一、什么是伪迹?
1.1 脑电中的"噪音"
脑电信号非常微弱(微伏级,百万分之一伏),在采集过程中会被各种"噪音"污染:
记录的信号 = 大脑信号 + 伪迹
伪迹来源:
👁️ 眼电伪迹(EOG) → 眨眼、眼球转动 → 大幅度的慢波
💓 心电伪迹(ECG) → 心跳 → 规律的尖峰
💪 肌电伪迹(EMG) → 咬牙、皱眉 → 高频噪声
🏃 运动伪迹 → 转头、吞咽 → 大幅度的漂移
⚡ 工频干扰 → 电源 → 50/60Hz 正弦波1.2 形象比喻
你给朋友拍照:
- 大脑信号 = 朋友的脸(我们想要的)
- 眨眼伪迹 = 朋友闭眼了(废片!)
- 心电伪迹 = 有人从镜头前走过
- 运动伪迹 = 相机晃动,照片模糊
去除伪迹 = 挑出好照片,修掉瑕疵二、ICA(独立成分分析)原理
2.1 鸡尾酒会问题
一个房间里有三个人同时说话:
人A:说中文 🇨🇳
人B:说英文 🇬🇧
人C:说法文 🇫🇷
三个麦克风放在房间不同位置,每个录到的是混合声音:
麦克风1 = 0.8×A + 0.5×B + 0.3×C
麦克风2 = 0.4×A + 0.9×B + 0.6×C
麦克风3 = 0.6×A + 0.3×B + 0.8×C
ICA 的魔法:
从三个混合录音中,分离出三个独立的声音!2.2 ICA 在脑电中的应用
60 个电极 = 60 个"麦克风"
每个电极记录的是所有信号源的混合:
电极1 = a1×脑电 + b1×眨眼 + c1×心跳 + ...
电极2 = a2×脑电 + b2×眨眼 + c2×心跳 + ...
...
ICA 分解后得到独立成分:
成分0 → 大脑视觉活动 → ✅ 保留
成分1 → 眨眼伪迹 → ❌ 去除
成分2 → 心跳伪迹 → ❌ 去除
成分3 → 大脑听觉活动 → ✅ 保留
...三、环境准备与数据加载
3.1 导入库
python
# ========== 环境设置 ==========
# matplotlib.use('TkAgg') 的作用:
# 指定 matplotlib 的渲染后端
# TkAgg 是 Windows 系统自带的 Tkinter 后端
# 必须在 import pyplot 之前设置
import matplotlib
matplotlib.use('TkAgg')
# pyplot:matplotlib 的主要绘图接口
import matplotlib.pyplot as plt
# mne:脑电分析核心库
import mne
# ICA:独立成分分析模块
# 从 mne.preprocessing 中导入
from mne.preprocessing import ICA
# numpy:数值计算库,np 是约定俗成的简写
import numpy as np
# os:操作系统路径处理
import os
# Counter:统计工具,可以快速计数
from collections import Counter
# warnings:控制警告信息
import warnings
warnings.filterwarnings('ignore') # 忽略所有警告,输出更干净
# ========== 中文字体设置 ==========
# rcParams 是 matplotlib 的全局配置字典
# 'font.sans-serif':设置无衬线字体列表
# matplotlib 会按顺序尝试,使用第一个可用的字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
# 解决负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第5天:伪迹处理(ICA)")
print("="*60)3.2 加载数据并提取通道
python
# ---------- 1. 加载数据 ----------
# mne.datasets.sample.data_path()
# 返回示例数据集的存储路径
# 第一次运行会自动下载(约 2GB),之后直接返回本地路径
sample_data_folder = mne.datasets.sample.data_path()
# os.path.join() 安全地拼接路径(自动处理 / 和 \ 的区别)
raw_fname = os.path.join(
sample_data_folder,
'MEG',
'sample',
'sample_audvis_raw.fif'
)
# read_raw_fif():读取 .fif 格式的原始数据
# preload=False:先不加载到内存,节省内存
raw = mne.io.read_raw_fif(raw_fname, preload=False)
# pick_types():根据类型筛选通道
# eeg=True → 保留 EEG(脑电)通道
# eog=True → 保留 EOG(眼电)通道
# ecg=True → 保留 ECG(心电)通道
# stim=True → 保留 STIM(刺激标记)通道
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, ecg=True, stim=True)为什么需要 EOG 和 ECG 通道?
