最近遇到一个的粉丝,问了一个问题:

总结成一句话就是:
AI生成到90%突然断了,你的恢复方案是什么?
这个问题其实在AI技术面试中经常被问到,也是一个"看似简单, 实则深奥"的问题。
如果大家的AI产品也遇到过以下问题,这篇文章将会非常有帮助:
- 用户网络波动(比如断网,网速时慢时快),WiFi 自动降级导致AI项目的流式输出中断
- 浏览器标签页被误关,重新打开后对话记录还在,但刚才那轮生成的内容丢失了
- 长任务生成到一半,服务端负载过高触发自动扩容,连接被重置
- 用户主动刷新页面,想保存刚才的内容,数据却丢失了
流式生成的核心价值是"快",但如果"快"伴随着不稳定(不可靠),用户体验就会从"惊艳"变成"崩溃"。
所以作为优秀的产品经理和AI产品开发者,为了打造最好的用户体验,这一"关",我们必须攻克。
接下来我就站在面试官的角度,系统的分析这个问题,并提供一个专业,可实操作,可落地的解决方案。
一个底层的背景:为什么流式生成天生脆弱?
要想深度理解"AI生成中断"问题的重要性,我们需要了解传统流式架构的几个痛点:
1. 纯内存状态:一断全丢
标准的 SSE(Server-Sent Events)或 WebSocket 流式架构中,生成状态通常只存在于如下图所示三个位置:
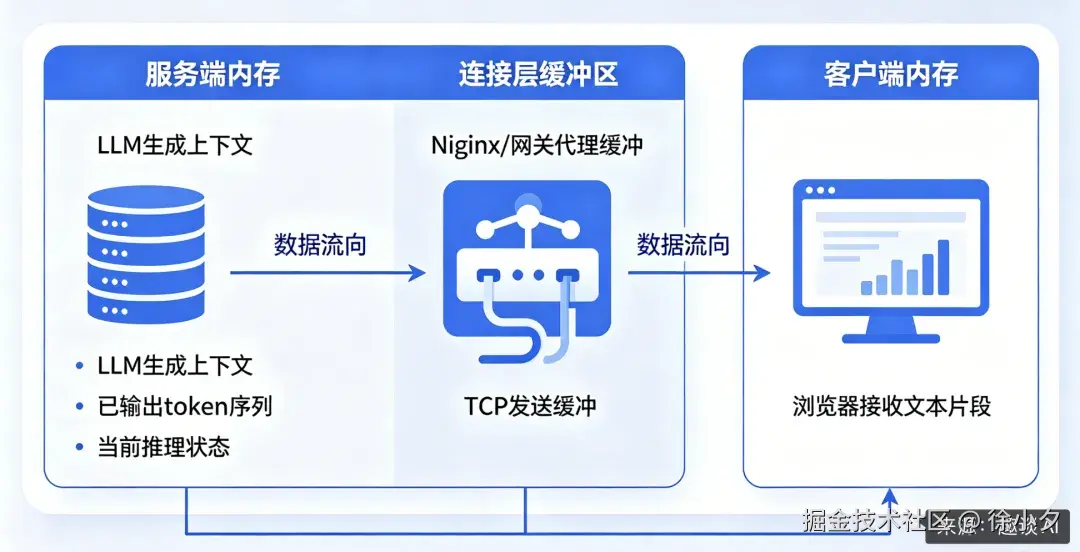
这三层全是易失性存储。 任何一层断裂,状态就彻底消失。
更复杂的问题是,LLM 生成具有强烈的顺序依赖性------第100个token的生成依赖前99个token的上下文,你无法像下载文件那样"从中间开始"。
2. 大模型的"不可重入"性(可以说是痛中之痛了)
这里给大家分享一个反直觉的事实:大多数AI生成请求不是幂等的。
即使我们把用户的 Prompt 原封不动再发一次,由于大模型的温度参数和采样的随机性,会导致第二次生成的结果和第一次完全不同。
这意味着"重新生成"不是"恢复",而是"替换"。
对于长文本生成、代码生成、报告撰写这类场景,用户往往对第一次生成的"中间态"已经有了认知预期( 可能已经读了一半,认为AI中断后继续生成, 应该按照中断之前的内容继续生成,如果替换,等于否定用户的Tokens)
3. 业务成本的损耗
从商业角度看,一次中断的代价远不止用户体验,还包含如下成本投入:
- 算力浪费:生成到90%中断,这90%的token消耗已经产生成本,但用户没看到结果(不过主流的AI产品貌似做了一下平权优化)
- 上下文窗口浪费:恢复时如果从头重传历史消息,会快速吃掉宝贵的上下文长度
- 用户流失 :我们内部AI产品的数据统计表明,一次"长生成中断"的用户,7日留存率下降约20%(太痛了)
综合上面的分析,其实结论已经很清晰了:流式生成必须像视频播放一样支持"断点续传"。
第一问:宏观思路------如果让你一句话概括解决方案,你会怎么说?
