本文在 AWS 中国区(cn-north-1)实现 Docker 自建 Kafka 与 AWS Lambda + Glue Schema Registry 的完整集成。Kafka 运行在 EC2 实例上,Lambda 通过 VPC 内网消费消息,使用 Avro 格式进行数据序列化。
整体的数据流图如下
CloudWatch Logs Glue Schema Registry Lambda Function Docker Kafka Producer (Avro) CloudWatch Logs Glue Schema Registry Lambda Function Docker Kafka Producer (Avro) 注册 Schema 发送 Avro 消息 ESM 轮询推送 获取 Schema (by ID) 返回 Schema 定义 Avro 反序列化 记录处理日志
核心概念
SelfManagedKafka 事件源
AWS Lambda 支持多种事件源,其中 SelfManagedKafka 类型允许 Lambda 直接连接自建 Kafka 集群,无需经过 MSK。
KafkaBootstrapServers: Kafka 代理地址(数组格式)Topics: 订阅的 Topic 列表StartingPosition: 消费起始位置 (LATEST/TRIM_HORIZON)SourceAccessConfigurations: VPC 访问配置
注意 :KafkaBootstrapServers 必须是数组类型:
yaml
KafkaBootstrapServers:
- !Sub "${EC2PrivateIp}:9092"EventSourceMapping 事件格式
Lambda 接收自 Kafka 的事件结构与直接调用不同:
records是字典,key 为{topic}-{partition}value是 Base64 编码的消息内容- Lambda 需要遍历
records字典的值
json
{
"eventSource": "SelfManagedKafka",
"bootstrapServers": "172.31.14.46:9092",
"records": {
"orders-0": [
{
"topic": "orders",
"partition": 0,
"offset": 1,
"timestamp": 1779613023206,
"timestampType": "CREATE_TIME",
"value": "eyJvcmRlcl9pZCI6...",
"headers": []
}
]
}
}Glue Schema Registry 集成
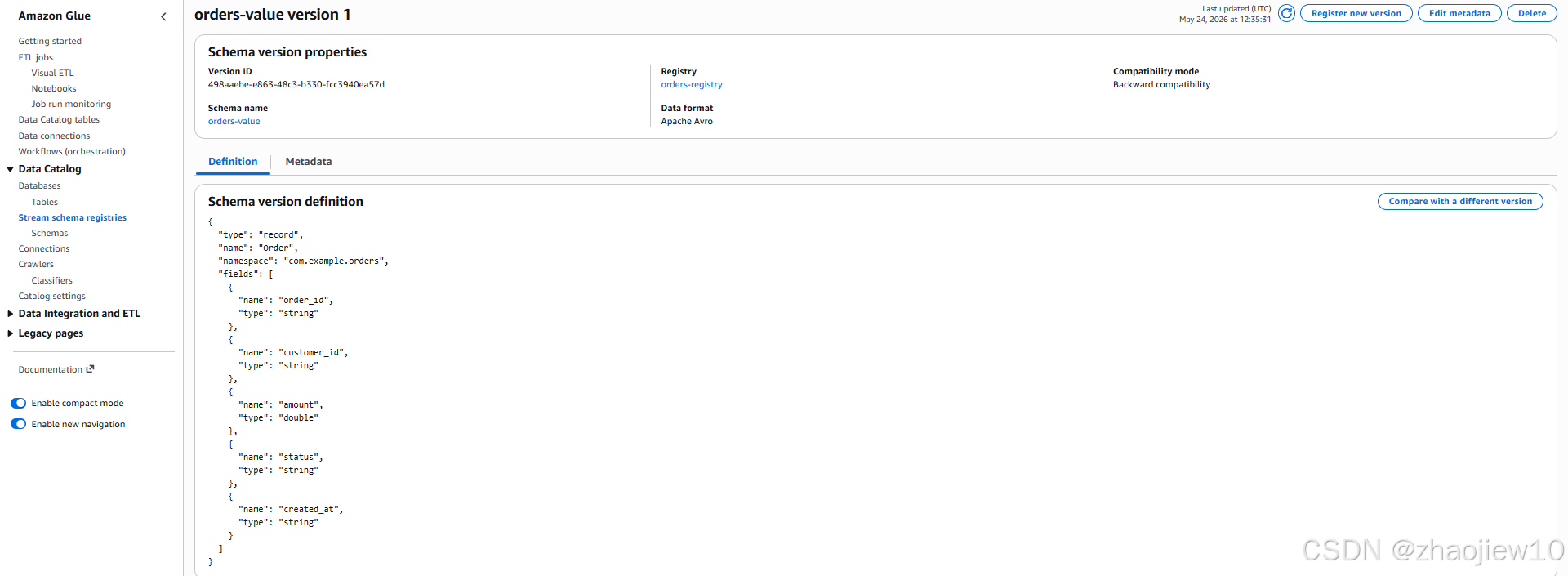
Glue Schema Registry 提供 Schema 定义和版本管理。但是根据 AWS 官方文档中国区的lambda服务目前不可用
Provisioned mode for event source mappings is not available in the China Regions.
