声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
相关知识:
2014年,Google团队在ImageNet大规模视觉识别挑战赛(ILSVRC 2014)中提出了一种代号为"Inception"的深度卷积神经网络架构,即GoogLeNet(InceptionV1),一举斩获分类与检测双料冠军。该架构以500万参数量达到了top-5错误率6.67%的优异性能,参数量仅为AlexNet(6000万)的1/12,计算量仅15亿次浮点运算,却拥有22层的深度,远超过AlexNet的8层。
一、产生背景
nceptionV1的诞生并非偶然,而是源于当时主流卷积神经网络所面临的深刻困境。在AlexNet于2012年取得突破性成果之后,研究者普遍认为提升网络性能最直接的方法就是增加网络的深度(层数)和宽度(神经元数量)。然而,这种朴素的堆叠策略在实践中暴露出了三个根本性问题:
(1)过拟合风险陡增。 网络越深、越宽,参数量急剧膨胀,对训练数据量的需求也随之增加。在高质量标注数据有限的情况下,模型极易陷入过拟合。
(2)计算资源难以承受。 网络规模的扩大直接带来计算复杂度的激增,不仅在训练阶段耗时巨大,在推理部署阶段也面临严峻的资源约束。
(3)梯度消失问题严重。 随着网络层数的加深,误差信号在反向传播过程中逐层衰减,底层网络参数难以获得有效的梯度更新,模型优化变得极为困难。
理论上,解决上述问题最直接的方法是将全连接层乃至卷积层转化为稀疏连接结构------这既有坚实的理论基础(Arora等人的开创性工作证明了其可行性),也符合生物神经系统的运作规律。然而,现实中的硬件基础设施对非均匀稀疏数据的计算效率极低。即便算术运算数量减少了100倍,查找和缓存丢失的开销依然占据主导地位,计算所消耗的时间反而难以降低。
二、核心设计思想:稀疏性与密集计算的融合
面对"稀疏连接理论优越但硬件效率低下"的困境,Google团队提出了一个极具洞见的解决方案:设计一种既能利用稀疏性、又能通过密集组件高效实现的网络结构,并将这一结构作为可重复的"基础神经元"在整个网络中堆叠。
这一设计思想贯穿了InceptionV1的整个架构。其核心逻辑在于:通过精心设计的局部拓扑结构,在保持网络稀疏性的同时,确保每一层计算都能充分发挥密集矩阵运算的硬件优势。Inception模块因此应运而生,它本质上是一种对最优局部稀疏结构的稠密近似。
