| 这个作业属于哪个课程 | 202501福大-软件工程实践-W班 |
|---|---|
| 这个作业要求在哪里 | 软件工程实践------大模型评测作业 |
| 这个作业的目标 | 完成小组分工与贡献度打分,编写自动化测试程序,量化评测、对比不同大模型在完成"购车决策"的综合表现 |
| 其他参考文献 | 《构建之法》 |
文章目录
-
- 前言
- 材料链接
- [1. 调研与评测](#1. 调研与评测)
-
- [1.1 大模型1:Deepseek R1](#1.1 大模型1:Deepseek R1)
-
- [1.1.1 体验](#1.1.1 体验)
- [1.1.2 自动化测试](#1.1.2 自动化测试)
- [1.1.3 结论](#1.1.3 结论)
- [1.2 大模型2:阿里百炼Qwen](#1.2 大模型2:阿里百炼Qwen)
-
- [1.2.1 体验](#1.2.1 体验)
- [1.2.2 自动化测试](#1.2.2 自动化测试)
- [1.2.3 结论](#1.2.3 结论)
- [2. 分析](#2. 分析)
-
- [2.1 开发时间估计](#2.1 开发时间估计)
- [2.2 同类产品对比排名](#2.2 同类产品对比排名)
- [2.3 软件工程方面的建议](#2.3 软件工程方面的建议)
-
- [2.3.1 程序层面](#2.3.1 程序层面)
- [2.3.2 软件工程层面](#2.3.2 软件工程层面)
- [2.3.3 商业层面](#2.3.3 商业层面)
- [2.4 BUG存在的原因分析](#2.4 BUG存在的原因分析)
- [2.5 市场概况](#2.5 市场概况)
- [2.6 产品规划](#2.6 产品规划)
- [3. 绩效分析](#3. 绩效分析)
前言
本次作业通过构建自动化购车决策评测系统,对两个大语言模型在真实购车场景中的表现进行量化评估。这不仅是对模型能力的测试,更是对软件工程实践中自动化测试、需求分析和系统设计能力的综合锻炼。
