读完本文,你将理解 CrewAI 的核心概念,掌握基本用法,并能独立完成一个"AI 写作团队"小项目。
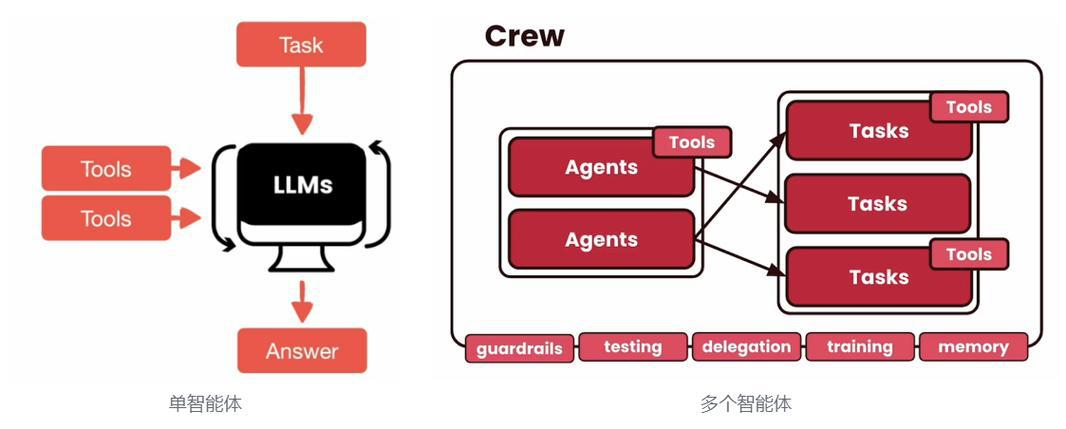
一、什么是 CrewAI?
想象一下公司里的团队协作:产品经理定义需求,工程师写代码,测试同学做验收。每个人有自己的角色、专长和分工,最终合力完成一个项目。
CrewAI 做的就是同样的事情,只不过团队成员换成了 AI Agent(智能体)。
CrewAI 是一个开源的 Python 框架,专门用来编排多个 AI Agent 协同工作,解决复杂任务。它的核心理念很简单:
- 每个 Agent 有自己的角色 (role)和目标(goal)
- Agent 接收任务(Task),输出结果
- 多个 Agent 组成一个团队(Crew),按流程协作
与其他框架相比,CrewAI 的优点是:独立轻量(不依赖 LangChain)、API 简洁、上手快。
二、安装与环境配置
安装 CrewAI
CrewAI 推荐使用 uv 作为包管理器(速度比 pip 快很多):
bash
# 先安装 uv(如果没有的话)
pip install uv
# 用 uv 安装 crewai
uv tool install crewai
# 或者直接用 pip
pip install crewai
pip install crewai[tools] # 同时安装官方工具集配置 API Key
CrewAI 默认使用 OpenAI 的模型,需要配置 API Key:
bash
export OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxx"或者在项目根目录创建 .env 文件:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx然后在代码里加载:
python
from dotenv import load_dotenv
load_dotenv()三、核心概念
CrewAI 有四个核心概念,理解了这四个,就掌握了大部分用法。
1. Agent(智能体)
Agent 是"干活的人"。每个 Agent 有:
role:角色名,比如"资深新闻记者"goal:目标,这个 Agent 想做什么backstory:背景故事,帮助模型更好地理解角色tools:这个 Agent 能用哪些工具llm:使用哪个语言模型
python
from crewai import Agent
researcher = Agent(
role="资深研究员",
goal="收集并分析关于{topic}的最新信息",
backstory="你是一位拥有10年经验的研究员,擅长从各种渠道获取准确信息并进行深度分析。",
verbose=True, # 打印执行过程
allow_delegation=False, # 是否允许将任务分配给其他 Agent
)2. Task(任务)
Task 是"要做的具体事情"。每个 Task 有:
description:任务描述,越详细越好expected_output:期望的输出格式agent:由哪个 Agent 来完成context:依赖哪些其他 Task 的输出(可选)
python
from crewai import Task
research_task = Task(
description="研究关于{topic}的最新动态,找出3~5个关键洞察点。",
expected_output="一份包含关键洞察的研究报告,每个洞察点用1~2句话说明。",
agent=researcher,
)3. Crew(团队)
Crew 是"整个项目团队",负责把 Agent 和 Task 组织起来按顺序执行。
python
from crewai import Crew, Process
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, # 顺序执行
verbose=True,
)4. Process(流程)
流程决定 Task 的执行顺序:
Process.sequential:顺序执行,一个 Task 完成后交给下一个Process.hierarchical:层级执行,有一个 Manager Agent 负责分配和协调任务
对于初学者,sequential 就够用了。
四、第一个 CrewAI 程序
我们来做一个最简单的例子:两个 Agent 合作写一篇文章,第一个负责研究,第二个负责写作。
python
import os
from crewai import Agent, Task, Crew, Process
from dotenv import load_dotenv
load_dotenv()
# 1. 定义 Agent
researcher = Agent(
role="研究员",
goal="深入研究给定主题,提供有价值的洞察",
backstory="你是一位经验丰富的研究员,善于从复杂信息中提炼核心要点。",
verbose=True,
allow_delegation=False,
)
