
一、本章诉求
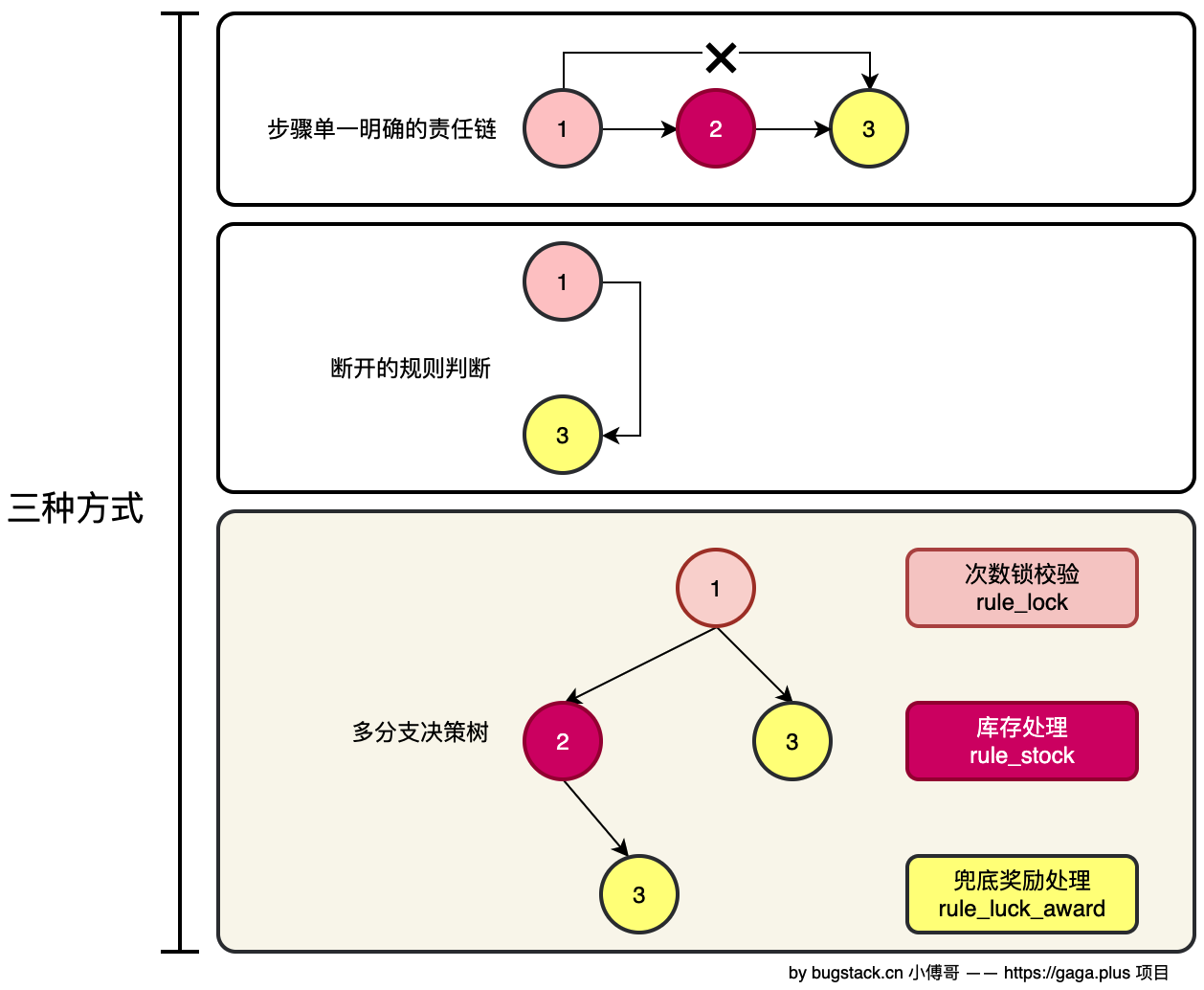
本章节需要引入新的设计模式结构,解决先阶段中抽奖策略规则的中、后两部分执行问题。通过组合模式的规则引擎,让过滤节点可以满足一颗二叉树的结构,自由的组合和多分支链路的方式完成流程的处理。
二、流程设计
这里有一个矛盾点需要解决。对于抽奖策略的前置规则过滤是顺序一条链的,有一个成功就可以返回。比如;黑名单抽奖、权重人群抽奖、默认抽奖,总之它只能有一种情况,所以这样的流程是适合责任链的
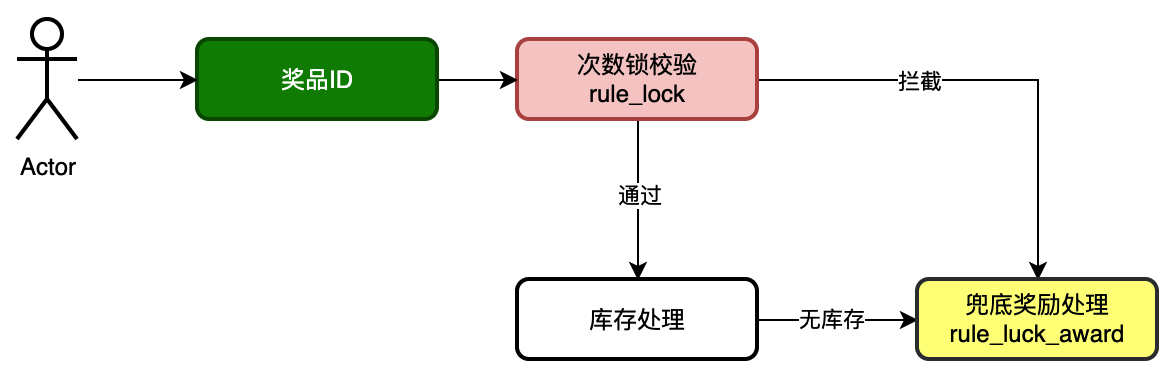
那么对于抽奖中到抽奖后的规则,它是一个非多分支情况的规则过滤。单独的责任链是不能满足的,如果是拆分开抽奖中规则和抽奖后规则分阶段处理,中间单独写逻辑处理库存操作。那么是可以实现的。但这样的方式始终不够优雅,配置化的内容较低,后续的规则开发仍需要在代码上改造。所以这里小傅哥会带着大家实现一版组合模式的决策树模型设计
三、功能实现
1. 工程结构
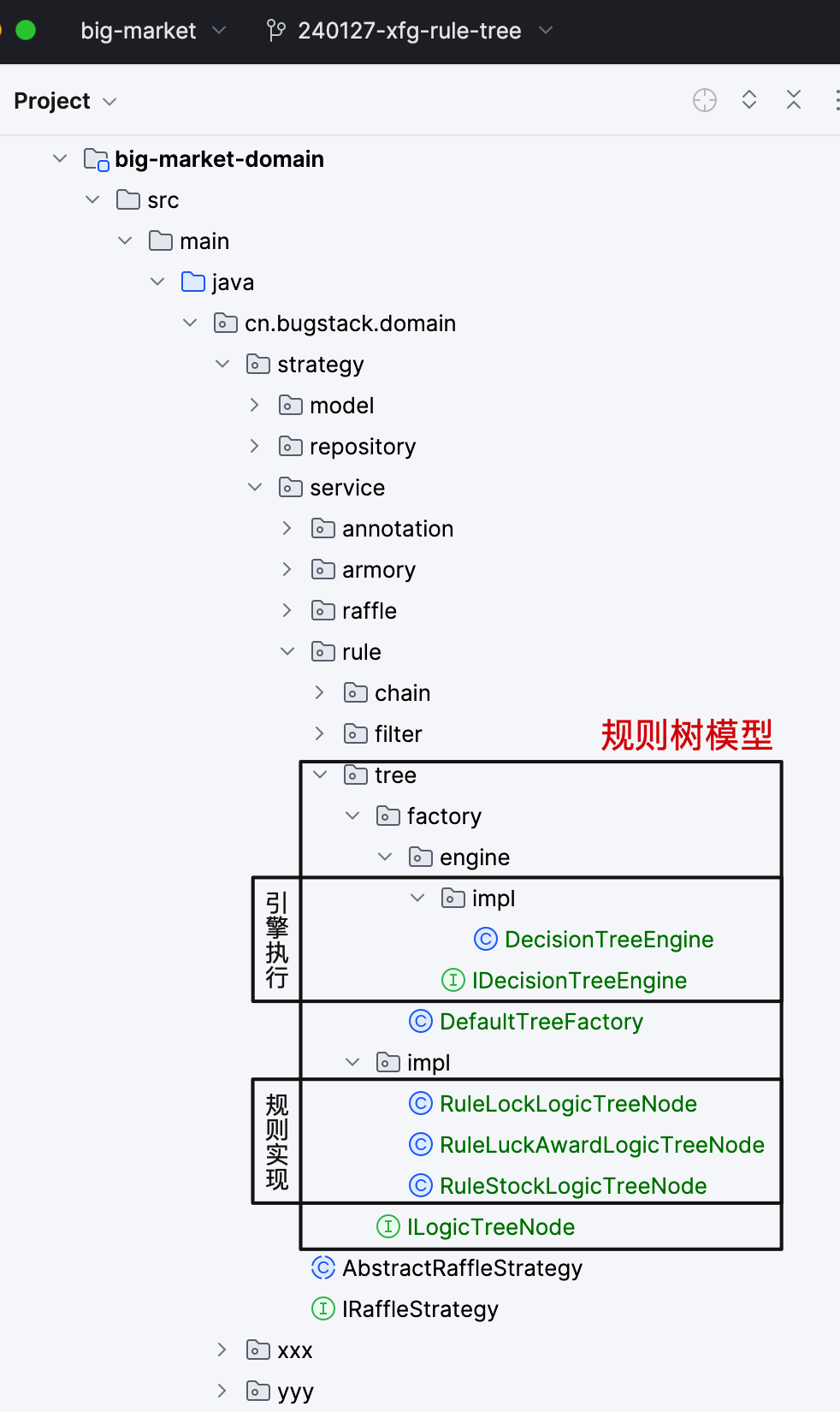
- 在策略领域模型下,rule 规则部分,添加 tree 规则树模型。「后续 filte 就会过删掉了,只保存一个chain链路,一个tree组合」
- 责任链的链路执行有它本身的优势,自身的实现就可以从一个链转入到下一个。那么对于普通策略规则的过滤一种是for循环顺序执行,另外一种借助组合模式的思想,创建出二叉树结构的调用链路关系。本节就是这种方式实现规则树模型。
2.为什么从责任链继续演进到规则树
第七节的责任链模式,已经非常适合处理"线性流程"的前置规则:
- 黑名单命中就接管
- 权重命中就接管
- 否则继续往下传递
- 最后走默认抽奖
这个模型的特点是:链路是单线的。
但到了抽奖中和抽奖后,规则关系开始变复杂。比如:
- 先判断次数锁是否放行
- 如果不放行,直接走兜底奖励
- 如果放行,再去做库存判断
- 库存不足,还要继续走兜底奖励
- 库存充足,才真正返回目标奖品
这类规则已经不是"一个接一个顺序往下传"就能表达清楚了,因为它开始出现分叉路径 。
责任链适合"顺着一条线走",而规则树更适合"根据不同判断结果走不同分支"。
所以第八节并不是推翻责任链,而是在责任链之后,继续为更复杂的规则组合补上一种新的结构表达方式。
3.新增规则树的基础值对象
这一节先补的是一整套规则树的数据模型,它们的作用不是直接执行业务,而是把"树长什么样"描述清楚
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则树对象【注意;不具有唯一ID,不需要改变数据库结果的对象,可以被定义为值对象】
* @create 2024-01-27 10:45
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class RuleTreeVO {
/** 规则树ID */
private Integer treeId;
/** 规则树名称 */
private String treeName;
/** 规则树描述 */
private String treeDesc;
/** 规则根节点 */
private String treeRootRuleNode;
/** 规则节点 */
private Map<String, RuleTreeNodeVO> treeNodeMap;
}这是整棵树的根对象,里面描述了:
-
树 ID
-
树名称
-
树描述
-
根节点 key
-
整棵树的节点集合 treeNodeMap
/**
-
@author Fuzhengwei bugstack.cn @小傅哥
-
@description 规则树节点对象
-
@create 2024-01-27 10:48
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class RuleTreeNodeVO {/** 规则树ID /
private Integer treeId;
/* 规则Key /
private String ruleKey;
/* 规则描述 /
private String ruleDesc;
/* 规则比值 */
