后台运营把某个热门商品的库存从 12 改成 5,管理后台弹出"修改成功"。可不到一秒,用户刷新商品详情页,页面上还是 12。
这类现象一出来,团队里最常见的两种回答很快就会冒出来。
- 一种说法是:
Redis只是缓存,过期了就好了。 - 另一种说法是:更新数据库后把缓存删掉,不就一致了。
这两句话都不算错,但都不够。因为真正难的不是"缓存会不会有旧值"这句空话,而是下面这几个更具体的问题:
- 旧值到底会在什么时刻冒出来。
- 为什么很多文章都推荐"先更新
MySQL,再删除Redis"。 - 为什么明明删了缓存,旧值还是可能被并发请求重新写回去。
- 延迟双删、
TTL、CDC这些词,到底分别在补什么洞。 - 如果业务真的不接受脏读,究竟该继续优化缓存,还是缩小缓存在这条链路里的职责。
这篇文章就只围绕这条主线往下讲,不展开成缓存全家桶,也不把 Canal、Debezium、Flink CDC 写成部署手册。
1. 先把问题说准:这里的一致性,到底在说什么
MySQL 和 Redis 组合里,最容易先犯的错,就是把两个东西写成两个平级的数据源。
它们不是平级关系。
MySQL是事实来源。Redis是副本,是为了把热点数据放得更近,读得更快。
只要这个角色关系没说清,后面很多争论都会跑偏。因为缓存一致性讨论的重点,从来不是"缓存里会不会有旧值"。缓存本来就可能有旧值。重点是旧值会存在多久、会影响哪些请求、业务能不能接受。
这件事通常至少要分成三层来看:
| 目标 | 含义 | 常见要求 |
|---|---|---|
| 强一致 | 任意时刻读到的都像只有一个真相源 | 余额、配额结算、最终扣减库存 |
| 读后写一致 | 自己刚写完,再读时希望看到新值 | 用户资料修改、配置开关、生效确认 |
| 最终一致 | 允许短时间旧值,但最终会收敛 | 商品详情、推荐结果、非关键统计 |
很多系统嘴上说"要缓存一致性",真正想要的其实不是第一层,而是后两层。因为一旦把"强一致"当成硬目标,缓存就会立刻变得很贵,甚至不再适合放在关键读路径上。
Redis不是第二个真相源,它只是把MySQL的结果搬近了一点。
所以,这篇文章后面说的"解决策略",本质上都是在回答一件事:怎样把不一致窗口压到业务能接受的范围里。