writer = Agent(
role="内容作者",
goal="基于研究结果撰写清晰易懂的文章",
backstory="你是一位专业的科技博主,擅长将复杂的技术内容转化为大众能读懂的文章。",
verbose=True,
allow_delegation=False,
)
# 2. 定义 Task
research_task = Task(
description="研究「大语言模型在医疗领域的应用」,整理出5个最重要的应用方向,每个方向给出具体案例。",
expected_output="一份结构化的研究报告,包含5个应用方向及对应案例。",
agent=researcher,
)
write_task = Task(
description="基于研究报告,撰写一篇面向普通读者的科普文章,约500字,语言生动有趣。",
expected_output="一篇500字左右的科普文章,包含引人入胜的标题和清晰的段落结构。",
agent=writer,
context=[research_task], # 依赖研究任务的输出
)
# 3. 创建 Crew 并运行
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential,
verbose=True,
)
result = crew.kickoff()
print("\n========== 最终结果 ==========")
print(result)运行后,你会看到两个 Agent 依次工作,最终输出一篇完整的科普文章。
五、使用工具(Tools)
工具是让 Agent 能够做事的关键。没有工具,Agent 只能依靠模型的内部知识;有了工具,Agent 可以搜索网络、读写文件、调用 API 等。
使用内置工具
CrewAI 提供了很多开箱即用的工具:
python
from crewai_tools import SerperDevTool, FileReadTool, WebsiteSearchTool
# 网络搜索工具(需要 SERPER_API_KEY)
search_tool = SerperDevTool()
# 文件读取工具
file_tool = FileReadTool(file_path="./data.txt")
# 网页内容抓取工具
web_tool = WebsiteSearchTool()把工具分配给 Agent:
python
researcher = Agent(
role="研究员",
goal="通过网络搜索获取最新信息",
backstory="你是一位善于利用互联网收集信息的研究员。",
tools=[search_tool, web_tool], # 分配工具
verbose=True,
)自定义工具
自定义工具非常简单,用装饰器就能搞定:
python
from crewai.tools import tool
@tool("天气查询工具")
def get_weather(city: str) -> str:
"""查询指定城市的天气情况。输入城市名称,返回天气信息。"""
# 这里可以调用真实的天气 API
# 示例返回
return f"{city}今天天气晴朗,气温22℃,适合出行。"然后像内置工具一样使用:
python
agent = Agent(
role="旅行助手",
goal="帮用户规划旅行",
backstory="你是一位专业的旅行规划师。",
tools=[get_weather],
)六、使用变量(输入参数)
前面代码里的 {topic} 是变量占位符,可以在运行时动态传入:
python
result = crew.kickoff(inputs={"topic": "量子计算"})这样同一套 Crew 可以复用,只需要改变输入内容。
七、使用不同的 LLM
CrewAI 不绑定 OpenAI,你可以换用任何支持的模型。
使用 Claude(Anthropic)
python
from crewai import Agent, LLM
llm = LLM(
model="claude-opus-4-5",
api_key="your-anthropic-api-key"
)
agent = Agent(
role="研究员",
goal="深度研究各类话题",
backstory="你是一位博学的研究员。",
llm=llm,
)使用 Ollama(本地模型)
python
llm = LLM(
model="ollama/llama3",
base_url="http://localhost:11434"
)为不同 Agent 指定不同模型
你可以为每个 Agent 单独指定模型,比如让"Manager"用更强的模型,"Worker"用便宜的模型:
python
from crewai import LLM
powerful_llm = LLM(model="gpt-4o")
fast_llm = LLM(model="gpt-4o-mini")
manager = Agent(role="项目经理", llm=powerful_llm, ...)
