
跨会话持久化
Checkpoint 的局限性
此前我们已经完整讲解完线程级持久化的各类基础用法,接下来开始学习跨会话持久化。
之前我们就区分过线程级持久化与跨会话持久化的概念,现在再来回顾巩固。
-
线程级持久化的作用,是保障单次对话拥有记忆能力。举个例子,对话中告知 AI 自己名叫小明,后续再次询问身份,AI 可以准确应答,这背后正是依靠 LangGraph 里的状态快照 机制实现记忆留存。
-
而跨会话场景下就会出现记忆断层。如果重新开启一轮全新对话,即便此前已经告知过姓名,新会话里再询问身份,AI 就无法识别,遗忘掉过往信息。我们可以通过代码复现这一现象。
问题场景:跨会话信息丢失
LangGraph 的 Checkpoint 机制提供了强大的短期记忆能力,它能够:
- 自动保存工作流每个步骤的状态快照
- 维持单次对话的完整上下文
- 隔离不同线程(Thread)的执行状态
简单示例(仅调用了下 LLM):
python
import operator
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# 定义状态
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
# 定义模型节点
model = init_chat_model("gpt-4o-mini", temperature=0)
def llm_call(state: dict):
"""LLM调用"""
return {
"messages": [
model.invoke([SystemMessage(content="你是一个乐于助人的助手。")]
+ state["messages"])
]
}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("llm_call", llm_call)
builder.add_edge(START, "llm_call")
builder.add_edge("llm_call", END)
graph = builder.compile(checkpointer=InMemorySaver())检查点可以完美处理会话内记忆,如下所示:
python
config1 = {"configurable": {"thread_id": "1"}}
# 第一次对话
result1 = graph.invoke({"messages": [HumanMessage(content="我爱吃汉堡,推荐一家餐厅")]}, config1)
# AI记得:你爱吃汉堡
result2 = graph.invoke({"messages": [HumanMessage(content="我爱吃什么?")]}, config1)
result2["messages"][-1].pretty_print()
# 输出: 你提到你爱吃汉堡,所以可以推测你喜欢美味的快餐和丰富的口味组合。如果你有其他喜欢的食物或菜系,也可以告诉我,我可以为你推荐更多相关的美食或餐厅!想象一个多会话的 AI 助手场景:
- 星期一,用户首次对话
- 星期二,用户开启一个新对话
python
# 星期一,用户首次对话
config1 = {"configurable": {"thread_id": "day_1"}}
result1 = graph.invoke({"messages": [HumanMessage(content="我爱吃汉堡,推荐一家餐厅")]}, config1)
# 星期二,用户开启一个新对话
config2 = {"configurable": {"thread_id": "day_2"}}
result2 = graph.invoke({"messages": [HumanMessage(content="我爱吃什么?")]}, config2)
result2["messages"][-1].pretty_print()
# 输出: 我不知道你具体喜欢吃什么,但可以根据一些常见的食物类型来猜测。比如,有些人喜欢甜食,如蛋糕和冰淇淋;有些人喜欢咸食,如薯条和披萨;还有些人喜欢健康的食物,如沙拉和水果。你可以告诉我你喜欢的食物类型,我可以给你一些推荐!问题出现:AI 不记得用户喜欢汉堡!每次对话都要 "重新认识"。

现实世界的需求:从 "单次对话" 到 "终身服务"
例如一个智能客服系统,具有以下实际业务需求:
- 识别 VIP 客户,优先服务
- 避免重复询问相同问题
- 基于历史投诉优化服务

仅是检查点无法满足这些需求:
python
graph = builder.compile(checkpointer=InMemorySaver())
config1 = {"configurable": {"thread_id": "query_1"}}
result1 = graph.invoke({"messages": [HumanMessage(content="我的账户被冻结了")]}, config1)
# 用户第一次投诉账户问题,已解决。智能客服的如下过程:
# - 搜集用户信息
# - 了解用户问题与需求
# - 处理问题
config2 = {"configurable": {"thread_id": "query_2"}}
