Python 实用工具与机器学习入门:Rich + Tqdm + Faker + Schedule + Scikit-learn
专栏:Python 常用工具库实战教程 | 第五篇
适合人群:Python 开发者、数据分析师、自动化运维工程师
目录
- 前言:实用工具的价值
- [第一章:Rich ------ 让终端焕然一新](#第一章:Rich —— 让终端焕然一新)
- [1.1 Rich 是什么](#1.1 Rich 是什么)
- [1.2 彩色文字与样式](#1.2 彩色文字与样式)
- [1.3 精美表格](#1.3 精美表格)
- [1.4 面板与布局](#1.4 面板与布局)
- [1.5 语法高亮](#1.5 语法高亮)
- [1.6 进度条](#1.6 进度条)
- [1.7 树形结构与日志](#1.7 树形结构与日志)
- [1.8 Emoji 与状态图标](#1.8 Emoji 与状态图标)
- [第二章:Tqdm ------ 最优雅的进度条](#第二章:Tqdm —— 最优雅的进度条)
- [2.1 基本用法](#2.1 基本用法)
- [2.2 手动控制](#2.2 手动控制)
- [2.3 与 Pandas/NumPy 配合](#2.3 与 Pandas/NumPy 配合)
- [第三章:Faker ------ 造数据的神器](#第三章:Faker —— 造数据的神器)
- [3.1 基本用法](#3.1 基本用法)
- [3.2 多语言支持](#3.2 多语言支持)
- [3.3 数据导出](#3.3 数据导出)
- [第四章:Schedule ------ 优雅的定时任务](#第四章:Schedule —— 优雅的定时任务)
- [4.1 基本用法](#4.1 基本用法)
- [4.2 复杂调度](#4.2 复杂调度)
- [4.3 实战案例](#4.3 实战案例)
- [第五章:Scikit-learn ------ 机器学习入门](#第五章:Scikit-learn —— 机器学习入门)
- [5.1 机器学习概述](#5.1 机器学习概述)
- [5.2 数据准备与预处理](#5.2 数据准备与预处理)
- [5.3 监督学习:分类](#5.3 监督学习:分类)
- [5.4 监督学习:回归](#5.4 监督学习:回归)
- [5.5 无监督学习:聚类](#5.5 无监督学习:聚类)
- [5.6 模型评估与交叉验证](#5.6 模型评估与交叉验证)
- 总结
前言
除了核心的数据处理库之外,Python 生态还有大量实用的小工具,它们虽然不起眼,却能在日常开发中大幅提升效率。本章将介绍四个实用工具和一个机器学习框架:
| 工具 | 定位 | 一句话 |
|---|---|---|
| Rich | 终端美化 | 让命令行输出像艺术品 |
| Tqdm | 进度条 | 让等待不再焦虑 |
| Faker | 数据生成 | 一键生成海量假数据 |
| Schedule | 定时任务 | 最优雅的 cron 替代 |
| Scikit-learn | 机器学习 | 机器学习界的瑞士军刀 |
第一章:Rich ------ 让终端焕然一新
1.1 Rich 是什么
Rich 是一个 Python 库,可以让你的终端输出变得五彩斑斓。它支持彩色文字、精美表格、进度条、语法高亮、树形结构等。如果你在开发 CLI 工具或命令行程序,Rich 是必备神器。
bash
pip install rich
python
from rich.console import Console
console = Console()1.2 彩色文字与样式
Rich 支持丰富的文字样式:
python
from rich.console import Console
console = Console()
# 基本颜色
console.print("红色警告", style="bold red")
console.print("绿色成功", style="bold green")
console.print("蓝色信息", style="bold blue")
# 背景色
console.print("黄底黑字", style="black on yellow")
# 渐变效果
for i, char in enumerate("Hello, Rich!"):
console.print(char, style=f"rgb({i*20},{255-i*10},{128+i*10})", end="")
console.print()
# 标记语法(类似HTML)
console.print("[bold red]重要[/bold red]: [green]操作成功[/green]")
console.print("[bold cyan]Python[/bold cyan] is [italic]awesome[/italic]!")
