1.前言
大家需要注意,实际上,row_number() 倾斜不是一个 SQL 语法问题,而是一个"窗口分区内数据无法并行"的问题。解决它的关键不是简单加盐,而是先判断业务场景属于哪一类:全量排序、首末记录、TopN、还是只需要去重(后面会分场景分别给大家介绍不同场景的处理思路)。
上面这个判断很重要,很多同学一看到数据倾斜就想到了加盐处理,但是所有场景都能加盐吗?至少对于 row_number() 数据倾斜而言,加盐不是万能的!
举个例子哈,看下面这段代码:
row_number() over(partition by user_id order by event_time)如果业务要求的是每个 user_id 下完整、连续、准确的全量编号,那不能随便对 user_id 加随机盐,因为随机盐会破坏同一个用户下的全局顺序。
所以,如果遇到一个关于 row_number() 倾斜的优化问题,第一步不是写SQL,而是先去尝试判断一下:这个 row_number() 到底是不是真的有必要存在?
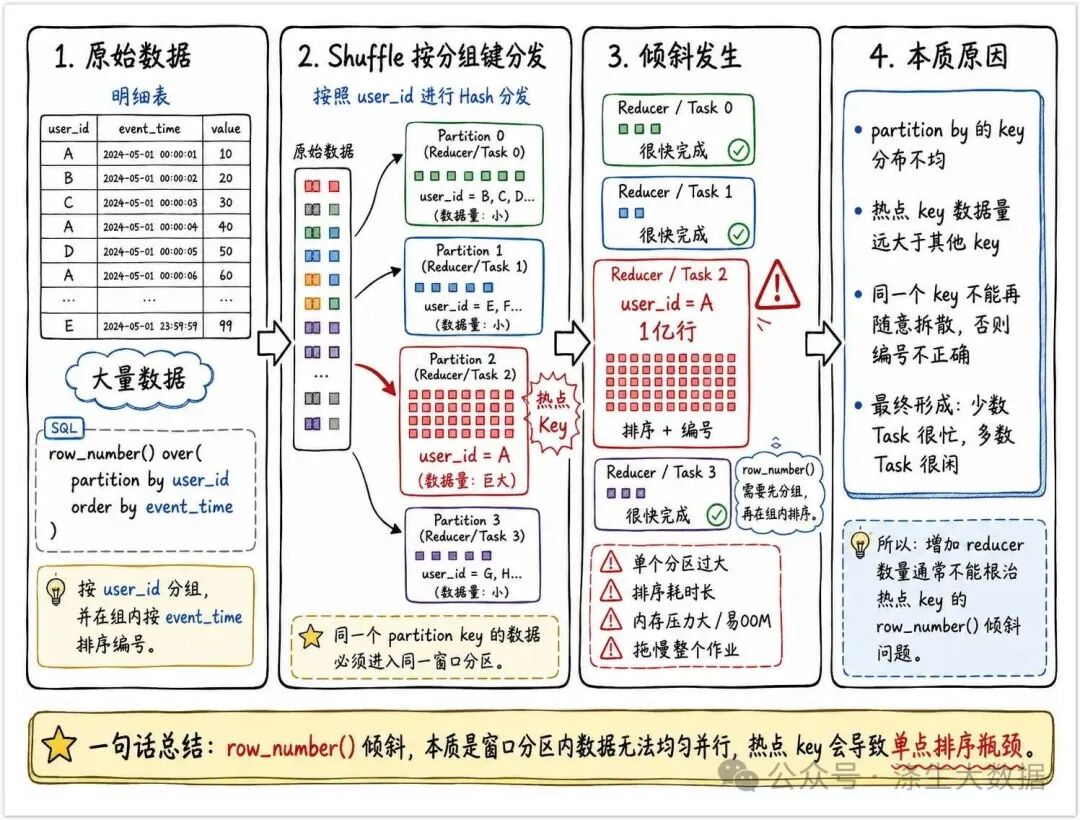
2.row_number() 为什么会发生数据倾斜?