材料链接
1. 调研与评测
1.1 大模型1:Deepseek R1
1.1.1 体验
基本功能介绍:Deepseek R1在购车决策任务中展现了完整的对话流程处理能力,能够理解用户需求、推荐车型、多维度权衡分析具体参数,并给出具有逻辑深度的最终推荐。
截图记录 :

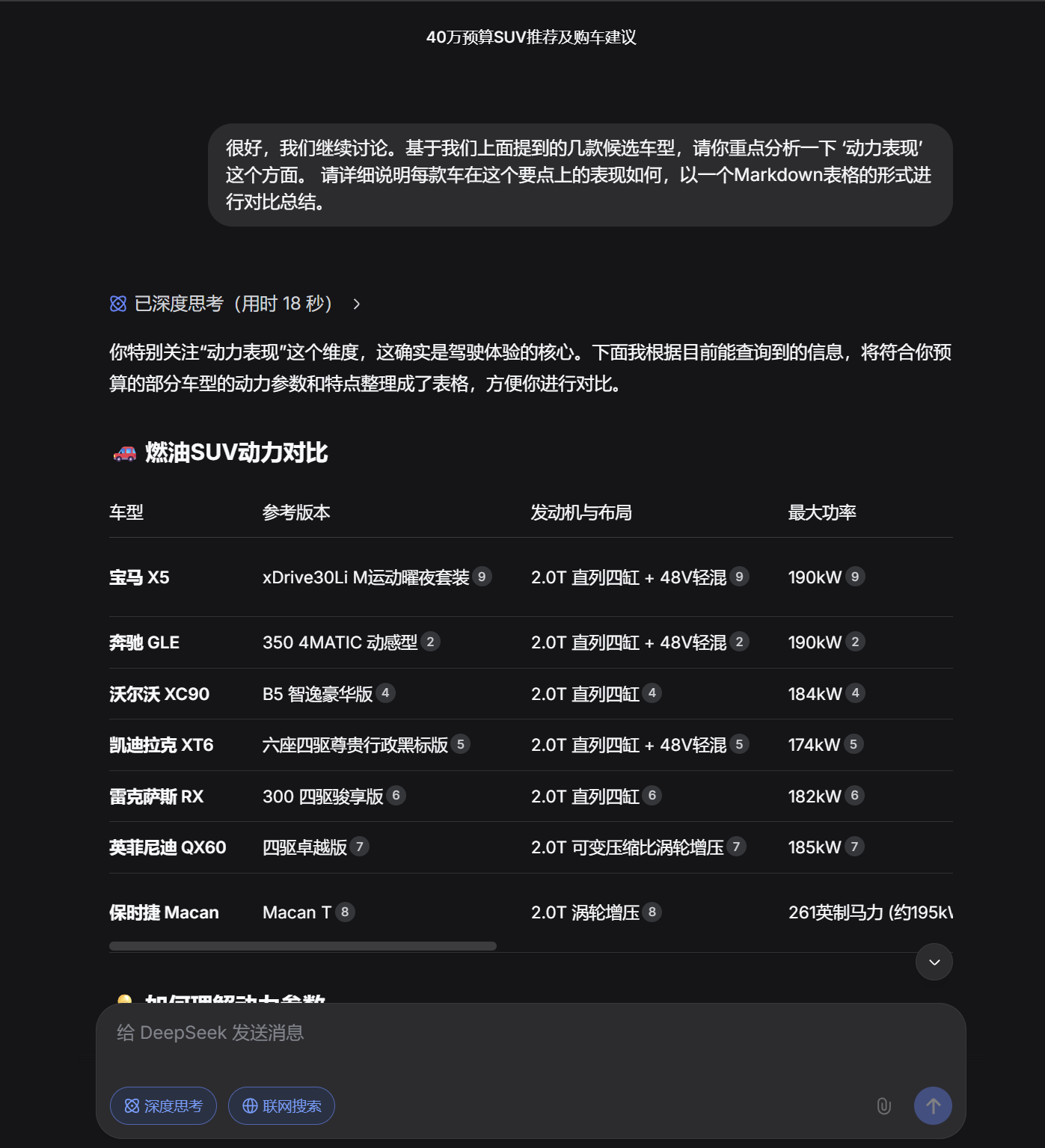

使用过程:
- 用户提出购车需求(预算、车型偏好、核心要求)
- 模型给出初步推荐列表
- 多轮深入讨论具体要点(动力、安全、经济性等)
- 生成参数对比表格
- 给出最终推荐及详细理由
优缺点分析:
优点:
- 数据量:参数信息全面,动力、配置、尺寸等关键数据齐全。
- 界面:输出结构化程度高,参数表格、列表等易于阅读和比较。
- 功能:核心推荐流程完整,从广筛到精荐。
- 用户体验:信息呈现标准化,易于横向对比。
缺点:
- 价格数据可能不精确,特别是选装件和最终落地价信息缺失或过时。
- 对矛盾需求(如保值率)的处理较粗糙,多停留在数据罗列,缺乏有说服力的归因分析和补偿性论证。
- 需求匹配准确度是最大短板,初步推荐常偏离核心约束(如预算、发动机类型)。
改进意见:
1. 针对价格数据不精确
建立"分层价格"显示机制,在官方指导价旁清晰展示估算的"典型落地价"及主要选装件价格。同时,需接入实时数据源并定期更新,确保信息与市场同步。
2. 针对矛盾需求处理粗糙
采用"承认-解释-补偿"的论证框架。先明确承认劣势,然后解释其成因,最后量化说明接受此劣势能换来的核心优势,从而将粗糙对比转化为有说服力的权衡。
3. 针对需求匹配不准
实施"硬性约束前置校验"机制。将预算、动力类型等设为硬性过滤条件,在推荐前强制排除不符车型,并对用户确认关键需求,从源头杜绝偏离核心约束的推荐。
用户采访:
Q1:之前有使用过DeepSeek R1吗?