console.print("[link=https://python.org]点击访问 Python 官网[/link]")支持的样式属性:
| 类别 | 值 | 示例 |
|---|---|---|
| 颜色 | red, green, blue, yellow, magenta, cyan, white |
style="red" |
| 亮色 | bright_red, bright_green... |
style="bright_cyan" |
| RGB | rgb(r,g,b) |
style="rgb(255,100,50)" |
| 背景 | on red, on #ffffff |
style="on blue" |
| 粗体 | bold |
style="bold" |
| 斜体 | italic |
style="italic" |
| 下划线 | underline |
style="underline" |
| 删除线 | strike |
style="strike" |
| 反转 | reverse |
style="reverse" |
| 闪烁 | blink |
style="blink" |
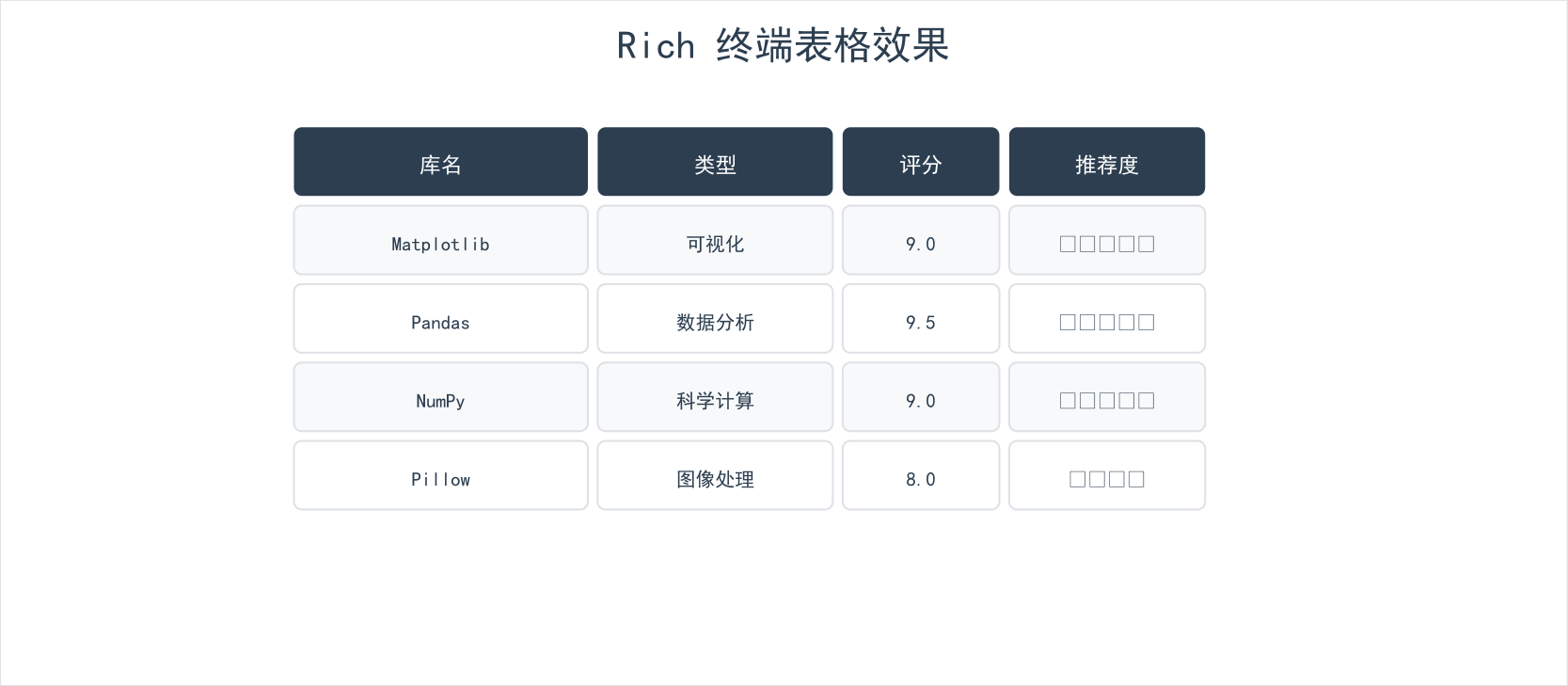
1.3 精美表格
Rich 最引以为傲的功能就是精美的表格输出:
python
from rich.table import Table
from rich import box
table = Table(title="Python 工具库速查表", box=box.ROUNDED,
show_lines=True, title_style="bold magenta",
border_style="bright_blue")
table.add_column("库名", style="bold cyan", width=15)
table.add_column("用途", style="green", width=30)
table.add_column("安装命令", style="yellow", width=25)
table.add_column("评分", justify="center", width=8)
table.add_row("NumPy", "数组运算、矩阵计算", "pip install numpy", "⭐⭐⭐⭐⭐")
table.add_row("Pandas", "数据分析、表格处理", "pip install pandas", "⭐⭐⭐⭐⭐")
table.add_row("Matplotlib", "数据可视化", "pip install matplotlib", "⭐⭐⭐⭐⭐")
table.add_row("Requests", "HTTP请求", "pip install requests", "⭐⭐⭐⭐⭐")
table.add_row("Pillow", "图像处理", "pip install pillow", "⭐⭐⭐⭐")
table.add_row("BeautifulSoup", "HTML解析", "pip install beautifulsoup4", "⭐⭐⭐⭐")
table.add_row("Scrapy", "爬虫框架", "pip install scrapy", "⭐⭐⭐⭐")
table.add_row("Rich", "终端美化", "pip install rich", "⭐⭐⭐⭐")
console.print(table)运行效果(终端中会显示彩色精美表格):
1.4 面板与布局
python
from rich.panel import Panel
from rich.columns import Columns
# 基本面板
console.print(Panel("面板内容", title="标题", border_style="green"))
# 多面板并排
panel1 = Panel("左侧面板", border_style="green")
panel2 = Panel("右侧面板", border_style="blue")
console.print(Columns([panel1, panel2]))
# 带副标题和边框的面板
long_text = """Rich 库是 Python 中最强大的终端美化库之一。
它可以创建精美的表格、进度条、语法高亮代码块等。"""
console.print(Panel(long_text, title="Rich 库简介",