row_number() 的执行通常会经历两个核心动作:
-
按 partition by 字段把数据 shuffle 到不同 task / reducer。
-
在每个分区内部按照 order by 字段排序,再生成编号。
可是问题就在于:例如,row_number() over(partition by department_id order by hire_date),如果 90% 的数据都属于同一个 department_id = 'a',那么这 90% 的数据最终还是会被打到同一个分区里排序。
也就是说:
-
小部门:1 万行 -> 一个 task 很快完成
-
普通部门:20 万行 -> 一个 task 正常完成
-
超级部门:1 亿行 -> 一个 task 排序很慢,甚至 OOM
这就是 row_number() 倾斜的本质(当然,其他倾斜也是这个原因,例如使用Join操作):partition by 的 key 不均匀,导致某个窗口分区过大,最终变成单点排序瓶颈。
❝
多问一句:增加 reducer 数量能不能解决 row_number() 倾斜?
答:不能,因为同一个 partition by key 的数据必须进入同一个窗口分区,否则无法保证该 key 下的排序结果正确。增加 reducer 只能缓解普通 key 的并行度,但无法把一个超级大 key 自动拆开。
给大家用一张图来理解一下这个过程:
案例1:全局排序
有一张员工入职时间表table_1,如下:
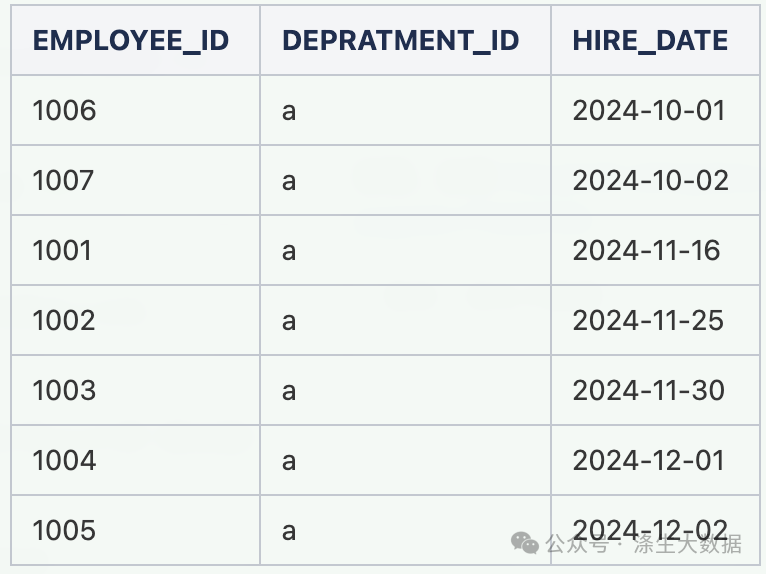
要求:按照部门已入职员工的入职时间排序,给每位员工编号。
思路一:
select
employee_id
,department_id
,hire_date
,row_number() over(partition by department_id order by hire_date) as rn
from table_1
-- PS:假如部门a的人数特别多,上述代码使用department_id分区,会产生数据倾斜问题,那怎么解决呢?思路二:
with hire_table AS (
SELECT 1001 as employee_id ,'a' as department_id, '2024-11-16' as hire_date
UNION ALL
SELECT 1002 as employee_id ,'a' as department_id, '2024-11-25' as hire_date
UNION ALL
SELECT 1003 as employee_id ,'a' as department_id, '2024-11-30' as hire_date
UNION ALL
SELECT 1004 as employee_id ,'a' as department_id, '2024-12-01' as hire_date
UNION ALL
SELECT 1005 as employee_id ,'a' as department_id, '2024-12-02' as hire_date
UNION ALL
SELECT 1006 as employee_id ,'a' as department_id, '2024-10-01' as hire_date
UNION ALL
SELECT 1007 as employee_id ,'a' as department_id, '2024-10-02' as hire_date
)
, local_rn_table as (
--1 先使用`department_id+入职年月`分区,局部编号
select
employee_id
,department_id
,hire_date
,date_format(hire_date, 'YYYY-MM') as months
,row_number() over(partition by department_id, date_format(hire_date, 'YYYY-MM') order by hire_date) as local_rn
from hire_table
)
, tmp2 as (
--2 计算每个`department_id+入职年月`分区,对应的起始编号
select department_id
,months
,month_cnt
,sum_monthg_cnt
,lag(sum_monthg_cnt, 1, 0) over (partition by department_id order by months) as lag_sum_monthg_cnt
from (
select department_id
,months
,month_cnt