private String ruleValue;/** 规则连线 */
private ListtreeNodeLineVOList;
}
-
这个类描述的是单个节点,包含:
- 当前节点属于哪棵树
- 节点的 ruleKey
- 节点描述
- 节点自身配置值 ruleValue
- 从这个节点出发能走到哪些线 treeNodeLineVOList
例子:
ruleKey = "rule_stock"
ruleValue = "award:107"
ruleKey = "rule_lock"ruleValue = "1"
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则树节点指向线对象。用于衔接 from->to 节点链路关系
* @create 2024-01-27 10:49
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class RuleTreeNodeLineVO {
/** 规则树ID */
private Integer treeId;
/** 规则Key节点 From */
private String ruleNodeFrom;
/** 规则Key节点 To */
private String ruleNodeTo;
/** 限定类型;1:=;2:>;3:<;4:>=;5<=;6:enum[枚举范围] */
private RuleLimitTypeVO ruleLimitType;
/** 限定值(到下个节点) */
private RuleLogicCheckTypeVO ruleLimitValue;
}这是树里的"边",也就是节点和节点之间的连接关系。里面描述了:
- 从哪个节点来
- 到哪个节点去
- 用什么条件判断这条边能不能走
- 命中的条件值是什么
这是规则树比责任链更强的地方。
责任链里"下一个是谁"是固定的;规则树里"下一个是谁"要看当前判断结果。
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则限定枚举值
* @create 2024-01-27 12:27
*/
@Getter
@AllArgsConstructor
public enum RuleLimitTypeVO {
EQUAL(1, "等于"),
GT(2, "大于"),
LT(3, "小于"),
GE(4, "大于&等于"),
LE(5, "小于&等于"),
ENUM(6, "枚举"),
;
private final Integer code;
private final String info;
}这个枚举是给树的边做条件类型定义的,支持:
- 等于
- 大于
- 小于
- 大于等于
- 小于等于
- 枚举
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则过滤校验类型值对象
* @create 2024-01-06 11:10
*/
@Getter
@AllArgsConstructor
public enum RuleLogicCheckTypeVO {
ALLOW("0000", "放行;执行后续的流程,不受规则引擎影响"),
TAKE_OVER("0001","接管;后续的流程,受规则引擎执行结果影响"),
;
private final String code;
private final String info;
}RuleLogicCheckTypeVO 本质上是在统一表达一件事:
当前规则执行完之后,流程下一步该怎么走。
它现在只有两个值:
- ALLOW
- TAKE_OVER
RuleLogicCheckTypeVO 虽然只是一个包含 ALLOW 和 TAKE_OVER 的简单枚举,但它在整个规则体系中承担了非常关键的统一语义作用。在过滤器模式下,它用来表达当前规则是否放行;在责任链模式下,它的语义被内化为"继续传递"与"当前节点接管";而到了规则树模型中,它又进一步承担了节点分支流转条件的角色。也正是因为有了这样一套统一的规则结果标识,前置规则、中置规则以及树形决策流程才能在不同模式下保持一致的执行语义。
4.新增规则树节点接口
