本文档记录如何使用中国区搭建一套完整的流数据处理管道,将纽约市出租车行程数据通过 Kinesis 回放,由 Managed Service for Apache Flink 实时处理,最终写入 OpenSearch 进行可视化分析。
纽约市出租车和豪华轿车管理局(TLC,Taxi and Limousine Commission)公开了全市出租车行程记录数据。这些数据记录了每一次出租车行程的上下车时间、经纬度坐标、行程距离、费用等信息。本 Workshop 利用这套真实数据集,构建一个实时监控仪表盘,回答两个运营问题:
- 每个区域每小时有多少次上车? --- 用于监控城市各区域的出行需求分布
- 从各区域到机场的平均行程需要多久? --- 用于评估交通状况和调度效率
这两个问题本质上都是时间窗口聚合问题:按地理区域分组,在固定时间窗口内做计数或求均值。这正是 Flink 流处理引擎的核心能力。
原始数据来自 AWS Open Data Registry 上的公开数据集 NYC TLC Trip Record Data(arn:aws:s3:::nyc-tlc)。该数据集以 CSV 格式存储,包含 2009 年至今的出租车行程记录。
Workshop 的作者将原始 CSV 数据做了预处理:提取关键字段、转换为 JSON 格式、用 lz4 压缩,存放在 aws-bigdata-blog 桶中,供 Kinesis Replay JAR 直接消费。这个预处理后的数据集包含 540 万条记录 (lz4 压缩后 358 MB ),时间跨度为 2010 年 1 月 1 日至 1 月 13 日(约 12 天)。
每条记录是一个 JSON 对象,包含以下字段:
json
{
"vendor_id": "VTS",
"pickup_datetime": "2010-01-01T23:48:00.000Z",
"dropoff_datetime": "2010-01-02T00:00:00.000Z",
"passenger_count": 1,
"trip_distance": 3.95,
"pickup_longitude": -73.986445,
"pickup_latitude": 40.761785,
"dropoff_longitude": -73.958318,
"dropoff_latitude": 40.81038,
"rate_code": 1,
"payment_type": "CAS",
"fare_amount": 10.9,
"surcharge": 0.5,
"mta_tax": 0.5,
"tip_amount": 0.0,
"tolls_amount": 0.0,
"total_amount": 11.9,
"trip_id": 0,
"type": "trip"
}关键字段说明:
| 字段 | 类型 | 用途 |
|---|---|---|
pickup_datetime |
ISO 8601 | 上车时间(行程开始) |
dropoff_datetime |
ISO 8601 | 下车时间(行程结束),作为 Flink Event Time 的时间戳 |
pickup_latitude/longitude |
double | 上车位置经纬度 |
dropoff_latitude/longitude |
double | 下车位置经纬度 |
total_amount |
double | 行程总费用 |
trip_id |
long | 唯一行程 ID |
vendor_id |
string | 出租车公司标识(VTS 或 CMT) |
注意这里用的是经纬度坐标 ,而不是 TLC 原始数据中后来引入的 location_id(区域编号)格式。这是因为 Workshop 需要做地理位置计算(geo hash、机场距离判定),必须要有经纬度。
整体架构如下
数据回放
Replay JAR /
Python 脚本
Amazon Kinesis
Data Stream
4 shards
分区键: UUID/trip_id
Managed Service for Apache
Flink (MF)
Event Time, 1h 窗口
NAT 子网
OpenSearch
pickup_count
trip_duration
环境配置
网络拓扑
由于我们使用的是 AWS 中国区(cn-north-1),所有资源都在同一个 VPC 中:
VPC: vpc-08xxxxxxx9e2ae (172.31.0.0/16)
│
├── IGW 公有子网 (subnet-077cfxxxxxa37)
│ ├── EC2 (172.31.14.46, t3a.2xlarge)
│ │ ├── OpenSearch Docker (端口 9200)
│ │ ├── OpenSearch Dashboards Docker (端口 5601)
│ │ └── 数据回放脚本
│
└── NAT 私有子网 (subnet-0xxxxxxxxa087)
└── Managed Flink JobManager / TaskManager为什么 MF 要放在 NAT 子网? Managed Flink 的 TaskManager 和 JobManager 没有公网 IP,它们只能使用 VPC 内网地址。在 IGW 公有子网中,资源必须拥有公网 IP 才能通过 Internet Gateway 出公网。部署过程中最初将 MF 错误地放在了 IGW 公有子网,导致 TaskManager 无法连接 Kinesis。发现后删除重建,改为 NAT 子网。
组件安装
OpenSearch
bash
mkdir -p ~/opensearch && cd ~/opensearch
# 创建 docker-compose.yml(见前文)
docker compose up -d
# 验证
curl http://localhost:9200
curl http://localhost:5601创建 OpenSearch 索引(带 geo_point 映射)
bash
curl -X PUT "http://localhost:9200/pickup_count" -H "Content-Type: application/json" -d '{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"pickup_count": { "type": "long" },
"timestamp": { "type": "date" }
}
}
}'
