测试学习记录,仅供参考!
Pytest 框架
本文实际结合测试项目接口服务进行 API 接口自动化测试;
七、分组执行和跳过执行
分组执行
在pytest中,可以使用标记(mark)或者参数化来实现测试用例的分组执行,分组执行是一种将测试用例按照特定的标记或者条件进行组织和运行的方法。
使用-m去执行分组的测试用例:pytest -vs -m 'P1';
使用-m去执行多个组的测试用例:pytest -vs -m "P1 or P3";
1、修改test_assert_result.py文件内容;
# 导包
import pytest
import random
# 创建一个类--写了一个测试类
class TestAssertResult:
# 使用装饰器 @pytest.mark 标记为 P1 级别
@pytest.mark.P1
# 相等断言,判断两个值是否相等--断言最常见的一种方式
def test_assert_eq(self):
assert 1 == 1, '登录失败,它们的值不相等'
def test_assert_eq_02(self):
# 这是一个 预期结果
exp = {'msg': '登录成功'}
# 这是一个 接口实际返回结果
response = {'msg': '登录成功'}
assert exp == response, '登录失败,它们不相等!'
# 不相等断言
def test_assert_nq(self):
exp = {'msg': '登录成功'}
response = {'msg': '登录成功'}
assert exp != response, '断言失败,它们相等!'
# 真假断言
def test_assert_bool(self):
assert random.choice([True, False]), '真假断言失败'
# 成员关系断言
def test_assert_contains(self):
contains = 'pytest'
contains_lst = ['pytest', 'unittest', 'python']
assert contains in contains_lst
@pytest.mark.P3
# 集合断言--不常用--在python中,集合是不考虑顺序的,只有元素不重复就行了
def test_assert_set(self):
set_a = {1, 2, 3}
set_b = {3, 2, 1}
assert set_a == set_b
if __name__ == '__main__':
pytest.main(['-vs', '-k', 'test_assert_result'])2、修改test_login.py文件内容;
# 导包--引入pytest模块框架
import pytest
import random
# 创建一个类 TestLogin--测试类以Test开头,后面可自定义
class TestLogin:
@pytest.mark.P1
def test_login_success(self):
# assert断言--random随机函数--随机取列表中的值True, False
assert random.choice([True, False]), '测试失败重跑'
print('登录成功场景')
# 登录失败
def test_login_failed(self):
assert random.choice([True, False]), '测试失败重跑'
print('登录失败场景')
@pytest.mark.P3
# 登录错误
def test_login_error(self):
assert random.choice([True, False]), '测试失败重跑'
