千斤重的承诺,轻如鸿毛的道歉,
请你都别在开口,你我都无法承受;
------ 26.5.25
前言
DeepSpeed是一个针对PyTorch的优化工具。它旨在加快训练速度和减小模型的内存占用。DeepSpeed通过一系列优化技术,如模型并行和梯度累计,来提高训练速度。此外,DeepSpeed还提供了内存优化的功能,能够有效地减小模型在GPU/NPU上的内存占用。
一、DeepSpeed简介
DeepSpeed是一个由微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。
DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。
此外,DeepSpeed基于PyTorch构建,只需要简单修改即可迁移。DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言型、图像分类、目标检测等等。
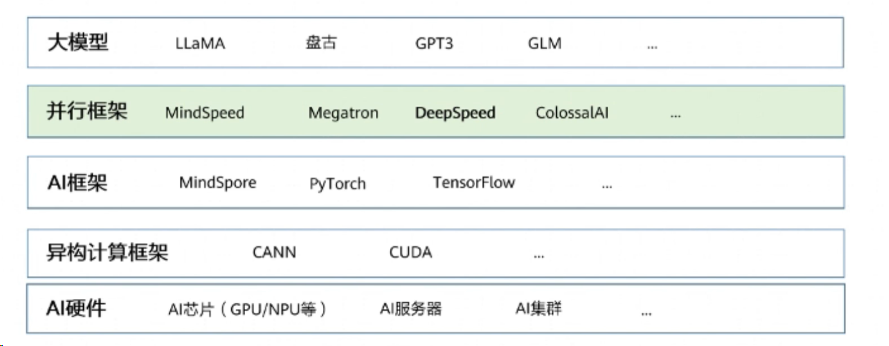
二、深度学习模型软件体系架构
DeepSpeed作为一个大模型训练加速库,位于模型训练框架和模型之间,用于提升训练、推理等。
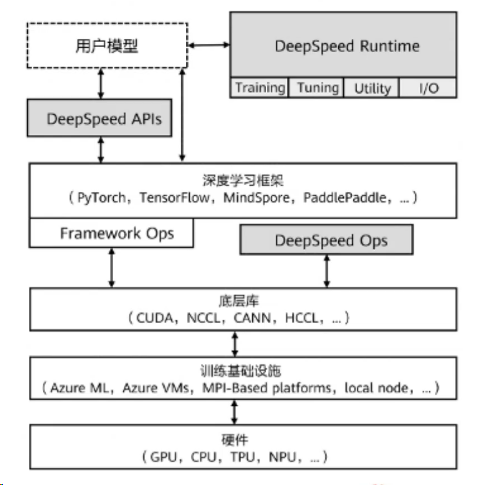
三、DeepSpeed软件架构
1.DeepSpeed主要包含三部分:
**APIS:**提供易用的api接口,训练模型、推理模型只需要简单调用几个接口即可。其中最重要的是initialize接口,用来初始化引擎,参数中配置训练参数及优化技术等。配置参数一般保存在config.json文件中。
**Runtime:**运行时组件,是DeepSpeed管理、执行和性能优化的核心组件。如部署训练任务到分布式设备、数据分区、模型分区、系统优化、微调、故障检测、checkpoints保存和加载等。该组件使用python语言实现。
**Ops:**用C++和cuda实现底层内核,优化计算和通信,提供了一系列底层操作等。
2.架构优势
可以在训练框架上进行两部分(训练和推理分开)优化。
与紧密耦合的结构比,该结构可以更好的利用整个生态,且与深度集成相比,更容易维护。
与基础设置无关,用户可以选择喜欢的平台,如Azure ML、Azure VMs等。
四、DeepSpeed核心技术
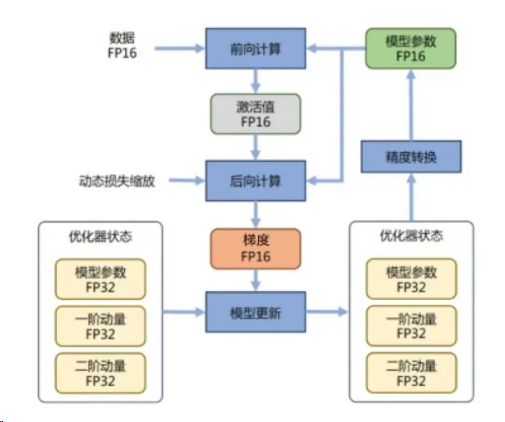
1.混合精度训练
混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型。在使用混合精度训练时,需要使用一些技术来解决可能出现的梯度消失和模型不稳定的问题,例如动态精度缩放和混合精度优化器等。
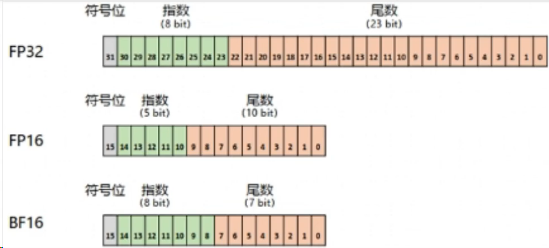
2.BF16
BF16和FP16都是半精度浮点数格式,主要区别如下:
BF16:
可以表示更广的数值范围。但尾数只有7位,所以精度较低。
更适合深度学习领域,可以减少模型大小,加速计算,同时保持足够的精度。
Ampere架构的Tensor Core支持BF16。
FP16:
数值范围窄,但尾数有10位,精度较高。
更适合图形渲染等需要高精度的场景。
大多数GPU架构都支持。
3.混合精度优化过程
DeepSpeed提供了混合精度训练的支持,在训练过程中,DeepSpeed会自动将一部分操作转换为FP16格式,并根据需要动态调整精度缩放因子,从而保证训练的稳定性和精度。
4.分布式并行
为什么需要分布式并行?
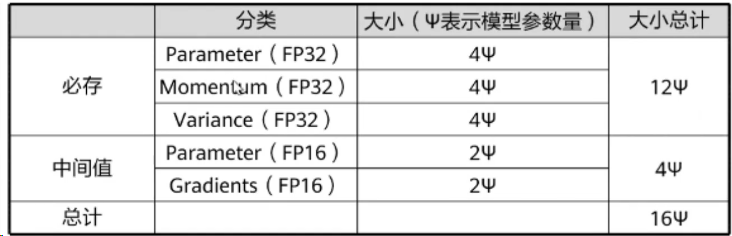
模型在训练过程中需要储存自身的参数和梯度,这便需要2x+2x的内存,同时混合精度FP32训练时,Adam需要一份FP32大小的模型拷贝,momentum和variance去储存模型的优化器状态,这需要4x+4x+4x,最终我们需要16x的内存用于训练,即对于一个GPT-2模型,我们训练时需要24GB的内存,对比一张V100的显存为32GB。
分布式模型训练
大模型在训练时往往需要大量内存来存储中间激活、权重等参数,百亿模型甚至无法在单个GPU上进行训练,使得模型训练在某些情况下非常低效和不可能。这就需要进行多卡,或者多节点分布式训练。
分布式并行的核心思想是把计算和存储分散到不同的设备。**【分而治之】**大规模深度学习模型训练主要范式:
数据并行(Data Parallelism,DP)
模型并行(Model Parallelism,MP)
混合并行(Hybrid Parallelism,HP)
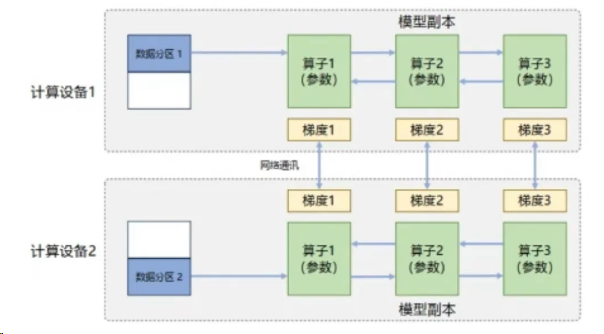
5.数据并行
在数据并行系统中,每个计算设备都有整个神经网络模型的完整副本,进行迭代时,每个计算设备只分配了一个批次数据样本的子集,并根据该批次样本子集的数据进行网络模型的前向和反向计算。