A1:有使用DeepSeek协助完成过作业。
Q2:之前用 DeepSeek 协助作业时,主要是帮你解决编程类任务,还是也会用来整理作业文档这类非编码需求?A2:主要是编程类任务,比如写 Python 代码,偶尔会让它帮理算法思路,文档整理用得少。
Q3:在作业里用它的时候,有没有遇到过生成的代码不太对的情况?A3:遇到过,比如复杂的循环题,它生成的代码漏了边界条件,得自己补全测试再改。
Q4:和你之前可能用过的其他辅助工具比,你觉得 DeepSeek 帮你写作业时最实用的一点是啥?A4:它能更快理解我的需求,比如说你告诉他"实现学生成绩排序",生成的代码直接能用,不用反复解释。
1.1.2 自动化测试
测试环境搭建:
python
# config.py
"""项目配置文件"""
# 定义需要进行自动化测试的模型
# 字典的键是自定义的测试名称(将用于创建结果文件夹),值是模型在API中实际的名称
MODELS_TO_TEST = {
"deepseek_test1": "deepseek-v3.2-exp", # 测试模型1
"QWEN3": "qwen3-max"
# 如果需要测试多个模型或同一模型的不同参数配置,可以在这里添加
# "deepseek_test2": "deepseek-v3.2-exp"
}
# 裁判模型(用于自动化评测的模型,通常选择能力最强的版本)
JUDGE_MODEL = "deepseek-v3.2-exp"
python
# llm_api_handler.py - API调用封装
"""
封装与阿里云百炼Deepseek模型的API交互逻辑,提供统一调用接口
"""
import os
import logging
from typing import List, Dict, Optional
from dotenv import load_dotenv
from openai import OpenAI, APIError, RateLimitError, Timeout
import requests
# 1. 加载环境变量(从项目根目录下的.env文件读取API密钥)
load_dotenv()
# 2. 配置日志记录器
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger("llm_api_handler")
def query_llm(
model_name: str,
conversation_history: List[Dict[str, str]],
temperature: float = 0.7
) -> Optional[str]:
"""
调用阿里云百炼平台的Deepseek模型API,获取对话回复。
参数:
model_name (str): 模型名称(需与阿里云百炼平台的模型名称一致,如"deepseek-v3.2-exp")。
conversation_history (List[Dict[str, str]]): 对话历史,格式为 [{"role": "user", "content": "..."}, ...]。
temperature (float): 生成温度,控制回复的随机性(0到1之间)。
返回:
Optional[str]: 模型的文本回复字符串。如果调用失败,则返回None。
"""
try:
# 3. 从环境变量中安全地获取API密钥
api_key = "sk-ce9fa26579554216811a7f0fcfbe1b00"
if not api_key:
logger.error("API密钥未找到!请确保在项目根目录的 .env 文件中设置了 DEEPSEEK_API_KEY。")
return None
# 4. 初始化与OpenAI兼容的客户端
# 阿里云百炼提供了兼容OpenAI API格式的端点
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 5. 发起API调用
logger.info(f"正在调用模型: {model_name},对话历史长度: {len(conversation_history)}条")
response = client.chat.completions.create(
model=model_name,
messages=conversation_history,
temperature=temperature,
stream=False, # 使用非流式输出,直接获取完整结果
)
# 6. 解析并返回有效的回复内容
if response.choices and len(response.choices) > 0:
answer = response.choices[0].message.content
logger.info(f"模型 '{model_name}' 调用成功,收到回复。")
return answer.strip() if answer else None
else:
logger.warning(f"模型 '{model_name}' 返回了空的回复内容。")
return None
# 7. 捕获并处理各种潜在的异常
except RateLimitError:
logger.error(f"模型 '{model_name}' API调用频率超限,请稍后重试。")
return None
except Timeout:
logger.error(f"对模型 '{model_name}' 的API调用请求超时。")
return None
except APIError as e:
logger.error(f"模型 '{model_name}' API返回错误: {e}")
return None
except requests.exceptions.RequestException as e:
logger.error(f"网络连接错误,无法访问API端点: {e}")
return None
except Exception as e:
logger.error(f"调用模型 '{model_name}' 时发生未知错误: {e}", exc_info=True)
return None多轮对话流程实现:
python
# 购车决策核心流程
def run_car_advisor_session(model_name: str) -> str | None:
"""
执行一个完整的购车咨询对话流程,并将所有交互记录为TXT文件。
参数:
model_name (str): 在config.py中定义的模型API名称。
返回:
str | None: 如果成功,返回创建的会话目录路径;如果失败,返回None。
"""
# 步骤1: 创建唯一的会话目录
session_timestamp = int(time.time())
session_dir = os.path.join("results", f"{model_name.replace('/', '_')}_session_{session_timestamp}")
os.makedirs(session_dir, exist_ok=True)
logging.info(f"为模型 '{model_name}' 创建新会话目录: {session_dir}")
full_log_path = os.path.join(session_dir, "00_full_conversation_log.txt")
conversation_history: List[Dict[str, str]] = []
try:
# --- 意图与初步推荐 ---
logging.info("阶段: 提出初步购车意图...")
