Linux-EXT系列文件系统
引入文件系统
1、引入"块"概念
硬盘本质上是一种块设备,OS在读取硬盘数据的时候,其实不是一个扇区一个扇区去读写的,这样效率太低了,而是一次性读取多个扇区,即一次性读取一个数据块 (block)。
硬盘的每一个分区都是由数据块组成的,每一个块的大小在格式化的时候就被确定了,并且不能被更改,最常见的块大小是4KB,即8个扇区,4096 = 512 * 8,由8个扇区组成一个块,块是文件存取的最小单位。
bash
[benjiangliu@VM-4-8-centos lesson8]$ stat code.c
File: 'code.c'
Size: 534 Blocks: 8 IO Block: 4096 regular file
# Size: code.c的文件大小是534字节
# Block: 文件实际占用的磁盘块数量。
# stat命令 的 Blocks 单位:stat 命令在汇报 Blocks 时,强制规定以 512 字节为一个"计数块"。
# 注意,这里的"块"指的是底层文件系统的磁盘块,默认大小通常是 512 字节。所以 8 * 512 = 4096 字节。
# IO Block:这是文件系统的标准块大小(也就是我们常说的 4K 块),也就是linux读取数据的最小单位
# regular: 指的是这是一个普通文件
Device: fd01h/64769d # 文件所在的设备编号
Inode: 1050758 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/benjiangliu) Gid: ( 1001/benjiangliu)
Access: 2026-04-19 21:48:30.381237426 +0800
Modify: 2025-10-21 12:11:13.528975201 +0800
Change: 2025-10-21 12:11:13.528975201 +0800
Birth: -几个问题:
1、为什么上面那个code.c文件只有534自己,但是却分配了8个"块",4K个字节的空间。
因为Linux 文件系统(比如 ext4 或 xfs)在存储文件时,最小的分配单位就是 4KB(4096字节)。这就好比停车场的一个车位,哪怕你停的是一辆很小的摩托车(534字节),你也必须独占整整一个车位(4096字节)。
2、为什么要按照一个块4KB来读取?
核心是机械硬盘读取效率导致的,在每次数据读取的过程中,如果磁盘就需要旋转、磁头移动定位一次就只需要进行一个扇区数据的读取,太浪费、效率也太低了。
3、为什么在对磁盘格式化例如U盘、重做系统格式化的时候,扇区有4K的选项?
因为512字节和4K字节的扇区大小都在广泛使用,取决于硬盘的年代、类型和配置。
在容量大于2TB的机械硬盘和几乎所有的SSD固态硬盘中,物理层面几乎都是4K扇区,但是想不同OS汇报数据的时候,他们会呈现不同逻辑扇区大小。
512e(512 字节仿真模式):这是目前最主流的模式。硬盘的物理扇区是 4K,但为了兼容老旧的操作系统和软件,硬盘固件会"假装"自己的扇区是 512 字节。当 Linux 发出 512 字节的读写请求时,硬盘内部会进行转换(通常是一次读取或写入完整的 4K 物理扇区)。
4Kn(原生 4K 模式):硬盘的物理扇区是 4K,逻辑扇区也直接汇报为 4K。这种模式效率最高,没有仿真转换的开销,但对操作系统和分区工具有一定的要求(现代 Linux 内核早已完美支持)。
我们可以通过 lsblk -t 命令查看磁盘信息。
bash
benjiangliu@DESKTOP-IPP4TUH:~$ lsblk -t
NAME ALIGNMENT MIN-IO OPT-IO PHY-SEC LOG-SEC ROTA SCHED RQ-SIZE RA WSAME
sda 0 512 0 512 512 1 none 1267 128 0B
sdb 0 512 0 512 512 1 none 1267 128 0B
sdc 0 4096 0 4096 512 1 none 1267 128 0B
sdd 0 4096 0 4096 512 1 none 1267 128 0B这个是我的WSL虚拟机,可以看到他的
PHY-SEC 代表物理扇区大小(Physical Sector Size)是 512字节。
LOG-SEC 代表逻辑扇区大小(Logical Sector Size) 是 512字节。
在上一篇文章中我们已经说了每个扇区都存在自己的LBA地址(线性地址),那么每8个扇区一个块,每个块的地址我们也就能算出来了。
块号 = LBA地址/8
例如我们知道LBA地址是30,那么我们就可以通过公式LBA30 = 3*8 + 6 得出块地址是3,LBA30这个扇区,在块号3内的第5个扇区(从0开始计算)。
2、引入分区概念
一个磁盘可以有多个分区,我们使用的windows电脑可以有C\D\E\F盘,那么C\D\E\F就是分区。
分区的本质是对磁盘进行格式化,但是linux中一切皆文件,他是怎么分区的呢?