面试官:"如果让你用一句话概括你的"AI中断恢复"的实现思路,你会怎么做?"
答 :"我会让生成过程像视频播放一样支持断点续传------核心是在生成过程中持续'落盘'状态,而不是等到结束才保存。"
面试官:"具体怎么落盘?"
答 :"我设计了一个三层状态恢复模型:
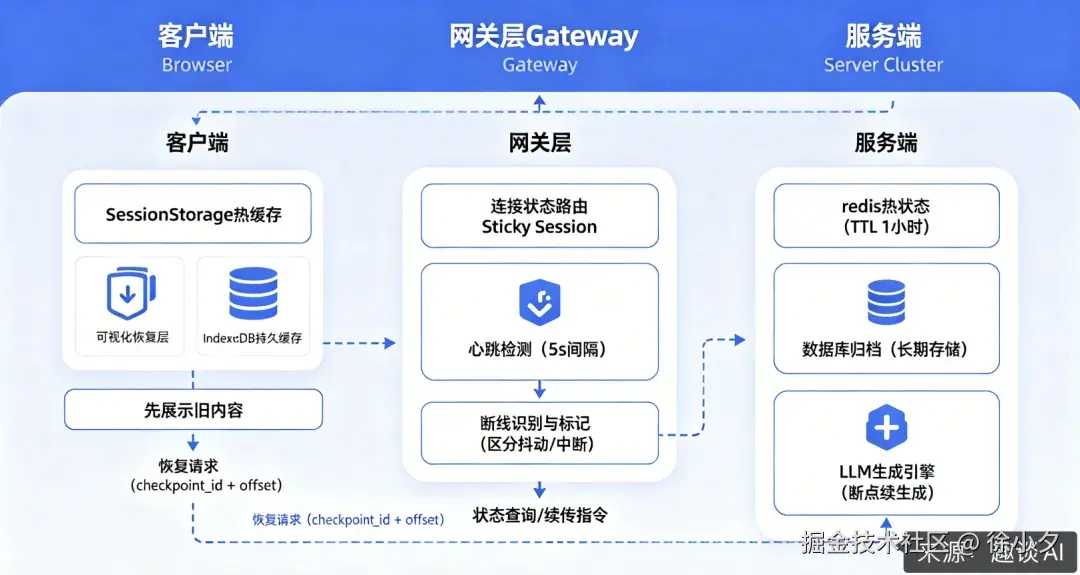
- 客户端缓存层:SessionStorage 做热缓存,IndexedDB 做持久缓存,页面刷新后先让用户直接看到上一次已经生成的内容;
- 网关缓冲层:负责连接状态路由、心跳检测、区分'网络抖动'和'真正中断';
- 服务端持久层:Redis 保存热生成状态(包括了 KV Cache),然后数据库做长期归档。
三层之间通过 checkpoint_id + offset + hash 三元组串联,确保恢复时的幂等性和数据一致性。"
同时在实现方案时,需要遵循如下几个实现原则:
1. 渐进式持久化
不要等到生成结束才保存。每生成一个"逻辑段落"(比如每512个token或每个自然段落结束),就触发一次状态快照。这样的好处是:即使对话中断,丢失的也只是最后一个段落,而不是全部。
2. 客户端是第一恢复"数据源"
建议优先从客户端的缓存中恢复已接收内容,实现"所见即所得"的视觉反馈,服务端只需补充"未接收的部分"。(当然也可以从统一服务端缓存层进行持久化兜底)
3. 幂等性设计(面试必备术语,用于"装"那啥)
通过 request_id + checkpoint_id + offset 三元组,确保同一恢复请求永远产生确定性的续传结果。
好啊,下面继续深入技术实现。
第二问:架构深挖------服务端怎么知道该从哪恢复呢?
面试官:"用户刷新页面后,客户端发了一个恢复请求过来。服务端如何判断'这个请求是要续传',而不是'新请求'?"
答 :"靠断点标记协议。我在 SSE 的每个数据包里都嵌入了 checkpoint 元信息,代码案例如下:

客户端在每次收到 chunk 时,都会把这个 checkpoint 存到本地。恢复时,在请求头(headers)中带上如下信息(标识):
X-Checkpoint-ID: 本次生成的唯一标识X-Client-Offset: 客户端最后收到的token数X-Content-Hash: 本地缓存内容的校验和
服务端收到 Headers 中的标识信息后,会先去 Redis 查这个 checkpoint_id。如果存在,说明生成状态还在有效期内,可以进入续传流程。"
面试官:"那如果客户端缓存损坏了,hash 校验不通过,又该怎么处理呢?"