,sum(month_cnt) over (partition by department_id order by months rows between unbounded preceding and current row) as sum_monthg_cnt
from (
select department_id
,date_format(hire_date, 'YYYY-MM') as months
,count(1) as month_cnt
from hire_table
group by department_id, date_format(hire_date, 'YYYY-MM')
) as t1
) as t2
)
select t1.employee_id
,t1.department_id
,t1.hire_date
,local_rn + lag_sum_monthg_cnt as res
from local_rn_table as t1
left join tmp2 as t2
on t1.department_id = t2.department_id
and t1.months = t2.months总结一下,思路二的核心思想在于分治的思想,充分利用集群并行的优势,将庞大的计算任务拆成多个小的任务执行,进而解决倾斜问题。当然,补充一点哈,如果某个月份本身仍然很大,比如 2024-11 有 5000 万行+,那么按月拆还不够,还可以继续按天、小时、或者更细的有序区间继续拆。反正思想是一样的:拆分字段必须能够表达全局排序顺序,不能随便用随机数拆。
当然,如果题目需要表达全局的排序顺序,且题目的字段中没有其他可用的有序字段,那这个方式就不行了哦~
案例2:Top1问题
需求描述:有一张用户登陆表 table_2 ,包含用户ID,登陆日期,在线时长,表的粒度为用户ID+登陆日期,需求是想要拿到每个用户最早一次登陆日期及对应的在线时长。
表结构如下:
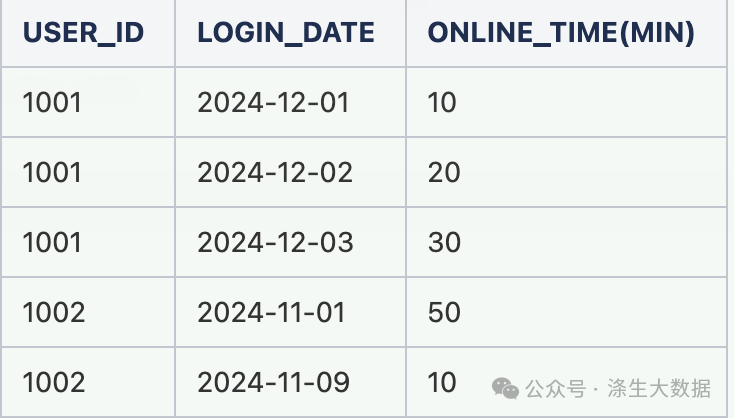
思路一(绝大多数人都会想到的思路,直接row_number()+where,这也是我们课程里提到的一种思路):
select
user_id
,login_date
,online_time
from
(
select
user_id
,login_date
,online_time
,row_number() over(partition by user_id order by login_date) as rn
from user_log
) a
where rn = 1
-- PS:如果存在部分头部用户数据量特别大,使用row_number()容易出现数据倾斜问题,该如何解决呢?思路二:
with table_2 AS (
SELECT 1001 as user_id ,'2024-12-01' as login_date, 10 as online_time
UNION ALL
SELECT 1001 as user_id ,'2024-12-02' as login_date, 20 as online_time
UNION ALL
SELECT 1001 as user_id ,'2024-12-03' as login_date, 30 as online_time
UNION ALL
SELECT 1002 as user_id ,'2024-11-01' as login_date, 50 as online_time
UNION ALL
SELECT 1002 as user_id ,'2024-11-09' as login_date, 10 as online_time
)
select
user_id
,substr(first_login_online_time, 1, 10) as login_date
,cast(substr(first_login_online_time, 12) as bigint) as online_time
from
(
select
user_id
,min(concat(login_date, '_', online_time)) as first_login_online_time
from table_2
group by
user_id
) a思路2这里利用了Map端预聚合的优化,减少后续shuffle时候的数据量,提高计算效率。此外,后续遇到【首/末次发生某种行为】的场景,也要先思考一下,是否能通过 max/min 的方式解决,尽量避免开窗函数带来的开销。
小结一下,如果 row_number() 只是为了取首条、末条、最大值对应行、最小值对应行,优先考虑用 group by、min、max、min_by、max_by 替代窗口排序。
案例3:TopN问题
案例1是使用了数据中本来就自带的顺序信息,也即日期;案例2是将开窗转换成了其他操作,来实现问题的求解
那假设问题不能转换,且数据中没有顺序信息或者日期不可用,该怎么求解呢?