柱面是分区的最小单位,我们可以利用参考柱面号码的方式进行分区,其本质就是设置每个分区的起始柱面和结束柱面,此时我们可以将硬盘上的柱面进行平铺,将其想象成一个大的平面线性结构。
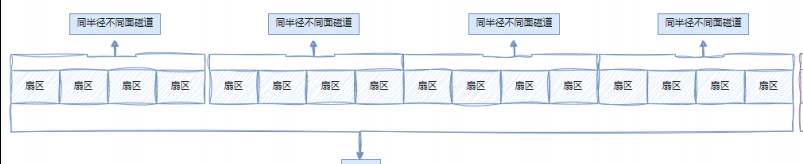
上图中详细描述了一个柱面的结构。
一个柱面就是由若干个盘面相同编号的磁道展开构成的。

上图中详细描述了一个分区的结构
一个分区就是由若干个编号连续的柱面构成的。
3、引入inode概念
之前我们学习linux基础IO的时候说过,linux中一切皆文件,而文件 = 数据 + 元属性。
我们在使用ls -l的时候除了能够看到文件名,还能够看到文件的属性(元属性)
bash
benjiangliu@DESKTOP-IPP4TUH:~$ ls -l
total 8
# 权限 硬链接数 文件所有者 文件所有组 文件大小 文件最后修改时间 文件名
-rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:40 a.out
-rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:41 test.c从这个ls命令我们读取到的信息中可以知道,我们看到的文件的属性,并不是文件的内容,而本质上在linux中文件属性和数据也是分开存放的。
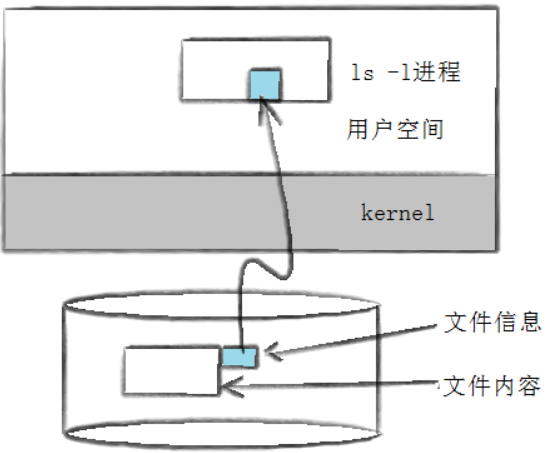
类似上图这个情况。
所以这种文件元属性和数据都存放在硬盘上,而元属性存放的区域就叫做inode,中文名叫做索引节点。
bash
benjiangliu@DESKTOP-IPP4TUH:~$ ls -li
total 8
1762 -rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:40 a.out