result2 = graph.invoke({"messages": [HumanMessage(content="我的账户又被冻结了")]}, config2)
# 10天后,用户第二次投诉账户问题。
# 由于智能客服不知道用户历史,无法准确解决问题。还需再次了解前因后果编译流程时,先采用内存型检查点存储,这种存储方式仅支持单次会话、单线程范围内的记忆功能。
倘若修改线程 ID,开启全新会话再次询问身份,AI 便无法识别用户信息。这个现象直观体现出检查点线程内存储的局限性,数据仅隔离在各自线程中,跨会话访问时关键信息会直接丢失。
日常开发搭建 AI 应用时,往往需要长期留存用户关键信息,可当前的存储模式无法满足跨会话记忆需求,切换会话线程后,所有历史数据都会无法调取。
结合实际业务场景就能清晰感受到该缺陷。AI 服务不能只局限于单次对话交互,更要打造面向用户的长期服务体系,智能客服就是典型应用场景。首先系统需要识别 VIP 用户,给到优先服务权限;其次要规避重复提问,减少用户重复阐述问题的麻烦;同时还能依据历史投诉记录,持续优化服务质量。
模拟业务场景来看,用户首次反馈账户冻结问题,客服系统会依次收集用户资料、梳理问题诉求并处理故障,完整记录本次对话相关信息。时隔数日用户再次遇到同类问题,重新发起对话后,线程标识随之变更。由于新会话无法读取过往线程的存储数据,客服系统调取不到用户历史记录,没办法快速定位问题,只能重复问询信息、重新梳理诉求,极大影响使用体验。
想要解决跨会话信息丢失的问题,就需要引入跨会话持久化 ,也常被称作Store全局存储。
如何做到【共享状态】的需求模型,如精准识别客户、保留 VIP 客户关键历史记录,是智能客服系统的关键。如下图所示:
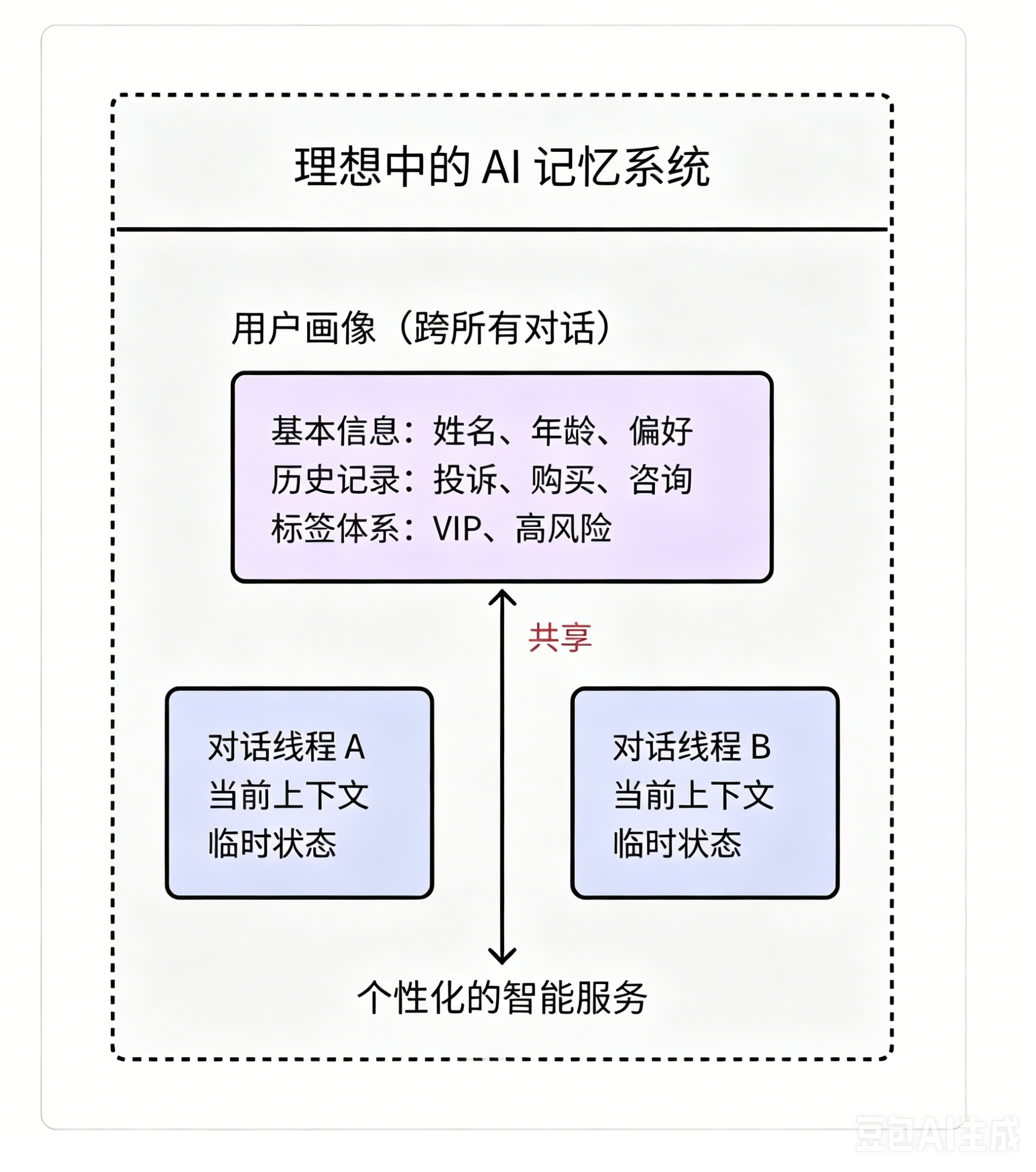
解决方案:引入 Store
Store 像是一个长期记忆仓库,支持在我们在执行过程中保存用户信息、偏好设置等长期数据,以实现不同对话间信息的持久化共享。
存储 vs 检查点
- 检查点:保存状态变化历史(时间线)
- 存储:保存结构化知识(数据库)
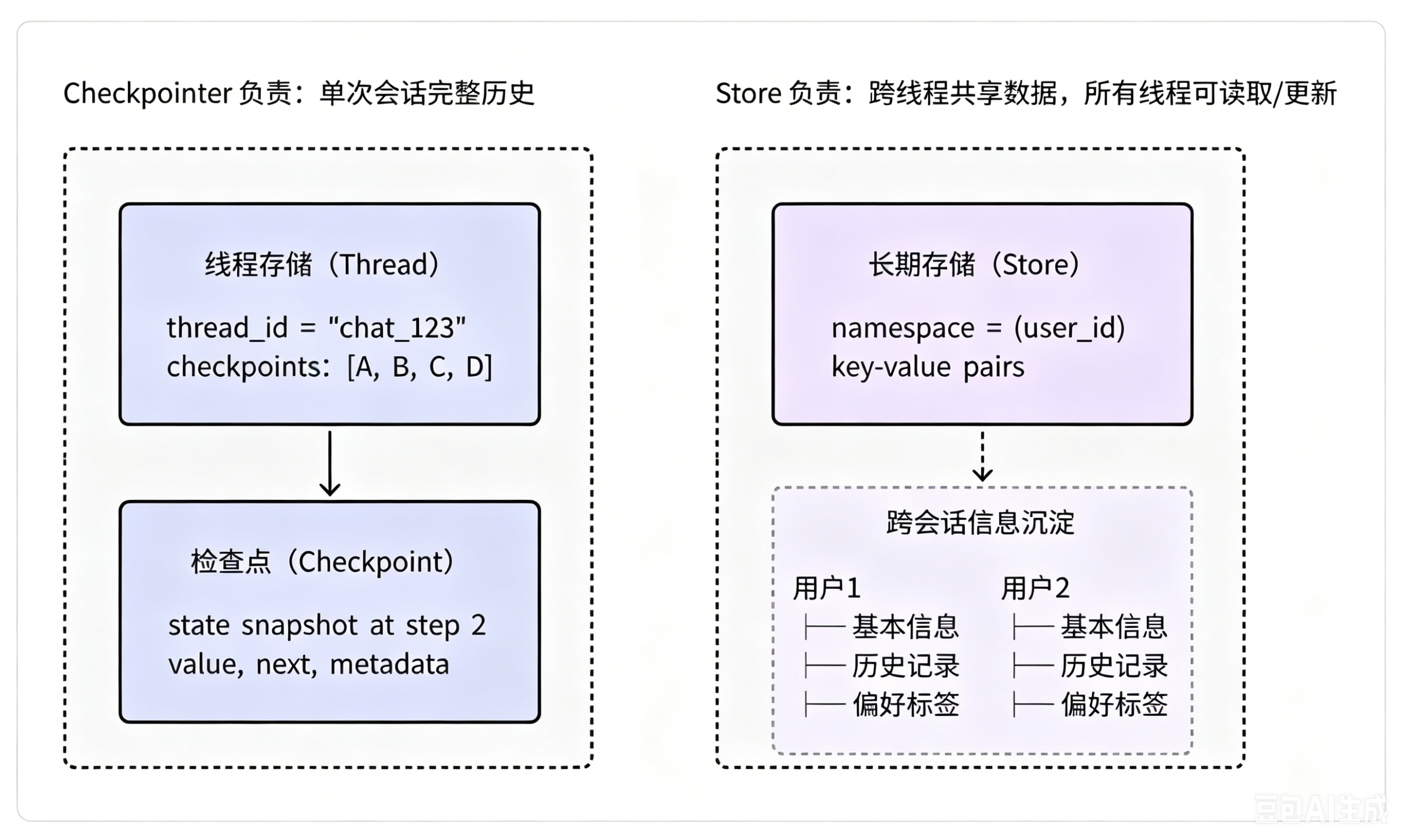
线程级存储只留存单次会话完整记录,依托检查点可以实现流程重放、状态修改、故障恢复等操作,但无法实现线程之间的数据互通。 而Store全局存储负责跨线程的数据共享,所有会话线程都能够读取、修改库里的数据,作用等同于公共数据库,各个独立线程均可存取数据。
实际上,使用 Checkpoint + Store 模式才能够真正实现:
两类存储机制相互配合,才能搭建完善的 AI 记忆体系。 检查点管控单次对话流程,保障会话内上下文连贯、流程可回溯;全局Store长期存放用户核心资料,比如姓名、年龄、使用偏好、消费记录、投诉历史、用户标签等画像信息。
单次会话交互时,程序会先调取全局存储里的用户画像数据,结合当下对话内容综合分析应答,无需用户反复报备个人信息与过往问题,服务智能性大幅提升。
引入 Store 后,AI 应用架构的范式转变
Store 的引入,不是简单的功能增加,而是 AI 应用架构的范式转变:

AI 应用的发展大致分为三个阶段。第一阶段是无状态 AI,不会留存任何对话信息,每一次交互都如同初次沟通;第二阶段接入检查点存储,实现单会话记忆,同一段对话内可以记住交流内容,切换会话便清空记忆;第三阶段结合检查点与全局Store,也就是现阶段主流智能 AI 架构,具备终身记忆与持续学习能力。
长期留存用户关键信息后,AI 能够追溯很久以前的交流内容,服务模式也从单纯应答当下请求,升级为结合历史数据处理问题;回复形式从通用话术,转变为贴合用户习惯的个性化应答,让 AI 工具逐步成长为陪伴式服务伙伴。
全局存储具备增、删、改、查基础数据操作能力,各个业务线程都可以调用接口存取数据,使用逻辑和常规数据库基本一致。
Store 的引入,真正能做到:
- 从关注单次交互 → 到关注用户生命周期
- 从处理当前请求 → 到利用历史数据
- 从通用回复 → 到深度个性化
这种转变让 AI 从 "工具" 进化为 "伙伴",真正实现智能服务的核心理念:在正确的时间,以正确的方式,为正确的人提供正确的价值。
最后补充一点使用注意事项,AI 系统会留存录入的关键信息,日常使用过程中,尽量不要在对话里提交身份证、隐私住址等私密资料,避免个人隐私数据被记录收集。
理解完跨会话持久化的核心概念与应用价值后,接下来我们就具体学习它的实际使用方式,掌握如何将用户关键信息持久化存入全局数据库。
跨会话持久化使用姿势
接下来我们正式学习跨会话持久化 的实际使用方式,核心就是定义并使用Store存储对象。在 LangGraph 框架里,存储实例分为两大类,分别是内存级存储 和第三方数据库存储,两种使用模式和此前讲解的线程级存储逻辑高度相似。
首先先讲解内存级存储,框架内置提供了InMemoryStore类,直接实例化就能创建内存存储对象,引用路径为langgraph.store.memory,编写代码时注意导入路径不要出错。创建完成后,该对象就代表内存存储空间。
python
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()接着只需像以前一样使用 Checkpoints 和 Store 变量编译图表即可。如下所示:
python
graph = builder.compile(checkpointer=checkpointer, store=store)方式 1:内存存储
