位排序,再按十位、百位... 像整理卡片时按最后一位数字分桶。
- 时间复杂度:O(d * (n + r))(d 是位数,r 是基数)
- 空间复杂度:O(n + r)
10. 桶排序
- 通俗解释:把数值范围分成几个桶,每个桶内再排序,最后合并。
- 时间复杂度:平均 O(n + k),最坏 O(n²)
- 空间复杂度:O(n + k)
四、软考常见考点(背一下)
- 稳定 vs 不稳定 :冒泡、插入、归并、计数、基数、桶是稳定 ;选择、希尔、快速、堆是不稳定。
- 最好情况 O(n) 的:冒泡、插入(已有序时)。
- 空间 O(1) 的:冒泡、选择、插入、希尔、堆。
- 最常考手写 :快速排序 (划分过程)、冒泡排序 、归并排序。
如果你需要,我可以给你一张 "一句话总结 + 表格速查图" 方便考前记忆。
软考案例分析
1.结构化开发方法
- 核心特征:面向数据流的传统方法,以数据流为中心构建分析模型和设计模型,采用"自顶向下,逐层分解"思想
- 完整流程:包含结构化分析(SA)、结构化设计(SD)和结构化程序设计(SPD)三个阶段
- 语言对应:结构化程序设计使用C语言,面向对象程序设计使用C++/Java
- 分析产出:
- 三大模型:功能模型(数据流图)、行为模型(状态转换图)、数据模型(ER图)
- 补充材料:数据词典、加工逻辑说明(小说明)、补充资料
数据流图DFD
基本图形元素:外部实体、加工、数据存储、数据流
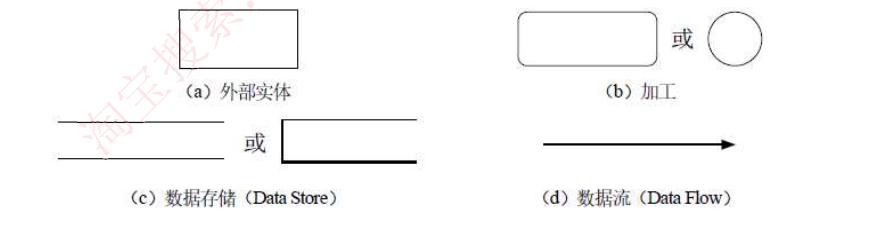
1)数据流:由一组固定成分的数据组成,表示数据的流向在DFD 中,数据流的流向必须经过加工。
2)加工:描述了输入数据流到输出数据流之间的变换,数据流图中常见的三种错误如图所示
- 加工3.1.2 有输入但是没有输出,称之为"黑洞
- 加工3.1.3 有输出但没有输入。称之为"奇迹"
- 加工3.1.1 中输入不足以产生输出,我们称之为"灰洞"
3)数据存储:用来存储数据
4)外部实体(外部主体):是指存在于软件系统之外的人员或组织或事物,它指出系统所需数据的发源地(源) 和系统所产生的数据的归宿地(宿)
数据流图描述了系统的分解,但没有对图中各成分进行说明。数据字典就是为数据流图中的每个数据流、文件、加工,以及组成数据流或文件的数据项做出说明。
数据字典有以下4 类条目: 数据流、数据项、数据存储和基本加工
┌─────────────────────────────────────┐
│ 数据流图(DFD) │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ 输 │────→│ 加 │────→│ 输 │ │
│ │ 入 │ │ 工 │ │ 出 │ │
│ └─────┘ └─────┘ └─────┘ │
│ ↓ │
└──────────────────┼──────────────────┘
↓
┌─────────────────────────────────────┐
│ 加工逻辑描述(小说明) │
│ IF 条件1 THEN │
│ 执行操作A │
│ ELSE IF 条件2 THEN │
│ 执行操作B │
│ ENDIF │
└─────────────────────────────────────┘解题技巧详解
- 补充外部实体
- 查找位置:在顶层图中寻找,因为外部实体只出现在顶层图
- 识别方法:外部实体是与系统交互的名词,可以是大型系统、公司部门或相关人员
- 解题步骤:
- 阅读题目描述
- 在顶层图中标出所有与系统交互的名词
- 根据事件流名称匹配题目描述
- 使用题目中给出的外部实体名称作答
