Token = 大模型能读懂的最小"文字碎片"
不再按汉字/字符算,按模型拆分后的碎片计费、算长度。
-
1 中文汉字 ≈ 1.3 个 Token
-
1 英文单词 ≈ 1 个 Token
-
1000 汉字 ≈ 1300 Token
-
字符:我们肉眼数的字、标点、字母
-
Token :模型内部切割后的小块
模型不会整字读,会拆偏旁、词根、词组碎片处理。
体验:阿里百炼平台->应用->侧栏知识库
RAG原理
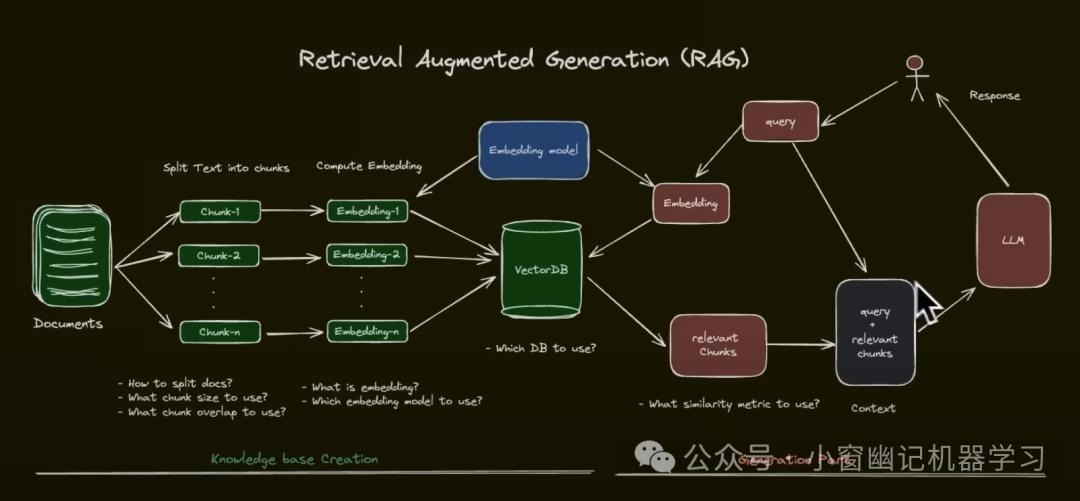
绿色:数据的嵌入embedding
-
文字性的相似性查询
存文档进知识库、数据分块(图片转成文字->文字提取出来->再存进去->再分块)、拆分策略、
常规数据库:文字存入数据库
常规数据库:查询:全文检索(关键字匹配)
大语言模型:查找:根据语义查找(相似性匹配)
向量数据库:文字转成数字(向量)存入向量数据库
embedding model本身也是一种大模型
-
图片性的相似性查询
红色 :数据的召回(检索)