Store 基本用法
我们先不急于将存储整合到 LangGraph 流程图中,先掌握Store自身的基础增查用法。全局存储需要具备新增、查询数据等基础能力,后续业务流程里的任意执行节点,都可以调用这些基础接口完成数据存取操作。
新增数据依靠store.put()方法,调用该方法需要传入三个核心参数,分别是命名空间namespace、键值key与存储内容value,弄懂参数含义才能正常完成数据存储。
namespace命名空间主要作用是实现数据隔离,同一个存储空间内,可以划分出多个独立命名空间,不同业务、不同用户的数据分门别类存放。查询数据时指定对应命名空间,就能精准检索对应分区内容,避免数据混淆。
Store 本身是通过 Namespace 区分不同数据,如下所示:
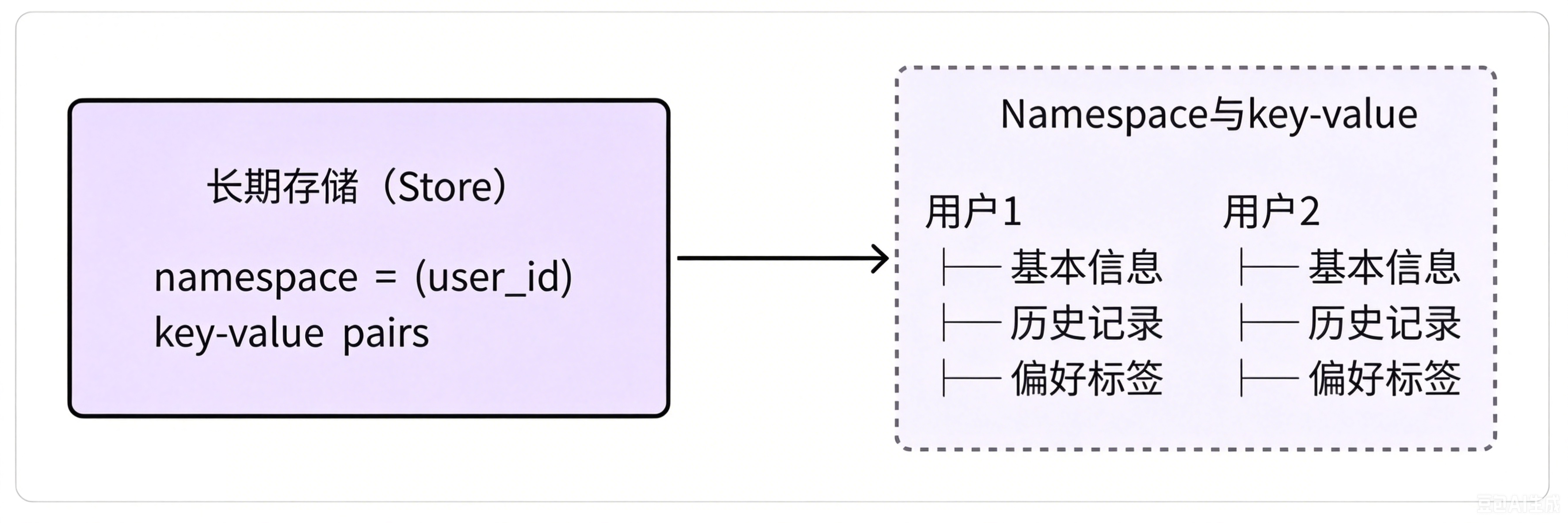
**key和value以键值对形式,存放单个命名空间内部的具体数据。**检索逻辑为先定位命名空间,再通过键匹配调取对应的存储内容。
定义命名空间优先推荐使用元组格式,层级划分清晰,后续检索、拓展都更加便捷。比如按照用户 ID、数据类型、具体分类组合元组,就能拆分出用户食物偏好、音乐偏好等独立数据区域。如果采用字符串格式定义命名空间,后续检索匹配需要额外解析字符,不仅流程繁琐,还容易出现逻辑错误。
参数具体释义:
-
命名空间界定数据归属主体与业务类型,实现数据分区隔离;
-
key作为单条记忆的唯一标识,一般采用uuid生成唯一编号; -
value存放记忆具体内容,规范使用字典格式封装各类信息。
基础存储流程分为四步,先创建内存存储实例,再定义对应命名空间,接着设定唯一键值与存储内容,最后调用put方法完成数据写入。
在 LangGraph 中,其提供了一个简单的内存实现 InMemoryStore。想要进行存储,需要:
**定义命名空间:**为了区分不同用户的记忆,需要一个 "命名空间"。这就像在数据库里为每个用户创建一个独立的文件夹。命名空间用于组织记忆,通常按业务逻辑划分。一般用元组来定义命名空间。如:
python
# 使用元组 - 层次清晰,易于扩展
namespace1 = ("user_123", "preferences", "food") # 用户食物偏好
namespace2 = ("user_123", "preferences", "music") # 用户音乐偏好
namespace3 = ("user_123", "conversations", "2025-05") # 用户某天的对话历史
# 使用字符串 - 扁平且易混淆
namespace4 = "user_123_preferences_food" # 需要解析,容易出错
namespace5 = "user_123_preferences_music"
namespace6 = "user_123_conversations_2024"当在对话中获取到用户的重要信息时,使用 store.put() 方法将内存保存到存储中的命名空间。该方法参数包含:
namespace:决定这个记忆属于谁以及是什么类型。memory_id:是这个记忆条目的唯一键。memory_content:是记忆的具体内容,一个字典。
python
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
store.put(namespace, memory_id, memory_content)完整代码如下:
python
# 1. 导入并创建存储
from langgraph.store.memory import InMemoryStore
import uuid # 用于生成唯一ID
store = InMemoryStore()
# 2. 定义命名空间 (Namespace)
# 命名空间用于组织记忆,通常按业务逻辑划分,例如按用户。
# 这里我们用一个元组(用户ID,记忆类型)
user_id = "user_123"
namespace = (user_id, "preferences") # 用户 user_123 的偏好记忆
# 3. 存入一条记忆 (Memory)
# 每条记忆需要一个唯一的 memory_id 和 一个 value(通常是字典)
memory_id = str(uuid.uuid4()) # 生成唯一ID,如 "abc-123-def-456"
memory_value = {"favorite_food": "汉堡", "allergy": "花粉"}
store.put(namespace, memory_id, memory_value)
print("记忆已存入!")
# 4. 读取记忆
# 可以搜索某个命名空间下的所有记忆
all_memories = store.search(namespace)
for mem in all_memories:
print(mem.dict()) # 记忆对象转成字典查看运行结果:
python
记忆已存入!
{
'namespace': [
'user_123', 'preferences'
],
'key': 'db826e33-c68c-4669-a79a-3579bff02ff1',
'value': {
'favorite_food': '汉堡',
'allergy': '花粉'