2. 为什么默认基线是"先更新 MySQL,再删除 Redis"
先看最常见的一套读写流程。这里说的"旁路缓存",指的是应用自己决定何时读缓存、何时读库、何时删除旧缓存,而不是把这些动作完全交给缓存中间件自动处理。
这张图对应的是旁路缓存的基线做法:
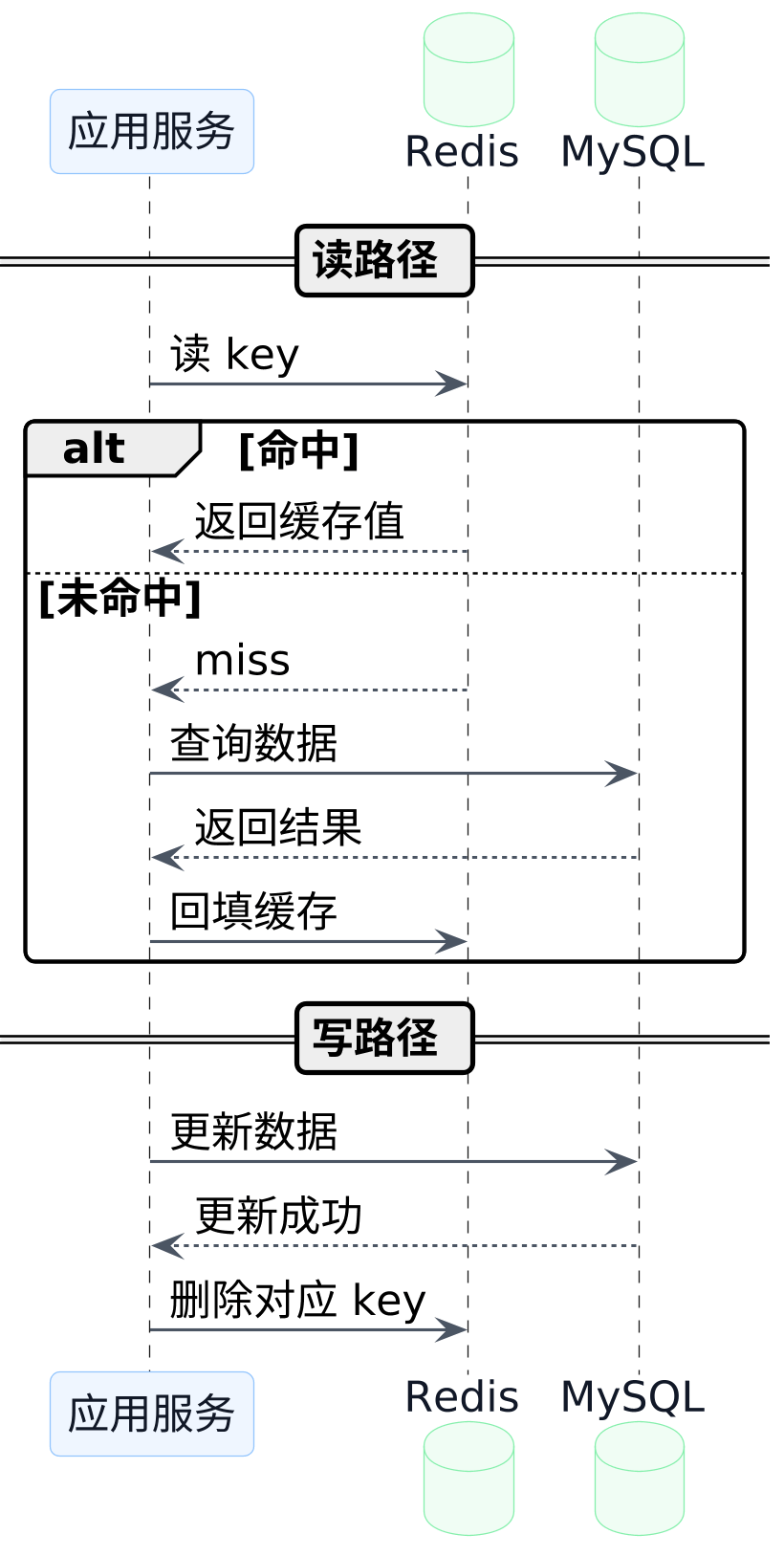
读路径很简单:先查缓存,没命中再查库,然后把结果回填到缓存。
写路径也很简单:先更新数据库,成功后删除缓存。
用伪代码写出来,大概就是这样:
java
public Product getProduct(Long productId) {
String key = "product:" + productId;
Product cached = redisClient.get(key);
if (cached != null) {
return cached;
}
Product product = productRepository.findById(productId);
if (product != null) {
redisClient.set(key, product, 300);
}
return product;
}
public void updateProductStock(Long productId, Integer newStock) {
productRepository.updateStock(productId, newStock);
redisClient.delete("product:" + productId);
}如果把这两条链路再压缩成最容易记的一版,其实就是下面这两句:
- 查询时缓存没命中 :查
MySQL,把结果回填到Redis,再返回给调用方。 - 修改时数据发生变化 :先更新
MySQL,成功后删除Redis里的旧 key。
也可以把它们理解成两种完全不同的职责:
- 查询链路负责把热点数据搬进缓存。
- 修改链路负责把旧缓存作废。
这里最值得注意的一点是,查询链路做的是"回填",修改链路做的是"失效",不是"顺手把缓存也改掉"。
很多人第一次看到这里,会有个本能追问:为什么不是更新完数据库,再顺手把缓存也更新成新值?
