衔接前序 :第 36-37 篇分别以代码实战实现了编码器和解码器的前向传播,并通过手动验证确认了每步计算的正确性。但前两篇使用的都是随机初始化的模型 ,输出没有语义意义。本文是"代码实战三部曲"的终章,将训练一个完整的 Transformer 模型(中英翻译),并通过逐阶段的检查点(checkpoint)分析,观察参数如何从随机走向有序。
建议运行配套 notebook
38_transformer_training.ipynb边看边读,效果最佳。
一、概述
本文的核心问题是:随机初始化的一组参数,经过梯度下降训练后,内部发生了什么变化?
为了回答这个问题,我们训练一个小型 Transformer(仅 13 万参数),并在训练过程中设置 8 个检查点(0、50、100、200、500、1000、2000、3000 步),在每个检查点保存:
- Embedding 矩阵(用于 t-SNE 可视化和余弦相似度分析)
- 编码器自注意力权重(观察注意力模式如何聚焦)
- QKV 和 FFN 的 Frobenius 范数(观察参数增长轨迹)
- 训练/验证损失(确认模型确实在学习)
通过纵向对比这些检查点,我们可以清晰地看到"学习"的本质------从随机的混沌状态,逐渐涌现出有结构、有规律的表示。
模型配置
与第 36-37 篇完全一致:
| 参数 | 值 |
|---|---|
| d_model | 32 |
| 注意力头数 h | 4 |
| 每头维度 d_k | 8 |
| FFN 隐藏层 d_ff | 128 |
| 编码器/解码器层数 N | 3 |
| 总参数量 | 133,302 |
| 优化器 | Adam (lr=1e-3) |
| 损失函数 | CrossEntropy (ignore pad) |
| Batch size | 32 |
| 训练数据 | 800 句对 |
| 训练步数 | 3000 步(120 个 epoch) |
导入依赖和模型初始化:
python
import torch
import torch.nn as nn
import numpy as np
from sklearn.manifold import TSNE
from data_utils import build_vocab, load_parallel_data, encode_line, decode_line, collate_batch
from transformer_modules import Transformer
model = Transformer(
src_vocab_size=zh_spec['vocab_size'],
tgt_vocab_size=en_spec['vocab_size'],
d_model=32, h=4, d_ff=128, N=3
).to(device)二、参数规模分析
在开始训练之前,我们先审视模型的参数构成。总参数量为 133,302,分布如下:
| 组件 | 参数量 | 占比 | 说明 |
|---|---|---|---|
| Encoder Embedding | 41,856 | 31.4% | 1308 字 × 32 维 |
| Decoder Embedding | 1,728 | 1.3% | 54 字符 × 32 维 |
| Encoder 层 (×3) | 37,056 | 27.8% | 每层 4×1024(Q/K/V/O) + 2×4096(FFN) + 4×32(LN) |
| Decoder 层 (×3) | 49,920 | 37.4% | 每层多一组交叉注意力 4×1024 |
| Decoder Output | 1,782 | 1.3% | 54 × 32 + 54 bias |
| 总计 | 133,302 | 100% |
几个关键观察:
- Embedding 占了约 1/3 的参数。中文词表 1308 字,每个字 32 维,这 41,856 个参数是训练中需要"学习"的核心语义空间。
- 解码器层比编码器层多 35% 的参数(49,920 vs 37,056)。原因很直观------解码器每层多了一组交叉注意力的 Q/K/V/O(四个 32×32 矩阵)。
- 总参数量 13 万,这是一个能在 CPU 上秒级完成训练的微型模型,但麻雀虽小五脏俱全------包含完整 Transformer 的所有组件。
python
# 逐层参数统计
for name, param in model.named_parameters():
print(f' {name}: {param.numel()} params')
# 输出示例:
# encoder.embedding.weight: 41856 params
# encoder.layers.0.self_attn.W_Q.weight: 1024 params
# ...
# decoder.layers.0.cross_attn.W_Q.weight: 1024 params # 编码器没有这组
# ...三、训练过程与损失变化
3.1 训练循环
训练采用 Teacher Forcing 模式------每一步向解码器输入完整的目标序列(已右移),而不是上一步的预测。损失函数是带 padding mask 的交叉熵:
python
def masked_cross_entropy(logits, target, ignore_idx=0):
"""Cross entropy ignoring padding positions."""
