Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
📄 arXiv: arXiv:2601.12993 | 🏷️ VLA模型 | ⭐ 评分: 9.1/10
🔑 论文笔记 VLA模型 跨本体学习 人为中心学习 具身智能 机器人操作 Flow-Matching MoE 统一动作空间 双臂操作 灵巧手 Being-H0.5 UniHand-2.0 Mixture-of-Flow pi0 pi0.5 OpenVLA AgiBot-World Qwen-VLA
文章目录
- [Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization](#Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization)
-
- 核心信息
- 摘要翻译
- 研究背景与动机
- 研究问题
- 方法概述
- 实验结果
- 深度分析
- 与相关论文对比
-
- 对比论文选择依据
- [Qwen-VLA - Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments](#Qwen-VLA - Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments)
- [π₀ / π₀.5 - Physical Intelligence](#π₀ / π₀.5 - Physical Intelligence)
- [Open X-Embodiment - Robotic Learning Datasets and RT-X Models](#Open X-Embodiment - Robotic Learning Datasets and RT-X Models)
- [AgiBot World Colosseo - A Large-scale Manipulation Platform](#AgiBot World Colosseo - A Large-scale Manipulation Platform)
- 对比总结
- 技术路线定位
- 未来工作建议
- 我的综合评价
- 我的笔记
- 相关论文
- 外部资源
核心信息
- 论文ID:arXiv:2601.12993
- 作者:BeingBeyond Team (Luo Hao, Wang Ye, Zhang Wanpeng, Zheng Sipeng, Xu Ziheng, Xu Chaoyi, Yuan Haiweng, Zhang Haoqi, Zhang Chi, Wang Yiqing, Feng Yicheng, Lu Zongqing et al.)
- 机构:BeingBeyond
- 发布时间:2026-01-19
- 会议/期刊:预印本
- 链接 :arXiv | PDF | 项目页
- VLM骨干:InternVL-3.5
摘要翻译
英文摘要
We introduce Being-H0.5, a foundational Vision-Language-Action (VLA) model designed for robust cross-embodiment generalization across diverse robotic platforms. While existing VLAs often struggle with morphological heterogeneity and data scarcity, we propose a human-centric learning paradigm that treats human interaction traces as a universal "mother tongue" for physical interaction. To support this, we present UniHand-2.0, the largest embodied pre-training recipe to date, comprising over 35,000 hours of multimodal data across 30 distinct robotic embodiments. Our approach introduces a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, enabling low-resource robots to bootstrap skills from human data and high-resource platforms. Built upon this human-centric foundation, we design a unified sequential modeling and multi-task pre-training paradigm to bridge human demonstrations and robotic execution. Architecturally, Being-H0.5 utilizes a Mixture-of-Transformers design featuring a novel Mixture-of-Flow (MoF) framework to decouple shared motor primitives from specialized embodiment-specific experts. Finally, to make cross-embodiment