🎯 读完这篇,你就能------上传一段 30 秒录音,让 AI 用你的声音朗读任何文字!
一、🤔 这是什么神仙项目?
👉 一句话总结:
- 🏠 开源地址:https://github.com/fishaudio/fish-speech
- 📖 官方文档:https://docs.fish.audio
- 🌐 在线体验:https://fish.audio
🌟 核心亮点速览
| 🏷️ 特性 | 📝 说明 |
|---|---|
| ⚡ 零样本克隆 | 无需训练,上传录音即用,10 秒即可克隆基础声线 |
| 🌍 多语言 | 中英日韩法等 13 种语言,中文效果尤其惊艳 |
| 💰 性价比爆表 | 成本仅为 ElevenLabs 的约 六分之一 |
| 🔓 完全开源 | Apache 2.0 协议,支持本地部署,数据不出门 |
二、⚡ 3 分钟极速上手(API 方案 · 零显卡)
🚫🧠 不需要显卡!不需要训练!有网就能跑!
🪜 Step 1:获取 API Key 🔑
- 🌐 打开 Fish Audio 官网 注册/登录
- ⚙️ 进入 用户设置 → API Keys
- 🆕 点击 New API Key ,复制密钥(形如
sk-xxxxxxxx)
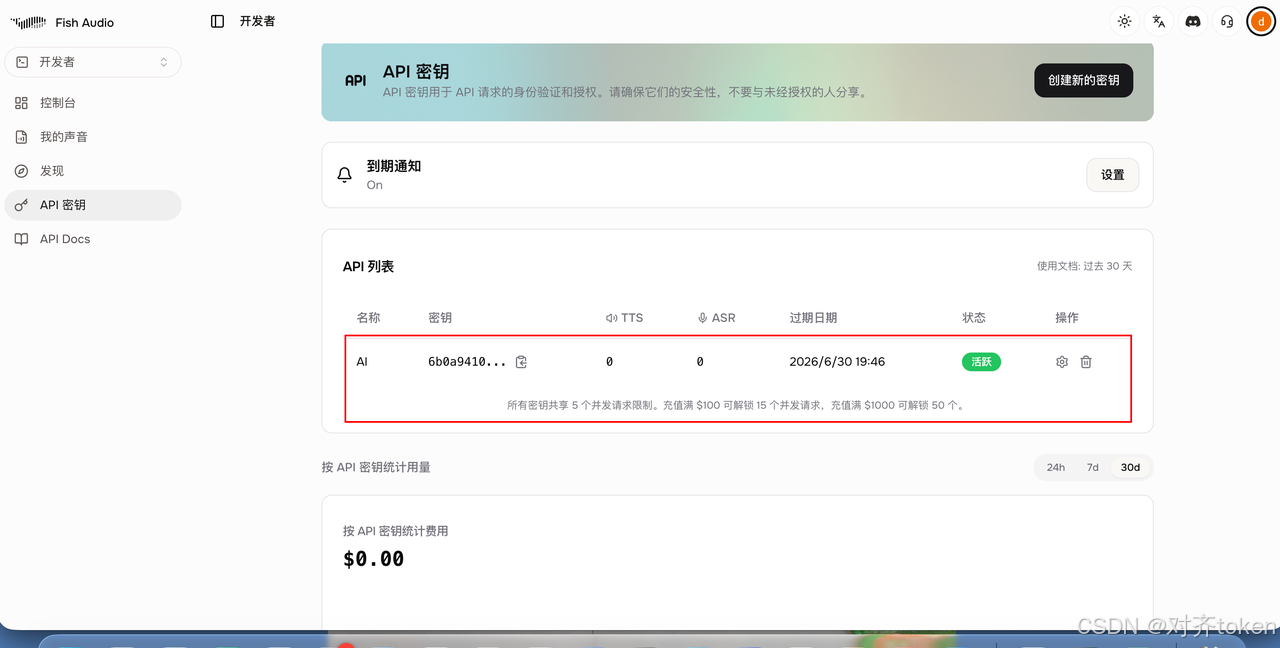
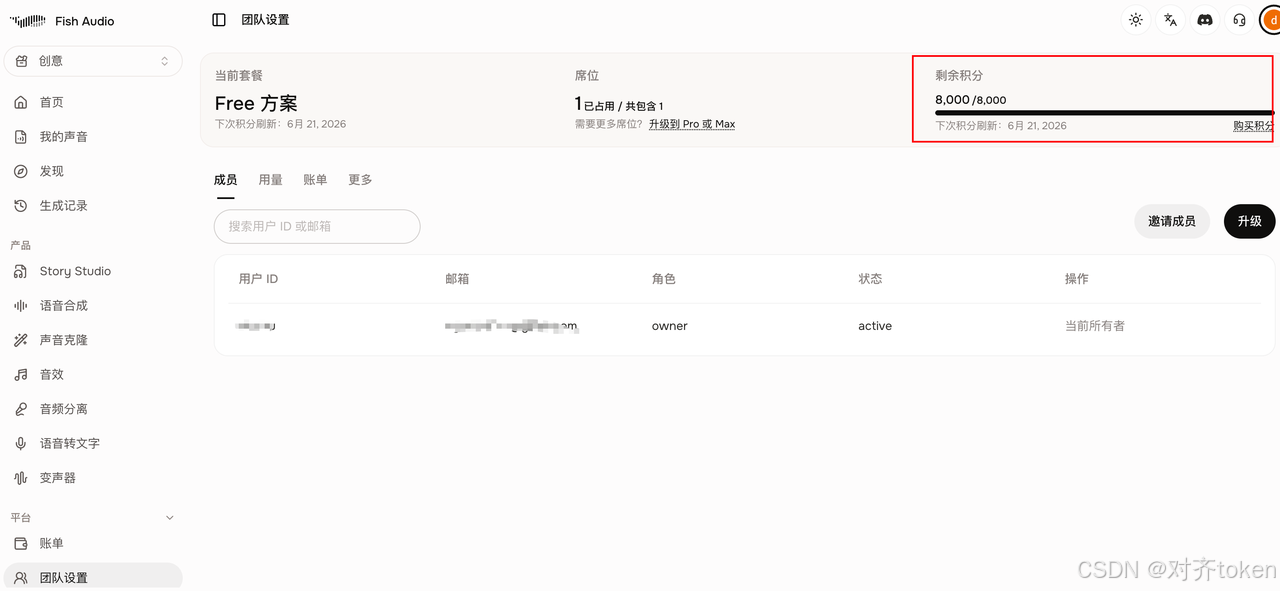
🎁 免费额度 :每月 7 分钟 高质量语音 + 8000 积分 ,够你玩到吐!
📦 Step 2:安装依赖
Bash
pip install requests gradio # 就这两个,没了🚀 Step 3:跑通第一个 Demo(这个要充值)
把下面代码保存为 tts_demo.py,替换 YOUR_API_KEY,运行即可:
Python
import requests
API_KEY = "YOUR_API_KEY"
TEXT = "你好,欢迎使用 Fish Audio,这是我的声音克隆效果。" # ✏️ 改这里
REFERENCE_AUDIO = "my_voice.wav" # 🎤 改成你的录音文件路径
