一、什么是"事件"?
1.1 通俗理解
想象你在做一个实验:
👂 听到"嘀"声 → 这是事件 1
👂 听到"嘟"声 → 这是事件 2
👁️ 看到闪光 → 这是事件 3
每一次刺激就是一个**"事件"** 。在脑电数据中,事件就是记录实验过程中发生了什么、什么时候发生的标记。
1.2 事件在数据中的存储
原始数据:
EEG通道1: [0.1, 0.2, 0.1, 0.3, 0.2, ...] ← 脑电波
EEG通道2: [0.2, 0.1, 0.3, 0.2, 0.1, ...] ← 脑电波
...
刺激通道: [0, 0, 0, 1, 0, 0, 0, 2, 0, ...] ← 事件标记
↑ ↑
事件1发生 事件2发生刺激通道(STIM) 平时是 0,事件发生时变成对应的编号。
1.3 事件的三个要素

二、实战:探索数据中的事件
2.1 ⚠️ 重要经验:先探索,后定义
很多教程直接告诉你事件编号是 1、2、3、4,但实际数据往往更复杂。正确的做法是:
先查看数据中有哪些事件编号 → 再创建 event_id 字典2.2 完整代码:环境准备
python
# ========== 环境设置 ==========
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import mne
import numpy as np
import os
from collections import Counter
import warnings
warnings.filterwarnings('ignore') # 忽略无关警告
# ========== 中文字体设置 ==========
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第3天:事件与标记处理")
print("="*60)
# 加载数据
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
print("✅ 数据加载完成")代码解析:
三、查看刺激通道
3.1 找到刺激通道
python
print("\n" + "="*60)
print("查看刺激通道")
print("="*60)
# mne.pick_types() 用于根据通道类型筛选通道索引
# stim=True 表示只选择刺激类型的通道
stim_picks = mne.pick_types(raw.info, stim=True)
print(f"刺激通道索引: {stim_picks}")
# 列表推导式:根据索引获取通道名称
print(f"刺激通道名称: {[raw.ch_names[i] for i in stim_picks]}")代码解析:

输出解读:
python
刺激通道索引: [306]
刺激通道名称: ['STI 014']数据中有一个刺激通道,索引为 306,名叫 STI 014。
3.2 查看刺激通道的原始数据
python
# raw.get_data() 获取指定通道的原始数据
# picks='STI 014' 指定获取名为 'STI 014' 的通道
stim_data = raw.get_data(picks='STI 014')
# np.unique() 找出数组中所有不重复的值
unique_values = np.unique(stim_data)
print(f"刺激通道中的唯一值: {unique_values}")代码解析:

输出示例:
python
刺激通道中的唯一值: [0 1 2 3 4 5 32]这说明数据中有 7 种不同的值:
(1)0****= 无事件(基线状态)
(2)1, 2, 3, 4, 5, 32****= 不同的事件类型编号
四、提取事件(核心步骤)
4.1 使用 find_events 函数
python
print("\n" + "="*60)
print("提取事件")
print("="*60)
# mne.find_events() 从刺激通道中自动检测事件
# stim_channel='STI 014' 指定使用哪个通道作为刺激通道
events = mne.find_events(raw, stim_channel='STI 014')
print(f"✅ 提取到 {len(events)} 个事件")
# .shape 返回数组的形状:(行数, 列数)
print(f"事件数组形状: {events.shape}")
print(f" 行数 = 事件总数: {events.shape[0]}")
print(f" 列数 = 3 (采样点, 持续时间, 事件编号)")代码解析:

find_events() 的工作原理:
(1)监控刺激通道的值
(2)当值从 0 变为非 0 时,记录为事件开始
(3)当值变回 0 时,记录为事件结束
(4)输出事件数组:[开始采样点, 持续采样点数, 事件编号]
4.2 事件数组详解
python
# events 是一个 N×3 的二维数组
# 每一行 = [采样点编号, 持续采样点数, 事件编号]
# N = 事件总数
# 查看前 5 个事件
print("\n前 5 个事件:")
print(f"{'采样点':<10}{'持续时间':<10}{'事件编号':<10}{'时间(秒)':<10}")
print("-" * 40)
for i in range(5):
sample = events[i, 0] # events[i, 0] = 第 i 个事件的采样点位置
duration = events[i, 1] # events[i, 1] = 第 i 个事件的持续时间
event_id = events[i, 2] # events[i, 2] = 第 i 个事件的事件编号
time_sec = sample / raw.info['sfreq'] # 采样点 / 采样率 = 时间(秒)
print(f"{sample:<10}{duration:<10}{event_id:<10}{time_sec:<10.3f}")代码解析:
4.3 🔑 关键步骤:发现所有事件编号
这是今天最重要的经验!