5606 -rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:41 test.c每一个文件都存在自己的inode,里面包含了与该文件有关的所有信息,为了解释清楚inode,我们深入了解下Ext文件系统。
4、认识ext2文件系统
1、文件系统组成
1、宏观认识
供存储操作系统数据的磁盘和我们使用的U盘都没有区别,都必须先进行某种格式化才能存储文件,
而格式化的目的其本质是向磁盘写入文件系统。
文件系统的目的就是组织和管理硬盘中的文件。
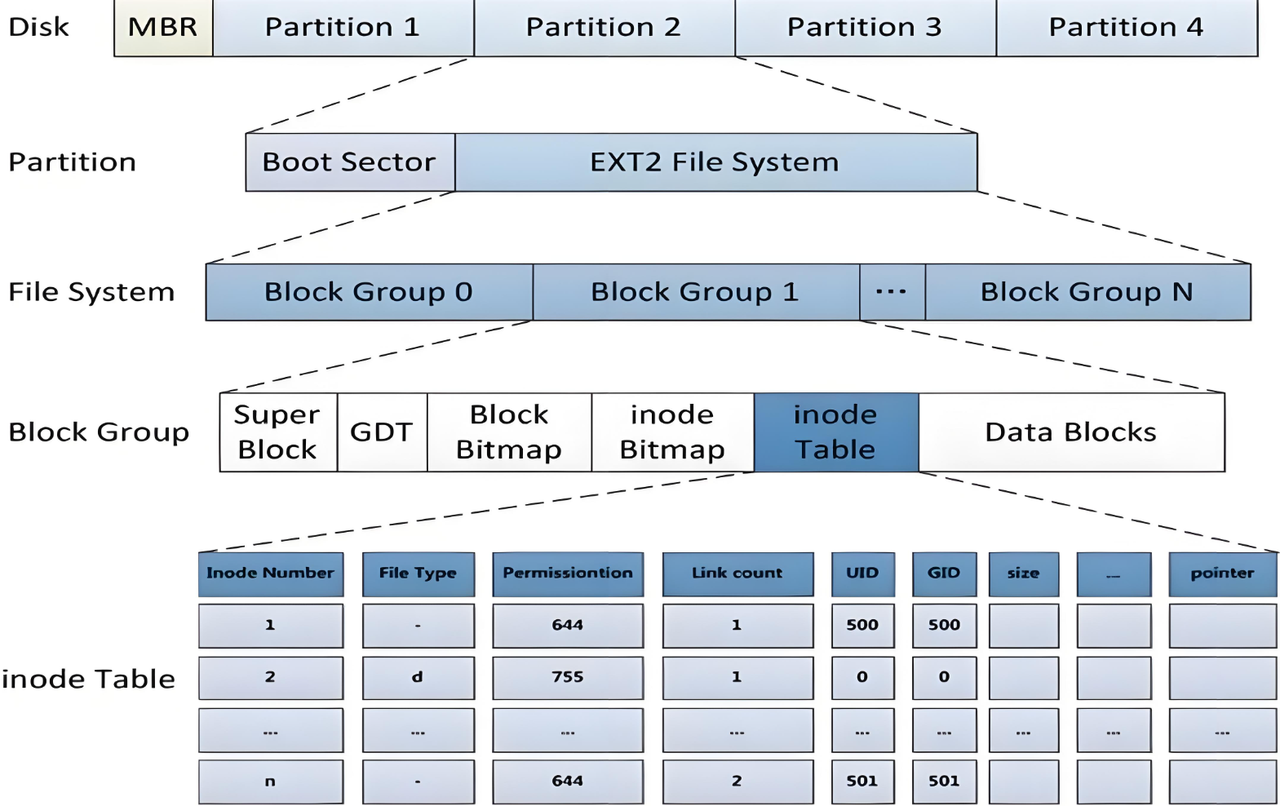
2、磁盘结构
这就是Ext2文件系统的基本组成,我们一层一层看,先看最上层,磁盘最基本的这里有MBR和若干个partition(分区)
MBR(Master Boot Record,主引导记录)想象成整块硬盘的"第一页目录"或者"总索引"。
它位于硬盘最开头的第一个扇区(也就是第 0 号扇区,大小固定为 512 字节)。虽然它非常小,但作用却至关重要,主要干两件大事:
引导系统(Bootloader):当你按下电脑开机键,BIOS/UEFI 会第一时间去读取硬盘的这个 MBR。它里面包含了一小段启动代码,负责告诉电脑:"操作系统装在哪里,该怎么把它加载起来。"
不过需要注意,MBR 是一种比较"古老"的标准,它有几个明显的短板:
容量限制:MBR 最多只支持 2TB 大小的硬盘。如果你插上一块 4TB 的硬盘,用 MBR 模式分区,系统只能认出前 2TB,剩下的空间就浪费了。
分区数量限制:它最多只能记录 4 个主分区。如果你需要更多分区,就得把其中一个主分区改成"扩展分区",再在里面划分逻辑分区,非常麻烦。
记录分区表:它就像一本书的目录,记录着这块硬盘被划分成了几个分区(Partition),以及每个分区的起始位置和结束位置。
