构建完整的实时数据分析管道,实现点击流数据的实时采集、处理和可视化,涵盖 Schema Registry 原理、Flink 时间窗口机制等。
总体架构如下
存储&可视化
流处理
消息队列
数据生产
Avro
Schema
Consumer Group
RPC
Deserialize
Bulk Index
Visualize
Java Producer
Avro 序列化
Kafka 3.9.0
KRaft 模式
Schema Registry
Confluent 7.4.4
Flink 1.20
JobManager
Flink 1.20
TaskManager
OpenSearch 2.19
Dashboards
核心数据流实现了自动注册schema registry并生产和消费avro数据
OpenSearch Flink Schema Registry Kafka Producer OpenSearch Flink Schema Registry Kafka Producer 注册 Schema Schema ID 发送 Avro 消息 Consumer 拉取 获取 Schema 反序列化 Session Window 聚合 Tumbling Window 聚合 Bulk Index 写入
生产和消费者参考官方示例仓库开源项目源码
bash
# Producer:模拟电商用户点击行为
git clone https://github.com/aws-samples/clickstream-producer-for-apache-kafka.git
# Flink Processor:流处理聚合逻辑
git clone https://github.com/aws-samples/flink-clickstream-processor-msk.gitSchema Registry 原理详解
Schema Registry 是 Kafka 生态系统中的元数据管理服务,提供 RESTful 接口存储和检索 Avro、JSON Schema、Protobuf 等数据格式的 Schema 定义。
核心角色功能如下图所示
Consumer端
SchemaRegistry
Producer端
否
是
Java/Python应用
KafkaAvroSerializer
Schema已注册?
注册新Schema
获取Schema ID
_schemas Topic Kafka存储
REST API:8081
Schema ID映射表
KafkaAvroDeserializer
提取Schema ID
获取Schema定义
反序列化数据
Schema Registry 使用 Kafka 作为底层存储,特殊的 Topic _schemas 作为高可用的预写日志(Write-Ahead Log)。存储内容如下
Key: <subject-name>
Value: {
"subject": "ExampleTopic-value",
"version": 1,
"id": 2,
"schema": "{\"type\":\"record\",\"name\":\"ClickEvent\"...}"
}Magic Byte 与消息编码格式
Confluent Schema Registry 定义了标准的消息编码格式,每条 Avro 消息前缀 5 字节元数据:
字节布局:
┌────────┬────────────────────────┬─────────────────────────┐
│ Byte 0 │ Bytes 1-4 │ Bytes 5+ │
│ Magic │ Schema ID │ Avro Serialized Data │
│ 0x00 │ (4-byte int) │ (variable length) │
└────────┴────────────────────────┴─────────────────────────┘
示例消息解析:
原始数据: 00 00 00 00 02 1866.249.1.114...
│ └──────┘ └─────────────────
│ │ └── Avro 编码的 ClickEvent
│ └── Schema ID = 2
└── Magic Byte (版本号)Magic Byte (0x00) 的作用:
- 格式标识:标识这是 Confluent Schema Registry 的序列化格式
- 版本预留:当前版本为 0,为未来格式变更预留空间
- 向后兼容承诺:Confluent 保证在同一 magic byte 版本内,格式不会以向后不兼容的方式变更
当 Flink Consumer 尝试反序列化非 Avro 格式的消息(如 echo "test" | kafka-console-producer 发送的纯文本),会触发 Unknown data format 错误:
java.io.IOException: Failed to deserialize consumer record
Caused by: java.io.IOException: Unknown data format. Magic number does not match这是因为 Consumer 期望第一个字节是 0x00,但实际收到的是 ASCII 字符(如 t = 0x74)。
Schema Evolution
Schema Registry 支持 Schema 演进(Schema Evolution),允许 Producer 和 Consumer 独立升级数据格式。
兼容性模式:
| 模式 | 定义 | 允许操作 | 适用场景 |
|---|---|---|---|
BACKWARD |
新 Schema 可读旧数据 | 添加可选字段、删除字段 | 消费者先升级 |
FORWARD |
旧 Schema 可读新数据 | 添加有默认值字段 | 生产者先升级 |
FULL |
双向兼容 | 添加可选字段、删除字段 | 独立升级 |
NONE |
无检查 | 任意修改 | 开发环境 |
更详细内容可参考https://www.cnblogs.com/peacemaple/p/20017661的兼容性模式部分解释
序列化与反序列化
Producer 端序列化
java
// KafkaProducerFactory.java - 配置 Avro 序列化器