表面上看,更新缓存好像更直接。但缓存一致性里真正更常见的做法,恰恰不是"改缓存",而是"删缓存"。因为大多数系统想要的不是"每次写完都立即重建所有副本",而是"先把旧副本作废,等下一次真实读请求再按新数据重建"。
换句话说,这里不是"数据库和缓存一起改,谁更顺手"的问题,而是"写请求到底该承担到哪一步"的问题。
真正落到工程里,删除通常更稳,原因主要有三层。
2.1. 第一层:删除比更新更容易做到幂等
删缓存这件事,失败重试的语义很简单。再删一次,结果还是"没有这条 key"。
更新缓存不是这样。缓存里放的值不一定就是数据库一行原样拷贝,它可能是:
- 多张表 join 之后的结果。
- 经过字段裁剪和格式转换的结果。
- 一个详情页对象外加多个统计字段的聚合结果。
- 单条记录、列表页、分页页、搜索结果这几类 key 的组合。
一旦改成"更新缓存",写请求就得知道自己影响了哪些 key,以及每个 key 的新值该长什么样。这件事会迅速从"更新库存"变成"重建一堆视图"。
2.2. 第二层:删除把"重建新值"的动作推迟到了真正需要读的时候
不是每次写完都值得立刻重建缓存。很多数据写了之后,短时间内未必有人读。
删除缓存的意思是:先把旧副本干掉。至于新副本什么时候构建,交给下一次真正的读请求。
这就是旁路缓存常见的风格。写请求只负责维护事实来源和清掉旧副本,不额外承担"马上把所有缓存视图都修好"的责任。
2.3. 第三层:把事实来源放在前面,错误面更小
只要数据库还是最终真相源,写请求就不该先把缓存写成新值,再去赌数据库一定成功。
下面这几种顺序,问题都更明显:
这张图对应的是几种常见写序的总对照:

| 顺序 | 主要问题 |
|---|---|
| 先更新缓存,再写数据库 | 数据库失败时,缓存先变成假新值 |