- 补充数据存储
- 查找位置:在0层图中寻找,因为数据存储只出现在0层图
- 判断依据:通过数据存储的
输入输出数据流判断其内容 - 示例:若流入"学生表"的是学生信息,流出的也是学生信息
- 命名原则:优先使用题目说明的数据存储名词,若无则自行命名但需保持命名一致性
- 补充缺失数据流
- 核心方法:详细阅读题目描述,找出"数据流动"名词,从哪里来到哪里去,逐条核对数据流图
- 效率建议:直接核对题目描述,无需先考虑数据守恒、父图子图平衡等原则
- 验证过程:阅读一条题目描述,在数据流图中标记对应数据流,找出缺失项
2.数据库分析
- 用
E-R图来描述概念数据模型,世界是由一组称作实体的基本对象和这些对象
之间的联系构成的。 - 在E-R模型中,使用椭圆表示属性(一般没有),长方形表示实体、菱形表示联系,联系的两端要填写联系类型,示例如下图:
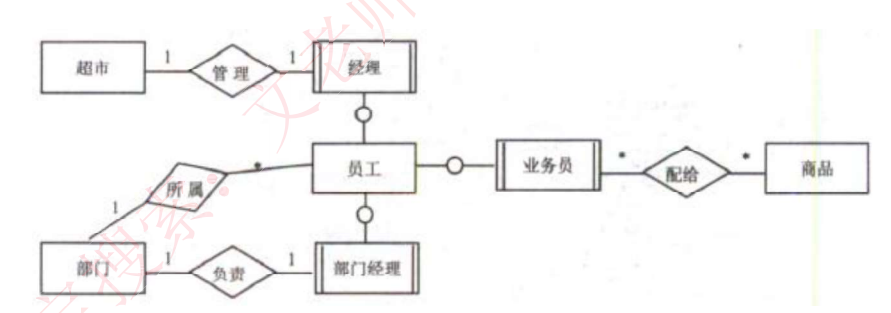
1.补充联系和联系类型:
- 基本元素:
- 长方形表示实体
- 菱形表示联系
- 椭圆表示属性
- 联系类型:
- 一对一(1:1)
- 一对多(1:N)
- 多对多(M:N)
- 特殊关系:
- 实体和弱实体:用直线连接,是从属关系,无联系类型
- 主键和外键:主键是本关系内唯一,外键是其他关系的主键,外键可以有多个
- 解题技巧:
- 联系类型判断:大多数情况下题目只会给出一个方面的描述,需要根据常识判断
- 弱实体识别:弱实体是依赖于强实体存在的,通过箭头表示
- 多实体联系:最多考到三个实体之间的联系,根据题目说明判断
2.关系模式,属性补充:
- 属性补充:
- 题目会给出部分属性,需要补充缺失的属性
- 补充时需要根据题目描述和E-R图转换关系模型规则
- 基本规则:每个实体都要转换为一个关系模式(表)
- 联系转换:
- 一对一:联系作为一个属性随便加入哪个实体中
- 一对多:
- 可以单独转换为一个关系模式
- 也可以作为一个属性加入到N端中(N端实体包含1端的主键)
- 通常考试中不考单独转换的情况
- 多对多:联系必须单独转换为一个关系模式(包含两端实体的主键)
- 注意事项:
- 转换后两个实体之间的联系必须还存在,能够通过查询方式查到对方
- 一对多联系转换时,应将一端的组件加到N端,避免数据冗余
- 主键:
- 不能为空
- 能唯一标识当前关系的属性
- 题目可能不会直接给出,需要根据常识判断
- 外键:
- 其他关系模式的主键
- 可以为空
- 可以有多个
3.解题技巧
- 三步解题法:
- 补充E-R图:根据题目描述确认实体之间的联系和联系类型
- 补充关系模式:
- 先根据题目描述补充属性
- 再按照E-R图转换规则补充缺失的属性
- 情景问答:新增实体-联系类型和关系模式
- 重点提示:
- E-R图补充错误会影响后续题目
- 关系模式补充时要注意一对多和多对多的转换规则
- 多对多联系必须单独转换为一个关系模式
3.面向对象
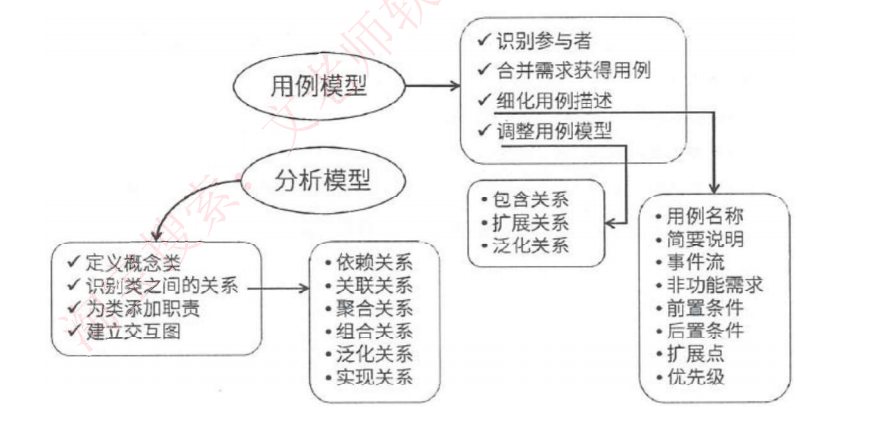
面向对象需求建模的两种模型
-
模型对比:
- 用例模型:描述系统功能需求(对应结构化方法中的功能模型)
- 分析模型:描述系统数据结构(对应结构化方法中的数据模型)
-
结构化对比:
- 数据模型:E-R图
- 行为模型:状态转换图
- 功能模型:数据流图
-
面向对象分析设计定义:需求分析和设计阶段的工作,与面向对象程序设计(编码阶段)不同
-
UML建模工具:面向对象建模使用UML图,结构化建模用数据流图,数据库建模用ER图
-
常考UML图类型:类图、用例图(最常考)、状态图(偶尔考)
-
