这篇文章解决什么问题
前两篇文章讲到,早期 AI 主要依赖符号、规则、搜索和专家知识。专家系统一度证明了窄领域 AI 的商业价值,但它也暴露出一个核心瓶颈:知识很难被完整、稳定、低成本地手写进机器。
机器学习的兴起,正是对这个瓶颈的回应。它把问题从"怎样把专家规则写进程序"转向"怎样让程序从数据中学习规律"。这不是一个简单的技术替换,而是 AI 研究方式的重大变化:研究者开始更重视数据、误差、泛化、评估、特征和统计规律。
这篇文章会解释机器学习如何从 AI 的一个分支逐渐成为主线,并说明 1980 到 2000 年代的统计学习方法为什么为后来的深度学习和大模型铺平了道路。
核心观点
- 机器学习的核心转向是:从手写规则变成从样本中学习函数、模型或决策边界。
- 统计学习方法把"模型在训练集上表现好"与"模型在新数据上表现好"区分开来,泛化成为核心问题。
- 1980 到 2000 年代,决策树、贝叶斯网络、隐马尔可夫模型、SVM、Boosting、Random Forest 等方法推动机器学习走向成熟。
- 特征工程曾经是机器学习实践的中心:算法重要,但怎样把原始数据变成有用特征同样重要。
- 数据集、基准测试、交叉验证、KDD 竞赛和 UCI Repository 让机器学习形成了更强的实验文化。
- 深度学习并不是凭空出现的,它继承了机器学习时代关于数据、优化、泛化和评估的整套问题意识。
历史背景
"机器学习"这个词通常追溯到 Arthur Samuel。他在 IBM 研究跳棋程序时使用了 machine learning 这一说法,强调机器可以通过经验改进表现,而不是完全依赖程序员显式写好的策略。Samuel 的跳棋程序很早就展示了一个方向:机器可以在反复对局和评估中改进,而不是只执行固定规则。
不过,在 1950 到 1970 年代,机器学习还没有成为 AI 的主流。那时更受重视的是符号主义、搜索、逻辑推理和专家知识。原因很现实:数据不够多,算力不够强,统计方法和计算机科学之间的连接还不够紧密,许多任务也没有形成可以标准化比较的数据集。
1980 年代之后,情况逐渐变化。一方面,专家系统的维护成本越来越明显,人们发现"把知识写成规则"并不容易;另一方面,统计学、信息论、优化理论、数据库和计算机硬件都在发展,研究者开始有条件处理更多真实数据。AI 的重点开始从"让机器按照人类写好的规则推理"转向"让机器从样本中归纳模式"。
这个转向并不意味着符号主义消失。事实上,很多机器学习方法仍然保留了可解释结构,例如决策树和贝叶斯网络。真正变化的是工作方式:系统的能力不再主要来自程序员手写的规则,而是来自训练数据、模型假设和学习算法之间的配合。
到了 1990 年代,统计学习理论、支持向量机、Boosting、概率图模型、数据挖掘、信息检索和语音识别等方向共同推动机器学习成熟。进入 2000 年代后,互联网带来更多数据,计算资源更便宜,开源工具和竞赛文化扩散,机器学习逐渐从学术研究进入搜索、广告、推荐、风控、语音、视觉等真实业务系统。
关键事件时间线