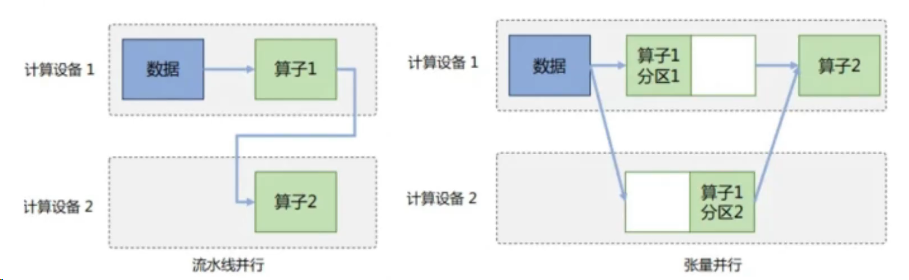
6.模型并行
模型并行往往用于解决单节点内存不足的问题。模型并行可以从计算图角度,以下两种形式进行切分:按模型的层切分到不同设备,即层间并行或算子间并行,也称之为流水线并行(Pipeline Parallelism,PP);将计算图层内的参数切分到不同设备,即层内并行或算子内并行,也称之为张量并行(Tensor Parallelism,TP)。
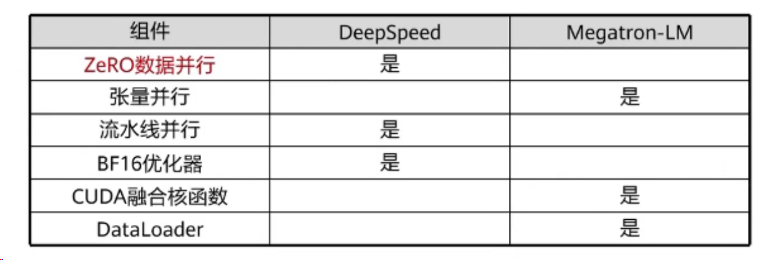
7.DeepSpeed vs Megatron
目前训练超大规模语言模型技术路线:PyTorch+Megatron-LM+DeepSpeed。
176B BLOOM模型使用Megatron-DeepSpeed进行训练,下表列出了在训练BLOOM时各采用了两个框架的哪些组件:
⭐8.ZeRO(零冗余优化器)
ZeRO(Zero Redundancy Optimizer)是一种用于优化大规模深度学习模型训练的技术。它的主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
ZeRO是一系列显存优化方法的统称,它分为:
ZeRO-DP
ZeRO-R
ZeRO-Offload
ZeRO-Infinity
显存占用分析
ZeRO首先分析了模型训练中内存主要消耗在两个方面:
Model States:模型本身相关且必须存储的内容,包括:
Parameters:模型参数
Gradients:模型梯度
Optimizer States:Adam优化算法中的momentum和variance
Residual States:非模型本身必须,但在训练过程中产生的内容,包括:
Activation:激活值
Temporary Buffers:临时存储
Unusable Fragmented Memory:碎片化存储空间
ZeRO分别使用ZeRO-DP和ZeRO-R来优化ModelStates和Residual States。
9.ZeRO-DP
ZeRO-DP包括三个阶段:
**ZeRO-1:**优化器状态切分(Pos),切分优化器状态到各个计算卡中,占用内存为原始的1/4,通信容量与数据并行相同。
**ZeRO-2:**添加梯度切分(Pos+g),在Pos的基础上,进一步将模型梯度切分到各个计算卡中占用内存为原始的1/8,通信容量与数据并行相同。
**ZeRO-3:**添加参数切分(Pos+g+p),在Pos+g的基础上,将模型参数也切分到各个计算卡中内存减少与数据并行度和复杂度成线性关系,同时通信容量是数据并行的1.5倍。
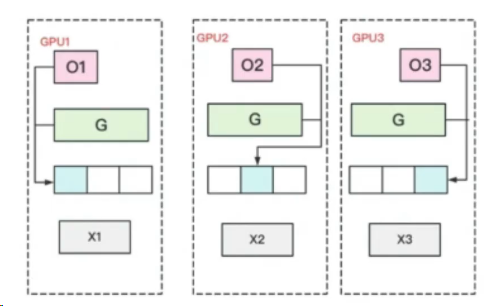
ZeRO-1优化器状态切分
流程:
每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮forward和backward后,各得一份梯度。
对梯度做一次AllReduce,得到完整的梯度G。
得到完整梯度G,就可以对W做更新。我们知道W的更新由Optimizer States和梯度共同决定。由于每块GPU上只保管部分Optimizer States,因此只能将相应的W(蓝色部分)进行更新。
此时,每块GPU上都有部分W没有完成更新(图中白色部分)。所以我们需要对W做一次All-Gather,从别的GPU上把更新好的部分W取回来。
ZeRO-2优化器状态与梯度切分
流程:
每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮forward和backward后,算得一份完整的梯度(下图中绿色+白色)。
对梯度做一次Reduce-Scatter,保证每个GPU上所维持的那块梯度是聚合梯度。例如对GPU1,它负责维护G1,因此其他的GPU只需要把G1对应位置的梯度发给GPU1做加总就可。汇总完毕后,白色块对GPU无用,可以从显存中移除。
每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次AIl-Gather,将别的GPU算好的W同步到自己这来。
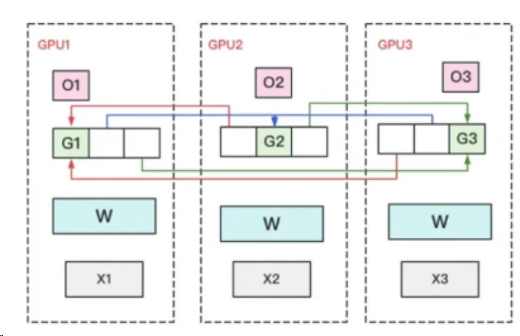
ZeRO-3优化器状态、梯度与参数切分
每块GPU上只保存部分参数W。将一个batch的数据分成3份,每块GPU各吃一份.
做forward时,对W做一次All-Gather,取回分布在别的GPU上的W,得到一份完整的W。forward做完,立刻把不是自己维护的W抛弃。
做backward时,对W做一次All-Gather,取回完整的W。backward做完,立刻把不是自己维护的W抛弃。