考试重点:图之间的关系,特别是类图和用例图的组合考察
3.1 用例图
用例图:静态图,展现了一组用例、参与者以及它们之间的关系。用例图中的参与者是人、硬件或其他系统可以扮演的角色;用例是参与者完成的一系列操作,用例之间的关系有扩展、包含、泛化。如下:
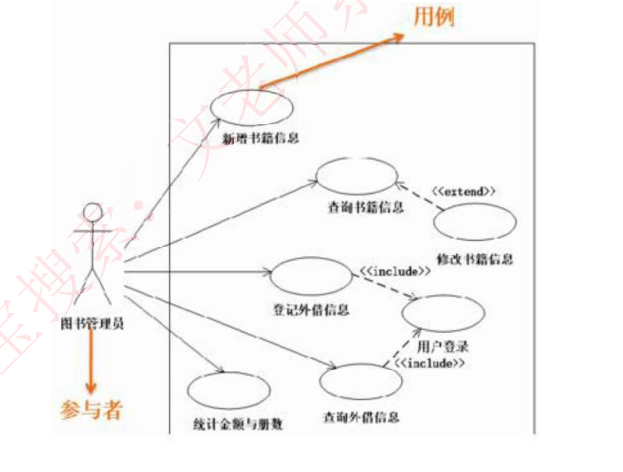
-
参与者
- 本质定义: 与系统交互的人、硬件或外部系统角色
- 识别特征:
- 名词性实体(如图书管理员)
- 参与系统交互过程
- 典型示例: 图书馆管理系统中的"图书管理员"参与者
-
用例
- 核心概念: 参与者完成的系列操作,对应系统功能
- 表现形式:
- 椭圆图形表示(如"新增书籍信息")
- 可理解为加工过程或功能模块
- 建模要点: 每个参与者对应多个用例(如管理员可进行查询、登记等操作)
-
用例之间的关系
-
箭头方向别搞反:
- 包含:基 → 包含用例
- 扩展:扩展 → 基
- 泛化:子 → 父
-
包含 ≠ 扩展:包含是"必须做",扩展是"可做可不做"
-
泛化用空心三角箭头 ,不是
<<extends>>
-
3.2 类图
- 类图解题技巧:
- 类图空置问题:学员面对空类图时容易困惑,需关注类与类之间的联系。
- 类图考点:类名称、类之间的关系(泛化、组合、聚合)、多重度(较少考)。
- 泛化关系:父子关系最重要,需通过图形符号判断。
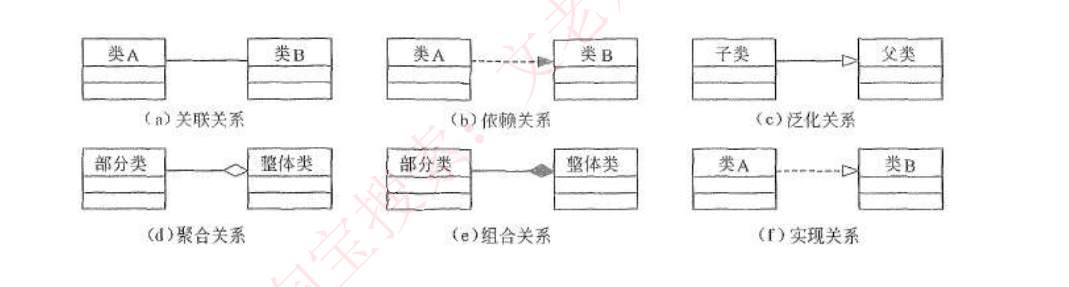
uml关系:依赖 <关联 <聚合 <组合 < 实现 =泛化(关系的强弱)
- 依赖关系
- 定义:一个事物的语义依赖于另一个事物的语义变化而变化
- 图形表示:虚线加实心箭头
- 举例:人类依赖于空气和水生存,当空气和水变化时,人类状态也会变化
- 关联关系
- 定义:结构关系,描述对象之间的连接,如老师与学生,丈夫与妻子
- 图形表示:一条直线(可能带有数字表示多重度)
- 特殊类型:
- 聚合:部分和整体关系,生命周期不绑定(空心菱形)
- 举例:雁群和大雁,大雁可以脱离雁群
- 组合:更强的部分和整体关系,具有共同生命周期(实心菱形)
- 举例:人和大脑,人不存在时大脑也不存在
- 泛化关系
- 定义:一般/特殊关系,即父类和子类关系
- 图形表示:实线加空心箭头
- 举例:学生(一般)与研究生(特殊)、图书(一般)与教材(特殊)
- 实现关系
- 定义:一个类元实现另一个类元定义的契约
- 图形表示:虚线加空心箭头
- 代码对应:类实现接口的关系
4.设计模式
Java基础语法与类定义
1.1 类的基本结构
- 定义关键字 :
class(如class Dog) - 访问修饰符 :
public(公有权限) - 成员组成 :
- 变量 :定义属性 (如
String breed) - 方法 :定义行为 (如
void hungry())
- 变量 :定义属性 (如
- 作用域 :所有成员需包含在
{}内。
1.2 构造方法 (Constructor)
- 命名规则:必须与类名完全相同(区分大小写)。
- 特性 :
- 无返回值类型声明。
- 可重载(通过参数个数/类型区分)。
- 创建对象时自动调用。
- 默认构造:未显式定义时,编译器自动生成无参构造方法。
1.3 创建对象
- 步骤 :
- 声明 :指定类型和名称 (如
Puppy myPuppy)。 - 实例化 :使用
new关键字分配内存。 - 初始化:自动调用匹配的构造方法。
- 声明 :指定类型和名称 (如
- 关键点 :
new是唯一创建对象的方式。
1.4 访问实例变量和方法
- 主函数 :
public static void main(String[] args)是程序唯一入口。 - 封装原则 :