producerProps.setProperty(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"io.confluent.kafka.serializers.KafkaAvroSerializer"
);
// 去哪里找 Avro 的 Schema 注册中心(Schema Registry)
producerProps.setProperty(
AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://localhost:8081"
);序列化内部流程,生产者发送 Avro 格式消息时,会自动把数据结构(Schema)注册到Schema Registry,同时从这里获取 Schema 来序列化数据。
Kafka Broker Schema Registry KafkaAvroSerializer 应用程序 Kafka Broker Schema Registry KafkaAvroSerializer 应用程序 alt Schema ID 未缓存 send(topic, ClickEvent object) 检查本地缓存 POST /subjects/{topic}-value/versions 兼容性检查 Schema ID (e.g., 2) 缓存 ID Avro 序列化数据 添加前缀 0x00, Schema ID 发送字节数组
Consumer 端反序列化,反序列化内部流程:
- 读取消息前 5 字节
- byte0 = 0x00 (magic byte)
- byte1-4 = Schema ID (big-endian int)
- 向 Schema Registry 请求 Schema 定义
- 使用 Avro 解码剩余字节
java
// Flink KafkaSource 配置
KafkaSource<ClickEvent> source = KafkaSource.<ClickEvent>builder()
.setValueOnlyDeserializer(new KafkaAvroDeserializer<>(ClickEvent.class, schemaRegistryUrl))
.build();实际使用示例Schema 定义(ClickEvent.avsc)
json
{
"namespace": "samples.clickstream.avro",
"type": "record",
"name": "ClickEvent",
"fields": [
{"name": "ip", "type": "string"},
{"name": "eventtimestamp", "type": "long"},
{"name": "devicetype", "type": "string"},
{"name": "event_type", "type": ["string", "null"]},
{"name": "product_type", "type": ["string", "null"]},
{"name": "userid", "type": "int"},
{"name": "globalseq", "type": "long"},
{"name": "prevglobalseq", "type": "long", "default": 0}
]
}Schema 注册验证
bash
# 查看已注册的 Schema
curl http://localhost:8081/subjects
# ["ExampleTopic-key", "ExampleTopic-value"]
# 获取 Schema 详情
curl http://localhost:8081/subjects/ExampleTopic-value/versions/latest
{
"type": "record",
"name": "ClickEvent",
"namespace": "samples.clickstream.avro",
"fields": [
{
"name": "ip",
"type": "string"
},
{
"name": "eventtimestamp",
"type": "long"
},
{
"name": "devicetype",
"type": "string"
},
{
"name": "event_type",
"type": ["string", "null"]
},
{
"name": "product_type",
"type": ["string", "null"]
},
{
"name": "userid",
"type": "int"
},
{
"name": "globalseq",
"type": "long"
},
{
"name": "prevglobalseq",
"type": "long",
"default": 0
}
]
}Docker Compose 配置
Producer 在宿主机运行时,Kafka 返回 kafka:9092 作为 broker 地址,导致宿主机无法解析容器主机名。
org.apache.kafka.common.errors.TimeoutException
Failed to send record to Kafka after 5 retries
No data format. Magic number does not matchKafka 的 ADVERTISED_LISTENERS 配置决定了 broker 向客户端返回的连接地址。当 Producer 从宿主机连接时:
- 客户端先连接
localhost:9092 - Broker 返回
PLAINTEXT://kafka:9092 - 客户端尝试连接
kafka:9092,但宿主机无法解析
通过配置双 Listener来解决
yaml
# docker-compose.yml - Kafka 服务配置
kafka:
image: apache/kafka:3.9.0
ports:
- "9092:9094" # 宿主机 9092 映射到容器 9094
environment:
# INTERNAL: 容器间通信
# EXTERNAL: 宿主机访问
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,EXTERNAL://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT注意事项:
PLAINTEXTlistener 用于容器内部通信(Schema Registry、Flink)EXTERNALlistener 用于宿主机 Producer 访问- 端口映射要对应:宿主机 9092 映射到 容器 9094
- Schema Registry 和 Flink 仍使用
kafka:9092
完整 Docker Compose 文件如下
yaml
services:
# Kafka
kafka:
image: apache/kafka:3.9.0
container_name: kafka
hostname: kafka
ports:
- "9092:9094"
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,EXTERNAL://localhost:9092
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk"
healthcheck:
test: ["CMD-SHELL", "opt/kafka/bin/kafka-broker-api-versions.sh --bootstrap-server localhost:9092"]
interval: 10s
timeout: 10s
retries: 5
# Schema Registry
schema-registry:
image: confluentinc/cp-schema-registry:7.4.4
depends_on:
kafka:
condition: service_healthy
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: kafka:9092 # 使用内部 listener
# Flink JobManager
flink-jobmanager:
image: flink:1.20-java17
ports:
- "8082:8081"
command: jobmanager
environment:
FLINK_PROPERTIES: |
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 4
volumes:
- ./flink-jobs:/opt/flink/usrlib
# Flink TaskManager
flink-taskmanager:
image: flink:1.20-java17
depends_on:
flink-jobmanager:
condition: service_healthy
command: taskmanager
environment:
FLINK_PROPERTIES: |
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 4
# OpenSearch
opensearch:
image: opensearchproject/opensearch:2.19.1
ports:
- "9200:9200"
environment:
discovery.type: single-node
DISABLE_SECURITY_PLUGIN: "true" # 简化本地开发
# OpenSearch Dashboards
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:2.19.1
ports:
- "5601:5601"
environment:
OPENSEARCH_HOSTS: '["http://opensearch:9200"]'
DISABLE_SECURITY_DASHBOARDS_PLUGIN: "true"Producer 改造
配置 Confluent Schema Registry 依赖,项目使用 Confluent Schema Registry 进行 Avro 序列化。
将kafka-avro-serializer替换为 Confluent
xml
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>7.4.4</version>
</dependency>Avro Schema 定义
json
{
"type": "record",
"name": "ClickEvent",
"namespace": "samples.clickstream.avro",
"fields": [
{"name": "ip", "type": "string"},
{"name": "eventtimestamp", "type": "long"},
{"name": "devicetype", "type": "string"},
{"name": "event_type", "type": ["string", "null"]},
{"name": "product_type", "type": ["string", "null"]},
{"name": "userid", "type": "int"},
{"name": "globalseq", "type": "long"},
{"name": "prevglobalseq", "type": "long", "default": 0}
]
}用户行为模拟逻辑
Producer 模拟电商用户会话的马尔可夫链状态转移,模拟真实用户的浏览和购买行为:
用户进入
浏览目录
查看商品
加入购物车
下单
结账
完成购买
取消商品
继续浏览
home_page
product_catalog
product_detail
add_to_cart
order
order_checkout
remove_from_cart
状态转移实现代码
java
// Events.java - 核心事件生成逻辑
class Events {
// 设备类型池
private static final String[] deviceType = {"mobile", "computer", "tablet"};