1959 Arthur Samuel 使用 machine learning 描述跳棋程序研究 1984 Leslie Valiant 提出 learnable 的理论框架,PAC 学习兴起 1986 Quinlan 发表决策树学习论文,ID3 成为代表方法 1986 Rumelhart、Hinton、Williams 推广反向传播 1987 UCI Machine Learning Repository 创建 1988 Judea Pearl 的概率推理和贝叶斯网络影响 AI 1989 Rabiner 的 HMM 教程推动语音识别中的统计建模 1995 Cortes 和 Vapnik 发表 Support-Vector Networks 1996 Breiman 提出 Bagging Predictors 1997 Freund 和 Schapire 发表 AdaBoost 相关论文 1998 LeCun 等人展示梯度学习在文档识别中的应用 2001 Breiman 发表 Random Forests 和 Two Cultures 2006 Netflix Prize 推动推荐系统和机器学习竞赛文化 从机器学习到统计学习方法
技术解释
1. 从手写规则到从数据中学习
专家系统的典型思路是:
text
如果 条件 A 成立
并且 条件 B 成立
那么 得出结论 C机器学习的思路则不同。它通常先收集一批样本,每个样本包含输入和期望输出,然后让算法学习一个映射关系:
text
输入 x -> 模型 f -> 输出 y例如,在垃圾邮件识别中,专家系统可能要求工程师手写大量规则:
- 如果邮件包含某些词,可能是垃圾邮件。
- 如果发件人地址可疑,可能是垃圾邮件。
- 如果链接数量过多,可能是垃圾邮件。
机器学习系统则会收集大量邮件样本,每封邮件标注为"垃圾邮件"或"正常邮件",然后让模型从词频、发件人、链接、格式等特征中学习判断规律。
这个变化可以用一张图概括:
专家系统
人类专家写规则
规则库
推理得出结论
机器学习
收集训练数据
学习算法
模型
预测新样本
机器学习不是不需要人,而是把人的工作重心改变了。人不再主要写每一条判断规则,而是设计数据、选择特征、定义目标、选择模型、评估误差、监控上线后的表现。
2. 训练集、测试集和泛化
机器学习最重要的概念之一是泛化。一个模型在训练数据上表现很好,并不代表它在新数据上表现好。
假设你给模型 1000 道已经有答案的数学题,让它学习。如果它只是记住了这 1000 道题的答案,那么训练集准确率可以很高。但遇到第 1001 道新题时,它可能完全不会。真正有用的学习不是记忆样本,而是学到可以迁移到新样本的规律。
因此,机器学习实践中通常会把数据分成几部分:
| 数据划分 | 作用 |
|---|---|
| 训练集 | 用来拟合模型参数 |
| 验证集 | 用来选择模型、调参、比较方案 |
| 测试集 | 用来估计模型在未知数据上的表现 |
这套评估文化极其重要。它让 AI 研究从"看起来很聪明的演示"转向"在未见数据上可重复比较的实验"。这也是机器学习区别于很多早期 AI 演示系统的关键。
泛化问题还引出了过拟合和欠拟合:
- 过拟合:模型把训练数据中的噪声也学进去了,在训练集好,在新数据差。
- 欠拟合:模型太简单,连训练数据中的主要规律都学不到。
训练数据
学习算法
模型
训练集表现
测试集表现
是否只记住训练样本
是否能处理新样本
过拟合风险
泛化能力
机器学习的许多理论和实践,其实都围绕一个问题展开:怎样让模型既足够灵活,又不过度记忆训练数据。
偏差-方差权衡:理解过拟合和欠拟合的统一框架
过拟合和欠拟合可以用一个更精确的语言来描述:偏差-方差分解(Bias-Variance Decomposition)。它说一个模型在新数据上的预测误差,可以拆成三个来源:
text
期望误差 = 偏差² + 方差 + 不可约误差- 偏差(Bias):模型假设过于简单,无法捕捉真实规律。表现是训练集和测试集都差。例如用一条直线去拟合明显是曲线的关系。
- 方差(Variance):模型对训练数据的具体抖动太敏感,换一批训练数据就给出完全不同的预测。表现是训练集很好但测试集差。
- 不可约误差:数据本身就有噪声和不可观测变量,任何模型都无法消除。
这两类误差通常此消彼长:模型越复杂,偏差越小(拟合能力强),但方差越大(容易"记住"训练样本的细节)。把测试误差画成模型复杂度的函数,会得到一条经典的 U 型曲线:
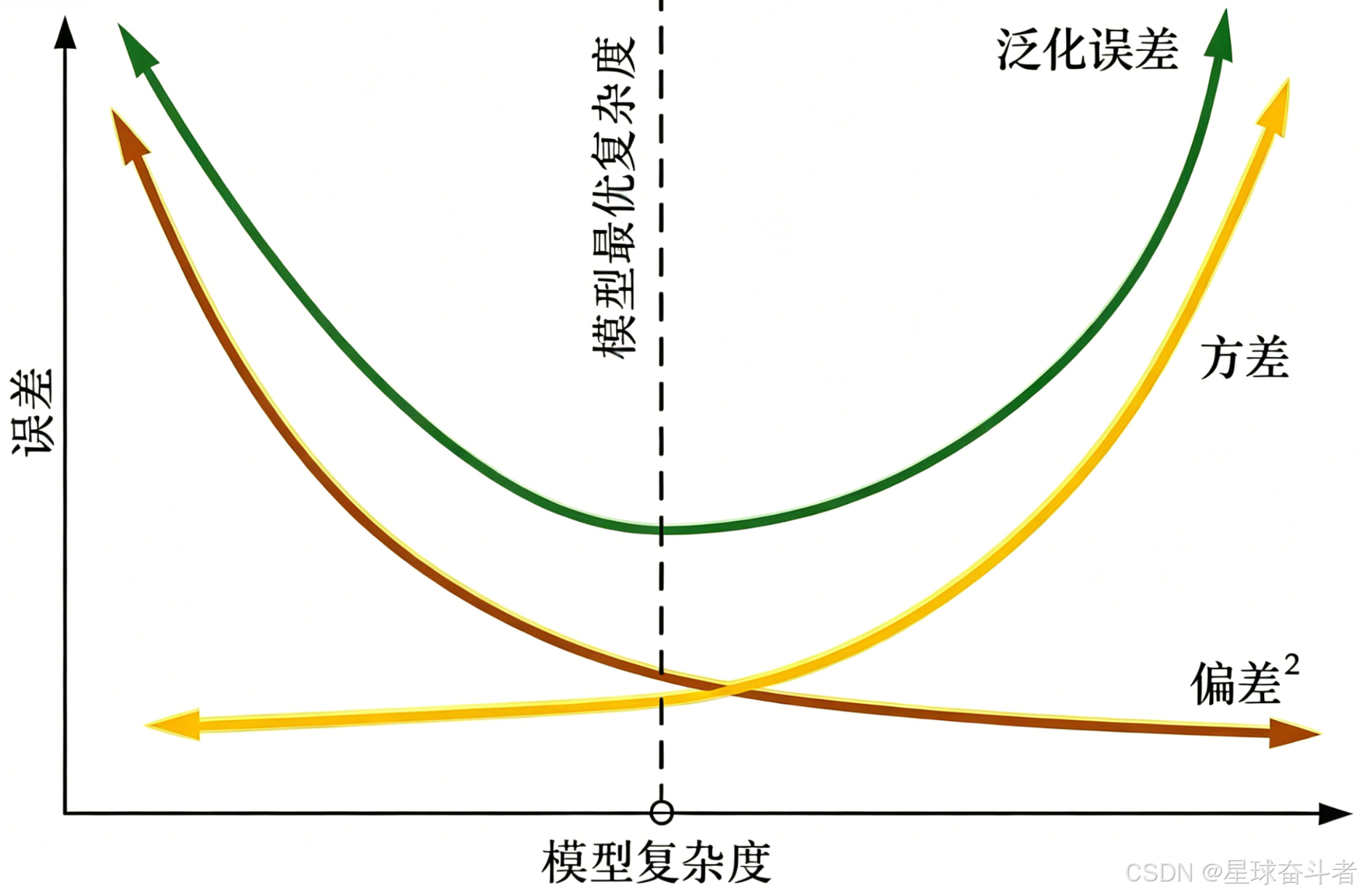
实践上常用的"扛过拟合"手段,本质都是在压方差:
- 正则化(L1、L2、weight decay):限制参数的大小,让模型更"平滑";
- 更多数据:方差对样本量很敏感,更多样本能直接降方差;
- Dropout、数据增强:注入随机性,让模型不容易记住单一样本;
- 早停(Early Stopping):在验证集误差开始上升前停止训练;
- 集成学习:用平均消减方差(详见后文)。
理解偏差-方差不是为了背公式,而是为了在调试模型时知道"该往哪边推":训练误差和测试误差都高,说明偏差大,要换更强模型或更好特征;训练误差低但测试误差高,说明方差大,要正则、加数据或简化模型。深度学习时代仍然在用这个框架做诊断。
3. 监督学习、无监督学习与强化学习
机器学习通常可以粗略分为三类。
监督学习是最常见的一类。数据中有输入,也有标准答案。分类、回归、排序、风险预测、图像识别、垃圾邮件识别都属于这个大方向。监督学习的目标是学会从输入预测输出。
无监督学习没有明确标准答案,目标是从数据中发现结构。聚类、降维、主题模型、异常检测都常见于这个方向。例如,你有一批用户行为数据,但没有人为标签,算法可以尝试把用户分成不同群体。
强化学习关注智能体在环境中行动,通过奖励信号学习策略。它和游戏、机器人、控制、推荐策略等问题有关。强化学习的历史很长,但在本文讨论的 1980 到 2000 年代,它更多是与动态规划、控制理论和学习理论交织发展,直到后来 AlphaGo 等系统才让它进入大众视野。
这三类不是严格隔离的。很多真实系统会组合使用它们。例如推荐系统可能同时使用监督学习预测点击率、无监督学习理解用户分群、强化学习优化长期反馈。
4. 特征工程:深度学习之前的核心手艺