curl -X PUT "http://localhost:9200/trip_duration" -H "Content-Type: application/json" -d '{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"airport_code": { "type": "keyword" },
"sum_trip_duration": { "type": "long" },
"avg_trip_duration": { "type": "double" },
"timestamp": { "type": "date" }
}
}
}'Kinesis Stream
bash
aws kinesis create-stream --stream-name managed-flink-taxi --shard-count 4 --region cn-north-1构建 Flink 应用
bash
cd amazon-managed-service-for-apache-flink-taxi-consumer
mvn clean package -DskipTests
aws s3 cp target/taxi-consumer-1.0.jar s3://ana-kda/flink-workshop/code/taxi-consumer.jar --region cn-north-1创建并启动 MF 应用
bash
aws kinesisanalyticsv2 create-application \
--application-name managed-flink-taxi \
--runtime-environment FLINK-1_20 \
--service-execution-role arn:aws-cn:iam::xxxxxxxxxx:role/service-role/kinesis-analytics-flink-workshop \
--application-configuration '{
"ApplicationCodeConfiguration": {
"CodeContent": {
"S3ContentLocation": {
"BucketARN": "arn:aws-cn:s3:::ana-kda",
"FileKey": "flink-workshop/code/taxi-consumer.jar"
}
},
"CodeContentType": "PLAINTEXT"
},
"EnvironmentProperties": {
"PropertyGroups": [{
"PropertyGroupId": "FlinkApplicationProperties",
"PropertyMap": {
"InputStreamArn": "arn:aws-cn:kinesis:cn-north-1:xxxxxxxxxx:stream/managed-flink-taxi",
"OpenSearchEndpoint": "http://172.31.14.46:9200"
}
}]
},
"FlinkApplicationConfiguration": {
"MonitoringConfiguration": {
"ConfigurationType": "CUSTOM",
"LogLevel": "INFO",
"MetricsLevel": "TASK"
}
},
"VpcConfigurations": [{
"SubnetIds": ["subnet-02xxxxxa087"],
"SecurityGroupIds": ["sg-096xxxxx7e9"]
}],
"ApplicationSnapshotConfiguration": { "SnapshotsEnabled": false },
"ApplicationSystemRollbackConfiguration": { "RollbackEnabled": false }
}' --region cn-north-1
aws kinesisanalyticsv2 start-application \
--application-name managed-flink-taxi \
--run-configuration '{"ApplicationRestoreConfiguration": {"RestoreType": "SKIP_RESTORE_FROM_SNAPSHOT"}}' \
--region cn-north-1数据回放
原始方案:Kinesis Replay JAR
官方提供了一个专用的回放工具 amazon-kinesis-replay。它的核心功能是从 S3 读取 JSON 事件数据,按照事件原始时间戳的顺序,以可配置的加速倍率回放到 Kinesis。
bash
java -jar amazon-kinesis-replay.jar \
-streamArn arn:aws:kinesis:us-east-1:xxx:stream/stream-name \
-speedup 3600Replay JAR 的实现很精巧:它不是简单地尽快发送所有数据,而是按照事件时间戳之间的间隔,乘以 speedup 因子来控制发送节奏。这样可以模拟真实的流数据产生速率,同时允许加速回放历史数据。Replay JAR 还内置了失败重试(最多 100 次,指数退避)和批量发送(每批最多 500 条),保证数据可靠写入。
在中国区部署时,Replay JAR 无法直接使用,原因是它内部使用 AWS SDK 访问全球区 S3 桶 aws-bigdata-blog。SDK 会自动加载中国区凭证(包含 session token),而中国区的 STS token 格式与全球区不兼容,导致 S3 返回 "The provided token is malformed or otherwise invalid" 错误。
用 AWS CLI 匿名下载数据到本地
bash
aws s3 cp \
s3://aws-bigdata-blog/artifacts/kinesis-analytics-taxi-consumer/taxi-trips.json.lz4/part-00000-462cf65e-5c22-47b2-bc5c-aa1e6b9e567c-c000.lz4 \
/tmp/test-trips.lz4 \
--no-sign-request \
--region us-east-1用 Python 脚本从本地文件回放到 Kinesis
