RAG 介绍:
什么是 RAG:
核心定义:
RAG 是 Retrieval-Augmented Generation 的缩写,中文通常译为检索增强生成;它是一种将大语言模型内部知识与外部知识库结合起来的技术范式,主要用来缓解 LLM 只依赖训练参数回答问题时可能出现的知识过时、细节不准和缺少依据等问题
从知识来源看,LLM 在预训练过程中学到的内容可以称为参数化知识,这类知识被固化在模型权重中,具有泛化能力强但更新困难的特点;企业文档、数据库、网页、知识库和实时业务数据则属于非参数化知识,这类知识更具体、更可控,也可以在不重新训练模型的情况下持续更新;
RAG 的关键价值,就是在模型生成答案之前,先从外部知识库中检索相关材料,再把这些材料作为上下文交给模型生成回答,从而提升回答的准确性、可解释性和时效性
一句话理解:RAG 就是让 LLM 从闭卷答题变成开卷答题;它既可以调用自己已经学到的通用知识,也可以临时查阅外部资料来回答具体问题
工作原理:
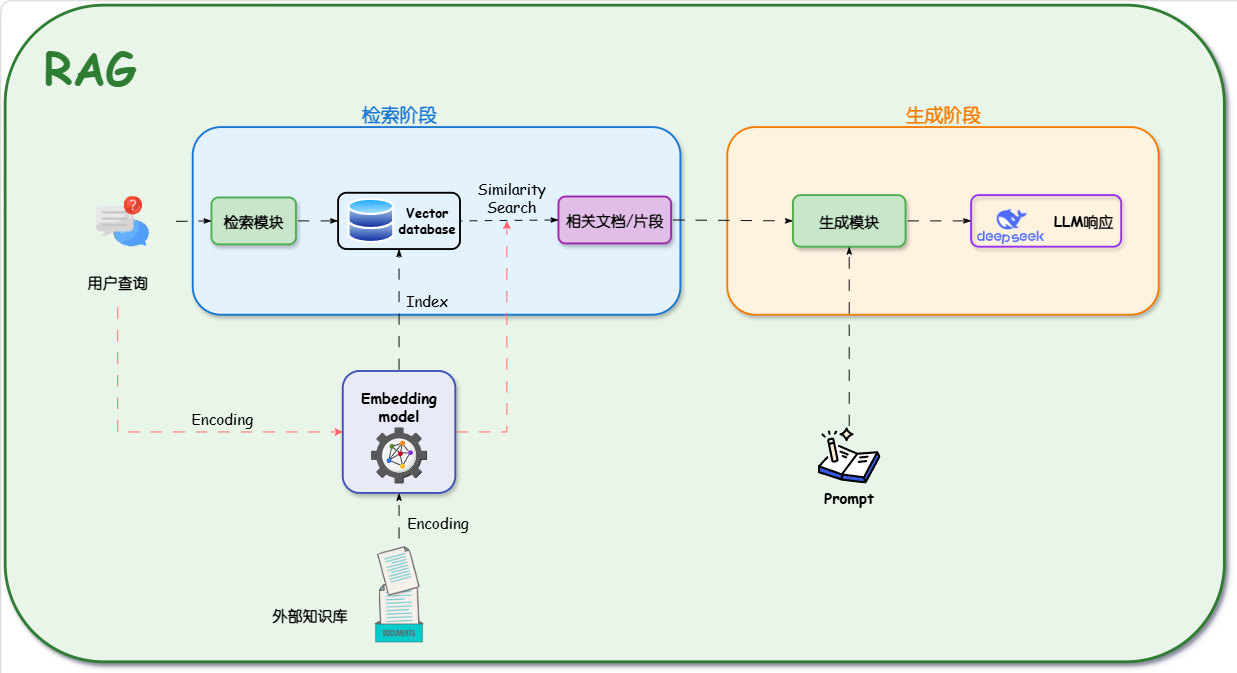
RAG 系统通常通过两个阶段完成参数化知识与非参数化知识的结合:第一阶段是检索,目标是从外部知识库中找到与用户问题最相关的内容;第二阶段是生成,目标是让 LLM 基于检索到的上下文组织答案
检索阶段:寻找非参数化知识
- 知识向量化:嵌入模型负责把文本、段落或文档片段编码成向量表示;这些向量会被写入向量索引或向量数据库,便于后续按语义相似度进行搜索
- 语义召回:当用户提出问题时,系统会使用同一个或兼容的嵌入模型把问题转换成向量;随后通过相似度搜索,从大量文档片段中召回最可能包含答案的内容
生成阶段:融合两类知识
- 上下文整合:生成模块会接收用户原始问题,以及检索阶段返回的相关文档片段;这些信息会被组织进提示词,形成模型可理解的上下文
- 指令引导生成:系统通过预设 Prompt 明确回答方式、引用依据和边界要求,引导 LLM 基于检索材料生成更可控、更有依据的答案;例如可以要求模型只依据上下文回答,缺少依据时直接说明不知道
技术演进:
RAG 的技术架构经历了从简单线性流程到复杂可编排系统的演进;按照常见划分方式,大致可以分为初级 RAG、高级 RAG 和模块化 RAG 三类:
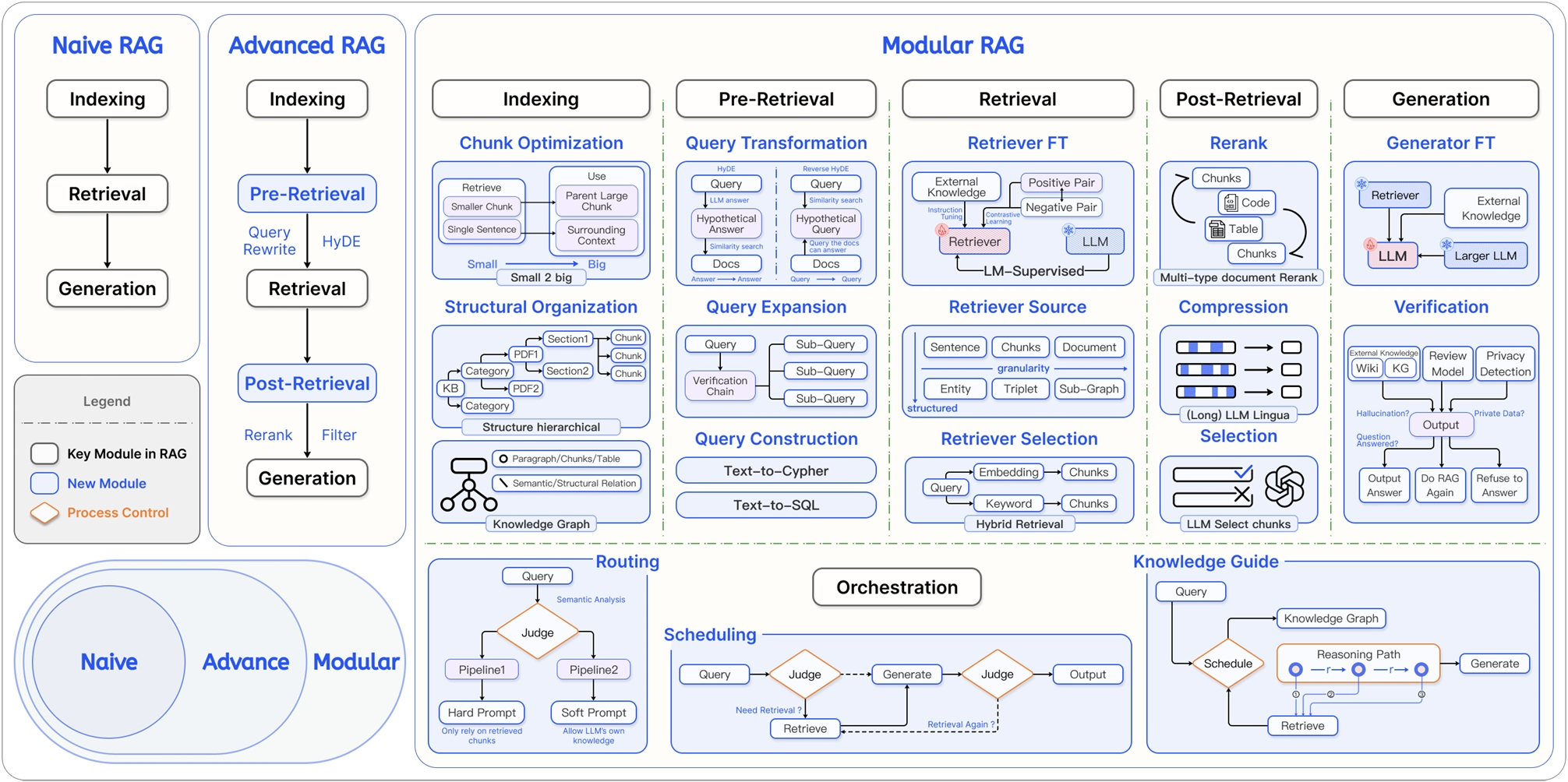
| 维度 | 初级 RAG(Naive RAG) | 高级 RAG(Advanced RAG) | 模块化 RAG(Modular RAG) |
|---|---|---|---|
| 流程 | 离线:索引;在线:检索 → 生成 | 离线:索引;在线:检索前优化 → 检索 → 检索后优化 → 生成 | 积木式、可编排、可替换的流程 |
| 特点 | 基础线性流程,容易搭建 | 在检索前后加入优化步骤,效果更稳定 | 模块化、可组合、可动态调整,适合复杂业务系统 |
| 关键技术 | 基础向量检索 | 查询重写(Query Rewrite)、结果重排(Rerank) | 动态路由(Routing)、查询转换(Query Transformation)、多路融合(Fusion) |
| 局限性 | 效果不稳定,排查和优化空间有限 | 流程仍相对固定,系统弹性有限 | 系统复杂度高,对工程设计、评估和运维能力要求更高 |
这里的离线是指用户提问前提前完成的数据预处理工作,例如文档清洗、切分、向量化和索引构建;在线是指用户发起请求之后实时发生的检索、排序、上下文组装和生成流程
为什么要使用 RAG:
RAG 与微调:
在为大模型应用选择技术路线时,一个核心原则是先使用成本更低、对模型改动更小的方法;一般来说,可以优先尝试提示词工程(Prompt Engineering),再考虑 RAG,最后才考虑微调(Fine-tuning)
从优化对象看,提示词工程主要优化输入方式,不改变模型权重,也不额外引入知识库;RAG 仍然不改变模型权重,但会通过外部知识库增强上下文;微调则会直接更新模型参数,更适合改变模型的行为模式、风格偏好或输出格式
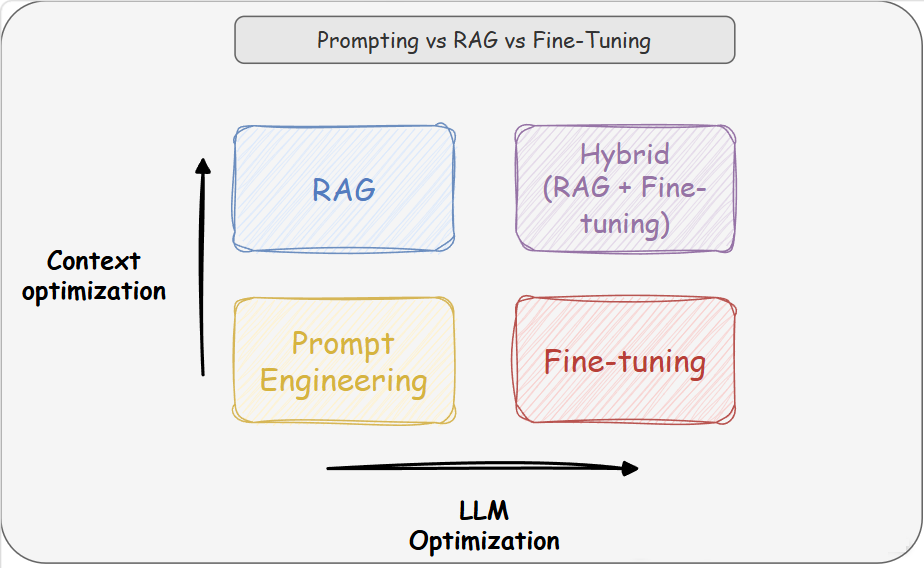
基于这一思路,常见选择路径如下
- 先尝试提示词工程:如果任务较简单,且模型本身已经具备相关知识,可以通过更清晰的角色设定、任务描述、输出格式和示例来提升回答质量
- 再选择 RAG:如果模型缺少特定领域知识、私有知识或最新知识,就可以通过外部知识库为模型补充上下文,让模型有依据地回答
- 最后考虑微调:如果目标不是让模型知道更多,而是让模型更稳定地按照特定方式做事,例如严格遵循某种输出格式、模仿特定对话风格,或把复杂指令内化为模型行为,微调才更合适
RAG 填补了通用模型与专业领域之间的鸿沟;当 LLM 遇到下面的典型局限时,RAG 通常是一种更直接、更经济的解决方案:
| 问题 | RAG 的解决方案 |
|---|---|
| 静态知识局限 | 实时检索外部知识库,支持知识动态更新 |
| 幻觉(Hallucination) | 基于检索内容生成回答,降低无依据编造的概率 |
| 领域专业性不足 | 引入医疗、法律、金融、企业制度等领域知识库 |
| 数据隐私风险 | 支持本地化或私有化部署知识库,减少敏感数据外泄风险 |
核心优势:
准确性与可信度的双重提升:
RAG 最核心的价值,是突破模型预训练知识的边界;它可以补充专业领域的知识盲区,也可以通过向模型提供具体参考材料,降低模型一本正经胡说八道的概率;相关研究表明,RAG 生成内容在具体性和多样性上通常优于纯 LLM 回答;更重要的是,RAG 具备可溯源性,回答可以关联到原始文档出处,这种有据可查的能力能显著提升法律、医疗、金融和企业知识问答等严肃场景中的可信度
