问题与思考
1、模型学习、机器学习的实质是什么?是怎么进行学习的
机器学习:输入知识->总结规律,再次遇到新的问题之后,能给出预测
学习方式:计算机可以没有明确的程序,从历史的数据中进行领域学习的能力
2、输入、输出之间的关系,又可以称为什么?
① 数学公式
② 事物之间的规律
一、机器学习概述
1.人工智能的三大概念
三者之间关系:
机器学习是实现人工智能的一种途径
深度学习是机器学习的一种方法
人工智能:向人一样理性思考、合理行动
机器学习(Machine Learning ):计算机可以没有明确的程序,从历史的数据中进行领域学习的能力
Field of study that gives computers the ability to learn without being explicitly programmed
深度学习(Deep Learning):也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物
大模型:参数量极大的神经网络
1.1 机器学习方式:
基于规则学习:程序员根据经验、或自己总结的规则,进行编程或将规则告诉LLM
基于模型学习:从数据中自动学习、总结规律
1.2 AI发展三要素:
数据、算法、算力
2. 机器学习常用语
特征 :等价于输入数据
样本 :输入、输出的一组数据
标签 :等价于输出组
训练集 :用来进行模型训练的由多个样本组成的数据集,
测试集:评估模型效果的数据集
3. 机器学习算法分类
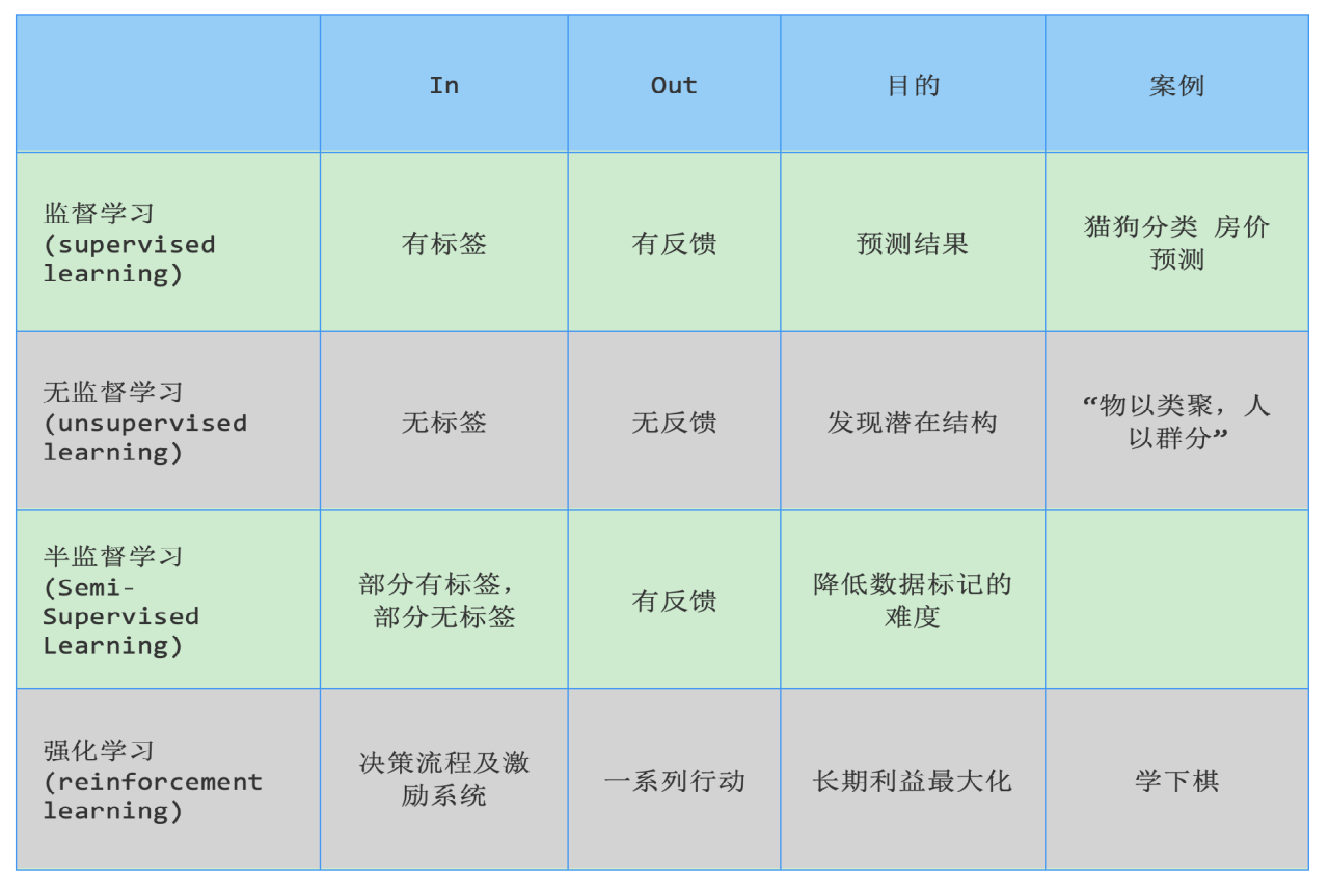
3.1 有效监督学习:
输入的数据由特征值和目标值组成
3.1.1 分类问题:
定义:目标值可枚举、离散、不连续
分类种类:二分类、多分类
3.1.2 回归问题:
定义:目标值是连续的、不可枚举的
3.2 无监督学习:
特点:输入的数据只有特征值
定义:由模型自动发现数据间的相似性,对样本进行分类,以发现数据内部结构及相互关系
3.3 半监督:
特点:输入的数据由只有部分数据有目标值组成
工作原理:
让专家标注少量数据,利用已标记的数据(带有标签的数据集)训练出一个模型
再利用训练出的的模型取标记未标记的数据
使用场景:数据标注
3.4 强化学习:
应用场景:各类游戏、对抗比赛、无人驾驶
基本原理:
通过构建四个元素:agent、环境状态、行动、奖励
agent根据环境状态进行行动,获得最多的累计奖励
3.5 总结
4、机器学习建模流程
获取数据->数据的基本处理->特征工程 ->模型学习->测试评估
机器学习建模流程
获取数据 :搜集与完成机器学习任务相关的数据集
数据基本处理 :数据集中异常值,缺失值的处理等
特征工程 :对数据特征进行提取、转成向量,让模型达到最好的效果
机器学习(模型训练): 选择合适的算法对模型进行训练
根据不同的任务来选中不同的算法: 有监督学习,无监督学习,半监督学习,强化学习
模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
5、特征工程概念入门
特征:与目标结果息息相关的属性(房子面积、照相、地段与房子价格的关系)
5.1 什么是特征工程?
利用人的专业背景知识和技巧从原始数据中提特征,形成特征向量,让机器学习算法效果更好,这个过程就是特征工程
数据和特征决定了机器学习的上限,而模型和算法知识取逼近这个上限。
5.2 特征工程实现方法:
**特征提取:**原始数据中提取与任务相关的特征,构成特征向量
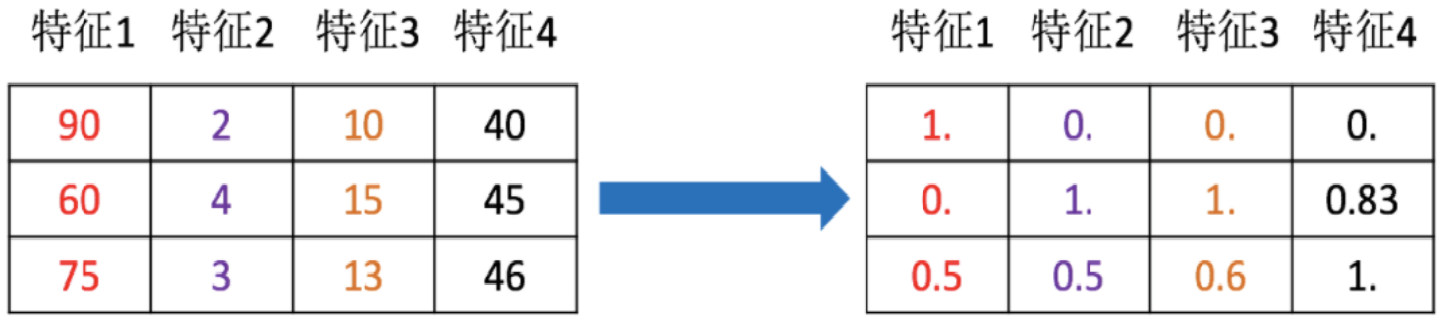
特征预处理: 因量纲问题(各个特征单位、数字大小),有些特征对模型影响大,有些影响小。
(数字越大、对模型影响越大,预处理使各个特征的数据,尽量在同一数量级上)
特征降维:将原始数据的维度降低,如将三维数据降维到二维
**特征选择:**从原始数据特征中挑取部分,认为有用的特征
**特征组合:**把多个特征合并为一个特征,多个特征之间进行数学运算
6. 模型拟合问题
6.1 什么是拟合?