initial_prompt = conversation_prompts.PROMPT_INITIAL_INTENT
_log_and_write(session_dir, full_log_path, "user", initial_prompt, "01_initial_user_prompt.txt")
conversation_history.append({"role": "user", "content": initial_prompt})
first_response = query_llm(model_name, conversation_history)
if not first_response:
logging.error("API调用失败,无法获取初步推荐。会话终止。")
return None
_log_and_write(session_dir, full_log_path, "assistant", first_response, "02_first_assistant_response.txt")
conversation_history.append({"role": "assistant", "content": first_response})
# 尝试从回复中解析候选车型
candidate_cars = []
try:
# 找到JSON对象的起始和结束位置,以应对模型可能添加额外文本的情况
start_index = first_response.find('{')
end_index = first_response.rfind('}') + 1
if start_index != -1 and end_index != 0:
json_str = first_response[start_index:end_index]
parsed_json = json.loads(json_str)
candidate_cars = [item['car_name'] for item in parsed_json.get('recommendations', [])]
logging.info(f"成功解析出候选车型: {candidate_cars}")
else:
logging.warning("在初步推荐中未找到有效的JSON对象。")
except json.JSONDecodeError:
logging.warning("无法将初步推荐解析为JSON。后续步骤可能受影响。")
if not candidate_cars:
logging.error("未能获取候选车型列表,无法继续进行。会话终止。")
return None
# --- 追问具体要点 ---
logging.info("阶段: 循环追问具体要点...")
requirement_points = ["动力表现", "燃油经济性", "主动安全配置", "品牌口碑", "价格和保值率"]
for point in requirement_points:
logging.info(f"正在追问要点: {point}")
deepen_prompt = conversation_prompts.PROMPT_DEEPEN_REQUIREMENT.format(requirement_point=point)
_log_and_write(session_dir, full_log_path, "user", deepen_prompt)
conversation_history.append({"role": "user", "content": deepen_prompt})
deepen_response = query_llm(model_name, conversation_history)
if not deepen_response:
logging.warning(f"API调用失败,未能获取关于'{point}'的分析。")
continue # 跳过失败的追问
_log_and_write(session_dir, full_log_path, "assistant", deepen_response)
conversation_history.append({"role": "assistant", "content": deepen_response})
time.sleep(1) # 简单的延时以避免过快的API请求
# --- 表格对比 ---
logging.info("阶段: 请求生成性能参数对比表...")
candidate_cars_str = ", ".join(candidate_cars)
table_prompt = conversation_prompts.PROMPT_GENERATE_TABLE.format(candidate_cars=candidate_cars_str)
_log_and_write(session_dir, full_log_path, "user", table_prompt)
conversation_history.append({"role": "user", "content": table_prompt})
table_response = query_llm(model_name, conversation_history)
if not table_response:
logging.error("API调用失败,无法获取参数对比表。会话终止。")
return None
_log_and_write(session_dir, full_log_path, "assistant", table_response, "03_assistant_table_response.txt")
conversation_history.append({"role": "assistant", "content": table_response})
# --- 最终推荐 ---
logging.info("阶段: 请求最终推荐...")
final_prompt = conversation_prompts.PROMPT_FINAL_RECOMMENDATION
_log_and_write(session_dir, full_log_path, "user", final_prompt)
conversation_history.append({"role": "user", "content": final_prompt})
final_response = query_llm(model_name, conversation_history)
if not final_response:
logging.error("API调用失败,无法获取最终推荐。会话终止。")
return None
_log_and_write(session_dir, full_log_path, "assistant", final_response, "04_final_recommendation_response.txt")
logging.info(f"会话成功完成!所有日志已保存在: {session_dir}")
return session_dir
except Exception as e:
logging.error(f"在执行会话期间发生意外错误: {e}", exc_info=True)
return None评测指标与自动化评分:
python
def run_evaluation(session_dir_path: str):
"""
对一个已完成的对话会话目录进行多步自动化评测。
参数:
session_dir_path (str): 阶段二生成的会话结果目录路径。
"""
logging.info(f"开始对会话目录进行评测: {session_dir_path}")
# --- 评测环节一: 初步推荐质量 ---
try:
logging.info("评测环节1: 初步推荐质量...")
with open(os.path.join(session_dir_path, "01_initial_user_prompt.txt"), "r", encoding="utf-8") as f:
prompt_content = f.read()
with open(os.path.join(session_dir_path, "02_first_assistant_response.txt"), "r", encoding="utf-8") as f:
response_content = f.read()
eval_prompt_1 = evaluation_prompts.EVAL_PROMPT_1_INITIAL.format(
initial_user_prompt=prompt_content,
first_assistant_response=response_content
)
eval_result_1 = query_llm(config.JUDGE_MODEL, [{"role": "user", "content": eval_prompt_1}])
if eval_result_1:
with open(os.path.join(session_dir_path, "eval_01_initial_recommendation.txt"), "w", encoding="utf-8") as f:
f.write(eval_result_1)
logging.info("评测环节1成功完成,结果已保存。")
else:
logging.error("评测环节1失败:裁判LLM未能返回有效结果。")
except FileNotFoundError as e:
logging.error(f"评测环节1失败:缺少必要的输入文件 - {e}")
except Exception as e:
logging.error(f"评测环节1发生未知错误: {e}", exc_info=True)
# --- 评测环节二: 参数对比表质量 ---
try:
logging.info("评测环节2: 参数对比表质量...")