python
print("\n" + "="*60)
print("🔍 发现所有事件编号(重要!)")
print("="*60)
# np.unique(events[:, 2]) 提取事件数组第2列(事件编号),找出所有唯一值
all_event_ids = np.unique(events[:, 2])
print(f"数据中的所有事件编号: {all_event_ids}")
# 统计每个编号出现的次数
print("\n各事件编号出现次数:")
for eid in all_event_ids:
# np.sum(events[:, 2] == eid) 统计等于 eid 的行数
count = np.sum(events[:, 2] == eid)
print(f" 编号 {eid}: {count} 次")代码解析:

输出示例:
python
数据中的所有事件编号: [1 2 3 4 5 32]
各事件编号出现次数:
编号 1: 72 次
编号 2: 73 次
编号 3: 72 次
编号 4: 73 次
编号 5: 12 次
编号 32: 1 次
五、创建事件 ID 字典
5.1 包含所有事件编号
python
print("\n" + "="*60)
print("📝 创建事件 ID 字典")
print("="*60)
# event_id 字典:键 = 有意义的名称,值 = 对应的事件编号
event_id = {
'听觉/左耳': 1,
'听觉/右耳': 2,
'视觉/左眼': 3,
'视觉/右眼': 4,
'事件5': 5, # 补充发现的事件(实际含义需查实验记录)
'事件32': 32 # 补充发现的事件(实际含义需查实验记录)
}
# 遍历字典,统计每种事件的数量
print("事件 ID 字典:")
for event_name, event_code in event_id.items():
# .items() 返回 (键, 值) 对
count = np.sum(events[:, 2] == event_code)
print(f" {event_name} (编号{event_code}): {count} 次")代码解析:
5.2 如果不补全会怎样?
python
# ❌ 不完整的事件 ID(缺少编号 5 和 32)
event_id_incomplete = {
'听觉/左耳': 1,
'听觉/右耳': 2,
'视觉/左眼': 3,
'视觉/右眼': 4
# 缺少 5 和 32!
}
# 如果使用不完整的 event_id 绘图或分段:
# 会触发 RuntimeWarning 警告
# 编号 5 和 32 的事件会被忽略,可能导致数据丢失教训:永远先查看数据中实际有哪些事件编号,再创建 event_id!
六、事件可视化
6.1 标准事件分布图
python
print("\n" + "="*60)
print("🎨 事件可视化")
print("="*60)
# 使用英文标签(避免 DejaVu Sans 字体不支持中文的问题)
event_id_en = {
'Auditory/Left': 1,
'Auditory/Right': 2,
'Visual/Left': 3,
'Visual/Right': 4,
'Event5': 5,
'Event32': 32
}
print("绘制事件分布图...")
# mne.viz.plot_events() 绘制事件时间线图
fig = mne.viz.plot_events(
events, # 事件数组
sfreq=raw.info['sfreq'], # 采样率(用于计算时间轴)
first_samp=raw.first_samp, # 数据第一个采样点的编号
event_id=event_id_en, # 事件 ID 字典(提供标签)
show=True # 显示图形
)
plt.title('Experimental Events Timeline', fontsize=14)
plt.show(block=True) # block=True 保持窗口打开代码解析:

6.2 自定义事件分布图(支持中文)
python
print("\n绘制自定义事件分布图...")
# plt.subplots() 创建画布和坐标轴
# figsize=(12, 4) 设置画布大小:宽12英寸,高4英寸
fig, ax = plt.subplots(figsize=(12, 4))
# 为每种事件选择颜色
colors = ['red', 'blue', 'green', 'orange', 'purple', 'brown']
y_labels = list(event_id.keys()) # 将字典的键转为列表,作为 Y 轴标签
# 遍历每种事件,在图上绘制竖线
for idx, (event_name, event_code) in enumerate(event_id.items()):
# 创建布尔掩码:该事件类型的行为 True
mask = events[:, 2] == event_code
# 只处理有出现的事件类型
if np.sum(mask) > 0:
# 获取该事件的所有时间点(秒)
event_times = events[mask, 0] / raw.info['sfreq']
# 创建 Y 轴位置数组(所有竖线在同一水平线上)
y_pos = np.ones_like(event_times) * idx
# ax.vlines() 绘制竖线
# y_pos-0.4 到 y_pos+0.4 是竖线的长度
ax.vlines(event_times, y_pos - 0.4, y_pos + 0.4,
colors=colors[idx % len(colors)],
linewidths=1.5,
label=event_name)
# 设置 Y 轴刻度和标签
ax.set_yticks(range(len(y_labels)))
ax.set_yticklabels(y_labels, fontsize=12)
# 设置 X 轴标签和标题
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_title('实验事件分布图', fontsize=14, fontweight='bold')
# 显示图例
ax.legend(loc='upper right', fontsize=8)
# 添加网格线
ax.grid(True, alpha=0.3, axis='x')
# 设置 X 轴范围
ax.set_xlim(0, raw.times[-1])
# 调整布局并保存
plt.tight_layout()
plt.savefig('day3_events_custom.png', dpi=150, bbox_inches='tight')
plt.show(block=True)6.3 事件类型饼图
python
print("\n绘制事件类型饼图...")
