1.算法描述
A2C是一种同步式策略梯度算法 ,核心是通过优势函数 (Â(s,a) = Q(s,a) - V(s))替代传统回报值,显著降低策略梯度的方差。
2.代码实现
python
# -*- coding: utf-8 -*-
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
class GridWorld:
def __init__(self, size=6):
self.size = size
self.action_space = 4
self.state_dim = size * size
self.goal = (size - 1, size - 1)
self.obstacles = {(2, 2), (3, 2), (1, 4)}
self.reset()
def reset(self):
while True:
self.agent = (
np.random.randint(self.size),
np.random.randint(self.size)
)
if self.agent != self.goal and self.agent not in self.obstacles:
break
return self._encode_state()
def step(self, action):
row, col = self.agent
nrow, ncol = row, col
if action == 0: # up
nrow -= 1
elif action == 1: # down
nrow += 1
elif action == 2: # left
ncol -= 1
elif action == 3: # right
ncol += 1
# 边界检查
if not (0 <= nrow < self.size and 0 <= ncol < self.size):
nrow, ncol = row, col
# 障碍物检查
if (nrow, ncol) in self.obstacles:
nrow, ncol = row, col
self.agent = (nrow, ncol)
reward = -0.05
done = False
if self.agent == self.goal:
reward = 1.0
done = True
return self._encode_state(), reward, done
def _encode_state(self):
s = np.zeros(self.size * self.size, dtype=np.float32)
idx = self.agent[0] * self.size + self.agent[1]
s[idx] = 1.0
return s
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.policy_head = nn.Linear(128, action_dim)
self.value_head = nn.Linear(128, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.policy_head(x), self.value_head(x)
class A2CAgent:
def __init__(self, state_dim, action_dim, lr=3e-4, gamma=0.99):
self.gamma = gamma
self.model = ActorCritic(state_dim, action_dim).to(device)
self.optimizer = optim.Adam(self.model.parameters(), lr=lr)
def select_action(self, state):
state_t = torch.tensor(state[None, :], dtype=torch.float32, device=device)
with torch.no_grad():
logits, value = self.model(state_t)
probs = F.softmax(logits, dim=-1)
action = np.random.choice(len(probs[0]), p=probs.cpu().numpy()[0])
return action, value.item()
def update(self, states, actions, rewards, values, next_value, done):
returns = []
R = 0.0 if done else next_value
for r in reversed(rewards):
R = r + self.gamma * R
returns.insert(0, R)
states_t = torch.tensor(np.array(states), dtype=torch.float32, device=device)
actions_t = torch.tensor(actions, dtype=torch.long, device=device)
returns_t = torch.tensor(returns, dtype=torch.float32, device=device)
values_t = torch.tensor(values, dtype=torch.float32, device=device)
advantages = (returns_t - values_t).detach()
logits, value_preds = self.model(states_t)
