多层感知器(MLP)计算过程分析
-
- 一、文件概述
-
- [1.1 网络结构概览](#1.1 网络结构概览)
- [1.2 网络结构图](#1.2 网络结构图)
- 二、Excel表格结构分析
-
- [2.1 列结构说明](#2.1 列结构说明)
- 三、数据提取与整理
-
- [3.1 初始参数汇总](#3.1 初始参数汇总)
- 四、MLP计算流程详解
-
- [4.1 第一步:前向传播计算](#4.1 第一步:前向传播计算)
-
- [4.1.1 隐藏层加权和计算](#4.1.1 隐藏层加权和计算)
- [4.1.2 隐藏层输出](#4.1.2 隐藏层输出)
- [4.1.3 输出层计算](#4.1.3 输出层计算)
- [4.1.4 误差计算](#4.1.4 误差计算)
- [4.2 第二步:反向传播计算](#4.2 第二步:反向传播计算)
-
- [4.2.1 输出层导数计算](#4.2.1 输出层导数计算)
- [4.2.2 隐藏层→输出层权重梯度](#4.2.2 隐藏层→输出层权重梯度)
- [4.2.3 隐藏层→输出层权重调整幅度](#4.2.3 隐藏层→输出层权重调整幅度)
- [4.2.4 隐藏层→输出层权重更新](#4.2.4 隐藏层→输出层权重更新)
- [4.2.5 输出层偏置梯度与更新](#4.2.5 输出层偏置梯度与更新)
- [4.2.6 输入层→隐藏层权重梯度](#4.2.6 输入层→隐藏层权重梯度)
- [4.2.7 输入层→隐藏层权重调整幅度](#4.2.7 输入层→隐藏层权重调整幅度)
- [4.2.8 输入层→隐藏层权重更新](#4.2.8 输入层→隐藏层权重更新)
- [4.2.9 隐藏层偏置梯度与更新](#4.2.9 隐藏层偏置梯度与更新)
- 五、参数更新汇总表
-
- [5.1 输入层→隐藏层参数更新](#5.1 输入层→隐藏层参数更新)
- [5.2 隐藏层→输出层参数更新](#5.2 隐藏层→输出层参数更新)
- [5.3 多次训练](#5.3 多次训练)
- 六、MLP计算原理总结
-
- [6.1 前向传播公式](#6.1 前向传播公式)
- [6.2 反向传播公式](#6.2 反向传播公式)
- [6.3 参数更新规则](#6.3 参数更新规则)
- 七、关键观察与说明
一、文件概述
本文档详细分析 计算示例.xlsx 中展示的多层感知器(MLP)前向传播与反向传播计算过程。
1.1 网络结构概览
| 参数 | 值 | 说明 |
|---|---|---|
| 输入层神经元数 | 1 | 单个输入值 |
| 隐藏层神经元数 | 6 | B1-B6共6个神经元 |
| 输出层神经元数 | 1 | 单个输出值 |
| 学习率(η) | 0.01 | 权重更新步长 |
1.2 网络结构图
输入层(5)
↓ W1-W6(权重)
隐藏层(B1-B6)
↓ W'1-W'6(权重)
输出层(ŷ)二、Excel表格结构分析
2.1 列结构说明
| 列号 | 列名 | 数据类型 | 用途 |
|---|---|---|---|
| A | 学习系数 | 数值 | 学习率 η = 0.01 |
| B | 0.01 | 数值 | 学习率具体值 |
| C | Bias(B1-B6) | 数值 | 隐藏层偏置初始值 |
| D | Bi新 | 数值 | 更新后的偏置值 |
| E | Bi导数 | 数值 | 偏置梯度 |
| F | Bi调整幅度 | 数值 | 偏置调整量 |
| H | W1-W6 | 数值 | 输入→隐藏层权重 |
| I | W1-W6新 | 数值 | 更新后的权重 |
| J | w导数 | 数值 | 权重梯度 |
| K | w调整幅度 | 数值 | 权重调整量 |
| N | 隐藏层加权和 | 数值 | Σ(输入×权重)+偏置 |