时效性保障:
LLM 的训练数据通常存在时间边界,因此模型可能不知道训练截止日期之后发生的事件、政策变化或业务更新;RAG 通过把知识库与模型本体解耦,让新政策、新产品资料或新业务数据在入库后即可被检索使用;这种能力也常被称为索引热拔插(Index Hot-swapping),它类似于为系统切换一套可更新的外部知识存储,而不需要重新训练模型
显著的综合成本效益:
从成本角度看,RAG 通常比频繁微调更经济;它避免了每次知识更新都重新训练模型的高昂算力成本,也允许团队在部分专业场景中使用参数规模更小的基础模型;当外部知识检索足够准确时,小模型也可能在特定任务上获得接近大模型的效果,从而进一步降低推理成本
灵活的模块化可扩展性:
RAG 架构天然支持多源数据集成;PDF、Word、网页、数据库、内部知识库和结构化表格都可以经过处理后进入知识系统;同时,RAG 将检索与生成解耦,使团队能够独立优化嵌入模型、向量数据库、重排模型、Prompt 模板和生成模型,而不必每次都重建整套系统
适用场景与风险:
RAG 并不是只要接入知识库就万无一失;不同场景的风险不同,对质量控制、人类审核和可解释性的要求也不同:
| 风险等级 | 案例 | RAG 适用性 |
|---|---|---|
| 低风险 | 翻译、语法检查、普通资料问答 | 通常可靠性较高,可作为自动化工具使用 |
| 中风险 | 合同起草、法律咨询、医疗资料解释 | 需要结合人工审核,并保留引用来源 |
| 高风险 | 证据分析、签证决策、诊疗建议、金融决策 | 需要严格质量控制机制,不应完全自动化决策 |
如何上手 RAG:
基础工具链:
构建 RAG 系统通常涉及开发框架、数据处理、向量存储、检索策略、生成模型和评估工具等环节;在开发模式上,可以使用 LangChain 或 LlamaIndex 等成熟框架快速搭建,也可以选择不依赖框架的原生开发方式,以获得更细粒度的流程控制;LangChain 当前官方文档会把常见 RAG 实现区分为 RAG agent 与 2-Step RAG chain 等形态,LlamaIndex 则强调从数据加载、索引、检索到生成的完整流程
在记忆载体方面,向量数据库负责存储和检索文本向量;Milvus、Pinecone 等更适合大规模或生产级场景,FAISS、Chroma 等更适合本地实验、轻量应用或快速原型;在效果评估方面,可以引入 Ragas 或 TruLens 等工具,把回答相关性、忠实性、上下文召回率等指标纳入持续评估流程;其中 Ragas 官方文档已经将其定位为面向 LLM 应用的系统化评估与实验工具
最小可行系统(MVP):
第一步 数据准备与清洗:这是 RAG 系统的地基;首先需要把 PDF、Word、网页和数据库导出的多源异构数据转换成统一文本或结构化格式;随后要去除噪声、重复内容和无效片段,并设计合理的分块策略;相比机械地按固定字符数切分,按标题、段落、语义边界或业务单元切分通常更有利于保留上下文完整性
第二步 索引构建:将切分后的文本片段交给嵌入模型,转换成向量后写入向量数据库或向量索引;在这个阶段建议同步保存元数据,例如来源文件、章节、页码、更新时间和权限标签;这些元数据不仅方便引用溯源,也能用于权限过滤和结果排序
第三步 检索策略优化:不要只依赖单一向量搜索;在实际业务中,可以组合向量检索与关键词检索,形成混合检索策略,提高召回率;对于召回结果,还可以加入重排序模型进行二次筛选,让 LLM 优先看到与问题最相关、质量最高的上下文
第四步 生成与提示工程:最后,需要设计清晰的 Prompt 模板,把用户问题、检索上下文、回答要求和安全边界组织在一起;建议明确要求模型基于给定上下文回答,无法从上下文判断时说明不知道,并在需要时给出引用来源;这样可以减少幻觉,也能让用户更容易追溯答案依据
进阶挑战:
当一个基础 RAG 系统能够跑通之后,下一阶段的重点不再是能不能回答,而是回答是否稳定、是否正确、是否可解释,以及出现错误时能否定位原因
评估维度与挑战:
一套 RAG 系统的质量不能只凭主观感觉判断;业界通常会从检索相关性、上下文召回率、生成质量、回答忠实性和术语准确性等维度进行评估;其中检索相关性关注系统是否找到了包含答案的材料,生成质量关注回答是否清晰、完整且符合任务要求,语义准确性关注回答含义是否正确,词汇匹配度则关注专业术语是否使用得当
这些评估维度也对应着 RAG 的主要挑战;如果检索系统召回了错误材料,再强的 LLM 也可能基于错误上下文生成貌似合理但事实错误的答案;对于需要跨多个文档、多个实体或多个时间点综合分析的多跳推理任务,普通线性 RAG 流程也常常力不从心
优化方向与架构演进:
针对这些问题,社区和工业界已经探索出多种优化路径;在性能层面,可以通过索引分层、缓存高频数据、批量向量化和检索结果复用来提升效率;在能力层面,可以扩展到多模态检索,让图片、表格、图表和结构化数据也参与问答
在架构层面,简单的检索再生成流程正在被更灵活的设计模式取代;例如,系统可以通过分支模式并行触发多路检索,再通过融合策略汇总结果;也可以通过循环模式让模型检查答案质量、发现信息不足并再次检索;这些模式让 RAG 从单一链路逐步演进为可诊断、可调度、可自我修正的知识系统
数据加载:
文档加载器:
在 RAG 系统中,数据加载是整个数据管道的第一步,也是不可省略的一步;文档加载器负责把 PDF、Word、Markdown、HTML 等非结构化文档转换为程序可以处理的结构化数据;加载效果会直接影响索引构建、召回质量和最终生成质量