// 产品类型池
private static final String[] productTypeOptions = {
"cell phones", "laptops", "ear phones", "soundbars",
"cd players", "AirPods", "video games", "cameras"
};
/**
* 生成单个用户的事件序列
* @param kafkaProducer Kafka 生产者
* @param userID 用户 ID
*/
void genEvents(Producer<String, ClickEvent> kafkaProducer, Integer userID) {
String userDeviceType = deviceType[rand.nextInt(deviceType.length)];
String userIP = "66.249.1." + rand.nextInt(255);
String previousEventType = null;
String previousProductType = null;
// 循环生成事件,直到事件类型为空(会话结束)
do {
ClickEvent event = genUserEvent(
userID, userDeviceType, previousEventType,
previousProductType, userIP, previousGlobalSeqNo
);
previousEventType = event.getEventType().toString();
previousProductType = event.getProductType().toString();
previousGlobalSeqNo = event.getGlobalseq();
// 发送到 Kafka
kafkaProducer.send(
new ProducerRecord<>(topic, userID.toString(), event),
(metadata, e) -> {
if (e != null) {
logger.error("发送失败", e);
errorCount.incrementAndGet();
} else {
eventCount.incrementAndGet();
}
}
);
} while (!event.getEventType().toString().equals("") && errorCount.get() < 1);
}
/**
* 根据当前状态生成下一个事件
*/
private ClickEvent genUserEvent(Integer userId, String userDeviceType,
String previousEventType, String previousProductType,
String userIP, Long previousGlobalSeqNo) {
String eventType;
String productType;
if (previousEventType == null) {
// 首个事件:首页
eventType = "home_page";
productType = "N/A";
} else {
// 根据上一事件类型确定下一事件
eventType = nextEventType(previousEventType);
productType = nextProductType(previousProductType, eventType);
}
return ClickEvent.newBuilder()
.setIp(userIP)
.setEventtimestamp(System.currentTimeMillis())
.setDevicetype(userDeviceType)
.setEventType(eventType.isEmpty() ? null : eventType)
.setProductType(productType.equals("N/A") ? null : productType)
.setUserid(userId)
.setGlobalseq(counter.incrementAndGet())
.setPrevglobalseq(previousGlobalSeqNo)
.build();
}
/**
* 状态转移逻辑:马尔可夫链
*/
private String nextEventType(String previousEventType) {
switch (previousEventType) {
case "home_page":
return rand.nextBoolean() ? "product_catalog" : "";
case "product_catalog":
return rand.nextBoolean() ? "product_detail" : "home_page";
case "product_detail":
double r = rand.nextDouble();
if (r < 0.3) return "add_to_cart";
if (r < 0.6) return "product_catalog";
return "";
case "add_to_cart":
return rand.nextBoolean() ? "order" : "remove_from_cart";
case "remove_from_cart":
return rand.nextBoolean() ? "product_catalog" : "";
case "order":
return rand.nextBoolean() ? "order_checkout" : "";
case "order_checkout":
return ""; // 购买完成,会话结束
default:
return "";
}
}
}该方法实现了一个有限状态机(FSM),模拟真实用户的电商购物行为路径。核心思想:
返回空字符串 "" = 会话结束(用户离开或购买完成)
返回事件名称 = 继续生成下一个事件逐状态解析规则
- 每个用户会话生成多条事件,形成完整的购买链路