| O | 隐藏层输出值 | 数值 | 隐藏层神经元输出 |
| Q | W'1-W'6 | 数值 | 隐藏层→输出层权重 |
| R | W'1-W'6新 | 数值 | 更新后的权重 |
| S | w'导数 | 数值 | 权重梯度 |
| T | w'调整幅度 | 数值 | 权重调整量 |
| W | 输出加权和 | 数值 | Σ(隐藏输出×权重')+偏置 |
| X | 最终输出值 | 数值 | 网络预测值 |
| Y | 真实目标值 | 数值 | 期望值 |
| Z | 误差平方 | 数值 | (目标-输出)² |
| AA | 导数 | 数值 | 误差对输出的导数 |
三、数据提取与整理
3.1 初始参数汇总
输入数据:
| 参数 | 值 |
|---|---|
| 输入值 x | 5 |
| 学习率 η | 0.01 |
隐藏层参数(6个神经元B1-B6):
| 神经元 | 初始偏置(Bi) | 初始权重(Wi) |
|---|---|---|
| B1 | 10 | 10 |
| B2 | 10 | 20 |
| B3 | 10 | 30 |
| B4 | 10 | 20 |
| B5 | 10 | 10 |
| B6 | 10 | 20 |
输出层参数:
| 参数 | 值 |
|---|---|
| 输出层偏置(B) | 20 |
| 目标值(t) | 208 |
隐藏层→输出层权重(W'1-W'6):
| 权重 | 值 |
|---|---|
| W'1 | 10 |
| W'2 | 20 |
| W'3 | 10 |
| W'4 | 10 |
| W'5 | 30 |
| W'6 | 20 |
四、MLP计算流程详解
4.1 第一步:前向传播计算
4.1.1 隐藏层加权和计算
公式: 加权和 = 输入值 × 权重 + 偏置
| 神经元 | 加权和计算 | 结果 |
|---|---|---|
| B1 | 5 × 10 + 10 | 60 |
| B2 | 5 × 20 + 10 | 110 |
| B3 | 5 × 30 + 10 | 160 |
| B4 | 5 × 20 + 10 | 110 |
| B5 | 5 × 10 + 10 | 60 |
| B6 | 5 × 20 + 10 | 110 |
4.1.2 隐藏层输出
观察: 该Excel中隐藏层未使用非线性激活函数(如Sigmoid、ReLU),直接输出加权和。
| 神经元 | 输出值 |
|---|---|
| B1 | 60 |
| B2 | 110 |
| B3 | 160 |
| B4 | 110 |
| B5 | 60 |
| B6 | 110 |
4.1.3 输出层计算
输出加权和 = Σ(隐藏层输出 × 对应权重') + 输出层偏置
输出加权和 = (60×10) + (110×20) + (160×10) + (110×10) + (60×30) + (110×20) + 20
= 600 + 2200 + 1600 + 1100 + 1800 + 2200 + 20
= 9520最终输出值: ŷ = 9520(无激活函数)
4.1.4 误差计算
误差平方 = (目标值 - 输出值)²
误差平方 = (208 - 9520)² = (-9312)² = 867133444.2 第二步:反向传播计算
4.2.1 输出层导数计算
误差对输出的导数 = 2 × (输出值 - 目标值)
导数 = 2 × (9520 - 208) = 2 × 9312 = 186244.2.2 隐藏层→输出层权重梯度
权重梯度 = 导数 × 对应隐藏层输出
| 权重 | 梯度计算 | 结果 |
|---|---|---|
| W'1 | 18624 × 60 | 1,117,440 |
| W'2 | 18624 × 110 | 2,048,640 |