拟合是模型训练的本质,AI模型通过不断调整自身的内部参数(比如神经网络中的权重),让它的预测结果不断逼近真实的训练数据。这个过程就是在寻找最优参数,使模型输出最接近观测数据
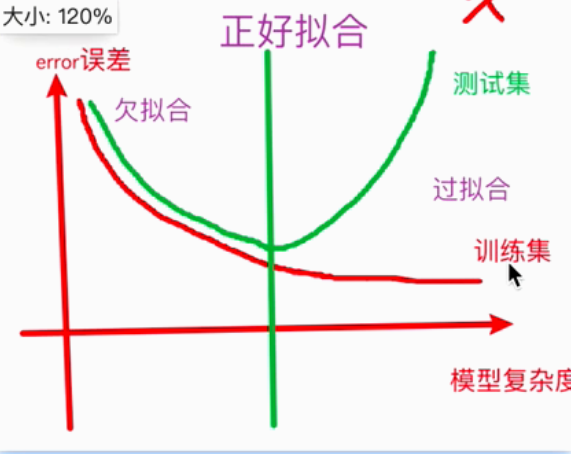
6.2 什么是过拟合和欠拟合?
欠拟合:模型在训练集和测试集上的表现都很差
"没学会":就像考试前连课本都没看明白,做题一塌糊涂。
过拟合:模型在训练集上表现很好,在测试机上表现很差
"死记硬背":把练习题的答案连同印刷错误都背下来了,题目稍微一变就不会做了。
6.3 过拟合和欠拟合出现的原因是什么?
过拟合:在训练集上学到了太多的特征 "死记硬背",或训练数据过少
欠拟合:模型过于简单、特征值太少
6.4 理解泛化是什么?
模型在新数据集(非训练集上)上表现好坏的能力
7、机器学习开发环境
基于python scikit-learn
作用:
简单高效的数据挖掘和数据分析工具
可供大家使用,可在各种环境中重复使用
建立在NumPy,SciPy和matplotlib上
开源,可商业使用-获取BSD许可证
二、机器学习常用算法
1. KNN算法------K.近邻算法(K Nearest Neighbor)
1.1 KNN算法简介
1.1.1 算法思想:
如果一个样本在特征空间的k个最相似的样本大多数属于某一个类别,则该样本也属于这个类别
1.1.2 如何找到最相似的样本?
欧式距离:
1.1.3 KNN分类流程
① 计算未知样本到每一个训练样本的距离
② 将训练样本根据距离大小升序排列
③ 取出距离最近的 K 个训练样本
④ 进行多数表决,统计 K 个样本中哪个类别的样本个数最多
⑤ 将未知的样本归属到出现次数最多的类别
1.1.4 KNN回归流程
① 计算未知样本到每一个训练样本的距离
② 将训练样本根据距离大小升序排列
③ 取出距离最近的 K 个训练样本
④ 把这个 K 个样本的目标值计算其平均值
⑤ 将未知的样本预测的值了
1.1.5 K值如何取:
实际工作中经常使用交叉验证的方式去选取最优的k值,而且一般情况下,k值都是比较小的数值。一般取:3、5、7、9、11
K值过小:过拟合
K值过大:欠拟合
1.2 KNN算法API介绍
1.2.1 KNN分类API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
python
# 导包
from sklearn.neighbors import KNeighborsClassifier
# 获取数据
x = [[4,1],[3,2],[2,1],[1,0]]
y = [0,0,1,1]
# 模型训练
estimator = KNeighborsClassifier(n_neighbors=1)
estimator.fit(x,y)
# 模型预测
result = estimator.predict([[2.5,1]])
print(result)1.2.2 KNN回归API:
sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)
python
# 导包
from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor
# 获取数据
x = [[4,1],[3,2],[2,1],[1,0]]
y = [0.5,1,1.5,2]
# 模型训练
estimator = KNeighborsRegressor(n_neighbors=2)
estimator.fit(x,y)
# 模型预测
result = estimator.predict([[2.5,1]])
print(result)1.3 特征预处理
目标:因量纲问题(各个特征单位、数字大小),有些特征对模型影响大,有些影响小。
(数字越大、对模型影响越大,预处理使各个特征的数据,尽量在同一数量级上)
1.3.1 归一化:
概念:
将原始数据进行转换,映射到mi,mx (默认0-1之间)
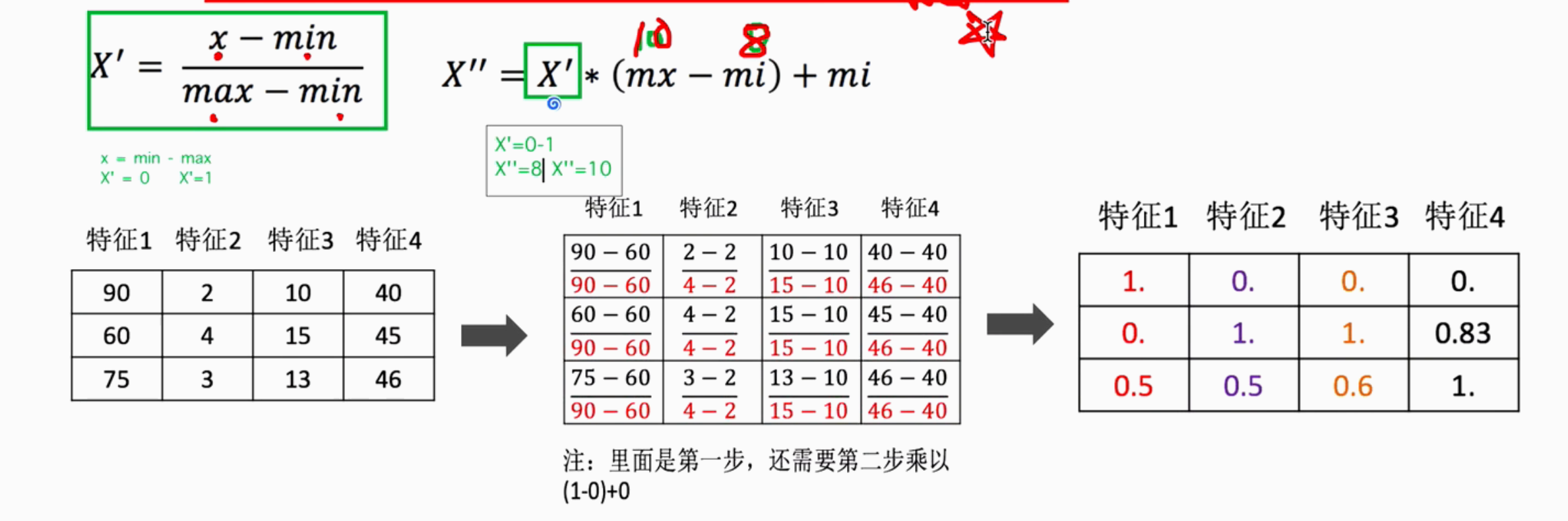
代码实现:
python
from sklearn.preprocessing import MinMaxScaler
# 1. 准备数据
x = [
[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]
]
# 2. 初始化归一化对象
transform = MinMaxScaler()
# 3. 对原始特征进行变换
data = transform.fit_transform(x)
# 4. 打印归一化后的结果
print(data)
# 输出
'''
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
'''transform.fit_transform() 与 transform.transform()的区别:
from sklearn.preprocessing import MinMaxScaler
2. 初始化归一化对象
transform = MinMaxScaler()
使用场景:
1、
