一、前言
PCA 全称 Principal Component Analysis,中文译作主成分分析,是机器学习、数理统计领域经典且应用广泛的数据降维算法。算法核心依托线性变换,将原始高维数据映射至全新坐标系,把数据核心信息与方差集中在少数低维维度中,以此完成数据降维、噪声剔除、多维数据可视化等任务。
PCA 算法生效存在基础前提,要求数据集变量间具备较强相关性,也就是存在多重共线性。日常常用的相关性检验方式包含:相关性矩阵、KMO 检验、Bartlett 球形检验、方差膨胀因子 VIF、特征值与碎石图。
二、PCA 核心思想
PCA 本质是不断寻找数据内部方差最大的投影方向,将数据向最优方向投影压缩维度,整体逻辑流程如下:
- 搜寻数据方差最大值方向,定义为第一主成分;
- 选取与第一主成分相互正交、方差次大的方向,定为第二主成分;
- 依照正交、方差递减规则,依次推导后续多阶主成分;
- 所有主成分组成全新坐标系,原始数据在坐标系内的投影结果,即为降维后数据。
三、PCA 完整数学计算流程
设定数据集包含n个样本,单个样本拥有p个特征,数据整体构成n×p矩阵,分步完成主成分求解。
步骤 1:数据标准化(可选关键步骤)
PCA 对数据方差敏感度极高,不同特征量纲尺度不一致时,数值方差偏大的特征会主导运算结果,干扰分析准确性。因此常规场景下必须标准化处理,统一特征均值为 0、方差为 1。 标准化计算公式: 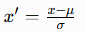 μ代表单特征均值,σ代表单特征标准差。
μ代表单特征均值,σ代表单特征标准差。
步骤 2:求解协方差矩阵
协方差矩阵用于刻画不同特征之间的线性关联程度,标准化数据矩阵为X,协方差矩阵计算公式: 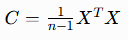 XT为数据矩阵转置,n为样本总数量。
XT为数据矩阵转置,n为样本总数量。
步骤 3:计算特征值与特征向量
协方差矩阵为p×p对称矩阵,对矩阵求解可得到对应特征值与特征向量。
- 特征值:表征单个主成分所能解释的数据方差大小;
- 特征向量:代表主成分对应的空间方向。
将特征值按照数值从大到小排序,匹配的特征向量即为各阶主成分方向,同时也是碎石图的数据来源。
步骤 4:筛选有效主成分
结合特征值大小、累计方差贡献率选取前k个主成分,行业通用标准为累计方差贡献率达到 95% 即可保留,筛选出的特征向量组合构成降维新坐标系。
步骤 5:数据投影得到降维结果
把原始标准化数据映射至选定主成分方向,最终生成n×k维度的降维矩阵。降维运算公式: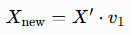 X′为标准化数据,v1为选定主成分特征向量。
X′为标准化数据,v1为选定主成分特征向量。
四、PCA 常用可视化图表解读
主成分分析配套五类核心可视化图形,分别从主成分价值、变量贡献、样本分布等角度解析数据。
1. 碎石图 Scree Plot
核心作用:判定最终保留的主成分个数,遵循少维度、高方差解释度原则筛选。 通过图形拐点法则判断,拐点前方主成分方差解释能力强予以保留,拐点后方方差贡献微弱可直接舍弃。
- 横轴:按优先级排列的主成分编号 PC1、PC2...
- 纵轴:单个主成分对应的特征值、方差解释占比。
2. 载荷图 Loading Plot
核心作用:分析单个原始特征对主成分的贡献权重,解释主成分实际业务含义。
- 坐标轴:横纵轴分别代表前两阶核心主成分;
- 图形元素:箭头 / 点位对应原始变量,坐标为变量载荷值,取值区间−1,1;
- 数值解读:载荷绝对值越大,变量与主成分关联性越强;正负代表相关方向;
- 夹角解读:变量夹角越小正相关性越强,90 度近似无关联,180 度呈强负相关。
3. 得分图 Score Plot
核心作用:直观展示降维后样本空间分布,识别聚类规律、异常离群样本。 通俗理解:得分图就是高维数据降维后的样本点位分布图。
- 坐标轴:对应主成分维度;
- 图形元素:单点代表单个数据样本;
- 实用价值:聚拢点位为同类样本,偏远孤立点位判定为异常值,同时可判断主成分样本区分能力。
4. 双标图 Biplot
融合型可视化图表,一张图同时呈现样本得分 与变量载荷,既能查看样本分布聚类特征,也可同步分析变量和主成分的关联关系,综合分析数据内在规律。
5. 热力图 Heatmap
主要用于展示特征间相关系数,和 PCA 降维核心逻辑关联度较低,多用于前期变量相关性预判。
五、关键补充知识点
1. 主成分数量规则
数据集原始存在d个特征维度,理论最多生成d个相互正交的主成分。实际应用不会全额选用,仅挑选前k个高贡献率主成分,以少量维度保留绝大多数原始数据信息,实现降维目的。
2. 标准化必要性
不同特征计量单位、数值尺度差距较大时,大尺度特征会挤占分析权重,弱化小尺度特征作用,破坏 PCA 分析公平性,异量纲数据必须执行标准化操作。
3. Kaiser 准则
也称作特征值大于 1 筛选准则,是快速确定主成分数量的常用方法。标准化数据单个原始变量方差为 1,仅保留特征值大于 1 的主成分,该类主成分方差解释能力优于单个原始变量,小于 1 的主成分信息价值偏低,直接剔除即可。
六、总结
PCA 依靠线性变换、协方差求解、特征分解完成高维数据压缩,用少量主成分替代繁杂原始特征,大幅降低数据计算复杂度。碎石图、载荷图、得分图等可视化图表,分别解决主成分筛选、变量释义、样本分类问题。 在机器学习建模、多维数据分析、数据降噪场景中,PCA 凭借简洁高效的特性,成为预处理阶段最常用的降维手段。