- 推荐使用
setAge()和getAge()方法访问成员变量。 - 避免直接访问(违反封装性,特别是
private变量)。
- 推荐使用
this关键字 :当参数与成员变量同名时,使用this.puppyAge明确指定成员变量。
1.访问权限
| 访问修饰符 | 同一个包内 | 不同包的子类 | 不同包的非子类 |
|---|---|---|---|
public |
✅ 允许 | ✅ 允许 | ✅ 允许 |
protected |
✅ 允许 | ✅ 允许 | ❌ 不允许 |
| 包访问权限 (default) | ✅ 允许 | ❌ 不允许 | ❌ 不允许 |
private |
❌ 不允许 | ❌ 不允许 | ❌ 不允许 |
在普通类中不加修饰符默认是包访问权限,而在接口中不加修饰符默认才是 public。
public interface UserService {
// 规范写法:等价于 public abstract void save();
void save();
}- 包访问权限(default):不加任何修饰符,权限仅限于同一个包内。
跨包调用默认修饰的方法 StringHelper.trimAllWhitespace() 会直接报错
- protected:需要显式加上 protected 关键字,权限不仅包含同一个包内,还额外开放给了不同包的子类。
| 访问修饰符 | 同一个包内 | 不同包的子类 | 不同包的非子类 |
|---|---|---|---|
| 包访问权限 (default) | ✅ 允许 | ❌ 不允许 | ❌ 不允许 |
protected |
✅ 允许 | ✅ 允许 | ❌ 不允许 |
"不同包的子类"在 Java 中指的是:一个类(子类)通过 extends 关键字继承了另一个包中的父类,并且这两个类位于不同的包(package)目录下。
- 父类 Animal 在不同修饰符下的情况
java
package com.animal;
public class Animal {
public void eatPublic() { System.out.println("public"); } // 1. public
protected void eatProtected() { System.out.println("protected"); } // 2. protected
void eatDefault() { System.out.println("default"); } // 3. 默认(包访问权限)
private void eatPrivate() { System.out.println("private"); } // 4. private
}- 不同包的子类 Dog 的访问测试结果
java
package com.pet;
import com.animal.Animal;
public class Dog extends Animal {
public void testAccess() {
// ✅ 1. public:任何地方都能访问,毫无限制
this.eatPublic();
// ✅ 2. protected:专门开放给跨包子类访问的
this.eatProtected();
// ❌ 3. 默认(default):权限被限制在 com.animal 包内,跨包无法访问
// this.eatDefault(); // 编译报错!
// ❌ 4. private:仅限父类自己内部使用,子类完全不可见
// this.eatPrivate(); // 编译报错!