value_preds = value_preds.squeeze()
policy_loss = F.cross_entropy(logits, actions_t, reduction='none')
policy_loss = torch.mean(policy_loss * advantages)
# Value Loss
value_loss = torch.mean(torch.square(returns_t - value_preds))
# Entropy Loss
probs = F.softmax(logits, dim=-1)
log_probs = F.log_softmax(logits, dim=-1)
entropy = -torch.mean(torch.sum(probs * log_probs, dim=1))
# 总 Loss
loss = policy_loss + 0.5 * value_loss - 0.01 * entropy
# 反向传播更新
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
env = GridWorld(size=6)
agent = A2CAgent(env.state_dim, env.action_space)
EPISODES = 600
MAX_STEPS = 80
for ep in range(EPISODES):
state = env.reset()
states, actions, rewards, values = [], [], [], []
for _ in range(MAX_STEPS):
action, value = agent.select_action(state)
next_state, reward, done = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
values.append(value)
state = next_state
if done:
break
state_t = torch.tensor(state[None, :], dtype=torch.float32, device=device)
with torch.no_grad():
_, next_value = agent.model(state_t)
agent.update(states, actions, rewards, values, next_value.item(), done)
if ep % 50 == 0:
print(f"Episode {ep:3d} | steps: {len(rewards)}")
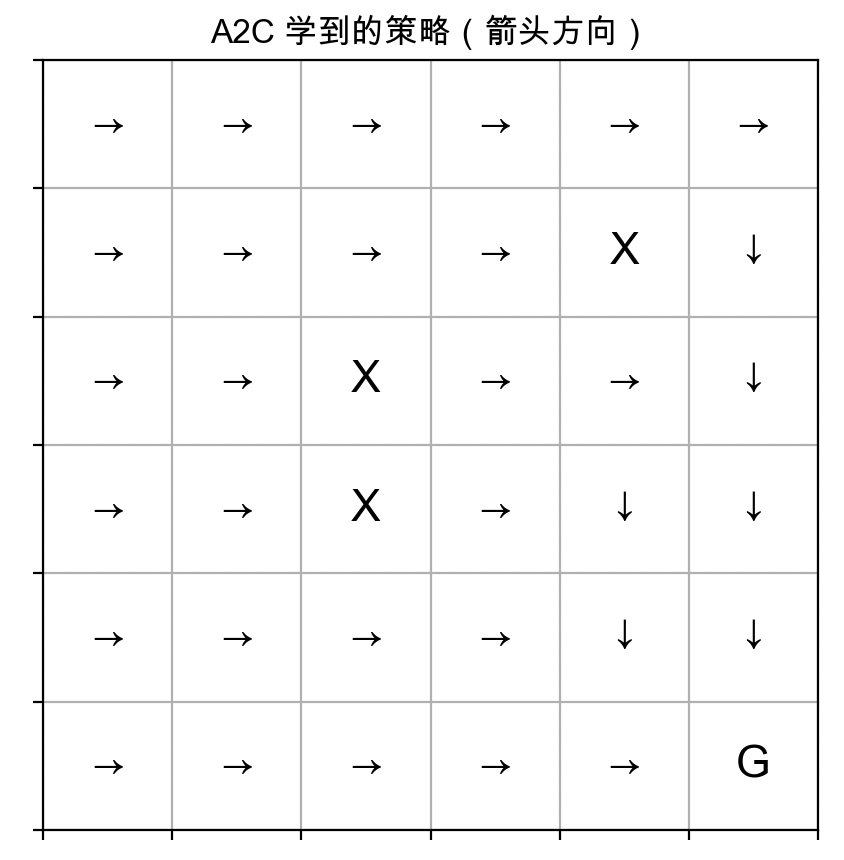
def visualize_policy(env, agent):
arrow = {0: "↑", 1: "↓", 2: "←", 3: "→"}
grid = [["" for _ in range(env.size)] for _ in range(env.size)]
for r in range(env.size):
for c in range(env.size):
if (r, c) == env.goal:
grid[r][c] = "G"
elif (r, c) in env.obstacles:
grid[r][c] = "X"
else:
s = np.zeros(env.size * env.size, dtype=np.float32)
s[r * env.size + c] = 1.0
s_t = torch.tensor(s[None, :], dtype=torch.float32, device=device)
with torch.no_grad():
logits, _ = agent.model(s_t)
a = torch.argmax(logits, dim=1).item()
grid[r][c] = arrow[a]
fig, ax = plt.subplots(figsize=(5, 5))
ax.set_xlim(0, env.size)
ax.set_ylim(0, env.size)
ax.set_xticks(np.arange(env.size + 1))
ax.set_yticks(np.arange(env.size + 1))
ax.grid(True)
for r in range(env.size):
for c in range(env.size):
ax.text(
c + 0.5,
env.size - r - 0.5,
grid[r][c],
ha="center",
va="center",
fontsize=16
)
ax.set_title("A2C 学到的策略(箭头方向)")
ax.set_xticklabels([])
ax.set_yticklabels([])
plt.show()
if __name__ == "__main__":
visualize_policy(env, agent)3.结果展示
bash
Using device: cpu
Episode 0 | steps: 80
Episode 50 | steps: 3
Episode 100 | steps: 38
Episode 150 | steps: 4
Episode 200 | steps: 31
Episode 250 | steps: 11
Episode 300 | steps: 7
Episode 350 | steps: 15
Episode 400 | steps: 9
Episode 450 | steps: 3
Episode 500 | steps: 15
Episode 550 | steps: 3