做完backward,算得一份完整的梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度。聚合操作结束后,立刻把不是自己维护的G抛弃。
用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何AllReduce操作。
10.ZeRO VS 模型并行
问题:既然ZeRO都把参数W给切了,那它应该是个模型并行呀?为什么要归到数据并行里呢?
其实ZeRO是模型并行的形式,数据并行的实质。
模型并行,是指在forward和backward的过程中,只需要用自己维护的那块W来计算就行。即同样的输入X,每块GPU上各算模型的一部分,最后通过某些方式聚合结果。
但对ZeRO来说,它做forward和backward的时候,是需要把各GPU上维护的W聚合起来的,即本质上还是用完整的W进行计算。它是不同的输入X,完整的参数W,最终再做聚合。
11.ZeRO-R
在ZeRO-DP提高了模型状态内存效率之后,主要消耗在激活值、临时缓冲区以及无法使用的内存碎片这三个方面的剩余内存成为次要的内存瓶颈。为了解决这个问题,我们开发了ZeRO-R来进行优化:
通过激活值分区(Partitioned Activation Checkpointing)来优化激活值内存。
**Activation Checkpointing:**前向计算时,只保留部分算子的激活值。反向更新时,需要其他算子的激活值时,再重新对其进行前向计算,得到其激活值。
恒定临时缓冲区大小,以在内存和计算效率之间取得平衡。
根据张量的不同生命周期来管理内存,以防止内存碎片化。
12.ZeRO-Offload和ZeRO-Infinity
ZeRO-Offload通过将数据和计算卸载到CPU来实现大规模模型训练(包括模型参数、梯度和优化器状态等模型状态),ZeRO-Offload能够在单个GPU上训练具有超过130亿参数的模型。ZeRO-Offload的做法是:
forward和backward计算量高,因此和它们相关的部分,例如Parameters,Activation等,就全放入GPU。
update的部分计算量低,因此和它相关的部分,全部放入CPU中。例如OptimizerStates和Gradients等。
ZeRO-Infinity是ZeRO-3的拓展。允许通过使用NVMe固态硬盘扩展GPU和CPU内存来训练大型模型。ZeRO-Infinity需要启用ZeRO-3。
四、DeepSpeed使用介绍
1.安装DeepSpeed
DeepSpeed有两种安装方式:pip安装和本地构建
pip安装(推荐):
bash
# 两种方式任选其一
pip install deepspeed # 安装deepspeed库
pip install transformers[deepspeed] # 通过transformers的extras选项安装本地构建:
pip安装通常会使用默认配置,适合绝大多数用户。如果您需要自定义DeepSpeed的配置,比如修改全局配置文件或在代码中进行相应的配置更改,可以克隆DeepSpeed项目到本地来自定义构建。
2.启动DeepSpeed
**使用PyTorch启动器:**保持PyTorch的训练流程,只在其中使用DeepSpeed的一些配置文件和设置来改进训练速度和内存效率。好处是更容易集成到现有的PyTorch代码中,因为它不需要你改变整个训练流程。
bash
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json**便用DeepSpeed提供的后动器:**DeepSpeed提供了目己的后动器,它是一个独立的命令行工具,用于配置和启动DeepSpeed训练。这种方式适用于需要更高度自定义控制的情况,可以轻松在不同环境中部署。
bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json3.使用DeepSpeed启动训练 - 命令行参数配置
命令行参数是一些经常需要更改的、运行时可灵活配置的参数。可以通过Deepspeed的add_config_arguments来添加这些参数,以便在命令行调用。例如:
python
import deepspeed
import argparse
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description="GPT-2 Training Script")
#使用DeepSpeed的add conflg_arquments添加DeepSpeed配置参数
deepspeed.add config arguments(parser)
# 添加其他训练参数
parser.add argument("--model name _or_path", type=str, default="gpt2", help="Model name or path")