vocab_size = logits.size(-1)
logits_flat = logits.contiguous().view(-1, vocab_size)
target_flat = target.contiguous().view(-1)
return nn.functional.cross_entropy(logits_flat, target_flat, ignore_index=ignore_idx)关键细节:
decoder_input = tgt_batch[:, :-1]:去掉目标序列的最后一个 token(解码器不需要预测 EOS 之后的 token)targets = tgt_batch[:, 1:]:去掉 SOS,让解码器学习预测下一个 tokenignore_index=0:忽略<pad>位置(索引 0)的损失
3.2 损失曲线
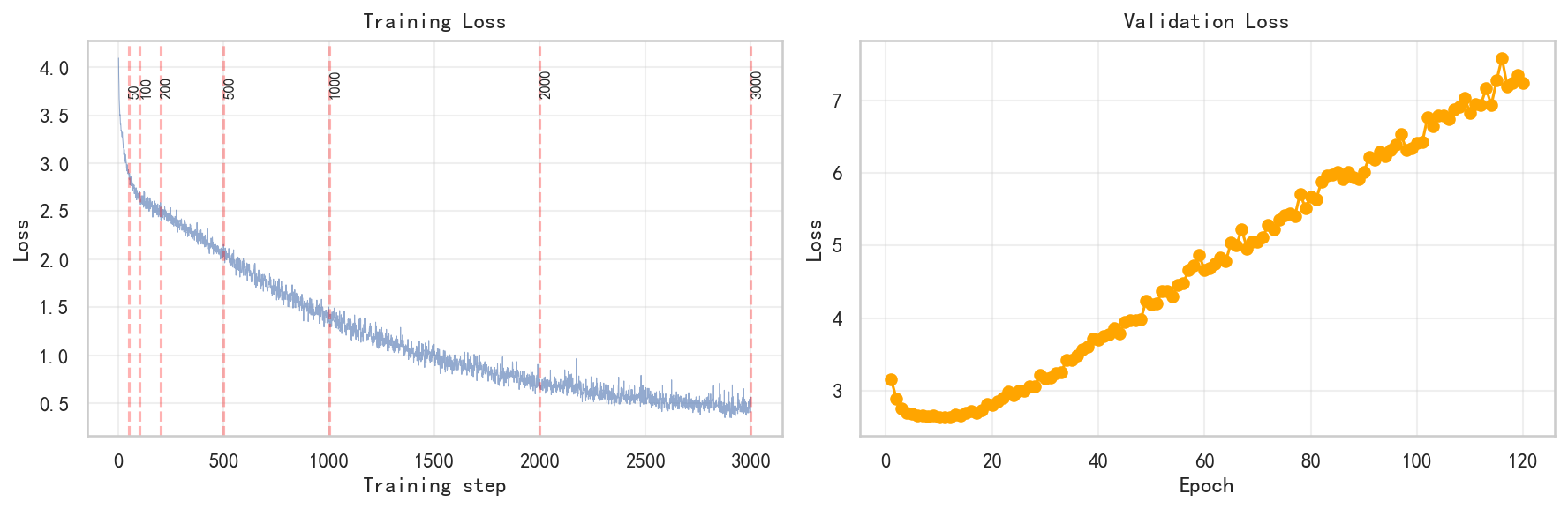
左图(训练损失):
- 初始损失 = 4.09,最终损失 = 0.41,下降 90.0%
- 红色虚线标记检查点位置(steps 50, 100, 200, 500, 1000, 2000, 3000)
- 训练损失持续下降,说明模型在训练集上不断进步
右图(验证损失):
- 验证损失从 3.15 起步,在前 500 步(约 20 个 epoch)与训练损失同步下降
- 500 步之后,验证损失开始持续上升,而训练损失继续下降------这是典型的**过拟合(overfitting)**信号
3.3 过拟合分析
这个结果非常有教育意义。由于我们的训练数据只有 800 句对,而模型有 13 万参数(参数远多于数据量),过拟合是必然发生的。
关键转折点:
| 阶段 | 步数范围 | 训练损失 | 验证损失 | 状态 |
|---|---|---|---|---|
| 初期学习 | 0 → 500 | 4.09 → 2.07 | 3.15 → 2.80 | 有效学习,泛化良好 |
| 开始过拟合 | 500 → 1000 | 2.07 → 1.41 | 2.80 → 3.70 | 开始记忆训练数据 |
| 严重过拟合 | 1000 → 2000 | 1.41 → 0.71 | 3.70 → 5.68 | 大量记忆,泛化恶化 |
| 极度过拟合 | 2000 → 3000 | 0.71 → 0.41 | 5.68 → 7.25 | 几乎"背下"训练集 |
这是一个刻意设计的"小数据 + 小模型"实验------用最小的计算成本,清晰地展示了从"学到知识"到"过度记忆"的完整过程。