用户提问->嵌入模型先对用户问题进行向量转换->根据数字到向量数据库进行相似度查询->返回相关的块数据(top_k=20这个数大一些保证需要的答案在召回数据里、1表示最相似但不一定正确、足够大如果还不行引入模型重排)->把用户的问题+返回的所有数据(上下文)一起发送给大模型
大模型智能体:把用户问题拆分成很多子问题、多次查询,增大召回准确率7
还可以做混合检索(语义+全文检索)
知识图谱:构建文档之间的关系
加载:不同格式的文档加载器加载各种各样的数据
借助嵌入模型进行转换
使用嵌入模型的方式:
-
在线服务商提供的api
-
私有化自己部署
https://www.modelscope.cn/home
huggingface
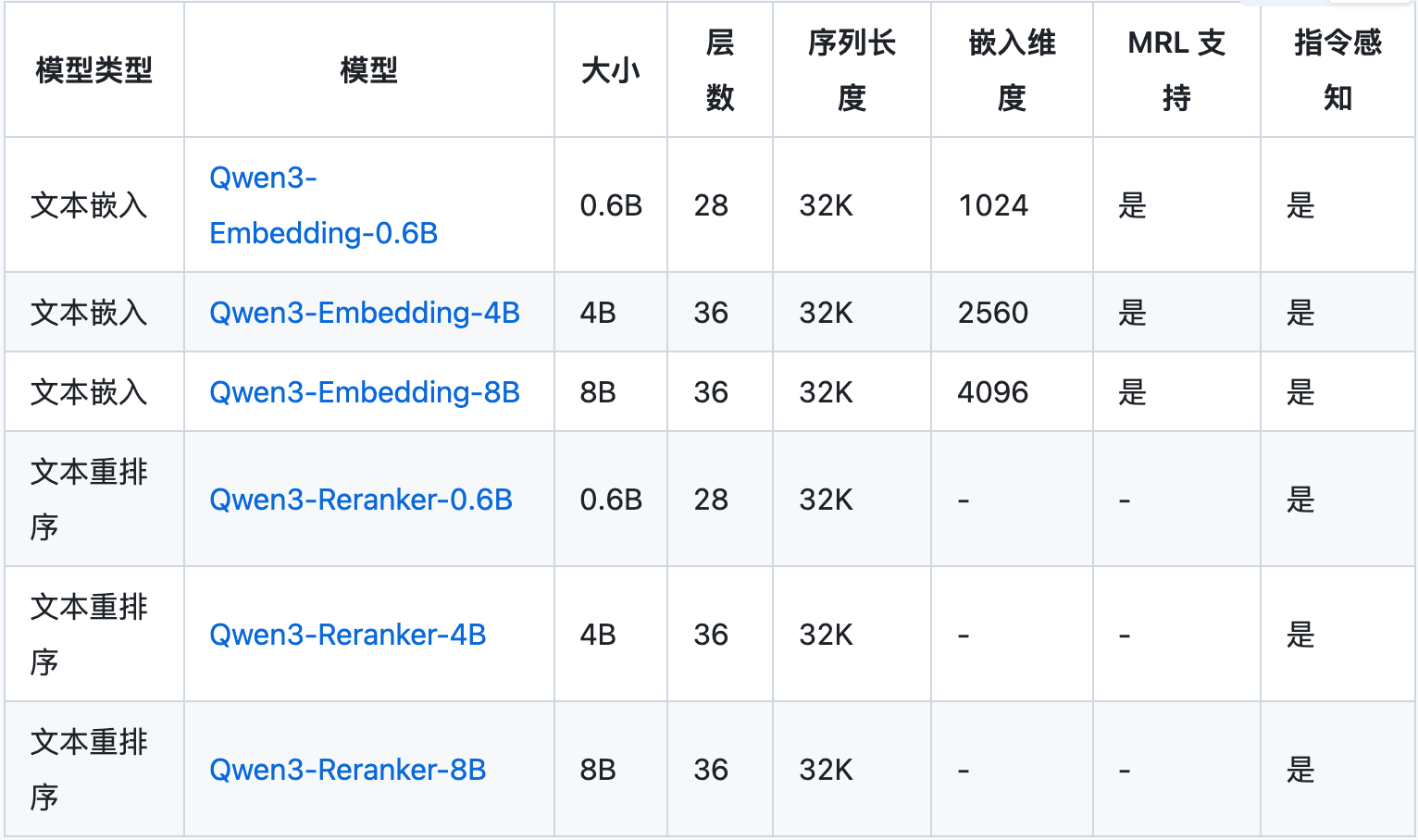
企业用8b,自己用0.6b
嵌入模型一旦使用不能修改(如果换模型纬度不一样数据都作废)
运行模型的框架:
- transformer
- VLLM是在本地运行一个API服务
