精选专栏链接 🔗
欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中~
【LeetCode 热题 100】字母异位分组
📝题目描述
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
示例 1:
bash
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]解释:
- 在 strs 中没有字符串可以通过重新排列来形成 "bat";
- 字符串 "nat" 和 "tan" 是字母异位词,因为它们可以重新排列以形成彼此;
- 字符串 "ate" ,"eat" 和 "tea" 是字母异位词,因为它们可以重新排列以形成彼此。
示例 2:
bash
输入: strs = [""]
输出: [[""]]示例 3:
bash
输入: strs = ["a"]
输出: [["a"]]💡提示信息
- 1 <= strs.length <= 10 4 10^4 104;
- 0 <= strsi.length <= 100;
- strsi 仅包含小写字母;
核心思路是:要将它们分组,我们需要找到一个共同的特征(Key)。只要两个字符串的"特征"一致,它们就属于同一组。
方法一:排序法
这是最容易想到的解法。既然字母异位词只是顺序不同,那如果我们把它们都按字母顺序重新排序,它们就变成同一个字符串了。
核心逻辑:
- 遍历字符串数组,将每个字符串转换为字符数组并进行排序;
- 排序后的字符串就是它的 "指纹标识" ;
- 使用哈希表存储:Key = 排序后的字符串, Value = 原字符串列表。
Java代码实现如下:
java
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
// 创建一个哈希表接收结果,Key是排序后的字符串,Value是原字符串的列表
HashMap<String, ArrayList> resultMap = new HashMap<>();
for(String str : strs){
// 1. 将字符串转为字符数组
char[] temp = str.toCharArray();
// 2. 排序(该方法直接修改原数组,无需接收返回值。)
Arrays.sort(temp);
// 3. 转回字符串,作为 Key
String key = new String(temp);
// 4. 如果 Key 不存在,初始化一个新的 List
if(!resultMap.containsKey(key)){
// 5. 将原字符串加入对应的组
resultMap.put(key,new ArrayList());
}
resultMap.get(key).add(str);
}
// 返回所有的分组
// map.get(key)返回当前key对应的字符串列表List<String>;
// .add(str) 将原字符串 str 直接追加到该列表末尾
return new ArrayList(resultMap.values());
}
}提交代码,运行结果如下:
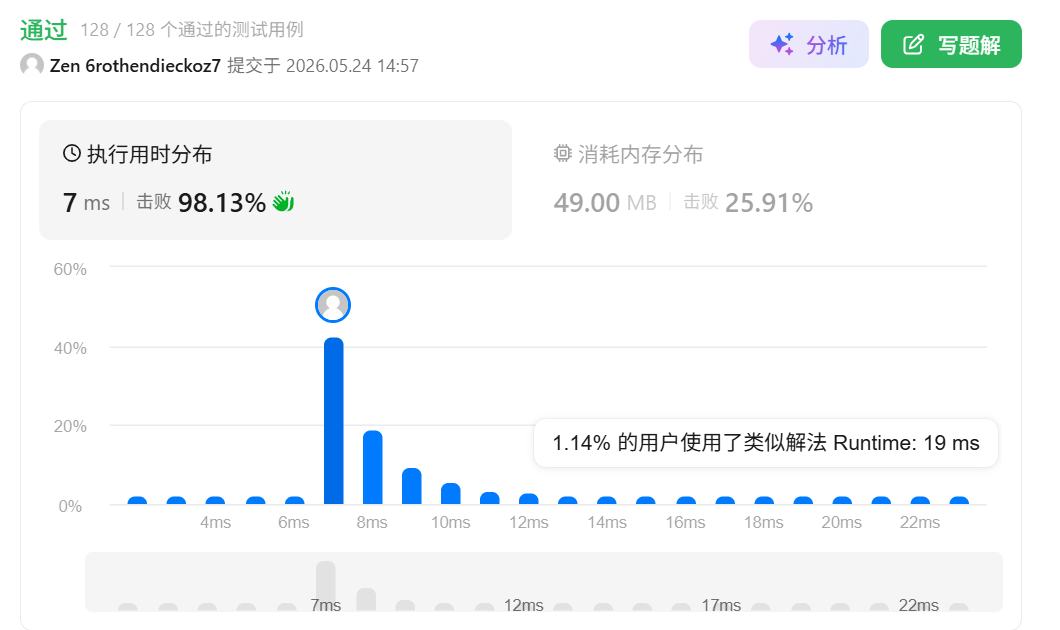
- 执行用时分析:击败 98.13% 的提交者。你的代码运行速度极快,属于第一梯队的解法;
- 消耗内存分析:击败 25.91% 的提交者。内存占用偏高,处于后 25% 的水平。
方法二:计数哈希法
字母异位词的本质在于字符种类和出现次数相同 。因此,我们可以直接统计字符频率来构建特征,从而将时间复杂度优化至线性级别 O(K)。
核心逻辑
- 遍历字符串数组;
- 统计每个字符串中 'a' 到 'z' 出现的频率(如使用长度为 26 的数组);
- 构建 Key:将这个频率数组转换成一个唯一的字符串作为 Key,存入哈希表(如用 # 分隔每个字符的计数);