print('登录错误场景')
# 主函数
if __name__ == '__main__':
pytest.main()3、修改test_adduser.py文件内容;
# 导包
import pytest
# 创建类 TestAddUser
class TestAddUser():
# 装饰器 标记方式
@pytest.mark.last
@pytest.mark.P1
# 定义测试用例 test_add_user_01
def test_add_user_01(self):
print('新增用户01')
@pytest.mark.second
def test_add_user_02(self):
print('新增用户02')
@pytest.mark.first
@pytest.mark.P3
def test_add_user_03(self):
print('新增用户03')
if __name__ == '__main__':
pytest.main(['-vs', '-k', 'test_adduser'])4、修改test_deleteUser.py文件内容;
# 导包
import pytest
# 创建类 TestDeleteUser
class TestDeleteUser():
@pytest.mark.P1
# 定义测试用例 test_delete_user_01
def test_delete_user_01(self):
print("删除用户01")
@pytest.mark.P3
def test_delete_user_02(self):
print('删除用户02')5、修改pytest.ini配置文件,再添加自定义注册标记;
[pytest]
addopts = -s -v --reruns 3
testpaths = ./testcase
python_files = test_*.py
python_classes = Test*
python_functions = test*
markers =
last
second
first
P1
P3命令行
使用 -m 去执行分组的测试用例,使用 -m 参数加上标记分组名称'P1',运行时只执行 P1 级测试用例;执行多个时使用关键词'not、and、or'等;
pytest -vs -m 'P1'
# 多个组时需添加引号(单引号、双引号)括起来
pytest -vs -m 'P1 or P3'主函数入口
import pytest
if __name__ == '__main__':
# 只单个 -m 参数时使用
pytest.main(['-m P1'])
pytest.main(['-m P1 or P3'])配置文件
亦可更改 pytest.ini 配置文件,再使用 run.py 主函数;
[pytest]
addopts = -s -v --reruns 3 -m "P1 or P3"
testpaths = ./testcase
python_files = test_*.py
python_classes = Test*
python_functions = test*
markers =
last
second
first
P1
P3跳过执行
在pytest中,可以使用 @pytest.mark.skip装饰器或者 @pytest.mark.skipif装饰器,以及可以使用 @pytest.mark.xfail装饰器来跳过测试用例的执行。
使用 pytest.mark.skip 装饰器
用于无条件的跳过测试用例,若某个测试用例上面有 pytest.mark.skip 装饰器标记,则无条件跳过执行;