}
}3.继承,实现
- 继承规则 :
- 父类
public方法在子类必须保持public。 - 父类
protected方法可保持protected或改为public,但不能改为private。 - 父类
private方法不能被继承。
- 父类
2.2 抽象类 (Abstract Class)
- 定义 :使用
abstract关键字修饰,不能实例化。 - 抽象方法 :
- 只有声明没有实现(以分号结尾,如
public abstract sample();)。 - 包含抽象方法的类必须声明为抽象类。
- 只有声明没有实现(以分号结尾,如
- 实现:子类必须实现父类所有抽象方法(除非子类也是抽象类)。
2.3 继承与接口 (Inheritance & Interface)
- 继承 (extends) :
- Java是单继承,一个子类只能
extends一个父类。 - 子类拥有父类非
private的属性和方法。 - 方法重写 (Override):子类用自己方式实现父类方法。
- Java是单继承,一个子类只能
- 接口 (implements) :
- 使用
interface关键字定义。 - 接口方法默认是抽象方法(无需加
abstract)。 - 接口变量通常是常量 (
public static final)。 - 多继承实现 :一个类可以
implements多个接口。
- 使用
java
// 父类
class Animal {
public void eat() {
System.out.println("动物在吃东西");
}
}
// 子类
class Dog extends Animal {
// 重写父类的 eat 方法
@Override
public void eat() {
System.out.println("狗在啃骨头");
}
}
public class Test {
public static void main(String[] args) {
// 向上转型:子类对象赋值给父类引用
Animal myPet = new Dog();
// 实现多态:编译看左边(Animal),运行看右边(Dog)
// 虽然 myPet 声明为 Animal 类型,但实际指向的是 Dog 对象
// 所以这里会调用 Dog 类中重写后的 eat 方法
myPet.eat(); // 最终输出结果:狗在啃骨头
}
}多态的实际含义:是同一操作作用于不同的对象上面,可以产生不同的解释和不同的执行结果。换句话说,给不同的对象发送同一个消息的时候,这些对象会根据这个消息分别给出不同的反馈。
对面向对象来说,多态分为编译时多态和运行时多态。其中编译时多态是静态的,主要是指方法的重载,它是根据参数列表的不同来区分不同的方法。通过编译之后会变成两个不同的方法,在运行时谈不上多态。而运行时多态是动态的,它是通过动态绑定来实现的,也就是大家通常所说的多态性。
java 实现多态有 3 个必要条件:继承、重写和向上转型
4.命令模式
- 命令接口(Command):定义执行请求的统一接口,通常包含一个 execute() 方法,有时还会包含 undo()(撤销)方法。
- 具体命令(ConcreteCommand):实现命令接口。它内部会持有一个"接收者"的引用,并在 execute() 方法中调用接收者的具体业务方法。
- 接收者(Receiver):真正执行业务逻辑的对象(比如开灯、炒菜、保存文件)。
- 调用者(Invoker):请求的触发者(比如遥控器按钮、菜单项)。它持有命令对象,并在合适的时机调用命令的 execute() 方法,但它完全不知道命令具体是如何执行的。
- 客户端(Client):负责组装。它创建具体的接收者和具体的命令,将接收者绑定到命令中,最后把命令交给调用者。
java
// 1. 接收者(Receiver):真正执行具体业务的对象
class Light {
public void turnOn() {
System.out.println("灯光已打开");
}
public void turnOff() {
System.out.println("灯光已关闭");
}
}
// 2. 命令接口(Command):定义统一的执行与撤销方法
interface Command {
void execute();
void undo();
}
// 3. 具体命令(ConcreteCommand):开灯命令
class LightOnCommand implements Command {
private Light light; // 持有接收者的引用
public LightOnCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.turnOn(); // 调用接收者的具体方法
}
@Override
public void undo() {
light.turnOff(); // 撤销操作:关灯
}
}
// 4. 具体命令(ConcreteCommand):关灯命令
class LightOffCommand implements Command {
private Light light;
public LightOffCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.turnOff();
}
@Override
public void undo() {
light.turnOn(); // 撤销操作:开灯
}
}
// 5. 调用者(Invoker):遥控器
class RemoteControl {
private Command command;
private Command lastCommand; // 记录上一次执行的命令,用于撤销
public void setCommand(Command command) {
this.command = command;
}
public void pressButton() {
if (command != null) {
command.execute();
lastCommand = command; // 保存当前命令
}
}
public void pressUndo() {
if (lastCommand != null) {
lastCommand.undo();
}
}
}
// 6. 客户端(Client):负责组装与测试
public class CommandPatternDemo {
public static void main(String[] args) {
// 创建接收者(电灯)
Light livingRoomLight = new Light();
// 创建具体命令,并绑定接收者
Command lightOn = new LightOnCommand(livingRoomLight);
Command lightOff = new LightOffCommand(livingRoomLight);
// 创建调用者(遥控器)
RemoteControl remote = new RemoteControl();
// 按下开灯按钮
remote.setCommand(lightOn);
remote.pressButton(); // 输出:灯光已打开
// 按下关灯按钮
remote.setCommand(lightOff);
remote.pressButton(); // 输出:灯光已关闭
// 按下撤销按钮
remote.pressUndo(); // 输出:灯光已打开
}
}5.观察者模式
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象(被观察者),当主题对象状态发生改变时,它会自动通知所有观察者并触发更新。
- 抽象主题(Subject / 被观察者):负责维护观察者列表,提供订阅(attach)、取消订阅(detach)和批量通知(notify)的抽象方法。