- 会话结束条件:
eventType为空字符串或发送出错 - 全局序列号 (
globalseq) 保证事件顺序唯一性 - 时间戳使用
System.currentTimeMillis()模拟事件时间
| 事件类型 | 含义 | 概率转移 |
|---|---|---|
home_page |
首页 | 50% → product_catalog, 50% → 结束 |
product_catalog |
浏览目录 | 50% → product_detail, 50% → home_page |
product_detail |
商品详情 | 30% → add_to_cart, 30% → product_catalog, 40% → 结束 |
add_to_cart |
加入购物车 | 50% → order, 50% → remove_from_cart |
remove_from_cart |
移出购物车 | 50% → product_catalog, 50% → 结束 |
order |
下单 | 50% → order_checkout, 50% → 结束 |
order_checkout |
结账 | 100% → 结束(购买完成) |
Flink Processor
从 Flink 1.8.2 升级到 1.20.1,KafkaSource 配置如下
java
// ClickstreamProcessor.java
KafkaSource<ClickEvent> source = KafkaSource.<ClickEvent>builder()
.setBootstrapServers("kafka:9092")
.setTopics("ExampleTopic")
.setGroupId("flink-clickstream-processor")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new KafkaAvroDeserializer<>(ClickEvent.class, schemaRegistryUrl))
.build();
DataStream<ClickEvent> events = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka-source");出现Jackson 版本冲突问题,StreamWriteConstraints 类从 Jackson 2.15.0 开始引入。OpenSearch Sink 和 Flink 内部使用的 Jackson 版本冲突:
java.io.IOException: Failed to deserialize consumer record
Caused by: java.lang.NoClassDefFoundError: com/fasterxml/jackson/core/StreamWriteConstraints$Defaults在 pom.xml 强制指定 Jackson BOM
xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.fasterxml.jackson</groupId>
<artifactId>jackson-bom</artifactId>
<version>2.15.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- 显式声明版本 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.15.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
</dependencies>时间窗口聚合
Flink 的窗口机制是流处理的核心概念,用于在无界数据流上定义有限的数据集进行计算。
窗口类型对比
会话窗口 Session
gap
gap
事件1-3
事件4-6
事件7
滑动窗口 Sliding
0-10s
5-15s
10-20s
滚动窗口 Tumbling
0-10s
10-20s
20-30s
| 窗口类型 | 特点 | 适用场景 | 本项目应用 |
|---|---|---|---|
| Tumbling | 固定大小、不重叠 | 定时统计 | 部门点击计数(10s) |
| Sliding | 固定大小、可重叠 | 移动平均 | 未使用 |
| Session | 动态大小、按活动分组 | 用户行为分析 | 用户会话(1s gap) |
事件时间语义示意图如下,具体请参考https://www.cnblogs.com/peacemaple/p/20128616
OpenSearch Sink Window Operator WatermarkGenerator Kafka Source OpenSearch Sink Window Operator WatermarkGenerator Kafka Source Watermark 用于处理迟到数据 alt 事件时间 \> Watermark 事件时间 \<= Watermark 提取 eventtimestamp 更新最大时间戳 计算 Watermark = max - lateness 正常处理,进入窗口 迟到数据,丢弃或侧输出 等待 Watermark 超过窗口结束 触发窗口计算,输出结果
窗口触发机制如下
java
// 1. Session Window: 用户会话聚合
events
.keyBy(ClickEvent::getUserid) // 按 userId 分组
.window(EventTimeSessionWindows.withGap(Time.seconds(1)))
// gap = 1s: 如果连续两个事件间隔超过 1 秒,视为新会话
.process(new SessionAggregator());
// 2. Tumbling Window: 部门点击统计
events
.keyBy(e -> e.getProductType()) // 按产品类型分组
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 每 10 秒一个窗口,窗口之间不重叠
