
TLiveOmni 1.0是一款面向电商直播场景的全模态大模型,原生支持图像、文本、视频、音频四模态统一输入,实现128K上下文窗口。该模型深度扎根电商直播领域,构建了超20项精细化原子能力,包括音频维度的语境感知ASR与多说话人分离、视频维度的商品时序切分与卖点提取、以及图像维度的商品空间定位与细粒度OCR。基于Qwen3-VL-Instruct架构,通过添加音频编码器并采用"模态对齐→能力强化→全任务微调"三阶段训练范式,模型在电商直播场景的关键任务上达到SOTA水平。在推理部署方面,通过定制化vLLM框架和FP8量化技术,在保持精度的同时实现2.5-3.5倍推理加速。实验表明,TLiveOmni 1.0在语音识别、商品定位和文本分类等任务上显著优于现有开源模型,为电商直播内容的深度理解与商业价值挖掘提供了强大支持。

引言
技术的前沿,已不再是模拟单一感官,而是真正融合视觉、听觉与语言进行综合思考。在这一趋势下,多模态(Multi-modal)大模型虽已成为行业主流,但能够统一处理所有信息模态的"全模态"(Omni-modal)模型,仍是技术版图中的稀缺板块。行业数据显示 1,截至2025年11月,全球8大主流厂商的大模型中,全模态占比仅为1.9%,相较于61.4%的单模态和36.7%的多模态,其技术挑战与战略价值不言而喻。为探索这一前沿方向并解决电商直播领域中高信息密度、多模态异构内容(视频、图像、音频、文本)的深度理解问题,我们提出了TLiveOmni 1.0------一个面向电商直播场景的全模态大模型。其核心能力与优势可概括为:
-
全模态融合架构: 原生支持图像、文本、视频、音频四模态统一输入,实现了128K上下文窗口,为端到端流式长时序理解奠定了基础。
-
场景化能力矩阵: 深度扎根电商直播场景,构建了覆盖音频、视频、图像维度的超20项精细化原子能力。包括音频维度的语境感知ASR与多说话人分离,视频维度的商品时序切分与直播卖点提取,以及图像维度的商品空间定位与细粒度OCR,实现了对直播内容的全面解构。
-
工业级部署效率: 不止于实验,更面向生产。基于对vLLM推理框架的深度定制与优化,并支持FP8等量化方案,在保证精度的前提下大幅提升推理吞吐、降低显存占用,为模型的大规模、低成本落地扫清了障碍。
-
业务价值闭环: 将强大的多模态理解能力转化为切实的商业应用。通过端到端的感知-理解-决策链路,为直播全场景理解、直播场次智能诊断、商品讲解模式归纳等高价值场景提供AI引擎,直接驱动人货场运营效率的跃迁。
TLiveOmni 1.0的推出,旨在解决从海量、非结构化的多媒体信息中提取商业价值的核心难题。它通过深度解析画面、声音与文本的内在关联,为商业分析提供了全新的维度。无论是电商直播中的实时互动,还是商品图、短视频中的静态与动态信息,TLiveOmni 1.0都能将其转化为可量化的商业洞察。

背景
电商与内容平台的数字生态,构建于由直播、短视频与图文构成的异构多媒体流之上,这已成为品牌与消费者交互的核心场域。然而,这些高价值的非结构化信息,却呈现出"价值密度高,提取难度大"的核心痛点。在此背景下,传统的单一模态处理范式,在面对真实、复杂、动态的场景时,已暴露出其局限性。具体挑战体现在以下几个层面:
-
音频理解的挑战:高噪、并发与领域专有性
直播等真实场景的音频流具有低信噪比、高并发(多说话人重叠)和内容变化快的特点。此外,内容中充斥着大量领域专属的低频词(如品牌、材质),严重影响了传统语音识别系统的准确性。因此,深度音频理解不仅要求精准的语音转录,更需具备说话人分离、说话人日志等超越标准ASR的能力,以全面捕捉语音中的语义、情感及交互信息。
-
视觉理解的挑战:动态时空与布局解析
视觉信息的挑战源于动态与静态两个维度。在动态的直播流或短视频中,核心商品可能仅出现数秒,并与复杂的背景、道具、主播动作交织在一起,这要求模型具备精准的时序定位与空间定位能力。在静态图像中,信息则常以密集的非结构化图文形式呈现,如何准确提取文字并解析其布局结构与信息层级,是理解视觉信息的关键瓶颈。
-
多模态融合的挑战:语义碎片化与对齐
多模态融合的根本挑战在于跨模态的语义碎片化和语义鸿沟。一个完整的事实信息(如商品促销),其线索往往分散在音频(口播)、视觉(展示)和文本(贴片)等多个通道中。如果缺乏一个统一的表示空间来对这些异构信号进行时序对齐和语义关联,任何单一维度的分析都将导致事实不一致与错误的判断,无法形成对场景的整体认知。
-
计算效率的挑战:高昂的推理成本
高昂的推理成本是全模态模型商业化的核心瓶颈。其庞大的参数规模与长上下文处理需求,带来了高推理延迟与资源消耗,极大地限制了模型的实时应用与规模化部署。因此,在不牺牲精度的前提下,通过模型量化、编解码分离等手段实现推理效率的极致优化,是全模态模型商业化落地的先决条件。
在此背景下,我们设计并实现了全模态大模型TLiveOmni的1.0版本。该模型通过其原生的全模态架构,旨在统一处理长时序、高动态的视听流,以解决跨模态语义碎片化的问题;同时,其高效的推理框架为应对高昂的计算成本提供了可行的工程路径。TLiveOmni模型的最终目标是将非结构化的视听内容系统性地转化为可驱动决策的商业洞察,从而在海量内容与其商业表现之间,建立起可量化的分析链路。

能力矩阵
TLiveOmni是一个全模态的理解大模型,以图像、视频、文本、音频作为输入,以文本作为输出,支持128K上下文长度。当前,TLiveOmni 1.0在电商直播场域支持以下模型能力(更多涌现能力团队仍在挖掘中~):
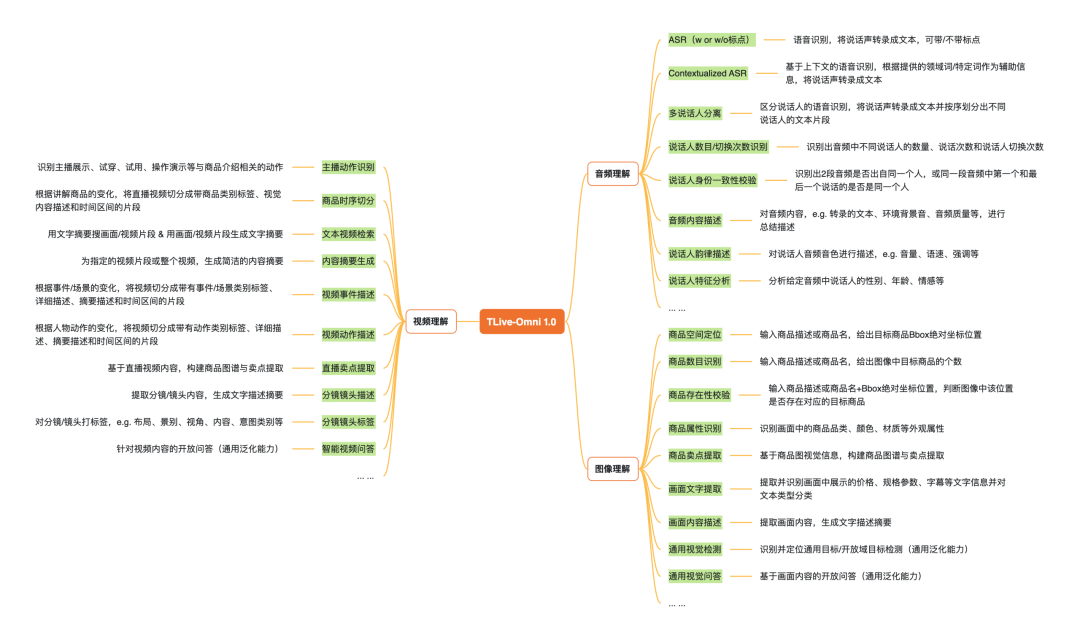
图1:TLiveOmni 1.0模型能力矩阵