policies stable in the real world, we introduce Manifold-Preserving Gating for robustness under sensory shift and Universal Async Chunking to universalize chunked control across embodiments with different latency and control profiles. We empirically demonstrate that Being-H0.5 achieves state-of-the-art results on simulated benchmarks, such as LIBERO (98.9%) and RoboCasa (53.9%), while also exhibiting strong cross-embodiment capabilities on five robotic platforms.
中文翻译
我们提出了 Being-H0.5,一个面向跨本体泛化的基础视觉-语言-动作(VLA)模型。现有VLA模型在形态异质性和数据稀缺方面常遇到困难,我们提出了一种以人为中心的学习范式,将人类交互轨迹视为物理交互的通用"母语"。为此,我们构建了 UniHand-2.0,这是迄今为止最大的具身预训练方案,包含超过 35,000 小时的多模态数据,覆盖 30 种不同的机器人本体。我们的方法引入了统一动作空间,将异构机器人控制映射到语义对齐的槽位中,使低资源机器人能够从人类数据和高资源平台中引导学习技能。在此以人为中心的基础上,我们设计了统一的序列建模和多任务预训练范式,以桥接人类演示与机器人执行。在架构上,Being-H0.5 采用混合Transformer(MoT)设计,包含新颖的混合流(Mixture-of-Flow, MoF)框架,将共享运动基元与专业化本体特定专家解耦。最后,为使跨本体策略在真实世界中稳定运行,我们引入了流形保持门控(Manifold-Preserving Gating, MPG)以增强感官偏移下的鲁棒性,以及通用异步分块(Universal Async Chunking, UAC)以泛化不同延迟和控制特性的本体间分块控制。实验证明 Being-H0.5 在仿真基准上达到最优结果,如 LIBERO(98.9%)和 RoboCasa(53.9%),同时在五个机器人平台上展现出强大的跨本体能力。
核心要点提炼
- 研究背景:现有VLA模型受限于形态异质性和数据稀缺,无法有效跨本体泛化
- 研究动机:借鉴NLP中多语言预训练的成功,将人类交互视为物理交互的"母语",通过大规模人类数据提供通用物理先验
- 核心方法:以人为中心的统一动作空间 + MoT/MoF架构 + MPG鲁棒门控 + UAC异步分块
- 主要结果:LIBERO 98.9%,RoboCasa 53.9%,5种真实机器人平台部署,首次观察到本体级零样本迁移
- 研究意义:证明了统一动作空间下跨本体联合训练的可行性和优越性,为VLA的通用化提供了新范式
研究背景与动机
领域现状
视觉-语言-动作(VLA)模型是当前通用机器人策略的主流范式,通过微调预训练视觉语言模型来生成机器人控制信号。然而现有VLA面临核心困境:
- "物理鸿沟":不同机器人的动作空间如同不同语言,模型在特定硬件上高度专业化但无法跨形态部署
- 数据稀缺:与NLP中万亿级token不同,机器人领域缺乏大规模示范数据,大多数平台数据极其有限
- 分布偏移:基于简单机器人(如平行夹爪)预训练的扩散VLA在遇到高维灵巧手时,推理轨迹会"漂移"出有效运动流形
现有方法的局限性
- 独立动作头策略(如GR00T-N1):为每个本体分配独立MLP投影层,绕过结构性不对齐问题,但浪费模型容量且阻碍跨本体知识共享
- 潜在动作方法(如LAPA、UniVLA):使用离散编码或连续嵌入表示意图,但缺乏动作级监督,限制了精确控制
- 视频预测方法(如GR-1/2):将视频生成作为理解动力学的代理,但文本规划缺乏物理交互所需的空间精度
- 跨本体预训练争议:Galaxea G0发现跨本体预训练可能有害,GraspVLA证明去OXE预训练反而更好
研究动机
核心洞察:人类交互轨迹是物理交互的通用"母语"。正如不同人类语言共享底层语法(句法和逻辑),不同机器人遵循共同的物理定律。人类运动提供了密集的语义先验,捕捉了因果交互逻辑和接触物理,这些在所有运动学"方言"中保持不变。关键是如何将人类数据和异构机器人数据统一建模。
研究问题
核心研究问题
如何构建一个VLA模型,使其能够:
- 利用大规模人类数据提供通用物理先验
- 将异构机器人控制统一到共享语义空间
- 在单一检查点下实现跨多个本体的有效部署
- 在真实世界中保持稳定和鲁棒的控制
方法概述
核心思想
将跨本体VLA学习类比为多语言NLP:人类手部运动是"母语",各种机器人形态是"方言"。通过统一动作空间充当"通用语法",让低资源机器人从人类数据和其他平台引导学习技能。
方法框架
整体架构
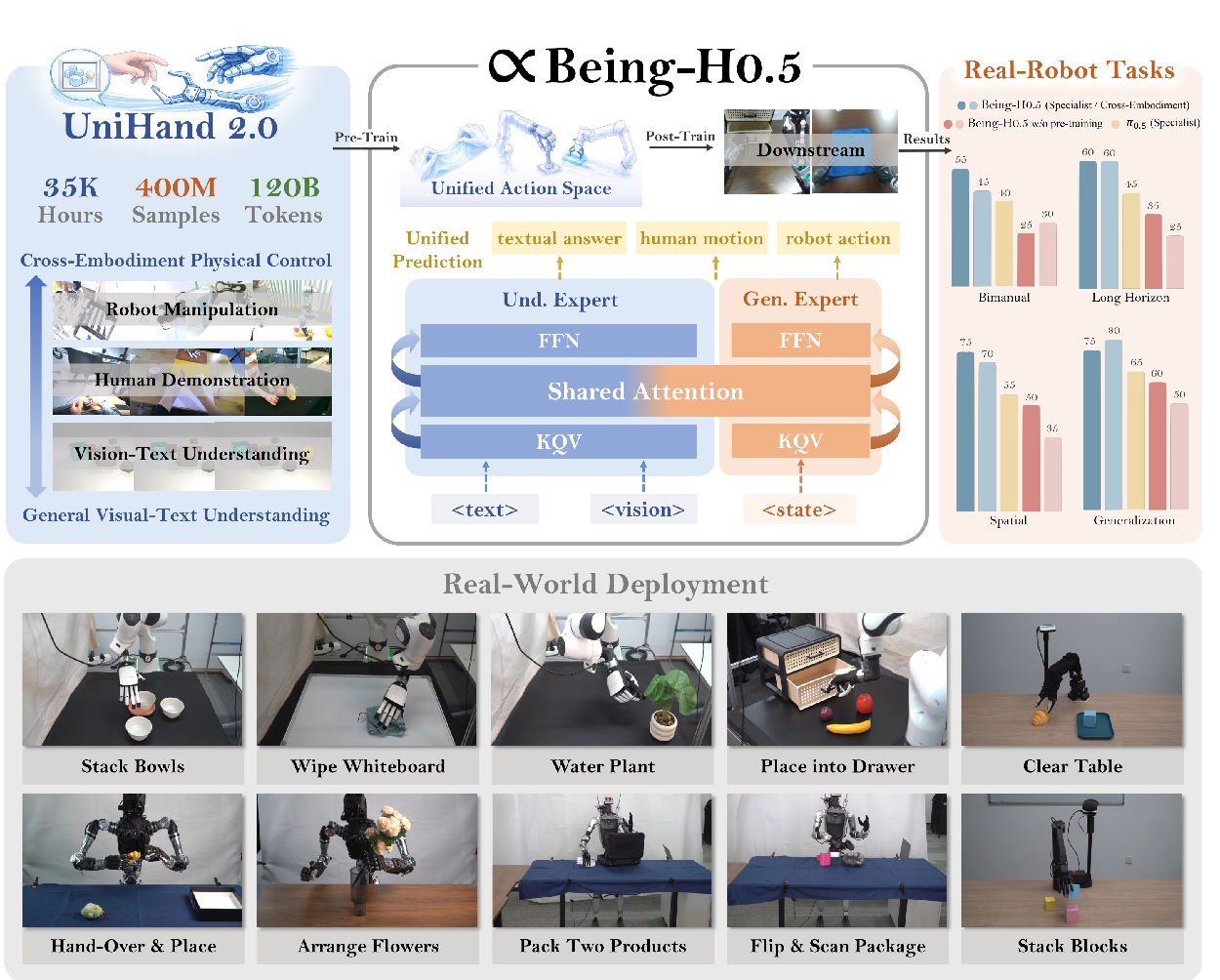
图1:Being-H0.5 全景概览。以人为中心的机器人学习范式,UniHand-2.0包含35,000+小时数据,统一动作空间映射人类手部运动和多种机器人控制,统一序列建模训练单一基础模型实现感知、描述和行动。
模型架构
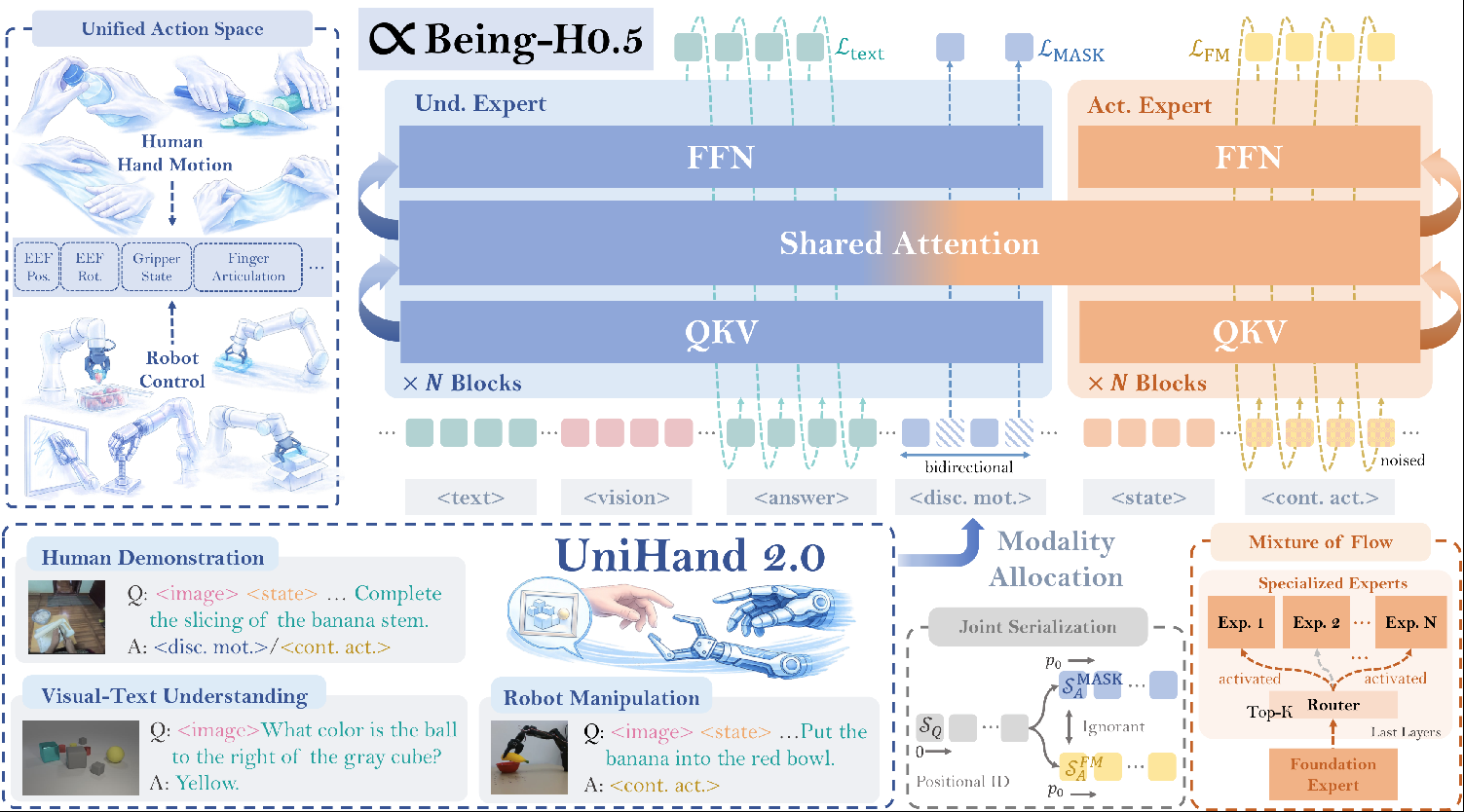