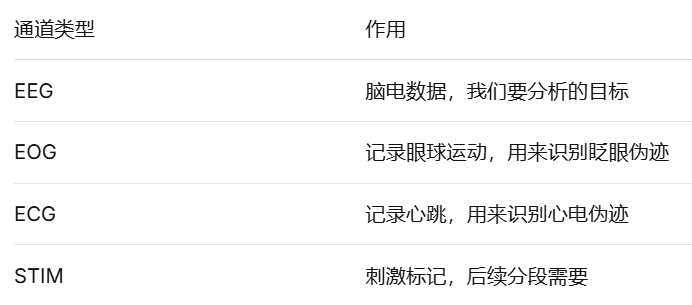
3.3 重命名通道并设置 Montage
python
# 找出以 'EEG' 开头的通道
# 列表推导式:遍历所有通道名,只保留以 'EEG' 开头的
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
# 创建标准 10-20 系统的蒙太奇(第2天学的内容)
montage = mne.channels.make_standard_montage('standard_1020')
# 取相同数量的标准名称
# montage.ch_names[:N] 取前 N 个标准电极名
standard_names = montage.ch_names[:len(eeg_names)]
# dict(zip(A, B)) 将两个列表配对为字典
# zip 将 ['EEG 001', 'EEG 002'] 和 ['Fz', 'Cz'] 配对
# dict 将配对结果转为 {'EEG 001': 'Fz', 'EEG 002': 'Cz'}
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
# 设置电极位置
raw_eeg.set_montage(montage)
# load_data():将数据从硬盘加载到内存
# 预处理需要频繁操作,加载到内存速度更快
raw_eeg.load_data()
print("✅ 数据加载完成")3.4 🔑 关键步骤:查看实际存在的通道
python
# ---------- 1.5 查看实际有哪些通道 ----------
# 这是今天学到的第一个重要经验:
# 使用通道名称前,一定要先确认通道是否存在!
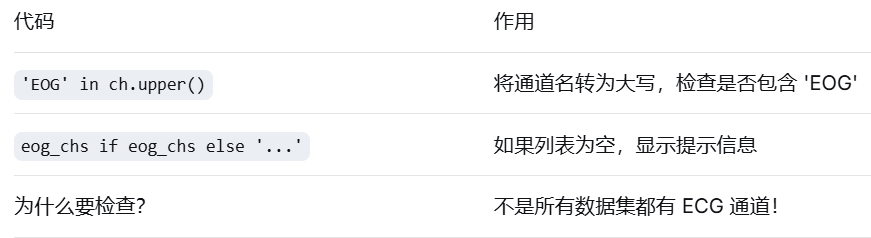
print("\n数据中的伪迹通道:")
# 查找 EOG 通道
# 遍历所有通道名,找包含 'EOG' 的(不区分大小写)
eog_chs = [ch for ch in raw_eeg.ch_names if 'EOG' in ch.upper()]
# 查找 ECG 通道
ecg_chs = [ch for ch in raw_eeg.ch_names if 'ECG' in ch.upper()]
print(f" EOG 通道: {eog_chs}")
print(f" ECG 通道: {ecg_chs if ecg_chs else '(没有 ECG 通道)'}")代码解析:
输出示例:
python
EOG 通道: ['EOG 061']
ECG 通道: (没有 ECG 通道) ← 这个数据集没有心电通道!⚠️ 重要经验:永远先检查通道是否存在,再使用它!
四、ICA 前预滤波
4.1 为什么 ICA 前要滤波?
python
ICA 需要稳定的信号来工作:
高通滤波(1Hz):
去除缓慢的基线漂移(皮肤出汗、电极移动)
让 ICA 专注于有意义的信号变化
不过滤太高频率:
ICA 需要利用眼电和心电的频率特征来识别它们
如果低通滤波太狠,可能去掉识别线索4.2 代码实现
python
# ---------- 2. ICA 前预滤波 ----------
print("\nICA前预滤波...")