模型结构
TLiveOmni 1.0模型以Qwen3-VL-Instruct 2模型为核心基座,其原生架构已具备强大的跨图文模态理解能力。在此基础上,我们用Qwen3-Omni的Audio Transformer (AuT) 3(~0.6B)作为音频编码器,直接复用其在超大规模多语言语音数据(超过 2000 万小时)上预训练所获得的强大表征能力,从而实现视觉、文本与音频三模态的统一建模。
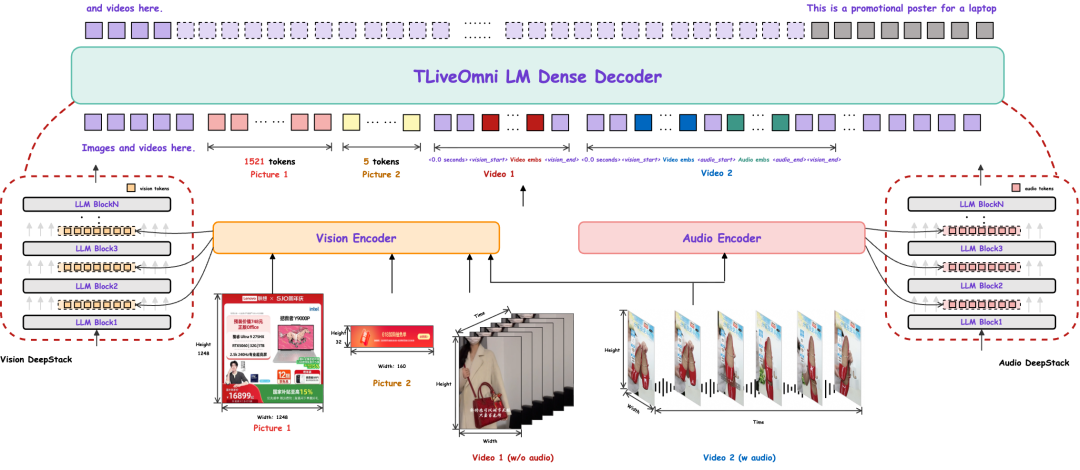
图2:TLiveOmni 1.0模型结构
▐Audio DeepStack
在继承基座模型基础结构的同时,我们参照Qwen3-VL中使用的Vision DeepStack 2方式,设计了Audio DeepStack模块。该模块保持了与AuT中的Aligner相同的结构,由两个线性层与一个激活函数层组成。在前向计算时,我们取Audio Encoder中的第 8, 16, 24层特征,分别经过Audio DeepStack模块映射后,融合至大语言模型(LLM)的前三层特征中,用来增强音频特征的丰富度。实验表明,Audio DeepStack能显著提升模型在各类音频任务上的收敛速度与最终效果。
▐时间编码策略与Token排布
在TLiveOmni 1.0模型中,对于视频输入,相比于Qwen3-Omni模型,我们在以下两个方面进行了关键改进:
-
首先,在时间编码策略上,我们沿用了Qwen3-VL模型中时间编码策略,即在每个视频时间片段前添加一个格式化的文本字符串形式的时间戳,例如
<2.0 seconds>。尽管该方法会略微增加上下文长度,但它使模型能够更有效、更精确地感知时间信息,从而更好地支持视频定位(video grounding)和密集描述(dense captioning)等需具备时间感知能力的视频任务。 -
其次,在视频(含音频)输入下的token排布方面,我们将
<audio_start_token>显式地添加在Audio tokens和Vision tokens之间,用以明确标识音频模态的起始位置,从而在序列层面建立清晰的模态边界,增强模型对多模态时序结构的感知能力。
具体而言,TLiveOmni 1.0在不同输入模态下的token排布示例如下表所示:

表1:TLiveOmni 1.0模型在不同模态数据输入下的Token排布方式

训练框架
▐基础框架
我们基于ms-swift框架和deepspeed分布式引擎(pytorch 2.8、ms-swift 3.9.1和 deepspeed 0.18.0)训练了TLiveOmni 1.0模型,通过原生优化组合提升训练效率:采用Flash Attention 2充分利用GPU SMs减少Attention计算IO,引入Liger Kernel(Triton算子库)对RMSNorm、SwiGLU及CrossEntropyLoss进行算子级优化,最终模型在训练时显存峰值降低了55%,使得模型可以支持更长的上下文。
▐Data Sampler
- 核心问题
全局同步与动态计算图的冲突:在大规模分布式训练中,系统要求所有算力节点在通信步调上严格一致。然而,由视频、音频、图文组成的异构数据会产生动态的计算图。这种"全局强同步"与"局部异构性"的矛盾,是导致训练频繁触发死锁、计算效率低下的根本原因。
- 方案演进
-
初期方案:随机模态采样器
简单按模态随机采样数据,这会导致Batch内部序列长度差异巨大,产生极高比例的无效填充(Padding),使得节点间计算负载不均,造成计算资源浪费。
-
中期探索:序列打包至定长 (Packing)
将多条短数据拼接为固定长度,虽然消除了填充,但不同模态数据token长度分布差异明显,序列打包后会使得每一个训练Step的Global Batch Size发生动态变化,进而导致模型对原始数据分布的感知受损,收敛性能下降。
为了彻底解决"全局强同步"与"局部异构性"的矛盾,我们设计并实现了同步长度分组采样器。该方案通过三层逻辑的紧密配合,在保障计算图统一的前提下,极大提升了 Token 吞吐效率。
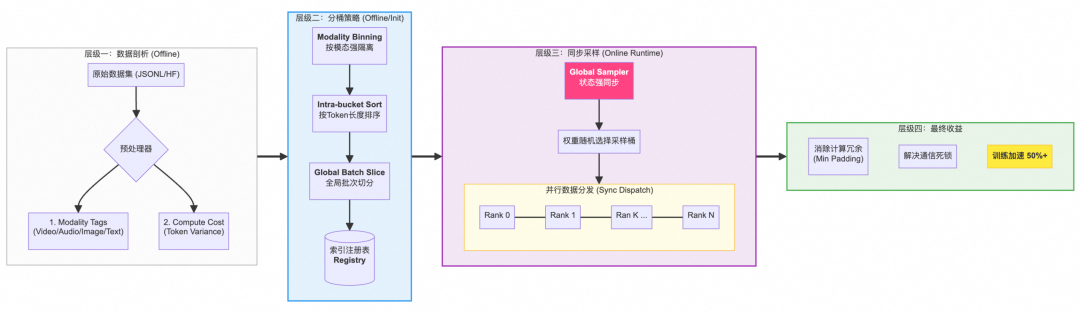
图3:同步长度分组采样机制
- 实现逻辑
-
数据剖析:在离线阶段,系统通过预处理器对原始数据集进行预处理。除了识别模态标签(视频/音频/图像/文本)外,核心任务是量化每个样本的计算成本,即Token序列长度,为后续的精确分桶提供元数据支撑。
-
分桶策略:执行"先隔离、再排序"的策略。首先进行模态强隔离(Modality Binning),保单Batch模态纯净,随后进行桶内长度排序(Intra-bucket Sort),并进行全局批次切分。最终生成的索引注册表(Registry)确保了所有Rank节点在采样时有据可依。
-
同步采样:这是解决死锁的关键。Global Sampler实现全局状态强同步,兼容DP/PP/TP/CP等混合并行模式。通过同步分发(Sync Dispatch),确保 Rank 0 到 Rank N 在每一轮迭代中所获取的序列长度高度对齐,从而实现节点间计算负载均衡,消除了通信等待时间。
实验数据表明,同步长度分组采样器的加速效果与数据分布的特征深度耦合。通过对不同模态数据集的实测(见图4与表2),我们得出以下结论:子数据集的 Token 长度方差越大,方案的加速收益越明显。
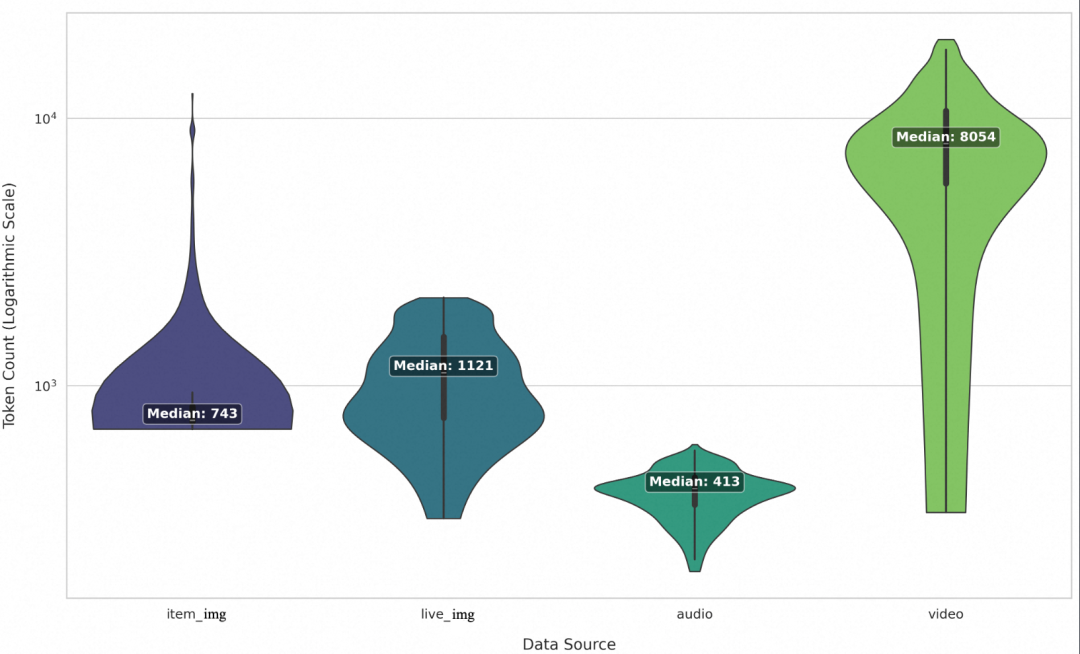
图4:不同模态数据的Token数量分布
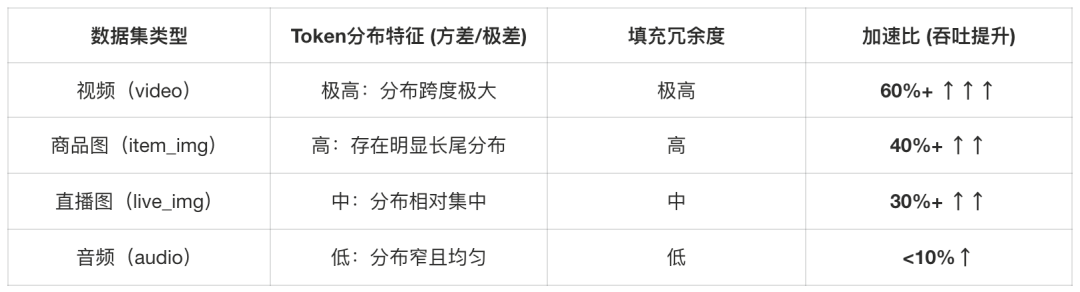
表2:不同模态数据的Token分布特性与同步长度分组采样器的加速比
- 结果收益
-
彻底解决死锁:通过全局同步采样机制,确保各Rank节点计算逻辑强一致,为大规模混合模态并行训练铺平了道路。
-
极致计算效率:方案本质是利用"方差坍缩"原理,将原本浪费在无效填充上的算力转化为有效吞吐。
-
综合加速 50%+:在处理高方差、长序列的大规模多模态任务时,整机训练吞吐量提升显著,实现了计算效率与模型性能的兼得。