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则树接口
* @create 2024-01-27 11:14
*/
public interface ILogicTreeNode {
DefaultTreeFactory.TreeActionEntity logic(String userId, Long strategyId, Integer awardId);
}和责任链节点相比,这里的输入更像"抽奖中的上下文":
- userId
- strategyId
- awardId
返回值也不再是单纯的 awardId,而是一个更完整的动作对象 TreeActionEntity
这说明树节点的职责不是简单地"产出一个奖品",而是"做一次判断,并告诉引擎本次判断结果是什么,同时可附带奖品处理数据"。
5. 新增规则树工厂
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则树工厂
* @create 2024-01-27 11:28
*/
@Service
public class DefaultTreeFactory {
private final Map<String, ILogicTreeNode> logicTreeNodeGroup;
public DefaultTreeFactory(Map<String, ILogicTreeNode> logicTreeNodeGroup) {
this.logicTreeNodeGroup = logicTreeNodeGroup;
}
public IDecisionTreeEngine openLogicTree(RuleTreeVO ruleTreeVO) {
return new DecisionTreeEngine(logicTreeNodeGroup, ruleTreeVO);
}
/**
* 决策树个动作实习
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public static class TreeActionEntity {
private RuleLogicCheckTypeVO ruleLogicCheckType;
private StrategyAwardData strategyAwardData;
}
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public static class StrategyAwardData {
/** 抽奖奖品ID - 内部流转使用 */
private Integer awardId;
/** 抽奖奖品规则 */
private String awardRuleValue;
}
}这个类是规则树体系的入口工厂。
它和前面的责任链工厂很像,也使用了:
private final Map<String, ILogicTreeNode> logicTreeNodeGroup;也就是说,这里的树节点 Bean 也是由 Spring 自动收集的,和责任链那套方式一致。
不同点在于,责任链工厂负责"按顺序拼链",规则树工厂负责"给定一棵树配置,创建一个决策引擎"。
它的核心方法是:
public IDecisionTreeEngine openLogicTree(RuleTreeVO ruleTreeVO)也就是说,树不是在工厂里写死的,而是由外部传入 RuleTreeVO,工厂只负责把"节点集合 + 树配置"组装成一台可执行的引擎。
这个类里还定义了两个内部数据对象:
- TreeActionEntity
- StrategyAwardData
这两个对象很关键:
TreeActionEntity 表达"节点执行结果",包括:
- 本次规则判断类型 ruleLogicCheckType
- 可选的奖品处理数据 strategyAwardData
StrategyAwardData 表达的是更贴近业务的结果数据:
- awardId
- awardRuleValue
这说明已经开始把"规则执行结果"和"奖品流转数据"分开包装,为后续更复杂的树节点交互做准备。
6.新增决策树引擎
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 决策树引擎