正因为 MBR 的这些限制,现在的新电脑和大容量硬盘(超过 2TB)基本都采用更先进的 GPT(GUID 分区表) 模式了。GPT 没有 2TB 的容量限制,支持的分区数量也远远超过 4 个,而且数据安全性更高。
3、分区结构

第二层,具体一个分区
Boot Sector(引导扇区)如果把硬盘比作一本书,MBR 是整本书的"总目录",那么 Boot Sector 就是每一个章节(分区)开头的那一页"章节简介"。Boot Sector 是分区内的第一个扇区。
位置:正如你图片所示,它位于分区的起始位置,紧挨着后面的 EXT2 文件系统数据区。
大小:通常也是 512 字节(或 4K)。
别名:在 Linux 系统中,如果这个分区是用来启动系统的,它也被称为 VBR(Volume Boot Record,卷引导记录)。
虽然它很小,但里面主要装了两样东西:
引导代码:一段小程序。如果这个分区是用来启动系统的(比如你的 Linux 根目录分区),这段代码负责去该分区里找到操作系统的内核文件(如 vmlinuz),并把它加载到内存里运行。
文件系统参数(BPB):因为后续分区内是 EXT2文件系统,那么这个 Boot Sector 里就会记录关于这个 EXT2 分区的重要参数,比如"这个分区有多少个块"、"每个块多大"、"文件系统是什么版本"等。这就像是该分区的"身份证"。
MBR(主引导记录):位于整块硬盘的最开头(第 0 扇区)。它的任务是"找分区"。它负责看分区表,确定哪个分区是"活动的"(Active),然后把控制权交给那个分区的 Boot Sector。
Boot Sector(引导扇区):位于某个具体分区的最开头(如你图中所示)。它的任务是"找系统"。它被 MBR 唤醒后,负责在这个分区里找到操作系统文件并启动它。
4、分区文件系统结构

在某一个具体的分区内,文件系统被分为不同的块组 ,就是从BLOCKx。
按照我们看待windows电脑分区的传统的理解,一个分区被分完以后,就是一个具体的大空间了,直接可以存储文件了,那么为什么还需要分组呢?