数据构建
▐音频数据构建
在多模态大模型的训练中,高质量的音频数据是实现ASR、说话人分离、语音及跨模态理解能力的核心基础。为此,我们构建了一套全链路可控、多维度验证的音频数据处理体系,覆盖从原始数据清洗到多模态任务数据产出的完整流程,为模型训练提供坚实支撑。
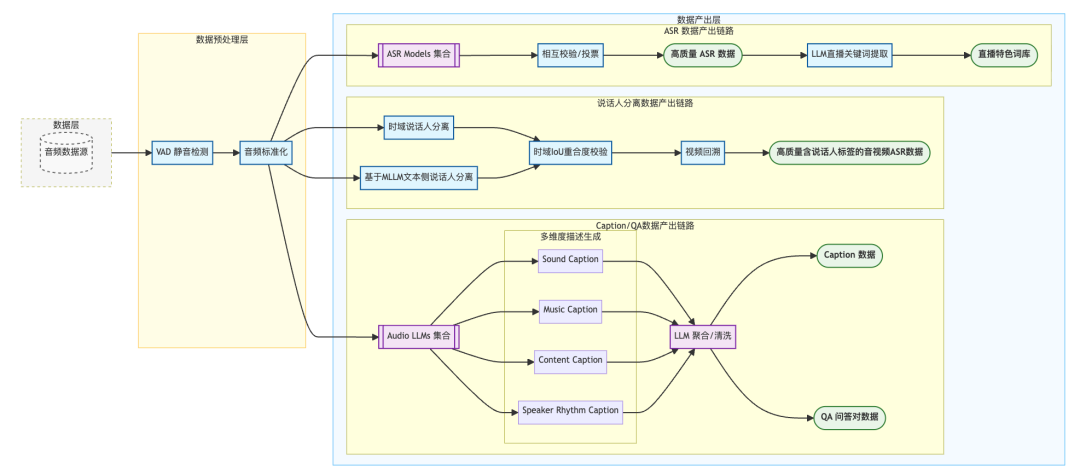
图5:多任务音频训练数据构建流程
▐视觉数据构建
同样,我们也构建了一套全链路可控、多维度可验证的图像和视频数据处理体系,为模型视觉能力的提升提供坚实的数据基础。
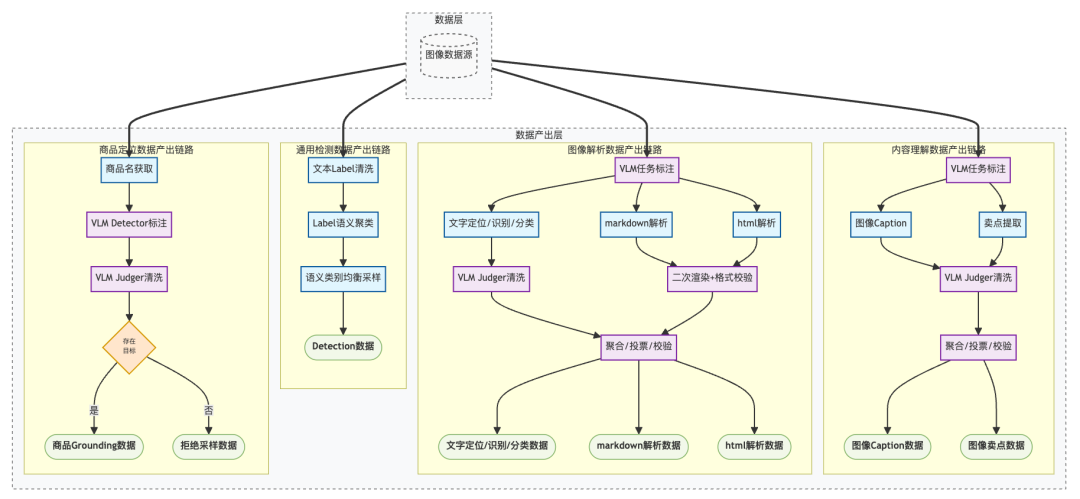
图6:多任务图像训练数据构建流程

图7:多任务视频训练数据构建流程

模型训练
TLiveOmni 1.0是基于Qwen3-VL-Instruct模型继续训练的,我们采用了"模态对齐→能力强化→全任务微调"的三阶段训练范式,实现了音频模态与文本、视觉模态的深度融合,最终使模型具备图像、文本、视频、音频全模态理解能力。
▐Stage 1:音频模态对齐
本阶段聚焦音频与文本的基础语义对齐,采用音频-ASR作为核心任务,通过500万条高质量语音-文本对数据,构建音频模态与语言模型的初始连接。在这一阶段,我们冻结LLM与Audio Encoder,仅微调Audio Aligner,确保语音信号能精准映射至文本语义空间。
▐Stage 2:音频能力强化
在完成基础对齐后,本阶段通过2600万条音频训练数据,全面强化模型对音频内容的深度理解能力,覆盖ASR、Audio Caption、Audio QA三大任务类型。在这一阶段,我们放开Audio Encoder与Audio Aligner参数,同时保持LLM参数冻结,通过多任务协同学习,使模型不仅能"转写语音",更能理解语音中声学事件、音乐、情感等非语义信息。
▐Stage 3:全任务微调
本阶段面向图像、文本、视频、音频四模态融合场景,通过1376万条跨模态数据,进行端到端联合微调。在这一阶段,我们冻结Audio/Vision Encoder,集中优化Aligner 以及 LLM参数,使语言模型能够融合多模态信息进行推理决策。