答:"那就退回到上一个可靠的 checkpoint 重新发送,而不是盲目续传。宁愿多传一点重复内容,也不能让恢复后的内容出现断层或乱码。"
第三问(状态机设计):AI生成到一半,突然断了,服务端的状态该怎么处理?
面试官:"连接断开的那一时刻,LLM 可能还在推理,这个时候是直接停止生成,还是有其他更好的方案呢?"
答 :"不用停止生成,这正是最容易踩坑的地方。我设计了一个六状态生成状态机:

状态转换的规则如下:
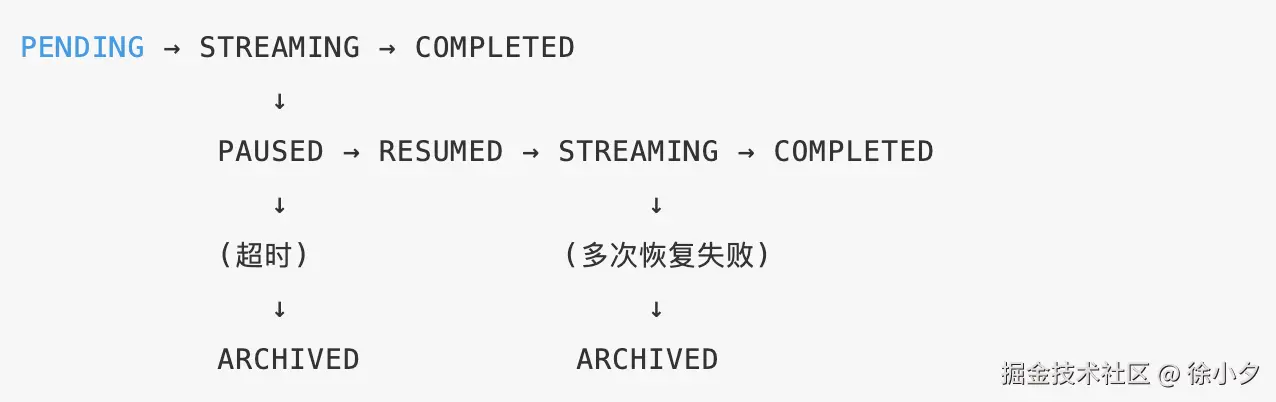
具体分享一下我的思路:
首先,当网关层检测到连接中断(连续3次心跳丢失)时,我们需要做的不是销毁状态,而是把状态机切到 PAUSED(暂停)。此时需要做的是:
- 冻结生成上下文 :把当前的
messages、past_key_values(KV Cache)、已输出token序列做序列化; - 写入Redis :
SETEX generation:chk_xxx 3600,TTL设1小时; - 异步归档:同时写入数据库(持久化备份, 企业级必备意识),保留3-7天,防止Redis淘汰。
核心设计价值在于:在'网络抖动'阶段(心跳延迟>2秒)就进入'预暂停',提前冻结。 因为 LLM 推理一直在消耗算力,如果等确认断连再冻结,可能已经有大量新生成内容送不到客户端,造成算力浪费。"
面试官:"Redis 挂了又该怎么办?" (可见面试官被企业问题折磨的不轻)
答:"Redis 是热存储,挂了就从数据库冷存储恢复。虽然延迟相对高一些(几十毫秒到几百毫秒),但至少不会丢状态。另一方面,我对 KV Cache 做了 INT8 量化压缩,能减少 70% 的 Redis 内存占用,避免高峰期 OOM。"
Good,我们继续下一个刁钻的技术面。
第四问:客户端策略------页面刷新了,用户凭什么能看到旧内容?
面试官:"用户刷新页面,浏览器内存全清空了,你凭什么让用户立即看到之前的内容?"