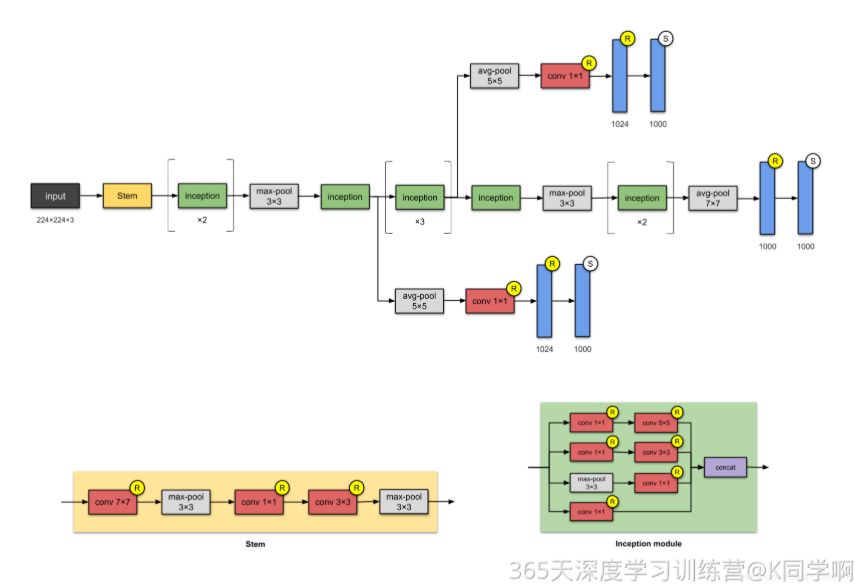
三、Inception模块的多尺度并行结构
3.1 并行分支与多尺度特征提取
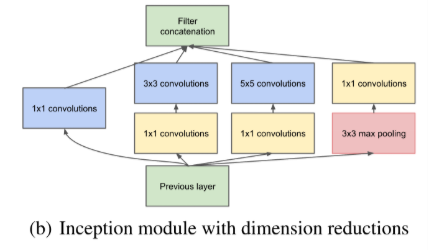
Inception模块最直观的特征是其四条并行计算路径。在原始版本(naive Inception)中,模块包含以下四个分支:
-
1×1卷积分支:用于特征降维与通道重组;
-
3×3卷积分支:捕获中等尺度的空间特征;
-
5×5卷积分支:提取大范围的上下文信息;
-
3×3最大池化分支:保留空间结构的同时进行下采样。
为什么选择1×1、3×3和5×5这三种卷积核? 这主要出于工程便利性的考虑。当设定卷积步长为1时,只要分别设置填充(padding)为0、1、2,三种卷积运算便能输出相同尺寸的特征图,从而可以在通道维度上直接拼接(concat)。此外,1×1卷积核的参数量为1,3×3为9,5×5为25,后续更大尺寸卷积核的参数量增长速度更快,因此在设计时予以限制。
四个分支的输出在通道维度上拼接(concat)形成最终的特征图,这种多尺度并行融合机制使网络能够在同一层内同时捕获不同粒度的信息。
3.2 为什么采用卷积并行而非串行
传统CNN通常采用串行堆叠设计,即在上一层输出基础上依次叠加卷积操作。而Inception模块采用的是并行架构,在同一层内同时执行多个不同规格的卷积和池化操作。这种设计的根本原因在于:不同大小的卷积核对应着不同大小的感受野,能够提取图像中不同尺度的特征信息。Inception模块通过并行设计,让网络自行选择最优的特征提取尺度组合,无需人为预设。
四、1×1卷积降维:InceptionV1的关键突破
4.1 降维的必要性
原始Inception模块虽然设计精妙,但存在一个致命缺陷:所有卷积核都在上一层所有输出特征图上进行计算,尤其是5×5卷积核,其计算量极为惊人,导致特征图厚度过大。例如,对于一个28×28×192的输入特征图,若直接使用5×5卷积核输出256个通道,参数量将达到5×5×192×256 =1,228,800,这对计算资源是沉重的负担。
4.2 1×1卷积的双重价值