| W'3 | 18624 × 160 | 2,979,840 |
| W'4 | 18624 × 110 | 2,048,640 |
| W'5 | 18624 × 60 | 1,117,440 |
| W'6 | 18624 × 110 | 2,048,640 |
4.2.3 隐藏层→输出层权重调整幅度
调整幅度 = 梯度 × 学习率
| 权重 | 调整幅度 |
|---|---|
| W'1 | 1,117,440 × 0.01 = 11,174.4 |
| W'2 | 2,048,640 × 0.01 = 20,486.4 |
| W'3 | 2,979,840 × 0.01 = 29,798.4 |
| W'4 | 2,048,640 × 0.01 = 20,486.4 |
| W'5 | 1,117,440 × 0.01 = 11,174.4 |
| W'6 | 2,048,640 × 0.01 = 20,486.4 |
4.2.4 隐藏层→输出层权重更新
新权重 = 旧权重 - 调整幅度
| 权重 | 更新计算 | 新值 |
|---|---|---|
| W'1 | 10 - 11,174.4 | -11,164.4 |
| W'2 | 20 - 20,486.4 | -20,466.4 |
| W'3 | 10 - 29,798.4 | -29,788.4 |
| W'4 | 10 - 20,486.4 | -20,476.4 |
| W'5 | 30 - 11,174.4 | -11,144.4 |
| W'6 | 20 - 20,486.4 | -20,466.4 |
4.2.5 输出层偏置梯度与更新
偏置梯度 = 导数 = 18624
偏置调整幅度 = 18624 × 0.01 = 186.24
新偏置 = 20 - 186.24 = -166.24
4.2.6 输入层→隐藏层权重梯度
权重梯度 = 导数 × W' × 输入值
| 神经元 | 梯度计算 | 结果 |
|---|---|---|
| B1 | 18624 × 10 × 5 | 931,200 |
| B2 | 18624 × 20 × 5 | 1,862,400 |
| B3 | 18624 × 10 × 5 | 931,200 |
| B4 | 18624 × 10 × 5 | 931,200 |
| B5 | 18624 × 30 × 5 | 2,793,600 |
| B6 | 18624 × 20 × 5 | 1,862,400 |
4.2.7 输入层→隐藏层权重调整幅度
调整幅度 = 梯度 × 学习率
| 神经元 | 调整幅度 |
|---|---|
| B1 | 931,200 × 0.01 = 9,312 |
| B2 | 1,862,400 × 0.01 = 18,624 |
| B3 | 931,200 × 0.01 = 9,312 |
| B4 | 931,200 × 0.01 = 9,312 |
| B5 | 2,793,600 × 0.01 = 27,936 |
| B6 | 1,862,400 × 0.01 = 18,624 |
4.2.8 输入层→隐藏层权重更新
新权重 = 旧权重 - 调整幅度
| 神经元 | 更新计算 | 新值 |
|---|---|---|
| B1 | 10 - 9,312 | -9,302 |
| B2 | 20 - 18,624 | -18,604 |
| B3 | 30 - 9,312 | -9,282 |
| B4 | 20 - 9,312 | -9,292 |
| B5 | 10 - 27,936 | -27,926 |
| B6 | 20 - 18,624 | -18,604 |
4.2.9 隐藏层偏置梯度与更新
偏置梯度 = 导数 × W'
| 神经元 | 梯度计算 | 结果 |