答 :"靠客户端双保险缓存, 具体的实现代码如下:

恢复时的优先级顺序是:内存 > IndexedDB > 服务端冷存储。
页面打开后,前端先读 IndexedDB(浏览器本地存储),立刻把旧内容渲染到对话区域,同时发恢复请求给服务端。
用户看到的效果是:内容已经渲染了,光标在文本末尾一直不停地闪烁,新的文字继续流出。用户根本不知道这是一次恢复,会认为只是'暂停了一下'。这样设计对用户体验来说比较友好~"
更健壮的代码实现如下,大家可以参考一下:
python
# 伪代码示意
class StreamingCheckpointManager:
def __init__(self):
self.redis = RedisClient()
self.db = Database()
async def freeze_generation(self, checkpoint_id: str, context: GenerationContext):
# 1. 序列化生成状态(包含KV Cache和token序列)
serialized = self.serialize_context(context)
# 2. 写入Redis热存储(1小时TTL)
await self.redis.setex(
f"generation:{checkpoint_id}",
ttl=3600,
value=serialized
)
# 3. 异步写入数据库冷存储(7天TTL)
asyncio.create_task(
self.db.archive_generation(checkpoint_id, serialized, retain_days=7)
)
async def resume_generation(self, checkpoint_id: str, client_offset: int):
# 1. 先查Redis
state = await self.redis.get(f"generation:{checkpoint_id}")
# 2. Redis未命中,查数据库
if not state:
state = await self.db.get_generation(checkpoint_id)
if not state:
raise CheckpointNotFound("生成记录已过期或不存在")
# 3. 反序列化上下文
context = self.deserialize_context(state)
# 4. 如果客户端offset小于服务端已生成量,先补发历史内容
if client_offset < context.output_length:
await self.replay_history(client_offset)
# 5. 如果生成尚未完成,继续流式输出
if context.state != GenerationState.COMPLETED:
await self.continue_generation(context)面试官:"如果用户换了设备呢?比如手机断了,在电脑上打开同一个页面,如何解决同步?"
答 :"这是更业务场景的功能实现了。我们可以把 checkpoint 与用户账号 绑定,而不是设备绑定。电脑端进入同一会话时,检测到该会如果话存在 PAUSED 状态的 checkpoint,就会提示用户:'检测到您在手机端有未完成的生成,是否继续?' 这对跨设备协作的场景非常有用。"
第五问:极限边界场景探索(考验求职者的创新和思考能力了)
面试官:"我问几个边界情况。第一,AI生成恢复时,已生成的内容过长,重新组装 Prompt 再发给模型,上下文窗口溢出了怎么办?"
答 :"可以对已生成内容,做智能摘要压缩 ,只保留关键结论作为上下文,而不是全文重传。我们可以在 Prompt 里区分 history_summary 和 continuing_context,让模型知道'这是前文摘要,请基于它继续完成'。"
这是一个非常实用且高频的解决方案,建议大家在AI项目中都采用。
面试官:"第二个问题,LLM 有随机性,恢复后续写时,风格变了、人称变了,前后不一致怎么办?"
答 :"在恢复 Prompt 里注入风格锚点(style anchor),明确告知模型'请保持前文的第一人称叙述风格'。同时,checkpoint 里记录了生成时的 temperature 和 top_p,恢复时严格复用,最大程度保证一致性。"
面试官:"第三个问题,如果模型版本升级了,旧版 KV Cache 新版加载不了,如何解决呢?"
答 :"可以通过序列化时加入模型版本标识 和序列化协议版本。恢复时严格校验兼容性,不兼容时自动降级为'文本级恢复'------从文本断点重新生成,而不是推理状态断点。虽然会多花一点算力,但至少不会崩溃。"
此时面试官是不是已经急切的想要"招"你了。下面为了挽回自己的颜面,补充一个"加时赛"。
最后一问:如果让你给团队落地,优先级该怎么设计?
面试官:"假设你们团队现在资源有限。让你排优先级,你会先做什么,后做什么?"
答:"我会分三步来落地:
第一步:先做客户端 IndexedDB 缓存 + 服务端文本级断点续传。不碰 KV Cache 序列化,只记录已生成的文本和 offset。恢复时从文本断点重新调用模型生成。这样投入最小,但能解决80%的用户痛点。用时大概1-3天,当然也需要评估团队目前的技术实力,是否需要配合AI辅助来完成。
第二步:引入 Redis 热状态存储,实现KV Cache的序列化与恢复。这是性能拐点,能把恢复后的首 token 延迟从秒级降到毫秒级。如果用AI Coding,不考虑产品UI和交互逻辑,1天内应该可以搞定。
第三步:做网关层的心跳检测、多端同步、分级TTL策略。这是稳定性拐点,让方案能扛住生产环境的高峰流量。" 这个需要团队前后端运维多方配合,预计大概3-5天能完整落地。
面试官:"为什么要先做客户端缓存,而不是先做服务端 KV Cache?"
答 :"因为我的思路中,用户体验的永远是第一优先级,比服务端性能优化更直观成本也更低。"
最后:给正在准备面试或转型AI的各位粉丝
如果大家正在准备AI工程、后端架构或大模型应用相关的面试,"流式生成状态恢复"是一个非常能体现工程深度的面试题。
给大家分享一个面试回答框架:**
**
场景痛点 → 架构分层 → 协议设计 → 边界兜底 → 落地优先级。
这个结构能帮大家把自己的技术回答变得既有广度又有深度。