python
import boto3, json, lz4.frame, sys
KINESIS_STREAM_NAME = "managed-flink-taxi"
REGION = "cn-north-1"
BATCH_SIZE = 500
def send_batch(client, records):
put_records = []
for rec in records:
partition_key = str(rec.get("trip_id", "default"))
put_records.append({
"Data": json.dumps(rec).encode("utf-8"),
"PartitionKey": partition_key
})
response = client.put_records(
StreamName=KINESIS_STREAM_NAME,
Records=put_records
)
failed = response.get("FailedRecordCount", 0)
return len(put_records) - failed, failed
def replay_file(file_path):
client = boto3.client("kinesis", region_name=REGION)
total_sent = total_failed = 0
batch = []
with lz4.frame.open(file_path, "rb") as f:
for line in f:
line = line.decode("utf-8").strip()
if not line:
continue
try:
record = json.loads(line)
except json.JSONDecodeError:
continue
batch.append(record)
if len(batch) >= BATCH_SIZE:
success, failed = send_batch(client, batch)
total_sent += success
total_failed += failed
batch = []
if batch:
success, failed = send_batch(client, batch)
total_sent += success
total_failed += failed
print(f"Done: {total_sent} sent, {total_failed} failed")
if __name__ == "__main__":
replay_file(sys.argv[1] if len(sys.argv) > 1 else "/tmp/test-trips.lz4")与原始 Replay JAR 相比,Python 脚本有几个简化:
- 没有按时间戳节奏发送:直接尽快发送所有数据。因为 Flink 用的是 Event Time 窗口,发送速率不影响处理结果。
- 没有失败重试:超过 Kinesis 吞吐量限制的记录直接丢弃。对于 Workshop 演示来说够用。
- 使用
trip_id作为分区键:确保数据均匀分布到所有 Shard
分区设计
为什么需要分区
Kinesis Data Stream 是一个分布式、可扩展的实时数据流服务。一个 Stream 由多个 Shard 组成,每个 Shard 提供固定的读写吞吐量:
- 写入 :每秒最多 1,000 条
PutRecords请求,最大 1,000 条记录,总数据量不超过 1 MB(含分区键) - 读取 :每秒最多 5 次
GetRecords()调用,最大 2,000 条记录,总数据量不超过 2 MB
本 Workshop 创建了 4 个 Shard 的 Stream:
bash
aws kinesis create-stream \
--stream-name managed-flink-taxi \
--shard-count 4 \
--region cn-north-1总写入吞吐量约 4,000 条/秒,足够覆盖数据回放的速率。
分区键与数据分布
Kinesis 使用 分区键(Partition Key) 决定每条记录路由到哪个 Shard。具体的路由方式是对分区键做 MD5 哈希,然后映射到 Shard 的哈希空间。相同分区键的记录一定会落到同一个 Shard,且保持顺序。
这个特性对 Flink 消费者至关重要:Flink 的 Kinesis Source 为每个 Shard 分配一个独立的读取子任务(subtask),每个子任务独立维护自己的 Watermark。
原始 Workshop 的 Replay JAR 使用 UUID.randomUUID() 作为分区键,这样每条记录的分区键都不同,数据会均匀分布到所有 Shard:
java
// KinesisProducer.java
private String randomPartitionKey() {
return UUID.randomUUID().toString();
}部署中的分区键踩坑
在我们的 Python 回放脚本中,最初使用了 vendor_id 作为分区键。这导致了一个严重的 bug:vendor_id 只有 VTS 和 CMT 两个值,MD5 哈希后只会映射到 4 个 Shard 中的 2~3 个。有 1~2 个 Shard 完全没有数据。
Flink 的 Watermark 机制要求所有 Source 子任务的 Watermark 都前进 才能推进全局 Watermark(取所有子任务 Watermark 的最小值)。空 Shard 的 Watermark 永远停在 Long.MIN_VALUE,导致全局 Watermark 无法前进,所有 Event Time 窗口都不会触发。
当时观察到的现象是:CloudWatch 日志显示 Checkpoint 大小持续增长(说明数据在被消费并积累在窗口状态中),但 OpenSearch 始终没有数据写入(窗口从未触发)。
修复方法是将分区键改为 trip_id(每条记录唯一),确保数据均匀分布到所有 4 个 Shard:
python
partition_key = str(rec.get("trip_id", "default"))Flink 处理逻辑详解
Flink 应用是整个数据管道的核心。它从 Kinesis 消费原始行程数据,经过一系列转换和窗口聚合,最终输出两类分析结果。
Event Time 与 Watermark 机制
