文章目录
- 前言
- 一、核心概念
- 二、缺省参数的两大分类
-
- [1. 全缺省参数](#1. 全缺省参数)
- [2. 半缺省参数](#2. 半缺省参数)
- [三、缺省参数 4 条硬性规则(重点!!!)](#三、缺省参数 4 条硬性规则(重点!!!))
-
- [规则 1:半缺省必须「从右往左、连续」缺省](#规则 1:半缺省必须「从右往左、连续」缺省)
- [规则 2:调用时实参必须「从左往右、依次」传参](#规则 2:调用时实参必须「从左往右、依次」传参)
- [规则 3:声明与定义分离 → 缺省值只写在声明中](#规则 3:声明与定义分离 → 缺省值只写在声明中)
- [规则 4:缺省值只能是「常量 / 全局变量」](#规则 4:缺省值只能是「常量 / 全局变量」)
- 四、缺省参数的实际应用场景
- 总结
前言
缺省参数 (有些地方也叫默认参数)是 C++ 在 C 语言基础上新增的核心语法特性,能让函数调用更灵活、代码更简洁。
一、核心概念
缺省参数 :在声明或定义函数 时,为函数的形参指定一个默认值。调用函数时遵循两个规则:
- 传入实参 → 使用传入的实参;
- 未传入实参 → 使用参数的默认值。
简单理解:调用函数时,没传的参数自动用预设的默认值补上。
二、缺省参数的两大分类
根据参数是否全部指定默认值 ,分为全缺省参数 和半缺省参数。
1. 全缺省参数
函数的所有形参都设置默认值,调用时可以:不传参、传部分参、传全部参。
cpp
#include <iostream>
using namespace std;
// 全缺省:所有参数都有默认值
void Func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
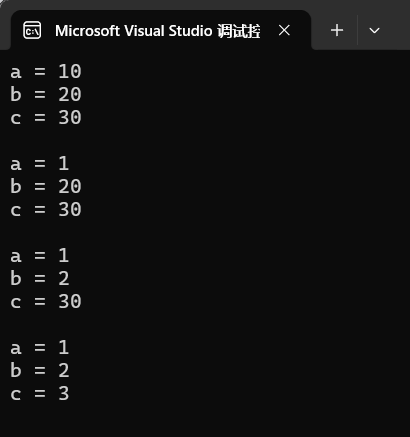
Func1(); // 不传参:全部用默认值 a=10,b=20,c=30
Func1(1); // 传1个参:a=1,b=20,c=30
Func1(1, 2); // 传2个参:a=1,b=2,c=30
Func1(1, 2, 3); // 传3个参:全部用实参 a=1,b=2,c=3
return 0;
}
2. 半缺省参数
函数的部分形参 设置默认值,必须从右往左连续指定,不能间隔、不能从左往右缺。
cpp
#include <iostream>
using namespace std;
// 半缺省:从右往左连续缺省(a无默认,b、c有默认)
void Func2(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func2(100); // 只传a:b=10、c=20(默认值)
Func2(100, 200); // 传a、b:c=20(默认值)
Func2(100, 200, 300);// 传全部参数
return 0;
}禁止的半缺省写法(编译报错):
cpp
// 错误1:从左往右缺,违反连续规则
void Func(int a = 10, int b = 20, int c) {}
// 错误2:间隔缺省,不连续
void Func(int a = 10, int b, int c = 20) {}三、缺省参数 4 条硬性规则(重点!!!)
违反以下规则会直接导致编译报错:
规则 1:半缺省必须「从右往左、连续」缺省
只能从最右侧参数 开始,向左依次设置默认值,不能跳跃、不能从左开始。
规则 2:调用时实参必须「从左往右、依次」传参
调用函数时不能跳跃传参,必须从第一个参数开始依次传入。
cpp
Func1( , 2, 3); // 错误:不能跳过第一个参数规则 3:声明与定义分离 → 缺省值只写在声明中
工程开发中函数声明在头文件、定义在源文件,缺省值只能出现在声明里,定义不能重复写。
cpp
// Stack.h 声明文件
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
// 缺省值仅在声明中指定
void STInit(ST* ps, int n = 4);
// Stack.cpp 定义文件
#include "Stack.h"
// 定义中不能再写缺省值!
void STInit(ST* ps, int n)
{
assert(ps && n > 0);
ps->a = (STDataType*)malloc(n * sizeof(STDataType));
ps->top = 0;
ps->capacity = n;
}规则 4:缺省值只能是「常量 / 全局变量」
不能用局部变量作为缺省参数(局部变量运行时才创建,函数声明在编译期确定)。
四、缺省参数的实际应用场景
本文章采用栈初始化的案例,体现缺省参数的实用性:
- 不知道数据量 → 用默认值4,无需手动指定;
- 知道数据量很大 → 手动传参,一次性开辟空间,避免后续频繁扩容。
频繁扩容会造成的影响:
内存使用 :频繁的扩容会导致大量的内存分配和回收 ,这会降低程序的性能 。
停顿时间 :在数组扩容的过程中,程序可能会出现短暂的停顿时间,影响程序的效率。
cpp
// Stack.h 声明文件
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps, int n = 4);
void STPush(ST* ps, STDataType x);
// Stack.cpp 定义文件
#include "Stack.h"
void STInit(ST* ps, int n)
{
assert(ps && n > 0);
ps->a = (STDataType*)malloc(n * sizeof(STDataType));
ps->top = 0;
ps->capacity = n;
}
void STPush(ST* ps, STDataType x)
{
assert(ps);
// 满了, 扩容
if (ps->top == ps->capacity)
{
printf("扩容\n");
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity
* 2;
STDataType* tmp = (STDataType*)realloc(ps->a,
newcapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
}
// test.cpp
#include "Stack.h"
int main()
{
ST s1;
STInit(&s1); // 不传参:默认开4个空间,适合小数据
// 知道要插入1000个数据,可以初始化就开好,避免频繁扩容
ST s2;
STInit(&s2, 1000); // 传参:直接开1000空间,无扩容损耗
for (size_t i = 0; i < 1000; i++) {
STPush(&st2, i);
}
return 0;
}总结
本文主要针对C++的缺省参数进行解析,方便更好地理解和学习。