border_style="magenta", subtitle="Python 终端利器"))1.5 语法高亮
python
from rich.syntax import Syntax
code = '''def fibonacci(n):
"""计算第n个斐波那契数"""
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
# 计算前10个
for i in range(10):
print(f"fib({i}) = {fibonacci(i)}")'''
syntax = Syntax(code, "python", theme="monokai", line_numbers=True)
console.print(Panel(syntax, title="Python 代码示例", border_style="cyan"))支持的语言包括:Python、JavaScript、Java、C++、Go、Rust、SQL、JSON、YAML、Markdown 等 100+ 种。
1.6 进度条
python
from rich.progress import (Progress, SpinnerColumn, TextColumn,
BarColumn, TimeElapsedColumn, MofNCompleteColumn)
import time
with Progress(
SpinnerColumn(),
TextColumn("[progress.description]{task.description}"),
BarColumn(bar_width=40),
TextColumn("[progress.percentage]{task.percentage:>3.0f}%"),
MofNCompleteColumn(),
TimeElapsedColumn(),
console=console,
) as progress:
task1 = progress.add_task("[red]下载数据...", total=100)
task2 = progress.add_task("[green]处理中...", total=100)
task3 = progress.add_task("[blue]分析中...", total=100)
while not progress.finished:
progress.update(task1, advance=1.5)
progress.update(task2, advance=1.2)
progress.update(task3, advance=0.8)
time.sleep(0.05)1.7 树形结构与日志
python
from rich.tree import Tree
from rich.console import Console
# 树形结构
tree = Tree("📁 project", guide_style="bold cyan")
tree.add("📄 requirements.txt")
src = tree.add("📁 src")
src.add("📄 main.py")
src.add("📄 utils.py")
tests = tree.add("📁 tests")
tests.add("📄 test_main.py")
console.print(tree)
# 日志
from rich.logging import RichHandler
import logging
logging.basicConfig(
level=logging.INFO,
format="%(message)s",
datefmt="[%X]",
handlers=[RichHandler()]
)
logger = logging.getLogger("rich")
logger.info("服务启动成功")
logger.warning("内存使用率超过80%")
logger.error("连接数据库失败")1.8 Emoji 与状态图标
Rich 支持 Emoji 和状态图标,让输出更加直观:
python
console.print("✅ 任务完成")
console.print("❌ 连接失败")
console.print("⚠️ 警告: 内存不足")
console.print("ℹ️ 提示: 请更新版本")
console.print("🚀 部署成功!")
console.print("📦 正在安装依赖...")
console.print("🔍 搜索中...")