流处理中,每条记录有两种时间语义:
- Processing Time:Flink 算子处理这条记录时的系统时钟时间。简单但不精确,受网络延迟、消费速率等因素影响。
- Event Time:事件实际发生的时间,嵌入在数据本身中。精确但需要额外的 Watermark 机制来处理乱序数据。
本 Workshop 使用 Event Time ,时间戳取自 dropoff_datetime(下车时间,即行程结束时间)。选择下车时间而非上车时间,是因为下车时间更准确地反映了行程的完成时刻,适合做"每小时完成了多少行程"的统计。
Watermark 的工作原理
在分布式流处理中,数据可能因为网络延迟、Shard 消费速度不同等原因乱序到达------先产生的事件可能后到达 Flink。Flink 使用 Watermark 来解决这个问题。
Watermark 的语义
Watermark 是 Source 向下游发出的一条声明:"我保证,时间戳早于 Watermark 的数据不会再出现了。"
Source 算子持续消费数据,记录每条数据的事件时间。定期发出 Watermark,公式为:
Watermark = 当前已见到的最大事件时间戳 - 允许乱序时间(Duration)举例:假设 Flink 已经消费到 dropoff_datetime = 2010-01-02T01:00:00 的记录,Duration 设为 2 分钟,那么 Watermark 为 2010-01-02T00:58:00。这意味着 Source 承诺:不会再有 dropoff_datetime 早于 00:58:00 的数据出现了。
下游窗口算子根据 Watermark 判断:当 Watermark >= 窗口结束时间时,认为该窗口的所有数据都已到齐,可以触发计算。上例中 Watermark 为 00:58:00,会触发 [22:00 - 23:00) 和 [23:00 - 00:00) 两个窗口,但 [00:00 - 01:00) 窗口还不会触发。
注意 Watermark 是基于策略的估算,不是绝对真理。实际的保证力度取决于 Duration 参数的选择。
Duration 参数:延迟与完整性的权衡
本 Workshop 的配置:
java
WatermarkStrategy.<TripEvent>forBoundedOutOfOrderness(Duration.ofMinutes(2))
.withTimestampAssigner((event, ts) -> event.dropoffDatetime.toEpochMilli())Duration.ofMinutes(2) 可以改为任意值。这个参数的含义是:我预期数据最多会乱序多久到达。
Duration 越大,系统等待越久才推进 Watermark,对迟到数据的容忍度越高;Duration 越小,Watermark 推进越快,但迟到数据被丢弃的风险越大:
Duration = 2min → Watermark = max_timestamp - 2min → 窗口触发快,但超出 2min 的迟到数据丢弃
Duration = 1hour → Watermark = max_timestamp - 1hour → 窗口触发慢 1 小时,但几乎不会丢数据本质上是结果产出延迟 vs 数据完整性的权衡。常见场景的经验值:
| 场景 | 建议值 | 理由 |
|---|---|---|
| 同机房直连 | 秒级 | 网络抖动很小 |
| 跨区域/公网采集 | 分钟级 | 网络延迟波动大 |
| IoT 设备上报 | 十分钟到小时级 | 设备可能离线、批量补传 |
| 本 Workshop(Kinesis 回放历史数据) | 2 分钟 | 原始数据已按时间排序,乱序风险很低 |
Flink 还提供其他 Watermark 策略:
forMonotonousTimestamps():数据严格按时间戳递增到达(乱序量 = 0),Watermark = 当前时间戳forBoundedOutOfOrderness(Duration):本 Workshop 用的,有界乱序- 自定义
WatermarkGenerator:完全自定义逻辑,比如基于业务规则动态调整
迟到数据的处理
Watermark 超过窗口结束时间 → 窗口触发计算 → 窗口关闭。之后到达的迟到数据默认直接丢弃。
但 Flink 提供了兜底机制:
java
.window(TumblingEventTimeWindows.of(Duration.ofHours(1)))
.allowedLateness(Duration.ofMinutes(5)) // 窗口关闭后再容忍 5 分钟
.sideOutputLateData(lateTag) // 超出容忍的迟到数据送到侧输出allowedLateness:Watermark 超过窗口结束时间后,再给一个宽限期。宽限期内迟到数据到达时,窗口会重新计算并更新结果。sideOutputLateData:连宽限期都过了的数据输出到一个侧流,可以单独处理(写入死信队列、人工排查等)。
本 Workshop 没有配置这些机制,迟到的数据直接丢弃。对于演示场景可以接受。
为什么传播时取最小值
Watermark 在 DAG 中传播时,每个算子取所有输入 Watermark 的最小值。这是唯一安全的选择:
Shard 0 的 Watermark = 2010-01-02T01:00
Shard 1 的 Watermark = Long.MIN_VALUE(没有数据)如果取最大值(01:00),窗口 [23:00 - 00:00) 会立即触发。但 shard 1 以后可能还会发来 dropoff_datetime = 23:30 的数据------这些记录本应属于这个窗口,但窗口已经关了。完整性保证被打破了。
取最小值(Long.MIN_VALUE)虽然保守,但是正确的------因为我们确实无法保证任何时间范围的数据已经完整。
Watermark 的传播与全局阻塞
Flink 的 Watermark 不是全局广播机制,而是沿着 DAG 逐算子传播、在汇聚点取最小值。具体规则:
- Source 层:每个 Kinesis Shard 对应一个 Source subtask,各自独立维护自己的 watermark
keyBy之后 :每个下游窗口算子实例会收到来自所有上游 Source subtask 的 watermark,取最小值作为自己的 watermark- 窗口触发:窗口算子实例的 watermark >= 窗口结束时间时触发