fig, ax = plt.subplots(figsize=(8, 6))
# 统计每种事件的数量
event_counts = []
event_labels = []
for event_name, event_code in event_id.items():
count = np.sum(events[:, 2] == event_code)
if count > 0: # 只包含有出现的事件
event_counts.append(count)
event_labels.append(f'{event_name}\n(编号{event_code}, n={count})')
# ax.pie() 绘制饼图
ax.pie(
event_counts, # 各部分的数量
labels=event_labels, # 各部分的标签
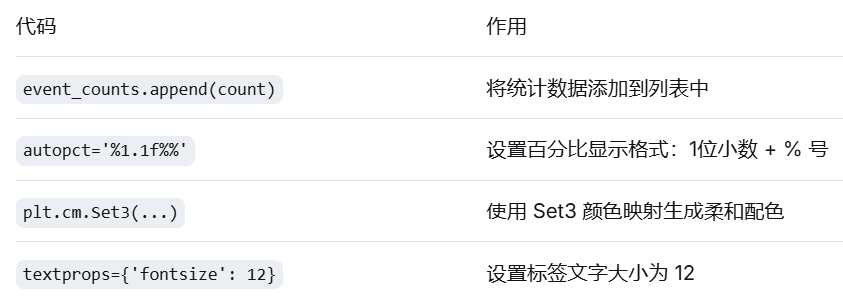
autopct='%1.1f%%', # 显示百分比,保留1位小数
colors=plt.cm.Set3(range(len(event_counts))), # 使用 Set3 配色方案
textprops={'fontsize': 12} # 文字属性:字号12
)
ax.set_title('事件类型分布', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('day3_events_pie.png', dpi=150, bbox_inches='tight')
plt.show(block=True)代码解析:
七、事件时间统计
python
print("\n" + "="*60)
print("⏱️ 事件时间统计")
print("="*60)
for event_name, event_code in event_id_en.items():
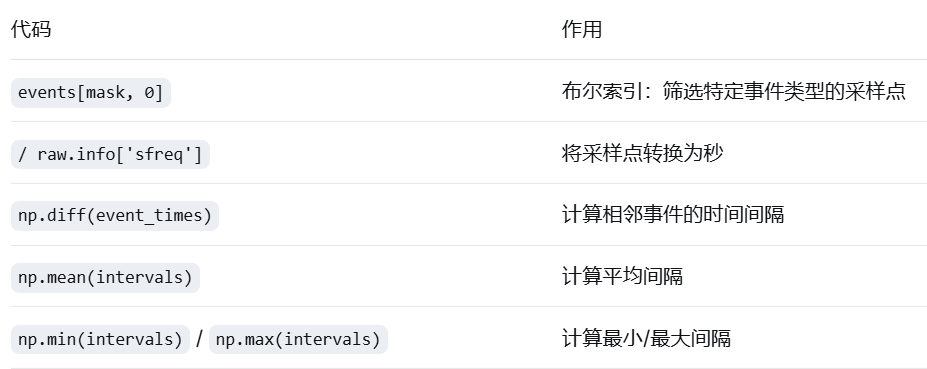
# 筛选该类型的事件
mask = events[:, 2] == event_code
if np.sum(mask) > 0:
# 获取该事件所有出现的时间点
event_times = events[mask, 0] / raw.info['sfreq']
print(f"\n{event_name}:")
print(f" 出现次数: {len(event_times)}")
print(f" 首次出现: {event_times[0]:.2f} 秒")
print(f" 最后出现: {event_times[-1]:.2f} 秒")
# 如果有多个事件,计算间隔
if len(event_times) > 1:
# np.diff() 计算相邻元素的差值
intervals = np.diff(event_times)
print(f" 平均间隔: {np.mean(intervals):.2f} 秒")
print(f" 最小间隔: {np.min(intervals):.2f} 秒")
print(f" 最大间隔: {np.max(intervals):.2f} 秒")代码解析:
八、数据整合:EEG + 事件
将第2天和第3天的知识结合起来:
python
print("\n" + "="*60)
print("🔄 数据整合:EEG + 事件")
print("="*60)
# ===== 使用第2天的方法处理 EEG 数据 =====
# 步骤1:提取 EEG 通道
raw_eeg = raw.copy().pick_types(eeg=True)
# 步骤2:创建标准 Montage
montage = mne.channels.make_standard_montage('standard_1020')