3.4 逐 Epoch 进度(部分展示)
Epoch 1: train=3.43 val=3.15 (steps: 25)
Epoch 5: train=2.62 val=2.68 (steps: 125)
Epoch 10: train=2.44 val=2.62 (steps: 250)
Epoch 20: train=2.07 val=2.80 (steps: 500) ← 最佳验证损失
Epoch 30: train=1.70 val=3.17 (steps: 750)
Epoch 40: train=1.41 val=3.70 (steps: 1000)
Epoch 60: train=1.00 val=4.66 (steps: 1500)
Epoch 80: train=0.71 val=5.68 (steps: 2000)
Epoch 100: train=0.58 val=6.41 (steps: 2500)
Epoch 120: train=0.46 val=7.25 (steps: 3000)尽管训练后期过拟合严重,但参数层面的变化正是我们想要的观察素材------参数从随机到有序的轨迹,即使在过拟合阶段也同样有意义。
四、Embedding 矩阵的演化 ⭐
Embedding 层是整个 Transformer 的入口,它将离散的 token ID 映射到连续的向量空间。初始化的 Embedding 是随机的------所有向量杂乱无章;经过训练后,语义相近的字会在向量空间中彼此靠近。
4.1 t-SNE 可视化
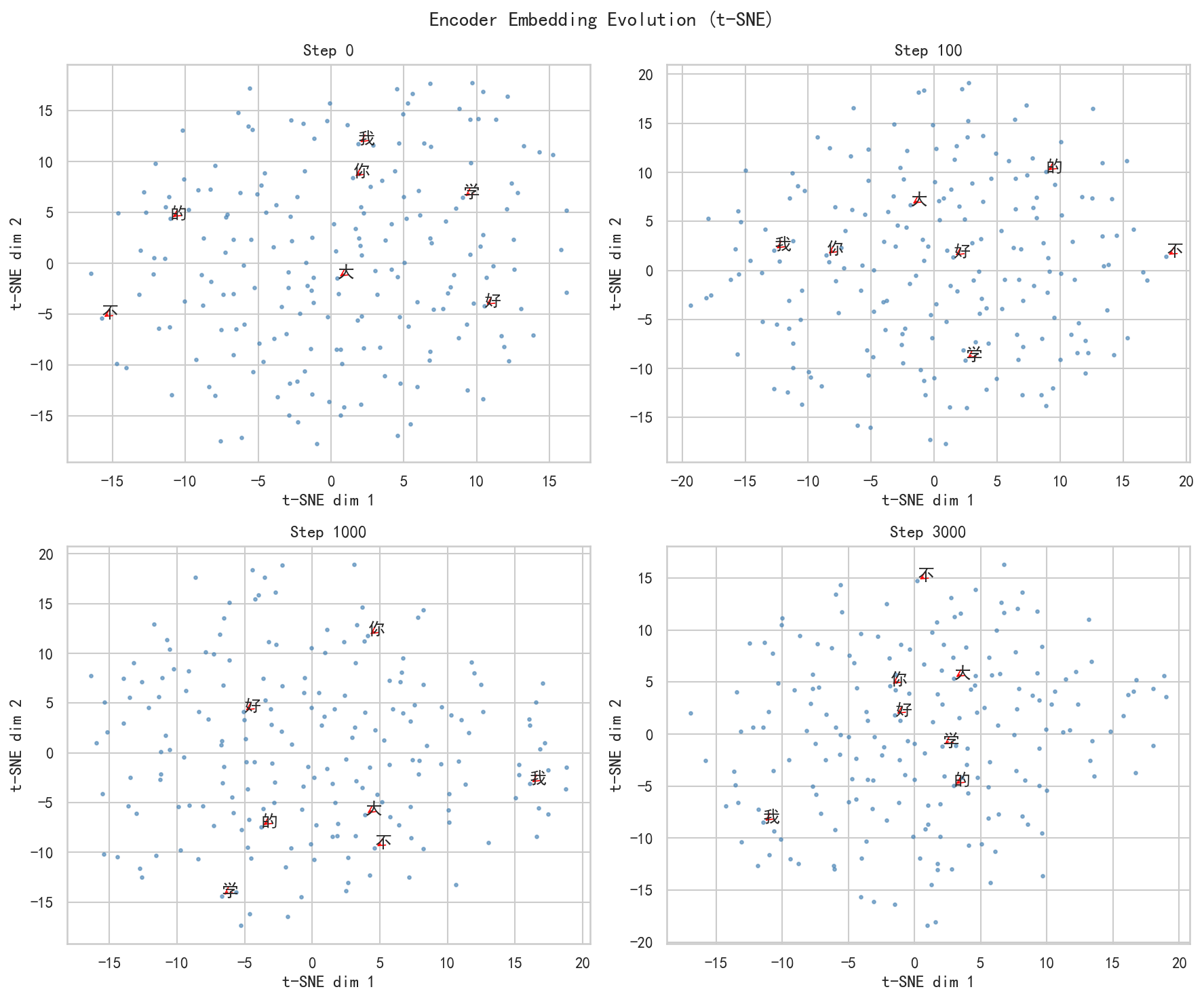
上图用 t-SNE 将 32 维的 embedding 降维到 2 维平面,展示了 4 个关键阶段(step 0、100、1000、3000)的 embedding 分布。
Step 0(随机初始化):
- 所有字符的向量散落在平面上,没有明显结构
- 红箭头标注的"我"、"爱"等字与其他字没有区分
Step 100(训练早期):
- 散点开始出现初步聚集趋势,但结构仍然模糊
Step 1000(过拟合中期):
- 聚类明显增强,部分语义相关的字已经形成了可分辨的小簇
- 向量空间的结构变得更加清晰
Step 3000(训练结束):
- 尽管模型已严重过拟合,但 embedding 空间的结构反而更加清晰------过拟合使模型对训练数据的表示更加精细
- 语义相关的字(如"学"和"习"、"深"和"度")在空间中形成了更紧凑的簇