.aggregate(new DepartmentAggregator());Watermark 策略
java
// WatermarkStrategy 配置
WatermarkStrategy<ClickEvent> watermarkStrategy = WatermarkStrategy
.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 允许 2 秒迟到
.withTimestampAssigner((event, timestamp) -> event.getEventtimestamp())
.withIdleness(Duration.ofSeconds(10)); // 空闲超时
DataStream<ClickEvent> events = env
.fromSource(kafkaSource, watermarkStrategy, "kafka-source");OpenSearch Sink
示例如下:
- OpenSearch 2.x client 使用 Request objects(
IndexRequest),不同于 ES 7.x 的IndexRequest类 DISABLE_SECURITY_PLUGIN=true简化本地开发,生产环境需要配置认证- Bulk flush 参数影响延迟和吞吐量
java
OpenSearchSink<String> opensearchSink = OpenSearchSink.<String>builder()
.setHosts("http://opensearch:9200")
.setConnectionUsername("")
.setConnectionPassword("")
.setBulkFlushMaxActions(100)
.setBulkFlushInterval(5000)
.setEmitter((element, context, indexer) -> {
indexer.add(
IndexRequest.of(ir -> ir.index("user_session_details").document(element))
);
})
.build();启动与验证
启动所有服务
docker-compose up -d创建 Kafka Topics
docker exec kafka /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--create --topic ExampleTopic --partitions 3 --replication-factor 1创建索引映射
bash
# user_session_details - 用户会话详情
curl -X PUT "http://localhost:9200/user_session_details" -H 'Content-Type: application/json' -d '{
"mappings": {
"properties": {
"userId": {"type": "integer"},
"eventCount": {"type": "integer"},
"orderCheckoutEventCount": {"type": "integer"},
"deptList": {"type": "keyword"},
"windowBeginTime": {"type": "date"},
"windowEndTime": {"type": "date"}
}
}
}'
# departments_count - 部门点击统计
curl -X PUT "http://localhost:9200/departments_count" -H 'Content-Type: application/json' -d '{
"mappings": {
"properties": {
"departmentName": {"type": "keyword"},
"departmentCount": {"type": "integer"},
"windowBeginTime": {"type": "date"},
"windowEndTime": {"type": "date"}
}
}
}'
# user_session_counts - 会话汇总统计
curl -X PUT "http://localhost:9200/user_session_counts" -H 'Content-Type: application/json' -d '{
"mappings": {
"properties": {
"userSessionCount": {"type": "integer"},
"userSessionCountWithOrderCheckout": {"type": "integer"},
"percentSessionswithBuy": {"type": "float"},
"windowBeginTime": {"type": "date"},
"windowEndTime": {"type": "date"}
}
}
}'上传 Flink JAR
curl -X POST -F "jarfile=@flink-jobs/ClickstreamProcessor-1.0-SNAPSHOT.jar" \
http://localhost:8082/jars/upload提交 Flink Job
curl -X POST "http://localhost:8082/jars/<jar-id>/run"查看运行状态
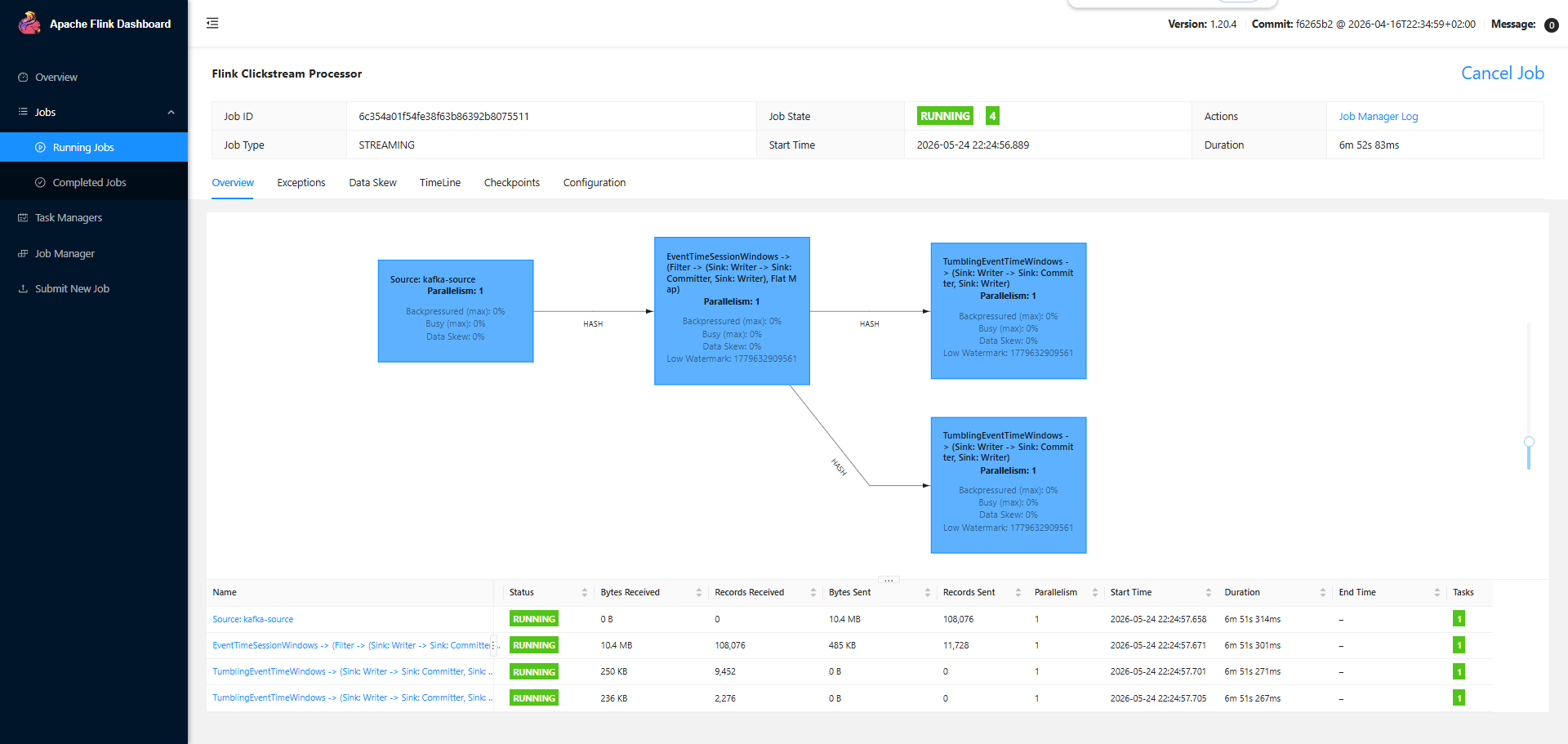
启动 Producer
shell
java -jar KafkaClickstreamClient-1.0-SNAPSHOT.jar \
--propertiesFilePath producer.properties \
--numThreads 4 --numberOfUsers 100 --runFor 120 --noDelay验证数据流
bash
# 1. Schema Registry - 确认 Schema 已注册
curl http://localhost:8081/subjects | jq '.'