这正是 EXT2(以及后来的 EXT3/4)文件系统最精妙的设计,也是它区别于简单文件系统的地方。
简单来说,将分区划分为不同的块组(Block Groups),主要是为了解决"性能"和"数据安全"这两个大问题。
如果不分组,整个分区就是一个巨大的连续空间,这会导致两个严重的问题:
1、想象一下,如果整个分区是一个巨大的仓库,所有的文件数据(比如你的 code.c)和目录信息(比如文件名)都随机散落在仓库的各个角落。
后果:磁头需要满磁盘乱飞来寻找数据,速度会非常慢。
分组的解决方案:
EXT2 将分区切分成很多个独立的"块组"。每个块组都是一个独立的小文件系统,它拥有自己的 Inode 表(存文件属性)和 数据块(存文件内容)。
设计意图:文件系统会尽量把同一个文件的 Inode 和 数据块,或者同一个目录下的文件,放在同一个块组里。
效果:当你读取 code.c 时,磁头只需要在很小的范围内移动,甚至不需要移动,就能把文件属性和内容都读出来。这大大减少了磁头的寻道时间,提高了速度。
2、为了容灾
这个我们后面说
5、块组结构
这个是我们需要核心学的内容,也是ext2文件系统的核心部分。
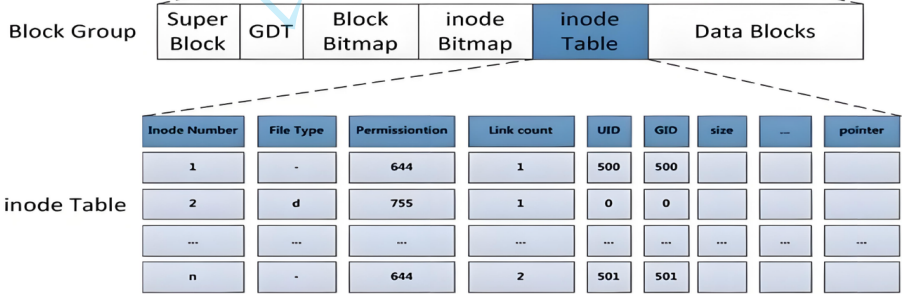
在这之前我想说的是,inode table存储的是文件的inode信息,也就是元属性信息。data blocks中存储的则是文件的数据。这样文件 = 属性 + 文件就闭环了,在这个前提下,我们来看下面的内容。
分组中具体的结构:
1、super block 超级块,其存放文件系统本身的结构信息,描述整个分区的文件系统信息 ,注意是整个分区,不是这个组。
记录的信息有:分区内inode和blocks的重量,未使用的inode和block的数量,一个inode和block的大小,最近一次挂载的时间,最近一次写入数据的时间,如果super block的信息被破坏了,可以说整个文件系统都被破坏了。
超级块存在于第 0 个块组中(主超级块),并且在后续特定的几个块组(而非每一个组)的开头都有备份。不止存在于分区内第一个组中!核心原因就是为了容灾,保证如果磁盘有坏道,第一个分组内超级块的分组内数据丢失了,还能够保证磁盘的数据不会丢失。
2、GDT 块组描述符,描述块组属性的信息,整个分区内分成多少块组就对应多少个块组描述符,每个块组描述符存储一个块组的描述信息,如这个块组中从哪开始存储inode table,从哪是data blocks,空闲的数据块还有多少等。块组描述符在每一个块组的开头都有一个拷贝。
下面就是GDT的结构体
c
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */ 块位图从哪开始
__le32 bg_inode_bitmap; /* Inodes bitmap block */ 块inode位图从哪开始
__le32 bg_inode_table; /* Inodes table block */ inode table从哪开始
__le16 bg_free_blocks_count; /* Free blocks count */ 空闲data block 数量
__le16 bg_free_inodes_count; /* Free inodes count */ 空闲inode数量
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
};3、块位图 block bitmap
记录data block中那个数据块已经被占用,那个数据块没有被占用。
4、inode位图 inode bitmap
每个bit表示一个inode是否空闲可用
5、i 节点表 inode table
存放着文件属性、大小、所有者、最近一次修改信息,就是我们ls -l看到的内容。
是当前分区所有inode信息的集合。
inode编号以分区为单位,整体划分,不可块分区。
换句话说,inode编号和data block块号,不是在整个块组内唯一的,而是在整个分区内唯一的,所以inode和块是可以跨组的,但是不能跨分区。
在一个分区内有多少个inode和数据块都是固定的,是在写入文件系统的时候就分配好的,因为超级块和GDT已经写死了!