},
'created_at': '2025-12-03T08:16:14.134568+00:00',
'updated_at': '2025-12-03T08:16:14.134576+00:00',
'score': None
}存入数据后可通过store.search()方法读取信息,传入命名空间参数,就能取出该分区下所有存储数据。读取结果为记忆对象,转换成字典格式展示,可直观查看命名空间、键值、内容、创建时间等完整信息。
因使用元组作为命名空间,故同样支持下面的搜索方式:
python
all_memories = store.search((user_id, ))检索还支持前缀匹配模式,截取部分命名空间层级查询,能够批量获取对应分类下的全部数据。除基础精准查询外,search方法还附带query语义检索、filter条件过滤、limit数量限制等实用参数,同时框架也提供get方法,可依据命名空间加唯一键值精准获取单条数据。
不过 想要启用语义搜索 功能,必须提前给存储对象绑定嵌入模型。初始化InMemoryStore时配置index索引参数,指定嵌入模型类型、向量维度,同时划定嵌入解析字段。绑定模型后,就能依靠文本语义相似度匹配内容,检索结果会附带相似度分值,分值越高匹配度越高,搭配数量限制参数,可筛选出关联性最强的记忆数据。【具体见下面详解过程】
框架底层BaseStore统一封装了全套操作接口,包含新增、查询、删除、列表查询以及异步操作方法,日常开发按需调用即可,遇到疑问也可以查阅 LangGraph 官方参考文档,对照接口说明学习使用。
除内存存储外,生产环境常用第三方数据库持久化存储,典型代表为 PostgreSQL 数据库。使用逻辑和内存存储基本一致,先配置数据库连接地址,通过对应类库创建数据库存储实例,首次启用时执行初始化设置。
数据库存储与内存存储的调用语法完全通用,同样使用put、search、get方法存取数据。二者核心区别在于数据生命周期,内存存储程序终止、服务重启后数据就会清空丢失;数据库存储可以永久留存数据,断开连接后再次访问,依旧能够正常调取历史存储信息。
掌握内存存储与第三方数据库存储的基础用法后,下一步我们就学习如何将Store存储对象整合进 LangGraph 业务流程图中,实现跨会话数据持久化联动使用。
在 LangGraph 中使用 Store
内存存储适用于开发和测试,程序重启后存储的数据会丢失。这里依旧使用 快速上手 --- 案例 2 的代码进行演示。
首先在编译流程图时,同时配置两类存储,分别是内存型检查点存储InMemorySaver,以及内存型跨会话存储InMemoryStore,引入对应依赖包后,编译函数中同步传入checkpointer和store两个参数。如此一来,流程图就同时具备单会话状态留存、跨会话数据持久化两种能力。
由于要加入 Store,需要在合适的地方加入与存储关键信息相关的代码。如我们可以在每次调用 LLM 前先进行信息收集,然后带着收集到的共享信息进行 LLM 调用。因此,流程变成了:
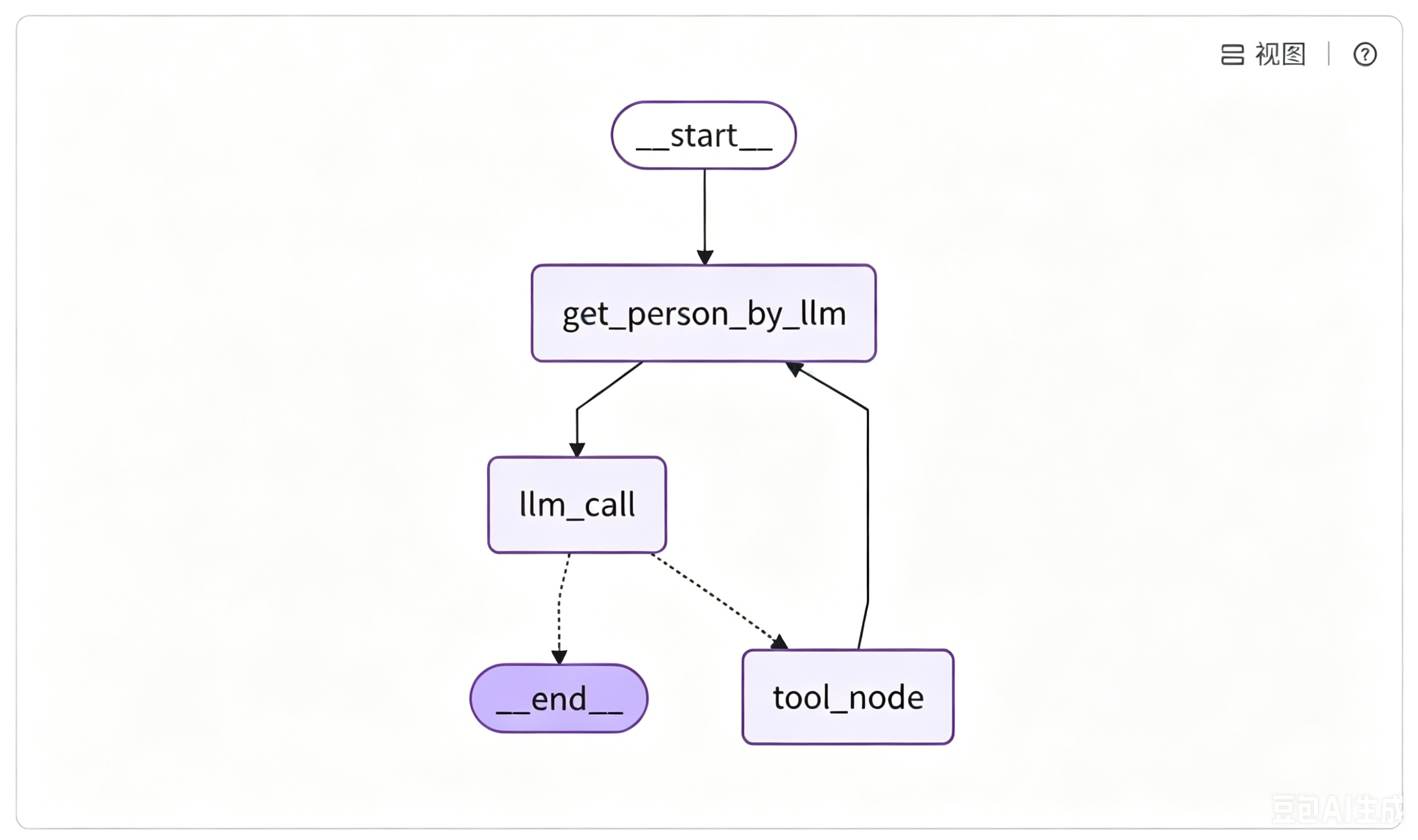
这样,两部分信息将会被收集:一是用户发的消息;二是通过工具调用返回的结果信息也会被采集。
在编译图时,直接添加编译参数 store,如下所示:
python
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
# 用 checkpointer + store 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)现在,在任何一个节点的函数中,都可以通过注入 store 参数来访问这个全局存储。
新增提取用户信息节点
在这个节点中,我们需要根据【用户发的消息】和【工具调用返回的结果】来采集需要收集的信息。收集的信息需要使用 Store 进行存储。关键设计如下:
- 任何节点函数,如果需要访问 Store,可以通过在参数中声明
store: BaseStore和config: RunnableConfig来获取。 - 在这里可以通过 LLM 提取用户信息,因此定义结构化返回是很有必要的。
python
# 定义结构化输出
class Person(BaseModel):
"""一个人的信息。"""
# 注意:
# 1. 每个字段都是 Optional(可选的) --- 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有一个 description "描述" --- LLM使用这个描述。
name: Optional[str] = Field(default=None, description="这个人的名字")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
favourite_food: Optional[list[str]] = Field(default=None, description="最喜欢的食物列表")
model_with_structured = model.with_structured_output(Person)
# 提取用户信息节点
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""通过 LLM 提取用户信息"""