fit_transform(X):仅用于训练集, 这是模型第一次接触数据,需要通过它来建立处理的"标尺"或"规则"2、transform(x):**用于测试集或新数据,**必须使用训练集建立的同一套"标尺"来处理,以保证标准一致(在之前必须有fit 或 fit_transform())
作用与逻辑:
**
fit_transform(X):先学习 + 后转换,**先从数据 X 中计算并保存转换所需的参数(如均值、标准差、最大最小值等),然后立刻用这些参数对 X 进行转换。transform(x):只转换, 不学习任何新东西,直接使用之前
fit阶段已经学到的参数,对数据进行同样的转换。为什么测试集只能用
transform()?目的:防止数据泄露(Data Leakage)
测试集或线上实时到来的新数据,对于模型来说应该是完全"未知"的。我们在训练集上使用
fit_transform()算出了均值、方差等统计量,这就相当于制定了一把标准的"尺子"。当处理测试集时,我们必须沿用这把训练集做好的"尺子"去衡量新数据(即只用
transform())。如果你在测试集上使用了fit_transform(),就相当于用测试集自己的数据重新做了一把"尺子",这不仅破坏了评估的一致性,还让模型间接"偷看"了测试集的信息,导致最终的模型评估结果虚高,无法反映真实水平。
缺点:很容易受异常值影响
下边示例中有一个异常值 9000,对其它特征值的影响就会很大,其它值对应的会很小
python
from sklearn.preprocessing import MinMaxScaler
# 1. 准备数据
x = [
[9000, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]
]
# 2. 初始化归一化对象
transform = MinMaxScaler()
# 3. 对原始特征进行变换
data = transform.fit_transform(x)
# 4. 打印归一化后的结果
print(data)
# 输出
'''
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.00167785 0.5 0.6 1. ]]
'''适用场景:
图像处理,精确无异常值的情况
1.3.2 标准化:
标准化思想:
通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
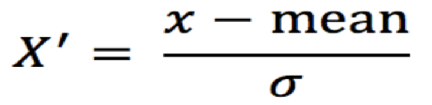
mean 为特征的平均值
σ 为特征的标准差
标准差公式:

API实现:
sklearn.preprocessing.StandardScaler( )
python
from sklearn.preprocessing import StandardScaler
# 1. 准备数据
x = [
[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]
]
# 标准化对象
transform = StandardScaler()
# 3. 对原始特征进行变换
data = transform.fit_transform(x)
# 打印结果
print(data)
# 输出
'''
[[ 1.22474487 -1.22474487 -1.29777137 -1.3970014 ]
[-1.22474487 1.22474487 1.13554995 0.50800051]
[ 0. 0. 0.16222142 0.88900089]]
'''应用场景:
适合现代嘈杂大数据场景。(以后就是用你了)
1.3.3 鸢尾花识别案例:
注意:sns.lmplot 的 x、y、hue 必须使用带引号的列名字符串(如 "sepal length (cm)"),而不是具体的 Series 数据
python
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
matplotlib.use('TkAgg')
# 获取数据
def load_iris_data():
iris_data = load_iris()
# print(iris_data)
data = iris_data["data"]
target = iris_data["target"]
target_names = iris_data["target_names"]
feature_names = iris_data["feature_names"]
return data, target, target_names,feature_names
# 可视化
def showiris():
data, target, target_names, feature_names = load_iris_data()
# print(data)
df = pd.DataFrame(data, columns=feature_names)
# print(df.head())
df["target"] = target