- Ollama(https://ollama.com/library/qwen3-embedding)用这个
Ubuntu安装Ollama(服务器/虚拟机内存4G以上)
(1)在Linux终端粘贴命令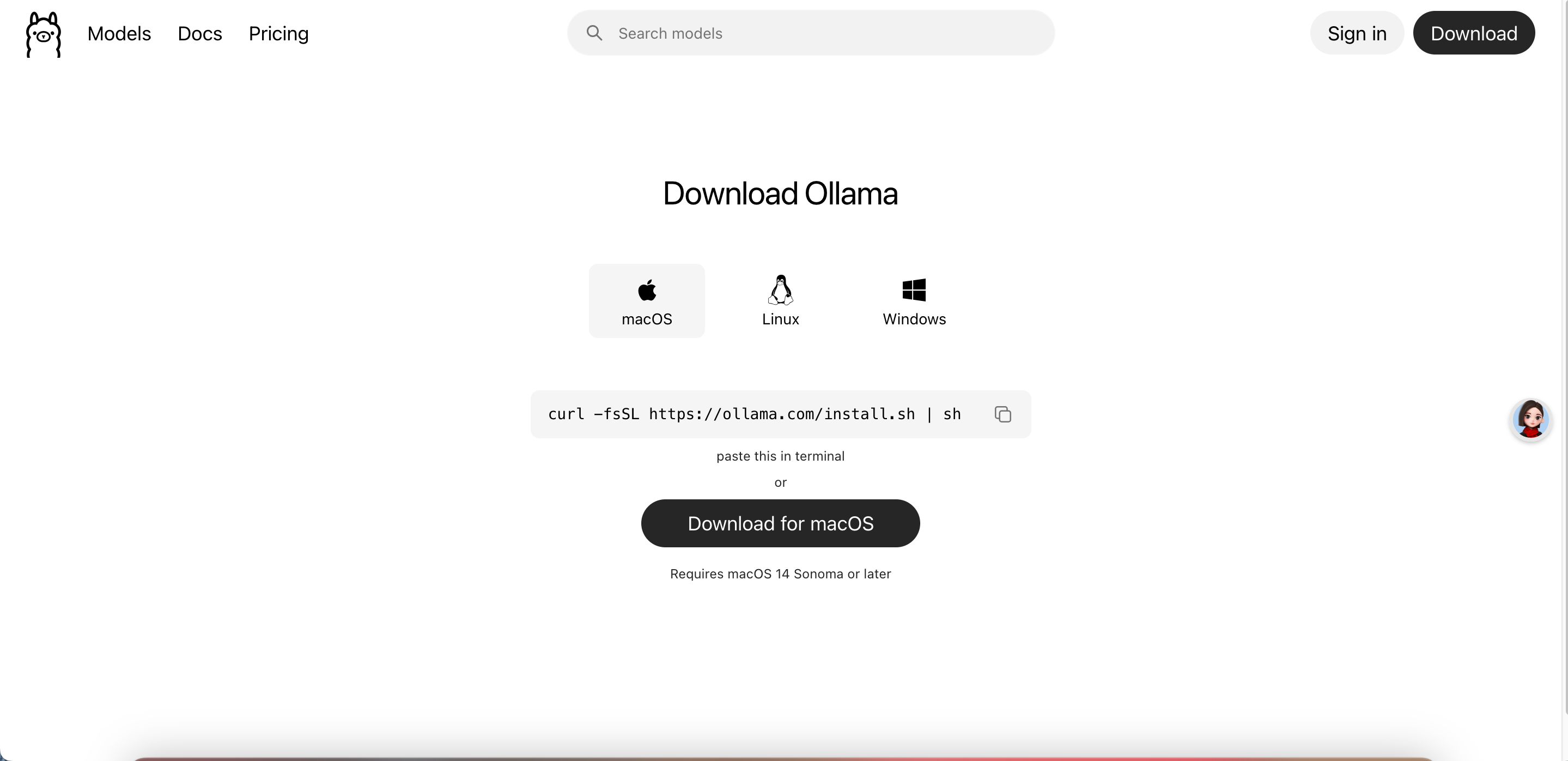
(2)下载模型
在Linux终端粘贴命令
bash
ollama pull qwen3-embedding:0.6b查看
bash
ollama list(3)修改配置支持ollama远程访问
bash
vi
bash
Environment="OLLAMA_HOST=0.0.0.0:11434"(4)重启服务
bash
sudo systemctl daemon-reload
sudo systemctl restart ollama(5)放开端口(本机)
bash
ufw allow 11434(云服务器)到官网后台
(6)用另一台电脑访问 http://你的服务器IP:11434,能返回结果就成功了
后续:部署和使用RAG系统,开发MCP server对接用例生成系统
关注"用例采纳率"