在深度学习大规模流行之前,机器学习项目的成败往往取决于特征工程。
特征是模型看到的数据表示。原始数据通常不能直接喂给传统算法,工程师需要把它转换成合适的数字形式。比如:
| 任务 | 原始数据 | 可能的特征 |
|---|---|---|
| 垃圾邮件识别 | 邮件正文 | 词频、链接数量、发件域名、是否含附件 |
| 信用风险预测 | 用户资料 | 收入、负债、逾期次数、账户年龄 |
| 图像识别 | 像素矩阵 | 边缘、纹理、角点、颜色直方图 |
| 语音识别 | 声波 | 频谱特征、音素序列、时间窗口统计 |
| 推荐系统 | 用户行为 | 点击、收藏、评分、相似用户、相似物品 |
传统机器学习算法通常无法自动从原始像素、原始音频、原始文本中学出足够高级的表示。人需要把领域知识编码成特征。特征工程越好,模型越容易学习。
这也解释了为什么深度学习后来如此重要。深度神经网络的一个核心优势,是可以在一定程度上自动学习多层表示。例如从图像像素中学习边缘、纹理、局部形状,再到更复杂的对象结构。它并没有消灭特征工程,而是把一部分表示学习交给了模型。
5. 决策树:可解释的归纳学习
决策树是机器学习史上非常重要的一类方法。它把决策过程表示成一棵树:每个内部节点检查一个条件,每条分支对应一个结果,叶子节点给出预测。
例如,一个非常简化的贷款审批树可能是:
否
是
是
否
是
否
是否有稳定收入
高风险
是否有严重逾期记录
负债率是否过高
中风险
低风险
决策树受欢迎,是因为它比较直观,也容易解释。Quinlan 的 ID3、后来的 C4.5,以及 Breiman 等人的 CART,都推动了决策树方法的发展。
不过,单棵决策树也容易过拟合。它可能为了适应训练数据,把树长得过深,记住许多偶然细节。后来的 Bagging、Random Forest 和 Boosting,都可以看作是在提高这类模型稳定性和预测能力。
6. 概率模型:让 AI 处理不确定性
符号主义 AI 擅长处理明确规则,但真实世界充满不确定性。一个症状不一定对应一种疾病,一个词不一定只有一个意思,一个语音片段也不一定唯一对应某个音素。
概率模型为 AI 提供了一种表达不确定性的方法。它不要求系统只给出"真"或"假",而是估计不同可能性的概率。
贝叶斯网络是其中的重要代表。它用图结构表示变量之间的依赖关系,用概率表示不确定性。例如疾病、症状、检查结果之间可以形成一个概率图。系统可以根据观察到的症状,更新不同疾病的概率。
隐马尔可夫模型则在语音识别、自然语言处理和序列建模中影响很大。它假设我们观察到的是可见序列,例如声音特征,而背后存在不可直接看到的状态序列,例如音素或词。模型要根据观测推断隐藏状态。
可以把 HMM 的思想简化为:
隐藏状态 1
隐藏状态 2
隐藏状态 3
观测 1
观测 2
观测 3
概率模型的重要意义在于:AI 不再只能依赖硬规则,也可以用概率处理模糊、噪声和不完整信息。这是从专家系统走向统计学习的重要一步。
7. 统计学习理论:泛化不是凭感觉
统计学习理论试图回答一个更根本的问题:我们凭什么相信模型在训练数据上学到的东西,对未来数据也有效?