文档加载器通常需要完成三个核心任务:第一,解析不同格式的原始文档,把 PDF、Word、Markdown 等内容提取为可处理的文本;第二,在解析过程中同步抽取文档来源、页码、作者、标题层级等元数据;第三,把文本和元数据整理成统一的数据结构,便于后续切分、向量化和入库
从数据工程角度看,文档加载器做的事情类似抽取、转换、加载(ETL);它的目标不是简单把文件读成字符串,而是把杂乱的原始文档清洗、解析和标准化,变成适合检索与建模的语料
不同加载器的优势并不相同;有些适合轻量文本,有些适合复杂 PDF,有些适合网页抓取,还有些更适合企业级多格式解析;实际选型时,需要结合文档类型、解析精度、速度、部署方式和成本综合判断
当前主流 RAG 文档加载器:
| 工具名称 | 特点 | 适用场景 | 性能表现 |
|---|---|---|---|
| PyMuPDF4LLM | 面向 LLM 场景的 PDF 到 Markdown 转换,适合保留段落、标题和表格等结构 | 科研文献、技术手册 | 开源免费,解析速度快,依赖轻 |
| TextLoader | 基础文本文件加载,通常用于 .txt 等纯文本文件 | 纯文本处理 | 轻量高效,适合入门和简单数据 |
| DirectoryLoader | 批量加载目录下的文件,可搭配不同文件加载器处理多种格式 | 混合格式文档库 | 支持多格式扩展,适合批处理 |
| Unstructured | 多格式文档解析,支持 PDF、Word、HTML、Markdown 等格式 | 通用文档预处理、RAG 数据入库 | 统一接口,结构识别能力强 |
| FireCrawlLoader | 网页内容抓取与清洗,适合在线资料获取 | 在线文档、新闻、网页知识库 | 支持实时内容获取 |
| LlamaParse | 面向复杂 PDF 的结构化解析服务 | 法律合同、学术论文、复杂版式 PDF | 解析精度较高,通常以商业 API 形式使用 |
| Docling | 模块化企业级文档解析工具,强调结构保留和企业场景 | 企业合同、报告、内部知识文档 | IBM 生态兼容,适合严肃文档处理 |
| Marker | PDF 到 Markdown 转换工具,重点处理论文、书籍等长文档 | 科研文献、书籍 | 专注 PDF 转换,可利用 GPU 加速 |
| MinerU | 面向复杂文档的多模态解析工具,兼顾布局、文字、表格和公式 | 学术文献、财务报表 | 集成布局分析与目标检测等能力 |
Unstructured 文档处理库:
核心优势:
Unstructured 是一个面向非结构化数据预处理的文档解析库,常用于 RAG 和 AI 微调前的数据准备;它的核心价值在于提供统一接口,把不同格式的文件解析为一组带有类型和元数据的文档元素,从而降低多格式文档接入成本
Unstructured 在格式支持和结构识别方面都有明显优势:一方面,它支持 PDF、Word、Excel、HTML、Markdown 等多种文档格式,可以避免为每种格式单独编写解析代码;另一方面,它可以识别标题、正文、列表、表格、页眉、页脚、图片说明等文档结构,并保留来源文件、页码、文件类型、坐标等元数据信息
支持的文档元素类型:
Unstructured 会把文档解析成一系列 Element 对象;每个元素通常包含元素类型、文本内容、元素 ID 和元数据;这种结构比普通字符串更适合 RAG,因为后续可以按元素类型过滤噪声,也可以用元数据实现溯源、分页引用和权限控制
Unstructured 官方文档中列出的常见元素类型如下:
| 元素类型 | 描述 |
|---|---|
| Title | 文档标题或章节标题 |
| NarrativeText | 由多个完整句子组成的正文文本,不包括标题、页眉、页脚和说明文字 |
| ListItem | 列表项,属于列表中的正文文本元素 |
| Table | 表格内容 |
| Image | 图像相关元数据 |
| Formula | 文档中的公式元素 |
| Address | 物理地址 |
| EmailAddress | 邮箱地址 |
| FigureCaption | 图片标题或说明文字 |
| Header | 文档页眉 |
| Footer | 文档页脚 |
| CodeSnippet | 代码片段 |
| PageBreak | 页面分隔符 |
| PageNumber | 页码 |
| UncategorizedText | 未分类的自由文本 |
| CompositeElement | 分块处理后产生的复合元素 |
CompositeElement 是分块处理时产生的特殊元素类型,由一个或多个连续文本元素组合而成;例如,多个连续列表项可能会被合并为一个块;官方文档也强调,CompositeElement 只会在分块阶段产生,不是原始分区时直接识别出的基础元素
使用 Unstructured 加载文档:
LangChain 提供的 UnstructuredMarkdownLoader,是框架基于 Unstructured 能力封装的专用文档加载器,能够适配 LangChain 完整工作流,快速完成 Markdown 文档的读取与加载;依据新版 LangChain 官方文档,该加载器归属在 langchain_community.document_loaders 模块,使用前需安装 langchain-community 与 unstructured 依赖库,同时原生支持 load()、lazy_load() 等多种文档加载方式
而直接调用 Unstructured 原生 API,能够实现更细粒度的自定义控制;开发者可自主指定 PDF 拆分规则、调整解析策略、配置 OCR 识别语言,开启表格结构解析,还能单独提取图片、表格等模块内容;面对复杂排版 PDF、扫描件文档,或是需要完整保留原文结构的业务场景,直接使用 Unstructured 原生接口,会比 LangChain 封装工具更加灵活可控