with open(os.path.join(session_dir_path, "03_assistant_table_response.txt"), "r", encoding="utf-8") as f:
table_response_content = f.read()
eval_prompt_2 = evaluation_prompts.EVAL_PROMPT_2_TABLE.format(assistant_table_response=table_response_content)
eval_result_2 = query_llm(config.JUDGE_MODEL, [{"role": "user", "content": eval_prompt_2}])
if eval_result_2:
with open(os.path.join(session_dir_path, "eval_02_table_quality.txt"), "w", encoding="utf-8") as f:
f.write(eval_result_2)
logging.info("评测环节2成功完成,结果已保存。")
else:
logging.error("评测环节2失败:裁判LLM未能返回有效结果。")
except FileNotFoundError as e:
logging.error(f"评测环节2失败:缺少必要的输入文件 - {e}")
except Exception as e:
logging.error(f"评测环节2发生未知错误: {e}", exc_info=True)
# --- 评测环节三: 最终推荐逻辑 ---
try:
logging.info("评测环节3: 最终推荐逻辑与说服力...")
with open(os.path.join(session_dir_path, "00_full_conversation_log.txt"), "r", encoding="utf-8") as f:
full_log_content = f.read()
eval_prompt_3 = evaluation_prompts.EVAL_PROMPT_3_FINAL.format(entire_conversation_log_string=full_log_content)
eval_result_3 = query_llm(config.JUDGE_MODEL, [{"role": "user", "content": eval_prompt_3}])
if eval_result_3:
with open(os.path.join(session_dir_path, "eval_03_final_recommendation.txt"), "w", encoding="utf-8") as f:
f.write(eval_result_3)
logging.info("评测环节3成功完成,结果已保存。")
else:
logging.error("评测环节3失败:裁判LLM未能返回有效结果。")