- 具体主题(Concrete Subject):具体的被观察者(如"某技术公众号")。当它的内部状态改变时,会触发通知方法,向所有观察者发送消息。
- 抽象观察者(Observer):定义一个统一的更新接口(如 update()),接收被观察者的通知。
- 具体观察者(Concrete Observer):具体的观察者(如"订阅该公众号的用户")。实现更新接口,自定义收到通知后的业务逻辑(比如弹出提醒、发送邮件等)。
java
import java.util.ArrayList;
import java.util.List;
// 1. 抽象观察者接口
interface Observer {
void update(String message);
}
// 2. 抽象主题(被观察者)
abstract class Subject {
// 维护观察者列表
protected List<Observer> observerList = new ArrayList<>();
// 订阅
public void attach(Observer observer) {
observerList.add(observer);
}
// 取消订阅
public void detach(Observer observer) {
observerList.remove(observer);
}
// 通知所有观察者
public void notifyObservers(String message) {
for (Observer observer : observerList) {
observer.update(message);
}
}
}
// 3. 具体主题(技术公众号)
class TechOfficialAccount extends Subject {
private String latestArticle;
public void publishArticle(String article) {
this.latestArticle = article;
System.out.println("【公众号】发布了新文章:" + article);
// 状态改变,触发通知
notifyObservers(latestArticle);
}
}
// 4. 具体观察者(邮件订阅用户)
class EmailSubscriber implements Observer {
private String name;
public EmailSubscriber(String name) { this.name = name; }
@Override
public void update(String message) {
System.out.println(" -> [邮件] 通知 " + name + ":您订阅的文章已更新 -> " + message);
}
}
// 5. 具体观察者(短信订阅用户)
class SmsSubscriber implements Observer {
private String phone;
public SmsSubscriber(String phone) { this.phone = phone; }
@Override
public void update(String message) {
System.out.println(" -> [短信] 通知 " + phone + ":您订阅的文章已更新 -> " + message);
}
}
// 6. 客户端调用
public class ObserverPatternDemo {
public static void main(String[] args) {
// 创建被观察者(公众号)
TechOfficialAccount account = new TechOfficialAccount();
// 创建观察者(订阅用户)
Observer emailUser = new EmailSubscriber("张三");
Observer smsUser = new SmsSubscriber("13800138000");
// 用户订阅公众号
account.attach(emailUser);
account.attach(smsUser);
// 公众号发布文章,所有订阅者自动收到通知
account.publishArticle("《深入理解Java观察者模式》");
System.out.println("-------------------");
// 短信用户取消订阅
account.detach(smsUser);
account.publishArticle("《设计模式实战:如何优雅地解耦》");
}
}6.工厂方法模式和抽象工厂模式
工厂方法模式
定义一个工厂接口 ,每个子工厂 负责生产一种具体产品。
-
遵循:一个工厂只造一个产品
-
有抽象产品、抽象工厂、具体产品、具体工厂
-
满足开闭:加新产品,就加一个产品类 + 一个工厂类,不改老代码
-
模式的结构
- 抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法 newProduct()来创建产品。
- 具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
java
/**
* @author tbb
* 汽车工厂
*/
public interface CarFactory
{
Car produceCar();
}
/**
* @author tbb
* 汽车模型
*/
public interface Car
{
/**
* 品牌
*/
void brand();
}
/**
* @author tbb
* 奔驰汽车工厂
*/
public class BenzCarFactory implements CarFactory
{
@Override
public Car produceCar()
{
return new BenzCar();
}
}
/**
* @author tbb
* 奥迪汽车工厂
*/
public class AudiCarFactory implements CarFactory
{
@Override
public Car produceCar()
{
return new AudiCar();
}
}
/**
* @author tbb
* 奔驰汽车
*/
public class BenzCar implements Car{
@Override
public void brand()
{
System.out.println("奔驰");
}
}
/**
* @author tbb
* 奥迪汽车
*/
public class AudiCar implements Car{
@Override
public void brand()
{
System.out.println("奥迪");
}
}
public class Test
{
public static void main(String[] args)
{
//客户想要买奔驰车
BenzCarFactory benzCarFactory = new BenzCarFactory();
benzCarFactory.produceCar().brand();//奔驰
}
}抽象工厂模式: 在代码设计层面,抽象工厂模式的结构同工厂方法模式的结构相似,不同的是其产品的种类不止一个,所以创建产品的方法也不止一个,所以只要增加创建不同种产品的方法,就可以实现抽象工厂模式
- 工厂方法模式 :有抽象工厂+抽象产品,一个工厂只生产一个产品。
- 抽象工厂模式 :有抽象工厂+多个抽象产品,一个工厂生产一整套关联产品。
java
/**
* @author tbb
* 工厂产品族接口类
*/
public interface Factory
{
WashingMachine createWashingMachine();
Refrigerator createRefrigerator();
}
/**
* @author tbb