Vapnik 等人的工作让机器学习获得了更坚实的理论语言,例如经验风险、结构风险、VC 维、间隔最大化等概念。这里不需要深入数学,但要理解它关心的核心:
- 模型不能只追求训练误差低。
- 模型复杂度会影响泛化。
- 样本数量越多,越有可能估计真实规律。
- 不同算法隐含不同偏置,没有一种方法适合所有问题。
一句话讲清楚的几个概念
- 经验风险(Empirical Risk):模型在已知训练数据上的平均损失。直观上就是"训练集表现"。
- 结构风险(Structural Risk):经验风险 + 模型复杂度惩罚。直观上是"既要拟合好,又要别太复杂"。L2 正则、SVM 的间隔最大化都是这个思想的实例。
- VC 维(Vapnik-Chervonenkis Dimension):粗略可以理解为模型的"表达能力上限"------它最多能完美区分多少个任意标注的点。VC 维越高,模型越灵活,但需要的样本量也越多才能保证泛化。
举个具体例子:二维平面上的直线分类器 VC 维是 3------任意 3 个点的二分类标签都能用一条直线完美划开,但 4 个点(如 XOR 分布)就做不到。这就是为什么 1969 年 Minsky/Papert 在《Perceptrons》里证明单层感知机不能解决 XOR 问题------XOR 的 VC 维需求超过了线性分类器的表达上限。
支持向量机是统计学习理论影响实践的代表。它在分类问题中寻找一个分隔边界,并希望这个边界离两类样本都尽量远。这个"间隔最大化"的思想,让 SVM 在许多中小规模、高维任务上表现很好,尤其在文本分类、生物信息、图像识别等场景中曾经非常流行。
直观地说,SVM 不只是找到一条能分开训练样本的线,而是希望找到一条更稳健的线:
训练样本
寻找分类边界
最大化间隔
得到更可能泛化的分类器
这类方法让机器学习从经验技巧进一步走向理论化。研究者不只问"这个算法在某个数据集上准不准",也问"为什么它可能在新数据上仍然准"。
8. 集成学习:多个弱模型胜过一个强模型
1990 年代后期到 2000 年代,集成学习成为机器学习的重要方向。它的核心思想是:把多个模型组合起来,往往比单个模型更稳定、更准确。
Bagging 的思路是从训练数据中反复抽样,训练多个模型,然后平均或投票。它可以降低模型对单一训练集波动的敏感性。
Boosting 的思路是逐步训练一系列模型,让后面的模型更关注前面模型犯错的样本。AdaBoost 是代表方法之一,它展示了多个"弱分类器"组合后可以形成很强的预测器。
Random Forest 则把决策树和随机性结合起来,训练许多不同的树,再通过投票或平均得到结果。它的优点是效果强、调参相对容易、对特征类型适应性好,还能提供变量重要性。
训练数据
模型 1
模型 2
模型 3
模型 N
投票或平均
最终预测
集成学习影响深远。即使在深度学习时代,模型集成、投票、平均、重采样、随机化这些思想仍然常见。很多竞赛方案也会通过组合多个模型提升表现。
Bagging 与 Boosting:偏差-方差视角的对比
Bagging 和 Boosting 都是集成学习,但它们解决的问题方向相反,用偏差-方差框架看就一目了然:
| 维度 | Bagging(如 Random Forest) | Boosting(如 AdaBoost、GBDT、XGBoost) |
|---|---|---|
| 训练方式 | 并行训练多个独立模型 | 串行训练,每个新模型修正前面的错误 |
| 子模型类型 | 通常用低偏差、高方差的强学习器(如深决策树) | 通常用高偏差、低方差的弱学习器(如树桩) |
| 主要降低 | 方差 | 偏差 |
| 直觉 | 用"平均"消除单个模型的随机抖动 | 用"接力赛"逐步纠正系统性错误 |
| 过拟合风险 | 较低,加更多树通常不会变差 | 较高,需要早停或限制迭代数 |
| 代表算法 | Random Forest、Extra Trees | AdaBoost、Gradient Boosting、XGBoost、LightGBM |
这个对比有几个实际意义:
- 如果训练误差就很高(偏差大),单纯增加 Bagging 树数没用,应该用 Boosting 或更强的基学习器。
- 如果训练误差很低但测试误差高(方差大),适合 Bagging 或更强的正则化。
- XGBoost / LightGBM 在 2014 年之后的结构化数据竞赛中长期占据榜首,靠的就是 Boosting 强降偏差能力,加上二阶导数优化和正则化抑制方差。
理解 Bagging 是"降方差"、Boosting 是"降偏差",比记住具体算法名字更重要------它是机器学习里少数能直接指导选型决策的理论结论。
9. 数据集、基准测试与竞赛文化
机器学习成为主线,离不开数据集和评估文化。