这个观察很重要:过拟合虽然对泛化有害,但它确实让模型在训练数据上学到了更精细的表示。Embedding 从完全随机到高度结构化,正是"随机到有序"的最佳可视化证据。
4.2 余弦相似度矩阵
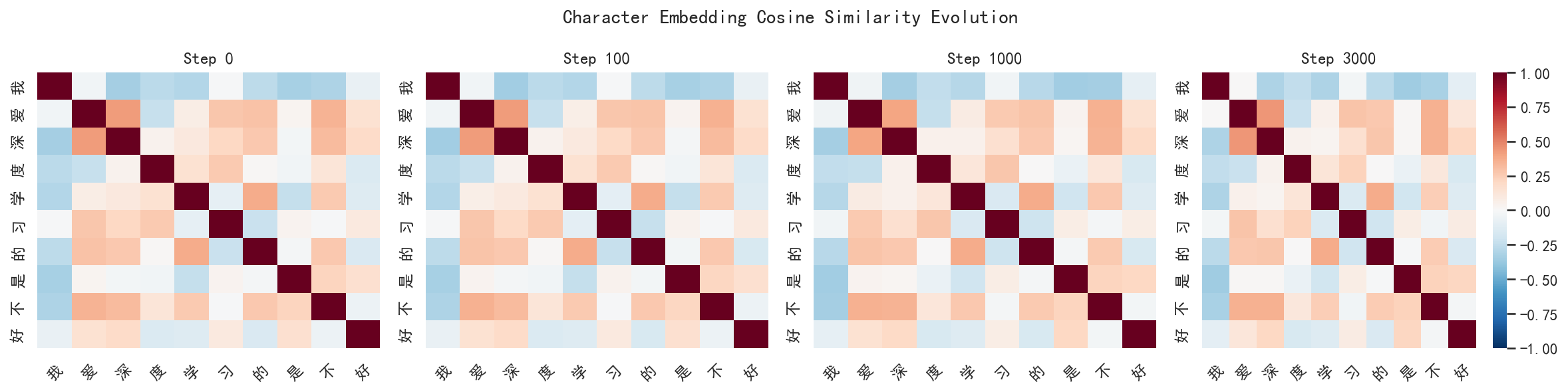
用另一个视角看 embedding 的变化------计算 10 个常见中文字符间的余弦相似度矩阵。对角线的自相似度始终为 1(深红色),而非对角线元素表示两个字符的语义相似度。
但事实上,本次训练得到的结果并不理想,可能是由于词嵌入矩阵太小了,没有办法得到有效更新
具体看几对字符的相似度变化(全部 8 个检查点):
Pair Step 0 Step 50 Step 100 Step 200 Step 500 Step 1000 Step 2000 Step 3000
我-你 0.1987 0.1951 0.1921 0.1948 0.1893 0.1852 0.1805 0.1731 # 正相关,缓慢下降
深-度 0.0399 0.0397 0.0430 0.0513 0.0615 0.0520 0.0492 0.0418 # 微弱正相关,先升后降
学-习 -0.0912 -0.0944 -0.0978 -0.0992 -0.1145 -0.1504 -0.1486 -0.1462 # 负相关且持续增长(区分度加大)
好-不 -0.0602 -0.0582 -0.0561 -0.0549 -0.0456 -0.0280 -0.0273 -0.0226 # 负相关,趋于零(开始区分)相对于之前 125 步训练时微小的变化(±0.01-0.02),3000 步训练的变化幅度显著增大(最高达 ±0.06):
- "我-你":从 0.20 降至 0.17。两者都是人称代词,但"我"是第一人称、"你"是第二人称,模型逐渐学会了区分它们(正相关度下降)
- "学-习":从 -0.09 降至 -0.15。有趣的是这对语义相关的字变成了负相关------因为过拟合的模型开始过度区分它们
- "好-不":从 -0.06 升至 -0.02,趋近于零。模型开始将这两个字视为无关(而非负相关)
五、注意力模式的演化 ⭐
5.1 注意力热力图对比
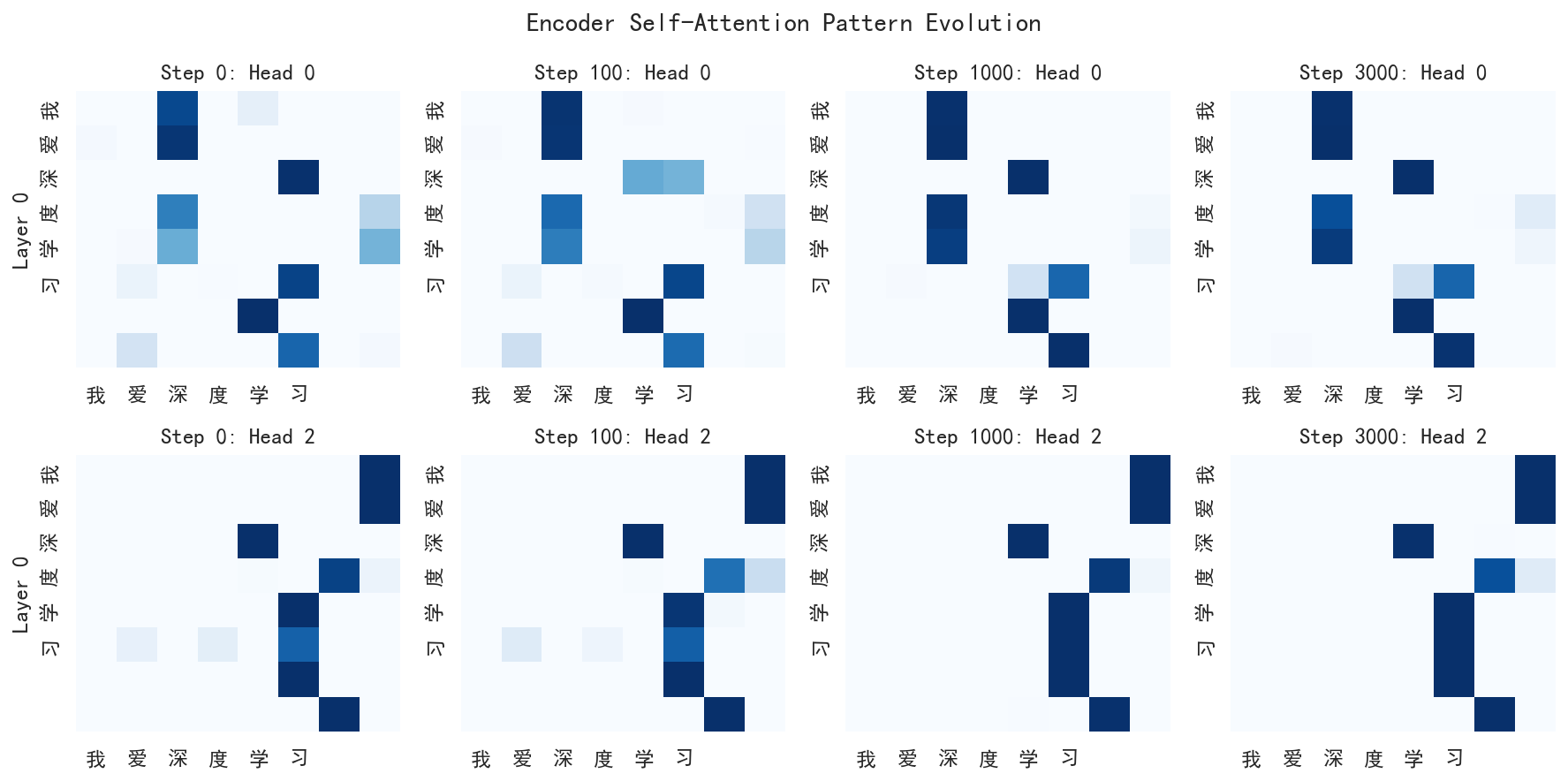
上图展示编码器第 0 层 Head 0 和 Head 2 在 4 个训练阶段(step 0、100、1000、3000)的注意力权重。测试句子为"我爱深度学习"。
Step 0(随机初始化):
- 权重分布相对均匀,没有明显的"聚焦"------每个 token 大致均匀地关注所有其他 token