|---|---|---|
| B1 | 18624 × 10 | 186,240 |
| B2 | 18624 × 20 | 372,480 |
| B3 | 18624 × 10 | 186,240 |
| B4 | 18624 × 10 | 186,240 |
| B5 | 18624 × 30 | 558,720 |
| B6 | 18624 × 20 | 372,480 |
偏置调整幅度 = 梯度 × 学习率
| 神经元 | 调整幅度 |
|---|---|
| B1 | 186,240 × 0.01 = 1,862.4 |
| B2 | 372,480 × 0.01 = 3,724.8 |
| B3 | 186,240 × 0.01 = 1,862.4 |
| B4 | 186,240 × 0.01 = 1,862.4 |
| B5 | 558,720 × 0.01 = 5,587.2 |
| B6 | 372,480 × 0.01 = 3,724.8 |
新偏置 = 旧偏置 - 调整幅度
| 神经元 | 更新计算 | 新值 |
|---|---|---|
| B1 | 10 - 1,862.4 | -1,852.4 |
| B2 | 10 - 3,724.8 | -3,714.8 |
| B3 | 10 - 1,862.4 | -1,852.4 |
| B4 | 10 - 1,862.4 | -1,852.4 |
| B5 | 10 - 5,587.2 | -5,577.2 |
| B6 | 10 - 3,724.8 | -3,714.8 |
五、参数更新汇总表
5.1 输入层→隐藏层参数更新
| 神经元 | 初始权重 | 权重调整 | 新权重 | 初始偏置 | 偏置调整 | 新偏置 |
|---|---|---|---|---|---|---|
| B1 | 10 | 9,312 | -9,302 | 10 | 1,862.4 | -1,852.4 |
| B2 | 20 | 18,624 | -18,604 | 10 | 3,724.8 | -3,714.8 |
| B3 | 30 | 9,312 | -9,282 | 10 | 1,862.4 | -1,852.4 |
| B4 | 20 | 9,312 | -9,292 | 10 | 1,862.4 | -1,852.4 |
| B5 | 10 | 27,936 | -27,926 | 10 | 5,587.2 | -5,577.2 |
| B6 | 20 | 18,624 | -18,604 | 10 | 3,724.8 | -3,714.8 |
5.2 隐藏层→输出层参数更新
| 参数 | 初始值 | 调整幅度 | 新值 |
|---|---|---|---|
| W'1 | 10 | 11,174.4 | -11,164.4 |
| W'2 | 20 | 20,486.4 | -20,466.4 |
| W'3 | 10 | 29,798.4 | -29,788.4 |
| W'4 | 10 | 20,486.4 | -20,476.4 |
| W'5 | 30 | 11,174.4 | -11,144.4 |
| W'6 | 20 | 20,486.4 | -20,466.4 |
| Bias B | 20 | 186.24 | -166.24 |
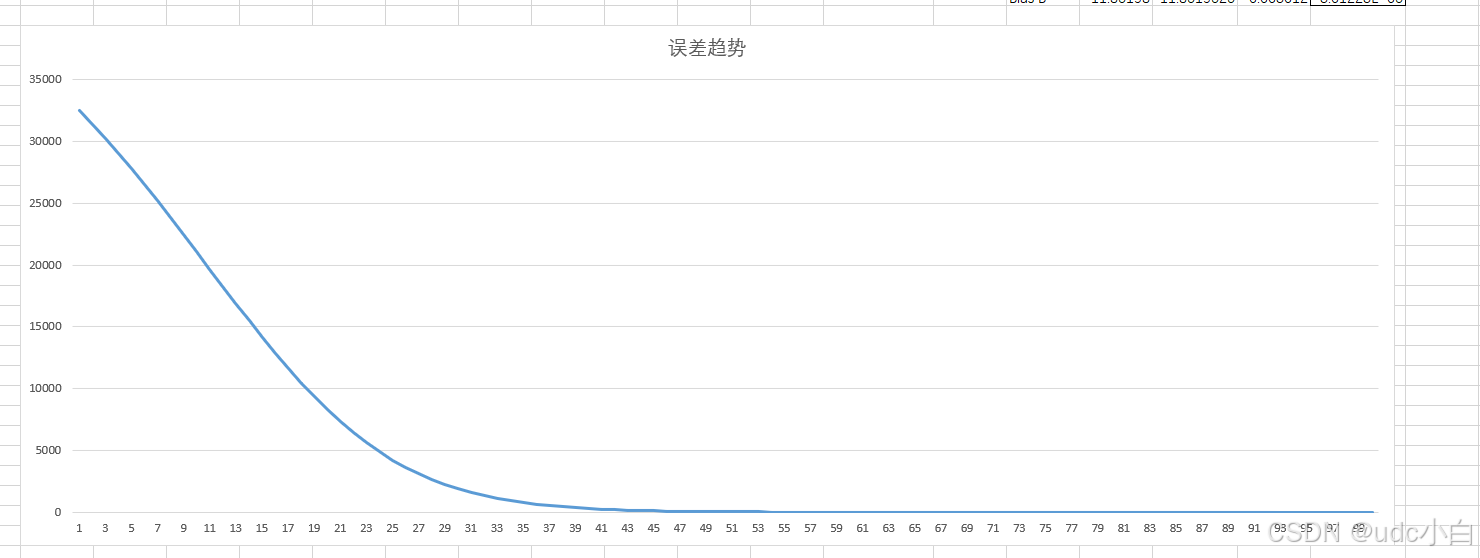
5.3 多次训练
按照上述步骤进行多次前向传播预测 y y y值和反向传播更新权重和偏置,最终让算法收敛,观察损失函数曲线
六、MLP计算原理总结
6.1 前向传播公式