使用 pytest.mark.skipif 装饰器
用于根据指定的条件来跳过测试用例的执行,若某个测试用例上面有 pytest.mark.skipif 装饰器标记,则有指定条件跳过执行;里面需要跟上两个参数,第一个 condition= 就是要跳过测试用例的表达式的意思,还可以再跟上一个参数 reason= 是跳过测试用例的原因,说明一个原因,为什么要跳过这个测试用例;
使用 pytest.mark.xfail 装饰器
用于标记测试用例为预期失败,测试用例的执行不会被视为失败,而是作为预期失败的处理;会给这个测试用例打上一个 xfail 标签,它不是一个真正的失败;使用场景不是特别多,了解即可;明确知道某一条测试用例肯定会失败,但是如果打上 pytest.mark.xfail 标签,这条测试用例仍然会去执行,不会导致整体测试用例运行失败,只是将测试结果打上 xfailed 标签,并不是真正意义上的测试失败;
6、在 login 目录下新建 test_skip_case.py 文件,并输入以下内容;
# 导包
import pytest
class TestLogin:
def test_login_success(self):
print('登录成功场景')
# 装饰器 @pytest.mark.skip --跳过此用例
@pytest.mark.skip
def test_login_failed(self):
print('登录失败场景')
# 定义一个变量
num = 5
# 装饰器--第一个参数后面接的是一个 表达式,第二个参数是 执行跳过的一个说明
# @pytest.mark.skipif(condition=num==5, reason='符合表达式条件,所以此用例跳过。。。')
@pytest.mark.skipif(num == 5, reason='符合表达式条件,所以此用例跳过。。。')
def test_login_error(self):
print('登录错误场景')
# 它只会将这条测试用例标记为一个 XFAIL 这样的标签--但它最后不会统计为一个失败的测试用例
@pytest.mark.xfail
def test_login_except(self):
assert 1 == 2
if __name__ == '__main__':
pytest.main()7、修改 pytest.ini 配置文件;
[pytest]
addopts = -vs
testpaths = ./testcase
python_files = test_*.py
python_classes = Test*
python_functions = test*
# 注册自定义标记
markers =
last
second
first
P1
P3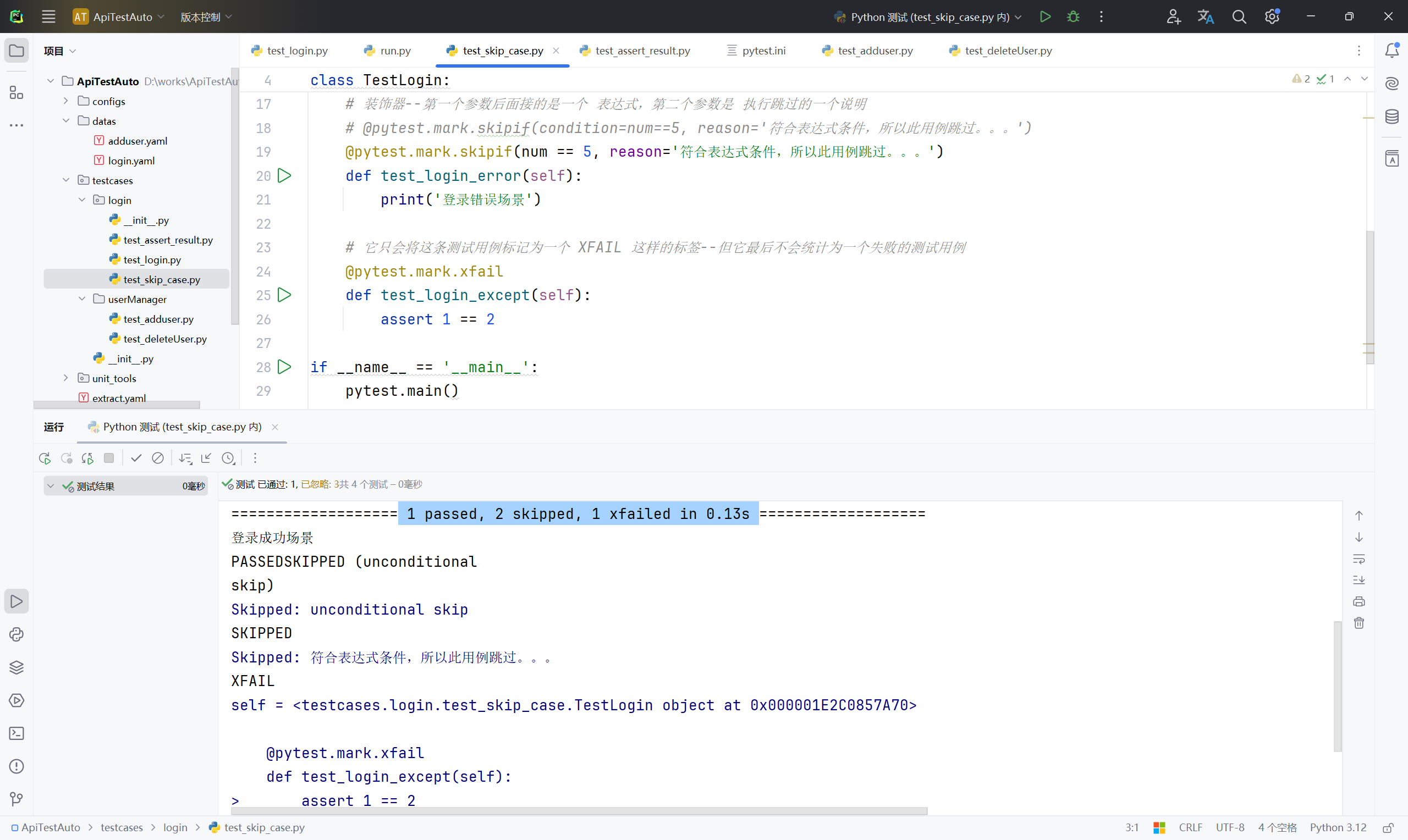
八、参数化处理
在pytest中,参数化是一种将相同的测试用例以不同的参数运行多次的机制,这可以帮助简化测试代码,使其更灵活和易维护,达到可以覆盖不同的测试场景;它通过 @pytest.mark.parametrize 装饰器去实现参数化,参数化最大的作用就是可以去简化测试代码。
参数化的基本用法:
- 使用 @pytest.mark.parametrize装饰器将参数传递给测试函数;
- 指定参数名和参数值;
- 在测试函数的参数中接收参数值,用于多次测试;
- 语法:@pytest.mark.parametrize("params1, params2......paramsN", iterable),第一个参数用于指定测试函数的参数名称,第二个参数是可迭代的 对象,如:列表、元组、字典等;
- 测试函数接收的参数名务必要与参数化的第一个参数保持一致,参数个数也要保持一致;