# 步骤3:重命名通道(EEG 001 → Fz, EEG 002 → Cz, ...)
eeg_names = raw_eeg.ch_names
standard_names = montage.ch_names[:len(eeg_names)]
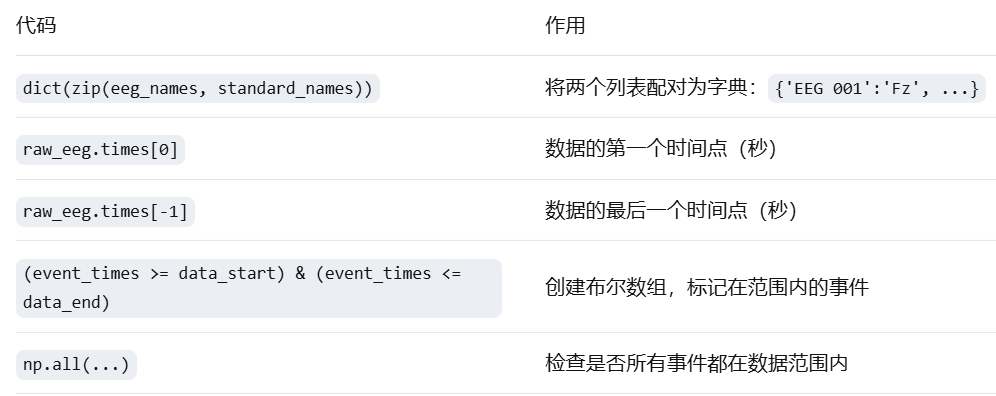
# dict(zip(A, B)) 将两个列表配对成字典
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
# 步骤4:设置电极位置
raw_eeg.set_montage(montage)
print(f"EEG 数据: {len(raw_eeg.ch_names)} 个通道")
print(f"事件数据: {len(events)} 个事件")
# ===== 验证数据一致性 =====
data_start = raw_eeg.times[0] # 数据开始时间
data_end = raw_eeg.times[-1] # 数据结束时间
event_times = events[:, 0] / raw.info['sfreq'] # 所有事件的时间
print(f"数据时间范围: {data_start:.1f} - {data_end:.1f} 秒")
print(f"事件时间范围: {event_times[0]:.1f} - {event_times[-1]:.1f} 秒")
# 确认所有事件都在数据范围内
all_in_range = np.all((event_times >= data_start) & (event_times <= data_end))
print(f"所有事件都在数据范围内: {all_in_range}")
print("\n✅ EEG数据 + 事件数据 准备就绪!")
print("可以进入第4天的分段分析")代码解析:
九、第3天完整可运行代码
python
# ========== 环境设置 ==========
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import mne
import numpy as np
import os
from collections import Counter
import warnings
warnings.filterwarnings('ignore') # 忽略无关警告
# ========== 中文字体设置 ==========
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第3天:事件与标记处理")
print("="*60)
# ---------- 1. 加载数据 ----------
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
print("✅ 数据加载完成")
# ---------- 2. 查看刺激通道 ----------
print("\n查看刺激通道...")
stim_picks = mne.pick_types(raw.info, stim=True)
print(f" 刺激通道: {[raw.ch_names[i] for i in stim_picks]}")
# ---------- 3. 提取事件 ----------
print("\n提取事件...")
events = mne.find_events(raw, stim_channel='STI 014')
print(f" 提取到 {len(events)} 个事件")
# ---------- 4. 查看数据中有哪些事件编号 ----------
print("\n数据中的所有事件编号:")
all_event_ids = np.unique(events[:, 2])
print(f" {all_event_ids}")
# 统计每个编号的数量
print("\n各事件编号出现次数:")
for eid in all_event_ids:
count = np.sum(events[:, 2] == eid)
print(f" 编号 {eid}: {count} 次")
# ---------- 5. 创建完整的事件 ID 字典 ----------
# 包含所有出现的事件编号
event_id = {
'听觉/左耳': 1,
'听觉/右耳': 2,
'视觉/左眼': 3,
'视觉/右眼': 4,
'事件5': 5, # 补充缺失的事件
'事件32': 32 # 补充缺失的事件
}
print("\n事件 ID 字典:")
for event_name, event_code in event_id.items():
count = np.sum(events[:, 2] == event_code)
print(f" {event_name} (编号{event_code}): {count} 次")
# ---------- 6. 事件可视化 ----------
print("\n绘制事件分布图...")