| 先删缓存,再写数据库 | 在数据库提交完成前,别的请求可能把旧值重新回填 |
| 先写数据库,再更新缓存 | 要维护复杂缓存视图,多 key 场景容易漏、容易乱 |
| 先写数据库,再删缓存 | 不是完美,但错误面最小,通常作为默认基线 |
很多文章把这件事总结成一句话:"更新数据库后删除缓存。"这句话本身没问题,但它只是基线,不是终点。因为下面这个竞态窗口,才是缓存一致性真正让人头疼的地方。
3. 为什么删了缓存,旧值还是会回来
这件事不靠口号,靠时序才能看清。
这张图对应的是最典型的旧值回填竞态:
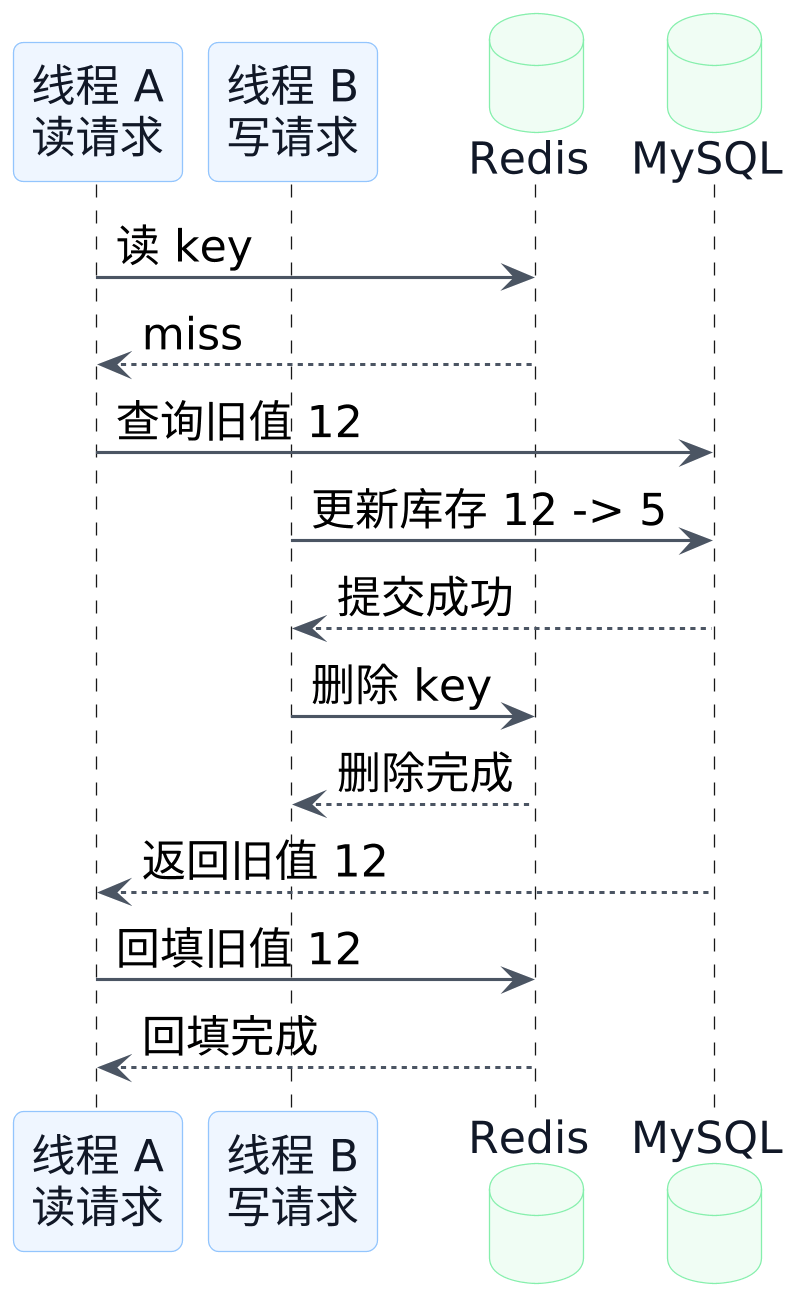
这里最关键的一步,是线程 A 的读请求在更早的时候就已经去数据库查了,只是它查到的还是旧值。线程 B 在这段时间里完成了写库和删缓存。按直觉看,缓存已经被清掉了,系统应该变干净了。
但线程 A 还没结束。它手里拿着旧值,最后一步还是会把 12 写回 Redis。
这就是很多人第一次遇到时会觉得别扭的地方:删缓存并不等于从此以后不会再出现旧值。删缓存只能保证"旧副本被清掉",不能保证"某个更早开始的读请求不会把旧值重新带回来"。
这个窗口通常不大,也不是每次都会撞上,所以"写库后删缓存"在大多数读多写少场景里依然够用。但只要业务对旧值更敏感,光靠这一步就不够了。
4. 先删缓存再写数据库,为什么反而更危险
很多人会想:既然问题出在"写库后删缓存"也有窗口,那是不是把顺序改成"先删缓存,再写数据库"更干净?
看起来像是在提前清场,实际更危险。
这张图对应的是这个顺序的风险:
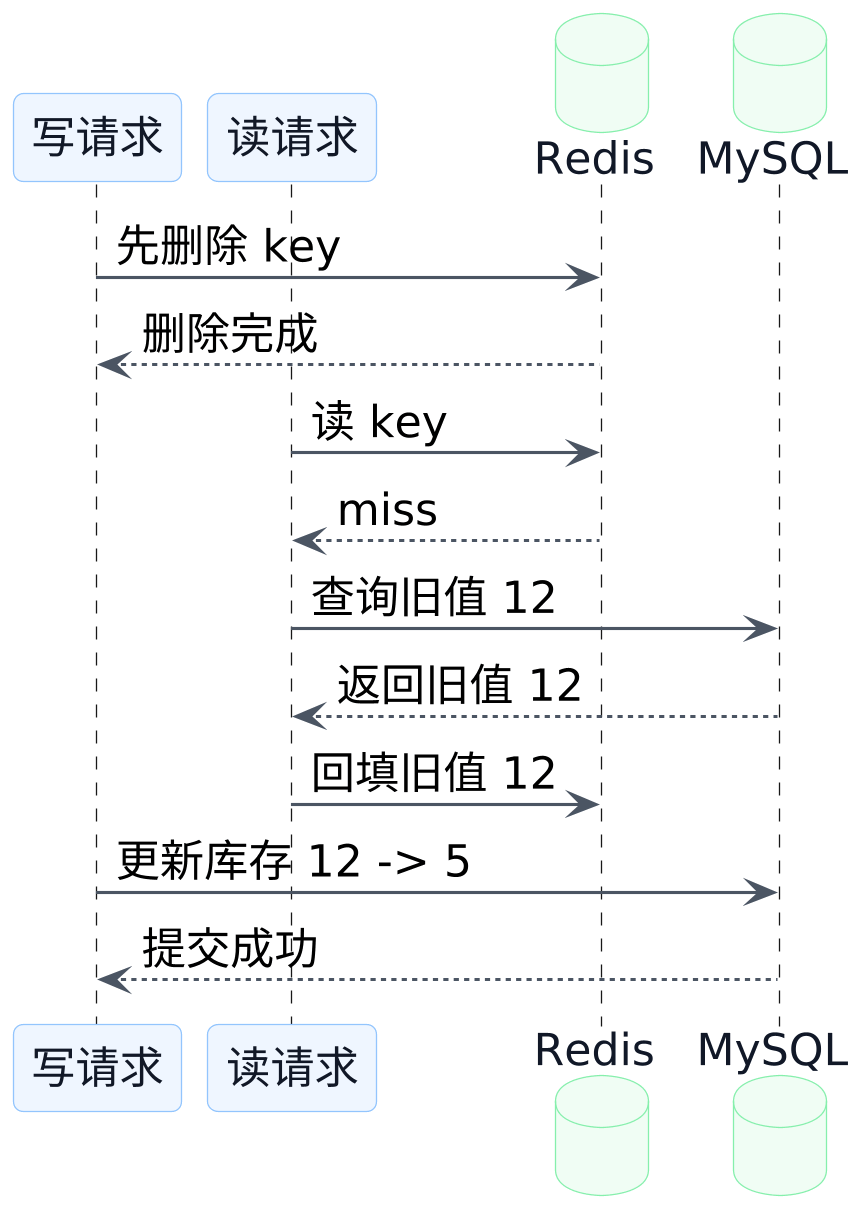