# print(df)
# x = df["sepal length (cm)"]
# y = df["petal width (cm)"]
# print(x)
# print(y)
# sns.lmplot() 显示
sns.lmplot(x="sepal length (cm)", y="petal width (cm)", data=df, hue="target", fit_reg=False)
plt.xlabel("sepal length (cm)")
plt.ylabel("petal width (cm)")
plt.title('iris')
plt.show()
def traintest_split():
data, target, target_names, feature_names = load_iris_data()
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=22)
# random_state=22 随机数种子,保证程序的可复现性
return x_train, x_test, y_train, y_test
def train_predict():
x_train, x_test, y_train, y_test = traintest_split()
# 数据预处理
# 标准化对象
transform = StandardScaler()
# 标准化训练集、测试集数据
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
# 模型训练
# 实例化
estimator = KNeighborsClassifier(n_neighbors=5)
# 训练
estimator.fit(x_train,y_train)
# 模型评估
# 1、获取预测结果 2、根据预测结果获取准确率
y_predict = estimator.predict(x_test)
print(accuracy_score(y_true=y_test, y_pred=y_predict))
# 另一种写法
my_score = estimator.score(x_test,y_test)
print(my_score)
# 模型预测
mydata = [[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata = transform.transform(mydata)
# 进行预测
mydata_predict = estimator.predict(mydata)
print("mydata_predict------>",mydata_predict)
mydata_proba = estimator.predict_proba(mydata)
print("mydata_proba------>",mydata_proba)
# 交叉验证、网格搜索
def across_grid():
x_train, x_test, y_train, y_test = traintest_split()
# 数据预处理
# 标准化对象
transform = StandardScaler()
# 标准化训练集、测试集数据
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
estimator = KNeighborsClassifier()
param_grid = {"n_neighbors": [3, 5, 7, 9]}
# 实现
estimator = GridSearchCV(estimator=estimator,param_grid=param_grid,cv=5)
estimator.fit(x_train,y_train)
# 交叉验证网格搜索结果查看
print('estimator.best_score_---', estimator.best_score_)
print('estimator.best_estimator_---',estimator.best_estimator_)
print('estimator.best_params_---', estimator.best_params_)
# print('estimator.cv_results_---', estimator.cv_results_)
# 模型评估
myscore = estimator.score(x_test,y_test)
print("myscore------>",myscore)
if __name__ == '__main__':
# data, target, target_names, feature_names = load_iris_data()
# showiris()
# print(x_train, y_train, x_test, y_test)
train_predict()
# across_grid()
# x_train, x_test, y_train, y_test = traintest_split()
# print(x_test)1.4 超参数选择方法
1.4.1 交叉验证
什么是交叉交叉验证?