# 方法1:使用英文命名避免字体问题(推荐)
event_id_en = {
'Auditory/Left': 1,
'Auditory/Right': 2,
'Visual/Left': 3,
'Visual/Right': 4,
'Event5': 5,
'Event32': 32
}
fig = mne.viz.plot_events(
events,
sfreq=raw.info['sfreq'],
first_samp=raw.first_samp,
event_id=event_id_en, # 使用英文标签
show=True
)
plt.title('Experimental Events Timeline', fontsize=14)
plt.show(block=True)
# ---------- 7. 事件时间统计 ----------
print("\n事件时间统计:")
for event_name, event_code in event_id_en.items():
mask = events[:, 2] == event_code
if np.sum(mask) > 0:
event_times = events[mask, 0] / raw.info['sfreq']
print(f" {event_name}:")
print(f" 次数: {len(event_times)}")
print(f" 首次: {event_times[0]:.2f}秒")
print(f" 末次: {event_times[-1]:.2f}秒")
# ---------- 8. 自定义事件图(支持中文) ----------
print("\n绘制自定义事件分布图...")
fig, ax = plt.subplots(figsize=(12, 4))
# 手动绘制事件线
colors = ['red', 'blue', 'green', 'orange', 'purple', 'brown']
y_labels = list(event_id.keys()) # 中文标签
for idx, (event_name, event_code) in enumerate(event_id.items()):
mask = events[:, 2] == event_code
if np.sum(mask) > 0:
event_times = events[mask, 0] / raw.info['sfreq']
y_pos = np.ones_like(event_times) * idx
ax.vlines(event_times, y_pos - 0.4, y_pos + 0.4,
colors=colors[idx % len(colors)],
linewidths=1.5, label=event_name)
ax.set_yticks(range(len(y_labels)))
ax.set_yticklabels(y_labels, fontsize=12)
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_title('实验事件分布图', fontsize=14, fontweight='bold')
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.3, axis='x')
ax.set_xlim(0, raw.times[-1])
plt.tight_layout()
plt.savefig('day3_events_custom.png', dpi=150, bbox_inches='tight')
print(" 图表已保存为 day3_events_custom.png")
plt.show(block=True)
# ---------- 9. 事件类型饼图(中文) ----------
print("\n绘制事件类型饼图...")
fig, ax = plt.subplots(figsize=(8, 6))
event_counts = []
event_labels = []
for event_name, event_code in event_id.items():
count = np.sum(events[:, 2] == event_code)
if count > 0:
event_counts.append(count)
event_labels.append(f'{event_name}\n(编号{event_code}, n={count})')
ax.pie(event_counts, labels=event_labels, autopct='%1.1f%%',
colors=plt.cm.Set3(range(len(event_counts))),
textprops={'fontsize': 12})
ax.set_title('事件类型分布', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('day3_events_pie.png', dpi=150, bbox_inches='tight')
print(" 饼图已保存为 day3_events_pie.png")
plt.show(block=True)
# ---------- 10. 整合 EEG 数据 ----------
print("\n整合 EEG 数据...")
raw_eeg = raw.copy().pick_types(eeg=True)
montage = mne.channels.make_standard_montage('standard_1020')
eeg_names = raw_eeg.ch_names
standard_names = montage.ch_names[:len(eeg_names)]
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
raw_eeg.set_montage(montage)
print(" EEG数据 + 事件数据 准备就绪")
print("\n" + "="*60)
print("第3天学习完成!")
print("="*60)十、今日总结
📝 核心概念

🛠️ 掌握的技能

🔑 核心经验
"先探索,后定义"
不要假设数据中只有 1、2、3、4 号事件。
先用 np.unique(events[:, 2]) 查看实际有哪些编号,再创建 event_id。
🔑 关键函数速查
python
# 事件提取
events = mne.find_events(raw, stim_channel='STI 014')
# 事件编号探索
all_ids = np.unique(events[:, 2]) # 所有编号
count = np.sum(events[:, 2] == id) # 某个编号出现次数
times = events[events[:, 2]==id, 0] / sfreq # 某个编号的时间点
# 事件可视化
mne.viz.plot_events(events, sfreq=..., event_id=...)
# 时间转换
seconds = sample_number / raw.info['sfreq'] # 采样点 → 秒