这里的问题更直接:缓存刚删完,数据库还没改好。只要这时插进来一个读请求,它查到的一定还是旧值,而且还会名正言顺地把旧值重新写回缓存。
和前面那个竞态相比,这个窗口更大,也更容易撞上。因为它把"缓存为空"这段时间主动提前了,而这段时间里的数据库仍然是旧值。
所以,"先删缓存再写数据库"不是更稳,而是把危险窗口放在了更显眼的位置。
5. 这些补强手段,分别在补什么洞
到这里,主线已经很清楚了。
- 基线方案是"先写库,再删缓存"。
- 这个方案不是零风险,只是把错误面压到了最小。
- 真正要做工程优化,重点不是去找银弹,而是分清每个补丁到底在补什么洞。
5.1. TTL 是兜底,不是主解法
缓存加过期时间当然有用,因为它至少能限制旧值最多活多久。
但它解决不了根问题。原因很简单:TTL 只能回答"脏数据多久后会死",回答不了"脏数据为什么会出现"。
如果系统本来就有旧值回填窗口,TTL=5min 和 TTL=30s 只是把后果拉长或缩短,不会让这个窗口消失。
所以 TTL 的定位更像兜底手段:
- 防止漏删缓存后旧值长期悬挂。
- 控制缓存自然淘汰节奏。
- 和随机过期一起分散热点 key 集中过期。
它很重要,但不能拿来替代失效策略本身。
5.2. 延迟双删补的是"旧值回填尾巴"
延迟双删的思路是:写库成功后先删一次缓存,过一个短延迟,再删一次。
这张图对应的是它在补哪个窗口:
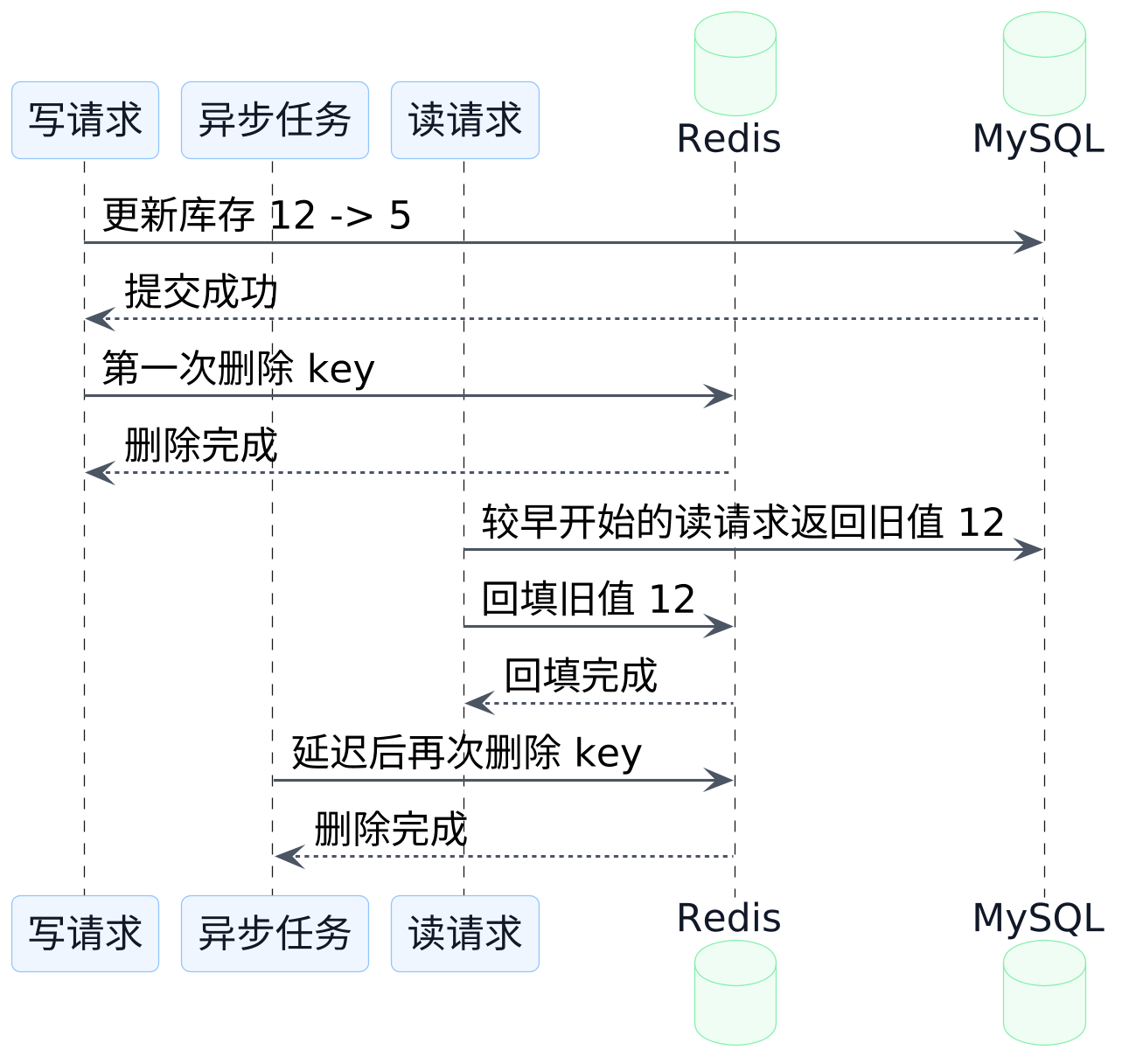
它想补的就是前面那种情况:某个更早开始的读请求,晚一点把旧值又塞回缓存里。第二次删除把这条"尾巴"再扫一遍。
这个办法在工程上是有价值的,但边界也要说清:
- 它补的是特定竞态,不是把系统变成强一致。
- 第二次删除必须能重试,否则异步任务丢了,这个补丁就断了。