为了解决这一问题,InceptionV1借鉴了Network in Network(NIN)的思想,在3×3卷积前、5×5卷积前以及最大池化后分别加入了1×1卷积核,形成了改良版Inception模块(即InceptionV1的最终结构)。1×1卷积在此扮演了至关重要的双重角色:
第一,维度压缩,大幅降低计算复杂度。 1×1卷积可以在进行真正的大卷积核运算之前,将输入通道数先降到较低的值,从而显著减少后续运算的参数量。仍以上述例子说明:若先使用1×1卷积将通道数从192降至32,再进行5×5卷积输出256个通道,参数量变为1×1×192×32 + 5×5×32×256 = 6,144 + 204,800 = 210,944,相较于原来的1,228,800减少了超过80%。实验数据显示,在224×224输入尺寸下,这一优化使单模块FLOPs减少约42%,而特征表达能力保持不变。
第二,增强网络非线性表达能力。 1×1卷积后接ReLU激活函数,可在局部感受野内构建深层非线性变换,增强模型对高维稀疏特征的处理能力。
4.3 降维逻辑的直观理解
可以把高维特征图理解为一本厚书,每个通道对应书中的一页。1×1卷积相当于先对这本书进行一次"浓缩"------用少量页数概括原始内容的核心信息,然后再用大卷积核去处理这些浓缩后的信息。这样既保留了信息的关键成分,又大幅降低了需要处理的页面数量,从而实现了计算效率的质变。
五、负责分类器:应对梯度消失的创新设计
深度达22层的InceptionV1面临严峻的梯度消失问题------误差信号从顶层向底层传播时逐步衰减,导致底层参数难以获得有效更新。为了解决这一问题,Google团队在网络中间层(Inception 4a和Inception 4d的输出之后)引入了两个辅助分类器。
辅助分类器的基本结构为:平均池化(5×5,stride=3)→ 1×1卷积(128个通道)→ 全连接层(1024个节点)→ 全连接层(1000个节点,对应分类类别数)。在训练过程中,辅助分类器产生的损失以0.3的折扣权重叠加到总损失中 ,最终损失函数为:总损失 = 主分类器损失 + 0.3 × 辅助分类器1损失 + 0.3 × 辅助分类器2损失。
辅助分类器的作用体现在三个层面:其一,在反向传播时向前端网络传递梯度,缓解梯度消失;其二,提供额外的正则化约束,提升模型的泛化性能;其三,中间层特征本身已具备较强的判别能力,其输出可作为模型融合的有益补充。需要注意的是,辅助分类器仅在训练阶段启用,推理时会被自动裁剪掉。