# 1. 先提取
people_info = model_with_structured.invoke(
[
SystemMessage(
content="你是一个提取信息的专家,只从文本中提取我的相关信息,不能提取别人的信息。如果你不知道要提取的属性的值,属性值返回null。"
)
]
+ state["messages"][-3:] # 只查看最近3条消息
)
# 2. 再保存
user_id = config["configurable"]["user_id"]
# 保存用户基本信息
namespace1 = (user_id, "info")
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这里简写
store.put(
namespace1,
str(uuid.uuid4()),
{
"name": people_info.name,
"height": people_info.height_in_meters
}
)
# 保存用户偏好
namespace2 = (user_id, "preferences")
store.put(
namespace2,
str(uuid.uuid4()),
{"favourite_food": people_info.favourite_food} # 省略追加逻辑:先搜再更新
)
return {
"llm_calls": state.get('llm_calls', 0) + 1
}需要注意两类存储的使用区别,检查点可以自动保存节点运行的状态快照,无需手动干预;而Store的数据读写必须手动编码调用接口,想要在节点内操作存储,就要先获取存储实例。定义节点函数时,除了业务状态参数,还需要声明RunnableConfig配置参数与BaseStore存储参数,框架会自动完成参数注入。参数书写有格式要求,星号后方的参数调用时必须显式指定名称,遵循规范才能正常获取配置与存储对象。
用户标识user_id不属于会话临时状态,统一放在执行图的配置信息中传递,**依靠它区分不同使用者。**节点内读取配置就能拿到用户编号,以此为基础搭配业务分类,用元组格式构建命名空间,实现不同用户、不同类型数据的隔离存放。
原有案例的执行逻辑为: 用户提问后调用大模型,按需触发网络搜索,检索完毕再汇总信息生成最终回复。现在对流程进行改造,在流程起始位置新增用户信息提取节点,同时调整原有大模型调用节点逻辑,修改节点间的跳转关系。工具检索结束后,流程不再直接跳转大模型节点,而是先回到信息提取节点,抓取对话与检索结果里的有效内容。
我们设定提取姓名、身高、饮食偏好三类核心信息,借助结构化输出规范大模型返回格式。定义数据模型,所有字段设为可选类型并补充字段描述,模型会依据描述文本识别信息,无对应内容则返回空值。
信息提取节点的执行逻辑分为三步,先截取近期对话消息,搭配专属提示词调用模型解析关键内容;接着从配置中获取用户 ID,划分基础信息、个人偏好两类命名空间;最后调用put方法,以 UUID 作为唯一键、字典封装数据完成存储。实际开发中存入数据前,应当先查询已有记录,根据业务需求选择覆盖或追加数据,本次演示简化该校验步骤即可。节点执行完毕后,同步统计大模型调用次数。
更新模型调用节点:添加共享信息到提示词
调用 LLM 之前,我们便可以通过查询 Store 获取共享信息,然后将其加入到提示词中,完成调用。
python
def llm_call(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""LLM决定是否调用工具"""
# 搜索用户信息
user_id = config["configurable"]["user_id"]
namespace1 = (user_id, "info")
namespace2 = (user_id, "preferences")
info_result = store.search(namespace1)
pref_result = store.search(namespace2)
return {
"messages": [
model_with_tools.invoke(
[
SystemMessage(
content=f"你是一个乐于助人的助手,支持调用工具进行搜索。 "
f"查询 LLM 前可参考以下信息: "
f"1. 用户基本情况: {info_result[0].value} "
f"2. 用户偏好情况: {pref_result[0].value}"
)
]
+ state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}改造后的大模型调用节点,不再只单纯依据用户问题作答。运行时先通过search方法,根据用户 ID 查询存储内留存的历史信息,把用户基础资料、喜好偏好拼接补充到系统提示词中。模型结合历史记忆与当下问题综合分析,让回复内容贴合用户个人情况。
构件图时,加入新节点与调整边
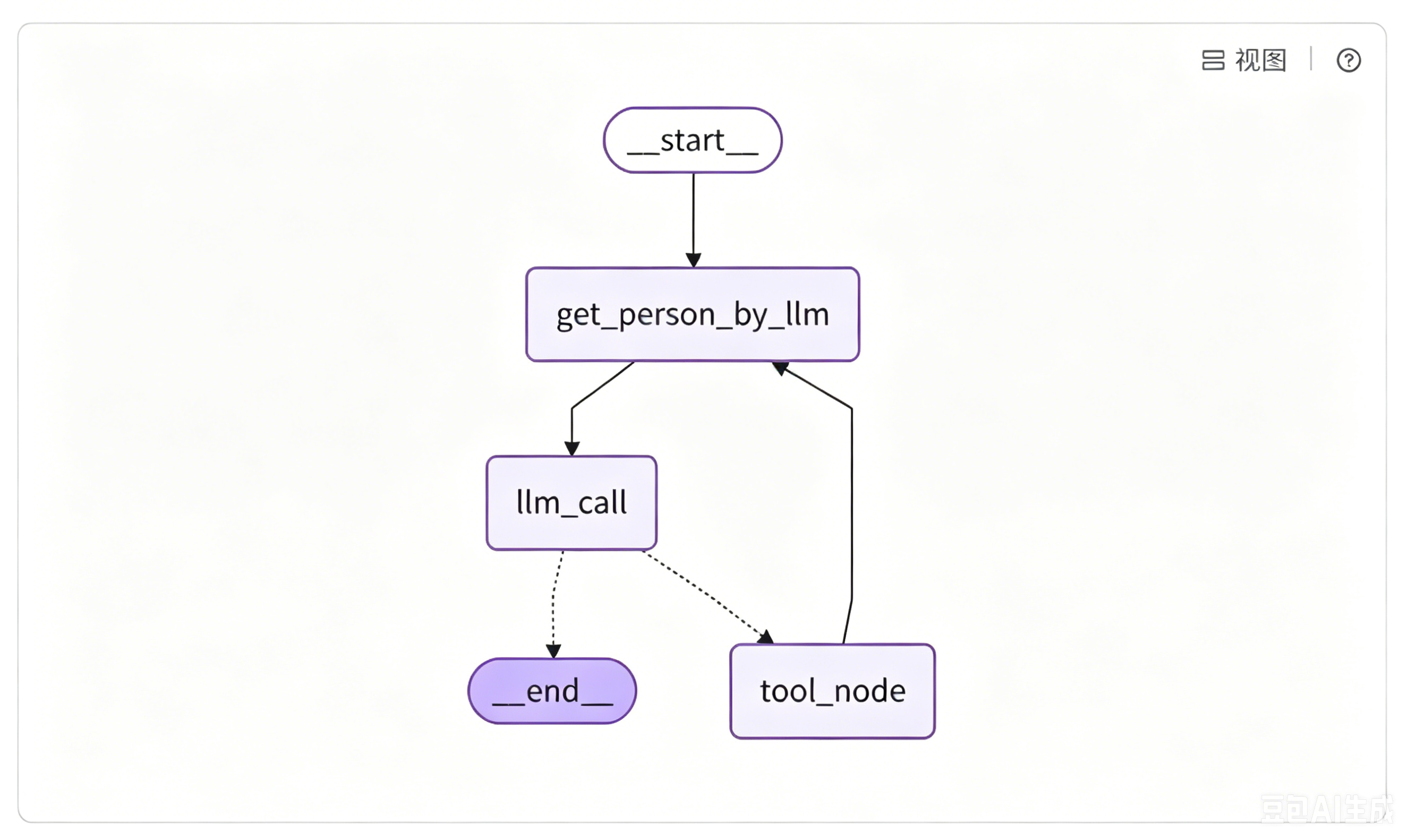
根据下图完成调整:
python
agent_builder = StateGraph(MessagesState)
agent_builder.add_node(llm_call)
agent_builder.add_node(tool_node)