关键在第 2 步:keyBy 虽然按 key 把数据路由到特定下游实例,但 watermark 通过所有 input channel 传播。每个下游实例与所有上游实例建立 input gate,并追踪每个 gate 的 watermark,取最小值。这意味着即使某个下游实例只处理来自 shard 0 的数据(因为 key 路由),它的 watermark 仍然被 shard 1/2/3 牵制。
Source subtask 0 (shard 0) ── watermark: 2010-01-02T01:00 ─┐
Source subtask 1 (shard 1) ── watermark: Long.MIN_VALUE ─┤ min = Long.MIN_VALUE
Source subtask 2 (shard 2) ── watermark: 2010-01-02T01:00 ─┤ → 所有窗口算子都被阻塞
Source subtask 3 (shard 3) ── watermark: 2010-01-02T01:00 ─┘这就是分区键选择不当导致窗口不触发的根本原因。Flink 提供了 withIdleness(Duration) 配置来缓解:如果某个 Source subtask 在指定时间内没有数据,标记为 "idle",其 watermark 不再参与 min 计算。但本 Workshop 的代码没有配置此选项,因此任何空闲的 Shard 都会阻塞整个管道。
完整的数据处理 DAG
Kinesis Source
│
│ 反序列化 JSON → TripEvent
│ Watermark: BoundedOutOfOrderness(2 min), Timestamp = dropoff_datetime
│
▼
Filter: hasValidCoordinates
│
│ 仅保留上下车坐标都在 NYC 范围内的行程
│
├──▶ 管道 A: Pickup Count ──▶ OpenSearch (pickup_count)
│ map → TripToGeoHash (7位)
│ keyBy → geoHash
│ window → TumblingEventTimeWindows(1h)
│ apply → CountByGeoHash
│
└──▶ 管道 B: Trip Duration ──▶ OpenSearch (trip_duration)
flatMap → TripToTripDuration (6位 hash, 仅机场目的地)
keyBy → (pickupGeoHash, airportCode)
window → TumblingEventTimeWindows(1h)
apply → TripDurationToAverageTripDuration下面逐环节详细展开。
数据摄入与反序列化
Kinesis Source 从 Stream 中读取原始字节,通过 EventDeserializationSchema 反序列化为 TripEvent 对象:
java
public TripEvent deserialize(byte[] bytes) {
try {
return TripEvent.parseEvent(bytes);
} catch (Exception e) {
return null; // 解析失败则跳过
}
}TripEvent 使用 Gson 的 LOWER_CASE_WITH_UNDERSCORES 命名策略,自动将 JSON 的 pickup_latitude 映射到 Java 的 pickupLatitude 字段。解析失败的记录返回 null,Flink 会自动丢弃。
如果在同一 Kinesis Stream 中混入了格式不同的旧数据(例如之前测试时发送的只有 location_id 没有 latitude/longitude 的记录),这些记录会因为无法映射到 TripEvent 的必填字段而解析失败并被丢弃。这保证了数据质量。
地理坐标过滤
java
DataStream<TripEvent> trips = kinesisStream
.filter(GeoUtils::hasValidCoordinates);原始数据中存在少量坐标异常的记录(经纬度为 0、超出 NYC 范围等)。过滤条件要求上车点和下车点都在 NYC 范围内:
java
private static final BoundingBox NYC = new BoundingBox(
new WGS84Point(40.878, -74.054), // 左上角
new WGS84Point(40.560, -73.722) // 右下角
);即纬度 40.560, 40.878,经度 -74.054, -73.722。这个范围大致覆盖了纽约市五个行政区。只有两个坐标都在这个矩形内的行程才会被保留。
数据流分叉:两个管道并行处理
过滤后的 trips 是一个 DataStream<TripEvent>,它被两个独立的管道同时消费:
java
// 管道 A:上车计数
DataStream<PickupCount> pickupCounts = trips
.map(new TripToGeoHash())
.keyBy(item -> item.geoHash)
.window(TumblingEventTimeWindows.of(Duration.ofHours(1)))
.apply(new CountByGeoHash());
// 管道 B:机场行程时长
DataStream<AverageTripDuration> tripDurations = trips
.flatMap(new TripToTripDuration())
.keyBy(item -> Tuple2.of(item.pickupGeoHash, item.airportCode))
.window(TumblingEventTimeWindows.of(Duration.ofHours(1)))
.apply(new TripDurationToAverageTripDuration());
// 两个管道各自写入 OpenSearch
pickupCounts.addSink(new OpenSearchHttpSink<>(opensearchEndpoint, "pickup_count"));