(在后续模型的发展中,该方法被采用较少)
运行结果:
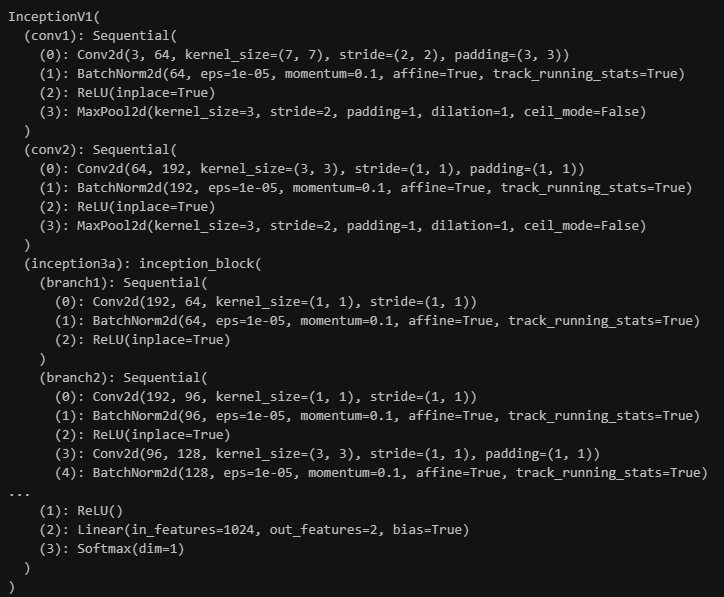
模型结构
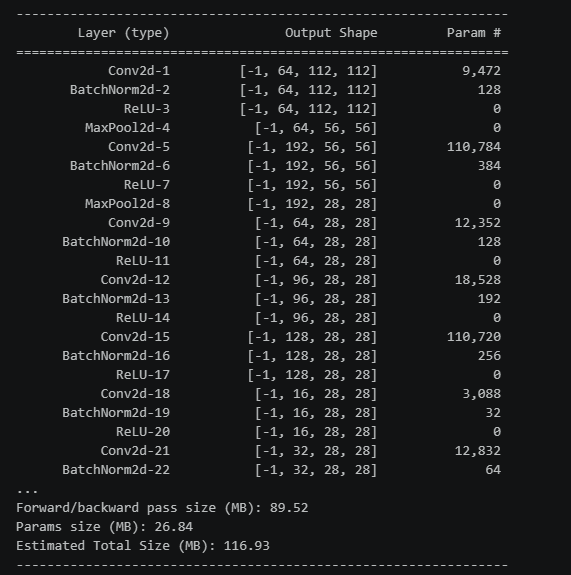
模型参数
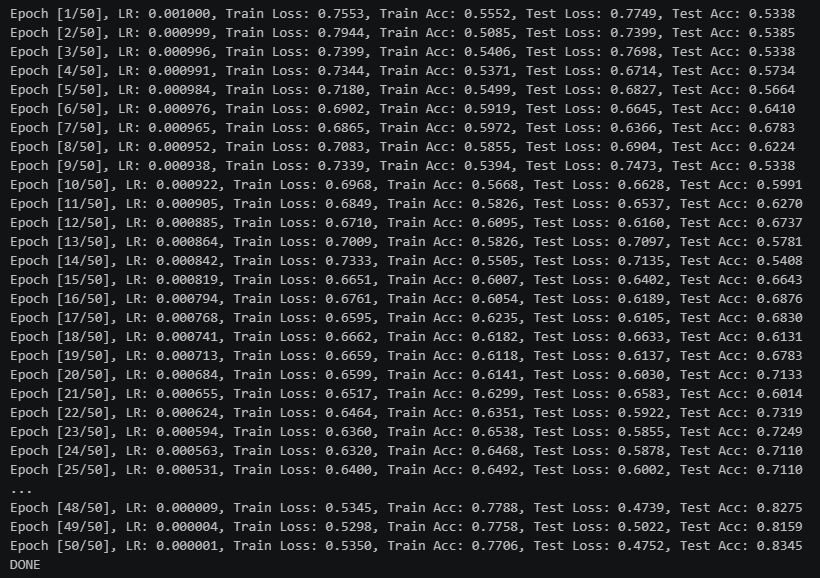
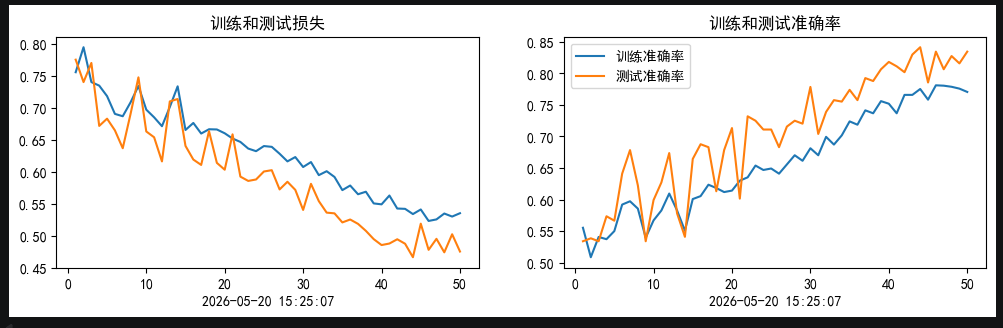
50epochs余弦退火0.001学习率训练
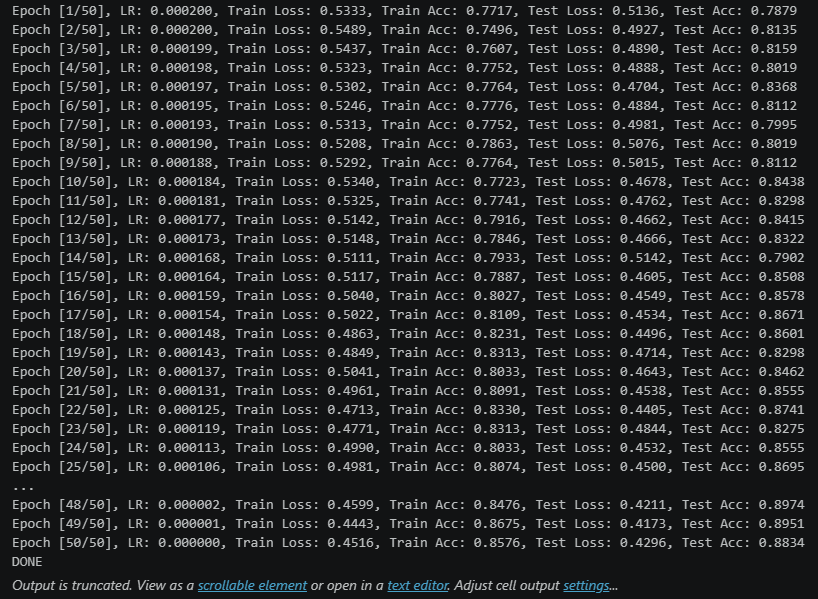
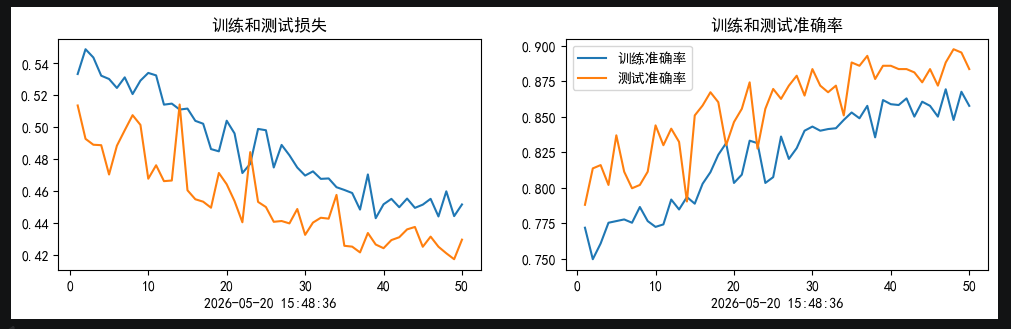
续50epochs余弦退火0.0002学习率训练
总结:
本节我们学习了Inception V1相关内容,特别是其中的卷积层并行结构和1*1卷积核的部分。
InceptionV1的卷积层并行结构打破了传统CNN串行堆叠的单一模式,通过在同一层内并行布置1×1、3×3、5×5卷积和池化分支,实现了多尺度感受野的同步特征提取。这种设计的本质是将尺度选择权交给网络自身------不同尺寸的卷积核分别捕获从局部细节到全局语义的跨尺度信息,最终在通道维度拼接形成融合表征。并行结构的价值不仅在于丰富了特征表达的多样性,更在于它以一种计算友好、参数高效的方式,在同一层空间内完成了传统架构需要多个串行层才能实现的信息聚合,为后续高效网络的设计提供了经典范式。
1×1卷积核在InceptionV1中扮演了双重关键角色:其一是高效降维,通过在3×3、5×5大卷积核前插入1×1卷积层,将高维输入特征图压缩到较低的通道数,使后续卷积的参数量和计算量降低约80%以上;其二是非线性增强,1×1卷积配合ReLU激活,在保持空间分辨率不变的前提下实现通道间的信息交互与非线性变换。此外,1×1卷积还用于池化分支后的通道对齐,确保四个分支的输出能够顺利拼接。正是这枚不起眼的"小核",使得Inception模块从理论上的"高成本多尺度结构"蜕变为实际可行的轻量化组件,成为现代卷积神经网络设计中最广泛使用的"杠杆工具"之一。
最总我们网络的训练结果能够达到90%左右的准确率(后续加入了50epochs的余弦退火0.0001学习率训练)