示例代码:
安装 Poppler:底层 PDF 工具,负责读取 PDF 结构、把 PDF 每页转成图片、获取页数
https://github.com/oschwartz10612/poppler-windows/releases/download/v25.12.0-0/Release-25.12.0-0.zip
解压到纯英文路径,复制路径:如 C:\poppler\Library\bin,加入系统环境变量 Path,重启终端 / 编辑器
安装 Tesseract-OCR:开源 OCR 工具,识别图片、扫描件里的文字
步骤同上(下载中文语言包 chi_sim.traineddata 放入目录:Tesseract-OCR\tessdata 下)
使用 Unstructured 解析一个 PDF 文件:
python
from collections import Counter
from pathlib import Path
from unstructured.partition.auto import partition
# PDF 文件路径
pdf_path = Path("./test.pdf")
# 使用 Unstructured 的 partition 函数解析 PDF,partition 会根据文件类型自动选择合适的解析方式
elements = partition(
filename=str(pdf_path), # PDF 文件路径,需要转成字符串
content_type="application/pdf", # 指定文件类型为 PDF
)
# 统计所有解析元素的文本字符总数,str(element) 可以拿到该元素的文本内容
total_chars = sum(len(str(element)) for element in elements)
print(f"解析完成: {len(elements)} 个元素, {total_chars} 字符")
# 统计不同元素类型的数量
# element.category 表示元素类别,例如 Title、NarrativeText、ListItem、Table 等
types = Counter(element.category for element in elements)
print(f"元素类型: {dict(types)}")
# 所有解析出来的元素
print("\n所有元素:")
for index, element in enumerate(elements, 1):
# 当前元素的编号和类型
print(f"Element {index} ({element.category}):")
# 当前元素的文本内容
print(element)
print("=" * 91)代码执行过程:首先 partition 会读取指定 PDF 文件,并根据 content_type="application/pdf" 直接按 PDF 类型处理,接着解析结果会以元素列表形式返回,每个元素都有自己的类别和文本内容;最后,代码统计元素类别,并逐个打印元素,方便观察 PDF 被解析成了哪些结构
通用解析函数 partition:
partition 是 Unstructured 提供的通用文档解析入口,它会根据文件类型自动路由到对应的专用解析函数,例如 PDF 会路由到 partition_pdf,Markdown 会路由到 partition_md,HTML 会路由到 partition_html;如果系统安装了 libmagic,会优先使用它识别文件类型,否则会回退到文件扩展名识别
| 参数 | 说明 |
|---|---|
| filename | 本地文档路径,适合处理磁盘上的文件 |
| content_type | 可选参数,用于指定 MIME 类型,例如 application/pdf;传入后可以绕过部分自动检测逻辑 |
| file | 文件对象,与 filename 二选一使用 |
| url | 远程文档地址,支持直接处理网络文档 |
| include_page_breaks | 是否在输出中包含页面分隔符;仅部分文件类型支持 |
| strategy | PDF 和图片等文件的解析策略,常见值包括 auto、fast、hi_res、ocr_only |
| encoding | 文本编码格式,默认会自动检测 |
入门学习时,使用 partition 足够简单便捷;但在生产环境中,如果已经明确文件类型,更推荐直接调用对应的专用解析函数,既能减少自动类型检测的开销,也能使用更多针对该文件类型的专属参数
PDF 解析函数 partition_pdf:
如果需要更专业地处理 PDF,可直接使用 partition_pdf,它支持 OCR 语言配置、表格结构推断、图片与表格块提取等 PDF 专用能力;根据 Unstructured 官方文档,PDF 解析策略包含 auto、fast、hi_res 和 ocr_only 四种模式
python
from pathlib import Path
from unstructured.partition.pdf import partition_pdf
pdf_path = Path("./test.pdf")
elements = partition_pdf(
filename=str(pdf_path),
strategy="hi_res", # 使用高精度解析策略