console.print("🔑 请先登录")
console.print("📊 数据分析完成")
console.print("🔄 正在同步...")Rich 还能导出为 HTML:
python
html = console.export_html(clear=False)
with open('output.html', 'w') as f:
f.write(html)第二章:Tqdm ------ 最优雅的进度条
2.1 基本用法
Tqdm(来自阿拉伯语 taqaddum,意为"进展")是 Python 中最流行的进度条库。它几乎零侵入------只需要一行代码就能给任何迭代器加上进度条。
bash
pip install tqdm
python
from tqdm import tqdm
import time
# 最简单的用法:直接包裹可迭代对象
for i in tqdm(range(100)):
time.sleep(0.02)
# 输出: 100%|██████████| 100/100 [00:02<00:00, 49.50it/s]
# 自定义描述
for i in tqdm(range(100), desc="下载进度", unit="MB"):
time.sleep(0.02)
# 输出: 下载进度: 100%|██████████| 100/100 [00:02<00:00, 49.50MB/s]
# 处理列表
data = list(range(1000))
for item in tqdm(data, desc="处理数据"):
# 处理每个数据项
pass2.2 手动控制
python
from tqdm import tqdm
import time
# 手动更新进度
with tqdm(total=100, desc="安装中", unit="%) as pbar:
for i in range(10):
time.sleep(0.5)
pbar.update(10) # 每次更新10%
# 自定义后缀信息
with tqdm(total=100, desc="传输") as pbar:
for i in range(100):
time.sleep(0.02)
pbar.set_postfix(loss=0.1/(i+1), acc=0.9+i*0.001)
pbar.update(1)
# 输出: 传输: 100%|██████████| 100/100 [00:02<00:00, loss=0.001, acc=0.991]2.3 与 Pandas/NumPy 配合
python
import pandas as pd
from tqdm import tqdm
# Pandas apply 进度条
tqdm.pandas(desc="Pandas处理")
df = pd.DataFrame({'data': range(1000)})
df['result'] = df['data'].progress_apply(lambda x: x ** 2)
# NumPy 手动进度
import numpy as np
data = np.random.rand(10000)
results = []
for i in tqdm(range(0, len(data), 100), desc="NumPy批量"):
batch = data[i:i+100]
results.extend(batch ** 2)Tqdm 参数速查:
| 参数 | 说明 | 示例 |
|---|---|---|
total |
总数量 | total=100 |
desc |
描述文字 | desc="下载中" |
unit |
单位 | unit="MB" |
ncols |
进度条宽度 | ncols=80 |
position |
多进度条位置 | position=0 |
leave |
完成后保留 | leave=False |
file |
输出到文件 | file=open('log.txt','w') |
第三章:Faker ------ 造数据的神器
3.1 基本用法
在开发和测试时,经常需要大量的模拟数据。Faker 可以一键生成各种逼真的假数据。
bash
pip install faker
python
from faker import Faker
fake = Faker('zh_CN') # 中文数据
# 个人信息
print(fake.name()) # 王伟
print(fake.phone_number()) # 13912345678
print(fake.address()) # 安徽省合肥市蜀山区XX路XX号
print(fake.email()) # wei@example.com
print(fake.company()) # 腾讯科技有限公司
print(fake.job()) # 软件工程师
print(fake.credit_card_number()) # 4123456789012345
# 文本
print(fake.text()) # 随机文本
print(fake.sentence()) # 随机句子
print(fake.paragraph()) # 随机段落
# 日期时间
print(fake.date()) # 2025-03-15
print(fake.date_time()) # 2025-03-15 14:30:00
print(fake.year()) # 2025
# 互联网
print(fake.user_name()) # zhangsan
print(fake.url()) # https://example.com/xxx
print(fake.ipv4()) # 192.168.1.1
print(fake.user_agent()) # Mozilla/5.0 ...
# 地理位置
print(fake.latitude()) # 31.2304
print(fake.longitude()) # 121.47373.2 多语言支持
Faker 支持 40+ 种语言和地区:
python
from faker import Faker
# 中文
zh = Faker('zh_CN')
print(zh.name()) # 李明
print(zh.address()) # 四川省成都市...