z i = x × W i + B i (隐藏层加权和) a i = z i (隐藏层输出,无激活函数) y = ∑ i = 1 6 a i × W i ′ + B (输出值) E = ( t − y ) 2 (均方误差) \begin{align*} z_i &= x \times W_i + B_i \quad \text{(隐藏层加权和)} \\ a_i &= z_i \quad \text{(隐藏层输出,无激活函数)} \\ y &= \sum_{i=1}^{6} a_i \times W'_i + B \quad \text{(输出值)} \\ E &= (t - y)^2 \quad \text{(均方误差)} \end{align*} ziaiyE=x×Wi+Bi(隐藏层加权和)=zi(隐藏层输出,无激活函数)=i=1∑6ai×Wi′+B(输出值)=(t−y)2(均方误差)
6.2 反向传播公式
∂ E ∂ y = 2 ( y − t ) (误差对输出导数) ∂ E ∂ W i ′ = ∂ E ∂ y × a i (输出层权重梯度) ∂ E ∂ B = ∂ E ∂ y (输出层偏置梯度) ∂ E ∂ W i = ∂ E ∂ y × W i ′ × x (输入层权重梯度) ∂ E ∂ B i = ∂ E ∂ y × W i ′ (隐藏层偏置梯度) \begin{align*} \frac{\partial E}{\partial y} &= 2(y - t) \quad \text{(误差对输出导数)} \\ \frac{\partial E}{\partial W'_i} &= \frac{\partial E}{\partial y} \times a_i \quad \text{(输出层权重梯度)} \\ \frac{\partial E}{\partial B} &= \frac{\partial E}{\partial y} \quad \text{(输出层偏置梯度)} \\ \frac{\partial E}{\partial W_i} &= \frac{\partial E}{\partial y} \times W'_i \times x \quad \text{(输入层权重梯度)} \\ \frac{\partial E}{\partial B_i} &= \frac{\partial E}{\partial y} \times W'_i \quad \text{(隐藏层偏置梯度)} \end{align*} ∂y∂E∂Wi′∂E∂B∂E∂Wi∂E∂Bi∂E=2(y−t)(误差对输出导数)=∂y∂E×ai(输出层权重梯度)=∂y∂E(输出层偏置梯度)=∂y∂E×Wi′×x(输入层权重梯度)=∂y∂E×Wi′(隐藏层偏置梯度)
6.3 参数更新规则
W n e w = W o l d − η × ∂ E ∂ W B n e w = B o l d − η × ∂ E ∂ B \begin{align*} W_{new} &= W_{old} - \eta \times \frac{\partial E}{\partial W} \\ B_{new} &= B_{old} - \eta \times \frac{\partial E}{\partial B} \end{align*} WnewBnew=Wold−η×∂W∂E=Bold−η×∂B∂E
七、关键观察与说明
-
无激活函数: 该MLP未使用非线性激活函数(如Sigmoid、ReLU),隐藏层和输出层均为恒等映射。这使得网络实际上是一个线性模型。
-
梯度消失/爆炸风险: 由于没有激活函数且学习率固定为0.01,单次更新后权重变化很大(从正数变为负数),可能导致训练不稳定。
-
误差计算: 使用标准均方误差(MSE)作为损失函数。
-
学习率影响: 学习率为0.01,在梯度较大时(如18624),单次更新步长会很大。
-
网络结构: 1×6×1的网络结构(1输入,6隐藏,1输出)。