infer_table_structure=True, # 尽量识别表格结构
)
for element in elements:
print(element.category, str(element)[:80])几种策略可以这样理解:
| 策略 | 适用情况 | 特点 |
|---|---|---|
| auto | 不确定文档质量时的默认选择 | 自动根据文档特征和参数选择策略 |
| fast | PDF 本身可复制、可提取文本 | 速度快,主要使用规则和传统文本提取方式 |
| hi_res | 复杂版式、表格、图片和布局结构重要 | 使用布局检测模型,结构识别更强,但速度较慢 |
| ocr_only | 扫描件或图片型 PDF | 通过 OCR 提取文字,再按文本进行解析 |
在实际应用中,PDF 处理往往是 RAG 数据加载中最容易踩坑的部分;如果文档包含复杂表格、公式、图片、脚注、多栏排版或扫描页,除了 Unstructured,也可以评估 PaddleOCR、MinerU、Marker、Docling 等工具;工具选择不应只看是否能读取文本,还要看结构保留、表格还原、公式识别、速度、部署成本和后续检索效果
文本分块:
文本分块(Text Chunking)是构建 RAG 流程的关键步骤;它的作用是把加载后的长篇文档切分成更小、更容易处理的内容单元;这些内容单元就是后续向量检索、重排和大模型生成时使用的基本单位

可以把文本分块理解为把一本书拆成若干张知识卡片;如果卡片太大,检索时很难准确命中关键内容;如果卡片太小,又可能丢失上下文,导致模型不知道这句话属于哪个主题;优秀的分块策略,目标是在语义完整性、检索精度和模型上下文限制之间取得平衡
为什么需要文本分块:
上下文长度限制:
文本分块的首要原因,是为了适应 RAG 系统中两个核心组件的输入长度限制:嵌入模型和大语言模型
嵌入模型(Embedding Model)负责把文本块转换成向量;这类模型通常有明确的输入长度上限;例如常见的 bge-base-zh-v1.5 这类模型通常以约 512 token 作为默认最大输入长度,具体限制应以模型配置为准;如果文本块超过输入上限,超出部分可能被截断,导致信息丢失,最终生成的向量也无法完整代表原文语义
大语言模型(LLM)负责根据检索到的上下文生成答案;LLM 也有上下文窗口限制,虽然这个窗口通常比嵌入模型大很多,可能从几千 token 到上百万 token 不等;检索到的所有文本块、用户问题、系统提示词和回答格式要求,都必须放进这个窗口;如果单个块过大,模型一次能参考的块数量就会减少,回答时可利用的信息广度也会受限
因此,文本分块是保证文本能够被嵌入模型和大语言模型完整、有效处理的基础;它不是可有可无的预处理步骤,而是 RAG 系统稳定运行的前提
块过大的问题:
假设嵌入模型最多能处理 8192 个 token,是否应该把每个块都切到接近 8000 token;答案通常是否定的;块大小并不是越大越好,过大的块反而会降低 RAG 系统的检索和生成效果
嵌入过程中的信息损失:
大多数嵌入模型都基于 Transformer 编码器;其处理流程通常包括分词、向量化和池化三个阶段:
- 分词(Tokenization):把输入文本拆分成一个个 token
- 向量化(Vectorization):Transformer 为每个 token 生成高维向量表示
- 池化(Pooling):通过 CLS 向量、平均池化(Mean Pooling)等方式,把所有 token 的向量压缩成一个单一向量,用这个向量表示整个文本块的语义
CLS 是 BERT 等 Transformer 模型在输入文本开头添加的特殊标记;它会通过自注意力机制聚合整个序列的上下文信息;在某些模型中,最终的 CLS 向量会被用来表示整体语义
在这种压缩过程中,信息损失不可避免;一个 768 维或 1024 维向量需要概括整个文本块的内容;文本块越长,包含的语义点越多,单一向量承载的信息就越稀释;这会让向量表示变得笼统,关键细节被模糊化,进而降低检索精度
生成阶段的关键信息淹没:
即使把多个大块文本都放进 LLM 的长上下文窗口,也可能出现关键信息被大量无关内容淹没的问题;研究表明,当模型处理很长且信息密集的上下文时,往往更容易利用开头和结尾的信息,而中间部分更容易被忽略,这就是常说的 Lost in the Middle 现象
如果提供给 LLM 的上下文块又大又杂,里面充满与问题无关的噪声,模型就更难找到真正关键的信息;这会导致回答质量下降,甚至诱发幻觉
主题稀释导致检索失败:
一个好的文本块应该尽量聚焦于一个明确主题;如果一个块同时包含太多不相关主题,它的语义表示会被稀释,检索时就很难被精确匹配
合理分块可以提升检索信噪比,让生成环节拿到更相关、更干净的上下文;因此,分块策略不只是工程细节,而是影响 RAG 质量的核心因素
基础分块策略:
长度分块 CharacterTextSplitter:
长度分块是最容易理解的分块方法;它会根据预设分隔符和目标块大小,将文本切成若干块;在 LangChain 中,CharacterTextSplitter 的默认分隔符通常是 "\n\n",因此它并不是完全机械地按固定字符数硬切,而是会优先按段落边界切分,再通过合并逻辑控制块大小
根据 LangChain 的实现逻辑,这个过程可以拆成两个阶段:
- 按段落分割:使用默认分隔符 "\n\n" 将文本分成若干段落片段
- 智能合并:调用父类的合并逻辑,把片段依次合并成块,并根据 chunk_size 与 chunk_overlap 控制目标长度和重叠内容
