对照项目 Agentium 的背景:Agentium 论文与开源项目介绍。本文图表及核心设计均来自开源项目Agentium,源码详见GitHub。
连载 06《AI 网关:路由、限流、内容与成本》 在网关处守住了 token 与内容安全。本篇回到「模型看见什么」 :对话历史会涨、事实要跨会话保留、检索库又另有一套------若全塞进 prompt,窗口和账单一起爆。记忆系统要回答:什么留在短期上下文里、什么写进外部记忆、读写各走哪条路。
两类「记忆」,别混成一个数组
工程上至少拆两块:
- 短期上下文(working context)
当前 Turn 要发给模型的messages列表:system、最近若干轮 user/assistant。来源通常是会话消息表;组装时要过 上下文预算------软删旧轮、硬停或降级摘要。 - 长期 / 分层外部记忆(external memory)
结构化记录:租户、层(短/中/长)、键、载荷、时间戳。通过 Memory Service 读写,后端可换 SQLite、进程内、或外联 Mem0 一类平台;不等于把整段聊天记录原样 append 到 prompt。
Chat 里常见组合:消息表管「原话流水」 ,Memory Service 管 摘录、抽取事实、会话摘要 等可检索片段;进模型前再由协调层决定 inject 哪些 scope(会话级 / 用户级)。
Memory Service:薄门面,重隔离
对外接口宜保持小:remember (写)、recall (读)、purge (清租户)。每条记录带 tenant_id + layer + key + payload。
租户隔离是硬 invariant :请求的 tenant_id 与目标租户不一致,直接拒绝并记审计------不能指望后端「碰巧查对了」。这样换 SQLite 还是外联平台,越权读写的形状不变。
Agentium 用三层枚举 SHORT / MID / LONG 表达时间尺度,而不是在业务里散落 magic string:
| 层 | 典型内容 | 生命周期 |
|---|---|---|
| SHORT | 单轮对话摘录、工具结果快照 | 短,可被后台整理 |
| MID | 会话级摘要、本会话抽取事实 | 跟 session_id / run_id 走 |
| LONG | 跨会话用户偏好、稳定事实 | 跟 user_id 走,scope 更宽 |
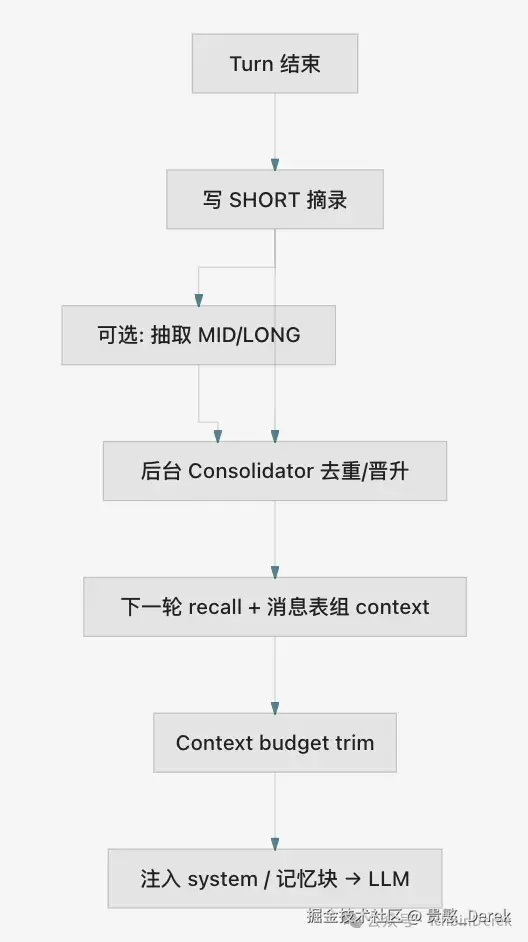
写路径在 Turn 结束后异步或 fire-and-forget:SHORT 先落盘 ,可选 LLM 抽取进 MID/LONG;读路径在下一轮组 prompt 或 API 查询时 按 layer + scope 过滤。
后端可插拔:Protocol 在,实现可换
Memory Service 下面应是 Backend 协议 :append / query / purge_tenant。工厂按配置实例化:
- in-memory:单测与 demo;
- sqlite:本地持久、易备份;
- mem0 等外联 :托管检索与向量能力,但要接受 数据出境 与 API 依赖。
协调层只依赖 Memory Service,不 import 具体后端------这是「可插拔边界」:企业内网部署换 sqlite,SaaS 试点换 mem0,不动 chat turn 逻辑。
泳道路由:同一会话,不同存储策略
当系统同时配置了 native(本地) 与 mem0(外联) 两条泳道时,不能全局写死一条。更稳妥的做法:按会话 metadata 解析 ------例如 workspace 里标记 memory_plugin: mem0 走外联,默认走 native。
隐私先于成本(P0) :若会话标记 local_only / on_prem 一类 residency,禁止 mem0 泳道------即使用户偏好外联,也强制 native;若 native 未配置,应 返回 None / 明确失败,而不是悄悄把受监管数据送到公网记忆库。
这与连载 06 网关的 privacy class 同族:数据驻留约束要在记忆层再守一遍。路由结果宜打结构化日志(选了哪条泳道、是否因 privacy 降级),方便合规复盘。
上下文窗口预算:trim 比「硬塞」体面
模型窗口有限;即使用网关限流,单轮 prompt 仍可能过长。Context budget 典型三档:
- soft limit:超出则丢弃最旧的非 system 消息,保留最近几轮;
- hard limit :仍超则要么抛错,要么进入 safe degrade;
- safe degrade:用短摘要或占位 user 消息替代大段历史,并保留尾部最近轮------用户至少还能接着聊。
system 消息通常 不参与丢弃 ,避免把 persona / 安全指令裁没。token 估算可用字符启发式(如 json 长度 ÷ 4),不必等每次调 tokenizer API------预算层要 快、可预测。
这与 Memory Service 互补:trim 管「原话流水」;MID 层的 running summary 管「裁掉之后还留什么语义」。
读路径 vs 写路径
写(Turn 后)