tripDurations.addSink(new OpenSearchHttpSink<>(opensearchEndpoint, "trip_duration"));关键点:trips 变量被两个链式调用复用 。Flink 的 DataStream 是不可变的------每次调用 .map() / .flatMap() / .filter() 都返回一个新的流 ,不修改原流。因此同一个 trips 可以被多个下游消费,形成"广播"式分叉:
trips (DataStream<TripEvent>)
│
├──▶ trips.map(...) → 管道 A
│
└──▶ trips.flatMap(...) → 管道 B这与"分流"不同------split / select 是有选择地把数据发往不同分支(每条记录只去一个分支),而这里是每条记录同时进入两个管道被独立处理。Flink 运行时会在物理上复制数据,两个管道并行执行,互不干扰。
上车计数分析(管道 A)
Geo Hash 转换
java
// TripToGeoHash.java
public TripGeoHash map(TripEvent tripEvent) {
return new TripGeoHash(
GeoHash.geoHashStringWithCharacterPrecision(
tripEvent.pickupLatitude,
tripEvent.pickupLongitude,
7 // 7 位精度
)
);
}GeoHash 是一种将经纬度编码为字符串的算法。它将地球表面划分为网格,每个网格用一个字符串表示。7 位 GeoHash 的精度约为 153 米 × 153 米,适合做城市级别的区域聚合。
为什么要把经纬度转成 GeoHash?因为直接用经纬度做 keyBy 分组没有意义------两个相邻的行程可能有微小不同的经纬度(比如 40.761785 和 40.761790),但实际上是同一个街区。GeoHash 将相近的坐标映射到同一个字符串,实现了空间聚合。
分区与窗口
java
DataStream<PickupCount> pickupCounts = trips
.map(new TripToGeoHash()) // 经纬度 → 7位 geoHash
.keyBy(item -> item.geoHash) // 按 geoHash 分区
.window(TumblingEventTimeWindows.of(Duration.ofHours(1))) // 1小时滚动窗口
.apply(new CountByGeoHash()); // 窗口内计数keyBy(geoHash):将相同 geoHash 的记录路由到同一个算子实例,确保同一区域的记录在同一个地方被聚合。TumblingEventTimeWindows.of(Duration.ofHours(1)):滚动事件时间窗口,窗口对齐到 epoch 整点(即 [00:00-01:00), [01:00-02:00), ...)。窗口之间不重叠,每条记录只属于一个窗口。- 窗口触发条件 :由 Event Time 语义隐式决定------Watermark 超过窗口结束时间时自动触发,无需、也无法在代码中显式配置。这是 Event Time 窗口的核心特点:触发逻辑由框架内部实现(
WindowOperator追踪 Watermark,当currentWatermark >= window.maxTimestamp()时调用用户的apply函数)。
窗口聚合函数
java
// CountByGeoHash.java
public void apply(String key, TimeWindow timeWindow,
Iterable<TripGeoHash> iterable,
Collector<PickupCount> collector) {
long count = Iterables.size(iterable);
String position = Iterables.get(iterable, 0).geoHash;
collector.collect(new PickupCount(position, count, timeWindow.getEnd()));
}窗口触发时,apply 函数收到该窗口内所有记录的迭代器。直接计算记录数量即为上车次数。输出的 timestamp 使用 timeWindow.getEnd(),即窗口的结束时间,代表这一小时统计结果的"所属时刻"。
机场行程时长分析(管道 B)
行程时长计算与机场判定
java
// TripToTripDuration.java
public void flatMap(TripEvent tripEvent, Collector<TripDuration> collector) {
String pickupLocation = GeoHash.geoHashStringWithCharacterPrecision(
tripEvent.pickupLatitude, tripEvent.pickupLongitude, 6); // 6位精度
long tripDuration = Duration.between(
tripEvent.pickupDatetime, tripEvent.dropoffDatetime).toMinutes();
if (GeoUtils.nearJFK(tripEvent.dropoffLatitude, tripEvent.dropoffLongitude)) {
collector.collect(new TripDuration(tripDuration, pickupLocation, "JFK"));
} else if (GeoUtils.nearLGA(tripEvent.dropoffLatitude, tripEvent.dropoffLongitude)) {
collector.collect(new TripDuration(tripDuration, pickupLocation, "LGA"));
}
// 都不是机场:不调用 collector.collect(),相当于丢弃这条数据
}理解 Collector
Collector<T> 是 Flink 的输出收集器,用于从算子中发射结果数据。collector.collect(record) 把数据写入算子的输出缓冲区,由 Flink 运行时传递给下游。
为什么需要 Collector?因为一条输入可能产生零条、一条或多条输出:
| 算子类型 | 输出数量 | 方法签名 |
|---|---|---|
MapFunction |
恰好 1 条 | T map(T value) --- 直接返回 |