# 新增节点
agent_builder.add_node(get_person_by_llm)
# 调整边
agent_builder.add_edge(START, "get_person_by_llm")
agent_builder.add_edge("get_person_by_llm", "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "get_person_by_llm")**调整完整的节点跳转链路:**流程启动后先进入信息提取节点,解析并保存用户数据;再发起大模型调用,判断是否需要联网检索;需要检索则执行工具节点,检索结束再次回到信息提取节点更新数据;无需检索就直接结束会话流程。
到此,代码已经改造完成,完整代码如下:
python
import uuid
from typing import Optional
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langchain_tavily import TavilySearch
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
from pydantic import BaseModel, Field
# 步骤 1: 定义工具和模型
search = TavilySearch(max_results=4)
tools = [search]
# 绑定工具
model = init_chat_model("gpt-4o-mini", temperature=0)
model_with_tools = model.bind_tools(tools)
# 步骤 2: 定义状态
from langchain.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
# 类型: list[AnyMessage] - 任意消息对象的列表
# 合并策略: operator.add - 使用加法操作符进行状态合并
# 效果: 当状态更新时,新的消息会追加到现有列表中,而不是替换
messages: Annotated[list[AnyMessage], operator.add]
# 类型: int - 整数值
# 用途: 跟踪LLM(大语言模型)的调用次数
llm_calls: int
# 步骤 3: 新增提取信息节点
# 定义结构化输出
class Person(BaseModel):
"""一个人的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" --- 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有一个 description "描述" --- LLM使用这个描述。
name: Optional[str] = Field(default=None, description="这个人的名字")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
favourite_food: Optional[list[str]] = Field(default=None, description="最喜欢的食物列表")
model_with_structured = model.with_structured_output(Person)
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""通过 LLM 提取用户信息"""
# 1. 先提取
people_info = model_with_structured.invoke(
[
SystemMessage(
content="你是一个提取信息的专家,只从文本中提取我的相关信息,不能提取别人的信息。如果你不知道要提取的属性的值,属性值返回null。"
)
]
+ state["messages"][-3:] # 只查看最近3条消息
)
# 2. 再保存
user_id = config["configurable"]["user_id"]
# 保存用户基本信息
namespace1 = (user_id, "info")
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这里简写
store.put(
namespace1,
str(uuid.uuid4()),
{
"name": people_info.name,
"height": people_info.height_in_meters
}
)
# 保存用户偏好
namespace2 = (user_id, "preferences")
store.put(
namespace2,
str(uuid.uuid4()),
{"favourite_food": people_info.favourite_food} # 省略追加逻辑: 先搜再更新
)
return {
"llm_calls": state.get('llm_calls', 0) + 1
}
# 步骤 4: 更新模型调用节点,添加共享用户信息到提示词
from langchain.messages import SystemMessage