Provisioned Mode 是 Lambda ESM (Event Source Mapping) 的一种事件轮询模式,用于控制 Lambda 如何从 Kafka/MSK/SQS 拉取消息。
由于 SchemaRegistryConfig 必须配合 ProvisionedPollerConfig(即 Provisioned Mode)使用,因此中国区 Lambda ESM 无法使用 Schema Registry 自动验证。解决方案是在 Lambda 代码中手动处理 Avro 反序列化。
根据 AWS 官方文档 Using schema registries with Kafka event sources:
This feature is only available for event source mappings using provisioned mode. Schema registry doesn't support event source mappings in on-demand mode.
如果尝试在 On-Demand 模式下配置 SchemaRegistryConfig,会收到以下错误:
SchemaRegistryConfig is only available for Provisioned Mode. To configure Schema Registry, please enable Provisioned Mode by specifying MinimumPollers in ProvisionedPollerConfig.
Schema Registry 集成需要在 ESM poller 层面执行额外工作(查询 schema、解码消息),AWS 将此功能绑定到 Provisioned Mode 实现。
Lambda Function
Lambda ESM Poller
Kafka Cluster
Provisioned Mode Required
Kafka Message
(Avro bytes)
Schema Registry Lookup
自动查询 Glue Schema
Avro Decode
自动反序列化
Handler
收到 JSON 格式事件
由于 Provisioned Mode 不可用,需在 Lambda 代码中手动处理 Avro 序列化:
python
from aws_schema_registry import SchemaRegistryClient, KafkaDeserializer
import boto3
glue_client = boto3.client('glue', region_name='cn-north-1')
registry_arn = 'arn:aws-cn:glue:cn-north-1:xxxxxxxxxx:registry/orders-registry'
schema_client = SchemaRegistryClient(glue_client, registry_arn)
deserializer = KafkaDeserializer(schema_client)
def lambda_handler(event, context):
for topic_partition, records in event.get('records', {}).items():
for record in records:
value_bytes = base64.b64decode(record['value'])
decoded = deserializer.deserialize(topic, value_bytes)
# 处理 decoded.data (Python dict)...部署与配置
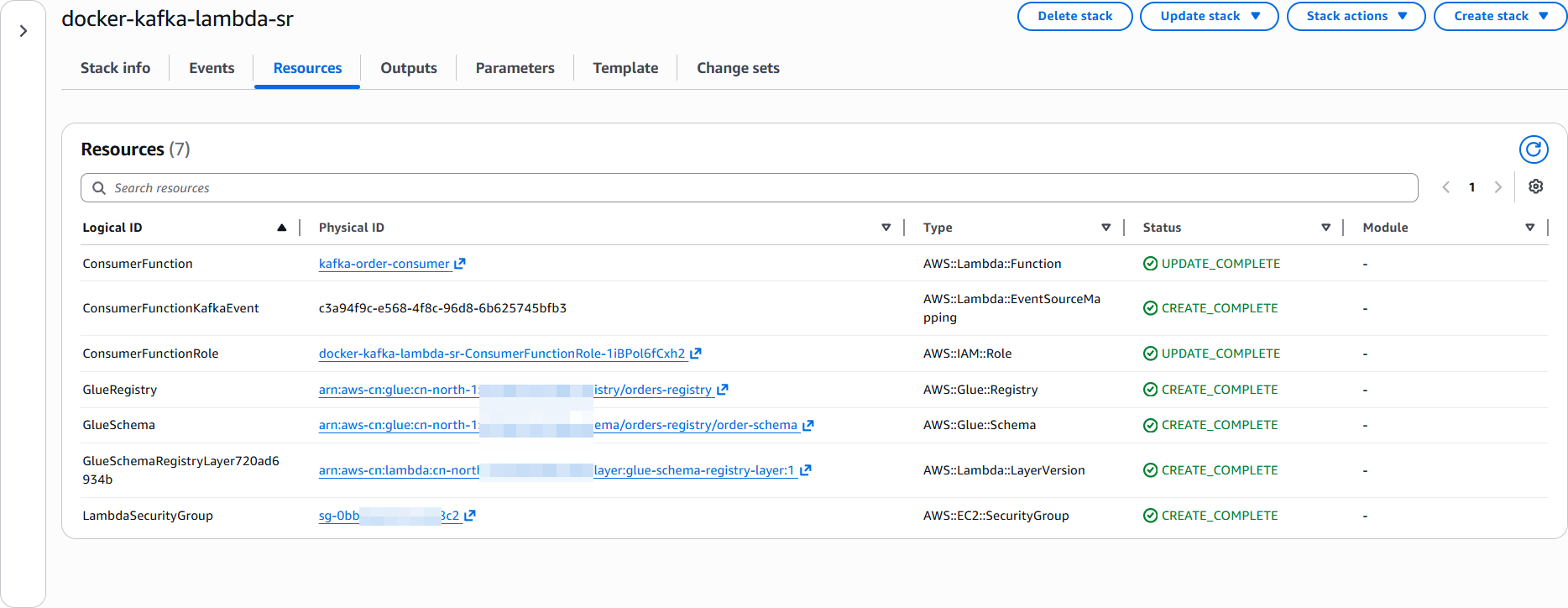
SAM部署基础设施
SAM 模板如下
yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
# Lambda Layer - 包含 aws-glue-schema-registry
GlueSchemaRegistryLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: glue-schema-registry-layer
ContentUri: glue-schema-registry-layer.zip
CompatibleRuntimes:
- python3.12
# Glue Registry
GlueRegistry:
Type: AWS::Glue::Registry