FilterFunction |
0 或 1 条 | boolean filter(T value) --- true 保留 |
FlatMapFunction |
0~N 条 | void flatMap(T value, Collector out) |
WindowFunction |
0~N 条 | void apply(..., Collector out) |
本例中 flatMap 根据目的地决定输出:
- 去 JFK →
collector.collect()发射一条 - 去 LGA →
collector.collect()发射一条 - 都不是 → 不调用,相当于过滤掉
这种设计比 Filter + Map 组合更高效:一次遍历同时完成筛选和转换。
这里有几个关键设计点:
-
使用 6 位 GeoHash(精度约 1.2km × 0.6km),比管道 A 的 7 位更粗粒度。因为到机场的行程相对较少,粒度太细会导致每个分组内样本数太少,统计结果不稳定。
-
只保留目的地是机场的行程 :通过判定下车坐标是否在 JFK 或 LGA 机场的包围盒内来筛选。JFK 位于 Queens 南部(约 40.640°N, 73.780°W),LGA 位于 Queens 北部(约 40.777°N, 73.872°W)。目的地不是这两个机场的行程会被直接丢弃(
flatMap不 emit 任何记录)。 -
行程时长 = dropoff_datetime - pickup_datetime,以分钟为单位。这代表乘客在车上的实际时间。
机场包围盒定义:
java
private static final BoundingBox JFK = new BoundingBox(
new WGS84Point(40.654, -73.800),
new WGS84Point(40.632, -73.761));
private static final BoundingBox LGA = new BoundingBox(
new WGS84Point(40.778, -73.881),
new WGS84Point(40.766, -73.859));分区与窗口
java
DataStream<AverageTripDuration> tripDurations = trips
.flatMap(new TripToTripDuration())
.keyBy(item -> Tuple2.of(item.pickupGeoHash, item.airportCode)) // 按(区域, 机场)分区
.window(TumblingEventTimeWindows.of(Duration.ofHours(1)))
.apply(new TripDurationToAverageTripDuration());分区键是 (pickupGeoHash, airportCode) 的二元组。这意味着同一个上车区域到 JFK 和到 LGA 的行程会分别统计------因为到这两个机场的距离和路况完全不同。
窗口聚合函数
java
// TripDurationToAverageTripDuration.java
public void apply(Tuple2<String, String> tuple, TimeWindow timeWindow,
Iterable<TripDuration> iterable,
Collector<AverageTripDuration> collector) {
if (Iterables.size(iterable) > 1) { // 至少 2 条记录才计算均值
String location = Iterables.get(iterable, 0).pickupGeoHash;
String airportCode = Iterables.get(iterable, 0).airportCode;
long sumDuration = StreamSupport
.stream(iterable.spliterator(), false)
.mapToLong(trip -> trip.tripDuration).sum();
double avgDuration = (double) sumDuration / Iterables.size(iterable);
collector.collect(new AverageTripDuration(
location, airportCode, sumDuration, avgDuration, timeWindow.getEnd()));
}
}注意 Iterables.size(iterable) > 1 的过滤:只有 1 条记录的分组不输出结果。这是为了避免样本量太小导致均值不稳定。
输出包含 sum_trip_duration(总时长)和 avg_trip_duration(平均时长),用户可以据此计算出样本数量(sum / avg)。
OpenSearch Sink
输出的两类文档通过 HTTP REST API 写入 OpenSearch。原始 Workshop 使用 AWS SDK 的 AmazonOpenSearchServiceSink(带 IAM 签名认证),但我们部署的是自建 OpenSearch(Docker,无 IAM 认证),所以替换为 Java 11 标准库的 HttpClient:
java
static class OpenSearchHttpSink<T> extends RichSinkFunction<T> {
private transient HttpClient client;
@Override
public void invoke(T value, Context context) throws Exception {
String url = endpoint + "/" + index + "/_doc";
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(value.toString()))
.build();
client.send(request, HttpResponse.BodyHandlers.ofString());
}
}这里用到了 Document 基类的 toString() 方法,它使用 Gson 将对象序列化为 JSON:
java
public abstract class Document {
private static final Gson gson = new GsonBuilder()