worker = Agent(role="执行员", llm=fast_llm, ...)八、Memory(记忆)
默认情况下,Agent 在不同任务之间不保留记忆。开启记忆功能后,Agent 能记住之前的对话和任务结果。
python
crew = Crew(
agents=[agent1, agent2],
tasks=[task1, task2],
memory=True, # 开启记忆
embedder={
"provider": "openai",
"config": {"model": "text-embedding-3-small"}
}
)CrewAI 支持三种记忆:
- 短期记忆(Short-term Memory):当前 Crew 执行过程中的上下文
- 长期记忆(Long-term Memory):跨多次执行的持久化记忆
- 实体记忆(Entity Memory):记录任务中涉及的关键实体(人名、地名等)
九、输出结果的格式化
有时候你希望 Task 的输出是结构化数据(比如 JSON),而不是纯文本。可以用 Pydantic 模型来定义输出格式:
python
from pydantic import BaseModel
from crewai import Task
class ArticleOutput(BaseModel):
title: str
summary: str
word_count: int
tags: list[str]
task = Task(
description="写一篇关于AI的文章",
expected_output="包含标题、摘要、字数和标签的文章信息",
agent=writer,
output_pydantic=ArticleOutput, # 指定输出格式
)
crew = Crew(agents=[writer], tasks=[task])
result = crew.kickoff()
# 直接访问结构化字段
print(result.pydantic.title)
print(result.pydantic.tags)十、用 CLI 快速创建项目
CrewAI 提供了命令行工具,可以快速生成项目模板:
bash
# 创建新项目
crewai create crew my_project
# 项目结构如下:
# my_project/
# ├── src/
# │ └── my_project/
# │ ├── config/
# │ │ ├── agents.yaml ← 在这里定义 Agent
# │ │ └── tasks.yaml ← 在这里定义 Task
# │ ├── crew.py ← Crew 的组装逻辑
# │ └── main.py ← 程序入口
# ├── .env
# └── pyproject.toml用 YAML 文件定义 Agent 和 Task 更加清晰:
agents.yaml
yaml
researcher:
role: "资深研究员"
goal: "深度研究{topic}的最新动态"
backstory: "你是一位拥有10年经验的行业研究员,善于发现趋势和洞察。"
writer:
role: "内容创作者"
goal: "将研究成果转化为引人入胜的内容"
backstory: "你是一位专业的科技博主,文笔流畅,逻辑清晰。"tasks.yaml
yaml
research_task:
description: "深入研究{topic},找出最新趋势和关键洞察"
expected_output: "一份包含5个关键洞察的研究报告"
agent: researcher
write_task:
description: "基于研究报告,撰写一篇500字的科普文章"
expected_output: "一篇面向大众的科普文章"
agent: writer
python
from crewai import Agent, Task, Crew, Process
from crewai.project import CrewBase, agent, task, crew
@CrewBase
class MyProjectCrew:
agents_config = "config/agents.yaml"
tasks_config = "config/tasks.yaml"
@agent
def researcher(self) -> Agent:
return Agent(config=self.agents_config["researcher"], verbose=True)
@agent
def writer(self) -> Agent:
return Agent(config=self.agents_config["writer"], verbose=True)
@task
def research_task(self) -> Task:
return Task(config=self.tasks_config["research_task"])
@task
def write_task(self) -> Task:
return Task(config=self.tasks_config["write_task"])
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)运行项目:
bash
cd my_project
crewai run十一、实战:AI 写作团队
把上面的东西综合起来,做一个实用的AI 写作团队:接收一个话题,自动完成研究 → 写作 → 校对三个步骤,输出一篇完整文章。
python
import os
from crewai import Agent, Task, Crew, Process
from crewai.tools import tool
from dotenv import load_dotenv
load_dotenv()
# ====== 自定义工具 ======
@tool("字数统计工具")
def count_words(text: str) -> str:
"""统计文本的字数。输入文本,返回字数统计结果。"""
count = len(text.replace(" ", ""))
return f"该文本共 {count} 个字符(不含空格)。"
# ====== 定义 Agent ======
researcher = Agent(
role="资深研究员",