需要注意,CharacterTextSplitter 不是严格意义上的固定大小切分;它会优先保持段落完整性,只有添加新段落会超过目标大小时才结束当前块;如果单个段落本身超过 chunk_size,可能会形成超长块;因此,更准确的理解是段落感知的长度分块
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
# 加载纯文本文件,返回 Document 对象列表
loader = TextLoader("./test.txt", encoding="utf-8")
documents = loader.load()
# 按段落优先切分文本,并限制每个块的大致长度
text_splitter = CharacterTextSplitter(
separator="\n\n", # 优先用空行作为分隔符
chunk_size=200, # 每个文本块的目标最大长度
chunk_overlap=10, # 相邻文本块之间保留 10 个字符重叠
)
# 把加载得到的 Document 列表切分成多个更小的块
chunks = text_splitter.split_documents(documents)
print(f"文本被切分为 {len(chunks)} 个块\n")
print("--- 前 5 个块内容示例 ---")
for index, chunk in enumerate(chunks[:5], 1):
print("=" * 78)
# page_content 是当前文本块的正文内容
print(f"块 {index} 长度: {len(chunk.page_content)}")
print(chunk.page_content)这种方法的优势是实现简单、速度快、计算开销小;劣势是它对语义边界的理解有限,可能在语义上相关的内容之间切断文本;因此,它适合日志分析、规则化文本预处理、简单知识库入门实验等场景,但不一定适合复杂知识文档
递归字符分块 RecursiveCharacterTextSplitter:
RecursiveCharacterTextSplitter 是 LangChain 官方文档中推荐优先尝试的通用分块器;它使用一组按优先级排列的分隔符递归切分文本,目标是在尽量保持段落、句子、词语等自然结构完整的同时,让每个块满足目标大小
它的默认分隔符通常是 "\\n\\n", "\\n", " ", "";含义是先尽量按段落切分,如果块仍然过大,再按换行切分,再按空格切分,最后才按字符切分;对于中文、日文、泰文等没有明显词间空格的语言,可以额外加入中文标点、全角标点和零宽空格
算法流程可以概括为三步:
第一步 寻找有效分隔符:从分隔符列表前到后遍历,找到当前文本中存在的第一个分隔符;如果都不存在,就使用最后一个分隔符,通常是空字符串
第二步 切分与分类处理:使用选定分隔符切分文本;不超过块大小的片段会暂存并等待合并;超过块大小的片段会继续递归使用更细粒度的分隔符
第三步 合并最终片段:把剩余的合格片段按 chunk_size 与 chunk_overlap 合并成最终文本块
与 CharacterTextSplitter 相比,递归字符分块最大的优势是能继续处理超长段落;如果段落太长,它会尝试句子级、词级甚至字符级切分,而不是只保留超长块
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader("./test.txt", encoding="utf-8")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "\u3002", "\uff0c", " ", ""], # 段落 行 中文句号 中文逗号 空格 空字符串
chunk_size=200,
chunk_overlap=10,
)
chunks = text_splitter.split_documents(documents)
print(f"文本被切分为 {len(chunks)} 个块")对于中文等语言,可以使用下面这种更完整的分隔符配置:
python
separators = [
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # 零宽空格
"\uff0c", # 中文逗号
"\u3001", # 中文顿号
"\uff0e", # 全角句号
"\u3002", # 中文句号
",", # 中文逗号
"",
]RecursiveCharacterTextSplitter 还可以针对代码文件使用语言特化分隔符:
python
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
# 创建一个适用于 Python 代码的递归切分器
# 它会优先按照 Python 代码中更自然的结构进行切分,例如类、函数、空行、换行等,而不是直接生硬地按字符数截断
splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, # 指定要切分的内容是 Python 代码
chunk_size=500, # 每个代码块的目标最大长度约为 500 个字符
chunk_overlap=50, # 相邻代码块之间保留 50 个字符重叠,避免上下文被切断
)LangChain 官方文档列出了多种支持语言,例如 Python、Java、JavaScript、TypeScript、C、C++、Markdown、HTML、LaTeX 等;这些语言预设会尽量在类、函数、控制流等结构附近切分,使代码块更符合程序逻辑
语义分块 SemanticChunker:
语义分块(Semantic Chunking)是一种更智能的切分方法,它不只依赖字符数或固定分隔符,而是尝试在语义主题发生明显变化的地方切开文本;这样得到的每个块往往具有更强的内部语义一致性
LangChain 提供了实验性的 SemanticChunker,该组件位于 langchain_experimental.text_splitter 模块中,使用前需要额外安装 LangChain 实验扩展包;因为它依赖嵌入模型计算句子之间的语义距离,所以速度通常慢于字符分块,成本也更高
bash
pip install langchain_experimentalSemanticChunker 的工作流程可以概括为五步:
第一步 句子切分:先按句子规则把文本拆成句子列表
第二步 上下文感知嵌入:通过 buffer_size 把每个句子与前后若干句子组合后再做嵌入,让句子向量包含局部上下文
第三步 语义距离计算:计算相邻句子嵌入向量之间的余弦距离
第四步 断点识别:根据统计方法识别语义距离明显变大的位置
第五步 合并成块:按断点把句子序列合并为语义更连贯的文本块
SemanticChunker 支持多种断点识别方法,可以通过 breakpoint_threshold_type 设置:
| 方法 | 含义 | 适用理解 |
|---|---|---|
| percentile | 百分位法,默认方法 | 只把语义差异最大的少数位置作为断点 |
| standard_deviation | 标准差法 | 把超过平均值若干倍标准差的位置视为异常跳跃 |
| interquartile | 四分位距法 | 用 IQR 识别语义差异异常值 |
| gradient | 梯度法 | 关注语义差异变化率,适合语义整体较平稳但局部有拐点的文本 |
python
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_experimental.text_splitter import SemanticChunker
# 创建文本嵌入模型,用于把句子转换成向量
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
)
# 创建语义切分器
# 它会先按句子拆分文本,再根据句子之间的语义关系决定在哪里切块
text_splitter = SemanticChunker(
embeddings=embeddings, # 使用上面的嵌入模型做语义判断
breakpoint_threshold_type="percentile", # 用百分位方法决定切分阈值
sentence_split_regex=r"(?<=[\u3002\uff01\uff1f.!?])\s*", # (正则表达式)按中英文句末标点切句
)
loader = TextLoader("./test.txt", encoding="utf-8")
documents = loader.load()
# 按语义而不是按固定字符数切分文本
chunks = text_splitter.split_documents(documents)
print(f"文本被切分为 {len(chunks)} 个语义块")语义分块适合主题变化明显、段落边界不够可靠、且对检索质量要求较高的文档;它的主要成本是需要调用嵌入模型,并且参数调优比字符分块更复杂
文档结构分块 MarkdownHeaderTextSplitter:
对于结构明确的文档格式,例如 Markdown、HTML、LaTeX,直接利用标题和结构标记进行分块通常更合理;这类方法不是只看文本长度,而是先理解文档的层级结构,再把内容组织成逻辑块
以 Markdown 为例,LangChain 提供了 MarkdownHeaderTextSplitter;它可以按标题层级切分文档,并把标题路径保存到每个块的元数据中;根据当前官方文档,该类同样从 langchain_text_splitters 导入
python
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
# 一段 Markdown 格式的文本示例
markdown_document = """
# 第三章 模型评估
## 2.5 评估指标
准确率、召回率和 F1 是常见评估指标
"""
# 指定要识别哪些 Markdown 标题层级
# 每个元组表示:(Markdown 标记, metadata 中对应的字段名)
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
# 创建 Markdown 标题切分器
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False, # 切分后的文本内容中保留标题本身
)
# 先按 Markdown 标题结构切分
# 返回的是 Document 列表,每个 Document 除了正文还有标题层级 metadata
header_splits = markdown_splitter.split_text(markdown_document)
# 创建递归字符切分器
# 把按标题切好的内容继续按长度切成更小的块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=250, # 每个块的目标最大长度约为 250 个字符
chunk_overlap=30, # 相邻块之间保留 30 个字符重叠
)
# 对按标题切好的文档再次切分
chunks = text_splitter.split_documents(header_splits)