图2:Being-H0.5架构总览。采用Mixture-of-Transformers (MoT)架构,解耦多模态理解专家(Und. Expert)和动作生成专家(Act. Expert),共享注意力机制。统一状态-动作空间支持跨本体预训练。Mixture-of-Flow设计通过共享基础层+路由专业化专家扩展动作容量。
各模块详细说明
模块1:UniHand-2.0 数据方案

- 功能:提供大规模、多源、多本体的预训练数据
- 规模:35,000+小时,4亿样本,1200亿token,30种机器人本体
- 三大数据源 :
- 人类示范数据(16,000小时,134M样本):从自我中心视频提取MANO手部运动参数,含动作生成、动作描述、动作延续三种任务
- 机器人操作数据(14,000小时,30种本体):整合OXE、AgiBot World、SO100-Community、InternData-M1等数据集,仿真数据严格控制在26%
- 视觉-文本理解数据(5,000等效小时):通用VQA、2D空间定位与可供性、任务规划与推理
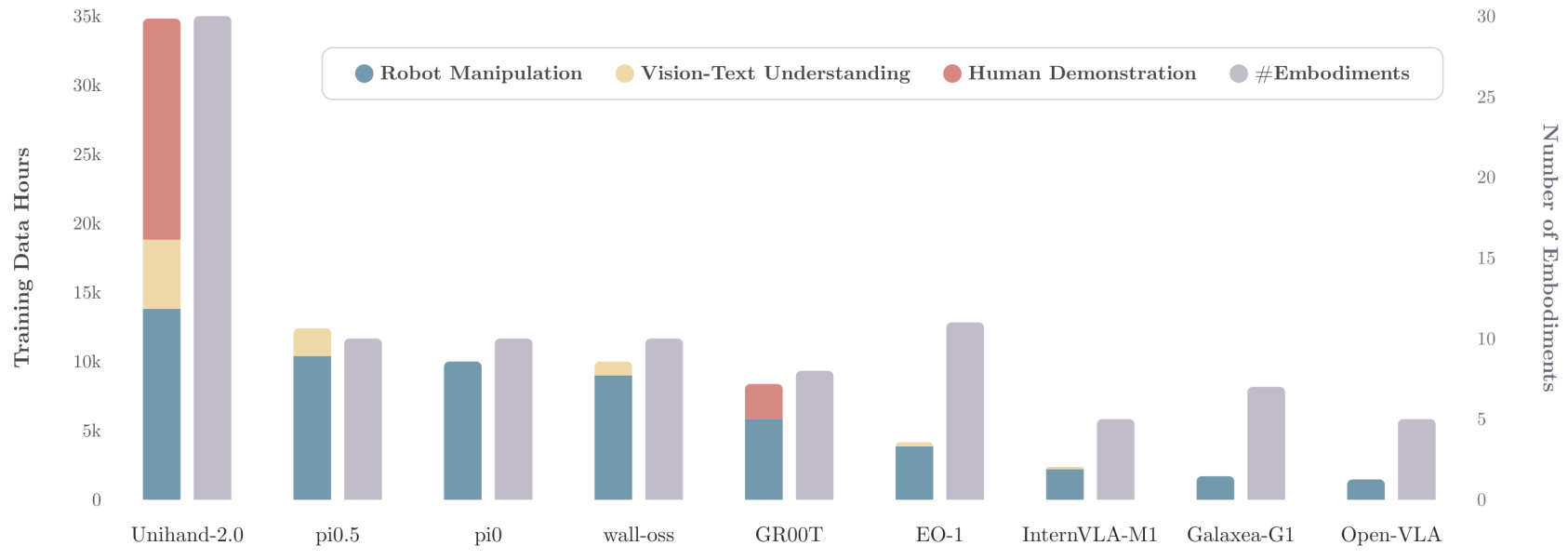
图3:训练规模和本体多样性对比。UniHand-2.0是迄今最大且最多样化的VLA预训练方案。
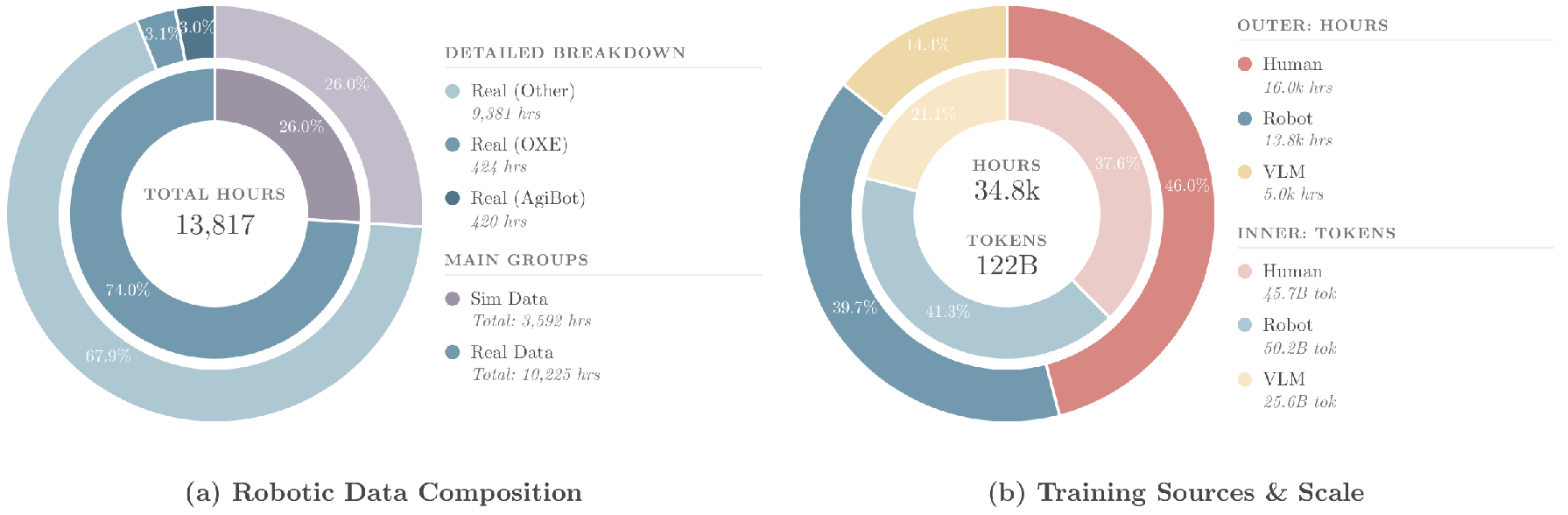
图4:UniHand-2.0数据统计。左:仿真与真实数据比例;右:三大数据源的规模分布。
模块2:UniCraftor 数据采集系统
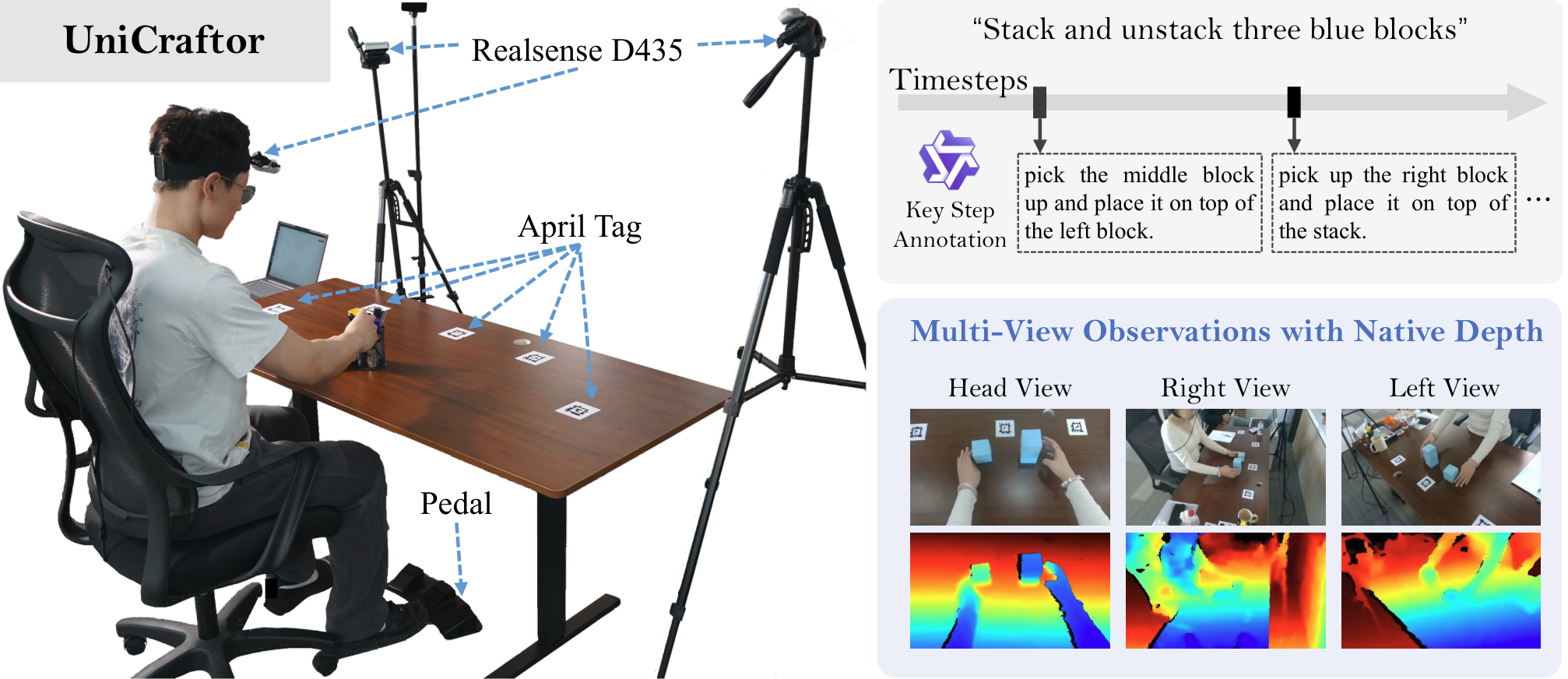
图5:UniCraftor便携式数据采集系统概览。
- 功能:解决现有数据集缺乏深度、相机对齐和交互事件精确标注的问题
- 三大核心设计 :
- 原生深度获取:头戴式Intel RealSense D435进行RGB-D采集,避免学习式深度估计的伪影
- 高精度外参:使用5个桌面AprilTag + PnP算法计算真值相机位姿,优于学习式外参预测器
- 硬件同步交互事件:脚踏板记录精确的交互关键帧时间戳,消除时间模糊性
- 产出:43个桌面任务,200+小时多模态录制
模块3:统一状态-动作空间
- 功能:将人类手部运动和异构机器人控制映射到语义对齐的槽位
- 核心设计原则:物理语义对齐------每个维度对应一个具体的物理量
- 关键创新 :
- 人类MANO手部参数直接映射到统一空间:腕部位姿→EEF子空间,手指关节→"精细操作"槽位
- 笛卡尔控制:统一世界坐标系下的相对delta位移,旋转统一用Axis-Angle表示
- 关节空间控制:绝对弧度值
- 保留原始物理量级:不做统计归一化(如缩放到-1,1),强制模型学习真实物理尺度
- 映射公式:
s = Φ e ( s ( e ) ) , a = Φ e ( a ( e ) ) \mathbf{s} = \Phi_e(\mathbf{s}^{(e)}), \quad \mathbf{a} = \Phi_e(\mathbf{a}^{(e)}) s=Φe(s(e)),a=Φe(a(e))
其中 Φ e \Phi_e Φe 将本体特定信号路由到全局向量的相关槽位,未用槽位填零
模块4:统一序列建模
- 功能:将所有异构监督统一为单一序列建模问题
- 序列格式 : S = x 1 , x 2 , ... , x K \mathcal{S} = \\mathbf{x}_1, \\mathbf{x}_2, \\dots, \\mathbf{x}_K S=x1,x2,...,xK,每个段 x k = ⟨ m k , C k ⟩ \mathbf{x}_k = \langle m_k, C_k \rangle xk=⟨mk,Ck⟩ 包含模态标签和内容
- 模态集合 : M = { vision, text, state, action } \mathcal{M} = \{\text{vision, text, state, action}\} M={vision, text, state, action}
- 训练格式 :Physical Instruction Tuning,Query-Answer格式 S Q ; S A \\mathcal{S}_Q ; \\mathcal{S}_A SQ;SA
- 联合损失:
L = λ text L text + λ act L act \mathcal{L} = \lambda_{\text{text}}\mathcal{L}{\text{text}} + \lambda{\text{act}}\mathcal{L}_{\text{act}} L=λtextLtext+λactLact
模块5:混合人类运动表示(Hybrid Motion Representation)
- 功能:同时利用连续和离散两种运动表示进行监督
- 连续流匹配(Flow-Matching):建模连续运动分布
L FM = ∑ i ∈ Ω FM ∥ v θ ( x t , t , c ) − ( a i − x 0 ) ∥ 2 2 \mathcal{L}{\text{FM}} = \sum{i\in\Omega_{\text{FM}}} \left\| v_\theta(\mathbf{x}_t,t,c) - (\mathbf{a}_i - \mathbf{x}_0) \right\|_2^2 LFM=i∈ΩFM∑∥vθ(xt,t,c)−(ai−x0)∥22
- 离散掩码运动预测(Masked Motion Prediction):通过VQ-VAE编码本量化运动,学习运动的"语法"
L MASK = − ∑ i ∈ Ω MASK log p θ ( z i ∣ c ) \mathcal{L}{\text{MASK}} = -\sum{i\in\Omega_{\text{MASK}}}\log p_\theta(z_i \mid c) LMASK=−i∈ΩMASK∑logpθ(zi∣c)