图8:TLiveOmni 1.0模型训练流程

表3:TLiveOmni 1.0模型训练数据分布

推理部署
▐vLLM推理部署
在TLiveOmni 1.0的生产环境落地中,我们选择 vLLM 作为核心推理框架,主要基于以下三个考量:
-
高效显存管理:vLLM通过类虚拟内存的分页管理机制(PagedAttention),将KV Cache离散存储,显存碎片率降低 30% 以上。
-
极致吞吐与调度:vLLM采用异步动态批处理(Continuous Batching)技术,打破了传统静态Batch的等待限制,显著提升了高并发场景下的请求吞吐。
-
生态与标准化:兼容OpenAI API规范,并原生支持Llama、Qwen等主流架构,为TLiveOmni 1.0模型的快速迭代与下游集成提供了成熟的基础设施。
- vLLM推理的主要挑战
-
多模支持缺陷:vLLM在处理长视频输入时存在引擎死锁(#28375)及多模态模型精度大幅下降(#29595)等遗留问题。
-
版本迭代断裂:vLLM v1在v0.11.1(2025.11.19)版本提供了对Omni模型的推理支持,但Omni模型的推理在部分场景下仍存在结果的异常(#30776)。Qwen3-Omni官方针对vLLM框架进行了适配,但官方适配版本为停止维护的vLLM v0版本,无法复用vLLM在v1重构所带来的优化增益。
-
异构框架导致的精度漂移:训练端(ms-swift)与部署端(vLLM)模型的实现方式不同,导致计算结果存在差异。
- vLLM定制化改造方案
针对上述挑战,我们基于vLLM v1进行了定制化改造:
-
架构层:支持TLiveOmni 1.0模型结构
-
-
自研优化适配:在框架层实现了TLiveOmni 1.0模型特有的Token排布逻辑和MRoPE计算。
-
音频模块定制:针对音频添加了音频数据标准化和DeepStack结构。
-
-
算子层:数值精度对齐优化
-
-
Norm 算子重构:修正了vLLM和Transformers的Norm计算差异。
-
加法顺序优化:重新排列GPU浮点运算顺序,防止因量级差异(Residual过大)导致的小值丢失问题。
-
序列对齐修正:修复了音频模块中由于缓存对齐导致的序列自动填充,确保推理序列长度与训练完全一致。
-
-
改造后精度对齐结果:
-
- 经过改造,vLLM推理精度与torch推理精度基本实现对齐:

表4:各模态任务下vLLM推理与torch推理精度对比
▐模型量化与加速
模型量化是大模型推理加速的重要手段之一,其优势在于:
-
释放显存:大模型权重规模大,通过int4/int8量化可释放约50%-75%显存,使大模型能够在消费级显卡(如 4090)或单机多卡环境中更高效运行。
-
降低延迟:大模型推理的Decoding阶段主要是访存受限,权重或激活值量化后,算子的访存压力相应减少。同时,现代GPU通常配备各种低精度计算单元,其理论算力显著高于高精度计算单元,因此采用低精度运算可有效减少算子执行时间,降低推理延迟。
- 量化方案
我们采用SmoothQuant 8 + GPTQ 9的复合量化方案。为了在降低模型权重精度的同时最大限度保留TLiveOmni 1.0模型的效果,我们设计了如下校准集抽取逻辑:
-
任务完整性:校准集必须覆盖模型所有训练过的任务。
-
任务敏感性:识别出那些对数值波动极其敏感的任务,并给予更多的样本权重(如:OCR、Grounding等)。
-
模态完整性:校准集必须包含模型涉及的所有输入模态组合及其时间/空间维度。
确保校准集包含图像、视频、音频及其所有组合形式,涵盖不同的时空维度特征,最终形成了共计5,000条高质量数据的校准池。
-
性能分析
-
精度评估
-
-
GPU:H20*1
-
量化方案:INT8、FP8
-
量化参数:Language Model
-
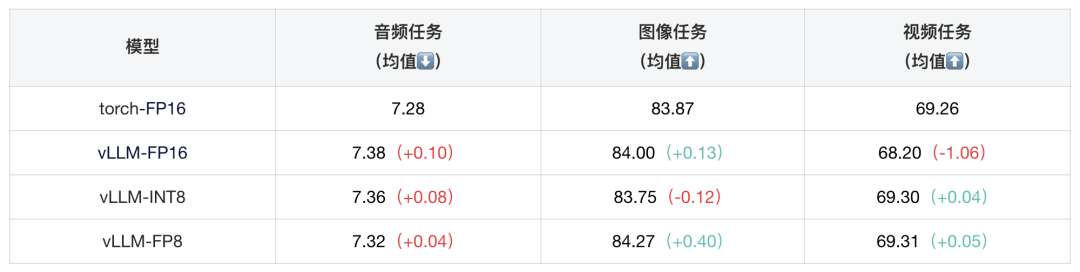
表5:各模态任务下8 bit量化与16 bit浮点推理精度对比
-
推理速度测试
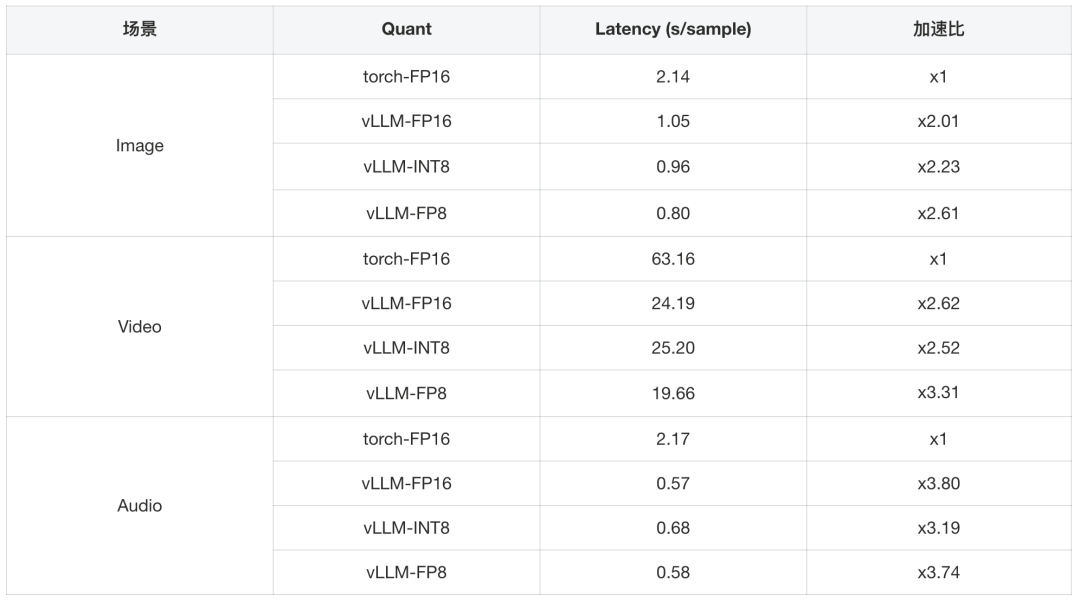
表6:各模态任务下不同量化方式单样本推理速度对比
我们测试了TLiveOmni 1.0在单样本下不同模态数据vLLM推理的加速比,经过8bit量化的TLiveOmni 1.0在保持各模态任务效果几乎不掉点的同时能取得2.5-3.5倍的推理加速。
PS:推理部署的具体优化方案可参考我们之前的文章《面向电商直播场景的全模态大模型推理加速方案》

实验结果
▐音频理解
在音频理解上,我们重点评估了模型在直播场域的语音识别、上下文语音识别、多说话人分离、音频内容描述和音频内容问答能力。
- 评测指标
语音识别(ASR)
我们用CER指标来衡量模型的语音识别能力。在计算指标时,我们去掉了标点,并对预测结果进行了文本标准化处理。具体的,CER的计算过程如下所示:
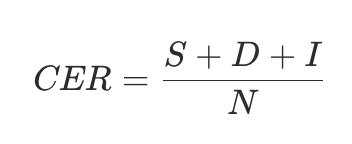
其中:
-
S(substitution) 表示替换的字符数目
-
D(deletion)表示删除的字符数目
-
I(insertion)表示插入的字符数目
-
N 表示参考序列中字符总数
上下文语音识别(Contextualized ASR)
为了系统评估模型上下文语音识别能力,在模型推理阶段,我们给模型随机输入K个低频词作为上下文,其中包含1个目标关键词(需要被识别的实体)与K-1个干扰关键词(非目标实体)。我们用模型语音识别结果在关键词上的召回率 以及语音识别词错误率CER来综合衡量模型的上下文语音识别能力。其中低频词召回率
以及语音识别词错误率CER来综合衡量模型的上下文语音识别能力。其中低频词召回率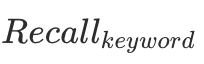 的具体计算方式如下:
的具体计算方式如下:

实验中,我们通过控制上下文关键词数量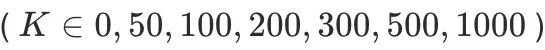 ,全面测试了模型在不同上下文规模下的性能表现。
,全面测试了模型在不同上下文规模下的性能表现。
多说话人分离(End-to-End Speaker Attributed ASR)
我们用cpWER10指标对模型的端到端说话人分离效果进行衡量。该指标通过在说话人维度计算语音识别准确度,再对不同说话人的识别准确度求平均,来反映模型预测说话人标签与ASR的综合效果。其具体计算过程如下:
-
设标注结果有
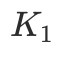 个说话人,模型预测有
个说话人,模型预测有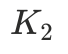 个说话人,令
个说话人,令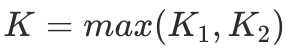 。
。 -
对标注结果,第 k 个说话人的所有话语按时间拼接成一个字符串,记为
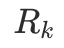 ,其中 k=1,2,..., K(不足K个说话人则用空字符串补齐)。
,其中 k=1,2,..., K(不足K个说话人则用空字符串补齐)。 -
对模型输出,第 k个说话人的所有话语同样拼接为
 (不足K个说话人则用空字符串补齐)。
(不足K个说话人则用空字符串补齐)。 -
定义拼接后的标注全文:
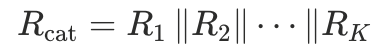 ,其中
,其中 表示字符串拼接。
表示字符串拼接。 -
尝试所有说话人匹配方式
-
-
由于模型输出的说话人标签可能与参考的标签不对应,需要考虑所有可能的说话人匹配方式。
-
共有 K!种方式将模型预测 中的 K 个说话人重新分配给标注结果中的 K 个说话人。
-
对每一种匹配方式(即一个排列
 ),把模型预测结果 按该排列重新排序后拼接:
),把模型预测结果 按该排列重新排序后拼接:
-
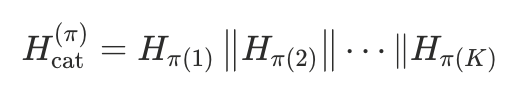
-
对每种排列
 ,计算拼接后的整体词错误率 WER(对于中文同CER):
,计算拼接后的整体词错误率 WER(对于中文同CER):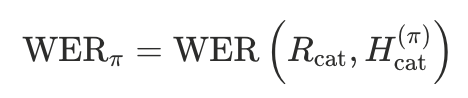
-
最终的
cpWER就是所有这些WER中的最小值:
音频内容描述(Audio Caption)与问答(Audio QA)
为评估模型在音频内容描述与问答方面的能力,我们对每一条测试音频利用多模态大模型自动生成多样化的提问,问题类型涵盖说话人属性(如性别、人数)和直播核心信息(如商品类别、价格、促销活动等)。每个问题会对应3-5个选项,其中必定有一个选项为"无法判断"。所有生成的问答对均经过人工校验与筛选,最终构建了一个高质量的测试集,用于系统评估模型在音频理解、描述生成及问答任务上的表现。
对于音频内容描述任务,我们将模型生成的音频内容描述作为上下文输入给一个强大的大语言模型(LLM),由该 LLM 基于此上下文回答音频对应问题,从而间接评测模型的音频内容描述能力。
对于音频问答任务,我们直接将原始音频及其对应的问题输入待评测模型,由模型端到端得生成答案。
我们用准确率(Accuracy)与幻觉率(Hallucination Rate)两个指标来衡量模型音频内容描述与问答能力,二者的计算方式如下所示:

- 测试样例
语音识别 / 上下文语音识别
语音识别 Prompt:"请将这段语音转换为纯文本。"
上下文语音识别 Prompt:"已知音频中可能出现以下关键词:海蓝之谜、鎏金...锦纶...。请将这段语音转换为纯文本。"
输出示例:"是的。嗯包括如果你要像在自己家,可能天气闷热的时候你打空调可能太冷了,对吧?嗯。开窗有点微微热,你就披一个这个,盖在自己身上,然后呢两面供你选择。如果你要确实比较热了,拿凉感面,这边是凉感面,嗯。这一面。对。叫锦纶做的。丝滑一点,凉感面。对,比较滑一些。对的,对的。这边是柔面,跟棉料比较接近,比较亲肤的。是。所以如果你要冷的话呢,拿这边再翻过来盖也可以。对。"
多说话人分离
Prompt:"完成多说话人分离任务,返回带有说话人标签的文本。说话人标签按照出现次序依次为<|spk0|>, <|spk1|>...当出现多人同时说相同内容时,用<|spkall|>表示。"
输出示例:"<|spk0|>是的。<|spk1|>嗯包括如果你要像在自己家,可能天气闷热的时候你打空调可能太冷了,对吧?<|spk0|>嗯。<|spk1|>开窗有点微微热,你就披一个这个,盖在自己身上,然后呢两面供你选择。如果你要确实比较热了,拿凉感面,这边是凉感面,<|spk0|>嗯。<|spk1|>这一面。<|spk0|>对。<|spk1|>叫锦纶做的。<|spk0|>丝滑一点,凉感面。<|spk1|>对,比较滑一些。<|spk0|>对的,对的。<|spk1|>这边是柔面,跟棉料比较接近,比较亲肤的。<|spk0|>是。<|spk1|>所以如果你要冷的话呢,拿这边再翻过来盖也可以。<|spk0|>对。"
音频内容描述
Prompt: "分析输入音频,并按照三段式的方式对输入音频进行描述,包括音频环境描述、核心内容总结与说话人韵律分析。"
输出示例:"
音频环境描述 音频整体清晰度高,无背景噪音或音乐干扰,呈现干练的录音质感。对话发生在受控环境中,可能为专业直播间或录音棚,语音平衡良好,男女声线区分明显,未出现失真或杂音,符合高质量产品演示场景的录制标准。
核心内容总结 音频由一位男性和女性说话者共同完成,男性以自信且富有说服力的语气介绍一款双面可选的纺织品(推测为毯子或披肩)。他通过日常场景(如空调房温度不适)引出产品功能,强调其两面材质差异:一面为"凉感面"(锦纶材质,触感丝滑),另一面为"柔面"(棉质,亲肤舒适)。女性说话者在关键节点以简短肯定回应(如"是的""对"),强化产品特性。整体内容聚焦于产品实用性与使用场景适配性,旨在引导听众根据需求选择不同面料。
说话人韵律分析 说话人通过语速调控与重音设计增强表达效果。在提及产品名称"凉感面"时,语速明显放缓并延长音节,配合音量提升,突出关键词;同时,"太冷了""微微热"等对比性表述也通过语速与音调变化形成张力。尽管情绪基调平稳,但通过节奏变化(如快速陈述问题后放慢解释方案)和重音强调(如"两面供您选择""比较亲肤的"),营造出逻辑清晰且具说服力的叙述节奏,使产品优势更易被听众感知与记忆。"
音频问答
Prompt:"音频中主播正在介绍的商品,哪一面的材质是锦纶?\nA) 凉感面\nB) 柔面\nC) 无法判断"
输出示例:"A) 凉感面"
- 评测结果
我们对比了TLiveOmni 1.0与业界主流开闭源音频&Omni模型,包括Qwen3-ASR-Flash 11、Fun-Audio-Chat 15、MiMo-Audio-Instruct 24、StepAudio R1.1 25、MiniCPM-o2.6 12、Ming-Lite-Omni v1.5 14、OmniVinci 16、Qwen2.5-Omni 17、Qwen3-Omni 3、Gemini2.5/3-Flash/Pro 1819。其中--表示模型不支持该能力,红色表示当下对比最优结果。
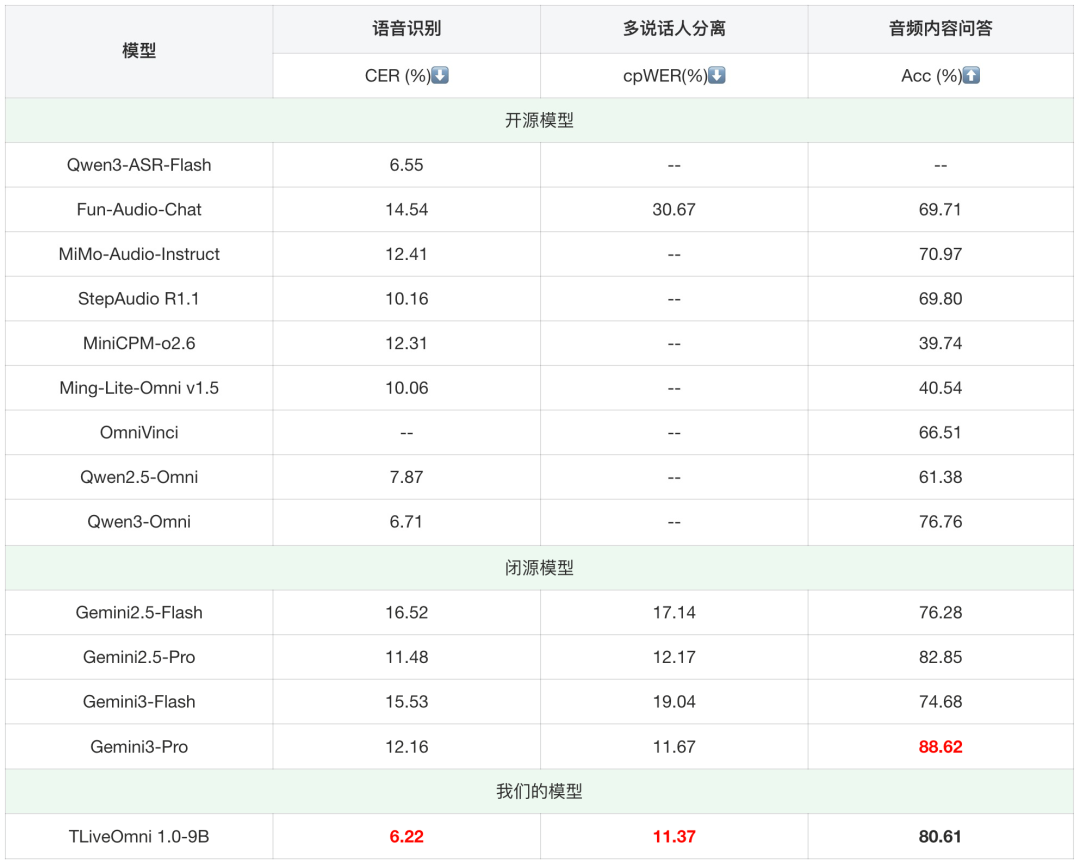
表7:音频任务---TLiveOmni 1.0模型与主流开闭源音频&Omni模型对比
相比于业界主流的开闭源音频和Omni模型,我们的TLiveOmni 1.0模型在电商直播域的ASR和多说话人分离能力上达到SOTA效果,在音频内容问答上相比开源模型有优势,且超过了Gemini2.5/3-Flash模型,接近Gemini2.5-Pro模型效果。
上下文语音识别
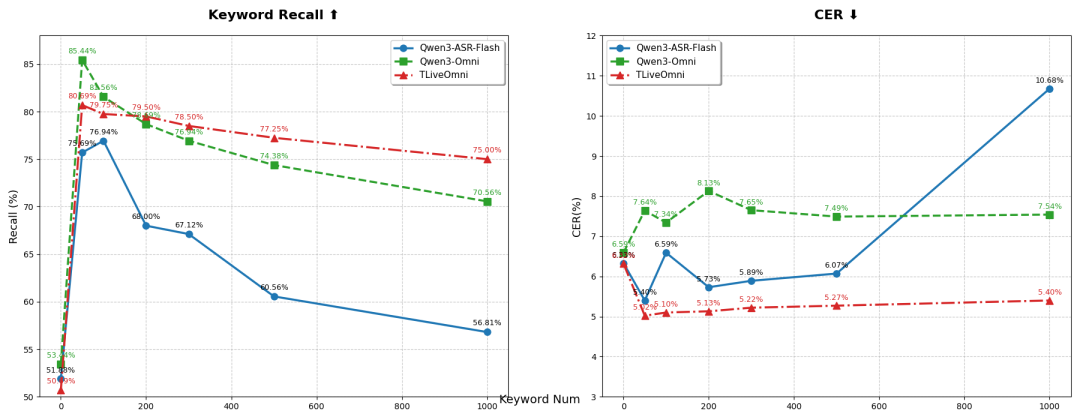
图9:TLiveOmni 1.0模型上下文语音识别能力对比
在上下文语音识别上,TLiveOmni 1.0相比于Qwen3-ASR-Flash和Qwen3-Omni也展现了明显优势,特别是当上下文关键词数量超过200时,TLiveOmni 1.0模型仍保持大于75%的关键词召回率,而Qwen3-ASR-Flash和Qwen3-Omni的关键词召回率则有明显回退。另一方面,当将低频词作为关键词嵌入模型上下文时,TLiveOmni 1.0的ASR效果取得了进一步提升,当上下文关键词数量为50时,TLiveOmni 1.0的ASR效果相比没有上下文关键词时提升了26%,这也表明上下文语音识别在电商直播的领域特性。
▐图像理解
在图像理解上,我们重点评估了模型在直播场域的商品空间定位、文字提取与文本分类能力。
- 评测指标
商品空间定位(Visual Grounding)
旨在评估模型在直播间图像和商品图像场景下的细粒度 Visual Grounding(视觉定位)能力。模型需支持对同类商品不同SKU粒度的多目标检测,并具备在目标缺失场景下的拒识能力。
定位能力测评
针对细粒度标签的多框定位精度,采用 作为核心指标。
作为核心指标。
-
匹配准则
-
-
一对一匹配:对于每一类别,遍历预测框,在真值框中寻找 IoU 最大的匹配对象。
-
命中判定:若IoU≥ 0.5,则视为"命中",并从该样本的 GT 集合中移除该框(确保每个 GT 仅能被匹配一次)。
-
负例判定:若IoU<0.5或对应 GT 已被消耗,则视为"误检"。
-
-
评估指标
-
- 单类别精度(Precision):
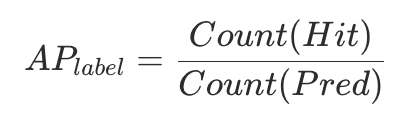
-
- 全类平均精度(AP):
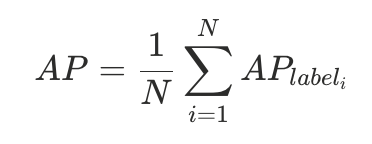
拒识能力测评
针对测试集中不含目标物(即 GT 为空)的样本,评估模型的负样本拦截能力。
-
评估指标:拒识准确率 (Acc)
-
-
判定逻辑:若模型对无目标样本给出的预测结果为空,则判定为"正确拒识"。
-
计算公式:预测为空的样本数 / 真实为空的样本总数
-