1987 年创建的 UCI Machine Learning Repository,为研究者提供了可复用的数据集。它的重要性不只是"有数据可下载",而是让不同算法可以在相同数据上比较。没有共同数据集,算法优劣很容易变成各说各话。
MNIST 手写数字数据集则成为图像识别和神经网络研究中的经典基准。它足够简单,适合教学和快速比较;又足够真实,能体现模型处理图像模式的能力。
KDD Cup、Netflix Prize 等竞赛进一步强化了这种文化。研究者和工程师围绕同一个任务、同一份数据、同一个指标竞争,推动了特征工程、模型组合、评估方法和工程实现的快速迭代。
这种文化对今天影响很大。大模型时代的排行榜、benchmark、evals、Kaggle、开源数据集,本质上都继承了机器学习时代形成的实验传统。
为什么它重要
机器学习的重要性在于,它改变了 AI 的基本生产方式。
第一,它降低了手写规则的依赖。对于许多任务,我们不再需要把所有规则都提前写出来,而是可以从样本中学习规律。这让 AI 更容易进入复杂、变化快、规则难以穷尽的领域。
第二,它建立了泛化和评估意识。早期 AI 演示常常强调系统能做什么,而机器学习更强调在未见数据上的表现。训练集、验证集、测试集、交叉验证、误差指标,这些工具让 AI 能力变得更可比较。
第三,它推动了 AI 与统计学的融合。概率、估计、误差、假设、正则化、置信度、不确定性,这些统计语言让 AI 更能处理真实世界的数据。
第四,它为深度学习准备了土壤。深度学习后来依赖的大规模数据、梯度优化、表示学习、训练验证测试划分、benchmark 文化,都不是凭空出现的。它们是在机器学习时代逐渐成熟的。
第五,它让 AI 应用从实验室走向业务系统。搜索排序、广告点击率预估、推荐系统、风控、语音识别、OCR、医学辅助分析等,都可以在机器学习框架下不断迭代。
局限与争议
机器学习解决了专家系统的很多问题,但也带来了新的问题。
首先是数据依赖。模型从数据中学习,如果数据有偏差,模型也会继承偏差。训练数据不代表真实世界时,模型上线后可能表现很差。
其次是可解释性下降。决策树还比较容易解释,但 SVM、集成模型、神经网络等方法往往更难说明每个预测背后的原因。准确率提高之后,解释和责任问题变得更重要。
第三是特征工程成本。传统机器学习虽然减少了手写规则,却把大量工作转移到特征设计上。特征工程需要领域知识,也需要反复实验,成本并不低。
第四是指标可能误导。一个模型在测试集上表现好,不代表它在真实业务中一定好。测试集可能泄漏,指标可能选择不当,数据分布可能随时间变化。机器学习把评估变得更科学,但没有让评估自动变得简单。
第五是"没有免费午餐"的问题。没有一种算法在所有任务上都最好。算法选择必须结合数据规模、特征类型、噪声水平、解释需求、部署成本和业务目标。
和今天 AI 的关系
今天的大模型看起来和 1990 年代的机器学习方法差别很大,但核心问题并没有消失。
大模型仍然需要训练数据、验证数据和评估指标;仍然会过拟合、欠拟合和分布外失效;仍然需要处理偏差、噪声、泛化和可解释性;仍然需要在真实业务中监控效果。
很多现代概念都可以追溯到机器学习时代的问题:
| 机器学习时代的问题 | 大模型时代的对应概念 |
|---|---|
| 特征如何设计 | 表示学习、Embedding、上下文工程 |
| 数据不够或不准 | RAG、数据清洗、合成数据、反馈数据 |
| 模型如何评估 | Evals、Benchmark、红队测试、A/B 测试 |
| 模型如何避免过拟合 | 正则化、早停、数据增强、预训练与微调 |
| 模型如何适应业务 | Fine-tuning、Prompt、Tool Use、Workflow |
| 模型如何解释 | 引用来源、可观测日志、解释性研究 |
大模型也让"从数据中学习"的思想进一步扩展。传统监督学习往往需要人为标注大量样本,而大模型通过自监督学习从海量文本中学习语言规律,再通过指令微调、人类反馈和工具使用适应任务。它不是抛弃机器学习,而是把机器学习推向更大规模、更通用的表示学习。
因此,理解机器学习史可以帮助我们避免一个误解:大模型不是和传统机器学习断裂的全新物种,而是建立在几十年关于数据、优化、泛化、表示和评估的积累之上。
小结
- 机器学习把 AI 的重心从手写规则转向从数据中学习。
- Arthur Samuel 的跳棋程序很早展示了"机器通过经验改进"的思想。
- 专家系统的知识获取和维护瓶颈,为机器学习兴起提供了现实动因。
- 泛化是机器学习的核心:模型必须在未见数据上表现好,而不只是记住训练集。
- 训练集、验证集、测试集和交叉验证让 AI 评估变得更可重复。
- 特征工程曾是传统机器学习实践的核心,也是深度学习后来试图部分自动化的对象。
- 决策树、概率模型、SVM、Boosting、Random Forest 等方法推动统计学习成熟。