Properties:
Name: orders-registry
# Lambda Function
ConsumerFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: kafka-order-consumer
Runtime: python3.12
Handler: consumer.lambda_handler
CodeUri: .
Layers:
- !Ref GlueSchemaRegistryLayer
VpcConfig:
SubnetIds:
- !Ref PrivateSubnet1
SecurityGroupIds:
- !Ref LambdaSecurityGroup
Environment:
Variables:
GLUE_REGISTRY_ARN: !Ref GlueRegistry
Events:
KafkaEvent:
Type: SelfManagedKafka
Properties:
KafkaBootstrapServers:
- !Sub "${EC2PrivateIp}:9092"
Topics:
- orders
StartingPosition: LATEST
SourceAccessConfigurations:
- Type: VPC_SUBNET
URI: !Ref PrivateSubnet1
- Type: VPC_SECURITY_GROUP
URI: !Ref LambdaSecurityGroup
Policies:
- Statement:
- Sid: GlueAccess
Effect: Allow
Action:
- glue:GetRegistry
- glue:GetSchemaVersion
- glue:GetSchemaByDefinition
- glue:GetSchema
Resource: "*"由于中国区不支持 ESM 级别的 Schema Registry 自动验证,Lambda 需要手动集成 Glue Schema Registry 进行消息反序列化。
Lambda 需要包含 aws-glue-schema-registry 库。创建 Layer:
bash
# 在本地创建 Layer
mkdir -p layer/python
pip install -t layer/python aws-glue-schema-registry boto3
cd layer && zip -r ../glue-schema-registry-layer.zip .在 SAM 模板中引用:
yaml
Layers:
- !Ref GlueSchemaRegistryLayer部署命令
bash
# 构建
sam build
# 部署
sam deploy --resolve-s3 --no-confirm-changeset部署资源如下
Lambda代码示例
Handler 代码如下
python
import json
import base64
import os
import logging
import boto3
from aws_schema_registry import SchemaRegistryClient, KafkaDeserializer
# 初始化(在 handler 外部,避免每次调用重新初始化)
logger = logging.getLogger()
logger.setLevel(os.getenv('LOG_LEVEL', 'INFO'))
glue_client = boto3.client('glue', region_name='cn-north-1')
registry_name = 'orders-registry'
# Schema Registry 客户端(延迟初始化)
schema_client = None
deserializer = None
def get_deserializer():
"""延迟初始化 deserializer"""
global schema_client, deserializer
if deserializer is None:
schema_client = SchemaRegistryClient(glue_client, registry_name)
deserializer = KafkaDeserializer(schema_client)
return deserializer
def lambda_handler(event, context):
"""
处理 Kafka 事件,使用 Glue Schema Registry 反序列化 Avro 消息.