OUTPUT_AUDIO = "output.mp3" # 💾 输出文件名
url = "https://api.fish.audio/v1/tts"
headers = {"Authorization": f"Bearer {API_KEY}"}
with open(REFERENCE_AUDIO, "rb") as f:
files = {"reference_audio": (REFERENCE_AUDIO, f, "audio/wav")}
data = {
"text": TEXT,
"reference_text": "", # 录音对应的文本,不知道可留空
"model": "fish-speech-1.5",
"format": "mp3"
}
response = requests.post(url, headers=headers, files=files, data=data)
if response.status_code == 200:
with open(OUTPUT_AUDIO, "wb") as out:
out.write(response.content)
print(f"✅ 合成成功!音频已保存为 {OUTPUT_AUDIO}")
else:
print(f"❌ 请求失败:{response.status_code}\n{response.text}")
python tts_demo.py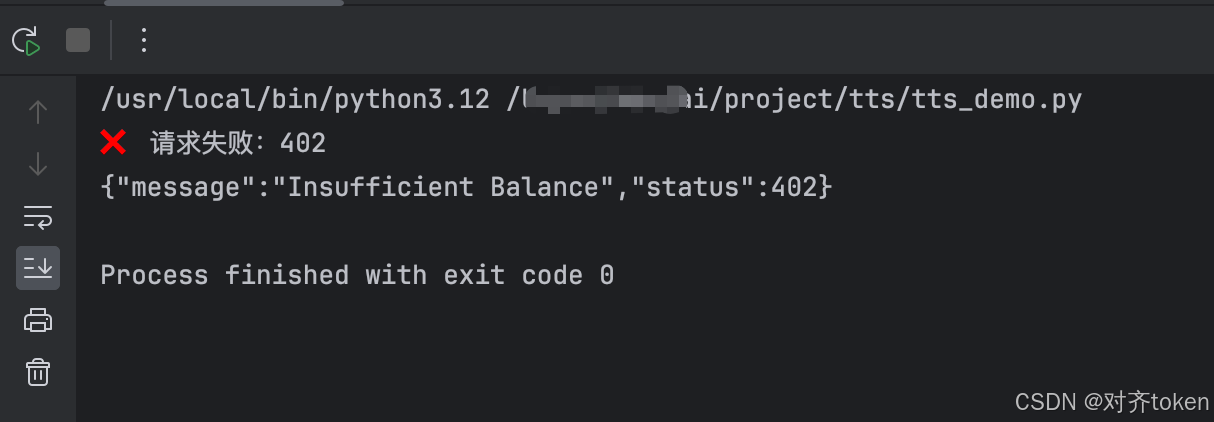
意思是余额不足,要充值
🎉 打开 output.mp3 ------ 恭喜,你已经成功克隆了自己的声音!
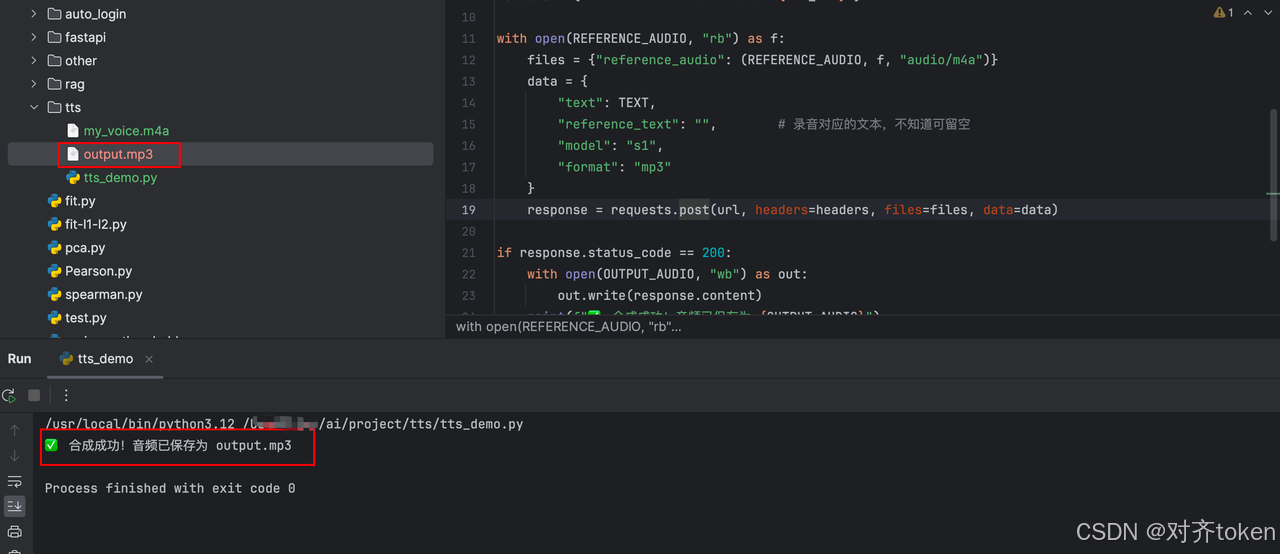
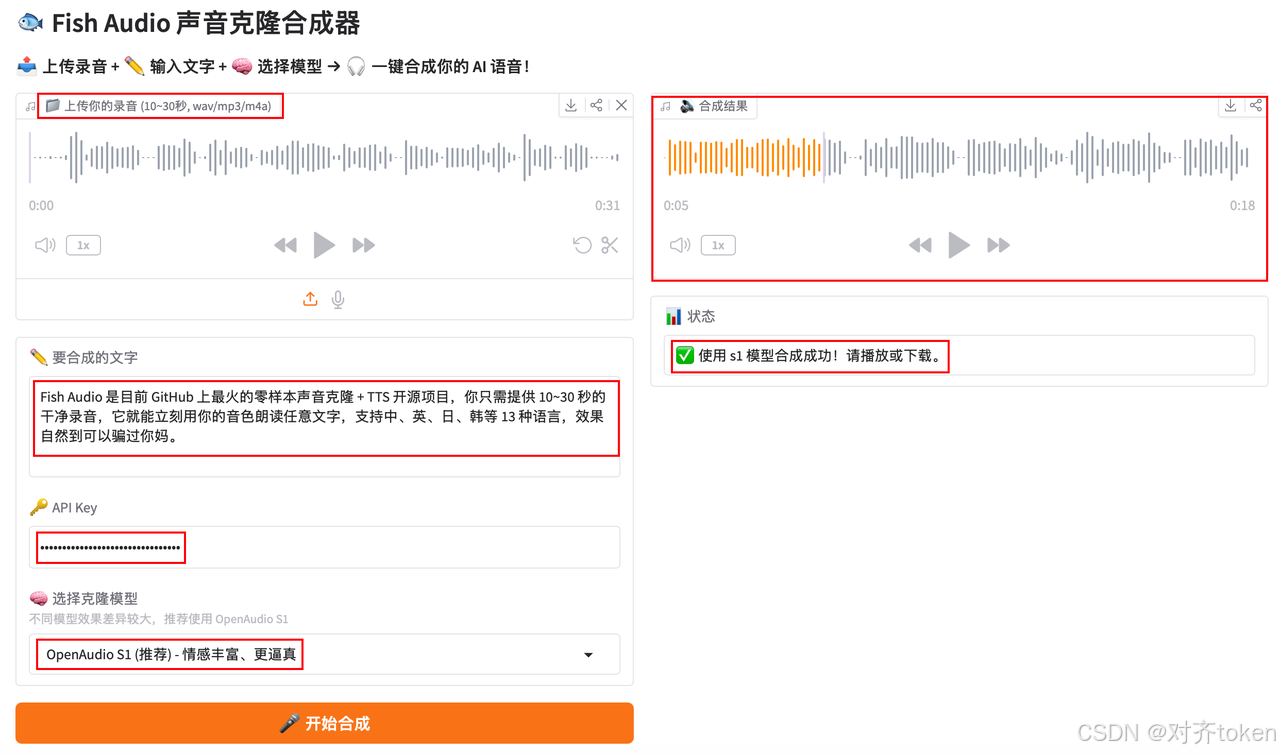
三、🖥️ Python 图形界面------点点鼠标就能用!
🎨 基于 Gradio 的 Web 界面,上传录音 → 输入文字 → 一键合成 → 在线播放 & 下载!