# 英文
en = Faker('en_US')
print(en.name()) # John Smith
print(en.address()) # 123 Main St, Springfield, IL
# 日文
ja = Faker('ja_JP')
print(ja.name()) # 山田太郎
# 韩文
ko = Faker('ko_KR')
print(ko.name()) # 김민수
# 多语言混合
multi = Faker(['zh_CN', 'en_US', 'ja_JP'])
for _ in range(3):
print(multi.name())3.3 数据导出
python
from faker import Faker
import pandas as pd
import json
fake = Faker('zh_CN')
# 生成 DataFrame
users = []
for _ in range(100):
users.append({
'姓名': fake.name(),
'年龄': fake.random_int(min=18, max=65),
'手机号': fake.phone_number(),
'邮箱': fake.email(),
'地址': fake.address(),
'公司': fake.company(),
'职位': fake.job(),
'注册日期': fake.date_between(start_date='-2y', end_date='today'),
'评分': round(fake.pyfloat(min_value=1.0, max_value=5.0), 1)
})
df = pd.DataFrame(users)
# 导出为 CSV
df.to_csv('fake_users.csv', index=False, encoding='utf-8-sig')
# 导出为 JSON
df.to_json('fake_users.json', orient='records', force_ascii=False, indent=2)
# 导出为 Excel
df.to_excel('fake_users.xlsx', index=False)
print(f"已生成 {len(df)} 条假数据")
print(df.head())自定义数据生成器:
python
from faker import Faker
from faker.providers import BaseProvider
fake = Faker('zh_CN')
# 自定义 Provider
class ProductProvider(BaseProvider):
def product_category(self):
categories = ['电子产品', '服装', '食品', '图书', '家居', '运动']
return self.random_element(categories)
def product_name(self):
brands = ['苹果', '华为', '小米', '索尼', '三星']
types = ['手机', '笔记本', '耳机', '手表', '平板']
return f"{self.random_element(brands)} {self.random_element(types)}"
def order_status(self):
statuses = ['待付款', '已付款', '已发货', '已签收', '已取消']
return self.random_element(statuses)
# 注册 Provider
fake.add_provider(ProductProvider)
# 使用
for _ in range(5):
print(f"商品: {fake.product_name()}")
print(f"类别: {fake.product_category()}")
print(f"状态: {fake.order_status()}")
print("---")第四章:Schedule ------ 优雅的定时任务
4.1 基本用法
Schedule 是一个轻量级的定时任务库,API 设计非常人性化。
bash
pip install schedule
python
import schedule
import time
# 每隔10秒执行
def job():
print("任务执行中...")
schedule.every(10).seconds.do(job)
schedule.every(1).minutes.do(job)
schedule.every(2).hours.do(job)
schedule.every().day.at("10:30").do(job)
schedule.every().monday.do(job)
schedule.every().wednesday.at("13:15").do(job)
while True:
schedule.run_pending()
time.sleep(1)4.2 复杂调度
python
import schedule
# 带参数的函数
def greet(name):
print(f"Hello, {name}!")
schedule.every(5).seconds.do(greet, name="Alice")
# 取消任务
job = schedule.every(5).seconds.do(greet, name="Bob")
schedule.cancel_job(job)
# 仅执行一次
def once_job():
print("只执行一次!")
return schedule.CancelJob # 返回 CancelJob 自动取消
schedule.every(10).seconds.do(once_job)
# 链式调用
schedule.every(1).hour.at(":30").do(job) # 每小时的第30分钟
schedule.every().hour.at("09:30").do(job) # 每天09:30
schedule.every().day.at("09:30:00").do(job) # 精确到秒
# 查看已注册的任务
print(schedule.get_jobs())
# 时间单位
schedule.every(1).second
schedule.every(1).minute
schedule.every(1).hour
schedule.every(1).day
schedule.every(1).week
# 星期
schedule.every().monday
schedule.every().tuesday
schedule.every().wednesday
schedule.every().thursday
schedule.every().friday
schedule.every().saturday
schedule.every().sunday4.3 实战案例
python
import schedule
import time
from datetime import datetime
def log(msg):
print(f"[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] {msg}")
def check_server():
"""模拟服务器健康检查"""
log("🔍 检查服务器状态...")
# 实际应用中用 requests 发起健康检查
log("✅ 服务器正常")
def backup_database():
"""模拟数据库备份"""
log("💾 开始数据库备份...")
log("✅ 备份完成")
def generate_report():
"""模拟生成日报"""
log("📊 生成日报...")
log("✅ 日报已发送")
def cleanup_temp():
"""模拟清理临时文件"""
log("🧹 清理临时文件...")