文字提取与分类(OCR & Tagging)
旨在评估模型在直播间图像和商品图像场景下的细粒度 OCR 提取与精细化文本分类能力。模型需实现对商品包装、SKU 规格参数及营销文案的精准定位与文字识别,并对文字类别进行分类,实现非结构化文本向标准化商业标签的对齐与统一。测评重点在于模型在复杂背景下的多区域文本检测、长短文本识别、多类别标签分类的准确度。
文本定位测评
针对不同模型在检测粒度(词、行、块)上的差异,我们在计算评测指标前通过 DBSCAN 聚类算法对预测框进行空间对齐预处理,通过对检测框中心点进行密度聚类,将物理空间临近的碎片化检测框合并为统一的语义区域(最小外接矩形),从而消除因检测尺度不一导致的评估偏置,确保不同模型在同一基准下进行对齐分析。
- 评估流程:
-
-
计算每一个预测框与每一个真值框之间的 IoU,并构建一个
iouMat矩阵。 -
循环遍历实现预测框与真值框的最佳一对一匹配。一个匹配被判定为真正例 (True Positive, TP),必须同时满足以下条件:
-
-
-
该真值框(GT)和预测框(Pred)均未曾被匹配过。
-
两者之间的IoU≥ 0.5。
-
-
评估指标:

文字识别测评
-
评估指标:归一化编辑距离 (Normalized Edit Distance)
-
-
基于Levenshtein距离 23,衡量将预测字符串转换为真值字符串所需的最少单字符编辑(插入、删除或替换)次数。在评估过程中,我们将模型识别出的零散文本块按从上至下、从左至右的顺序进行拼接,构成完整的文本序列。归一化编辑距离分数的计算公式如下:

-
文本分类评测
- 标签体系定义
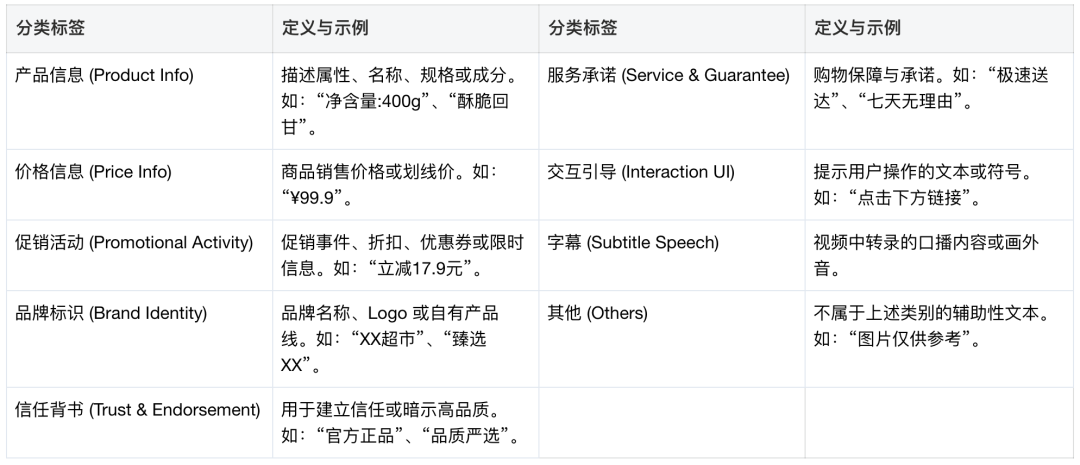
-
评估指标:
-
-
采用准确率 (Accuracy) 衡量模型对文本标签分类的正确性,其中y为对应的类别标签,N为样本总数:
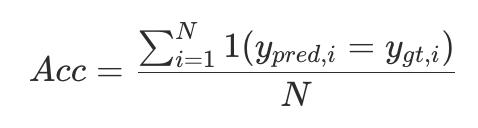
-
-
测试样例