🎛️ 界面功能
- 📁 拖拽上传你的录音文件
- ✏️ 输入要合成的文字
- 🔑 填写 API Key(仅本地使用,不上传)
- 🎤 一键合成,自动播放
💾 下载合成音频
📝 完整代码
新建 fish_tts_gui.py,粘贴以下代码:
Python
import gradio as gr
import requests
import tempfile
import os
def tts_clone(audio_file, text, api_key):
"""🪄 使用 Fish Audio API 进行声音克隆与合成"""
if not api_key:
return None, "❌ 请输入 API Key"
if audio_file is None:
return None, "❌ 请上传参考录音"
if not text.strip():
return None, "❌ 请输入要合成的文本"
url = "https://api.fish.audio/v1/tts"
headers = {"Authorization": f"Bearer {api_key}"}
with open(audio_file, "rb") as f:
files = {"reference_audio": (os.path.basename(audio_file), f, "audio/wav")}
data = {
"text": text,
"reference_text": "",
"model": "fish-speech-1.5",
"format": "mp3"
}
try:
resp = requests.post(url, headers=headers, files=files, data=data, timeout=30)
except Exception as e:
return None, f"❌ 网络错误:{e}"
if resp.status_code == 200:
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as tmp:
tmp.write(resp.content)
tmp_path = tmp.name
return tmp_path, "✅ 合成成功!请播放或下载。"
else:
return None, f"❌ API 错误 {resp.status_code}:{resp.text}"
# 🎨 构建界面
with gr.Blocks(title="🐟 Fish Audio 声音克隆合成器") as demo:
gr.Markdown("""
# 🐟 Fish Audio 声音克隆合成器
### 📤 上传录音 + ✏️ 输入文字 → 🎧 一键合成你的 AI 语音!
""")
with gr.Row():
with gr.Column(scale=1):
audio_input = gr.Audio(
label="📁 上传你的录音 (10~30秒, wav/mp3)",
type="filepath"
)
text_input = gr.Textbox(
label="✏️ 要合成的文字",
lines=4,
placeholder="请输入需要朗读的内容... 💬"
)
api_key_input = gr.Textbox(
label="🔑 API Key",
type="password",
placeholder="输入你的 Fish Audio API Key"
)