log("✅ 清理完成")
# 注册定时任务
schedule.every(5).minutes.do(check_server)
schedule.every().day.at("02:00").do(backup_database)
schedule.every().day.at("09:00").do(generate_report)
schedule.every().saturday.at("03:00").do(cleanup_temp)
log("🚀 定时任务服务启动")
log(f"已注册 {len(schedule.get_jobs())} 个任务")
while True:
schedule.run_pending()
time.sleep(1)Schedule vs Cron 对比:
| 特性 | Schedule | Cron |
|---|---|---|
| Python 原生 | 是 | 否(系统工具) |
| 可读性 | 极高 | 低(需要记忆语法) |
| 跨平台 | 是 | 是(但语法不同) |
| 守护进程 | 需自己实现 | 自带 |
| 分布式 | 不支持 | 不支持 |
| 适用场景 | 简单定时任务 | 系统级复杂调度 |
第五章:Scikit-learn ------ 机器学习入门
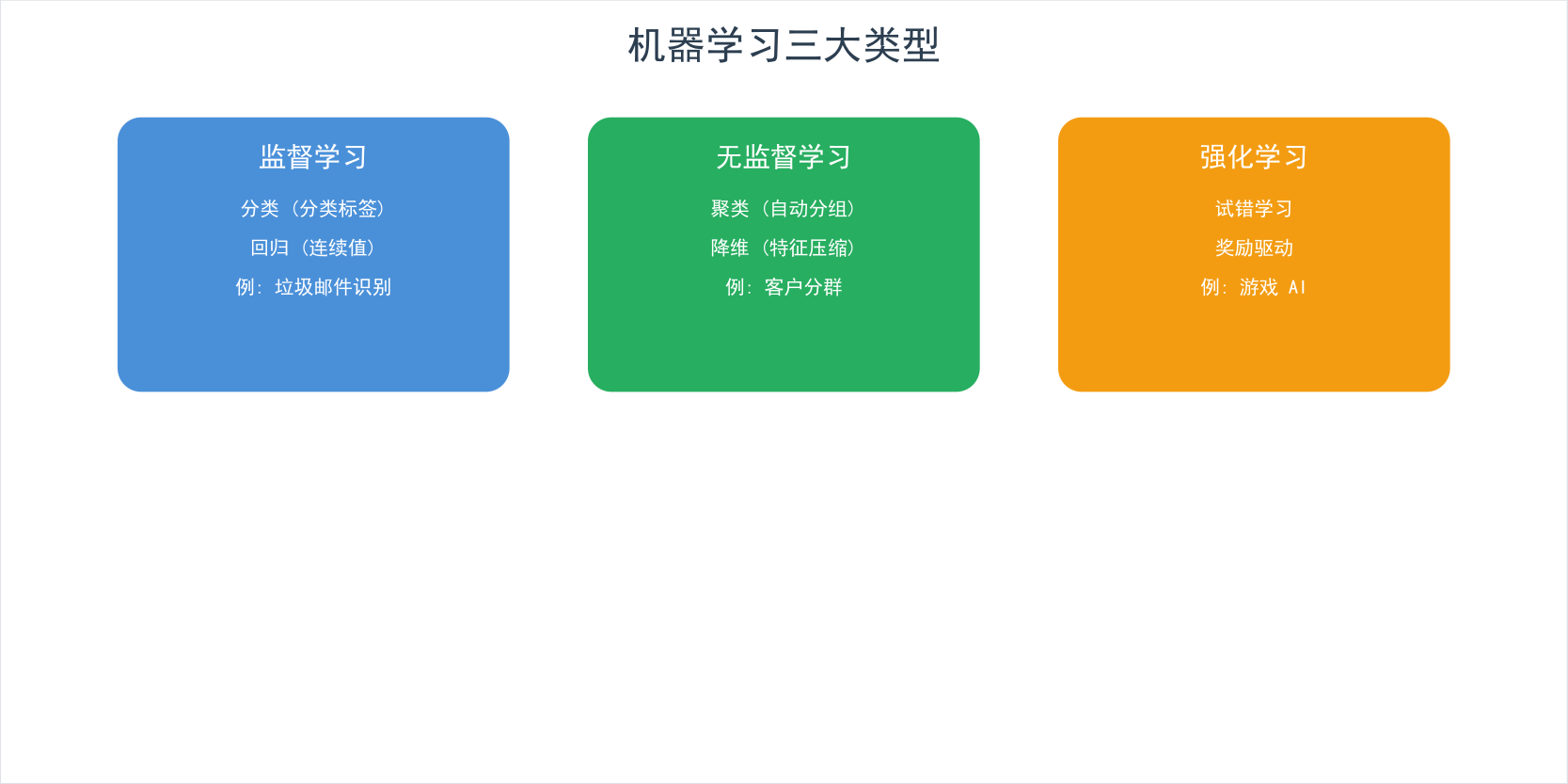
5.1 机器学习概述
Scikit-learn(简称 sklearn)是 Python 中最流行的机器学习库。它提供了从数据预处理到模型评估的完整工具链。
bash
pip install scikit-learn机器学习的三大类型:
5.2 数据准备与预处理
python
import numpy as np
from sklearn.datasets import load_iris, load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 加载内置数据集
iris = load_iris()
X = iris.data # 特征 (150, 4)
y = iris.target # 标签 (150,)
print(f"特征数: {X.shape[1]}")
print(f"样本数: {X.shape[0]}")
print(f"类别数: {len(np.unique(y))}")
print(f"特征名称: {iris.feature_names}")
print(f"类别名称: {iris.target_names}")
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集: {len(X_train)}, 测试集: {len(X_test)}")
# 特征标准化 (Z-score)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 用训练集fit
X_test_scaled = scaler.transform(X_test) # 用训练集的参数transform测试集
# 特征归一化 (Min-Max)
normalizer = MinMaxScaler()
X_train_normalized = normalizer.fit_transform(X_train)
X_test_normalized = normalizer.transform(X_test)预处理方法对比:
| 方法 | 公式 | 范围 | 适用场景 |
|---|---|---|---|
| StandardScaler | (x - μ) / σ | 无界 | 大多数算法 |
| MinMaxScaler | (x - min) / (max - min) | 0, 1 | 神经网络 |
| RobustScaler | (x - median) / IQR | 无界 | 有离群值的数据 |
| MaxAbsScaler | x / max | -1, 1 | 稀疏数据 |
5.3 监督学习:分类
逻辑回归
python
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
model = LogisticRegression(max_iter=200)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
print(f"准确率: {accuracy_score(y_test, y_pred):.4f}")
print(classification_report(y_test, y_pred, target_names=iris.target_names))决策树
python
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"准确率: {accuracy_score(y_test, y_pred):.4f}")