一种数据集分割办法,将训练集划分为n份,拿一份做验证集,其它n-1份做训练集
目标:为了得到更加准确、可信的模型评分
交叉验证法原理:
将数据集划分为 cv=4 份
第一次:把第一份数据做验证集,其他数据做训练
第二次:把第二份数据做验证集,其他数据做训练
... 以此类推,总共训练4次,评估4次。
使用训练集+验证集多次评估模型,取平均值做交叉验证为模型得分
若k=5模型得分最好,再使用全部训练集(训练集+验证集) 对k=5模型再训练一边,再使用测试集对k=5模型做评估

1.4.2 网格搜索
网格搜索------寻找最优超参数的工具!
只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数
网格搜索 + 交叉验证的强力组合 (模型选择和调优)
目标:选出最优参数组合建立模型
1、遍历参数列表:{n_neighbors=3,5,7..}
2、分别使用每个参数进行交叉验证,并取得对应准确率,最终选出准确率最高的参数
1.4.3 交叉验证网格搜索 -- API
交叉验证网格搜索API介绍

利用KNN算法对鸢尾花分类 -- 交叉验证网格搜索
python
# 交叉验证、网格搜索
def across_grid():
x_train, x_test, y_train, y_test = traintest_split()
# 数据预处理
# 标准化对象
transform = StandardScaler()
# 标准化训练集、测试集数据
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
estimator = KNeighborsClassifier()
param_grid = {"n_neighbors": [3, 5, 7, 9]}
# 实现
estimator = GridSearchCV(estimator=estimator,param_grid=param_grid,cv=5)
estimator.fit(x_train,y_train)
# 交叉验证网格搜索结果查看
print('estimator.best_score_---', estimator.best_score_)
print('estimator.best_estimator_---',estimator.best_estimator_)
print('estimator.best_params_---', estimator.best_params_)
# print('estimator.cv_results_---', estimator.cv_results_)
# 模型评估
myscore = estimator.score(x_test,y_test)
print("myscore------>",myscore)
# 模型预测
mydata = [[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata = transform.transform(mydata)
# 进行预测
mydata_predict = estimator.predict(mydata)
print("mydata_predict------>",mydata_predict)
mydata_proba = estimator.predict_proba(mydata)
print("mydata_proba------>",mydata_proba)1.5 分类问题评估
1.5.1 理解混淆矩阵的构建方法

真正例:正例中预测正确的数量(TP,True Positive)x
伪正例:反例中预测错误的数量(FP,False Positive)f2 - y
真反例:反例中预测正确的数量(TN,True Negative)y
伪反例:正例中预测错误的数量(FN,False Negative) f1 - x
1.5..2 掌握精确率,召回率和F1score的计算方法和概念
精确率是指预测为正例中实际为正例的比例,召回率是指实际为正例中被预测为正例的比例,F1score 值是精确率和召回率的调和平均数
准确率:
预测结果正确的的比率
P = (TP + FN) / TOTAL
(正例中预测正确的 + 反例中预测正确的) / 总数
精确率:
对正例样本的预测准确率。比如:把恶性肿瘤当做正例样本,想知道模型对恶性肿瘤的预测准确率。
计算方法:P = TP/TP+ FP
正例中预测正确的 / 正例中预测正确的 + 反例中预测错误的
召回率:
也叫查全率,正例中预测正确的数量占(反例中预测错误的数量+正例中预测正确的数量)
指的是预测为真正例样本占所有真实正例样本的比重例如:恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。
计算方法:P = TP/TP+ FN
正例中预测正确的 / 总正例数
F1- score:
若对模型的精度、召回率都有要求,希望知道模型在这两个评估方向的综合预测能力
计算方法:P == 2 ∗Precision ∗Recall/Precision+Recall

1.5.3 代码实现计算求精确率、召回率、f1_score:
python
from sklearn.metrics import confusion_matrix,accuracy_score,precision_score,recall_score,f1_score
msg_true = ["恶性", "恶性", "恶性","恶性","恶性","恶性", "良性", "良性", "良性", "良性"]
pre_A = ["恶性", "恶性", "恶性", "良性", "良性", "良性", "良性", "良性", "良性", "良性"]
pre_B = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性"]