parser.add_argument("--per_device_train _batch_size", type=int, default=4, help="Batch size per device")
args = parser.parse _args()
# 使用DeepSpeed配置参数初始化DeepSpeed引擎
model, optimizer,_= deepspeed.initialize(model=your_gpt2_model, optimizer=your optimizer.model_parameters-your model parameters, training_data=your_data_loader,config_params=args)在上面的示例中,您可以在命令行中指定DeepSpeed的配置参数:
python
deepspeed train_gpt2.py --deepspeed ds_config_stage3.json --model_name_or_path gpt2-medium --per_device_train_batch_size 24.使用DeepSpeed启动训练 - json配置文件
上述命令行中的ds_config_stage3.json就是DeepSpeed的配置文件,通常用于设置较为复杂的优化策略,例如ZeRO的阶段配置、分层参数分组等,一般不会经常修改。比如你要进行DeepSpeed ZeRO Stage 3的训练,其训练优化配置就可以写在一个json文件中,例如:
python
'''
{
"zero optimization":{
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
}
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce bucket size": "auto",
"stage3 _prefetch_bucket_size": "auto",
"stage3 param persistence threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3 _gather_16bit weights_on_model save": true
}
}
'''5.使用DeepSpeed启动训练 - 多GPU部署
以下是用DeepSpeed运行run_translation.py并使用所有GPU进行部署的示例,在run_translation.py中我们配置了更多的命令行参数:
bash
# 运行DeepSpeed示例脚本
deepspeed examples/pytorch/translation/run_translation.py
--do_train \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small \
--per_device_train_batch_size 1 \
--output_dir output_dir \
--overwrite_output_dir \
--fp16 \
--max_train_samples 500 \
--num_train_epochs 1 \
--dataset_name wmt16 \
--dataset_config "ro-en" \
--source_lang en \
--target_lang ro6.使用DeepSpeed启动训练 - 单GPU部署
如果是使用一个GPU部署DeepSpeed,只需要设置 --num_gpus=1,明确告诉DeepSpeed仅使用一个GPU。
bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
......如果要在GPU0之外的特定GPU上运行,可以运行以下代码:
bash
#使用GPU1(第二个 GPU)进行训练
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py \7.使用DeepSpeed启动训练 - 多节点部署
假设有2个节点,每个节点有8个GPU,你可以分别使用ssh hostname1和ssh hostname2来访问这两个节点,且两者都必须能够通过本地ssh相互访问而无需密码。
要使用deepspeed启动器,必须首先创建一个hostfile文件:
bash
hostname1 slots=8
hostname2 slots=8然后执行以下代码:
bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.jsondeepspeed将在两个节点上自动启动此命令
8.使用transformers启动训练