支持两种消息格式:
1. Avro 格式(带 schema ID 前缀)- 使用 Glue Schema Registry 反序列化
2. JSON 格式 - 直接解析
"""
logger.info(f"Event source: {event.get('eventSource')}")
results = []
batch_item_failures = []
records_by_topic = event.get('records', {})
for topic_partition, records in records_by_topic.items():
logger.info(f"Processing {topic_partition}: {len(records)} records")
for record in records:
try:
topic = record.get('topic', 'unknown')
partition = record.get('partition', -1)
offset = record.get('offset', -1)
value_b64 = record.get('value', '')
if not value_b64:
value = {}
else:
value_bytes = base64.b64decode(value_b64)
# 尝试 Avro 反序列化
try:
deser = get_deserializer()
decoded = deser.deserialize(topic, value_bytes)
value = decoded.data
logger.info(f"[{topic}] p={partition} o={offset} (Avro) data={value}")
except Exception as avro_err:
# 回退到 JSON 解析
try:
value = json.loads(value_bytes.decode('utf-8'))
logger.info(f"[{topic}] p={partition} o={offset} (JSON) data={value}")
except Exception as json_err:
logger.error(f"Failed to deserialize: avro={avro_err}, json={json_err}")
raise avro_err
# 处理业务逻辑
process_order(value)
results.append({
'recordId': record.get('recordId', ''),
'result': 'Ok',
'data': value_b64
})
except Exception as e:
logger.error(f"Failed to process record: {e}")
batch_item_failures.append({
'itemIdentifier': str(record.get('offset'))
})
if batch_item_failures:
return {'batchItemFailures': batch_item_failures}
return {'records': results}
def process_order(order: dict):
"""业务处理逻辑"""
order_id = order.get('order_id')
logger.info(f"Processing order: {order_id}")Producer 使用 aws-glue-schema-registry 库序列化 Avro 消息:
python
#!/usr/bin/env python3
import uuid
from datetime import datetime, timezone
import boto3
from aws_schema_registry import SchemaRegistryClient, KafkaSerializer, DataAndSchema
from aws_schema_registry.avro import AvroSchema
from confluent_kafka import Producer
REGISTRY_NAME = "orders-registry"
BOOTSTRAP_SERVERS = "172.31.1.2:9092"
TOPIC = "orders"
AVRO_SCHEMA = """
{
"type": "record",
"name": "Order",
"namespace": "com.example.orders",
"fields": [
{"name": "order_id", "type": "string"},
{"name": "customer_id", "type": "string"},
{"name": "amount", "type": "double"},
{"name": "status", "type": "string"},
{"name": "created_at", "type": "string"}
]
}
"""
def main():
glue = boto3.client("glue", region_name="cn-north-1")
schema_client = SchemaRegistryClient(glue, registry_name=REGISTRY_NAME)
serializer = KafkaSerializer(schema_client)