* @create 2024-01-27 11:34
*/
@Slf4j
public class DecisionTreeEngine implements IDecisionTreeEngine {
private final Map<String, ILogicTreeNode> logicTreeNodeGroup;
private final RuleTreeVO ruleTreeVO;
public DecisionTreeEngine(Map<String, ILogicTreeNode> logicTreeNodeGroup, RuleTreeVO ruleTreeVO) {
this.logicTreeNodeGroup = logicTreeNodeGroup;
this.ruleTreeVO = ruleTreeVO;
}
@Override
public DefaultTreeFactory.StrategyAwardData process(String userId, Long strategyId, Integer awardId) {
DefaultTreeFactory.StrategyAwardData strategyAwardData = null;
// 获取基础信息
String nextNode = ruleTreeVO.getTreeRootRuleNode();
Map<String, RuleTreeNodeVO> treeNodeMap = ruleTreeVO.getTreeNodeMap();
// 获取起始节点「根节点记录了第一个要执行的规则」
RuleTreeNodeVO ruleTreeNode = treeNodeMap.get(nextNode);
while (null != nextNode) {
// 获取决策节点
ILogicTreeNode logicTreeNode = logicTreeNodeGroup.get(ruleTreeNode.getRuleKey());
// 决策节点计算
DefaultTreeFactory.TreeActionEntity logicEntity = logicTreeNode.logic(userId, strategyId, awardId);
RuleLogicCheckTypeVO ruleLogicCheckTypeVO = logicEntity.getRuleLogicCheckType();
strategyAwardData = logicEntity.getStrategyAwardData();
log.info("决策树引擎【{}】treeId:{} node:{} code:{}", ruleTreeVO.getTreeName(), ruleTreeVO.getTreeId(), nextNode, ruleLogicCheckTypeVO.getCode());
// 获取下个节点
nextNode = nextNode(ruleLogicCheckTypeVO.getCode(), ruleTreeNode.getTreeNodeLineVOList());
ruleTreeNode = treeNodeMap.get(nextNode);
}
// 返回最终结果
return strategyAwardData;
}
public String nextNode(String matterValue, List<RuleTreeNodeLineVO> treeNodeLineVOList) {
if (null == treeNodeLineVOList || treeNodeLineVOList.isEmpty()) return null;
for (RuleTreeNodeLineVO nodeLine : treeNodeLineVOList) {
if (decisionLogic(matterValue, nodeLine)) {
return nodeLine.getRuleNodeTo();
}
}
throw new RuntimeException("决策树引擎,nextNode 计算失败,未找到可执行节点!");
}