- 评测结果
我们对比了TLiveOmni 1.0与业界主流开闭源Omni模型,包括MiniCPM-o2.6 12、Ming-Lite-Omni v1.5 14、OmniVinci 16、Qwen2.5-Omni 17、Qwen3-Omni 3、Gemini2.5/3-Flash/Pro 1819。其中--表示模型不支持该能力,红色表示当下对比最优结果。
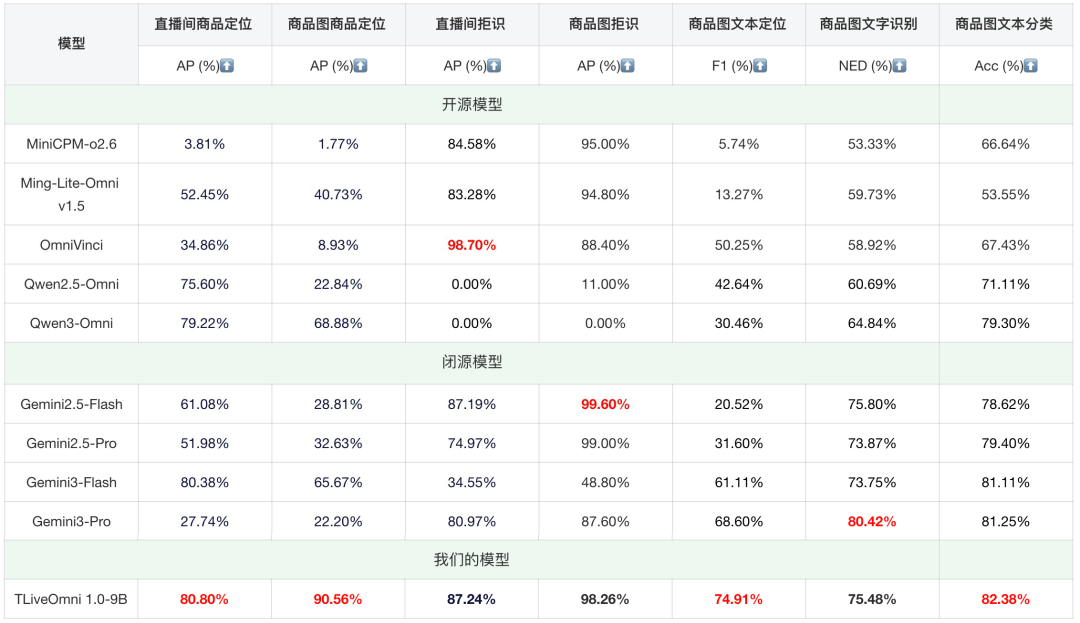
表8:图像任务---TLiveOmni 1.0模型与主流开闭源Omni模型对比
相比于业界主流的开闭源Omni模型,我们的TLiveOmni 1.0模型在商品定位、文本定位和文本分类能力上均达到SOTA效果,在文字识别上虽相距Gemini3-Pro仍有一定距离,但相比开源模型有明显优势。特别地,在商品定位拒识子集上,虽然OmniVinci和Gemini2.5-Flash分别实现了直播间图和商品图的最佳拒识效果,但在商品定位上它们的AP均处于较低水位,这也表明OmniVinci和Gemini2.5-Flash取得较高拒识效果的根本原因在于模型倾向于输出空的检测结果。
▐视频理解
在视频理解上,我们重点评估了模型在直播场域的视频时序定位、事件动作描述、视频内容描述、视频内容问答和分镜理解能力。
- 评测指标
时序定位(Temporal Grounding)
为了评测模型对视频时序的感知能力,我们对商品讲解、主播互动、细节展示等电商直播特有的音视频事件进行时间维度的定位,即模型输出特定事件发生的时间区间 [start_time, end_time]。我们采用mIoU来衡量模型的时序定位能力,具体计算方式如下:
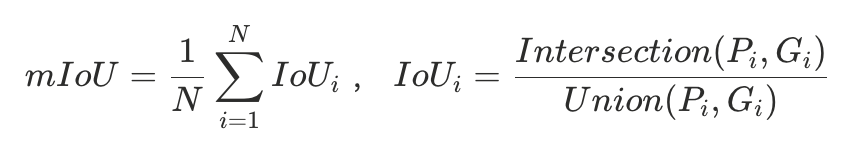
其中N为样本总数,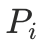 和
和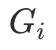 分别为第
分别为第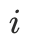 个样本模型预测的时间区间和真实标注的时间区间。
个样本模型预测的时间区间和真实标注的时间区间。
视频描述(Video Caption)
视频描述任务要求模型对视频内容进行自然语言描述,侧重于对音视频信息的综合刻画。对于每一个视频片段,我们融合专家标注与多模态大模型的能力自动生成问题,每个问题会对应3-5个选项,其中必定有一个选项为"无法判断"。所有生成的问答对均经过人工校验与筛选,最终构建了一个高质量的测试集,用于系统评估模型在视频描述任务上的表现。
测试时,我们将模型生成的视频描述作为上下文输入给一个强大的LLM,由该 LLM 基于此上下文回答视频对应问题,从而间接评测模型的视频描述能力。
我们用准确率(Accuracy)与幻觉率(Hallucination Rate)两个指标来衡量模型视频内容描述能力,二者的计算方式如下所示:

视频密集描述(Video Dense Caption)
视频密集描述是视频理解领域的高阶任务。不同于传统的视频描述任务,密集描述要求模型在时序上精确定位视频中发生的多个事件,并为每个事件生成细粒度的文字描述。其输出表现为:[start_time, end_time] + 细粒度描述(声音/场景/事件/主体/动作等),它是实现视频结构化的关键技术。我们采用与视频描述相同的评测方法来评估模型在密集描述任务上的表现,使用准确率与幻觉率两个指标来衡量模型视频密集描述能力。
视频问答(Video QA)
针对视频问答能力的评测,我们直接复用了在视频密集描述评测中经过人工校验与筛选后的问答对,这些问题涵盖了细粒度视频信息,包括声音、场景、事件、动作、时间等。评测时,我们直接将原始视频及其对应的问题输入待评测模型,由模型端到端得生成答案。我们用准确率(Accuracy)来衡量模型视频问答能力:
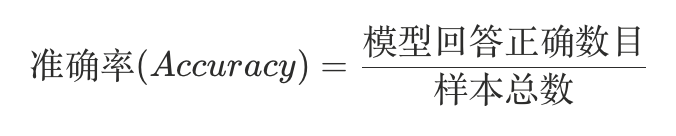
分镜理解(Storyboard Understanding)
为评估模型对直播分镜的视觉语法与空间叙事结构的理解能力,我们从画面布局、景别、镜头视角以及内容呈现形式等维度进行了结构化的表征与细粒度的标注,用于评测模型能否准确识别并区分不同的直播分镜表达方式。直播分镜理解为直播视频素材的标准化提供了依据,可支持素材库的精细化归档、检索与推荐,并为后续的内容分析与辅助创作提供可对齐、可复用的标签体系与评估基线。
- 标签体系
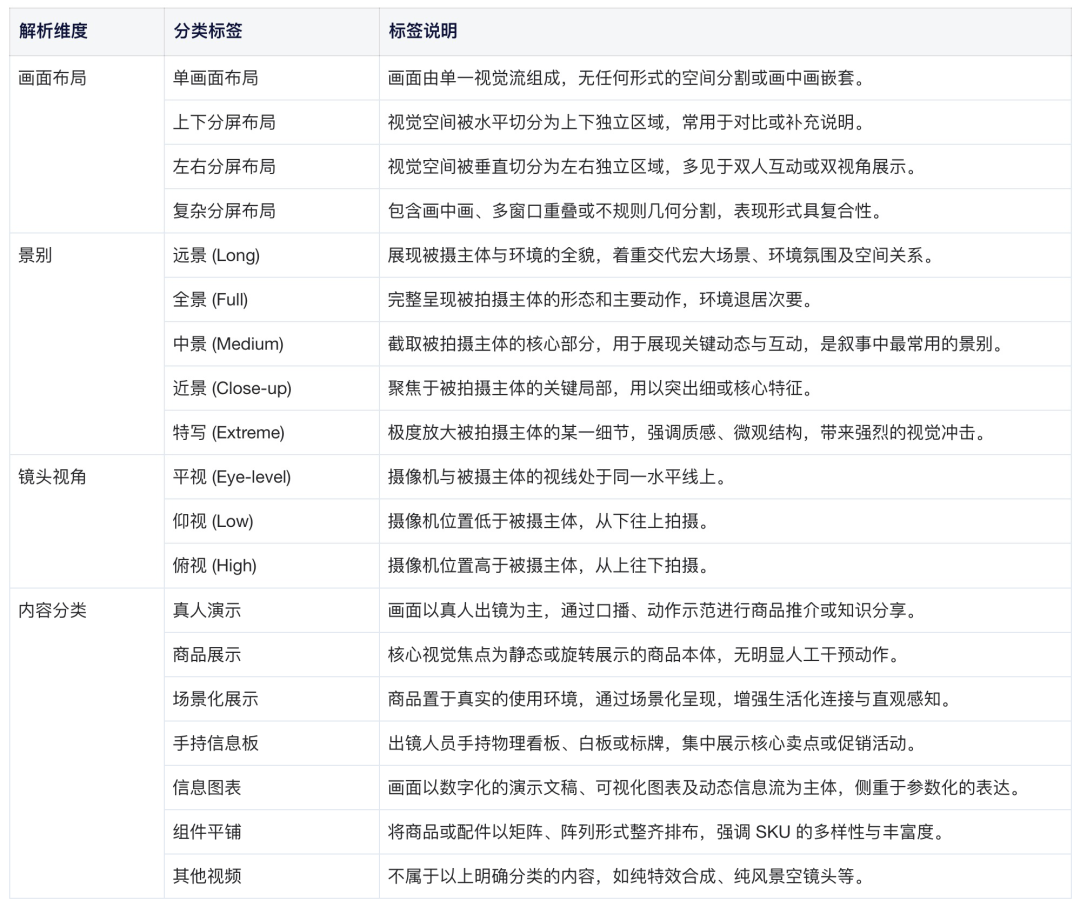
- 评估指标:
我们采用准确率(Accuracy)来衡量模型对视频分镜多维度标签预测的能力。