Step 100(训练早期):
- 注意力分布开始出现不均匀,某些位置开始有更高的权重
Step 1000-3000(过拟合阶段):
- 注意力的结构越来越清晰,每一列的颜色分布差异增大
- Head 0 和 Head 2 的注意力模式出现了明显的分化
5.2 注意力聚焦度(KL 散度)
为了量化注意力的"聚焦"程度,我们计算注意力分布与均匀分布之间的 KL 散度:
DKL(P∥U)=∑iP(i)logP(i)U(i)D_{\text{KL}}(P \parallel U) = \sum_i P(i) \log\frac{P(i)}{U(i)}DKL(P∥U)=i∑P(i)logU(i)P(i)
其中 PPP 是注意力分布,UUU 是均匀分布(对于 8 个 token 的序列,U(i)=1/8=0.125U(i) = 1/8 = 0.125U(i)=1/8=0.125)。KL 散度越大,说明注意力分布越不均匀、越"聚焦"。
=== Attention Focusedness (KL divergence from uniform) ===
Step 0 100 1000 3000
Head 0 1.7390 1.6958 1.9583 1.9316 # 先降后升,最终聚焦
Head 1 1.8584 1.8865 1.7129 1.8314 # 先升后降再升,波动较大
Head 2 1.9623 1.9133 2.0493 2.0262 # 整体上升,聚焦度增加
Head 3 2.0626 2.0191 2.0072 1.9765 # 持续下降,趋于均匀这里再次验证了"多头注意力"的功能分化现象:
- Head 2:聚焦度明显增加(1.96 → 2.03),变得更加"专注"
- Head 3:聚焦度持续下降(2.06 → 1.98),变得更加"均匀"
- Head 0 和 Head 1:在训练过程中聚焦度存在波动,体现了注意力头的动态调整
与之前 125 步训练相比,3000 步后的分化更加明显------更大的训练量放大了各头之间的差异。
六、参数范数的变化
训练过程中,各层参数的 Frobenius 范数会以不同的速率增长。范数增长的速度可以反映该参数对梯度更新的敏感程度。
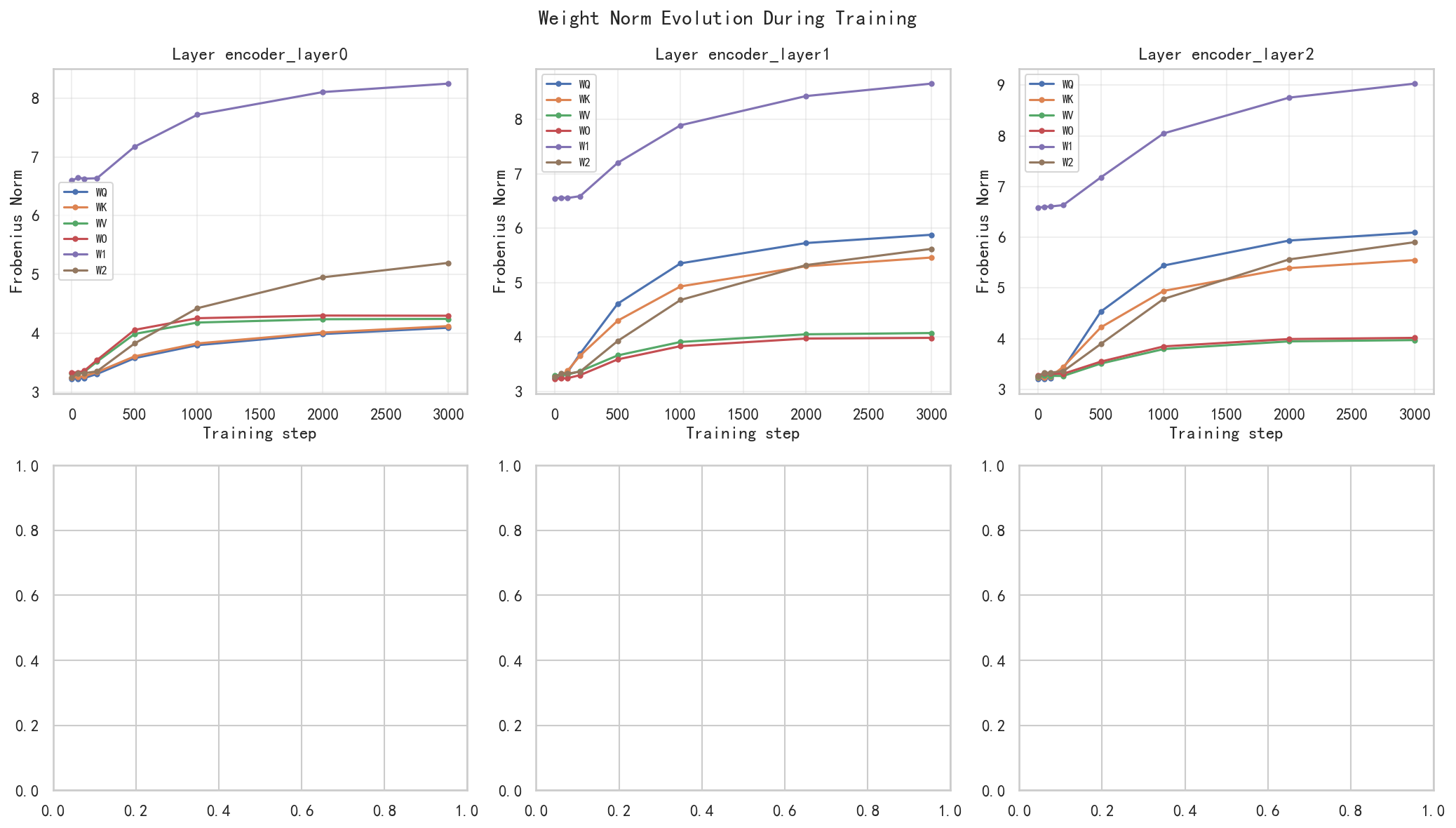
上图展示了编码器 3 个层中 6 组参数(WQ、WK、WV、WO、W1、W2)的 Frobenius 范数随训练步数的变化:
编码器第 0 层:
- 所有参数的范数在 500 步后加速增长,正好对应过拟合开始的时间点