.setFieldNamingPolicy(FieldNamingPolicy.LOWER_CASE_WITH_UNDERSCORE)
.create();
public final long timestamp;
@Override
public String toString() {
return gson.toJson(this); // 序列化为 snake_case JSON
}
}LOWER_CASE_WITH_UNDERSCORE 策略将 Java 的 pickupCount 转为 JSON 的 pickup_count,与 OpenSearch 的字段命名习惯一致。
输出数据
pickup_count 索引
每个 (geoHash, 1小时窗口) 组合输出一条记录:
json
{
"location": "dr5ru3q",
"pickup_count": 18,
"timestamp": 1262397600000
}| 字段 | 含义 |
|---|---|
location |
7 位 GeoHash,表示约 153m × 153m 的区域 |
pickup_count |
该小时内该区域的上车次数 |
timestamp |
窗口结束时间(epoch 毫秒) |
trip_duration 索引
每个 (geoHash, 机场, 1小时窗口) 组合输出一条记录:
json
{
"location": "dr5rue",
"airport_code": "LGA",
"sum_trip_duration": 120,
"avg_trip_duration": 10.0,
"timestamp": 1262394000000
}| 字段 | 含义 |
|---|---|
location |
6 位 GeoHash,表示约 1.2km × 0.6km 的区域 |
airport_code |
目的地机场代码(JFK 或 LGA) |
sum_trip_duration |
该分组所有行程的总时长(分钟) |
avg_trip_duration |
平均行程时长(分钟) |
timestamp |
窗口结束时间(epoch 毫秒) |
OpenSearch 索引映射
官方提供了预定义的索引映射模板,其中 location 字段被定义为 geo_point 类型,可以直接在 Dashboards 中绘制地图可视化:
json
// pickup-count-index.json
{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"pickup_count": { "type": "long" },
"timestamp": { "type": "date" }
}
}
}OpenSearch 的 geo_point 类型原生支持 GeoHash 字符串------写入 "dr5ru3q" 会被自动解析为对应的经纬度坐标。
索引映射必须在数据写入前创建 。如果 OpenSearch 先收到数据,会根据动态映射规则将 location 推断为 text 类型。一旦映射确定就无法更改,只能删除索引重建。部署过程中就遇到过这个问题:旧数据写入后 location 变成了 text,导致无法做地图可视化,最终需要清空索引重来。
正确的做法是在启动 Flink 应用之前,先通过 API 创建好带 geo_point 映射的索引:
```bash
curl -X PUT "http://localhost:9200/pickup_count" -H "Content-Type: application/json" -d '{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"pickup_count": { "type": "long" },
"timestamp": { "type": "date" }
}
}
}'
curl -X PUT "http://localhost:9200/trip_duration" -H "Content-Type: application/json" -d '{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"airport_code": { "type": "keyword" },
"sum_trip_duration": { "type": "long" },
"avg_trip_duration": { "type": "double" },
"timestamp": { "type": "date" }
}
}
}'
```进入 Dashboards 后,左侧导航栏选择 Dev Tools,可以直接查询 OpenSearch:
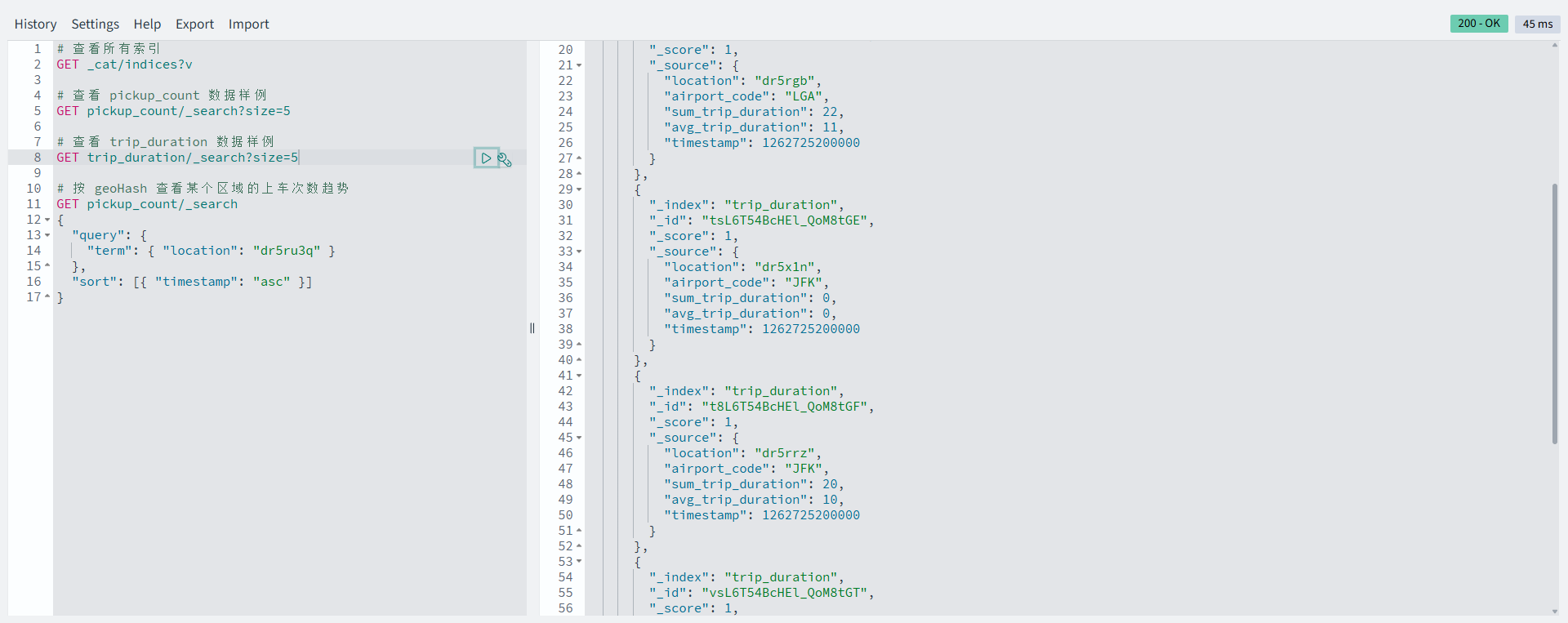
shell
# 查看所有索引
GET _cat/indices?v
# 查看 pickup_count 数据样例
GET pickup_count/_search?size=5
# 查看 trip_duration 数据样例
GET trip_duration/_search?size=5
# 按 geoHash 查看某个区域的上车次数趋势
GET pickup_count/_search
{
"query": {
"term": { "location": "dr5ru3q" }
},
"sort": [{ "timestamp": "asc" }]
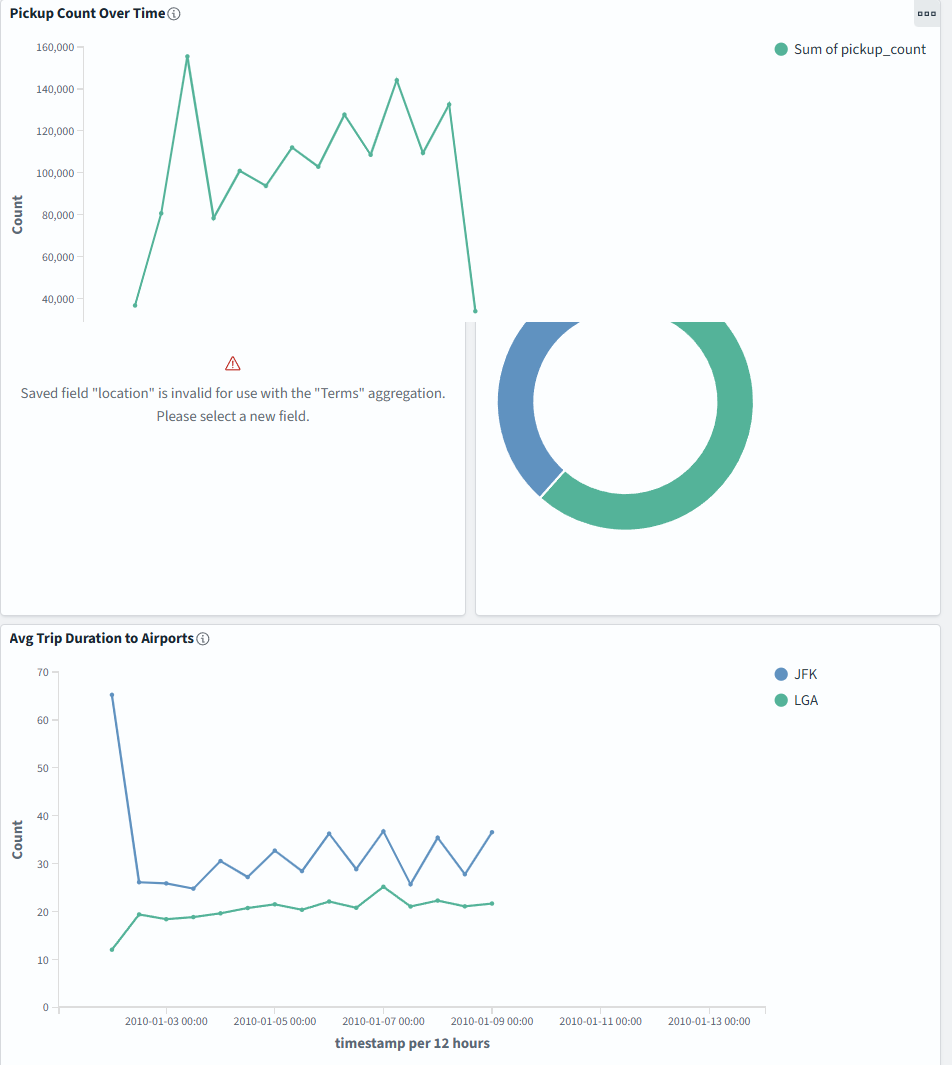
}左侧导航栏选择 Dashboard ,打开 "NYC Taxi Workshop Dashboard",包含以下可视化:
| 面板 | 类型 | 说明 |
|---|---|---|
| Pickup Count Over Time | 折线图 | 按时间展示全市上车次数趋势 |
| Top Pickup Locations | 柱状图 | 按上车次数排名的热门区域(GeoHash) |
| Trips by Airport | 饼图 | JFK 和 LGA 机场的行程数量对比 |
| Avg Trip Duration to Airports | 折线图 | 按时间展示到各机场的平均行程时长变化 |
数据时间戳是 2010 年 1 月,需要在 Dashboards 右上角的时间选择器中设置对应范围From: 2010-01-01 00:00:00,To: 2010-01-14 00:00:00