* 海尔工厂产品族类
*/
public class HaierFactory implements Factory
{
@Override
public WashingMachine createWashingMachine()
{
return new HaierWashingMachine();
}
@Override
public Refrigerator createRefrigerator()
{
return new HaierRefrigerator();
}
}
/**
* @author tbb
* TCL工厂产品族类
*/
public class TCLFactory implements Factory {
@Override
public WashingMachine createWashingMachine()
{
return new TCLWashingMachine();
}
@Override
public Refrigerator createRefrigerator()
{
return new TCLRefrigerator();
}
}
/**
* @author tbb
* 冰箱接口类
*/
public interface Refrigerator
{
void brand();
}
/**
* @author tbb
* 洗衣机接口类
*/
public interface WashingMachine
{
/**
* 品牌
*/
void brand();
}
/**
* @author tbb
* 海尔品牌冰箱类
*/
public class HaierRefrigerator implements Refrigerator {
@Override
public void brand()
{
System.out.println("海尔品牌冰箱");
}
}
/**
* @author tbb
* 海尔品牌洗衣机类
*/
public class HaierWashingMachine implements WashingMachine{
@Override
public void brand()
{
System.out.println("海尔品牌洗衣机");
}
}
/**
* @author tbb
* TCL品牌冰箱类
*/
public class TCLRefrigerator implements Refrigerator{
@Override
public void brand() {
System.out.println("TCL品牌冰箱");
}
}
/**
* @author tbb
* TCL品牌洗衣机类
*/
public class TCLWashingMachine implements WashingMachine{
@Override
public void brand() {
System.out.println("TCL品牌洗衣机");
}
}
public class Test
{
public static void main(String[] args)
{
//客户想要Haier 品牌的 洗衣机和冰箱
HaierFactory haierFactory = new HaierFactory();
WashingMachine haierWashingMachine = haierFactory.createWashingMachine();
haierWashingMachine.brand();//海尔品牌洗衣机
Refrigerator refrigerator = haierFactory.createRefrigerator();
refrigerator.brand();//海尔品牌冰箱
}
}7.备忘录
在动手写代码前,我们先明确备忘录模式中的三个关键角色:
- 发起人(Originator):需要被保存状态的实际业务对象(比如文本编辑器、游戏角色)。它负责创建一个包含其当前内部状态的备忘录,并能使用这个备忘录来恢复自身状态。
- 备忘录(Memento):一个纯粹的"状态快照"载体。它负责存储 Originator 的内部状态,并且严格防止 Originator 以外的任何对象访问或修改它。
- 负责人(Caretaker):备忘录的管理者(比如历史记录管理器)。它负责保存和管理备忘录对象,但对备忘录的内部内容一无所知,只能像保管"黑盒子"一样将其传递给发起人进行恢复。
java
// 备忘录:仅存状态
public class Memento {
private String state;
public Memento(String state) {
this.state = state;
}
public String getState() {
return state;
}
}
// 发起人:自身状态 + 创建备忘录 + 恢复状态
public class Originator {
private String state;
// 生成备忘录保存当前状态
public Memento saveStateToMemento() {
return new Memento(state);
}
// 从备忘录恢复状态
public void getStateFromMemento(Memento memento) {
this.state = memento.getState();
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
}
// 管理者:只管存备忘录,不读不改状态
import java.util.ArrayList;
import java.util.List;
public class Caretaker {
// 存放所有历史备忘录
private List<Memento> mementoList = new ArrayList<>();
// 添加存档
public void addMemento(Memento memento) {
mementoList.add(memento);
}
// 根据下标获取指定历史存档
public Memento getMemento(int index) {
return mementoList.get(index);
}
// 获取存档总数
public int getSaveCount(){
return mementoList.size();
}
}
//测试调用
public class Client {
public static void main(String[] args) {
Originator game = new Originator();
Caretaker record = new Caretaker();
// 状态1 存档
game.setState("血量满,装备齐全");
record.addMemento(game.saveStateToMemento());
// 状态2 存档
game.setState("残血,战斗中");
record.addMemento(game.saveStateToMemento());
// 状态3 存档
game.setState("战败倒地");
record.addMemento(game.saveStateToMemento());
// 回溯恢复第1个存档
game.getStateFromMemento(record.getMemento(0));
System.out.println("恢复存档1:" + game.getState());
// 回溯恢复第2个存档
game.getStateFromMemento(record.getMemento(1));
System.out.println("恢复存档2:" + game.getState());
}
}8.代理模式
在代理模式中,主要包含三个核心角色:
- 抽象主题(Subject)
角色定位:定义了一套"标准"或"契约",规定了代理对象和真实对象都能做哪些事情。