在 Linux 的 EXT 文件系统中,Inode 编号是相对的,不是全局的。
分区 A:有自己的 Inode 表。它的第一个 Inode 编号是 1(通常编号 0 保留),第二个是 2......一直到最大值。
分区 B:也有自己的 Inode 表。它的第一个 Inode 编号也是 1,第二个也是 2......
仅凭一个 Inode 编号(比如 100),你无法确定是哪个文件。你必须结合分区信息(比如 /dev/sda1)才能唯一确定一个文件。
文件身份 = 设备号 (分区) + Inode 编号
6、data block
数据区:存放文件内容,也就是一个个block,根据不同的文件类型,有下面几种情况:
对于普通文件,文件的数据存放在数据块中。
对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除去文件名外,ls -l命令看到的其他信息存放在该文件的inode中。
block按照分区划分,不可跨分区。
2、目录和文件名的关系
1、
我们在访问文件,比如cat code.c文件的时候,都是使用的文件名,重来没有使用过inode号,那么目录是文件吗?
在之前介绍data block,就说过了:
如果inode信息指向的是普通文件的时候,那么data block中存储的就是文件内容
如果inode信息指向的是目录的时候,那么data block中存储的是文件名和inode号的映射关系!
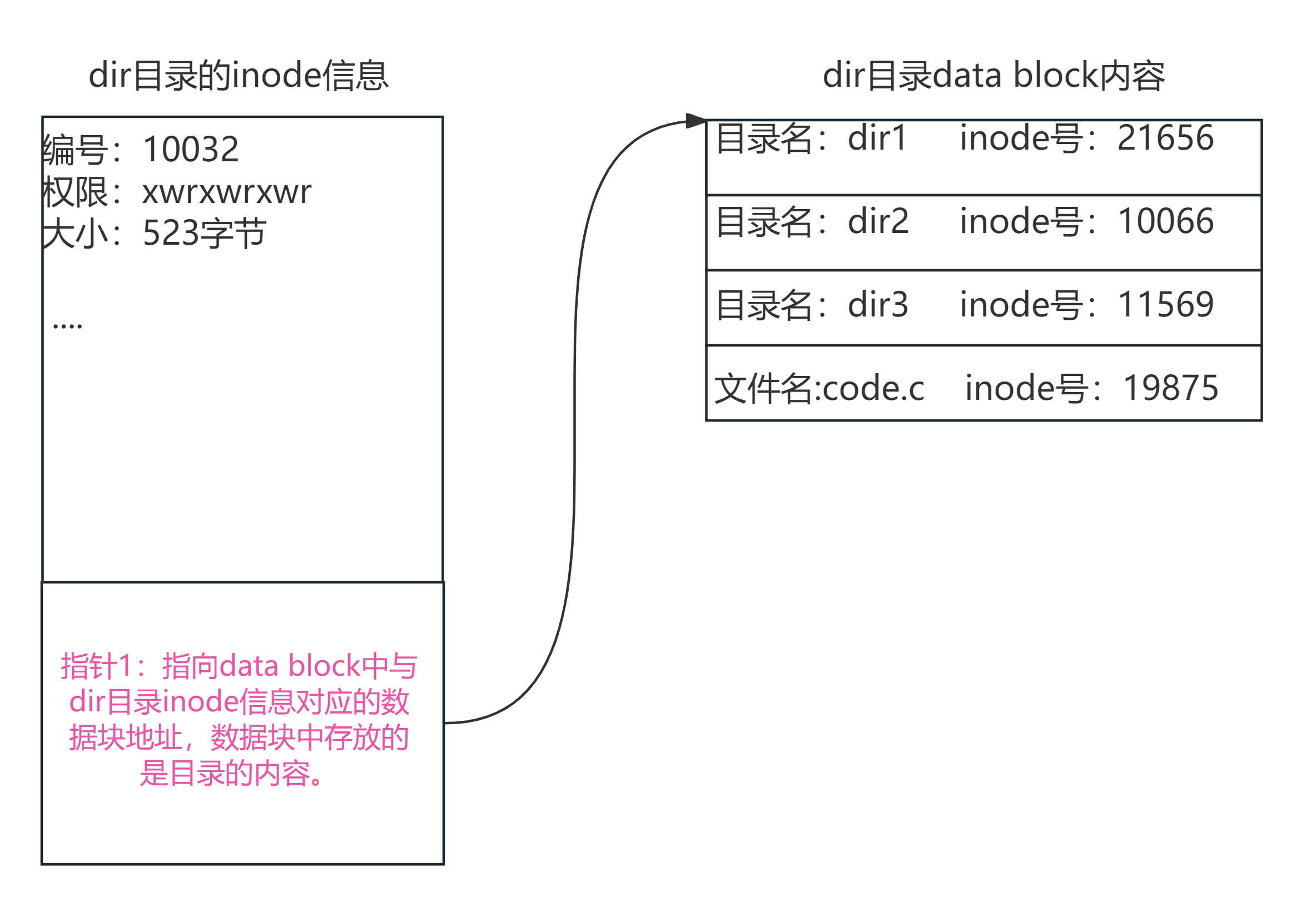