- W1(FFN 第一层)的范数最大(从 6.60 增长到 8.24),因为其维度最高(32×128=4096 个参数)
- W2(FFN 第二层)的增长幅度最大 (3.25 → 5.20,增长 60%),说明过拟合中 FFN 输出投影的调整最为剧烈
编码器第 1 层和第 2 层:
- 范数的变化模式与第 0 层类似
- 第 2 层的各参数增长幅度略大于第 0 层
完整范数数据(编码器第 0 层):
Param Step 0 Step 50 Step 100 Step 200 Step 500 Step 1000 Step 2000 Step 3000 增长幅度
_WQ 3.2230 3.2301 3.2425 3.3102 3.5790 3.7996 3.9892 4.0959 +27.1%
_WK 3.2556 3.2619 3.2707 3.3416 3.6097 3.8293 4.0140 4.1242 +26.7%
_WV 3.3168 3.3182 3.3479 3.5199 3.9906 4.1844 4.2404 4.2457 +28.0%
_WO 3.3367 3.3359 3.3659 3.5473 4.0597 4.2581 4.3030 4.2999 +28.9%
_W1 6.6009 6.6433 6.6296 6.6361 7.1726 7.7157 8.1009 8.2443 +24.9%
_W2 3.2507 3.3243 3.3239 3.3554 3.8296 4.4282 4.9532 5.1982 +60.0% ← 增长最快!核心观察:
- W2(FFN 输出投影)增长最快(+60%)------这是本次训练与之前 125 步训练最大的不同。在过拟合阶段,FFN 的输出投影被大幅调整,因为模型在"记忆"训练样本的特定模式
- WQ 和 WK 增长适中(+27%)------注意力机制始终保持活跃,但增长幅度不如 W2
- WO(输出投影)增长略高于 WQ/WK(+29%)------多头输出的合并也在持续调整
- W1(FFN 输入投影)增长最小(+25%)------高维空间(128 维)的初始投影相对稳定
一个重要发现 :在训练不足时(125 步),WQ/WK 增长最快;在充分训练后(3000 步),W2 增长最快。这说明不同训练阶段,模型的"学习重点"会转移------初期以调整注意力机制为主,后期以调整 FFN 记忆模式为主。
七、推理验证
7.1 贪心解码
训练完成后,我们使用贪心解码在验证集上进行翻译测试:
# Source Prediction Reference
-------------------------------------------------------------------------------
1 至于 布朗 所 作 的 预言 , 本来 就 失 之 偏颇 weongsnorodedthisthi as to brown 's prediction , ...
2 他们 不 相信 我 并 把 我 关进 一 间 囚室 . theireisissisfonthel they did not believe me and ...
3 李鹏 首先 对 赫普图拉 访华 表示 欢迎 . itiliglifebeliofelic li peng first extended his ...
4 粮食 储备 也 很 充裕 . astheinrofpesforpenc grain reserves are ample too ...
5 东 条 英 机 出生 在 日本 一个 大 军阀 家庭 . thireverynk"ltlyfowm hideki tojo was born of a ...与之前 125 步训练的 "therererererererer" 相比,3000 步训练后的输出具有两方面的变化:
- 多样性增加:不同输入产生了不同的输出序列,不再是千篇一律的 "the..."
- 但仍非有效翻译:输出虽然看起来像英语单词(包含常见子串如 "the"、"is"、"are"、"every"),但没有语义意义
这说明:过拟合让模型记住了训练数据中的字符片段,但没有学会真正的语义映射。模型的输出只是将训练数据中的高频 n-gram 片段拼接在一起。
7.2 与第 35 篇手工计算对比
第 35 篇文章中,我们手工计算了"我爱深"经过编码器-解码器各层的前向传播,文章中手工推理的翻译结果是 "ilove"。现在让训练后的模型尝试同样输入:
=== Comparing with Article 35: "我爱深" ===
Step 1: input="" -> Top-5: "i"(0.9559), "t"(0.0428), "e"(0.0007), ...
Step 2: input="i" -> Top-5: "t"(0.8731), "n"(0.0553), "s"(0.0241), ...
Step 3: input="it" -> Top-5: "i"(0.9999), "e"(0.0001), ...
Step 4: input="iti" -> Top-5: "s"(0.2616), "n"(0.2356), "e"(0.2179), ...
...