代码体现:通常是一个 Java 接口(Interface)或抽象类。
生活类比:明星的演艺合同。合同里明确规定了"明星"这个角色需要完成拍戏、唱歌等工作。无论是明星本人,还是经纪人代为出面,都必须遵循这份合同里的约定。 - 真实主题(RealSubject / Target)
角色定位:真正负责执行业务逻辑、干实事的对象,也就是我们最终想要调用的"真身"。
代码体现:实现了抽象主题接口的具体类(例如上一轮代码中的 UserServiceImpl)。
生活类比:明星本人。他/她是真正拥有演技和歌喉,负责在镜头前完成核心表演工作的人。 - 代理(Proxy)
角色定位:明星的"替身"或"中介"。它对外提供与真实主题相同的接口,内部持有真实主题的引用。它的核心作用是在调用真实主题的前后,加入一些额外的控制或增强逻辑(如权限校验、日志记录、事务管理等)。
代码体现:同样实现了抽象主题接口,并在内部封装了真实主题对象的类(例如上一轮代码中的 UserServiceProxy 或 JDK 动态生成的 $Proxy 类)。
生活类比:明星经纪人。外界(客户端)想联系明星拍戏,必须先找经纪人。经纪人会在明星正式拍戏前负责谈合同、挡记者(前置处理),拍完戏后负责收尾款(后置处理),最后才让明星本人去专注表演。
Java 示例:
java
// 1. 抽象主题(合同 Subject):规定了明星需要完成的工作
interface StarContract {
void perform(); // 核心表演任务
}
// 2. 真实主题(明星本人 RealSubject):只专注于核心表演
class SuperStar implements StarContract {
private String name;
public SuperStar(String name) {
this.name = name;
}
@Override
public void perform() {
System.out.println("🌟 " + name + " 正在聚光灯下全情投入地飙戏!");
}
}
// 3. 代理(经纪人 Proxy):处理杂事,并持有明星本人的引用
class Agent implements StarContract {
private SuperStar superStar; // 经纪人手里握着自家明星的档期
public Agent(SuperStar superStar) {
this.superStar = superStar;
}
@Override
public void perform() {
// 【前置处理】经纪人处理杂事
System.out.println("📞 经纪人:正在与剧组对接合同细节,并确认出场费已到账...");
System.out.println("🛡️ 经纪人:正在驱赶门口的狗仔队,为明星清场...");
// 经纪人安排明星本人进行核心表演
superStar.perform();
// 【后置处理】经纪人收尾
System.out.println("💰 经纪人:表演结束,正在收取尾款并安排保姆车送明星离开。");
}
}
// 4. 客户端(客户 Client):拿着合同去找经纪人
public class Client {
public static void main(String[] args) {
// 剧组(客户端)想请一位叫"张三"的超级明星
SuperStar zhangSan = new SuperStar("张三");
// 剧组不能直接找明星,必须先找到他的经纪人(创建代理对象)
Agent agent = new Agent(zhangSan);
// 剧组拿着"合同"(接口)去调用经纪人的 perform 方法
System.out.println("--- 剧组联系经纪人要求安排表演 ---");
agent.perform();
}
}9.单例模式
单例模式(Singleton Pattern)是 Java 中最经典、最基础的设计模式之一。它的核心目标非常简单:确保一个类在任何情况下都绝对只有一个实例,并提供一个全局的访问点。
为了让你更直观地理解,我们可以打个生活中的比方:一个国家的"总统"或一家公司的"CEO"。
在一个国家或公司里,总统/CEO 只能有一个。无论谁(政府机关、公司员工、新闻媒体)需要找总统/CEO 签字或下达指令,找到的都必须是同一个人,不能凭空变出第二个"总统"来。
在 Java 代码中,要实现这个目标,必须满足三个硬性条件:
- 私有化构造方法:防止外部通过 new 关键字随意创建对象。
- 内部持有唯一实例:在类的内部自己偷偷 new 一个唯一的实例存起来。
- 提供全局访问点:对外提供一个公共的静态方法(通常叫 getInstance()),让外界能获取到这个唯一的实例。
- 饿汉式
java
public class HungrySingleton {
// 1. 在类加载时,直接创建唯一的静态实例
private static final HungrySingleton INSTANCE = new HungrySingleton();
// 2. 私有化构造方法,禁止外部通过 new 创建对象
private HungrySingleton() {}
// 3. 提供全局公共的静态方法,供外部获取唯一的实例
public static HungrySingleton getInstance() {
return INSTANCE;
}
}- 双重检查锁定(DCL - Double Checked Locking)
核心思想:为了解决"饿汉式"浪费内存的问题,我们想要"用到时再创建"(懒加载)。但在多线程环境下,简单的懒加载会导致线程安全问题。DCL 通过两次判空 + 加锁,既保证了懒加载,又保证了线程安全和高性能。
java
public class DclSingleton {
// 必须使用 volatile 关键字修饰,防止指令重排序导致多线程下获取到未初始化完成的对象
private static volatile DclSingleton instance;
private DclSingleton() {}
public static DclSingleton getInstance() {
// 第一次检查:如果实例已经存在,直接返回,避免不必要的同步开销
if (instance == null) {
synchronized (DclSingleton.class) {
// 第二次检查:防止多个线程同时通过第一次检查后,重复创建实例
if (instance == null) {
instance = new DclSingleton();
}
}
}
return instance;
}
}- 静态内部类(Static Inner Class)
核心思想:这是最推荐的懒加载单例写法。它巧妙地利用了 Java 类加载机制的特性:外部类加载时,不会主动加载内部类。只有当真正调用 getInstance() 方法时,才会去加载内部类并初始化实例。
java
public class StaticInnerSingleton {
private StaticInnerSingleton() {}
// 静态内部类:只有被主动使用时才会被加载
private static class SingletonHolder {
private static final StaticInnerSingleton INSTANCE = new StaticInnerSingleton();
}
public static StaticInnerSingleton getInstance() {
return SingletonHolder.INSTANCE;
}
}| 实现方式 | 线程安全 | 懒加载 | 优缺点总结 |
|---|---|---|---|
| 饿汉式 | 是 | 否 | 写法最简单,但可能造成内存浪费 |
| 双重检查锁定(DCL) | 是 | 是 | 性能高,但代码复杂,需配合 volatile |
| 静态内部类 | 是 | 是 | 最推荐,优雅、安全、高效 |