Huggingface的transformers库已经集成了DeepSpeed功能,你可以使用两种方式来调用:
**Trainer调用:**transformers的Trainer类已经集成了DeepSpeed,你可以直接传递DeepSpeed配置参数来启用DeepSpeed功能,而无需太多自定义配置。
**自定义集成DeepSpeed:**如果你想要更大的自由度和自定义控制流程,也可以不使用Trainer,而是手动集成Deepspeed。对此,transformers库仍然提供了一些功能,如from_pretrained和from_config,你只需要按照相关文档进行配置。
具体来说,transformers集成了DeepSpeed ZeRO training和DeepSpeed ZeRO Inference:
**Deepspeed ZeRo training:**通过 ZeRO-Infinity(CPU 和 NVME 卸载)支持完整的 ZeRO stages 1,2 and 3 。
**DeepSpeed ZeRO Inference:**与训练不同,推理时只需要做前向传播,所以不需要优化器、lr调度器和梯度。DeepSpeedZeRO Inference只使用ZeRO stage 3(参数划分),专注于模型的前向传播,这使得推理更轻量且更快速
使用Trainer启动DeepSpeed训练示例
python
import torch
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
TrainingArguments,
Trainer
)
from datasets import load_dataset
# 1. 加载模型&分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 2. 加载测试数据集
dataset = load_dataset("glue", "mrpc")
def tokenize_fn(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_fn, batched=True)
# 3. 核心:TrainingArguments 加入 deepspeed 配置
training_args = TrainingArguments(
output_dir="./bert_model",
overwrite_output_dir=True,
num_train_epochs=2,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
save_steps=1000,
logging_steps=500,
save_total_limit=2,
learning_rate=5e-5,
lr_scheduler_type="cosine",
deepspeed="ds_config.json", # 指定DeepSpeed配置文件
fp16=True, # 混合精度加速(GPU必须开)
)
# 4. 初始化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
)
# 5. 训练+保存+推理
if __name__ == "__main__":
trainer.train() # 启动DeepSpeed训练
trainer.save_model("./final_model") # 保存模型
results = trainer.predict(tokenized_dataset["test"]) # 推理
print("推理结果:", results)DeepSpeed配置
零冗余优化器(ZeRO)是DeepSpeed库的主要功能,它支持3个不同阶段的优化。通常情况下,不同阶段的配置信息被保存在一个JSON文件中,并通过命令行接口传递给训练脚本,例如:
python
TrainingArguments(.. deepspeed="/path/to/ds_config.json")你可以在DeepSpeedExamples存储库中找到数十个可满足各种实际需求的DeepSpeed配置示例:
python
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find .-name '*json'共享配置
在使用Trainer 和DeepSpeed进行深度学习训练时,有一些注意事项:
共享配置值: 有些配置值在Trainer和DeepSpeed中都需要,为了避免配置值的冲突,从而导致难以检测的错误,应该通过Trainer的命令行参数来配置这些共享的值,确保二者的配置值一致。