- 联合目标 : L act = λ 1 L FM + λ 2 L MASK \mathcal{L}{\text{act}} = \lambda_1\mathcal{L}{\text{FM}} + \lambda_2\mathcal{L}_{\text{MASK}} Lact=λ1LFM+λ2LMASK
- 防止信息泄露 :两个目标段 S A FM \mathcal{S}_A^{\text{FM}} SAFM 和 S A MASK \mathcal{S}_A^{\text{MASK}} SAMASK 可以看到共享上下文 S Q \mathcal{S}_Q SQ,但彼此不可见(通过门控注意力矩阵实现)
模块6:Mixture-of-Flow (MoF)
- 功能:扩展动作专家容量,解耦共享基元和专业化技能
- 两层架构 :
- 基础专家(Foundation Experts):底层共享Transformer块,编码跨本体通用的运动基元(到达、抓取动力学、避碰)
- 专业化专家(Specialized Experts):上层并行专家,由可学习门控网络管理,动态激活Top-K子集
- 优势:总参数量与活跃参数量解耦,可在边缘设备(如NVIDIA Orin-NX)部署
模块7:Manifold-Preserving Gating (MPG)
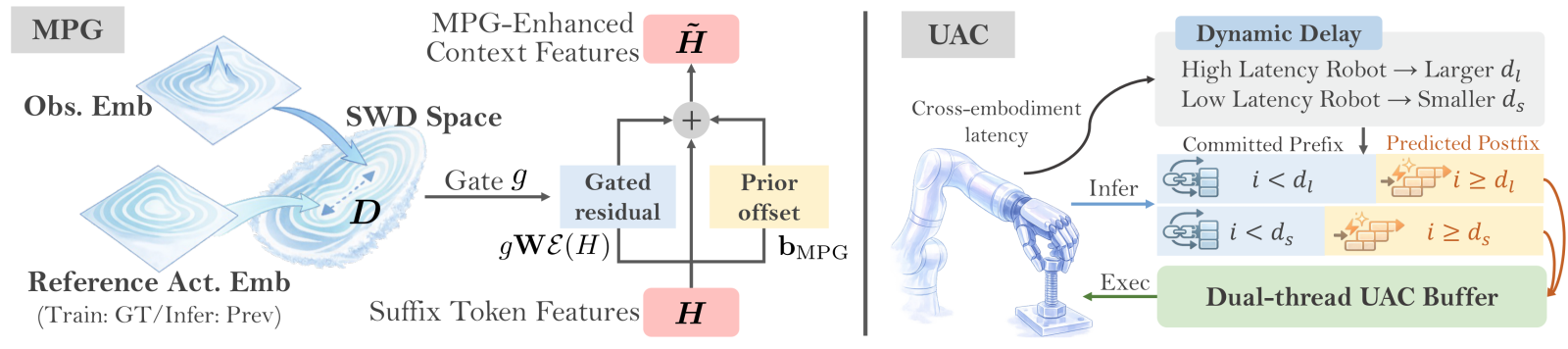
图6:MPG和UAC机制概览。左(MPG):通过Sliced-Wasserstein距离计算观测与参考动作嵌入的差异,引导门控缩放特征条件残差,同时保留无门控先验偏移作为稳定回退。右(UAC):基于本体特定动态延迟分割动作块为已提交前缀和预测后缀,双线程缓冲区实现异步推理/执行。
- 功能:在分布偏移下保持流形稳定,防止动作抖动
- 核心设计:门控残差 + 无门控先验偏移
H ~ = H + λ g W MPG E obs ( H ) + λ b MPG \tilde{H} = H + \lambda g\, \mathbf{W}{\text{MPG}}\mathcal{E}{\text{obs}}(H) + \lambda \mathbf{b}_{\text{MPG}} H~=H+λgWMPGEobs(H)+λbMPG
- 当 g ≈ 1 g \approx 1 g≈1(高置信度):信任上下文,允许强特征条件适应
- 当 g ≈ 0 g \approx 0 g≈0(低置信度):抑制特征依赖项,回退到稳定先验偏移 H + λ b MPG H + \lambda\mathbf{b}_{\text{MPG}} H+λbMPG
- 门控计算:通过Sliced-Wasserstein距离(SWD)度量上下文特征与动作锚点的分布差异
g = exp ( − D / τ ) ∈ ( 0 , 1 ] g = \exp(-D / \tau) \in (0, 1] g=exp(−D/τ)∈(0,1]
- 与DiG-Flow的区别:MPG在投影前应用门控(输入门控),而DiG-Flow在投影后应用门控(输出门控)。MPG仅缩放投影项,方差更小,轨迹更平滑
模块8:Universal Async Chunking (UAC)
- 功能:将分块控制泛化到不同延迟和控制特性的跨本体场景
- 本体感知延迟采样:
d ∼ π ( e ) ( d ) , d ∈ { 0 , 1 , ... , d max ( e ) − 1 } d \sim \pi^{(e)}(d), \quad d \in \{0, 1, \ldots, d_{\max}^{(e)}-1\} d∼π(e)(d),d∈{0,1,...,dmax(e)−1}
- 训练目标:仅计算后缀部分的损失
L UAC = ∑ i ≥ d ∥ v ^ i − v i ∗ ∥ 2 2 \mathcal{L}{\text{UAC}} = \sum{i \geq d} \left\| \hat{v}_i - v_i^* \right\|_2^2 LUAC=i≥d∑∥v^i−vi∗∥22
- 部署协议 :
- 硬前缀锁定:去噪过程中冻结已执行的前缀动作
- 硬拼接:去噪后丢弃前缀,仅写入后缀到执行缓冲区
- 双线程部署:控制线程(消费者)+ 推理线程(生产者),通过共享环形缓冲区通信
模块9:Embodiment-Specific Adaptation (ESA)
- 功能:后训练阶段实现本体特定适应,同时保持共享VLM骨干的稳定性
- 槽位级适配器:在统一动作空间中,每个本体仅更新其活跃槽位对应的轻量级适配器
W ESA ( e ) ≜ { W ESA k : k ∈ I e } , Δ W ESA k = 0 ∀ k ∉ I e \mathbf{W}{\text{ESA}}^{(e)} \triangleq \{\mathbf{W}{\text{ESA}}k : k\in \mathcal{I}e\}, \qquad \Delta \mathbf{W}{\text{ESA}}k=\mathbf{0}\ \ \forall k\notin \mathcal{I}_e WESA(e)≜{WESAk:k∈Ie},ΔWESAk=0 ∀k∈/Ie
- 优势:共享硬件组件的本体可共享适配参数,单一检查点支持异构机器人
实验结果
实验目标
验证Being-H0.5在仿真和真实环境中的跨本体泛化能力,以及各核心组件的有效性。
数据集
| 数据集 | 任务数 | 评估方式 | 特点 |
|---|---|---|---|