- 延迟多久没有通用标准,通常要结合业务读写时延和数据库访问耗时来定。
- 如果业务根本无法接受这段窗口里的旧值,延迟双删也不够。
5.3. 互斥回源 / 单飞,补的是失效瞬间的大量并发回填
有些 key 很热,一旦失效,可能一群请求一起 miss,然后一起去数据库查,再一起回填缓存。
这时候真正的问题不只是数据库被打爆,还可能出现多个并发回填把旧值和新值来回覆盖。常见的办法是让同一个 key 在同一时刻只允许一个请求负责回源,其他请求等待结果或者短暂重试缓存。
它补的不是写序,而是缓存失效瞬间的并发回填秩序。
5.4. 版本号 / 时间戳,补的是"谁有资格写回缓存"
如果旧值回填特别敏感,还可以给缓存值带上版本号或更新时间。
思路很直接:
- 读请求从数据库查到数据时,顺手带上版本。
- 回填缓存时,只有当自己的版本不落后,才允许写入。
这类做法会复杂一些,但它回答的是一个很关键的问题:不是所有查完库的请求,都应该有资格把结果写回缓存。
5.5. 读后写一致要求更高时,可以短时绕开缓存
有些场景不是全局都要求强一致,只是"刚改完的人,下一次最好别看到旧值"。
比如用户改昵称、改地址、改配置开关之后,自己立刻刷新页面。这个时候可以做短时绕过缓存:
- 更新成功后,把某个用户或某个 key 标记为短时间强制读库。
- 或者在响应里带一个最新版本,让随后的读请求按版本校验。
这不是全局强一致,但它能把"自己刚改完却还看到旧值"的体验问题单独收掉。
6. 当写入路径不止一个服务时,为什么要让 CDC 接手
如果整个系统只有一个应用写数据库,而且所有写操作都老老实实从这一层经过,那么"写库后删缓存"虽然不完美,至少闭环还在同一个服务里。