goal="针对{topic}进行全面深入的研究,提供准确可靠的信息",
backstory=(
"你是一位拥有15年经验的行业研究员,曾在多家顶级咨询公司工作。"
"你擅长快速获取信息、识别关键趋势,并将复杂信息梳理成清晰的结论。"
),
verbose=True,
allow_delegation=False,
)
writer = Agent(
role="专业内容作者",
goal="将研究成果转化为一篇结构清晰、语言生动的文章",
backstory=(
"你是一位科技媒体的资深编辑,善于用通俗易懂的语言解释复杂概念。"
"你的文章总是兼具深度和可读性,深受读者喜爱。"
),
verbose=True,
allow_delegation=False,
)
editor = Agent(
role="文章校对编辑",
goal="检查文章的逻辑性、准确性和可读性,确保文章质量",
backstory=(
"你是一位严格的编辑,有着敏锐的语感和严谨的逻辑思维。"
"你会指出文章中的逻辑漏洞、语言问题,并给出具体的修改建议。"
),
tools=[count_words],
verbose=True,
allow_delegation=False,
)
# ====== 定义 Task ======
research_task = Task(
description=(
"请深入研究「{topic}」这个话题,完成以下工作:\n"
"1. 梳理该话题的核心概念和背景\n"
"2. 找出5个最重要的发展趋势或应用场景\n"
"3. 列举2~3个具体的实际案例\n"
"4. 总结当前面临的主要挑战和未来展望"
),
expected_output=(
"一份结构化的研究报告,包含:核心概念、5个关键趋势/场景、具体案例、挑战与展望。"
),
agent=researcher,
)
write_task = Task(
description=(
"基于研究员提供的研究报告,撰写一篇完整的科普文章:\n"
"- 字数:600~800字\n"
"- 包含一个吸引人的标题\n"
"- 有清晰的开头、中间和结尾结构\n"
"- 语言面向普通读者,避免过多专业术语\n"
"- 每个段落不超过150字,保持节奏感"
),
expected_output="一篇完整的科普文章,包含标题和正文,字数在600~800字之间。",
agent=writer,
context=[research_task],
)
edit_task = Task(
description=(
"仔细阅读作者写的文章,进行全面的编辑校对:\n"
"1. 使用字数统计工具确认字数是否符合要求(600~800字)\n"
"2. 检查逻辑结构是否清晰\n"
"3. 检查语言是否通顺易懂\n"
"4. 如有问题,直接给出修改后的完整文章\n"
"5. 如果文章质量不错,做小幅润色后输出最终版本"
),
expected_output="经过编辑校对的最终文章,包含标题和正文,质量达到发布标准。",
agent=editor,
context=[write_task],
)
# ====== 创建 Crew 并运行 ======
crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, write_task, edit_task],
process=Process.sequential,
verbose=True,
)
# 运行,传入话题
result = crew.kickoff(inputs={"topic": "AI Agent 在软件开发中的应用"})
print("\n" + "=" * 60)
print("✅ 最终文章")
print("=" * 60)
print(result)十二、常用配置速查
Agent 常用参数
| 参数 | 说明 | 默认值 |
|---|---|---|
role |
角色名称(必填) | --- |
goal |
角色目标(必填) | --- |
backstory |
背景故事(必填) | --- |
llm |
使用的语言模型 | gpt-4o |
tools |
工具列表 | \[\] |
verbose |
是否打印执行过程 | False |
allow_delegation |
是否允许委托任务给其他 Agent | True |
max_iter |
最大迭代次数 | 25 |
memory |
是否开启记忆 | False |
Task 常用参数
| 参数 | 说明 |
|---|---|
description |
任务描述(必填) |
expected_output |
期望输出(必填) |
agent |
执行该任务的 Agent(必填) |
context |
依赖的其他 Task 列表 |
tools |
覆盖 Agent 的工具(可选) |
output_file |
将输出保存到文件 |
output_pydantic |
用 Pydantic 模型定义结构化输出 |
callback |
任务完成后的回调函数 |
Crew 常用参数
| 参数 | 说明 |
|---|---|
agents |
Agent 列表(必填) |
tasks |
Task 列表(必填) |
process |
执行流程(sequential / hierarchical) |
verbose |
是否打印详细信息 |
memory |
是否开启记忆 |
max_rpm |
每分钟最大请求数(限速) |
manager_llm |
hierarchical 模式下 Manager 使用的模型 |
十三、常见问题
Q: Agent 陷入死循环怎么办?
设置 max_iter 限制最大迭代次数,或者给 Task 描述写得更清晰具体。
Q: 如何节省 API 费用?
对轻量任务使用 gpt-4o-mini 或本地 Ollama 模型,只有关键任务才用 GPT-4o。
Q: Agent 的输出结果不稳定怎么办?
在 Task 的 expected_output 里写清楚格式要求,必要时用 output_pydantic 强制结构化输出。
Q: 多个 Agent 之间如何传递信息?
通过 context 参数:Task(context=[前置task]) 会自动把前置任务的输出作为当前任务的上下文。
官方文档:docs.crewai.com
GitHub:github.com/crewAIInc/crewAI
社区论坛:community.crewai.com