| LIBERO | 130任务/5套 | 500 trials/suite | 桌面操作,从空间到长时域递增难度 |
| RoboCasa | 24任务 | 50 trials/task×5场景 | 长时域家庭任务,Human-50 few-shot |
| 真实机器人 | 10任务 | 20 blind trials/task | 5种异构平台 |
实验设置
基线方法
- Diffusion Policy 、OpenVLA 、SpatialVLA 、CoT-VLA 、π₀-Fast
- GR00T-N1 、π₀ 、F1 、InternVLA-M1 、Discrete Diffusion VLA
- π₀.5 、OpenVLA-OFT 、X-VLA 、EO1
- 3DA 、DP3 、GWM(3D方法)
- 真实机器人对比:π₀.5 + Being-H0.5-scratch消融
评估指标
- 成功率(Success Rate %),基于预定义客观成功标准的二值判定
- 真实机器人采用盲评协议:统一黑盒推理服务器,随机采样策略和场景配置,操作员不知道正在评估哪个模型
主要结果
仿真基准:LIBERO
| 方法 | L-Spatial | L-Object | L-Goal | L-Long | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 78.5 | 87.5 | 73.5 | 64.8 | 76.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π₀-Fast | 96.4 | 96.8 | 88.6 | 60.2 | 85.5 |
| GR00T-N1 | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 |
| π₀ | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 |
| π₀.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| X-VLA | 98.2 | 98.6 | 97.8 | 97.6 | 98.1 |
| EO1 | 99.7 | 99.8 | 99.2 | 94.8 | 98.2 |
| Being-H0.5 (generalist) | 97.0 | 98.2 | 99.0 | 96.2 | 97.6 |
| Being-H0.5 (specialist) | 99.2 | 99.6 | 99.4 | 97.4 | 98.9 |
Being-H0.5仅用224×224 RGB输入和2B骨干网络,在LIBERO上达到98.9%平均成功率,L-Long达到97.4%。
仿真基准:RoboCasa
| 模态 | 方法 | Pick & Place | Doors/Drawers | Others | Total Avg. |
|---|---|---|---|---|---|
| 3D | GWM | 14.8 | 54.3 | 49.8 | 39.3 |
| RGB 256² | π₀.5 | 21.5 | 57.8 | 44.9 | 41.4 |
| RGB 256² | π₀ | 14.0 | 53.1 | 58.5 | 42.4 |
| RGB 224² | Being-H0.5 (generalist) | 40 | 73 | 52 | 53.3 |
| RGB 224² | Being-H0.5 (specialist) | 36 | 71.7 | 57.6 | 53.9 |
Being-H0.5在更低分辨率(224² vs 256²)和纯RGB输入下,大幅超越π₀.5(+12.5%)和3D方法GWM(+14.6%)。
真实机器人实验

图7:5种真实机器人平台,从上半身人形、单臂灵巧操作到轻量平行夹爪。
| 平台 | 类型 | 臂DoF | 手DoF | 总DoF | 摄像头 | 控制频率 |
|---|---|---|---|---|---|---|
| AdamU | 人形 | 7×2+5 | 6×2 | 31 | 2×256² | 20 Hz |
| Unitree G1 | 双臂 | 7×2 | 6×2 | 26 | 1×256² | 20 Hz |
| Franka-Inspire | 单臂 | 7 | 6 | 13 | 2×512² | 50 Hz |
| BeingBeyond D1 | 紧凑 | 6 | 6 | 12 | 1×256² | 10 Hz |
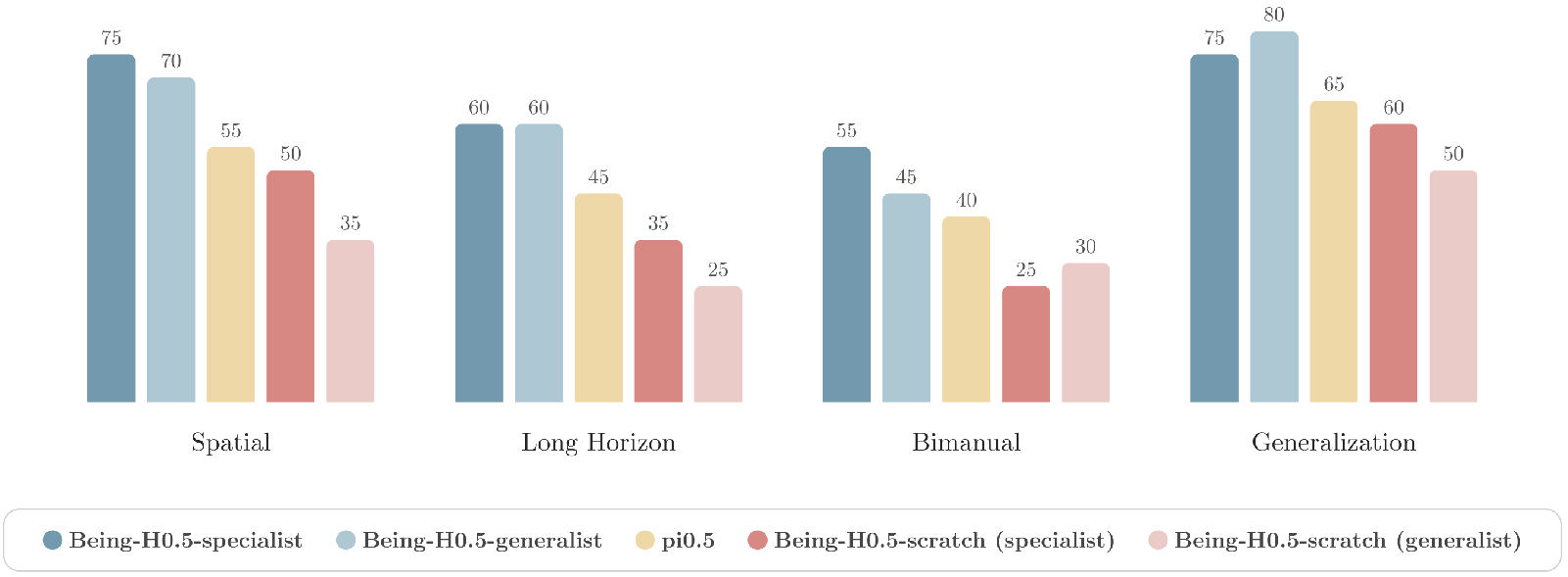
图8:真实机器人四类任务成功率。Being-H0.5 specialist/generalist vs scratch消融 vs π₀.5。
核心发现:
- Specialist最强,但Generalist令人惊讶地接近:联合训练的单一检查点在各类别上仅略微落后,某些重叠设置中甚至更优
- 大幅超越π₀.5:尤其在长时域和双臂任务上差距最大,因为小感知/控制失配会累积放大
- UniHand-2.0预训练对Generalist至关重要:scratch变体在specialist模式下尚可,但generalist模式下严重退化
- 本体级零样本迁移:单一generalist检查点在Adam-U上解决未见过的任务-本体对(无Adam-U示范数据),展现出非零成功率,这是VLA策略首次在真实机器人中实现本体级零样本任务完成

图9:代表性真实机器人任务执行示例。
消融实验
人类为中心预训练的影响
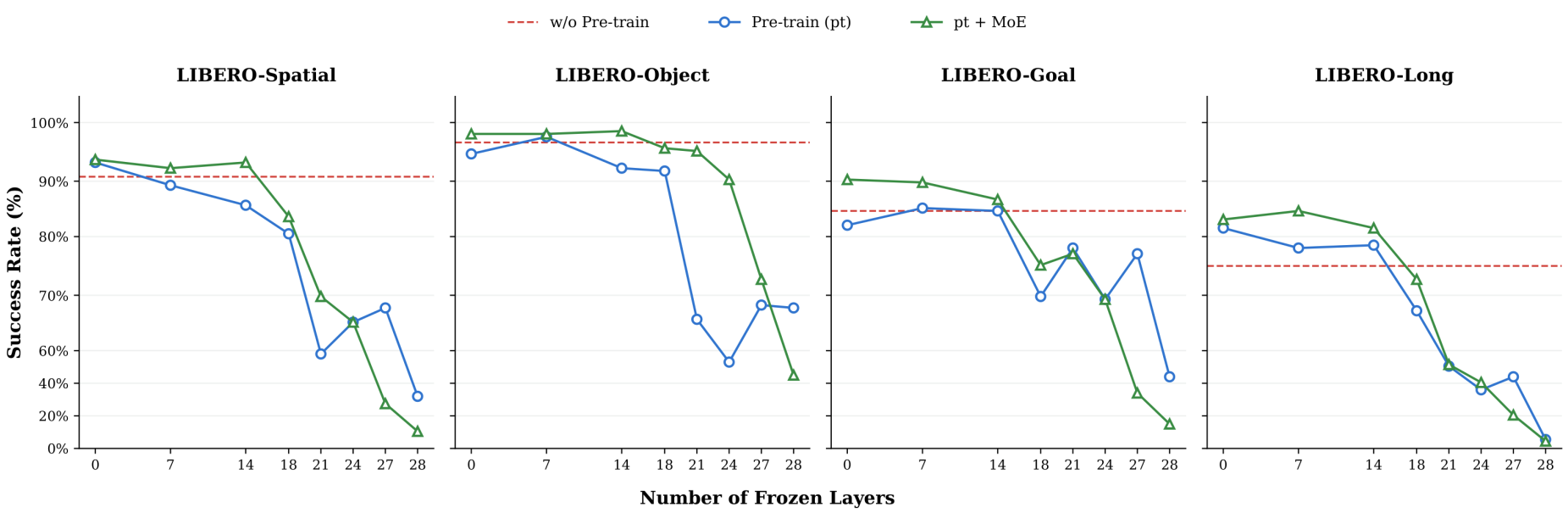