except FileNotFoundError as e:
logging.error(f"评测环节3失败:缺少必要的输入文件 - {e}")
except Exception as e:
logging.error(f"评测环节3发生未知错误: {e}", exc_info=True)
logging.info(f"对目录 {session_dir_path} 的所有评测环节已执行完毕。")测试结果可视化:
Deepseek R1 自动化评测结果(4次测试平均值)
| 评测维度 | 得分(满分5) | 表现评价 |
|---|---|---|
| 格式规范性 | 5.0 | 优秀 |
| 信息完整性 | 5.0 | 优秀 |
| 逻辑一致性 | 4.4 | 良好 |
| 需求匹配度 | 2.5 | 需改进 |
| 综合得分 | 4.2 | 良好 |
1.1.3 结论
Deepseek R1在AI购车顾问在格式规范性和信息完整性 方面表现卓越,所有报告均显示参数表格生成满分,体现了强大的结构化输出能力。然而,需求匹配度 明显不足(平均仅2.5分),多次出现预算溢出、忽略用户关键需求(如保值率、安全性能)等问题,这严重影响了整体服务质量。逻辑一致性表现良好(平均4.4分),但在深度推理和权衡解释上仍有提升空间。
1.2 大模型2:阿里百炼Qwen
1.2.1 体验
基本功能介绍:阿里百炼Qwen在购车决策任务中展现了完整的对话流程处理能力,能够理解用户需求、初步推荐、预算控制,并给出最终推荐。
截图记录 :

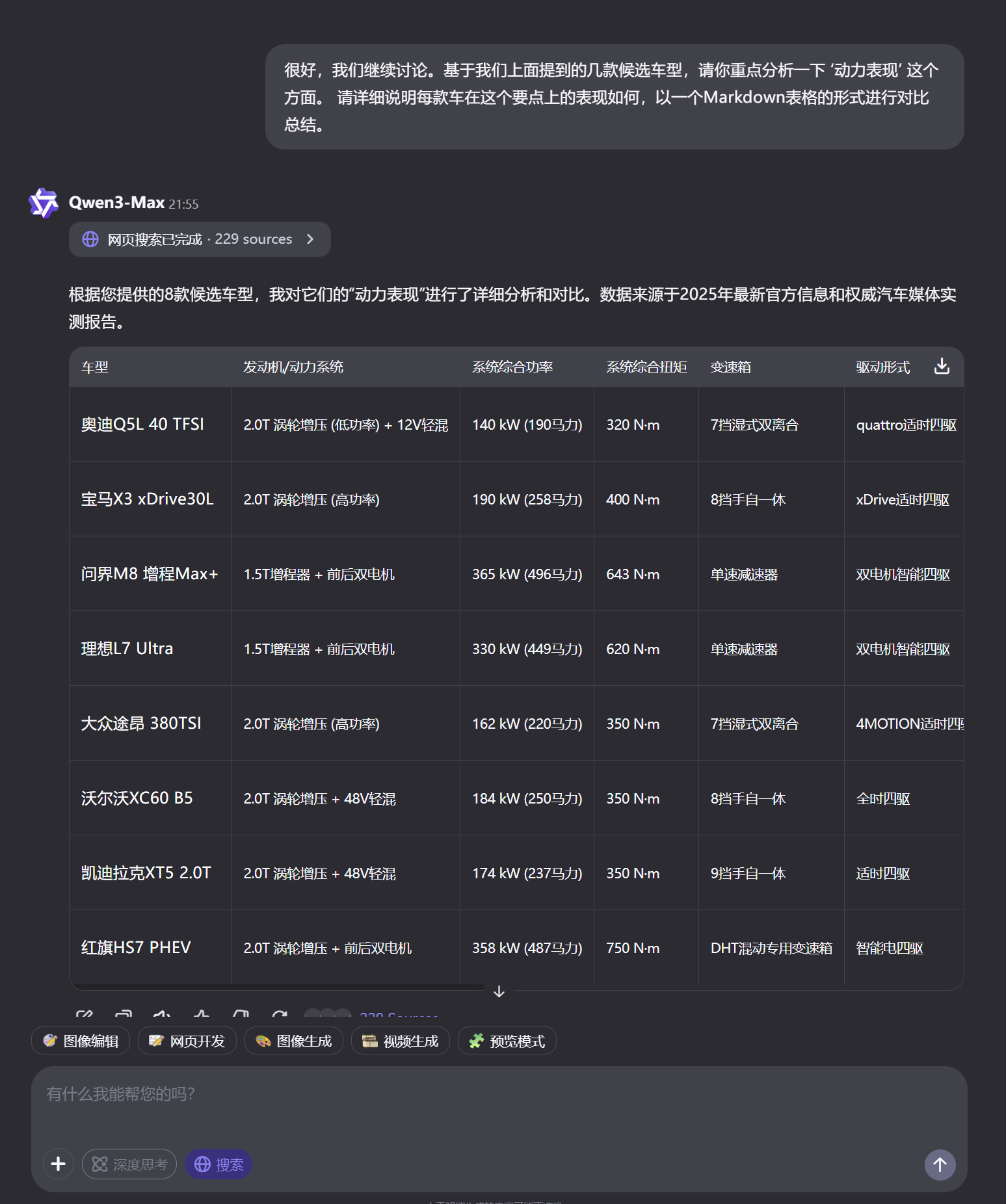

使用过程:
- 用户提出购车需求(预算、车型偏好、核心要求)
- 模型给出初步推荐列表
- 多轮深入讨论具体要点(动力、安全、经济性等)
- 生成参数对比表格
- 给出最终推荐及详细理由
优缺点分析:
优点:
- 数据量:参数信息完整准确,包含动力、油耗、轴距、安全配置等核心数据
- 准确度:最终推荐逻辑自洽,能系统化整合多维度数据
- 功能:参数表格生成卓越(格式和完整性均获满分)
缺点:
- 保值率数据存在预估值,缺乏权威来源
- 主观需求响应不足(如"内饰较好"未提供具体依据)
- 需求匹配不稳定:200万豪车案例中5/8车型严重超预算
- 软性需求理解偏差:对"安全性优秀"的理解停留在配置清单
改进意见:
1. 保值率数据问题
- 接入权威数据源(如中国汽车流通协会),确保数据可信度
- 对预估数据明确标注"行业预估值"并说明原因,主动管理用户预期
2. 主观需求响应不足
- 建立关键词映射库,将"内饰好"等模糊需求关联到具体参数(材质、工艺等)
- 增设追问环节,主动澄清用户偏好的具体方向
3. 预算控制不稳定
- 实施预算硬约束过滤,强制排除显著超预算车型
- 对可能超预算车型主动标注警示,明确提示用户
4. 软性需求理解偏差
- 引入第三方安全评级(如C-NCAP),超越单纯配置罗列
- 区分配置有无与系统优劣,对比不同品牌技术的成熟度差异
用户采访:
Q1:之前有使用过阿里百炼Qwen吗?