# 复制数据,保持原数据不变
raw_for_ica = raw_eeg.copy()
# 🔑 关键:使用 mne.pick_types() 获取通道索引
# 不能用字符串 'eeg',因为 notch_filter 需要具体的通道索引
# 获取 EEG 通道的索引(整数列表)
picks_eeg_all = mne.pick_types(
raw_for_ica.info, # 数据信息
eeg=True, # 要 EEG 通道
eog=False, # 不要 EOG
ecg=False # 不要 ECG
)
# 获取 EOG 通道的索引
picks_eog_all = mne.pick_types(raw_for_ica.info, eog=True)
# 获取 ECG 通道的索引(可能为空列表)
picks_ecg_all = mne.pick_types(raw_for_ica.info, ecg=True)
# 合并所有需要滤波的通道索引
# list() 确保是列表格式
filter_picks = list(picks_eeg_all) + list(picks_eog_all) + list(picks_ecg_all)
print(f" 滤波通道数: {len(filter_picks)}")
print(f" EEG: {len(picks_eeg_all)} 个")
print(f" EOG: {len(picks_eog_all)} 个")
print(f" ECG: {len(picks_ecg_all)} 个")
# 陷波滤波:去除 60Hz 工频干扰
# picks=filter_picks:指定要滤波的通道索引
raw_for_ica.notch_filter(freqs=60, picks=filter_picks, verbose=False)
# 高通滤波:去除 <1Hz 的基线漂移
# l_freq=1:低截止频率 1Hz(只保留 >1Hz 的成分)
# h_freq=None:不做低通滤波(保留所有高频)
raw_for_ica.filter(l_freq=1, h_freq=None, picks=filter_picks, verbose=False)
print("✅ ICA 前预滤波完成")代码详解:

⚠️ 常见错误:
python
# ❌ 错误:'eeg' 是类型名,不是通道名
raw.notch_filter(freqs=60, picks=['eeg'])
# ❌ 错误:'EOG 061' 可能不存在
raw.notch_filter(freqs=60, picks=['EOG 061'])
# ✅ 正确:用 pick_types 获取实际存在的通道索引
picks = mne.pick_types(raw.info, eeg=True)
raw.notch_filter(freqs=60, picks=picks)五、运行 ICA
5.1 创建 ICA 对象
python
# ---------- 3. 运行 ICA ----------
print("\n运行ICA...")
# 创建 ICA 对象
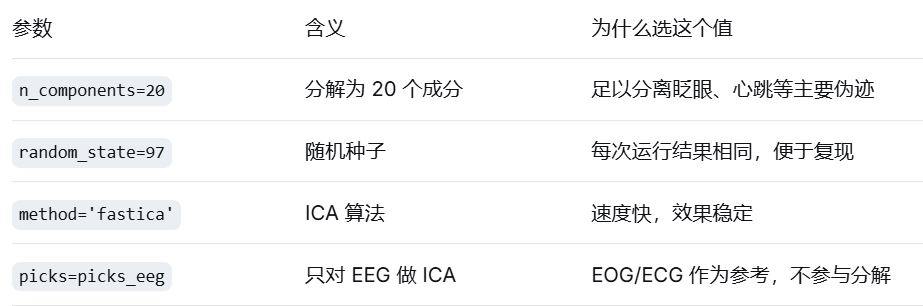
ica = ICA(
n_components=20, # 分解为 20 个独立成分
random_state=97, # 随机种子,确保结果可重复
method='fastica', # 使用 FastICA 算法
verbose=False # 不打印详细信息
)
# 获取 EEG 通道索引(不包含 EOG 和 ECG)
# ICA 只对 EEG 通道分解
picks_eeg = mne.pick_types(
raw_for_ica.info,
eeg=True, # 要 EEG
eog=False, # 不要 EOG
ecg=False # 不要 ECG
)
# fit():用数据训练 ICA 模型
# ICA 学习如何将 60 个通道的信号分解为 20 个独立成分
ica.fit(raw_for_ica, picks=picks_eeg)
print("✅ ICA 拟合完成")参数详解:
六、识别伪迹成分
6.1 识别眼电成分
python
# ---------- 4. 识别伪迹 ----------
print("\n识别伪迹成分...")