真正麻烦的,是写入路径开始分叉。这里的 CDC 全称是 Change Data Capture,中文通常翻成"变更数据捕获"。它的意思是把数据库里的新增、修改、删除变更转成一条条可消费的事件,再由下游去做同步、失效或派生处理。
- 管理后台也能改这张表。
- 运营脚本会直连数据库修数据。
- 另一个服务会更新同一份业务对象。
- 订正任务、批处理任务会在半夜批量改库。
这时候,缓存失效逻辑继续写在当前服务里,就天然覆盖不全。因为总会有一些数据库变更根本没经过这段删缓存代码。
这张图对应的是更稳的一种做法:让数据库变更自己触发失效通知。
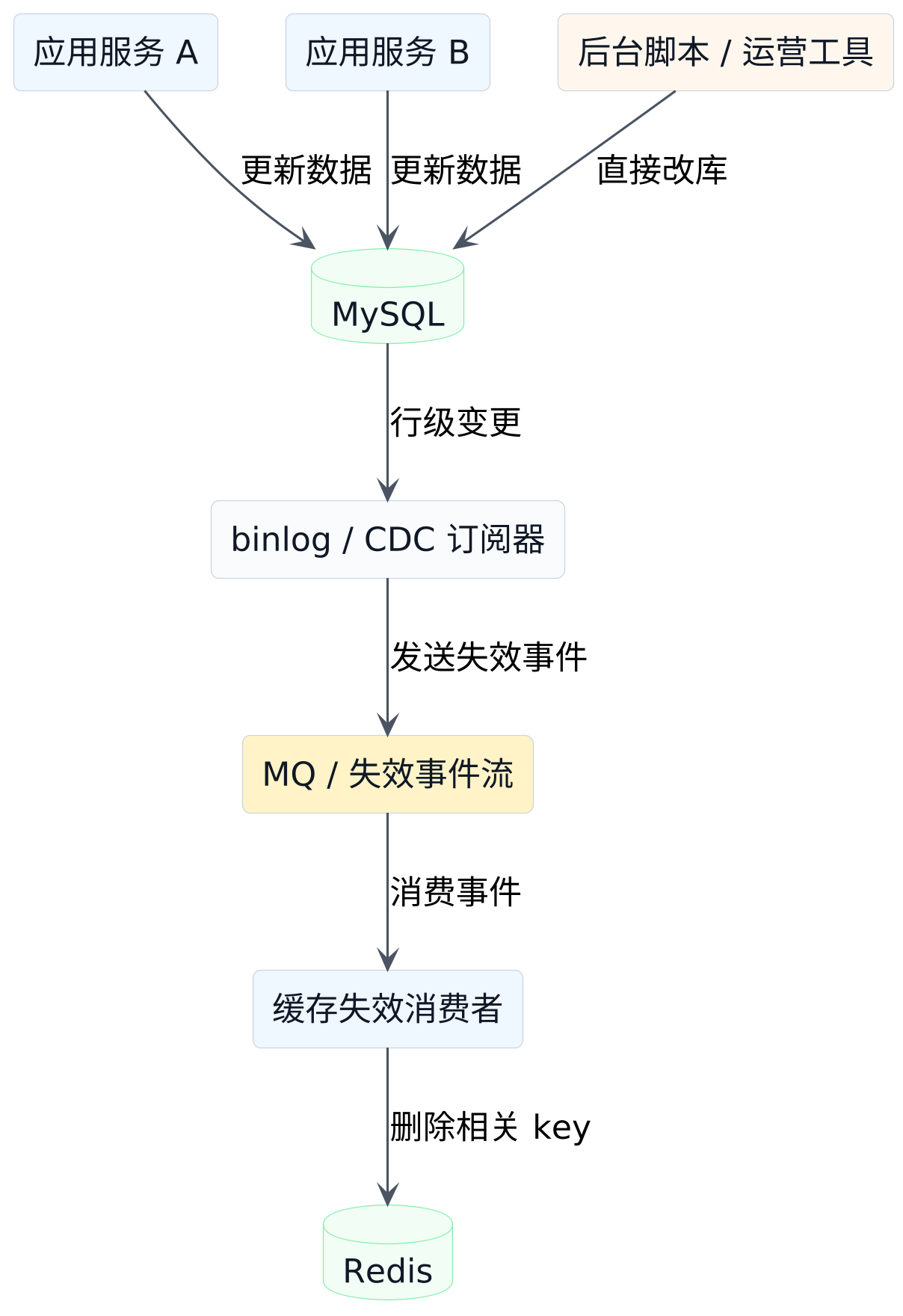
这里的关键变化,不是"删缓存更快了",而是删缓存这件事不再依赖某个业务服务记得手写这段逻辑。
只要数据库发生了变更,不管变更来自哪个入口,都能沿着统一的变更传播链路去失效缓存。
这也是 binlog / CDC 真正有价值的地方:
- 它覆盖跨服务写入。
- 它覆盖后台脚本或直连 SQL。
- 它把业务写逻辑和缓存失效逻辑解耦。
当然,边界也要说清:
CDC不是零延迟,仍然存在传播时间。- 它解决的是"失效通知覆盖不全",不是直接把系统变成强一致。
- 如果缓存 key 很复杂,最终还是要解决"根据哪条数据库变更删除哪些 key"的映射问题。
所以 CDC 更像是把"谁来发失效通知"这件事做统一,而不是把所有缓存问题一次解决掉。
7. 到底该怎么选:别再追一个万能答案
讲到这里,其实已经能看出一个很现实的结论:缓存一致性没有万能答案,只有按业务约束选一个最合适的错误面。
下面这个表,更适合拿来做工程判断:
| 场景 | 典型特点 | 推荐基线 | 常见补强 |
|---|---|---|---|
| 商品详情、配置页、用户资料展示 | 读多写少,允许极短时间旧值 | 写库后删缓存 | TTL、必要时延迟双删 |