def llm_call(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""LLM决定是否调用工具"""
# 搜索用户信息
user_id = config["configurable"]["user_id"]
namespace1 = (user_id, "info")
namespace2 = (user_id, "preferences")
info_result = store.search(namespace1)
pref_result = store.search(namespace2)
return {
"messages": [
model_with_tools.invoke(
[
SystemMessage(
content=f"你是一个乐于助人的助手,支持调用工具进行搜索。 "
f"查询 LLM 前可参考以下信息: "
f"1. 用户基本情况: {info_result[0].value} "
f"2. 用户偏好情况: {pref_result[0].value}"
)
]
+ state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}
# 步骤 5: 定义工具节点
from langchain.messages import ToolMessage
tools_by_name = {tool.name: tool for tool in tools}
def tool_node(state: dict):
"""执行工具调用"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# 步骤 6: 构件图
from langgraph.graph import StateGraph, START, END
# 定义结束逻辑
def should_continue(state: MessagesState):
"""根据LLM调用工具来决定是否应该继续循环 (路由到工具节点) 还是停止循环 (END)"""
messages = state["messages"]
last_message = messages[-1]
# 如果LLM调用工具,则执行操作
if last_message.tool_calls:
return "tool_node"
return END
# 加入新节点并修改边
agent_builder = StateGraph(MessagesState)
agent_builder.add_node(llm_call)
agent_builder.add_node(tool_node)
agent_builder.add_node(get_person_by_llm)
agent_builder.add_edge(START, "get_person_by_llm")
agent_builder.add_edge("get_person_by_llm", "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "get_person_by_llm")
store = InMemoryStore()
checkpointer = InMemorySaver()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)运行与验证:同一用户但不同会话的请求
python
# 第一次聊天
config1 = {"configurable": {"thread_id": "1", "user_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="我叫李华,我最爱吃汉堡。我的朋友叫小明,他爱吃披萨")]},
config1
)
print(f"调用 LLM 总次数: {result1['llm_calls']}次")
m = result1["messages"][-1]
m.pretty_print()
# ------------------- 过了几天 -------------------
# 同一个人,再次开启对话
config2 = {"configurable": {"thread_id": "2", "user_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="给我推荐下餐厅")]},
config2
)
print(f"调用 LLM 总次数: {result2['llm_calls']}次")
m = result2["messages"][-1]
m.pretty_print()执行结果如下:
python
调用 LLM 总次数: 2次
================================ Human Message =================================
我叫李华,我最爱吃汉堡。我的朋友叫小明,他爱吃披萨
================================== Ai Message =================================
你好,李华!很高兴认识你。汉堡和披萨都是很受欢迎的美食。你和小明有没有一起去过什么好吃的地方呢,或者你有没有想尝试的新餐厅?