8、在 login 目录下新建 test_parameter.py 文件,并输入以下内容;
# 定义一个测试类
class TestParameter:
# 定义测试方法
def test_login(self):
print('正确的用户名和密码登录成功校验')
def test_failed(self):
print('正确的用户名错误的密码登录校验')
def test_failed_02(self):
print('错误的用户名正确的密码登录校验')
def test_failed_03(self):
print('输入特殊字符登录校验')一般情况下未使用参数化时,需要输入一系列的校验,每一个都需要写一个校验,去验证每一个场景;若做了参数化,可直接通过参数化去输入不同的数据去校验一个功能,验证其是否满足各种场景;通过传入不同的参数,去校验功能。
9、修改test_parameter.py文件内容;
# 导包
import pytest
# 定义一个测试类
class TestParameter:
# 装饰器 @pytest.mark.parametrize 它可以跟上两个参数
# 第一个参数它是一个字符串,用于指定测试函数的参数名称
# 第二个参数就是 需要参数化的一个数据,它可以跟任何可迭代的对象
@pytest.mark.parametrize('user_name, password', [('test01', 'admin123'), ('test01', 'admin999'), ('test02', 'admin123'), ('test@#&', 'admin999$-~')])
# 定义测试方法
def test_login(self, user_name, password):
print(user_name, password)
print('正确的用户名和密码登录成功校验')
if __name__ == '__main__':
pytest.main(['-k', 'test_parameter'])10、一般使用最多的就是列表类型或者元组类型,字典类型的比较少,不是特别多,再次修改test_parameter.py文件内容;
# 导包
import pytest
# 定义一个测试类
class TestParameter:
# 传递多个参数,通过列表类型的可迭代对象实现参数化
@pytest.mark.parametrize('user_name, password', [('test01', 'admin123'), ('test01', 'admin999'), ('test02', 'admin123'), ('test@#&', 'admin999$-~')])
def test_login(self, user_name, password):
print(user_name, password)
print('正确的用户名和密码登录成功校验')
# 传递一个参数
@pytest.mark.parametrize('user_name', ['test01', 'test02', 'test03'])
def test_login02(self, user_name):
print(user_name)
print('这是要打印的内容:test_login02')
# 通过元组类型的可迭代对象实现参数化
@pytest.mark.parametrize('user_name', ('test01', 'test02', 'test03'))
def test_login03(self, user_name):
print(user_name)
print('这是一个打印内容test_login03-元组类型')