- 哈希存储:将原字符串存入哈希表对应的分组中。
Java代码实现如下:
java
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, ArrayList<String>> resultMap = new HashMap<>();
for(String str:strs){
// 1. 统计字符频率
int[] count = new int[26];
for(char c:str.toCharArray()){
count[c-'a']++;
}
// 2. 将频率数组转化为唯一的 Key。例如 "12" -> "#1#2..." 这种格式
StringBuilder sb = new StringBuilder();
for(int freq:count){
sb.append("#"); // 分隔符
sb.append(freq);
}
// 3. 存入哈希表
String key = sb.toString();
if(!resultMap.containsKey(key)){
resultMap.put(key, new ArrayList<>());
}
resultMap.get(key).add(str);
}
return new ArrayList(resultMap.values());
}
}提交代码:运行结果如下:
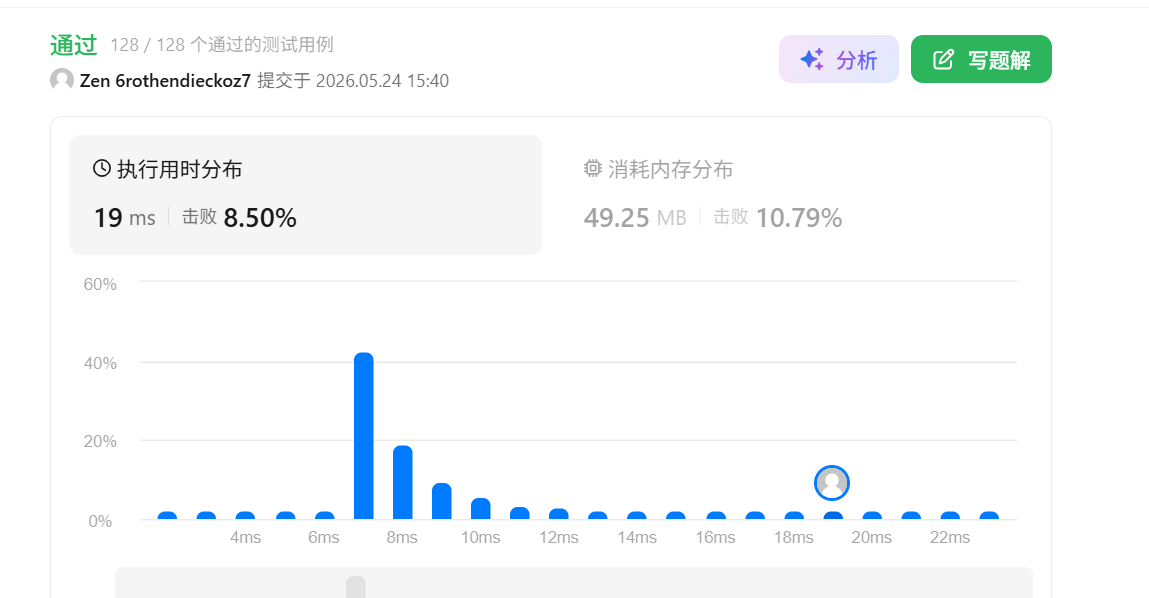
观察结果可以发现,和排序法相比,虽然哈希法的时间复杂度降低了,但在力扣上的效果确远不如排序法。原因是:
虽然计数法数学上更优,但在 LeetCode 里却输给了排序法。原因在于测试用例的单词都很短,排序几乎不花时间;而计数法为了生成"指纹",必须死板地遍历 26 个字母并拼接字符串,这些额外的"准备工作"反而比直接排序还要慢。这提醒我们:在数据量级较小时,过度优化反而是一种负担。
对比总结
在解决"字母异位词分组"问题时,排序法 和计数哈希法分别代表了"代码简洁优先"和"理论性能优先"两种不同的工程思路。虽然在 LeetCode 的特定测试用例下,排序法的实际运行速度往往更快,但这并不代表计数法没有价值。以下是两种方法的详细对比:
| 维度 | 排序法 | 计数哈希法 |
|---|---|---|
| 核心思想 | 将字符串排序,异位词排序后必相同 | 统计字符频率,频率分布相同即为异位词 |
| 时间复杂度 | O ( N ⋅ K log K ) O(N \cdot K \log K) O(N⋅KlogK) | O ( N ⋅ K ) O(N \cdot K) O(N⋅K) (理论最优) |
| 空间复杂度 | O ( N ⋅ K ) O(N \cdot K) O(N⋅K) | O ( N ⋅ K ) O(N \cdot K) O(N⋅K) |
| 代码复杂度 | 极低 (依赖排序) | 中等 (需处理数组转字符串逻辑) |
| 通用性 | 高 (支持任意字符集,如中文、Emoji) | 低 (通常仅限小写字母,扩展性差) |
| LeetCode 实测 | 较快 (得益于短字符串 + 底层优化) | 较慢 (常数项过大,Key 构建耗时) |
- 在 LeetCode 刷题或日常业务中 :
首选 排序法 。因为日常业务中的单词、短语长度( K K K)通常很短, log K \log K logK 的增长可以忽略不计,而Arrays.sort的底层优化使得其常数极小。排序法代码量少,不易出错,且天然支持各种字符集。- 在面试/高阶优化中 :
计数哈希法是绝对的加分项。当面试官追问"如果字符串非常长(例如长文本),排序太慢怎么办?"时,提出计数法能体现我们对算法复杂度的深刻理解。
一句话总结:
排序法是"短平快"的实战首选,而计数法是应对"超长文本"场景的杀手锏。
这道题不仅考察我们对字符串的处理能力,更是检验我们对 哈希表 这一核心数据结构理解的试金石。