从上图中我们可以看出在目录dir的inode信息中有一个指针,指向了dir文件在data block中的地址,我们查看data block中发现了原来目录文件的内容是这个目录中下一级的存在的目录和文件名字,以及这个目录或者文件的inode信息。
换句话说在 EXT2 中,目录文件的数据块里,其实就是一张列表。每一行(我们称为目录项)只包含两个核心要素:
文件名:比如 code.c(这是给人看的)。
Inode 编号:比如 19875(这是给机器用的索引)。
bash
benjiangliu@DESKTOP-IPP4TUH:~$ tree dir
dir
├── code.c # inode号 19875
├── dir1 # inode号 21656
├── dir2 # inode号 10066
└── dir3 # inode号 11569整个查找过程(比如我们要找 dir/code.c)是这样的:
第一步(查目录文件):
系统读取 dir 目录的 Inode(编号 10032)。
根据 Inode 里的指针,找到 dir 的 数据块。
在数据块里遍历查找,发现了:"哦,code.c 对应的 Inode 编号是 19875。"
第二步(查 Inode 表):
系统拿着编号 19875,去分区的 Inode 表 中找到第 19875 号格子。
读取里面的详细信息(权限、大小、以及指向数据块的指针)。
第三步(读数据):
根据 Inode 19875 里的指针,去 数据区 读取 code.c 的真正内容。
所以我们得到结论,在文件系统中,存储目录和普通文件是没有区别的,都是inode+data block。
2、
这里需要解释在之前说权限没有说明白的内容:
1、为什么没有r权限无法在目录内部使用ls命令查看目录内容?
