一、为什么神经网络需要激活函数?
很多新手初学神经网络时会疑惑:为什么不能直接用线性层堆叠,一定要加激活函数?
这里给出核心结论:纯线性层堆叠,无论网络多深,本质都是单层线性变换,无法拟合复杂非线性任务。
公式证明:假设两层线性变换 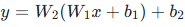 ,化简后依然是
,化简后依然是 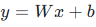 ,完全丢失深层网络的拟合能力。
,完全丢失深层网络的拟合能力。
激活函数的核心作用 :引入非线性特性,让深层神经网络具备拟合任意复杂函数的能力(通用近似定理),同时过滤冗余特征、提升模型泛化能力。
本文将详解深度学习中6种最常用的激活函数,从零梳理公式、图像、优缺点、梯度问题、适用场景,最后附全网通用选型指南,彻底解决激活函数选择难题。
二、Sigmoid激活函数(逻辑回归函数)
2.1 数学公式与值域
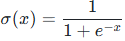
输出值域 :
函数特性:单调递增、连续光滑、处处可导,是经典的S型饱和函数。
2.2 核心优点
-
输出归一化在0-1之间,可直接表征概率值,适合二分类、概率预测场景;
-
曲线平滑、梯度连续,训练过程相对稳定;
-
物理意义清晰,可解释性强。
2.3 致命缺点(核心劝退点)
-
极易梯度消失 :当输入
 时,函数进入饱和区,梯度无限趋近于0,深层网络参数无法更新;
时,函数进入饱和区,梯度无限趋近于0,深层网络参数无法更新; -
输出非零均值:输出恒大于0,会导致后一层输入偏移,梯度更新震荡、收敛缓慢;
-
指数运算开销大:包含幂运算,计算成本远高于线性激活函数,不利于大规模训练。
2.4 适用场景
仅用于二分类任务输出层 、概率预测场景;严禁用于隐藏层,深层网络极易梯度消失。
三、Tanh激活函数(双曲正切函数)
3.1 数学公式与值域
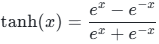
输出值域 :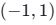
本质:Sigmoid函数的平移缩放版本,曲线形态与Sigmoid高度相似。
3.2 优化改进
解决了Sigmoid非零均值的问题,输出以0为中心,数据分布更均衡,模型收敛速度更快。
3.3 遗留缺陷
-
依然存在梯度消失:正负区间两端饱和,输入极值时梯度趋近于0;
-
计算开销依旧较高:包含多次指数运算;
-
深层网络表现依然受限。
3.4 适用场景
早期用于RNN、LSTM隐藏层、小维度特征归一化;目前基本被ReLU系列替代,仅少量传统模型使用。
四、ReLU激活函数(修正线性单元)
ReLU是目前深度学习最主流、默认首选的激活函数,CNN、Transformer、MLP基础模型标配。
4.1 数学公式与值域
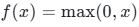
输出值域 :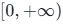
函数逻辑:输入正数直接保留,输入负数直接置0。
4.2 核心优势(碾压Sigmoid/Tanh)
-
计算极快:无指数、幂运算,仅做简单判断,训练速度大幅提升;
-
缓解梯度消失:正数区间梯度恒为1,无饱和区,深层网络梯度可正常回传;
-
稀疏性激活:负数置0,自动过滤无效特征,稀疏化网络,降低过拟合风险。
4.3 致命缺陷:死亡ReLU问题
死亡ReLU(Dead ReLU):当输入持续为负数时,输出恒为0、梯度恒为0,神经元参数永久不更新,彻底失效"死亡"。
常见诱因:学习率过大、参数初始化不当,导致大量输入落入负区间。
同时存在输出非零均值问题,数据分布偏移。
4.4 适用场景
几乎所有卷积网络、全连接网络、Transformer隐藏层默认首选激活函数。
五、Leaky ReLU激活函数(ReLU改进版)
专为解决死亡ReLU问题设计,是ReLU最经典的优化变体。
5.1 数学公式与值域
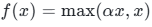
通常取 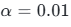
输出值域 :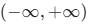