# 特征重要性
for name, importance in zip(iris.feature_names, model.feature_importances_):
print(f" {name}: {importance:.4f}")随机森林
python
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"准确率: {accuracy_score(y_test, y_pred):.4f}")
print("Top 3 特征重要性:")
indices = np.argsort(model.feature_importances_)[::-1][:3]
for i in indices:
print(f" {iris.feature_names[i]}: {model.feature_importances_[i]:.4f}")支持向量机 (SVM)
python
from sklearn.svm import SVC
model = SVC(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
print(f"SVM 准确率: {accuracy_score(y_test, y_pred):.4f}")K 近邻 (KNN)
python
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
print(f"KNN 准确率: {accuracy_score(y_test, y_pred):.4f}")分类算法对比:
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 逻辑回归 | 简单快速、可解释 | 只能线性分类 | 二分类基线 |
| 决策树 | 可解释、无需归一化 | 容易过拟合 | 特征分析 |
| 随机森林 | 精度高、抗过拟合 | 较慢、不可解释 | 通用分类 |
| SVM | 小数据精度高 | 大数据慢 | 小数据集 |
| KNN | 简单直观 | 大数据慢 | 小数据集 |
| XGBoost | 精度最高 | 需调参 | 竞赛、业务 |
5.4 监督学习:回归
python
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
# 加载房价数据
housing = fetch_california_housing()
X, y = housing.data, housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 线性回归
lr = LinearRegression()
lr.fit(X_train_scaled, y_train)
y_pred = lr.predict(X_test_scaled)
print("=== 线性回归 ===")
print(f"MSE: {mean_squared_error(y_test, y_pred):.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred)):.4f}")
print(f"MAE: {mean_absolute_error(y_test, y_pred):.4f}")
print(f"R²: {r2_score(y_test, y_pred):.4f}")
# 随机森林回归
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print("\n=== 随机森林 ===")
print(f"MSE: {mean_squared_error(y_test, y_pred_rf):.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_rf)):.4f}")
print(f"MAE: {mean_absolute_error(y_test, y_pred_rf):.4f}")
print(f"R²: {r2_score(y_test, y_pred_rf):.4f}")回归指标解读:
| 指标 | 说明 | 值域 | 越好越 |
|---|---|---|---|
| MSE | 均方误差 | [0, ∞) | 小 |
| RMSE | 均方根误差 | [0, ∞) | 小 |
| MAE | 平均绝对误差 | [0, ∞) | 小 |
| R² | 决定系数 | (-∞, 1] | 大 |
5.5 无监督学习:聚类
python
from sklearn.cluster import KMeans, DBSCAN
from sklearn.decomposition import PCA
# 使用 Iris 数据做聚类
X_scaled = StandardScaler().fit_transform(iris.data)