public boolean decisionLogic(String matterValue, RuleTreeNodeLineVO nodeLine) {
switch (nodeLine.getRuleLimitType()) {
case EQUAL:
return matterValue.equals(nodeLine.getRuleLimitValue().getCode());
// 以下规则暂时不需要实现
case GT:
case LT:
case GE:
case LE:
default:
return false;
}
}
}/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 规则树组合接口
* @create 2024-01-27 11:33
*/
public interface IDecisionTreeEngine {
DefaultTreeFactory.StrategyAwardData process(String userId, Long strategyId, Integer awardId);
}这是这一节最核心的代码。
责任链解决的是"节点顺序怎么传",规则树引擎解决的是"从根节点开始,怎么根据每次节点判断结果决定下一步走向"。
process(...) 的执行流程是:
- 先从 RuleTreeVO 里拿到根节点 key
- 根据根节点 key 从 treeNodeMap 里拿到节点配置
- 根据节点的 ruleKey 去 Spring 收集好的 logicTreeNodeGroup 里找到真正的节点实现类
- 调用节点的 logic(...) 计算出当前动作结果
- 根据这个结果和当前节点的连线配置,决定下一个节点是谁
- 循环往下执行,直到没有下一个节点为止
- 最后返回最终的 StrategyAwardData
这就是一个典型的树型决策流程。
它比责任链多出来的关键能力在于:
- 责任链的下一步是固定的 next()
- 决策树的下一步是通过 nextNode(...) 动态算出来的
这里的 nextNode(...) 又依赖 decisionLogic(...) 去判断当前规则结果是否满足某条边的条件。当前实现里只支持 EQUAL,也就是"当前节点返回的结果 code 是否等于某条边要求的值"。
这套结构虽然现在还很初级,但骨架已经完整了:
- 树配置
- 节点接口
- 节点实现
- 引擎执行
- 分支跳转
都已经搭起来了
7.新增三个规则树节点实现
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 次数锁节点
* @create 2024-01-27 11:22
*/
@Slf4j
@Component("rule_lock")
public class RuleLockLogicTreeNode implements ILogicTreeNode {
@Override
public DefaultTreeFactory.TreeActionEntity logic(String userId, Long strategyId, Integer awardId) {
return DefaultTreeFactory.TreeActionEntity.builder()
.ruleLogicCheckType(RuleLogicCheckTypeVO.ALLOW)
.build();
}
}这个节点表示"次数锁判断节点"。
当前实现非常简单,直接返回 ALLOW。
也就是说,它现在更像一个占位实现,用来验证"树能不能从锁节点继续往下走",而不是完整实现实际次数锁逻辑。
这个设计能看出这一节的重点:
先把树模型和引擎跑通,再逐步往节点里填业务。
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 库存扣减节点
* @create 2024-01-27 11:25
*/
@Slf4j
@Component("rule_stock")
public class RuleStockLogicTreeNode implements ILogicTreeNode {
@Override