# confusion_matrix
mA = confusion_matrix(msg_true, pre_A)
print("confusion_matrix_A->\n", mA)
mB = confusion_matrix(msg_true, pre_B)
print("confusion_matrix_A->\n", mB)
# accuracy_score:准确率
acc_score = accuracy_score(y_true=msg_true,y_pred=pre_A)
print("accuracy_score_A->",acc_score)
acc_score = accuracy_score(y_true=msg_true,y_pred=pre_B)
print("accuracy_score_B->",acc_score)
# precision_score:精确率
pre_score = precision_score(y_true=msg_true, y_pred=pre_A, pos_label="恶性")
print("precision_score_A->", pre_score)
pre_score = precision_score(y_true=msg_true, y_pred=pre_B, pos_label="恶性")
print("precision_score_B->", pre_score)
# recall_score: 召回率
re_score = recall_score(y_true=msg_true, y_pred=pre_A, pos_label="恶性")
print("recall_score_A->", re_score)
re_score = recall_score(y_true=msg_true, y_pred=pre_B, pos_label="恶性")
print("recall_score_B->", re_score)
# f1_score
f_score = f1_score(y_true=msg_true, y_pred=pre_A, pos_label="恶性")
print("f_score_A->",f_score)
f_score = f1_score(y_true=msg_true, y_pred=pre_B, pos_label="恶性")
print("f_score_B->",f_score)
# 输出
'''
confusion_matrix_A->
[[3 3]
[0 4]]
confusion_matrix_A->
[[6 0]
[3 1]]
accuracy_score_A-> 0.7
accuracy_score_B-> 0.7
precision_score_A-> 1.0
precision_score_B-> 0.6666666666666666
recall_score_A-> 0.5
recall_score_B-> 1.0
f_score_A-> 0.6666666666666666
f_score_B-> 0.8
'''1.6【重要】KNN实现步骤:
- 数据处理:
1.1 获取数据(获取sklearn已经封装的数据)
from sklearn.datasets import load_iris
data = iris_data"data"
target = iris_data"target"
1.2 划分数据集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=22)
test_size=0.2 测试集占比
random_state=22 随机种子,保证每次获取相同部分
- 特征预处理:
2.1 标准化对象(除过图像一般都使用标准化处理)
transform = StandardScaler()
标准化训练集、测试集数据
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
- 模型训练:
3.1 交叉验证+网格搜索------寻找最优超参数
estimator = GridSearchCV(estimator=KNeighborsClassifier(),param_grid={"n_neighbors": 3, 5, 7, 9},cv=5)
estimator.fit(x_train,y_train)
print('estimator.best_params_---', estimator.best_params_) # 获取最优参数
3.2 实例化
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier(n_neighbors=estimator.best_params_) # 分类
from sklearn.neighbors import KNeighborsRegressor
estimator = KNeighborsRegressor(n_neighbors=estimator.best_params_) # 回归(目标值不连续)
3.3 训练
estimator.fit(x_train,y_train)
- 模型评估:
my_score = estimator.score(x_test,y_test)
另一种写法------1、获取预测结果 2、根据预测结果获取准确率
from sklearn.metrics import accuracy_score
y_predict = estimator.predict(x_test)
print(accuracy_score(y_true=y_test, y_pred=y_predict))
- 模型预测:
5.1 待预测数据 特征预处理
mydata = transform.transform(mydata)
5.2 预测
mydata_predict = estimator.predict(特征值)