- UCI Repository、MNIST、KDD Cup、Netflix Prize 等数据集和竞赛塑造了机器学习实验文化。
- 机器学习没有解决所有问题,它仍然依赖数据质量、评估设计和人类判断。
- 今天的大模型继承了机器学习时代的核心问题,只是在更大规模上重新展开。
参考资料
- IBM, The games that helped AI evolve, Arthur Samuel and machine learning: https://www.ibm.com/history/early-games
- Arthur L. Samuel, Some Studies in Machine Learning Using the Game of Checkers, IBM Journal of Research and Development, 1959: https://ieeexplore.ieee.org/document/5392560
- Leslie G. Valiant, A Theory of the Learnable, Communications of the ACM, 1984: https://cacm.acm.org/research/a-theory-of-the-learnable/
- J. R. Quinlan, Induction of Decision Trees, Machine Learning, 1986: https://link.springer.com/article/10.1023/A:1022643204877
- David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams, Learning representations by back-propagating errors, Nature, 1986: https://www.nature.com/articles/323533a0
- UCI Machine Learning Repository, About: https://archive.ics.uci.edu/about
- Judea Pearl, Probabilistic Reasoning in Intelligent Systems, 1988: https://archive.org/details/probabilisticrea00pear
- Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proceedings of the IEEE, 1989: https://www.fceia.unr.edu.ar/prodivoz/Rabiner_1989.pdf
- Corinna Cortes and Vladimir Vapnik, Support-Vector Networks, Machine Learning, 1995: https://link.springer.com/article/10.1007/BF00994018
- Yoav Freund and Robert E. Schapire, A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting, Journal of Computer and System Sciences, 1997: https://www.sciencedirect.com/science/article/pii/S002200009791504X
- Leo Breiman, Random Forests, Machine Learning, 2001: https://link.springer.com/article/10.1023/A:1010933404324
- Leo Breiman, Statistical Modeling: The Two Cultures, Statistical Science, 2001: https://projecteuclid.org/journals/statistical-science/volume-16/issue-3/Statistical-Modeling--The-Two-Cultures-with-comments-and-a/10.1214/ss/1009213726.full
- Yann LeCun, Corinna Cortes, Christopher J. C. Burges, The MNIST Database of Handwritten Digits: https://yann.lecun.com/exdb/mnist/
- ACM SIGKDD, KDD Cup: https://kdd.org/kdd-cup