在数据开发过程中,经常会遇到取某个维度下的Top数据:比如要取类目下的TopN的属性值,通用的方法是使用row_Number排序,然后再取Top。
常规写法:
select cate_id,
property_id,
value_id
from (
select cate_id,
property_id,
value_id,
row_number() over (partition by cate_id order by property_id asc, value_id asc) as rn
from one_plat.ads_tb_sycm_cate_xx
where ds = '${date}'
) p
where rn <= N;倾斜问题:
row_number按照 cate_id 分组,在每个分组内进行排序,如果一个 cate_id 下有大量的属性值就会发生倾斜,那么如何才能既防止倾斜,又能实现排序呢?
优化思路:
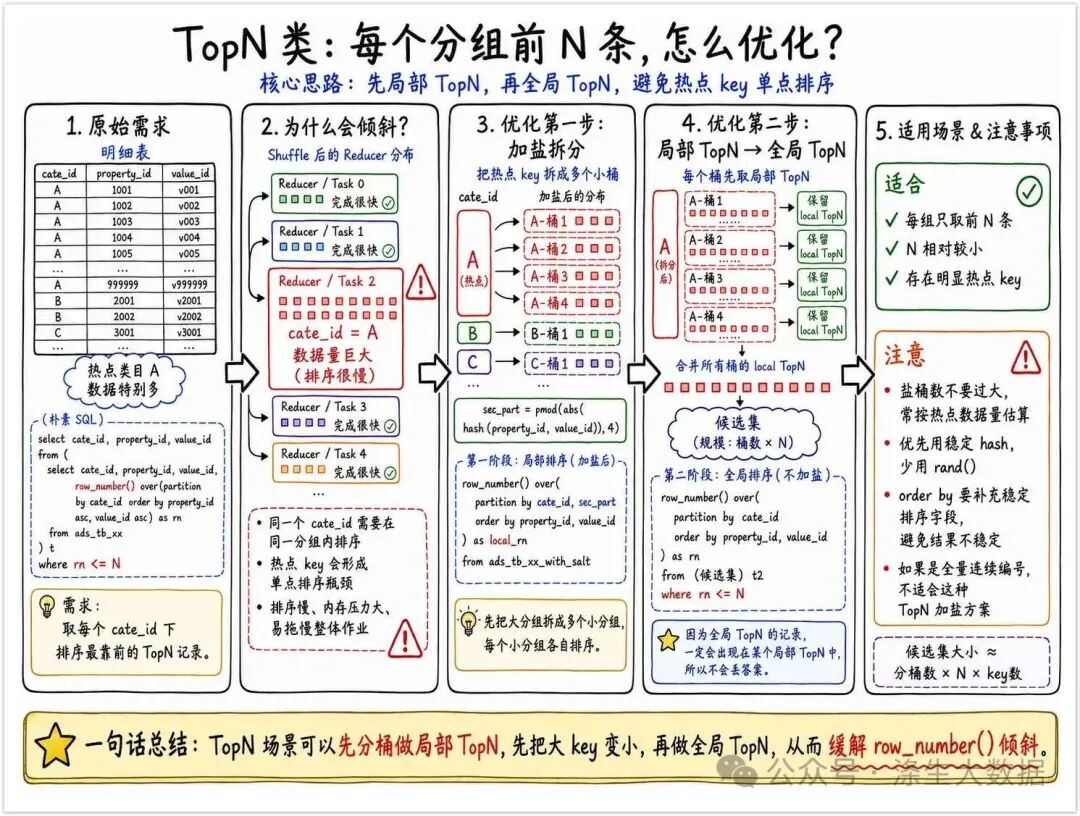
-
大量的数据分发到同一个分组,我们可以考虑对这个分组再做一次分发,这样就能把大的分组拆分成N个小分组。
-
可以使用两次row_number(),第一次按照 cate_id 和 加盐随机数 进行分发,第二次再使用 cate_id 进行分发,求最终的TopN
-
关于加盐随机数的选择:
-
ceil(rand()*100):生产0-100的随机整数
-
关于rand()后面应该乘以多少?可以大概探查一下倾斜的cate_id的数据量
-
假设有1亿行数据,且每个排序分区处理100万行数据是比较合理的,那么就用 1亿/100w = 100,因此乘以100是比较合理的
-
优化后的写法1:
select
cate_id,
property_id,
value_id
from
(
select
cate_id,
property_id,
value_id,
row_number() over(
partition by cate_id
order by
property_id asc,
value_id asc
) as rn -- 第二次排序
from
(
select
cate_id,
property_id,
value_id
from
(
select
cate_id,
property_id,
value_id,
row_number() over(
partition by cate_id,
sec_part
order by
property_id asc,
value_id asc
) as rn -- 第一次排序
from
(
select
cate_id,
property_id,
value_id,
ceil(rand() * 100) as sec_part -- 生成随机数,取值为0-100
from
one_plat.ads_tb_sycm_cate_xx
where
ds = '${date}'
) s
) p
where
rn <= N
) part
) a
where
rn <= N关于这个思路为什么是对的:
- 对于某个 cate_id 的全局 TopN 中任意一条记录,它前面最多只有 N-1 条记录比它更靠前。当我们把数据随机拆成多个盐桶后,这条记录所在的盐桶里,比它更靠前的数据只会更少,不可能超过全局范围内的 N-1 条。因此,全局 TopN 中的记录一定会出现在某个盐桶的局部 TopN 中。所以先取局部 TopN,再取全局 TopN,不会丢失正确答案。
优化后的写法2(核心思想是:热点 key 拆分,不要全量加盐):
生产中还有一个非常实用的优化方式:只对热点 key 做特殊处理。
比如 cate_id 有 100 万个,但真正倾斜的可能只有 10 个。如果对所有 cate_id 都加盐,会让普通 key 的计算变复杂,还会增加不必要的数据量。
更好的方式是:
-
先统计每个 key 的数据量。
-
找出热点 key。
-
热点 key 走加盐 TopN 或范围分治。
-
普通 key 继续走原来的 row_number()。
with hot_key as (
select
cate_id
from
one_plat.ads_tb_sycm_cate_xx
where
ds = '{date}' group by cate_id having count(1) > 1000000 -- 定义热点key的数量级 ), normal_data as ( select t.* from one_plat.ads_tb_sycm_cate_xx t left join hot_key h on t.cate_id = h.cate_id where t.ds = '{date}'
and h.cate_id is null
),
hot_data as (
select
t.*
from
one_plat.ads_tb_sycm_cate_xx t
join hot_key h on t.cate_id = h.cate_id
where
t.ds = '{date}' ) -- 普通 key 用原始 row_number select cate_id, property_id, value_id from ( select cate_id, property_id, value_id, row_number() over( partition by cate_id order by property_id asc, value_id asc ) as rn from normal_data ) t where rn <= {n}
union all
-- 热点 key 用加盐局部 topn + 全局 topn
select
cate_id,
property_id,
value_id
from
(
select
cate_id,
property_id,
value_id,
row_number() over(
partition by cate_id
order by
property_id asc,
value_id asc
) as rn
from
(
select
cate_id,
property_id,
value_id
from
(
select
cate_id,
property_id,
value_id,
row_number() over(
partition by cate_id,
sec_part
order by
property_id asc,
value_id asc
) as local_rn
from
(
select
cate_id,
property_id,
value_id,
pmod(abs(hash(property_id, value_id)), 100) as sec_part -- 这个地方改成了hash,因为hash加盐比较稳定,而rand()是随机的,每次执行结果可能不同。
from
hot_data
) s
) p
where
local_rn <= {n} ) x ) y where rn <= {n};
案例4:去重类问题
很多 row_number() 的真实用途其实是去重,比如下面这种写法:
select
*
from
(
select
*,
row_number() over(
partition by user_id,
item_id
order by
update_time desc
) as rn
from
table_a
) t
where
rn = 1;遇到任何问题,不要先着急想怎么解决,可以先尝试反问自己:这个问题一定要有吗?可不可以不让这个问题出现
对于上面这个场景来说,我们可以先确认两个问题:
-
是否真的需要按照 update_time 取最新?
-
还是只要每组保留任意一条?