| 热点 key,高并发回源明显 | 缓存一失效就很多请求一起查库 | 写库后删缓存 | 互斥回源、单飞、随机过期 |
| 多服务写入、后台脚本改库 | 删除缓存逻辑无法保证都经过同一服务 | 数据库变更驱动失效 | binlog / CDC、MQ |
| 聚合缓存、列表缓存 | 一个写操作会影响多个 key | 写库后删缓存 | 标签失效、版本号、异步重建 |
| 余额、最终扣减库存、硬约束配额 | 不能把旧值当成可接受代价 | 关键读绕开缓存 | 数据库事务、锁、限流,把缓存降级成加速层 |
这个表里最容易被忽略的一行,反而是最后一行。
很多人遇到强一致诉求时,第一反应还是继续给缓存打补丁。但对余额、结算、最终扣减库存这类场景,真正该先问的往往不是"缓存怎么做得更准",而是:这次读,是否还应该经过缓存。
如果这次读本来就承担最终裁决职责,那缓存更适合做旁路加速,而不是做判定依据。
8. 最后收一下:缓存一致性真正要解决的,不是口号
把整件事压成几条判断,其实就够了。
MySQL是事实来源,Redis是副本,这个关系决定了写请求为什么通常先写库,再删缓存。- "写库后删缓存"能成为默认答案,不是因为它完美,而是因为它把错误面压到了最小。
- 旧值回填是缓存一致性的核心竞态,延迟双删、互斥回源、版本号这些补强,都是围着这个窗口在做文章。
TTL只能兜底,不能代替失效策略本身。CDC的意义,不是把系统升级成强一致,而是把数据库变更统一转成失效通知,覆盖跨服务和直连库写入。- 如果业务真的不能接受脏读,优先缩小缓存的职责,而不是继续指望缓存承担最终真相。
说到底,缓存一致性讨论的重点,从来不是"系统里有没有旧值",而是旧值会出现在哪里、会持续多久、业务愿不愿意为更强的一致性继续付成本。