A1:之前有用这个AI帮我制定减肥计划。
Q2:它给你制定的减肥计划里的内容,是不是比较贴合你的日常?A2:挺贴合的,饮食都是常见食材,运动也推荐的是我能坚持的慢跑、跳绳,没搞太复杂的。
Q3:用这个计划执行的时候,有没有遇到过计划里的建议不太好落地的情况?A3:有过,比如工作日中午建议的沙拉不好带,我就换成了别的。
Q4:比起自己在网上查攻略拼减肥计划,你觉得阿里百炼 Qwen 帮你做计划最省心的一点是啥?A4:不用自己凑信息,它会直接按我的体重、作息来定,不用反复筛选哪些适合自己。
1.2.2 自动化测试
测试代码与Deepseek R1相同
测试结果可视化:
Qwen大模型 自动化评测结果(4次测试平均值)
| 评测维度 | 得分(满分5) | 表现评价 |
|---|---|---|
| 格式规范性 | 5.0 | 优秀 |
| 信息完整性 | 4.8 | 优秀 |
| 逻辑一致性 | 4.3 | 良好 |
| 需求匹配度 | 2.6 | 需改进 |
| 综合得分 | 4.2 | 良好 |
1.2.3 结论
Qwen模型在技术能力(格式、信息整合)和深度推理上表现优异,但需求匹配的可靠性和一致性不足,导致整体服务体验断层。这与Deepseek模型类似,呈现"高能力低可靠性"特征。优先解决需求匹配问题后可提升至A级。
2. 分析
2.1 开发时间估计
基于我们的项目实践经验,开发一个类似的购车顾问评测系统需要:
基础版本开发:
- 时间周期:2-3个月
- 第一阶段(1个月):搭建对话框架,接入基础车型数据库
- 第二阶段(1个月):实现多轮对话和参数对比功能
- 第三阶段(1个月):测试优化,部署上线
迭代优化:
- 时间周期:持续1-2个月
- 重点任务:
- 根据用户反馈快速迭代
- 完善数据更新机制
2.2 同类产品对比排名
传统汽车平台:
- 懂车帝 - 内容全面,用户量大
- 汽车之家 - 专业性强,数据详细
- 太平洋汽车 - 老牌平台,信息可靠
AI购车顾问优势:
- 一对一深度咨询
- 多轮对话理解需求
- 个性化推荐
2.3 软件工程方面的建议
2.3.1 程序层面
当前系统架构分析:
1. 对话管理算法
- 基于状态机的多轮对话流程控制
- 简单的列表结构存储对话历史
- 缺乏智能的对话状态跟踪
2. 推荐算法结构
- 基础的关键词匹配推荐
- JSON格式的数据交换结构
- 缺乏个性化权重计算
3. 数据处理流程
- 线性处理管道:用户输入 → LLM处理 → 结果解析
- 文件系统作为主要数据存储
- 文本文件格式的日志记录
大模型平台技术体现:
- Transformer架构:Deepseek模型基于现代Transformer架构
- 注意力机制:处理长文本对话的上下文理解
- 嵌入向量:车型特征和用户需求的语义表示
- 生成式算法:基于概率分布的文本生成
2.3.2 软件工程层面
服务架构分析:
现有服务组件:
- LLM API服务:阿里云百炼API接口封装
- 对话引擎服务:main.py中的流程控制
- 评测服务:evaluator.py的自动化评测
- 报告生成服务:report_generator.py的综合报告
文档体系现状:
- 代码内文档(docstring)基本完整
- 缺乏API接口文档
- 缺少部署和运维文档
- 用户使用指南缺失
协作机制:
- 基于文件的模块化开发
- 配置集中管理(config.py)
- 日志统一格式
- 缺乏版本控制策略说明
大模型平台服务体现:
阿里云百炼平台服务:
- 模型推理服务:提供多种大模型API
- 监控统计服务:调用次数、响应时间监控
- 安全防护服务:内容安全检测
- 扩展插件服务:支持自定义功能扩展
2.3.3 商业层面
商业模式分析:
当前系统商业模式:
- 技术验证型:主要展示AI能力,未形成完整商业模式
- B2B潜在方向:为汽车平台提供AI导购解决方案
- 数据服务可能:积累的用户偏好数据具有商业价值
竞争优势分析:
技术竞争优势:
- 多轮对话能力:超越传统关键词搜索的交互体验
- 个性化推荐:基于深度需求理解的精准匹配
- 自动化评测:独特的模型性能评估体系
- 快速迭代:基于配置的模型切换和优化
大模型平台商业价值:
- 降低技术门槛:无需自研大模型,专注应用层开发
- 弹性扩展:按需调用,成本可控
- 持续进化:依托平台模型升级获得能力提升
- 生态整合:可与其他云服务无缝集成
竞争优势构建:
- 技术深度:在汽车垂直领域建立专业壁垒
- 用户体验:提供传统平台无法实现的个性化服务
- 数据积累:通过用户交互持续优化推荐算法