submit_btn = gr.Button("🎤 开始合成", variant="primary", size="lg")
with gr.Column(scale=1):
output_audio = gr.Audio(label="🔊 合成结果", type="filepath", interactive=False)
status_text = gr.Textbox(label="📊 状态", interactive=False)
submit_btn.click(
fn=tts_clone,
inputs=[audio_input, text_input, api_key_input],
outputs=[output_audio, status_text]
)
gr.Markdown("---")
gr.Markdown("""
> 🔐 API Key 仅在本地使用,不会上传到第三方。
> 🔗 获取地址:[Fish Audio 设置页](https://fish.audio/user/settings)
""")
if __name__ == "__main__":
demo.launch()▶️ 运行
Bash
python fish_tts_gui.py浏览器打开 http://127.0.0.1:7860,开箱即用!
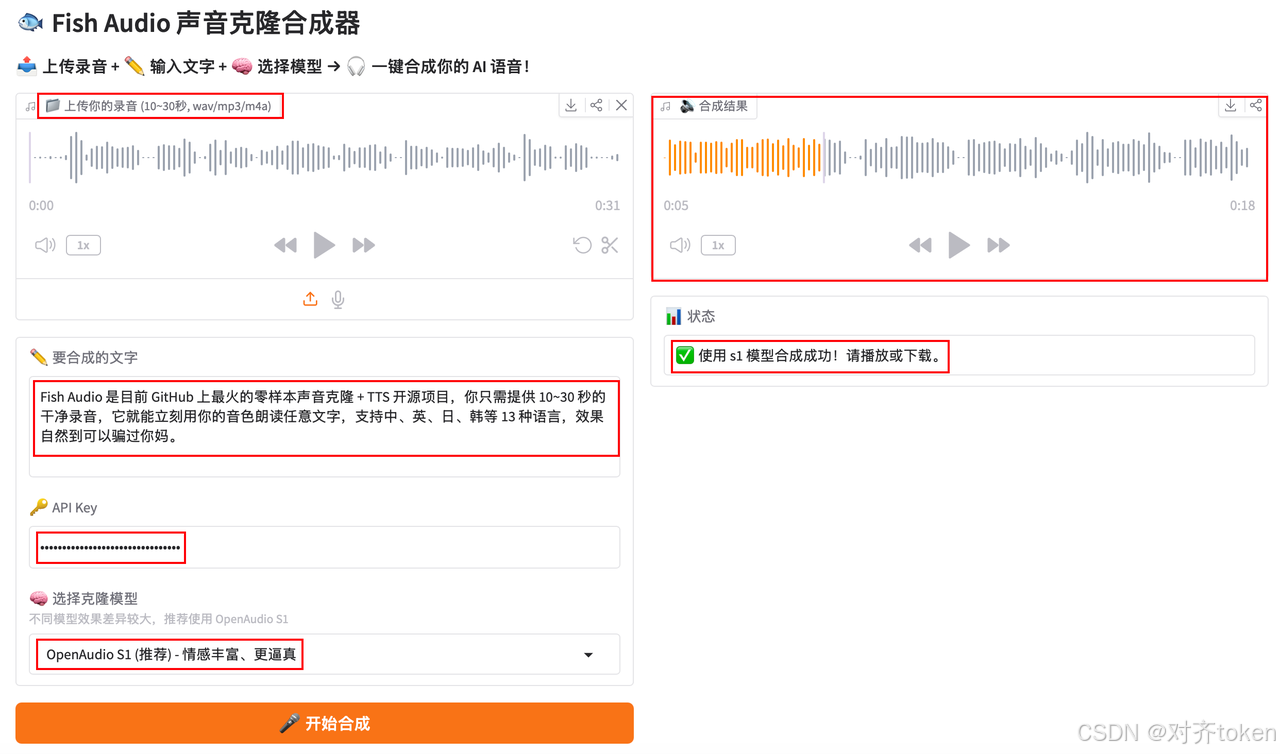
📦 打包成 EXE(可选)
Bash
pip install pyinstaller
pyinstaller --onefile --collect-all gradio fish_tts_gui.py💡 更省事的方案:代码中
demo.launch(share=True)即可生成公网链接(72 小时有效),分享给任何人直接使用!
四、🥊 同期精品大乱斗:谁才是声音克隆之王?
2024~2025 年开源 TTS 迎来大爆发,各家打得不可开交。下面一张表帮你快速选型:
| 🏷️ 维度 | 🐟 Fish Audio | 🎯 CosyVoice(阿里) | ⚡ GPT-SoVITS | 🔥 F5-TTS | 🌍 OpenVoice |
|---|---|---|---|---|---|
| ⭐ GitHub | 17k+ | 13.7k+ | 56k+ | 12k+ | 4k+ |
| 🎤 最少样本 | 10~30 秒 | 3 秒 🏆 | 5 秒 | 2 秒 🏆 | 10 秒 |
| 🌐 语言支持 | 13 种 🏆 | 5 种 + 方言 | 5 种 | 中英 | 6 种 |
| 🎭 情感控制 | S1 模型支持 | 细粒度情感指令 🏆 | 自然继承 | ❌ | 8 种情绪 |
| ⚡ 推理速度 | 中等 | 流式 150ms 🏆 | 快 | RTF 0.15 🏆 | 快 |
| 🎯 音色相似度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 95%+ 🏆 | ⭐⭐⭐ | ⭐⭐⭐ |
| 📜 开源协议 | Apache 2.0 ✅ | Apache 2.0 ✅ | MIT ✅ | MIT ✅ | MIT ✅ |
| 💻 本地部署 | 需 GPU | 需 GPU | 需 GPU | 需 GPU | 需 GPU |
| 🌍 在线 API | ✅ 免费额度 | ✅ 阿里云 | ❌ | ❌ | ❌ |
📌 选型指南(太长不看版) :
- 🧧 中文优先 + 有 API 需求 → 🐟 Fish Audio(语言支持最广,在线 API 可用)
