本文面向需要批量获取亚马逊类目节点数据的技术团队,对比官方PA-API与第三方采集方案的优劣,并提供完整的Python调用示例。
前言
在构建亚马逊数据分析系统时,亚马逊商品类目节点数据是最基础也是最容易被低估的数据资产。无论是选品工具、竞品监控系统,还是广告投放优化平台,都需要依赖完整的Browse Node分类树来定位商品所属类目、分析细分市场容量。
本文将深入探讨三种主流采集方案的技术细节,重点介绍如何通过专业API实现高效、稳定的数据获取。
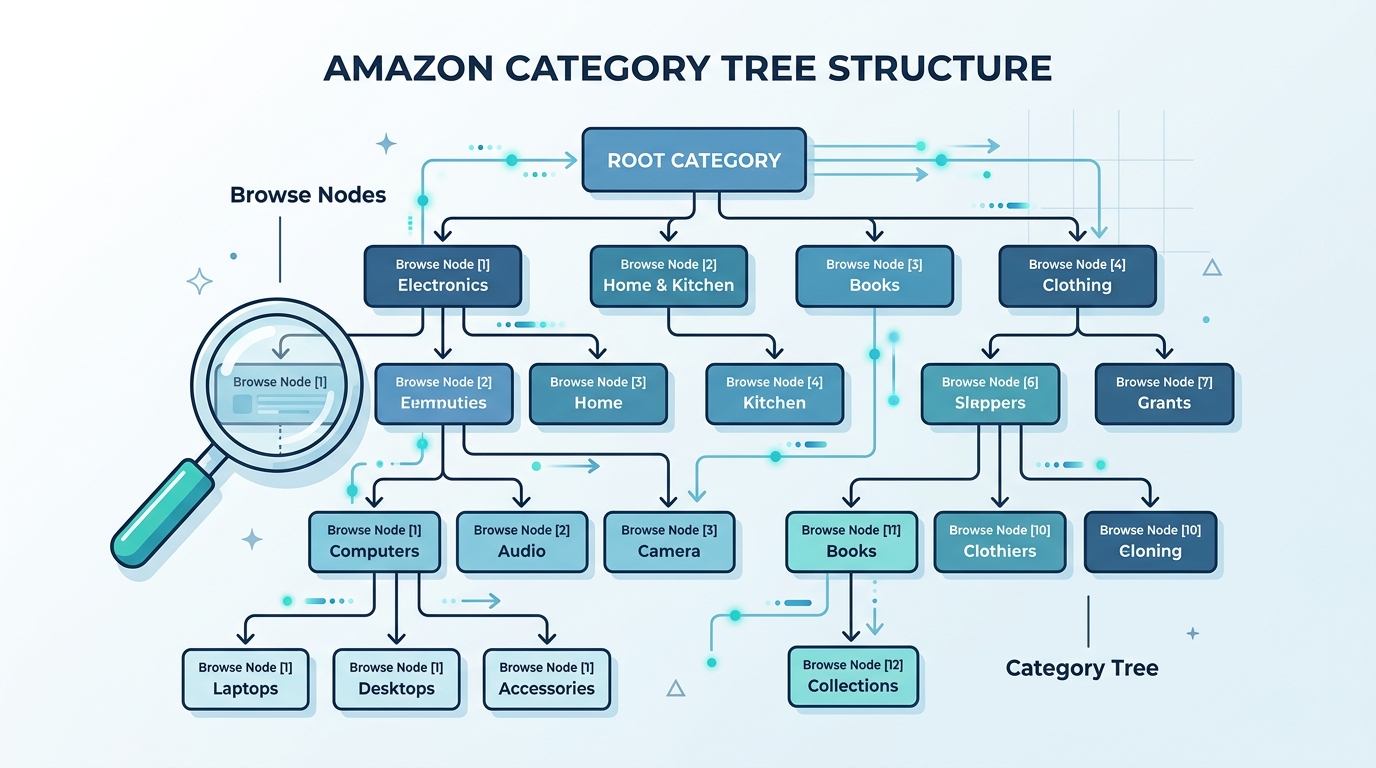
亚马逊Browse Node数据结构解析
亚马逊的类目体系采用**多叉树(N-ary Tree)**结构存储。每个节点包含以下核心字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| node_id | string | 唯一节点标识,如"284507" |
| name | string | 类目显示名称 |
| parent_id | string | 父节点ID |
| children | array | 子节点列表 |
| level | integer | 层级深度 |
| product_count | integer | 节点下商品数量(可选) |
美国站当前有效节点数约12万,深度通常在4-6层。不同站点完全独立,Node ID不能跨站复用。
方案对比:官方PA-API vs 第三方API
亚马逊PA-API(Product Advertising API)
PA-API提供BrowseNodeLookup接口,可查询指定节点的基本信息。但存在以下限制:
xml
<!-- PA-API 返回示例 -->
<BrowseNode>
<BrowseNodeId>284507</BrowseNodeId>
<Name>Kitchen & Dining</Name>
<Children>
<BrowseNode>
<BrowseNodeId>289668</BrowseNodeId>
<Name>Small Appliances</Name>
</BrowseNode>
</Children>
</BrowseNode>限制分析:
- 需完成销售配额(~3个月成交记录)才能申请
- 单请求最多返回10个子节点
- 无商品数量统计
- 速率限制:1秒/请求
- 不支持批量查询
按此速率遍历12万节点,理论上需要33小时以上,且不包括网络波动和重试。
第三方专业API:Pangolinfo Scrape API
Pangolinfo Scrape API专门针对电商数据采集场景设计,在类目节点采集上有显著优势:
| 能力项 | PA-API | Pangolinfo API |
|---|---|---|
| 权限门槛 | 高(需销售记录) | 低(注册即用) |
| 返回层级 | 单层 | 可配置多层 |
| 商品数量 | 不支持 | 支持 |
| 批量查询 | 不支持 | 支持 |
| 全站点覆盖 | 有限 | 15个站点 |
| 定时同步 | 不支持 | 支持 |
完整代码实现
基础调用:获取指定节点层级
python
import requests
import json
class AmazonCategoryCollector:
def __init__(self, api_key: str):
self.api_url = "https://api.pangolinfo.com/v1/amazon/browse-nodes"
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def get_node_hierarchy(self, site: str, node_id: str, depth: int = 3):
"""
获取指定节点下的层级结构
Args:
site: 站点标识,如 amazon.com, amazon.co.jp
node_id: 起始节点ID
depth: 向下获取的层级深度
"""
payload = {
"site": site,
"node_id": node_id,
"depth": depth,
"include_product_count": True
}
try:
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
return None
def print_tree(self, nodes: list, prefix: str = ""):
"""树形打印节点结构"""
for i, node in enumerate(nodes):
is_last = i == len(nodes) - 1
connector = "└── " if is_last else "├── "
count = node.get('product_count', 'N/A')