# 4.1 识别眼电成分
eog_indices = []
# 🔑 防御性编程:先检查 EOG 通道是否存在
if eog_chs:
# eog_chs[0]:使用第一个 EOG 通道
eog_indices, _ = ica.find_bads_eog(
raw_for_ica, # 包含 EOG 通道的原始数据
ch_name=eog_chs[0], # EOG 通道名称
threshold=3.0 # Z-score 阈值
)
print(f" 眼电成分: {eog_indices}")
else:
print(" ⚠️ 没有 EOG 通道,跳过眼电检测")find_bads_eog() 的工作原理:
python
步骤1:计算每个 ICA 成分与 EOG 通道的相关系数
步骤2:计算所有相关系数的 Z-score
步骤3:Z-score > 3.0 的成分 → 标记为眼电伪迹
Z-score = (该成分的相关系数 - 平均相关系数) / 标准差
Z-score > 3 → 该成分与眼电的相关性显著高于其他成分为什么只用 eog_chs[0]?
因为这个数据集中只有一个 EOG 通道 ,所以 eog_chs[0] 就是唯一的那个。find_bads_eog() 只需要一个 EOG 通道作为参考就够了。
python
工作原理:
┌─────────────────────────────────────────┐
│ │
│ EOG 通道(参考) │
│ ↓ │
│ 计算每个 ICA 成分与 EOG 的相关系数 │
│ ↓ │
│ 成分0 与 EOG 相关: 0.95 ← 眼电! │
│ 成分1 与 EOG 相关: 0.12 │
│ 成分2 与 EOG 相关: 0.88 ← 眼电! │
│ 成分3 与 EOG 相关: 0.05 │
│ ... │
│ ↓ │
│ 标记相关性最高的成分为眼电伪迹 │
│ │
└─────────────────────────────────────────┘
只需要一个 EOG 通道作为"参考答案"就够了
多个 EOG 通道并不会提高检测精度6.2 识别心电成分
python
# 4.2 识别心电成分
ecg_indices = []
# 🔑 防御性编程:先检查 ECG 通道是否存在
if ecg_chs:
ecg_indices, _ = ica.find_bads_ecg(
raw_for_ica,
ch_name=ecg_chs[0], # ECG 通道名称
threshold=3.0
)
print(f" 心电成分: {ecg_indices}")
else:
print(" ⚠️ 没有 ECG 通道,跳过心电检测")find_bads_ecg() 的工作原理:
python
步骤1:从 ECG 通道检测心跳(QRS 波群)
步骤2:计算每个 ICA 成分在心电事件时刻的活动
步骤3:活动与心跳高度同步的成分 → 标记为心电伪迹6.3 合并排除列表
python
# 4.3 合并排除列表
# set() 去重:如果一个成分同时被识别为眼电和心电,只保留一次
ica.exclude = list(set(eog_indices + ecg_indices))
print(f" 总计去除: {len(ica.exclude)} 个成分")
七、应用 ICA 去除伪迹
python
# ---------- 5. 应用 ICA ----------
print("\n应用ICA...")
# apply() 的工作流程:
# 1. 将原始信号分解为 20 个独立成分
# 2. 去除 ica.exclude 中标记的成分(设为 0)
# 3. 用剩余成分重建干净的脑电信号
raw_clean = ica.apply(raw_for_ica.copy())
print("✅ ICA 应用完成")ICA 应用原理图:
python
原始数据(60通道)
↓
ICA 分解
↓
┌─────────────────────────────────┐
│ 成分0:大脑视觉活动 → 保留 │
│ 成分1:眨眼伪迹 → 去除 │
│ 成分2:大脑听觉活动 → 保留 │
│ 成分3:心跳伪迹 → 去除 │
│ 成分4:大脑运动活动 → 保留 │
│ ... │
└─────────────────────────────────┘
↓
去除成分1和3
↓
重建信号(60通道干净脑电)八、保存结果
python
# ---------- 6. 保存结果 ----------
# save() 将 Raw 对象保存为 .fif 文件
# overwrite=True:如果文件已存在,覆盖它
raw_clean.save('day5_cleaned_eeg.fif', overwrite=True)
print("\n✅ 清洗后数据已保存为 day5_cleaned_eeg.fif")九、完整代码
python
# ========== 环境设置 ==========
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import mne
from mne.preprocessing import ICA
import numpy as np
import os
from collections import Counter
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第5天:伪迹处理(ICA)")
print("="*60)
# ---------- 1. 加载数据 ----------
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, ecg=True, stim=True)
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
montage = mne.channels.make_standard_montage('standard_1020')
standard_names = montage.ch_names[:len(eeg_names)]
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
raw_eeg.set_montage(montage)
raw_eeg.load_data()
print("✅ 数据加载完成")
# ---------- 1.5 查看实际有哪些通道 ----------
print("\n数据中的伪迹通道:")
eog_chs = [ch for ch in raw_eeg.ch_names if 'EOG' in ch.upper()]
ecg_chs = [ch for ch in raw_eeg.ch_names if 'ECG' in ch.upper()]
print(f" EOG 通道: {eog_chs}")
print(f" ECG 通道: {ecg_chs if ecg_chs else '(没有 ECG 通道)'}")
# ---------- 2. ICA 前预滤波 ----------
print("\nICA前预滤波...")
