快速了解部分
基础信息(英文):
- 题目: VGGT-Ω
- 时间: 2026.05
- 机构: Visual Geometry Group, University of Oxford / Meta AI
- 3个英文关键词: Feed-forward Reconstruction, Vision Transformer (ViT), 4D Reconstruction
1句话通俗总结本文干了什么事情
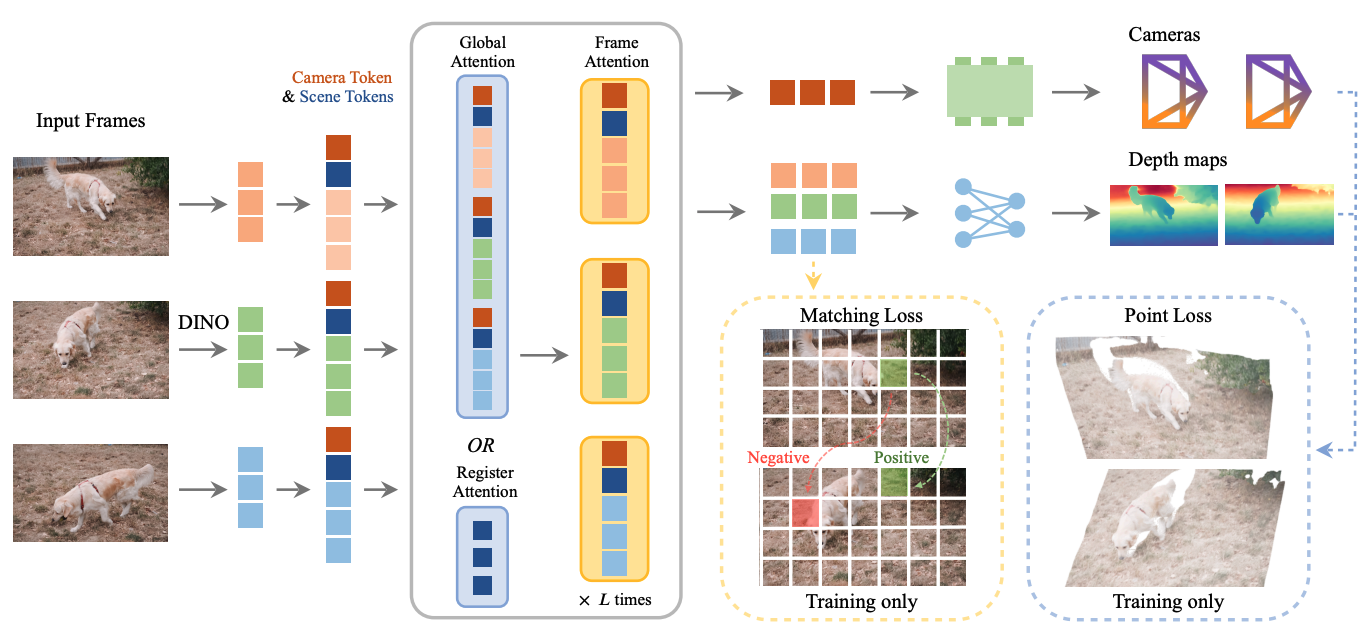
本文提出了一种名为 VGGT-Ω 的模型,旨在通过扩大模型和数据规模,并改进架构(如引入 Register Attention),实现更快速、更准确的静态和动态场景 3D 重建。
研究痛点:现有研究不足 / 要解决的具体问题
- 效率与能力的平衡:现有的 feed-forward 重建模型(如 VGGT)虽然比传统优化方法(如 COLMAP)快,但在处理动态场景(4D)时能力不足,且显存占用高。
- 数据瓶颈:处理动态内容需要大量数据,但高质量的标注数据稀缺,且现有模型在处理互联网风格的视频时鲁棒性不够。
核心方法:关键技术、模型或研究设计(简要)
通过引入 Register Attention 机制减少计算量,并开发了一套高质量的数据标注流水线,结合自监督学习,在扩大模型和数据规模的同时,显著降低了训练显存占用,实现了 SOTA 的重建效果。
深入了解部分
作者想要表达什么
作者试图证明:重建模型(Reconstruction Models)可以作为通用的"基础模型"。通过像训练大语言模型一样扩大规模(Scaling Laws),结合高效的架构改进(如 Register),不仅可以解决复杂的动态场景重建问题,还能生成具有高级语义(如可与语言对齐)的空间特征,而不仅仅是简单的几何数据。
相比前人创新在哪里
- 架构革新(效率核心) :提出了 Register Attention。不同于传统的全局注意力(Global Attention)让所有像素互相计算,Register Attention 引入"寄存器"(Registers)作为信息交换的瓶颈,大幅降低了显存消耗(仅需前代的 30%),使得训练超大规模模型成为可能。
- 数据处理(规模核心):建立了一套针对动态视频的自动标注流水线,从 4000 万视频中筛选出高质量数据,并引入自监督学习(Teacher-Student 模式),利用了海量无标签视频。
- 能力扩展:证明了该模型不仅能做几何重建,其提取的特征(Registers)还能直接用于机器人 VLA 任务和语言对齐,展示了其作为通用空间理解模型的潜力。
解决方法/算法的通俗解释
想象你要拼一张巨大的全景图(3D 重建):
- 以前的做法(Global Attention) :让图上的每一个碎片都去和其他所有碎片对话,确认位置。这非常准确但极慢且费内存。
- VGGG-Ω 的做法(Register Attention):设立几个"小组长"(Registers)。碎片们先把信息汇报给小组长,小组长之间进行沟通协调,再把指令传回给碎片。这样沟通成本大大降低(效率提升),且依然能拼出完整的图。
- 数据方面:作者写了一套程序,能自动给网上的视频"打标签"(生成深度和相机参数),解决了"没题库刷分"的问题。