# 预期输出: ["ExampleTopic-key", "ExampleTopic-value"]
# 2. Kafka - 确认消息存在(Avro 格式)
docker exec kafka /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic ExampleTopic --from-beginning --max-messages 1
# 预期输出: 乱码(Avro 二进制),说明数据存在
# 3. Flink Consumer Group - 确认消费完成
docker exec kafka /opt/kafka/bin/kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--describe --group flink-clickstream-processor
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
flink-clickstream-processor ExampleTopic 0 83550 83550 0 - - -
flink-clickstream-processor ExampleTopic 2 87172 87172 0 - - -
flink-clickstream-processor ExampleTopic 1 86511 86511 0 - - -
# 4. OpenSearch - 确认数据写入
curl http://localhost:9200/user_session_details/_count | jq '.count'
curl http://localhost:9200/departments_count/_count | jq '.count'
curl http://localhost:9200/user_session_counts/_count | jq '.count'Dashboards 可视化
OpenSearch Dashboards 需要先创建索引模式才能对数据进行可视化分析。
bash
# 创建 user_session_details 索引模式
curl -X POST "http://localhost:5601/api/saved_objects/index-pattern" \
-H "Content-Type: application/json" \
-H "osd-xsrf: true" \
-d '{
"attributes": {
"title": "user_session_details",
"timeFieldName": "windowBeginTime"
}
}'
# 创建 departments_count 索引模式
curl -X POST "http://localhost:5601/api/saved_objects/index-pattern" \
-H "Content-Type: application/json" \
-H "osd-xsrf: true" \
-d '{
"attributes": {
"title": "departments_count",
"timeFieldName": "windowBeginTime"
}
}'
# 创建 user_session_counts 索引模式
curl -X POST "http://localhost:5601/api/saved_objects/index-pattern" \