自动配置值: 有些配置值可以根据模型的配置自动计算,而无需手动设置(例如scheduler.params.total_num_steps),这种自动配置值就是"auto"。当设为"auto"时,Trainer会将其自动替换为正确或最有效的值,这能减少手动配置的复杂性和错误的可能性。
DeepSpeed-only: 有一些配置值只在DeepSpeed中使用的,它们需要手动设置,例如zero_optimization
zero_optimization: 配置文件的zero_optimization部分是最重要的,它定义了要启用ZeRO的哪些阶段以及如何配置它们。所以这部分内容是DeepSpeed-only,你无法通过Trainer来设置。
9.ZeRO stage 0 和 ZeRO stage 1
stage 0会禁用所有的分片,即把DeepSpeed当作是Pytorch DDP来使用。
python
{
"zero_optimization": {
"stage": 0
}
}stage 1仅对优化器状态进行分片,可以尝试它来稍微加快速度。
python
{
"zero optimization":{
"stage": 1
}
}10.ZeRO stage 2
下面是一个完整的stage 2配置文件,包括优化器状态卸载到CPU、使用AdamW优化器和 WarmupLR调度器,并使用--fp16来启动混合精度训练:
python
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 1e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 10
}11.ZeRO stage 3 CPU Offload
如果你拥有大量的CPU内存可用,你可以选择只将它们卸载到CPU内存,因为这可能会更快。以下是stage 3完整配置:
python
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 1e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1e8,
"contiguous_gradients": true,
"stage3_prefetch_bucket_size": 1e8,
"stage3_param_persistence_threshold": 1e5,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 10
}12.NVMe Support
deepspeed支持ZeRO-Infinity技术,该技术通过利用NVMe存储器来扩展GPU和CPU的内存,即使用NVMe存储器来存储模型的参数和优化器状态,以减轻内存压力,从可以处理更大的模型和数据集。以下是使用NVMe卸载优化器状态和参数的stage3配置:
python
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme", // 优化器状态卸载到 NVMe 硬盘
"nvme_path": "./nvme_offload", // 硬盘缓存文件夹(自动创建)
"pin_memory": false
},
"offload_param": {
"device": "nvme", // 模型参数卸载到 NVMe 硬盘
"nvme_path": "./nvme_offload",
"pin_memory": false
},
"allgather_partitions": true,
"allgather_bucket_size": 1e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1e8,
"contiguous_gradients": true,
"stage3_prefetch_bucket_size": 1e8,
"stage3_param_persistence_threshold": 0,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"sub_group_size": 1e9
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 10
}13.ZeRO策略选择总体原则
通常,以下规则适用:
速度方面(左边比右边快):
stage 0(DDP) > stage 1 > stage 2 > stage 2 + offload > stage 3 > stage3 + offload
GPU内存使用方面(右边比左边更节省GPU内存):
stage 0(DDP) < stage 1 < stage 2 < stage 2 + offload < stage 3 < stage 3 + offload
所以,当你希望在尽量使用较少数量的GPU的同时获得最快的执行速度时,可以按照以下步骤进行。我们从最快的方法开始,如果遇到GPU内存溢出,然后切换到下一个速度较慢但使用的GPU内存更少的方法,以此类推。