bash
benjiangliu@DESKTOP-IPP4TUH:~$ chmod u-r dir # 给拥有者删除dir目录的r权限
benjiangliu@DESKTOP-IPP4TUH:~$ ls -l
total 12
-rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:40 a.out
d-wxr-xr-x 5 benjiangliu benjiangliu 4096 May 23 12:35 dir
-rw-r--r-- 1 benjiangliu benjiangliu 12 May 23 10:41 test.c
# 发现依然可以ls 当前所在目录的内容,因为在未进入dir文件夹之前,我们ls查看的是上级目录的data block中的文件名和inode的映射信息
benjiangliu@DESKTOP-IPP4TUH:~$ cd dir # 进入dir目录
benjiangliu@DESKTOP-IPP4TUH:~/dir$ ls -al
ls: cannot open directory '.': Permission denied # 发现无法使用ls命令查看目录的内容
# 因为我们删除了dir目录的r权限,也就是说无法读取dir目录的data block中的文件名和inode的映射信息
# 所以导致了我们无法查看映射信息,也就无法查看目录的内容了2、为什么没有目录的r权限却可以在目录内新建文件?
bash
benjiangliu@DESKTOP-IPP4TUH:~/dir$ touch newfile # 在dir目录下新建文件newfile
benjiangliu@DESKTOP-IPP4TUH:~/dir$ ls -al
ls: cannot open directory '.': Permission denied
# 虽然我们没有r权限,但是我们有w权限,依然可以向目录的data block中写映射表,所以我们能新建文件3、为什么没有目录的r权限却可以进入目录的二级目录?
bash
benjiangliu@DESKTOP-IPP4TUH:~/dir$ cd dir1
# 注意,我们没有dir目录的权限,依然进入了dir目录的二级目录dir1 !
benjiangliu@DESKTOP-IPP4TUH:~/dir/dir1$ pwd
/home/benjiangliu/dir/dir1
# 为什么我们dir目录的r权限,无法读取dir读取目录的data block中的映射表,为什么还能进入目录中的下级目录dir1?
# 核心原因,虽然用户我没有dir目录的r权限,但是我有dir目录的x权限
# 目录的 x 权限:控制我能否根据文件名查找 Inode(即能否"穿越"这个目录去访问下面的文件)。
# 而访问下级目录或者文件,是OS帮你实现的,而不是没有r权限的用户!!!r 权限是用来"看"(ls列出文件名)的。
x 权限是用来"过"(根据文件名查找 Inode 并进入)的。
只要你知道下级目录的名字,并且有 x 权限,内核就能帮你找到它,而不需要你拥有 r 权限去把整个目录列表看一遍。
写一段代码,输出当前目录的data block内容
c
#include <stdio.h>
#include <dirent.h>
#include <sys/types.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory_path>\n", argv[0]);
return 1;
}
const char *dir_path = argv[1];
DIR *dir = opendir(dir_path);
if (dir == NULL) {
perror("opendir");
return 1;
}
printf("Contents of directory '%s':\n", dir_path);
printf("%-20s %s\n", "Inode", "Filename");
printf("-------------------- --------------------\n");
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) {
// d_ino: inode number, d_name: filename
printf("%-20lu %s\n", (unsigned long)entry->d_ino, entry->d_name);
}
closedir(dir);
return 0;
}运行代码
bash
benjiangliu@DESKTOP-IPP4TUH:~/dir$ gcc code.c -o list_dir
benjiangliu@DESKTOP-IPP4TUH:~/dir$ ll
total 56
drwxr-xr-x 5 benjiangliu benjiangliu 4096 May 23 17:09 ./
drwxr-x--- 6 benjiangliu benjiangliu 4096 May 23 17:08 ../
-rw-r--r-- 1 benjiangliu benjiangliu 986 May 23 17:08 code.c
drwxr-xr-x 2 benjiangliu benjiangliu 4096 May 23 12:35 dir1/
drwxr-xr-x 2 benjiangliu benjiangliu 4096 May 23 12:35 dir2/
drwxr-xr-x 2 benjiangliu benjiangliu 4096 May 23 12:35 dir3/
-rwxr-xr-x 1 benjiangliu benjiangliu 16248 May 23 17:09 list_dir* # 可执行文件在这
-rw-r--r-- 1 benjiangliu benjiangliu 0 May 23 12:48 newfile
benjiangliu@DESKTOP-IPP4TUH:~/dir$ ./list_dir .
Contents of directory '.':
Inode Filename
-------------------- --------------------
6872 list_dir
2417 code.c
6541 dir1
477 ..
602 newfile
6561 dir3
5817 .
6556 dir2
# 此处输出了文件信息所以我们得到结论
1、访问文件,必须打开文件当前目录,根据文件名,获取当前文件的inode信息,然后进行文件访问
2、访问文件必须要知道当前目录的工作目录,本质是必须能够打开当前工作目录文件,查看目录文件内容