print(f"{prefix}{connector}{node['name']} (ID: {node['node_id']}, Products: {count})")
children = node.get('children', [])
if children:
extension = " " if is_last else "│ "
self.print_tree(children, prefix + extension)
# 使用示例
if __name__ == "__main__":
collector = AmazonCategoryCollector(api_key="YOUR_API_KEY")
# 获取美国站 Kitchen & Dining 下3层数据
result = collector.get_node_hierarchy(
site="amazon.com",
node_id="284507",
depth=3
)
if result and "nodes" in result:
collector.print_tree(result["nodes"])进阶:全站类目树采集
python
def collect_full_tree(self, site: str, output_file: str = "category_tree.json"):
"""
采集指定站点的完整类目树
策略:从根节点开始,逐层广度优先遍历
"""
from collections import deque
root_nodes = self.get_node_hierarchy(site, node_id="0", depth=1)
if not root_nodes:
return
tree = {"site": site, "nodes": [], "total_count": 0}
queue = deque(root_nodes["nodes"])
visited = set()
while queue:
node = queue.popleft()
node_id = node["node_id"]
if node_id in visited:
continue
visited.add(node_id)
tree["nodes"].append(node)
tree["total_count"] += 1
# 每100个节点保存一次进度
if tree["total_count"] % 100 == 0:
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(tree, f, ensure_ascii=False, indent=2)
print(f"已采集 {tree['total_count']} 个节点...")
# 将子节点加入队列
for child in node.get("children", []):
if child["node_id"] not in visited:
queue.append(child)
# 最终保存
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(tree, f, ensure_ascii=False, indent=2)
print(f"采集完成,共 {tree['total_count']} 个节点,已保存至 {output_file}")常见问题与解决方案
Q1:节点ID失效怎么办?
亚马逊每年约调整5-8%的类目结构。建议:
- 建立节点有效性检查机制,定期验证存量Node ID
- 订阅增量更新服务,及时获取变更通知
- 在数据库中标记节点状态(active/deprecated/merged)
Q2:不同站点的类目树差异如何管理?
建议按站点维护独立的类目树表,表结构增加site字段。不要尝试建立跨站点的Node ID映射,因为不同站点的分类逻辑本身就不一致。
Q3:反爬机制如何应对?
如果自建爬虫,需处理:
- 请求频率控制(建议<5 req/s)
- User-Agent轮换
- Cookie/Session管理
- CAPTCHA识别(打码平台或视觉模型)
- IP代理池(住宅代理优先)
更推荐的方案:直接使用Pangolinfo Scrape API,上述问题已全部封装解决。
性能优化建议
- 并发控制:批量采集时设置合理的并发数(建议10-20),避免触发限流
- 增量更新:首次全量采集后,后续只请求变更节点
- 本地缓存:热点类目树可缓存24小时,减少API调用
- 异步处理:大规模采集使用消息队列(如Celery + Redis)异步执行
总结
亚马逊商品类目节点数据的采集,从早期的手动记录到官方API,再到现在的专业数据采集服务,技术路径已经比较清晰。对于需要稳定、完整、可扩展类目数据的技术团队,专业API是最务实的选择。
通过Pangolinfo Scrape API,可以在数小时内建立覆盖全球多站点的类目数据体系,并将维护成本降至最低。