数据与模型投毒
- 资料来源:
genai.owasp.org - 资料整理:韦胖
是什么意思?
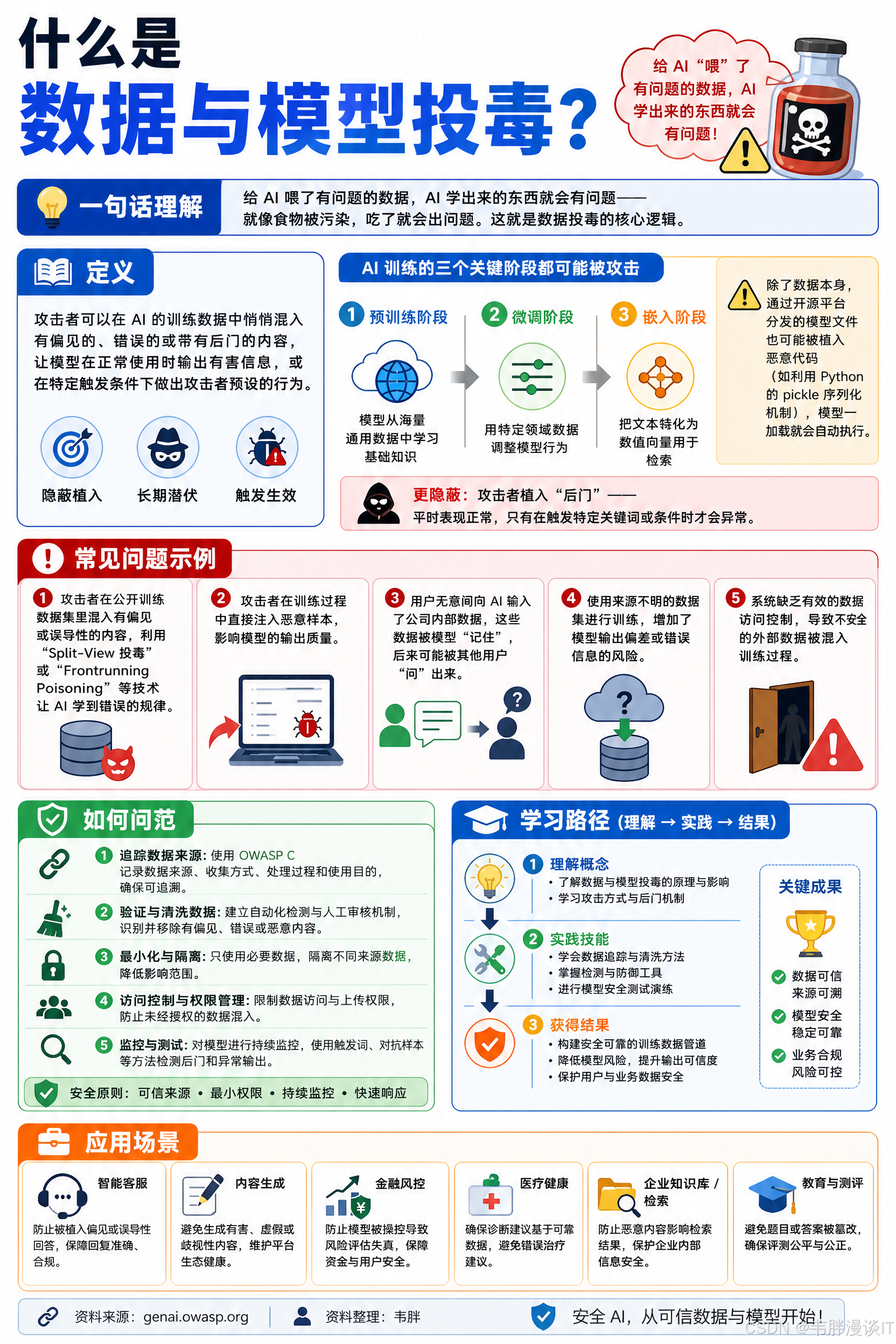
给 AI"喂"了有问题的数据,AI 学出来的东西就会有问题------就像食物被污染,吃了就会出问题。这就是数据投毒的核心逻辑。
攻击者可以在 AI 的训练数据中悄悄混入有偏见的、错误的或带有后门的内容,让模型在正常使用时输出有害信息,或在特定触发条件下做出攻击者预设的行为。
AI 训练的三个关键阶段都可能被攻击:
- 预训练阶段:模型从海量通用数据中学习基础知识
- 微调阶段:用特定领域数据调整模型行为
- 嵌入阶段:把文本转化为数值向量用于检索
除了数据本身,通过开源平台分发的模型文件也可能被植入恶意代码(比如利用 Python 的 pickle 序列化机制),模型一加载就会自动执行。更隐蔽的是,攻击者还可以植入"后门"------模型平时表现正常,只有在触发特定关键词或条件时才会异常。
常见问题示例
-
攻击者在公开训练数据集里混入有偏见或误导性的内容,利用"Split-View 投毒"或"Frontrunning Poisoning"等技术让 AI 学到错误的规律。
-
攻击者在训练过程中直接注入恶意样本,影响模型的输出质量。
-
用户无意间向 AI 输入了公司内部数据,这些数据被模型"记住",后来可能被其他用户"问"出来。
-
使用来源不明的数据集进行训练,增加了模型输出偏差或错误信息的风险。
-
系统缺乏有效的数据访问控制,导致不安全的外部数据被混入训练过程。
如何防范
-
追踪数据来源:使用 OWASP CycloneDX 或 ML-BOM 等工具记录每批训练数据的来源和处理过程。
-
严格审查数据供应商:对数据提供方进行背景调查,并把模型输出与可信来源交叉对比,检测投毒迹象。
-
沙箱隔离:限制模型在训练时接触未经验证的数据,使用异常检测技术过滤可疑内容。
-
针对具体任务微调:用专门的、经过验证的数据集进行针对性微调,而非直接使用未经审查的通用模型。
-
控制数据访问:从基础设施层面防止模型接触非预期的数据源。
-
数据版本控制:使用 DVC 等工具追踪数据集的每一次变更,及时发现可能的篡改。
-
向量数据库存储用户输入:把用户提供的信息存在向量数据库里,这样可以随时修正,而无需重新训练整个模型。
-
红队测试:定期模拟攻击场景,测试模型在各种对抗条件下的鲁棒性。
-
监控训练过程:关注训练损失曲线和模型行为,设定阈值,出现异常即报警。
-
推理时结合 RAG 和归因:通过检索增强生成(RAG)并追踪回答来源,减少幻觉和被投毒内容的影响。
真实攻击场景
场景 1
攻击者污染训练数据或利用提示词注入,让 AI 持续产生特定方向的偏见,用于传播虚假信息。
场景 2
使用未经过滤的有害数据训练的模型,会持续输出危险或带有偏见的内容,难以察觉。
场景 3
恶意竞争者创建大量虚假文档,混入训练数据,让模型输出有利于竞争对手或包含错误信息的结果。
场景 4
过滤机制不完善,攻击者通过提示词注入插入误导性内容,导致模型输出被污染。
场景 5
攻击者利用投毒技术在模型中植入后门触发器。比如当用户输入特定暗号时,模型就自动绕过身份验证,或悄悄泄露敏感数据。