函数逻辑:正数区间等价ReLU,负数区间保留极小斜率,不直接置0。
5.2 核心改进
-
彻底解决神经元死亡:负区间存在微小梯度,参数可持续更新;
-
保留ReLU计算快、无梯度消失的优势;
-
兼顾稀疏性与特征完整性,避免丢失负数有效特征。
5.3 微小缺陷
负数区间固定斜率,无法自适应不同数据集特征,泛化能力有局限。
5.4 适用场景
ReLU出现神经元死亡、梯度停滞的场景;图像分割、GAN生成网络、轻量化模型首选。
六、Swish激活函数
Google提出的平滑激活函数,兼顾ReLU的高效性与Sigmoid的平滑性,在深层模型表现更优。
6.1 数学公式与值域
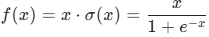
输出值域 :
6.2 核心优点
-
全程光滑可导,无折点,梯度更新更平滑、收敛更稳定;
-
负区间不会硬置0,避免特征丢失、神经元死亡;
-
自适应门控特性,拟合能力强于ReLU系列。
6.3 缺点
包含Sigmoid指数运算,计算开销略高于ReLU;低浅层网络提升不明显。
6.4 适用场景
深层CNN、大型分类模型、高精度任务,替代ReLU可小幅提升精度。
七、GELU激活函数(现代大模型标配)
GELU是BERT、GPT、Transformer大模型标配激活函数,目前NLP、多模态模型主流首选。
7.1 核心原理与公式
基于高斯分布的随机正则化激活,公式近似:
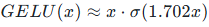
核心逻辑:结合 dropout 随机正则化思想,根据输入自适应加权,比固定激活更智能。
7.2 核心优势
-
具备随机性正则化效果,无需额外dropout,抑制过拟合;
-
平滑度极高,梯度稳定,适配超深层大模型训练;
-
拟合能力远超ReLU、Swish,是大模型性能优异的关键细节之一。
7.3 缺点
计算开销最大,轻量化小模型使用会增加冗余算力。
7.4 适用场景
Transformer、BERT、GPT等NLP大模型、多模态模型、高精度深度学习任务。
八、六大激活函数全方位对比表
| 激活函数 | 值域 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Sigmoid | (0,1) | 输出概率化、可解释性强 | 梯度消失、非零均值、计算慢 | 二分类输出层、概率预测 |
| Tanh | (-1,1) | 零均值、收敛快于Sigmoid | 依然梯度消失、计算开销大 | 传统RNN小模型、旧版本网络 |
| ReLU | [0,+∞) | 计算极速、缓解梯度消失、稀疏性强 | 神经元死亡、非零均值 | CNN/MLP常规隐藏层(默认首选) |
| Leaky ReLU | (-∞,+∞) | 杜绝神经元死亡、保留ReLU优势 | 固定斜率、自适应能力弱 | GAN、分割任务、ReLU失效场景 |
| Swish | (-∞,+∞) | 全程平滑、无死亡神经元、精度更高 | 计算开销略高 | 深层高精度CNN模型 |
| GELU | (-∞,+∞) | 自适应正则、梯度稳、拟合能力极强 | 计算开销最大 | Transformer、BERT、GPT大模型 |
九、深度学习激活函数终极选型指南
新手直接背诵这套通用选型规则,99%场景不会出错:
-
常规CNN、分类、检测、轻量化模型 :无脑选 ReLU(速度、精度、稳定性平衡最优);
-
出现训练停滞、神经元死亡 :替换为 Leaky ReLU;
-
二分类任务输出层 :固定使用 Sigmoid;
-
多分类任务输出层 :搭配 Softmax(不属于激活函数,为归一化函数);
-
高精度深层视觉模型 :优先 Swish;
-
NLP大模型、Transformer系列 :固定标配 GELU;
-
所有隐藏层禁止使用Sigmoid/Tanh,梯度消失严重,训练效率极低。
十、全文总结
-
激活函数的核心价值是引入非线性,让深层网络具备复杂拟合能力;
-
传统Sigmoid/Tanh因梯度消失、计算低效,已逐步退出隐藏层,仅保留少量输出层场景;
-
ReLU系列是传统CV、通用模型的基石,Leaky ReLU解决其神经元死亡缺陷;
-
Swish、GELU属于进阶平滑激活函数,适配深层、高精度、大模型场景,是当前前沿模型的主流选择;
-
工程落地优先遵循通用选型规则,可极大降低训练bug、梯度异常、收敛缓慢等问题。