- 测试样例

- 评测结果
我们对比了TLiveOmni 1.0与业界主流开闭源Omni模型,包括MiniCPM-o2.6 12、ARC-Hunyuan-Video 13、ARC-Qwen-Video-Narrator 13、Ming-Lite-Omni v1.5 14、Ming-flash-omni Preview、OmniVinci 16、Qwen2.5-Omni 17、Qwen3-Omni 3、Gemini2.5/3-Flash/Pro 1819。其中--表示模型不支持该能力,红色表示当下对比最优结果。
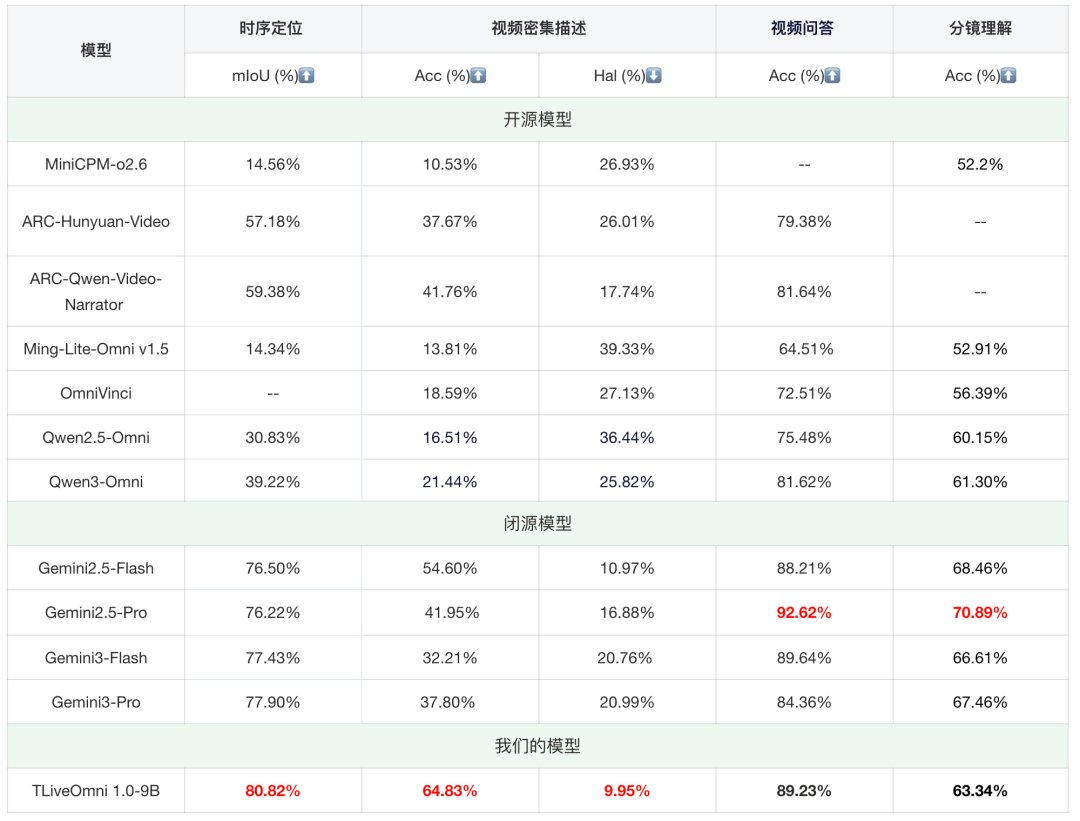
表9:视频任务---TLiveOmni 1.0模型与主流开闭源Omni模型对比
相比于业界主流的开闭源Omni模型,我们的TLiveOmni 1.0模型在电商直播域的时序定位和视频密集描述能力上达到SOTA效果,在视频问答和分镜理解上相比开源模型有优势,接近Gemini2.5/3-Flash模型效果。

总结展望
TLiveOmni 1.0模型目前已在淘宝直播中场次智能诊断、讲解模式归纳、主播Skill沉淀等场景应用,赋能真人直播和淘宝数字人直播。在未来我们还将围绕下述方向持续打磨TLiveOmni模型,探索直播场域的更多可能:
-
【模型扩展】围绕模型参数、数据质量、任务范式、专家蒸馏等维度,探索全模态视频理解模型的Scaling Law。
-
【知识压缩】提升数据效率和上下文效率,探索视觉上下文压缩技术,扩展模型上下文窗口到百万级,进一步增强长视频理解能力。
-
【训推提效】探索Omni模型混合并行训练的最佳实践方式;通过自定义算子、算子融合、编解码分离部署等方案,进一步提升推理效率。
-
【规划决策】探索大规模Omni模型RFT/RL训练,提升模型心智,实现全模态的"感知-理解-推理-决策一体化"。

参考文献
1 https://www.questmobile.com.cn/research/report/2003371476837830657
2 Qwen3-VL Technical Report https://arxiv.org/pdf/2511.21631
3 Qwen3-Omni Technical Report https://arxiv.org/pdf/2509.17765
4 Robust Speech Recognition via Large-Scale Weak Supervision https://arxiv.org/abs/2212.04356
5 Fun-ASR Technical Report https://arxiv.org/abs/2509.12508
6 Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception https://arxiv.org/abs/2510.12720
7 AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models https://arxiv.org/abs/2411.18953
8 SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models https://arxiv.org/pdf/2211.10438
9 GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers https://arxiv.org/pdf/2210.17323
10 CHiME-6 Challenge: Tackling multispeaker speech recognition for unsegmented recordings https://arxiv.org/pdf/2004.09249
11 Qwen3-ASR Blog: https://qwen.ai/blog?id=41e4c0f6175f9b004a03a07e42343eaaf48329e7\&from=research.latest-advancements-list
12 MiniCPM-o 2.6: A GPT-4o Level MLLM for Vision, Speech, and Multimodal Live Streaming on Your Phone https://openbmb.vercel.app/minicpm-o-2-6-en
13 ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts https://arxiv.org/pdf/2507.20939
14 Ming-Omni: A Unified Multimodal Model for Perception and Generation https://arxiv.org/pdf/2506.09344
15 Fun-Audio-Chat Technical Report https://arxiv.org/pdf/2512.20156
16 OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM https://arxiv.org/pdf/2510.15870
17 Qwen2.5-Omni Technical Report https://arxiv.org/pdf/2503.20215
18 Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities https://arxiv.org/pdf/2507.06261
19 Gemini 3 Blog: A new era of intelligence with Gemini 3 https://blog.google/products/gemini/gemini-3/
20 ms-swift: https://github.com/modelscope/ms-swift
21 deepspeed: https://github.com/deepspeedai/DeepSpeed
22 vLLM: https://github.com/vllm-project/vllm
23 Binary codes capable of correcting deletions, insertions, and reversals https://nymity.ch/sybilhunting/pdf/Levenshtein1966a.pdf
24 MiMo-Audio: Audio Language Models are Few-Shot Learners https://www.arxiv.org/pdf/2512.23808
25 Step-Audio-R1 Technical Report https://arxiv.org/pdf/2511.15848

团队介绍
本文作者博煊,来自淘天集团-直播AIGC团队。作为直播电商智能化领域的先行者,始终致力于通过AI原生技术创新重构电商直播场景中的人货场交互范式。团队基于对大语言模型研发、多模态语义理解、语音合成、数字人形象建模、AI工程化部署及音视频处理技术的深厚沉淀和积累,已搭建起覆盖直播全链路的AI技术矩阵。自主研发的数字人直播解决方案通过商业化验证,成功实现从技术研发到商业变现的完整闭环,累计服务上千家商家。
¤ 拓展阅读 ¤