public DefaultTreeFactory.TreeActionEntity logic(String userId, Long strategyId, Integer awardId) {
return DefaultTreeFactory.TreeActionEntity.builder()
.ruleLogicCheckType(RuleLogicCheckTypeVO.TAKE_OVER)
.build();
}
}这个节点表示"库存处理节点"。
它当前直接返回 TAKE_OVER,也没有真正去扣库存。
这也是一个典型的骨架节点,说明此时树的目标主要还是验证路径流转,而不是把库存能力彻底做完。
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 兜底奖励节点
* @create 2024-01-27 11:23
*/
@Slf4j
@Component("rule_luck_award")
public class RuleLuckAwardLogicTreeNode implements ILogicTreeNode {
@Override
public DefaultTreeFactory.TreeActionEntity logic(String userId, Long strategyId, Integer awardId) {
return DefaultTreeFactory.TreeActionEntity.builder()
.ruleLogicCheckType(RuleLogicCheckTypeVO.TAKE_OVER)
.strategyAwardData(DefaultTreeFactory.StrategyAwardData.builder()
.awardId(101)
.awardRuleValue("1,100")
.build())
.build();
}
}这个节点表示"兜底奖励节点"。
它会返回:
- TAKE_OVER
- 一个固定的 StrategyAwardData
- awardId = 101
- awardRuleValue = "1,100"
这个节点是三个里面最有业务意味的,因为它已经开始返回"实际奖品数据"了。
这说明在规则树语境下,兜底奖励会成为某些分支路径的叶子节点,一旦走到这里,就直接产出最终奖励数据。
8.抽奖装配算法修复(之前遗留)
java
/**
* @author Fuzhengwei bugstack.cn @小傅哥
* @description 策略装配库(兵工厂),负责初始化策略计算
* @create 2023-12-23 10:02
*/
@Slf4j
@Service
public class StrategyArmoryDispatch implements IStrategyArmory, IStrategyDispatch {
@Resource
private IStrategyRepository repository;
@Override
public boolean assembleLotteryStrategy(Long strategyId) {
// 1. 查询策略配置
List<StrategyAwardEntity> strategyAwardEntities = repository.queryStrategyAwardList(strategyId);
assembleLotteryStrategy(String.valueOf(strategyId), strategyAwardEntities);
// 2. 权重策略配置 - 适用于 rule_weight 权重规则配置
StrategyEntity strategyEntity = repository.queryStrategyEntityByStrategyId(strategyId);
String ruleWeight = strategyEntity.getRuleWeight();
if (null == ruleWeight) return true;
// TODO queryStrategyRule 方法名称限定,只查询一个对象。目前可能造成别人调用查询list返回