- 生态合作:与汽车产业链各方建立合作关系
大模型平台商业策略:
阿里云百炼平台优势:
- 技术可靠性:阿里云基础设施保障服务稳定性
- 成本效益:相比自建大模型团队更具经济性
- 合规安全:符合国内数据安全和内容监管要求
- 持续创新:平台持续集成最新模型和技术
通过这三个层面的系统分析,可以清晰地看到当前系统的技术基础、工程化程度和商业潜力,为后续的优化和发展提供了明确的方向。
2.4 BUG存在的原因分析
从测试中发现的BUG主要源于:
- 数据验证缺失 - LLM返回数据格式不可靠
- 状态管理薄弱 - 多轮对话容易丢失上下文
- 缓存机制缺失 - 重复查询降低性能
给出一些简单解决方案:
- 添加数据验证装饰器
- 实现对话状态跟踪
- 引入查询结果缓存
2.5 市场概况
市场规模:
- 新车销量:中国每年约2500万辆
- 二手车交易量:约1500万辆
用户规模:
- 直接用户:准备购车人群,每年约3000万人
- 潜在用户:有车一族,约2亿人
竞争机会:
传统平台信息繁杂,AI助手可以提供更精准的个性化服务。
2.6 产品规划
新功能:智能购车清单
为什么做这个功能?
用户选车时需要记录和比较多个车型,手动整理很麻烦。
为什么不选其他功能?
- 实现简单,用户需求明确
- 能立即提升用户体验
- 为后续功能打下基础
NABCD分析
| 维度 | 详细说明 |
|---|---|
| N(需求 - Need) | 用户需要工具来记录和比较感兴趣的车型,避免信息混乱。 |
| A(做法 - Approach) | - 用户点击"加入对比"保存车型 - 生成对比表格,突出差异点 - 支持笔记记录和个人评分 |
| B(好处 - Benefit) | - 方便用户管理选车信息 - 提升决策效率 - 增加用户粘性 |
| C(竞争 - Competition) | 传统平台有对比功能,但不智能。我们可以做得更贴心。 |
| D(推广 - Delivery) | - 在对话中自然引导使用 - 通过社交媒体分享案例 - 与合作平台交叉推广 |
3. 绩效分析
组员分工与贡献度
| 学号 | 姓名 | 工作内容 | 贡献度 |
|---|---|---|---|
| 042301118 | 赵俊强 | 演讲答辩、协调沟通、验收工作成果 | 12.60% |
| 102300103 | 刘子祎 | 大模型评测报告答辩PPT制作与优化 | 12.53% |
| 102300106 | 陈思焓 | 大模型1评测测试、辅助环境搭建 | 12.53% |
| 102300110 | 尹肇兴 | 模拟购车决策环境搭建 | 13.23% |
| 102300123 | 鲁申如 | 调研采访用户使用体验 | 11.98% |
| 102300125 | 林浩宇 | 博客撰写、活动图与流程图优化 | 12.41% |
| 102300425 | 郭育铭 | 大模型2评测测试、辅助环境搭建 | 12.19% |
| 102300426 | 陈炜滨 | 大模型评测报告答辩PPT制作与优化 | 12.53% |
总分值 700分 按个人得分/700 *100% 得出贡献度
| 昵称 | 个人成果 (70) | 工作态度 (30) | ||||
|---|---|---|---|---|---|---|
| 任务完成度(35) | 成果质量(30) | 贡献独特性(5) | 参与度(15) | 协作性(10) | 实效性(5) | |
| 颜(赵俊强) | 35 | 25.5 | 4 | 13 | 8 | 5 |
| Atom(刘子祎) | 35 | 26 | 4 | 12 | 8 | 5 |
| Csih(陈思焓) | 35 | 25 | 4 | 13 | 8 | 5 |
| satori(尹肇兴) | 35 | 29 | 5 | 13 | 8 | 5 |
| GAT0R(鲁申如) | 35 | 23 | 4 | 11 | 8 | 5 |
| Afterglow_ML(林浩宇) | 35 | 24 | 4 | 13 | 8 | 5 |
| 执言(郭育铭) | 35 | 23.5 | 4 | 12 | 8 | 5 |
| =+@...%_KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲-%&/(陈炜滨) | 35 | 26 | 4 | 12 | 8 | 5 |
采用线上会议+QQ即使沟通 共同协作完成任务
线上自由选择分工岗位
周日晚8点会议交流总结协作内容
QQ即时沟通协作
| 部分图片如下 | |
|---|---|
 |
 |