- SHORT:本轮 user/assistant 预览写入,key 含 session + pair_id;
- MID:LLM 抽取会话事实、Hermes 式 running summary;
- LONG:跨会话用户事实,写前 dedupe(normalize key,避免同义重复)。
读(Turn 前或 API)
- 按
tenant_id+layer+ 可选run_id_filter拉记录; - 用户级 LONG 需再滤
user_id/memory_scope; - 注入 prompt 时控制 条数与总 token,别 recall 200 条全塞进去。
后台 Memory Consolidator (Background 平面)可周期性:SHORT 同 key 去重、存活够久的 promote 到 MID、冲突 payload 打 _conflict_with 标记------保守合并,不覆盖高置信旧记录。
「污染」:评测、生产、租户之间
记忆篇必须提 污染(contamination) ,否则实验结论不可信:
- 评测集事实写进生产 LONG 层 → 模型「偷看答案」;
- A 租户 recall 混入 B 租户 key → 隔离失败(所以 Service 层硬拦 cross-tenant);
- dev 环境 sqlite 拷到 prod → 脏事实永久化;
- 外联 mem0 与本地 native 双写不一致 → 同一会话两条真相。
工程习惯:环境前缀 、purge API 、run_id / session scope 默认收紧 、评测专用 tenant;外联泳道与 local_only 会话 物理上不能 fallback 到外网。
上下文检索扩展(KB)
除「对话记忆」外,还有 文档库 / 知识块 :按 tenant 隔离的 FTS 或向量检索,带 contextual prefix 提升命中。它可以是 Memory 子模块,也可以是独立 KB store------关键是 检索结果进 prompt 前仍过网关安全与 token 预算,别把整库 PDF 灌进去。
一张白板图:从 Turn 到记忆再回上下文
伪代码:memory 与 context budget
scss
function MemoryRecall(ctx, layer, query_scope) -> List[Record]:
assert ctx.tenant_id matches target tenant
lane := MemoryLaneRouter.Resolve(ctx.session_id, privacy_tier)
if lane is None:
return []
records := lane.recall(ctx, layer, limit=N, run_id_filter=scope)
return filter_by_user_scope(records, query_scope)
function MemoryWrite(ctx, layer, key, payload, policy):
assert policy.allows_write(layer, payload)
lane := MemoryLaneRouter.Resolve(ctx.session_id, privacy_tier)
if lane is None:
return Denied
lane.remember(ctx, layer, key, payload)
function ContextWindowTrim(messages, soft, hard, safe_degrade) -> messages:
if estimate_tokens(messages) <= soft:
return messages
kept := [system] + drop_oldest_non_system_until_soft(messages, soft)
if estimate_tokens(kept) <= hard:
return kept
if safe_degrade:
return [system, budget_notice] + tail_recent(kept, k=4)
raise ContextHardStop几句容易踩坑的地方
只有 messages 表没有 Memory Service ------跨会话偏好全靠用户重复自我介绍。Memory 无 tenant 校验 ------一次 bug 就是跨客户泄露。local_only 会话仍 fallback mem0 ------合规直接击穿。recall 不 limit ------prompt 隐形爆炸。SHORT 永不 consolidate ------库膨胀、检索变慢。评测与生产共库 ------指标虚高。把 KB 检索结果绕过内容安全------脏片段直进模型。
收束一下,下一篇讲什么
本篇应能说清:短期上下文与外部记忆的分工 、Memory Service 读写与 backend 边界、泳道与 privacy 门 、context budget 三档、以及 污染 在工程里指什么。
下一篇进入 编排与工作流:从单轮 Chat 到任务图/DAG------协调层怎样串多个 Turn、制品如何贯穿审计。(连载 08)