raw_for_ica = raw_eeg.copy()
# 🔧 修改:用 mne.pick_types 来获取 EEG 通道索引
picks_eeg_all = mne.pick_types(raw_for_ica.info, eeg=True, eog=False, ecg=False)
picks_eog_all = mne.pick_types(raw_for_ica.info, eog=True)
picks_ecg_all = mne.pick_types(raw_for_ica.info, ecg=True)
# 合并所有需要滤波的通道索引
filter_picks = list(picks_eeg_all) + list(picks_eog_all) + list(picks_ecg_all)
print(f" 滤波通道数: {len(filter_picks)}")
print(f" EEG: {len(picks_eeg_all)} 个")
print(f" EOG: {len(picks_eog_all)} 个")
print(f" ECG: {len(picks_ecg_all)} 个")
raw_for_ica.notch_filter(freqs=60, picks=filter_picks, verbose=False)
raw_for_ica.filter(l_freq=1, h_freq=None, picks=filter_picks, verbose=False)
print("✅ ICA 前预滤波完成")
# ---------- 3. 运行 ICA ----------
print("\n运行ICA...")
ica = ICA(n_components=20, random_state=97, method='fastica', verbose=False)
picks_eeg = mne.pick_types(raw_for_ica.info, eeg=True, eog=False, ecg=False)
ica.fit(raw_for_ica, picks=picks_eeg)
print("✅ ICA 拟合完成")
# ---------- 4. 识别伪迹 ----------
print("\n识别伪迹成分...")
# 4.1 识别眼电成分
eog_indices = []
if eog_chs:
eog_indices, _ = ica.find_bads_eog(
raw_for_ica,
ch_name=eog_chs[0],
threshold=3.0
)
print(f" 眼电成分: {eog_indices}")
else:
print(" ⚠️ 没有 EOG 通道,跳过眼电检测")
# 4.2 识别心电成分
ecg_indices = []
if ecg_chs:
ecg_indices, _ = ica.find_bads_ecg(
raw_for_ica,
ch_name=ecg_chs[0],
threshold=3.0
)
print(f" 心电成分: {ecg_indices}")
else:
print(" ⚠️ 没有 ECG 通道,跳过心电检测")
# 4.3 合并排除列表
ica.exclude = list(set(eog_indices + ecg_indices))
print(f" 总计去除: {len(ica.exclude)} 个成分")
# ---------- 5. 应用 ICA ----------
print("\n应用ICA...")
raw_clean = ica.apply(raw_for_ica.copy())
print("✅ ICA 应用完成")
# ---------- 6. 保存结果 ----------
raw_clean.save('day5_cleaned_eeg.fif', overwrite=True)
print("\n✅ 清洗后数据已保存为 day5_cleaned_eeg.fif")
print("\n" + "="*60)
print("第5天学习完成!")
print("="*60)这里有一个问题:
为什么此处已经滤除了eog和ecg
python
picks_eeg = mne.pick_types(raw_for_ica.info, eeg=True, eog=False, ecg=False)这里还要再去滤除与eog和ecg相关的成分呢?
python
eog_indices = []
if eog_chs:
eog_indices, _ = ica.find_bads_eog(
raw_for_ica,
ch_name=eog_chs[0],
threshold=3.0
)
print(f" 眼电成分: {eog_indices}")
else:
print(" ⚠️ 没有 EOG 通道,跳过眼电检测")
# 4.2 识别心电成分
ecg_indices = []
if ecg_chs:
ecg_indices, _ = ica.find_bads_ecg(
raw_for_ica,
ch_name=ecg_chs[0],
threshold=3.0
)
print(f" 心电成分: {ecg_indices}")
else:
print(" ⚠️ 没有 ECG 通道,跳过心电检测")