如果只是保留任意一条,完全没必要排序,可以直接这样写:
select
user_id,
item_id,
max(col1) as col1,
max(col2) as col2
from table_a
group by user_id, item_id;如果要取最新记录,可以考虑:
select
user_id,
item_id,
max(update_time) as max_update_time
from
table_a
group by
user_id,
item_id;小结一下:去重场景要先区分"任意去重"和"按规则去重"。任意去重不要用 row_number();按规则去重也要优先考虑聚合替代窗口排序。
PS:当然,row_number() 也有自己的优势,那就是开窗不会对数据行数产生影响,写法更加简单一些,不需要过多子查询。
3.总结
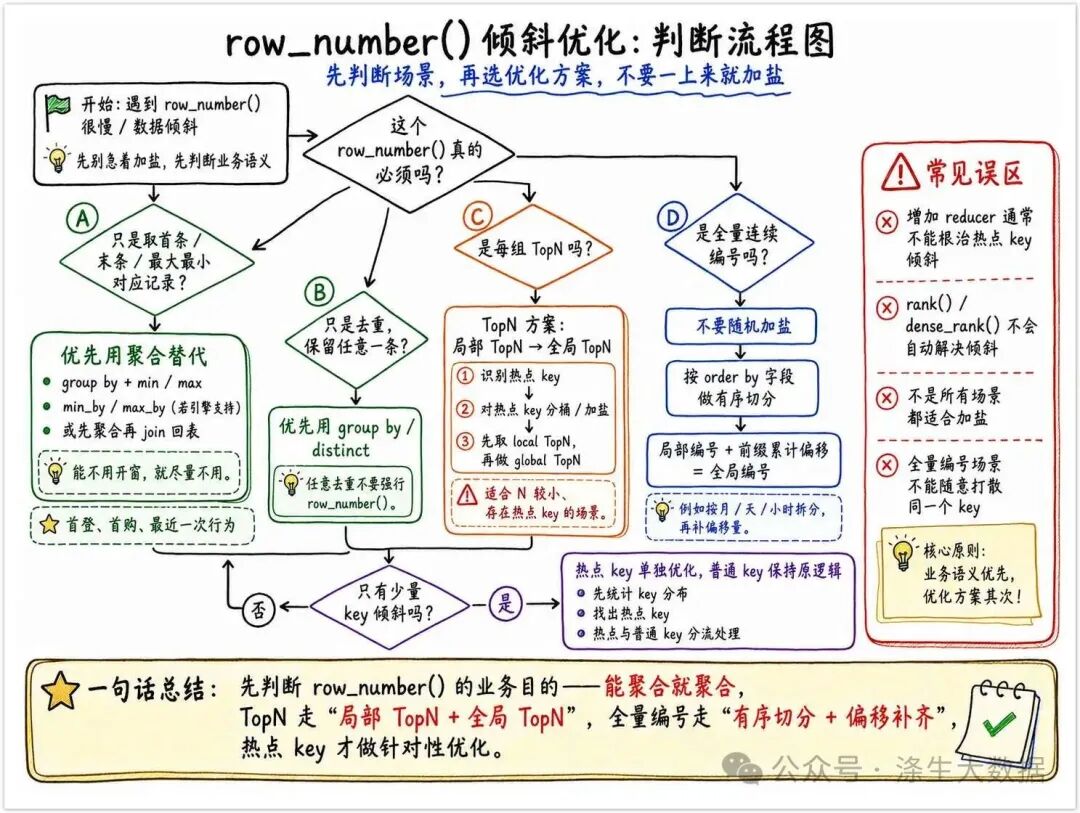
row_number() 数据倾斜的本质,是某些 partition key 下的数据量过大,导致窗口排序无法充分并行。解决这个问题时,不要一上来就加盐,而是先判断业务需求属于哪一类。如果只是取首条、末条、最大值、最小值,要优先用聚合替代窗口函数;如果是 TopN,可以用加盐拆桶,先局部 TopN,再全局 TopN;如果是全量连续编号,则必须按照有序字段进行分治,并通过前缀累计量补齐全局编号。
真正成熟的 SQL 优化,不是把所有问题都套进一个模板,而是先理解业务语义,再选择成本最低、结果正确、稳定可维护的实现方式。