- 🎙️ 追求极致克隆逼真度 → 🎯 CosyVoice / ⚡ GPT-SoVITS(音色相似度天花板)
- 🏭 批量生产 + 极速推理 → 🔥 F5-TTS(2 秒克隆,实时因子 0.15)
- 🎬 需要情感表演 → 🎯 CosyVoice(支持哭腔、方言口音调整)
Fish Audio 的差异化王牌 🃏:它是唯一一个同时提供 在线 API + 免费额度 + 13 语言支持 的开源方案。不需要折腾 GPU,注册就能用,跟 ElevenLabs 这种商业产品对标,但成本只有其 六分之一。
五、🎓 进阶玩家必读:让克隆效果飙升的秘籍
🎤 录音黄金法则
📌 参考音频是克隆的基石,录得好,效果立竿见影:
| ✅ 推荐 | ❌ 避免 |
|---|---|
| 🎧 安静环境,手机就够 | 📢 嘈杂背景、多人说话 |
| ⏱️ 时长 5~30 秒 | 📉 短于 5 秒(信息不足) |
| 🗣️ 自然语速、清晰发音 | 🏃 过快/过慢/刻意朗读 |
| 📱 手机放桌面,距嘴 20~30cm | ✋ 手持手机(摩擦噪音) |
| 🔇 关闭空调、风扇 | 🎵 背景音乐、混响 |
💡 实测发现:只需一部智能手机 + 安静卧室 + 语音备忘录,就能录出可克隆的参考音频。
📈 进阶优化套路
- 🔉 降噪处理:录好的音频可用 Audacity(免费)做轻微降噪
- 📝 提供参考文本 :如果你知道录音内容,务必填入
reference_text,音色对齐准确率大幅提升 - 🎚️ 音量标准化:归一化到 -3dB,避免爆音或过轻
- 🔀 多参考音频融合:准备 2~3 段不同情绪的短录音,克隆效果更稳定、表现力更强
🎭 这些脑洞大开的应用,你绝对想不到
- 🎮 游戏 NPC 配音:某独立游戏团队用 Fish Speech 后,角色对话制作周期从 2 周缩短到 3 天
- 📖 有声书量产:效率提升 60%,一个人就是一个配音工作室
- 👨👩👧 数字分身 & 情感陪伴:把 AI 助手声音设置成孩子或恋人的声音,随时随地听到想听的声音
- 👻 鬼畜整活:克隆朋友的声音说骚话,效果拔群
- 🎓 知识科普新玩法:用克隆的爱因斯坦声线讲解相对论,学生们听得眼睛发光
- 🏠 留学生「在场感」 :有海外留学生用声音克隆保持与国内家人的日常交流,让家人感知到的「在场率」提升 76%
六、📊 API 费用一览 & 本地部署预告
| 💎 套餐 | 💰 价格 | 📦 API 额度(月) | 🏷️ 适合 |
|---|---|---|---|
| 🆓 Free | 免费 | 7 分钟 + 8000 积分 | 尝鲜、个人测试 |
| ⭐ Plus | $11/月(约 ¥80) | 200 分钟 | 自媒体、内容创作者 |
| 🚀 Pro | $75/月(约 ¥540) | 27 小时 | 企业级、批量生产 |
🔮 如果你后期想要完全免费 + 无限调用 + 数据不出门,本地部署是终极选择(需要 NVIDIA 显卡,显存 ≥ 8GB)。需要的话告诉我,我为你出完整教程!
七、🐟 总结
| 你的需求 | 推荐方案 |
|---|---|
| 🧪 我就想试试,零成本 | 注册 API → 免费额度 → 跑 Demo |
| ✍️ 自媒体/内容创作 | Plus $11/月,性价比拉满 |
| 🏭 批量生产 | Pro 套餐或本地部署 |
| 🔒 数据敏感/离线使用 | 本地部署(需 GPU) |
🎉 恭喜你读到这里!现在你已经是 声音克隆理论 + 实战 双修的选手了。
📣 有任何问题(本地部署教程、效果调优、API 报错排查),随时告诉我,我给你续上!
关注我,送你一个月的"plus"会员权益