StrategyRuleEntity strategyRuleEntity = repository.queryStrategyRule(strategyId, ruleWeight);
if (null == strategyRuleEntity) {
throw new AppException(ResponseCode.STRATEGY_RULE_WEIGHT_IS_NULL.getCode(), ResponseCode.STRATEGY_RULE_WEIGHT_IS_NULL.getInfo());
}
Map<String, List<Integer>> ruleWeightValueMap = strategyRuleEntity.getRuleWeightValues();
Set<String> keys = ruleWeightValueMap.keySet();
for (String key : keys) {
List<Integer> ruleWeightValues = ruleWeightValueMap.get(key);
ArrayList<StrategyAwardEntity> strategyAwardEntitiesClone = new ArrayList<>(strategyAwardEntities);
strategyAwardEntitiesClone.removeIf(entity -> !ruleWeightValues.contains(entity.getAwardId()));
assembleLotteryStrategy(String.valueOf(strategyId).concat(Constants.UNDERLINE).concat(key), strategyAwardEntitiesClone);
}
return true;
}
/**
* 计算公式;
* 1. 找到范围内最小的概率值,比如 0.1、0.02、0.003,需要找到的值是 0.003
* 2. 基于1找到的最小值,0.003 就可以计算出百分比、千分比的整数值。这里就是1000
* 3. 那么「概率 * 1000」分别占比100个、20个、3个,总计是123个
* 4. 后续的抽奖就用123作为随机数的范围值,生成的值100个都是0.1概率的奖品、20个是概率0.02的奖品、最后是3个是0.003的奖品。
*/
private void assembleLotteryStrategy(String key, List<StrategyAwardEntity> strategyAwardEntities) {
// 1. 获取最小概率值
BigDecimal minAwardRate = strategyAwardEntities.stream()
.map(StrategyAwardEntity::getAwardRate)
.min(BigDecimal::compareTo)
.orElse(BigDecimal.ZERO);
// 2. 循环计算找到概率范围值
BigDecimal rateRange = BigDecimal.valueOf(convert(minAwardRate.doubleValue()));
// 3. 生成策略奖品概率查找表「这里指需要在list集合中,存放上对应的奖品占位即可,占位越多等于概率越高」
List<Integer> strategyAwardSearchRateTables = new ArrayList<>(rateRange.intValue());
for (StrategyAwardEntity strategyAward : strategyAwardEntities) {
Integer awardId = strategyAward.getAwardId();
BigDecimal awardRate = strategyAward.getAwardRate();
// 计算出每个概率值需要存放到查找表的数量,循环填充
for (int i = 0; i < rateRange.multiply(awardRate).intValue(); i++) {
strategyAwardSearchRateTables.add(awardId);
}
}
// 4. 对存储的奖品进行乱序操作