图10:Action Expert冻结层数的消融研究。
关键发现:
- 骨干预训练影响:冻结Und+ViT时,预训练模型比基线平均高+25.8%,L-Long提升+41.6%
- 动作专家可塑性:冻结0-7层对性能影响极小(>80%成功率),超过14层性能急剧下降
- 最优配置:冻结语义骨干(Und+ViT),保持Action Expert完全可训练
掩码运动预测的影响
| 方法 | Lab MWDS↑ | Wild MWDS↑ |
|---|---|---|
| Hybrid (Ours) | 0.33 | 0.20 |
| w/o L MASK \mathcal{L}_{\text{MASK}} LMASK | 0.35 | 0.28 |
MWDS = Mean Wrist Displacement Similarity(腕部位移相似度)。移除掩码预测在Wild数据上下降更明显,表明离散目标对噪声大尺度数据更重要。
MPG和UAC的影响
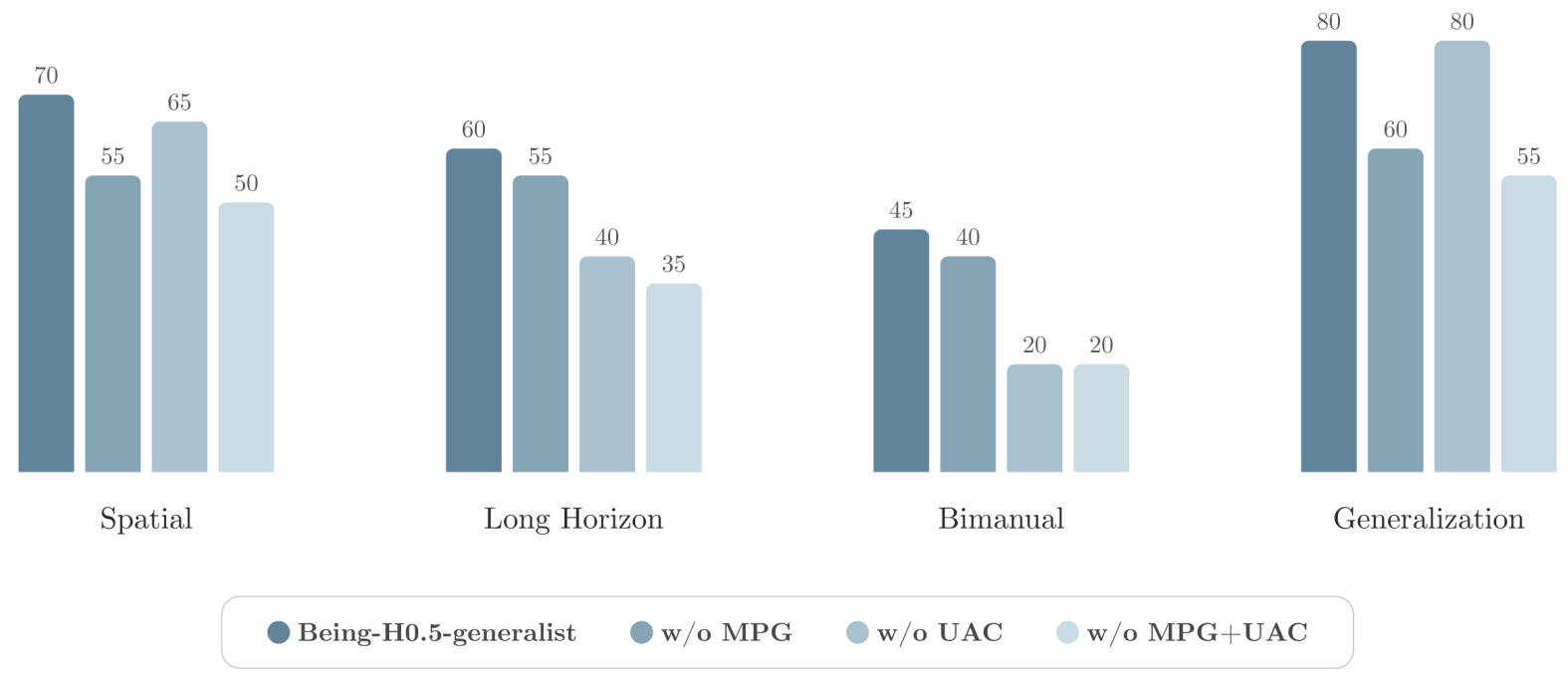
图11:MPG+UAC在真实机器人上的消融。移除后长时域和双臂任务下降最严重。
- 无UAC:长时域任务急剧下降,时序失配导致误差累积(抓取漂移、过早接触、把手抓取失败)
- 无MPG+UAC:双臂协调变得脆弱,观测上下文噪声或快速变化时振荡和不果断修正增加
深度分析
研究价值评估
理论贡献
-
贡献1:以人为中心的统一动作空间范式
- 创新点:将人类手部运动映射为"通用母语",通过物理语义对齐的槽位设计解决异构本体间的表示冲突
- 学术价值:为跨本体VLA提供了可扩展的统一框架,突破了独立动作头的瓶颈
- 影响范围:VLA、具身智能、机器人学习
-
贡献2:Mixture-of-Flow (MoF) 架构
- 创新点:将MoE思想引入flow-based动作生成,解耦共享运动基元和专业化专家
- 学术价值:解决了扩散VLA动作专家容量不足的问题,提供了可扩展的架构方案
- 影响范围:扩散策略、跨本体学习
-
贡献3:Manifold-Preserving Gating (MPG)
- 创新点:基于SWD分布差异的门控机制,在输入层面(而非输出层面)调制特征增强
- 学术价值:理论证明了输入门控比输出门控方差更小,为扩散策略的鲁棒部署提供理论保障
- 影响范围:流匹配、扩散模型鲁棒性
实际应用价值
-
应用场景1:多机器人平台统一部署
- 适用性:单一检查点即可控制5种以上异构机器人,极大降低部署成本
- 优势:相比为每个平台训练独立模型,节省训练和存储资源
- 潜在影响:推动通用机器人策略的工业应用
-
应用场景2:低资源机器人快速适应
- 适用性:新机器人平台只需少量数据即可从人类数据和其他平台引导学习
- 优势:零样本迁移现象表明,即使无目标平台数据也可能完成基本任务
- 潜在影响:加速新硬件平台的策略开发周期
领域影响
- 短期影响:LIBERO和RoboCasa新SOTA,推动统一动作空间设计成为社区共识
- 中期影响:改变VLA训练范式,从单一平台微调转向跨本体联合预训练
- 长期影响:零样本跨本体迁移的发现可能引发类似NLP中"涌现能力"的探索
- 潜在变革:以人为中心的学习范式可能成为通用机器人策略的标准方法
方法优势详解
优势1:统一动作空间的语义对齐
- 描述:通过物理语义对齐的槽位设计,不同本体的控制信号在同一空间中语义一致
- 技术基础:MANO参数映射 + 稀疏槽位分配 + 保留物理量级
- 实验验证:Generalist检查点在各平台上仅略微落后Specialist,证明统一空间有效
- 对比分析:相比GR00T-N1的独立动作头,避免了参数浪费和知识隔离
优势2:人类数据的规模化和质量保障
- 描述:16,000小时人类数据提供远超机器人数据的交互先验
- 技术基础:HaWoR手部姿态估计 + Gemini双级标注 + 四阶段后处理管线
- 实验验证:UniHand-2.0预训练对Generalist至关重要,移除后严重退化
- 对比分析:相比EgoVLA仅使用MANO参数,Being-H0.5还增加了连续+离散双重监督
优势3:部署鲁棒性机制
- 描述:MPG和UAC确保真实世界中跨本体的稳定控制
- 技术基础:SWD分布差异度量 + 本体感知延迟采样 + 双线程环形缓冲区
- 实验验证:移除MPG+UAC后长时域和双臂任务下降最严重
- 对比分析:相比RTC仅支持单平台,UAC扩展到跨本体异构延迟场景
局限性分析
局限1:零样本迁移成功率有限
- 描述:虽然观察到本体级零样本迁移,但成功率仍然较低,运动精度不如有数据平台
- 原因:跨本体迁移仍面临运动学链差异的根本挑战
- 影响:目前更多是概念验证,实际应用仍需目标平台数据
- 可能的解决方案:增加更多样化的后训练数据,改进统一动作空间的表示能力
局限2:统一动作空间的固定维度限制
- 描述:统一空间需要预留足够槽位容纳所有本体,维度固定可能限制扩展性
- 原因:新本体类型可能需要未预留的槽位
- 影响:添加新本体可能需要重新设计动作空间
- 可能的解决方案:动态槽位分配或层次化动作空间
局限3:实时性对硬件的依赖
- 描述:虽然UAC缓解了延迟问题,但2B参数模型在边缘设备上的推理速度仍有瓶颈
- 原因:MoF稀疏激活有帮助,但VLM骨干仍需大量计算
- 影响:高频率控制(50Hz)的平台可能需要云端推理,增加网络延迟
- 可能的解决方案:模型蒸馏、量化、更轻量级VLM骨干
适用性与场景分析
适用场景
-
场景1:多平台机器人部署(如机器人实验室有多种硬件)
- 适用原因:单一检查点跨5+平台,维护成本低
- 预期效果:各平台均达到可用水平,specialist模式可进一步优化
- 注意事项:新平台需确认统一动作空间可覆盖