-H "Content-Type: application/json" \
-H "osd-xsrf: true" \
-d '{
"attributes": {
"title": "user_session_counts",
"timeFieldName": "windowBeginTime"
}
}'验证索引模式创建成功
bash
# 列出所有索引模式
curl -s "http://localhost:5601/api/saved_objects/_find?type=index-pattern" | jq '.saved_objects[].attributes.title'
# 预期输出:
# "user_session_details"
# "departments_count"
# "user_session_counts"创建可视化图表
打开 Visualize 界面,左侧菜单点击 Visualize → Create visualization
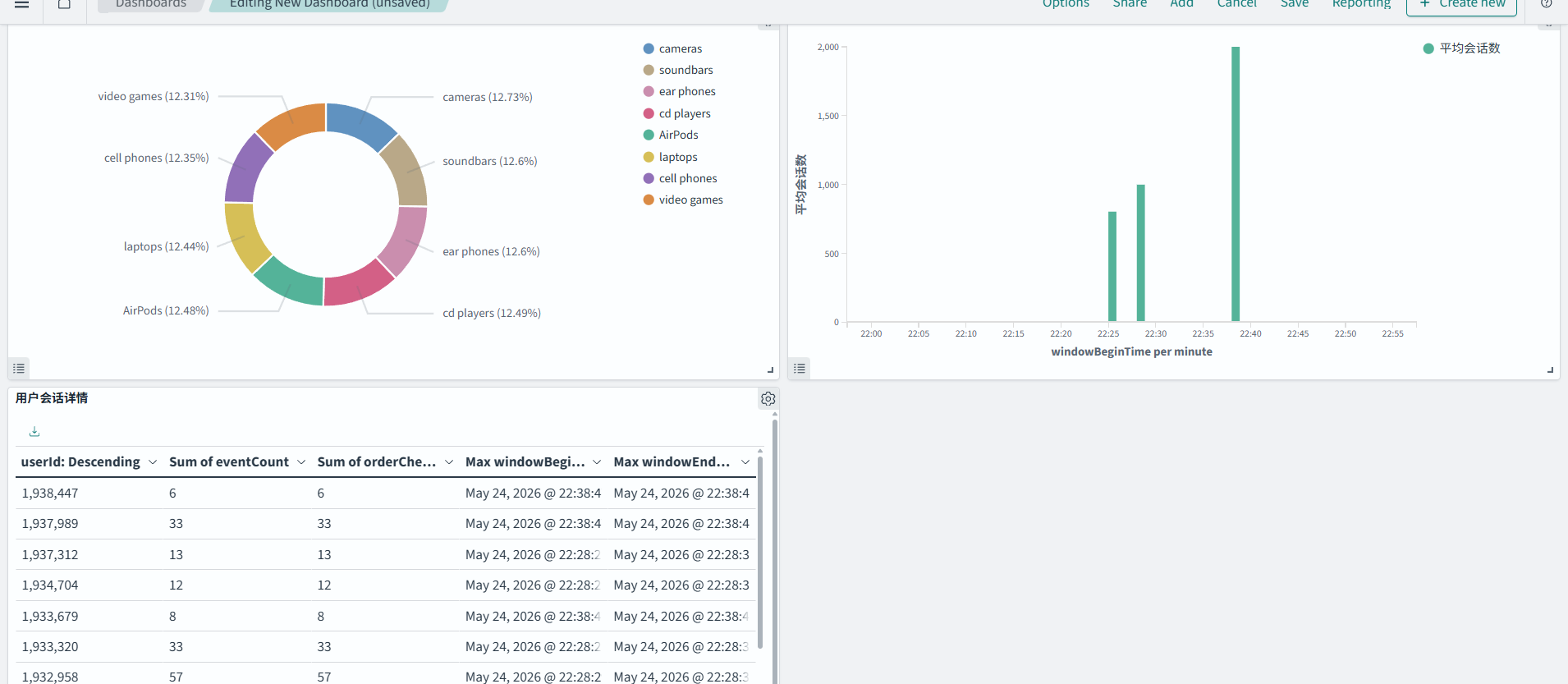
部门点击分布饼图
- 选择 "Pie" 图表类型
- 选择索引模式: departments_count
- 配置 Metrics(指标):
- Aggregation: Count(默认,统计文档数量)
- 或选择 Sum,Field: departmentCount(统计总点击数)
- 配置 Buckets(分桶)- 点击 "Add" 添加:
- Split Slices
- Aggregation: Terms
- Field: departmentName(现在应该在下拉列表中可见)
- Order By: Metric: Count
- Order: Descending
- Size: 10
- 点击右上角 "Update" 预览图表
- 点击 "Save" 保存为 "部门点击分布"
用户会话统计柱状图
配置步骤:
- 选择 "Vertical Bar" 图表类型
- 选择索引模式: user_session_counts
- 配置 Metrics(指标):
- Y-axis
- Aggregation: Average(平均值)
- Field: userSessionCount
- Custom label: "平均会话数"
- 配置 Buckets(分桶)- 点击 "Add" 添加:
- X-axis
- Aggregation: Date Histogram
- Field: windowBeginTime
- Interval: Auto(或手动选择如 1 hour)
- 点击 "Update" 预览
- 保存为 "用户会话趋势"
用户会话详情表格
配置步骤:
- 选择 "Data Table" 图表类型
- 选择索引模式: user_session_details
- 配置 Metrics(指标):
- Aggregation: Count(默认)
- 配置 Buckets(分桶)- 点击 "Add" 添加:
- Split Rows
- Aggregation: Terms
- Field: userId
- Order By: Metric: Count
- Order: Descending
- Size: 100
- 如果需要显示更多列,可以添加多个 Metrics:
- 点击 Metrics 下方 "Add Metric"
- Aggregation: Average
- Field: eventCount
- 点击 "Update" 预览表格
- 保存为 "用户会话详情"
最终效果如下