调用 LLM 总次数: 4次
================================ Human Message =================================
给我推荐下餐厅
================================== Ai Message =================================
Tool Calls:
TavilySearch(call_id=..., name=tavily_search, query="推荐汉堡餐厅")
================================= Tool Message =================================
[{省略...}]
================================== Ai Message =================================
以下是一些推荐的汉堡餐厅:
1. **Burger She Wrote** (https://www.novacircle.com/zh-CN/sps/north-america/9un7ea267) - 位于洛杉矶,这是一家小而温馨的餐厅,以美味的和牛汉堡而闻名。
2. **[TripAdvisor 上洛杉矶的最佳汉堡]** (https://cn.tripadvisor.com/Restaurants-g32655-xfdj09-zo7f2g104-los-Angeles,_California-Hamburgers.html) - 包含多家受欢迎的汉堡餐厅,如Bottarga Louie和Angelus,后者以其鸡蛋汉堡而著称。
希望这些推荐能帮助你找到美味的汉堡!完成代码编写后分两次模拟会话测试。首次对话中用户提交个人信息与饮食喜好,程序自动将数据存入跨会话存储;时隔一段时间开启全新会话线程,同一用户提出餐厅推荐需求。常规会话隔离机制下,新对话无法读取过往记录,而依托Store持久化能力,程序可以调取历史留存的饮食偏好。
模型参考记忆信息分析需求,调用搜索工具定向查找契合用户口味的门店,最终给出个性化推荐结果。测试结果能够印证,跨会话存储可以长久保留用户关键数据,即便切换对话线程,智能体也能记住用户特征,给出贴合个人习惯的应答,模拟出专属私人助手的效果。
最后梳理实操核心要点,编译流程图时绑定存储实例,内存存储便于调试,生产环境可替换为数据库存储;用户标识统一交由配置传递,依靠命名空间完成数据隔离;节点支持注入配置与存储对象,手动调用接口完成数据存取。
语义搜索
Store 的强大之处在于它支持语义搜索,而不仅仅是精确匹配。这意味着我们可以用自然语言问题来查找相关记忆。
首先,我们需要配置带嵌入模型的 Store,如下所示:
python
store = InMemoryStore(
index={
"embed": init_embeddings("openai:text-embedding-3-small"), # 使用OpenAI嵌入模型
"dims": 1536, # 嵌入向量的维度
"fields": ["$"] # 对value中的所有字段进行嵌入
}
)在节点中,可以这样搜索:
python
user_id = config["configurable"]["user_id"]
namespace = (user_id, )
# 在Store中进行语义搜索,找出最相关的2个记忆
# 这里直接在user-id维度下通过语义去找
info_result = store.search(namespace, query="用户基本信息", limit=2)
pref_result = store.search(namespace, query="用户偏好信息", limit=2)扩展:如果我们让 AI 助手能记住用户的更多信息(比如不喜欢的东西、上次聊到的话题记录等)。在新的对话,语义搜索可以把历史记录中的相关记忆找出来,帮助 AI 助手进行更加准确的回复。
方式 2:Postgres 存储库
Postgres 存储库适用于生产环境或需要状态持久化的场景。由于之前已经启动过 PostgreSQL,这里可以直接连接到数据库,作为 PostgresStore 使用。只需在编译时设置 store 即可。
修改【内存存储】部分的代码:将内存存储方式修改为 Postgres 存储库。
注意:第一次使用 Postgres store 时需要调用
store.setup()
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 第一次使用 Postgres store 时需要调用 store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# ...后续调用...模拟第一次聊天:
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 第一次使用 Postgres store 时需要调用 store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# 第一次聊天
config1 = {"configurable": {"thread_id": "1", "user_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="我叫李华,我最爱吃汉堡。我的朋友叫小明,他爱吃披萨")]},
config1
)
print(f"\n调用 LLM 总次数: {result1['llm_calls']}次")
for m in result1["messages"]:
m.pretty_print()运行系统后可以看到,postgres 中新增 store 相关表,其中存放了用户基本的信息:
| prefix | key | value |
|---|---|---|
1.info |
064a33cd-0ee7-48b... |
{"name": "李华", "height": null} |
1.preferences |
2098bdc2-2c6c-4e7... |
{"favourite_food": ["汉堡"]} |
再次验证:同一用户但不同会话的请求
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 第一次使用 Postgres store 时需要调用 store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# ------------------- 过了几天 -------------------
# 同一个人,再次进行对话
config2 = {"configurable": {"thread_id": "2", "user_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="给我推荐下餐厅")]},
config2
)
print(f"\n调用 LLM 总次数: {result2['llm_calls']}次")
for m in result2["messages"]:
m.pretty_print()注意执行前,将以下代码注释,因为:在存入 store 前,并没有编写 "不存在存入,存在更新" 的代码逻辑(只是演示),因此会将空的用户信息误存,导致 LLM 调用前查出来空的。
python
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
...
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这里简写
# store.put(
# namespace1,
# str(uuid.uuid4()),
# {
# "name": people_info.name,
# "height": people_info.height_in_meters
# }
# )
# # 保存用户偏好
# namespace2 = (user_id, "preferences")
# store.put(
# namespace2,
# str(uuid.uuid4()),
# {"favourite_food": people_info.favourite_food} # 省略追加逻辑:先搜再更新
# )
...最终执行结果如下:
python
调用 LLM 总次数: 3次
================================ Human Message =================================
给我推荐下餐厅
================================== Ai Message =================================
Tool Calls:
TavilySearch(call_id=..., query="推荐汉堡餐厅")
================================= Tool Message =================================
[{
"query": "推荐汉堡餐厅",
"results": [
{
"url": "https://www.reddit.com/r/AskNYC/comments/1470o9z/best_burger_spot_in_nyc/?tl=zh-hans",
"title": "纽约最好吃的汉堡店是哪家推荐? : r/AskNYC",
"content": "1个月前。The Thompson's Burger Joint 和 Minetta Tavern 等被推荐。纽约/布鲁克林最好的汉堡?...Read more"
},
{
"url": "https://www.cosmopolitan.com/tw/lifestyle/food-and-drink/g44382807/hamburger-hamburger-20230629/",
"title": "美国旅游必吃7大人气汉堡店!",
"content": "IN-N-OUT、Five Guys、Shake Shack 和 Smashburger..."
}
]
}]
================================== Ai Message =================================
以下是一些推荐的汉堡餐厅:
1. **纽约最好吃的汉堡店**(https://www.reddit.com/...):推荐的汉堡店包括 The Thompson's Burger Joint 和 Minetta Tavern 等。
2. **美国旅游必吃人气汉堡店**(https://www.cosmopolitan.com/...):Five Guys、In-N-Out、Shake Shack 等连锁品牌都很受欢迎。
3. ...
希望这些推荐能帮助到您!如果您有特定的城市或地区需求,请告诉我。