# K-Means
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
clusters = kmeans.fit_predict(X_scaled)
# 对比聚类结果与真实标签
from collections import Counter
print("K-Means 聚类结果:")
for i in range(3):
mask = clusters == i
labels = y[mask]
dominant = Counter(labels).most_common(1)[0][0]
print(f" 簇 {i}: {mask.sum()} 样本, 主导类别: {iris.target_names[dominant]}")
# 降维可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
for i in range(3):
mask = y == i
plt.scatter(X_pca[mask, 0], X_pca[mask, 1], label=iris.target_names[i])
plt.title('真实标签')
plt.legend()
plt.subplot(1, 2, 2)
for i in range(3):
mask = clusters == i
plt.scatter(X_pca[mask, 0], X_pca[mask, 1], label=f'簇 {i}')
plt.title('K-Means 聚类')
plt.legend()
plt.tight_layout()
plt.savefig('images/cluster_comparison.png', dpi=150)5.6 模型评估与交叉验证
python
from sklearn.model_selection import cross_val_score, GridSearchCV
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 交叉验证
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print(f"5折交叉验证准确率: {scores.mean():.4f} ± {scores.std():.4f}")
# 网格搜索超参数调优
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 10, None],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid, cv=5, scoring='accuracy', n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳准确率: {grid_search.best_score_:.4f}")
print(f"测试集准确率: {grid_search.score(X_test, y_test):.4f}")
# 混淆矩阵
y_pred = grid_search.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(cm, display_names=iris.target_names)
disp.plot(cmap='Blues')
plt.title('混淆矩阵')
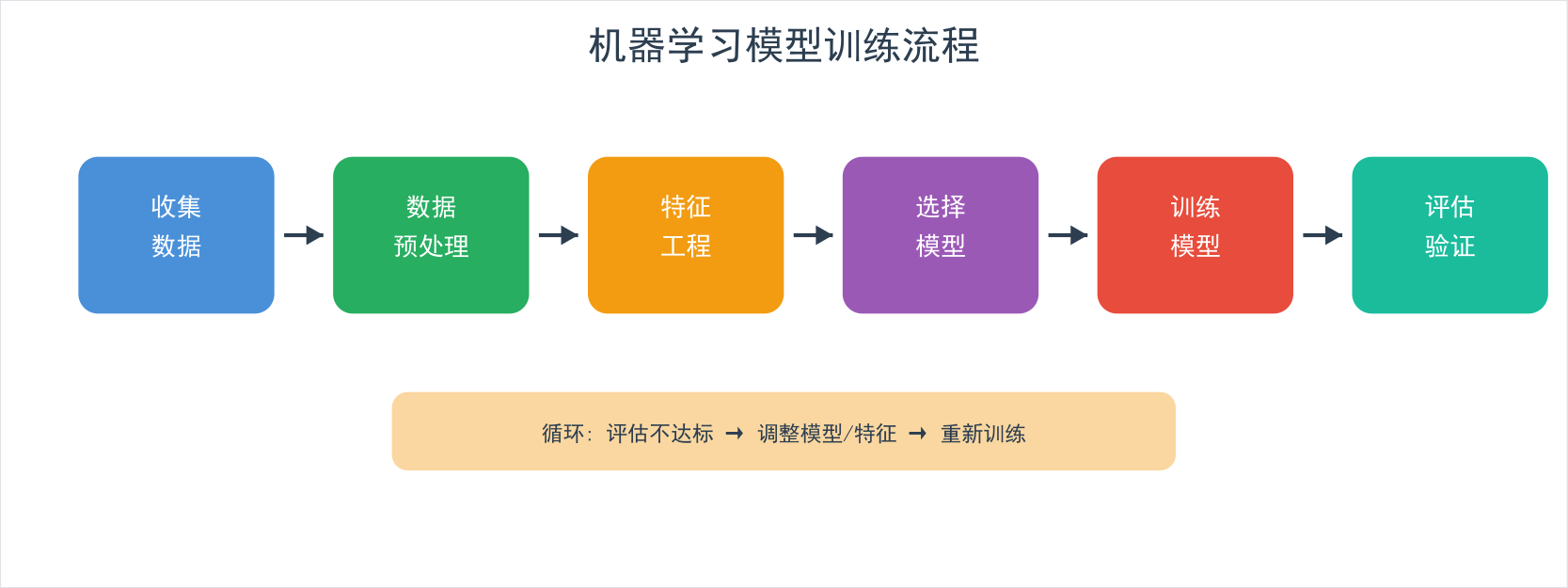
plt.savefig('images/confusion_matrix.png', dpi=150)模型选择流程:
总结
工具选择速查表
| 你的需求 | 推荐工具 | 安装命令 |
|---|---|---|
| 终端输出美化 | Rich | pip install rich |
| 进度条 | Tqdm | pip install tqdm |
| 生成测试数据 | Faker | pip install faker |
| 定时任务 | Schedule | pip install schedule |
| 机器学习 | Scikit-learn | pip install scikit-learn |
| 深度学习 | PyTorch / TensorFlow | pip install torch |
完整安装命令
bash
pip install rich tqdm faker schedule scikit-learn numpy pandas matplotlib学习路线
下一篇预告:《Python 游戏开发与文件处理:PyGame + Turtle + openpyxl + python-docx 实战》------ 用 Python 做游戏、画图形、处理 Excel 和 Word!