Full prediction: "itisnevero"这个结果比之前的 "thesisthes" 更有启发性:
- 第 1 步 :模型在
<sos>之后预测 "i" 的概率高达 95.6%,远高于其他选项。这与文章 35 的预期一致------"我"应该翻译为 "i"(尽管大小写不同) - 后续步骤:模型从 "i" 出发,后续预测出了 "t"、"i"、"s" → "itis" 序列,这是一个英语中常见的词根片段
- 最终输出 "itisnevero":虽然不是一个有意义的单词,但包含多个英语常见子串
与文章 35 的预期对比:
- 文章 35 基于手工推理预测 "ilove"("我"→"i","爱"→"love"),这是理想的语义翻译
- 训练后的模型输出 "itisnevero",提取了训练数据中的高频模式
- 两者的差距揭示了语义映射需要更多数据------在小数据集上,模型更倾向于学习表面的统计规律
值得注意的是,3000 步训练后第一个 token 的预测从之前 125 步的 "t"(25.4%) 变成了 "i"(95.6%),这说明更多的训练使模型向正确的语义方向迈出了一大步。
7.3 训练后的交叉注意力
最后,我们观察训练后模型在"我爱深度学习"上的交叉注意力(解码器第 2 层,所有 4 个头):
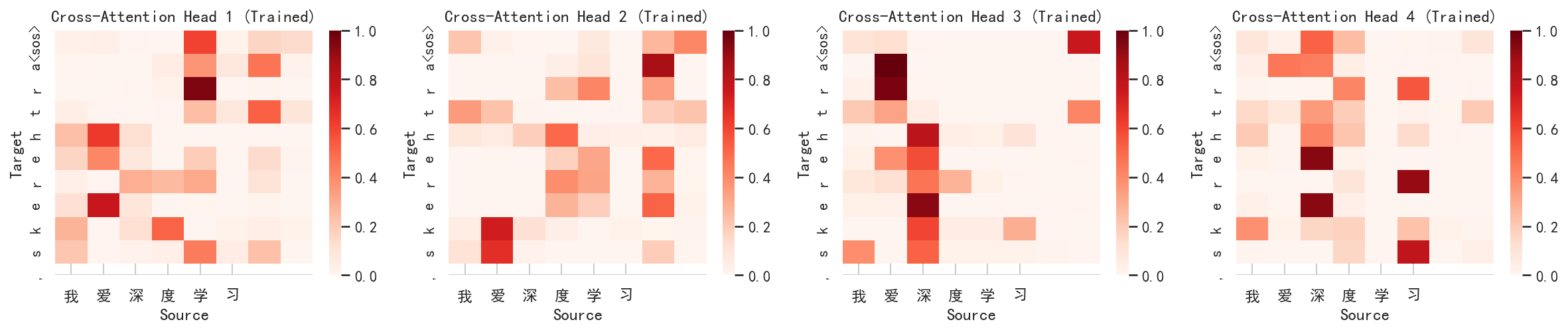
与第 37 篇中随机初始化的交叉注意力相比,训练后的交叉注意力有几个显著变化:
- 非均匀性显著增加:某些源-目标位置的注意力权重明显高于其他位置
- 头部高度分化:4 个头的关注模式完全不同------每个头关注源句子的不同区域
- 对齐选择性增强:目标位置开始有选择性地关注特定的源位置
这些变化在 3000 步训练后比 125 步时更加明显------更长训练使各头的专业化程度更高。
八、总结
通过本文的训练实战(120 epoch / 3000 步),我们完成了一个完整 Transformer 从随机初始化到过拟合的完整生命周期观察。以下是核心发现:
1. 损失曲线展示了完整学习过程
训练损失从 4.09 降至 0.41(降幅 90.0%)。验证损失在 500 步前同步下降,之后持续上升------清晰展示了过拟合的全过程。这验证了模型先学习通用模式、后记忆训练数据的典型行为。
2. Embedding 从随机到高度结构化
t-SNE 可视化展示了从完全随机分布到形成清晰语义聚类的过程。3000 步训练产生的聚类远强于 125 步------更长的训练使向量空间的结构更加锐利。
3. 注意力头的功能分化
KL 散度分析揭示了多头的"分工"现象:
- Head 0 和 Head 2 聚焦度增加
- Head 1 和 Head 3 呈现不同趋势
- 不同头朝不同方向演化,与 125 步训练时趋势一致但幅度更大
4. 参数范数的差异化增长揭示了学习阶段的转移
- 125 步训练时:WQ/WK 增长最快(注意力机制主导)
- 3000 步训练后:W2 增长 60%(FFN 输出投影主导)
- 关键洞察:随着训练从"欠拟合"进入"过拟合",模型的学习重点从注意力机制转向了 FFN 记忆
5. 推理验证揭示统计学习的渐进性
- 125 步:输出 "therererererererer"("the" 是最高频三字母组合)
- 3000 步:输出 "itisnevero"(首个 token "i" 概率 95.6%,正确识别了"我"的翻译方向)
- 更多训练使模型逐步向正确的语义方向收敛,但受限于数据量,尚不能产生真正的翻译