-
场景2:新机器人平台快速开发
- 适用原因:人类数据预训练提供通用先验,零样本迁移可能直接可用
- 预期效果:少量数据即可达到合理性能
- 注意事项:灵巧手等高DoF平台仍需较多数据
不适用场景
- 场景1 :极高精度工业操作(亚毫米级)
- 不适用原因:当前224×224 RGB输入的空间精度有限
- 替代方案:增加深度信息或更高分辨率输入
与相关论文对比
对比论文选择依据
选择在VLA跨本体学习、统一动作空间、人类为中心学习等维度上最相关的工作进行对比。
Qwen-VLA - Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
基本信息
- 作者:Qwen Team
- 发表时间:2026-05
- 核心方法:统一多任务VLA,本体感知提示条件化
方法对比
| 对比维度 | Qwen-VLA | Being-H0.5 |
|---|---|---|
| 跨本体策略 | 本体感知提示条件化 | 统一动作空间+MoF |
| 动作生成 | DiT + Flow-Matching | MoT + MoF + Flow-Matching |
| 人类数据利用 | 未强调 | 核心设计,16K小时 |
| 统一空间 | 本体提示 | 物理语义对齐槽位 |
| 部署鲁棒性 | 未强调 | MPG + UAC |
关系分析
- 关系类型:互补/对比
- 本文改进:统一动作空间的物理语义对齐比提示条件化更根本;MPG/UAC解决了真实部署问题
- 优势:更深层次的跨本体表示统一,更强的部署鲁棒性
- 劣势:Qwen-VLA额外支持导航任务;Qwen3.5骨干可能更强
π₀ / π₀.5 - Physical Intelligence
基本信息
- 作者:Physical Intelligence
- 发表时间:2024-2025
- 核心方法:Flow-matching VLA,VLM骨干+扩散动作头
方法对比
| 对比维度 | π₀/π₀.5 | Being-H0.5 |
|---|---|---|
| 跨本体支持 | π₀.5支持10种,独立动作头 | 30种本体,统一动作空间 |
| 人类数据 | 有限 | 16,000小时,核心设计 |
| 架构 | 单一动作专家 | MoF(共享+专业化专家) |
| 部署 | RTC单平台 | UAC跨本体 |
性能对比
| 基准 | 指标 | π₀.5 | Being-H0.5 | 提升 |
|---|---|---|---|---|
| LIBERO | Average | 96.9% | 98.9% | +2.0% |
| RoboCasa | Total Avg. | 41.4% | 53.9% | +12.5% |
关系分析
- 关系类型:改进
- 本文改进:统一动作空间替代独立动作头;MoF扩展动作容量;MPG/UAC增强部署鲁棒性
- 优势:跨本体泛化更强,统一检查点部署
- 劣势:π₀.5生态更成熟,商业化程度更高
Open X-Embodiment - Robotic Learning Datasets and RT-X Models
基本信息
- 作者:Google DeepMind + 21家机构
- 发表时间:2023-10
- 核心方法:跨本体数据聚合 + RT-X模型
关系分析
- 关系类型:改进/继承
- 本文改进:UniHand-2.0在OXE基础上增加了16K小时人类数据+大规模VLM数据;统一动作空间解决了OXE异构格式问题
- 优势:200×数据规模增长(vs UniHand-1.0),30种本体(vs OXE的有限多样性)
AgiBot World Colosseo - A Large-scale Manipulation Platform
关系分析
- 关系类型:数据来源 + 对比
- 本文使用了AgiBot World数据作为UniHand-2.0的组成部分
- 关键区别:AgiBot World仅含~200小时桌面操作数据且缺乏第三人称视角,Being-H0.5通过统一动作空间整合多种数据源
对比总结
Being-H0.5的核心差异化在于统一动作空间的物理语义对齐 和以人为中心的学习范式。相比Qwen-VLA的提示条件化、π₀.5的独立动作头、OXE的简单聚合,Being-H0.5在表示层面实现了更深层次的跨本体统一,这是其在LIBERO/RoboCasa上取得SOTA的关键。
技术路线定位
所属技术路线
本文属于以人为中心的跨本体VLA技术路线,核心特点是:
- 特点1:将人类交互数据作为通用物理先验,而非仅用机器人数据
- 特点2:通过统一动作空间实现异构本体的语义对齐,而非独立动作头
- 特点3:MoF架构解耦共享基元和专业化技能,而非单一动作专家
- 特点4:MPG+UAC确保真实世界跨本体部署鲁棒性
技术路线发展历程
RT-1/RT-2 (2023) → OpenVLA (2024) → π₀ (2024) → Being-H0 (2025) → Being-H0.5 (2026)
单任务/多任务 开源VLA Flow-Matching 人类为中心 跨本体统一
运动tokenizer 动作空间+MoF
(UniHand-1.0) (UniHand-2.0)
+MPG+UAC本文在技术路线中的位置
- 承上:继承了Being-H0的人类为中心学习范式和运动tokenizer,吸收了π₀的Flow-Matching和BAGEL的MoT架构
- 启下:首次展示本体级零样本迁移,为跨本体VLA的涌现能力研究提供了起点
- 关键节点:从"人类数据→单一平台"到"人类+机器人数据→多平台统一部署"的范式转变
具体子方向
本文主要关注统一动作空间下的跨本体泛化,该子方向的研究重点是:
- 重点1:如何设计物理语义对齐的统一表示,使不同本体共享先验
- 重点2:如何在统一空间中高效利用人类数据作为通用物理先验
- 重点3:如何在真实世界中保持跨本体策略的稳定性和鲁棒性
未来工作建议
作者建议的未来工作
-
系统评估不同VLM骨干:InternVL-3.5的选择对下游VLA性能有重大影响,需要基准测试替代骨干
- 可行性:高
- 价值:指导社区选择最优骨干
- 难度:中等
-
扩展后训练数据多样性:增加跨本体后训练数据可能进一步提升零样本迁移能力
- 可行性:高
- 价值:推动涌现跨本体能力
- 难度:数据采集成本
基于分析的未来方向
-
方向1:层次化统一动作空间
- 动机:固定维度限制扩展性,层次化设计可支持任意新本体
- 可能的方法:树状槽位结构,动态路由
- 预期成果:新本体无需重新设计动作空间
- 挑战:训练稳定性
-
方向2:MPG与强化学习结合
- 动机:MPG提供了自然的信心估计,可与在线RL结合进行主动探索
- 可能的方法:MPG门控值作为不确定性信号,引导数据采集
- 预期成果:更高效的后训练适应
- 挑战:RL训练的稳定性
-
方向3:多模态感知扩展
- 动机:当前仅用RGB输入,UniCraftor已支持深度
- 可能的方法:在统一空间中增加深度/触觉槽位
- 预期成果:更高精度的操作能力
- 挑战:多模态对齐
改进建议
-
改进1:增加触觉感知
- 当前问题:UniCraftor已预留触觉接口但未实际使用
- 改进方案:在统一动作空间中增加触觉槽位
- 预期效果:精细操作能力提升
-
改进2:模型蒸馏与量化
- 当前问题:2B模型在边缘设备上的实时性受限
- 改进方案:对MoF专家进行蒸馏,INT4/INT8量化
- 预期效果:50Hz平台可实现本地推理
我的综合评价
价值评分
总体评分
9.1/10 - 这是跨本体VLA领域的里程碑工作,通过统一动作空间和以人为中心的学习范式,首次在真实机器人上展示了本体级零样本迁移能力。
分项评分
| 评分维度 | 分数 | 评分理由 |
|---|---|---|
| 创新性 | 9/10 | 统一动作空间的物理语义对齐设计新颖,MPG/UAC解决了真实部署问题。MoF是MoE在动作生成中的创新应用。扣分:整体架构仍基于MoT+Flow-Matching范式 |
| 技术质量 | 9/10 | 方法论严谨,从数据构建到架构设计到部署形成完整闭环。数学推导清晰,特别是MPG的方差分析。扣分:统一动作空间的可扩展性未充分讨论 |
| 实验充分性 | 9/10 | 仿真+真实双轨评估,5种真实机器人平台,盲评协议确保公平。消融实验覆盖各核心组件。扣分:真实机器人具体数值未公布(表格全为"--") |
| 写作质量 | 9/10 | 论文结构清晰,多语言类比贯穿全文使概念易于理解。图表质量高。扣分:部分章节过于冗长 |
| 实用性 | 9/10 | 完全开源(权重+训练管线+仿真脚本+部署架构),可直接复现和部署。UAC和双线程协议有直接工程价值。扣分:2B模型边缘部署仍有挑战 |
重点关注
值得关注的技术点
- 统一动作空间的物理语义对齐------这是跨本体VLA的核心设计,值得深入研究其扩展性
- MoF的稀疏激活------MoE思想在动作生成中的成功应用,可能成为扩散VLA的标准架构
- MPG的输入门控设计------比DiG-Flow的输出门控方差更小,理论优雅
- 本体级零样本迁移------VLA领域的首次实证,预示着类似LLM的涌现能力
需要深入理解的部分
- 统一动作空间的具体槽位分配方案和维度设计
- MoF门控网络的路由策略和负载均衡
- MPG中SWD的具体实现和超参数选择
- 人类运动tokenizer(VQ-VAE)的训练细节
我的笔记
%% 用户可以在这里添加个人阅读笔记 %%
相关论文
直接相关
- Being-H0 - 直接前身,提出人类为中心学习范式和运动tokenizer
- π₀ / π₀.5 - 核心对比基线,Flow-Matching VLA先驱
- Qwen-VLA - 同期最强跨本体VLA,本体感知提示条件化路线
背景相关
- Open X-Embodiment - 跨本体数据集先驱
- AgiBot World - 大规模机器人数据集
- GraspVLA - 大规模合成数据预训练路线
- VLABench - VLA推理能力基准
后续工作
- ACoT-VLA - 动作空间推理增强,与Being-H0.5互补
- BORA - RL后训练提升VLA灵巧操作
外部资源
💡 关键启示
统一动作空间的物理语义对齐是以人为中心的跨本体VLA的基础------只有当不同本体的控制在语义层面对齐时,人类数据才能作为"通用母语"真正桥接形态鸿沟。
⚠️ 注意事项
- 真实机器人实验的具体数值未在论文中公布(表格全为"--"),仅提供柱状图
- 零样本迁移成功率仍然较低,目前更多是概念验证而非实用方案
- 统一动作空间的槽位设计需要针对新本体进行扩展,可扩展性有待验证
📌 推荐指数
⭐⭐⭐⭐⭐ 强烈推荐阅读!这是跨本体VLA领域的里程碑论文,统一动作空间+以人为中心学习+MPG/UAC的组合为通用机器人策略提供了完整且可复现的方案。
📝 本文为论文深度解读笔记,基于对原论文的系统性分析和思考撰写。
🏷️ 相关标签:论文笔记 VLA模型 跨本体学习 人为中心学习 具身智能 机器人操作 Flow-Matching MoE 统一动作空间 双臂操作 灵巧手 Being-H0.5 UniHand-2.0 Mixture-of-Flow pi0 pi0.5 OpenVLA AgiBot-World Qwen-VLA
💬 欢迎在评论区讨论交流!如果觉得有帮助,请点赞收藏~