# 通过字典类型的可迭代对象实现参数化--字典类型的是迭代其key值
@pytest.mark.parametrize('user_name', {"user_name": "test01", "user_name2": "test02"})
def test_login04(self, user_name):
print(user_name)
print('这是一个打印内容test_login04-字典类型')
if __name__ == '__main__':
pytest.main(['-k', 'test_parameter'])11、这种方式比在 unittest 框架中做参数化要方便(unittest是使用ddt模块),这里通过读取操作文件的方式去做参数化,一般会把参数化中的参数改造成可读取文件中的数据(例如 yaml 文件、Excel 文件等等),此处简单引用;
# 导包
import pytest
from unit_tools.handle_data.yaml_handler import read_yaml
# 定义一个测试类
class TestParameter:
# 传递多个参数,通过列表类型的可迭代对象实现参数化
@pytest.mark.parametrize('user_name, password', [('test01', 'admin123'), ('test01', 'admin999'), ('test02', 'admin123'), ('test@#&', 'admin999$-~')])
def test_login(self, user_name, password):
print(user_name, password)
print('正确的用户名和密码登录成功校验')
# 传递一个参数
@pytest.mark.parametrize('user_name', ['test01', 'test02', 'test03'])
def test_login02(self, user_name):
print(user_name)
print('这是要打印的内容:test_login02')
# 通过元组类型的可迭代对象实现参数化
@pytest.mark.parametrize('user_name', ('test01', 'test02', 'test03'))
def test_login03(self, user_name):
print(user_name)
print('这是一个打印内容test_login03-元组类型')
# 通过字典类型的可迭代对象实现参数化--字典类型的是迭代其key值
@pytest.mark.parametrize('user_name', {"user_name": "test01", "user_name2": "test02"})
def test_login04(self, user_name):
print(user_name)
print('这是一个打印内容test_login04-字典类型')
# 引入读取yaml文件方法--这里需要注意文件的 相对路径 位置
@pytest.mark.parametrize('api_info', read_yaml('../../datas/login.yaml'))
def test_login05(self, api_info):
print(f"获取到的接口信息:{api_info}")
if __name__ == '__main__':
pytest.main(['-k', 'test_parameter'])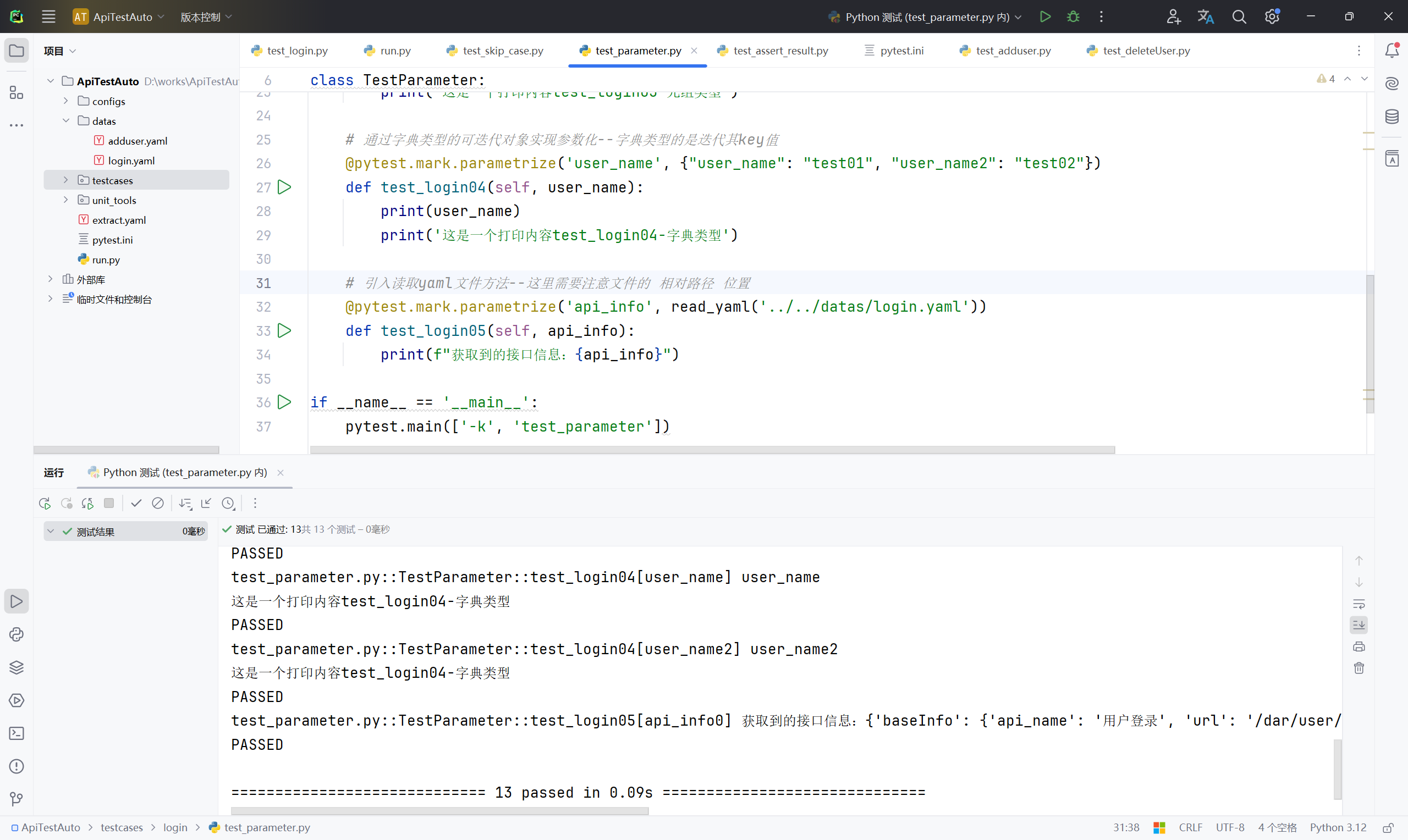
未完待续。。。