14.ZeRO策略选择具体步骤
设置初始条件:
首先将batch size设为1。
启用梯度累积,可以实现任意的有效batchsize。
首先尝试stage 2。
如果OOM(Out Of Memory,内存溢出),则启用梯度检查点(Gradient Checkpointing)功能。你可以通过设置--gradient_checkpointing 1来启用此功能,或者在模型中直接使用model.gradient_checkpointing_enable()方法。继续检查GPU内存,如果没有出现OOM,则可以继续提高batchsize,否则逐步尝试以下阶段。
如果OOM,尝试stage2+offload_optimizer。
如果OOM,尝试ZeRO stage 3.
如果OOM,尝试offload_param到CPU。
如果OOM,尝试offload_optimizer到CPU。
如果OOM,则尝试降低一些默认参数。比如使用generate时,减小beam search的搜索范围,或者是启用混合精度训练。
如果仍然OOM,则使用ZeRO-Infinity,offload_param和offload_optimizer到NVMe。
优化配置:
一旦某个阶段使用batch size=1时,没有导致OOM,可以优化以下参数:
尽可能增大batch size。
关闭一些offload功能,或者降低ZeRO stage。
继续调整batch_size,测量吞吐量,直到性能比较满意(调参可以增加66%的性能)。
15.内存估算
可以通过下面的代码,先估算不同配置需要的显存数量,从而决定开始尝试的ZeRO stage
python
def estimate_deepspeed_memory(
model_params_b: float, # 模型参数,单位 B(例如 7B、13B、34B)
zero_stage: int = 3, # ZeRO 1/2/3
optimizer: str = "adamw", # adamw | sgd
offload_optimizer: str = "none", # none | cpu | nvme
offload_param: str = "none", # none | cpu | nvme (仅stage3有效)
dtype: str = "fp16", # fp16 / fp32
micro_batch_size: int = 1, # 单卡batch size
grad_accum_steps: int = 1, # 梯度累积
include_activation: bool = True
):
"""
DeepSpeed ZeRO 显存估算(单位:GB)
"""
params = model_params_b * 1e9
dtype_bytes = 2 if dtype == "fp16" else 4
# --------------------------
# 1. 模型本身
# --------------------------
model_mem = params * dtype_bytes / 1e9
# --------------------------
优化器状态(AdamW占 8 字节/参数)
# --------------------------
if optimizer == "adamw":
opt_per_param = 8 # FP16/FP32 统一按 8 字节估算(moment + var)
else:
opt_per_param = 4
opt_total_mem = params * opt_per_param / 1e9
# --------------------------
# ZeRO 分布策略
# --------------------------
if zero_stage == 1:
opt_per_gpu = opt_total_mem
model_per_gpu = model_mem
elif zero_stage == 2:
opt_per_gpu = opt_total_mem
model_per_gpu = model_mem
elif zero_stage == 3:
opt_per_gpu = opt_total_mem
model_per_gpu = model_mem / 1 # ZeRO3 不常驻GPU
else:
opt_per_gpu = opt_total_mem
model_per_gpu = model_mem
# --------------------------
# 卸载优化器
# --------------------------
if offload_optimizer in ["cpu", "nvme"]:
opt_per_gpu = 0.0
# --------------------------
# 卸载参数(仅ZeRO3)
# --------------------------
if zero_stage == 3 and offload_param in ["cpu", "nvme"]:
model_per_gpu = 0.0
# --------------------------
# 梯度(和模型同精度)
# --------------------------
grad_per_gpu = params * dtype_bytes / 1e9
if zero_stage >= 2:
grad_per_gpu /= 1
# --------------------------
# 激活值显存(经验公式:大模型通用)
# --------------------------
act_mem = 0.0
if include_activation:
act_mem = 0.06 * model_params_b * micro_batch_size
# --------------------------
# 总计
# --------------------------
total = model_per_gpu + opt_per_gpu + grad_per_gpu + act_mem
print("=" * 60)
print(f" DeepSpeed 显存估算 | 模型 {model_params_b}B | ZeRO Stage {zero_stage}")
print("=" * 60)
print(f" 模型参数 : {model_per_gpu:.2f} GB")
print(f" 优化器状态 : {opt_per_gpu:.2f} GB")
print(f" 梯度 : {grad_per_gpu:.2f} GB")
print(f" 激活值 : {act_mem:.2f} GB")
print("-" * 60)
print(f" 🎯 单卡总显存预估 : {total:.2f} GB")
print("=" * 60)
return total
# ==============================
# 你只需要改这里!
# ==============================
if __name__ == "__main__":
estimate_deepspeed_memory(
model_params_b=7, # 7B 模型
zero_stage=3, # ZeRO 3
optimizer="adamw",
offload_optimizer="nvme", # none / cpu / nvme
offload_param="nvme", # none / cpu / nvme (stage3 only)
dtype="fp16",
micro_batch_size=1,
grad_accum_steps=8,
include_activation=True
)16.Huggingface预训练模型启用DeepSpeed训练
如果你想使用Huggingface Transformers库中的预训练模型来进行DeepSpeed训练,要确保在创建模型之前设置了DeepSpeed配置。具体来说,需要先创建一个TrainingArguments对象(training_args),并在其中指定包括DeepSpeed配置(ds_config)在内的训练参数。然后再加载预训练模型,最后创建Trainer对象,加载模型传递训练参数,开始训练。整个顺序如下所示:
python
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("t5-smal!")
trainer = Trainer(model=model, args=training_args, ...)17.DeepSpeed推理
推理时只需要做前向传播,所以不需要优化器、lr调度器和梯度,所以只使用ZeRO stage 3(参数划分),这使得推理更轻量且更快速。另外正因为不需要优化器、lr调度器和梯度,内存需求减少,推理时可以使用更大的batchsize和更长的序列长度。
bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json18.总结
本章内容围绕并行训练框架DeepSpeed展开详细介绍,首先介绍了DeepSpeed的软件架构和核心技术,包括混合精度训练、ZeRO(零冗余优化器)等;然后介绍了DeepSpeed的使用方法,包括DeepSpeed安装、DeepSpeed启动、DeepSpeed配置文件等;最后介绍了如何选择DeepSpeed最佳配置策略,以及内存估算、模型训练和推理的实践方法。