print(f"文本被切分为 {len(chunks)} 个块") # 1
for chunk in chunks:
print(chunk.page_content) # 每个块的文本内容
print(chunk.metadata) # 每个块的 metadata
# {'Header 1': '第三章 模型评估', 'Header 2': '2.5 评估指标'}这个流程可以理解为两阶段分块:第一步使用 MarkdownHeaderTextSplitter 按标题结构形成较大的逻辑块,并给每个块写入标题元数据;第二步再使用 RecursiveCharacterTextSplitter 控制块大小,让最终块既保留文档结构,又满足检索和模型输入长度要求
标题元数据非常有价值;例如某个段落位于 "第三章 模型评估" 下的 "2.5 评估指标" 中,分块后它的元数据可以记录 {"Header 1": "第三章 模型评估", "Header 2": "3.2 评估指标"};这样模型在回答问题时不仅能看到局部内容,还能知道内容来自哪个章节背景
这种结构化分块特别适合技术文档、产品手册、政策文件、课程讲义和知识库文章;它的局限是依赖文档本身结构质量,如果原始 Markdown 标题混乱或层级不清,分块效果也会受到影响
其他框架的分块策略:
Unstructured 元素分块:
Unstructured 也提供了实用的文档分块能力;它的思路与普通文本分块不同,不是先把文档变成纯文本再按字符切,而是先通过分区(Partitioning)把 PDF、HTML、Word 等文档解析成一组结构化元素,再在元素列表上进行分块
Unstructured 官方文档强调,分块是在文档元素上执行的;通常会把连续元素组合成尽可能接近目标大小的块;如果单个元素本身超过最大块大小,才会对该元素进行文本切分;这种做法能尽量保留标题、段落、列表、表格等语义单元的完整性
Unstructured 主要提供两类分块策略:
| 策略 | 说明 | 适用场景 |
|---|---|---|
| basic | 默认策略,连续组合元素直到接近 max_characters;如果单个元素过长,则拆分该元素 | 通用文档处理 |
| by_title | 在 basic 基础上增加章节感知,遇到 Title 元素时开启新块 | 报告、书籍、论文、结构化文档 |
Unstructured 支持在分区时直接指定分块策略,也支持先分区再调用分块函数;前者流程更简洁,后者更适合调参
python
from unstructured.partition.html import partition_html
# 解析网页,并在解析时直接完成切块
chunks = partition_html(
url="https://2778.com", # 要解析的网页地址
chunking_strategy="by_title", # 按标题结构切块,尽量保持语义完整
max_characters=1000, # 每个块的最大字符数上限
new_after_n_chars=800, # 块内容达到约 800 字符后,倾向于开始新块
)这种先理解再分割的策略,让 Unstructured 在处理版式复杂文档时更有优势;尤其是 PDF、报告、网页、扫描件和包含表格的资料,通常比普通纯文本切分更稳定
LlamaIndex 节点解析:
LlamaIndex 将数据处理流程抽象为节点(Node)操作:文档被加载后,会被解析成一系列节点,分块只是节点转换(Transformation)中的一环;这种设计让 LlamaIndex 更强调数据结构、元数据和索引之间的关系
LlamaIndex 的节点解析器大致可以分为三类:
- 结构感知型:例如 MarkdownNodeParser、JSONNodeParser、CodeSplitter,适合按 Markdown 标题、JSON 结构或代码函数切分
- 语义感知型:例如 SemanticSplitterNodeParser,会使用嵌入模型检测句子之间的语义断点;SentenceWindowNodeParser 会把文档切成句子节点,并在元数据中保留前后相邻句子的窗口
- 常规型:例如 TokenTextSplitter、SentenceSplitter,适合按 token 数量或句子边界进行常规切分
SentenceWindowNodeParser 是一个很有代表性的设计:它先用单个句子做精确检索,再把句子附近的上下文窗口一起送给 LLM;这样既能提升检索精度,又能让生成阶段拿到足够上下文
LlamaIndex 还支持灵活的转换流水线;例如可以先用 MarkdownNodeParser 按章节切分,再对章节节点使用 SentenceSplitter 做更细粒度切分;每个节点都会携带来源和上下文元数据,方便后续检索、溯源和调试
另外,LlamaIndex 提供了 LangchainNodeParser,可以把 LangChain 的 TextSplitter 封装成 LlamaIndex 的节点解析器,这让两套生态之间具备较好的互操作性
ChunkViz 可视化工具:
ChunkViz 是一个简单直观的可视化分块工具;本章开头展示的分块图就是通过 ChunkViz 生成的;它可以把文档和分块配置作为输入,用不同颜色展示每个 chunk 的边界和重叠部分,方便观察分块是否过大、过碎或重叠不合理
对于新手来说,ChunkViz 的价值在于把抽象的分块参数变成可见结果;当你修改 chunk_size、chunk_overlap 或分隔符时,可以直观看到块边界如何变化,从而更容易理解不同策略的效果