Collections.shuffle(strategyAwardSearchRateTables);
// 5. 生成出Map集合,key值,对应的就是后续的概率值。通过概率来获得对应的奖品ID
Map<Integer, Integer> shuffleStrategyAwardSearchRateTable = new LinkedHashMap<>();
for (int i = 0; i < strategyAwardSearchRateTables.size(); i++) {
shuffleStrategyAwardSearchRateTable.put(i, strategyAwardSearchRateTables.get(i));
}
// 6. 存放到 Redis
repository.storeStrategyAwardSearchRateTable(key, shuffleStrategyAwardSearchRateTable.size(), shuffleStrategyAwardSearchRateTable);
}
/**
* 转换计算,只根据小数位来计算。如【0.01返回100】、【0.009返回1000】、【0.0018返回10000】
*/
private double convert(double min){
double current = min;
double max = 1;
while (current < 1){
current = current * 10;
max = max * 10;
}
return max;
}
@Override
public Integer getRandomAwardId(Long strategyId) {
// 分布式部署下,不一定为当前应用做的策略装配。也就是值不一定会保存到本应用,而是分布式应用,所以需要从 Redis 中获取。
int rateRange = repository.getRateRange(strategyId);
// 通过生成的随机值,获取概率值奖品查找表的结果
return repository.getStrategyAwardAssemble(String.valueOf(strategyId), new SecureRandom().nextInt(rateRange));
}
@Override
public Integer getRandomAwardId(Long strategyId, String ruleWeightValue) {
String key = String.valueOf(strategyId).concat(Constants.UNDERLINE).concat(ruleWeightValue);
return getRandomAwardId(key);
}
@Override
public Integer getRandomAwardId(String key) {
// 分布式部署下,不一定为当前应用做的策略装配。也就是值不一定会保存到本应用,而是分布式应用,所以需要从 Redis 中获取。
int rateRange = repository.getRateRange(key);
// 通过生成的随机值,获取概率值奖品查找表的结果
return repository.getStrategyAwardAssemble(key, new SecureRandom().nextInt(rateRange));
}
}这个文件的改动虽然不属于规则树主线,但很重要,因为它修的是概率装配算法。
旧逻辑是:
- 先算总概率和最小概率
- 再用 totalAwardRate / minAwardRate 得到范围值
- 然后用 setScale(..., CEILING) 去扩展每个奖品的占位数
新逻辑改成:
- 单纯根据最小概率的小数位数,算出一个合适的放大倍数
- 比如 0.01 -> 100
- 0.009 -> 1000
- 0.0018 -> 10000
然后再用这个倍数去生成概率表。
新增的 convert(...) 方法本质上是在做"把最小概率转换成整数精度范围"的事。
这个修正的意义是:
原来的算法在某些概率组合下,可能会出现装配偏差;现在的方式更直接,按小数位精度来构建概率表,思路更稳定。