解决方法的具体做法
- 模型架构 :基于 ViT (DINOv3),在帧内注意力和全局注意力层之间交替。关键改进是用 Register Attention 替换了 25% 的全局注意力层。
- 训练策略 :
- 多任务学习:同时监督深度图、相机参数、点云匹配等任务,但只保留一个轻量级的密集预测头(Decoder),去掉了冗余的卷积层。
- 自监督:使用教师-学生网络(Teacher-Student),在无标签视频上进行对比学习。
- 数据流水线:利用 VLM 进行视频初筛 -> 提取特征 -> 使用 COLMAP 进行稀疏重建 -> 几何过滤器剔除坏数据 -> 生成伪标签。
基于前人的哪些方法
- VGGT:本文的基础模型,作者在 VGGT 的基础上进行了架构优化。
- DINOv3:作为视觉 backbone 的初始化。
- Registers (寄存器):借鉴了之前 ViT 中使用可学习寄存器来携带全局信息的思想,并将其应用于跨帧的信息交换。
- MegaSaM / COLMAP:作为传统优化方法的代表,本文在实验部分将其作为主要对比基准,证明自己方法的优越性。
实验设置、数据、评估方式、结论
- 设置:训练了 4 个变体(200M, 500M, 1B, 10B 参数),使用 128 块 H100 GPU。
- 数据:混合了 400 万序列的高质量数据(含 20 万动态场景)和 1800 万无标签视频。
- 评估 :
- 静态数据集:7 Scenes, NRGBD, ETH3D。
- 动态数据集:DyCheck, Sintel, TUM-Dynamic。
- 指标 :相机姿态估计(AUC)、深度估计(AbsRel, δ1.25\delta_{1.25}δ1.25)。
- 结论 :VGGT-Ω 在所有基准测试中均超越了 SOTA 方法(如 Depth Anything 3, MegaSaM)。例如在 Sintel 动态数据集上,相机估计准确率(AUC@3°)相对提升了 77%,且推理速度极快。
提到的同类工作
- VGGT (前代模型)
- Depth Anything 3 (DA3) (竞品,也是通用重建模型)
- MegaSaM (基于优化的动态重建 SOTA)
- DUSt3R / MASt3R (同类 feed-forward 重建方法)
- DINO / DINOv2 (使用的 backbone 技术来源)
和本文相关性最高的3个文献
- VGGT (Wang et al., CVPR 2025):这是本文的直接前身,本文所有的改进都是基于 VGGT 的架构进行的。
- Depth Anything 3 (Lin et al., arXiv 2025):这是目前该领域最强的竞品之一,本文在实验部分花费大量篇幅与之对比,证明自己在动态场景和效率上的优势。
- DINOv2 (Oquab et al., 2024):本文模型的 backbone 初始化来源,对于模型能够快速收敛和具备良好的特征提取能力至关重要。
我的
- 改进了注意力,省显存了
- matching loss思想是让离得近的tokens要尽量像
- 提取的feature在VLA上验证,有助于机器人操作。