producer = Producer({"bootstrap.servers": BOOTSTRAP_SERVERS})
for i in range(3):
order = {
"order_id": f"avro-{uuid.uuid4().hex[:8]}",
"customer_id": f"cust-{(i % 5) + 1:03d}",
"amount": round(100.0 + i * 10.5, 2),
"status": "pending",
"created_at": datetime.now(timezone.utc).isoformat(),
}
print(f"Sending Avro message {i+1}: {order['order_id']}")
schema = AvroSchema(AVRO_SCHEMA.strip())
serialized = serializer.serialize(
TOPIC,
DataAndSchema(data=order, schema=schema),
)
producer.produce(
topic=TOPIC,
value=serialized,
callback=lambda err, msg: print(f"Delivered to {msg.topic()} [{msg.partition()}]" if not err else f"Failed: {err}"),
)
producer.poll(0)
producer.flush()
print(f"\nSent 3 Avro messages to {TOPIC}")
if __name__ == "__main__":
main()注意 :aws-glue-schema-registry 会自动在 Glue 中创建 {topic}-value 命名的 schema(如 orders-value),而非使用 SAM 创建的 order-schema。
kafka部署
使用 KRaft 模式:
yaml
services:
kafka:
image: confluentinc/cp-kafka:7.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_PROCESS_ROLES: "broker,controller"
KAFKA_NODE_ID: "1"
KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka:9093"
KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER"
KAFKA_LISTENERS: "INTERNAL://:9092,CONTROLLER://:9093"
KAFKA_ADVERTISED_LISTENERS: "INTERNAL://${PRIVATE_IP}:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "INTERNAL:PLAINTEXT,CONTROLLER:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL"
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "false"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: "1"
CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk"
volumes:
- kafka-data:/var/lib/kafka/data
volumes:
kafka-data:生产和消费
发送测试消息
bash
# JSON 格式(用于基础测试)
sudo docker exec kafka bash -c 'echo "{\"order_id\":\"test-001\",\"customer_id\":\"cust-001\",\"amount\":99.99,\"status\":\"test\"}" | kafka-console-producer --bootstrap-server localhost:9092 --topic orders'
# Avro 格式
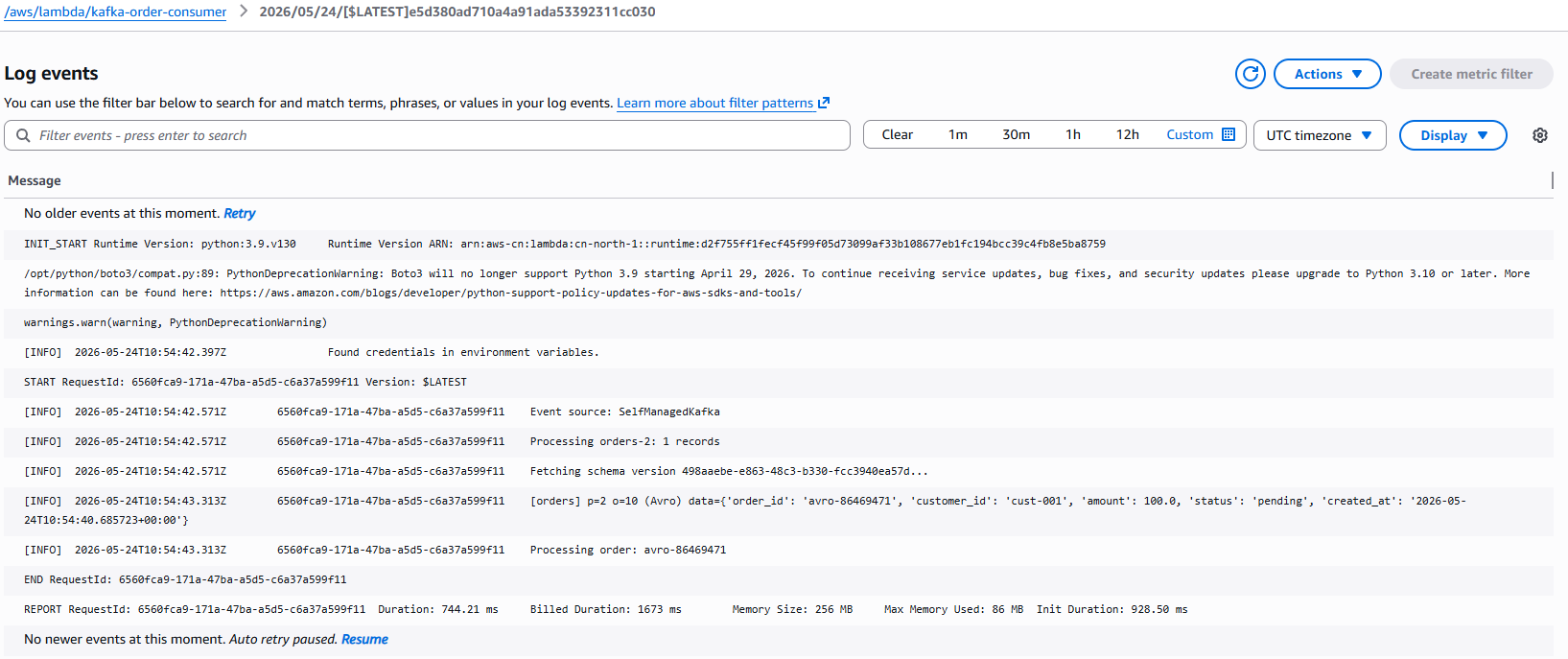
~/.local/bin/uv run python producer_avro.py查看 Lambda 日志
bash
aws --region cn-north-1 logs tail /aws/lambda/kafka-order-consumer --since 2m --format short成功日志如下
Event source: SelfManagedKafka
Processing orders-1: 2 records
Fetching schema version 498aaebe-e863-48c3-b330-fcc3940ea57d...
[orders] p=1 o=6 (Avro) data={'order_id': 'avro-9591de65', 'customer_id': 'cust-002', 'amount': 110.5, 'status': 'pending', 'created_at': '2026-05-24T10:54:40.799489+00:00'}
Processing order: avro-9591de65日志截图