1. 作者介绍
邓璎珈,女 西安工程大学电子信息学院,2025级研究生。
研究方向:机器视觉与人工智能。
电子邮件:1823143791@qq.com
2. 高斯混合模型理论介绍
2.1 高斯混合模型的基本思想
高斯混合模型(Gaussian Mixture Model,GMM)是一种基于概率分布的聚类方法。该模型认为样本数据并非来自单一分布,而是由若干个高斯分布共同生成。每一个高斯分布可被理解为一个潜在类别,模型通过估计不同高斯分布的均值、协方差和混合权重,进一步判断样本更可能属于哪一个聚类成分。
与 K-Means 等硬聚类方法相比,GMM 的特点在于"软聚类"。K-Means 通常直接将样本划分到某一类别,而 GMM 会计算样本属于各个聚类成分的概率,再根据最大概率输出最终类别。因此,GMM 更适合处理类别边界不完全清晰、样本分布存在交叉的聚类任务。
2.2 EM算法与主要参数
GMM 通常采用 EM 算法进行参数估计。E 步用于估计每个样本属于不同高斯成分的概率,M 步则根据这些概率更新各成分的均值、协方差和权重。经过多次迭代后,模型逐渐收敛并形成较稳定的聚类结果。
|-----------------|------------------------------|------------------------|
| 参数 | 含义 | 本实验设置 |
| n_components | 设置高斯混合模型的聚类成分数量,即最终希望识别的类别数。 | 设置为3,对应鸢尾花数据集的三类结构。 |
| covariance_type | 设置协方差矩阵形式,影响模型对数据分布形态的刻画能力。 | 设置为 full,表示使用完整协方差矩阵。 |
| random_state | 固定随机种子,保证实验结果具有可复现性。 | 设置为42。 |
| n_init | 设置模型初始化次数,多次初始化后选择较优结果。 | 设置为10,用于降低单次初始化的不稳定影响。 |
重要说明: n_components 决定"分成几类", n_init 决定"模型尝试初始化几次",二者含义不同。
2.3 聚类评价指标
由于聚类任务属于无监督学习,模型训练时不使用真实类别标签。因此,不能简单依据聚类编号与真实类别编号是否相同来判断模型效果。本实验采用 ARI、NMI 和轮廓系数进行综合评价。
|-----------------|-----------------------|---------------------|
| 指标 | 作用 | 解释方向 |
| ARI 调整兰德指数 | 衡量聚类结果与真实类别之间的一致程度。 | 越接近1,说明聚类结果越接近真实类别。 |
| NMI 标准化互信息 | 衡量聚类结果与真实类别之间共享信息的程度。 | 越接近1,说明两者一致性越强。 |
| Silhouette 轮廓系数 | 衡量类内紧密程度和类间分离程度。 | 通常越高表示聚类结构越清晰。 |
3. GMM鸢尾花数据集聚类实验
3.1 数据集与实验环境
本实验使用经典的 Iris 鸢尾花数据集。该数据集共包含150个样本,每个样本包含4个特征,分别为花萼长度、花萼宽度、花瓣长度和花瓣宽度。数据集中原本包含三类鸢尾花,分别为 Setosa、Versicolor 和 Virginica,每类各50个样本。
在实验过程中,真实类别标签不参与GMM模型训练,仅用于后续计算ARI、NMI等评价指标。模型训练主要基于四个数值特征进行无监督聚类。
|--------------|--------------------------------|
| 实验准备 | 说明 |
| Python | 建议使用 Python 3.8 及以上版本。 |
| numpy | 用于数值计算。 |
| pandas | 用于数据表组织与结果保存。 |
| matplotlib | 用于绘制聚类结果图。 |
| scikit-learn | 用于加载鸢尾花数据集、标准化、PCA、GMM建模和指标计算。 |
安装命令:pip install numpy pandas matplotlib scikit-learn
3.2 实验流程
• 加载 Iris 鸢尾花数据集,提取四个特征变量和真实类别标签。
• 使用 StandardScaler 对特征数据进行标准化处理,减少量纲差异对模型估计的影响。
• 使用 PCA 将四维特征降至二维,用于后续可视化展示。
• 构建 GaussianMixture 模型,设置 n_components=3、covariance_type="full"、random_state=42、n_init=10。
• 使用 fit_predict 完成模型训练和聚类预测。
• 使用 ARI、NMI、轮廓系数评价聚类效果,并绘制真实类别图、GMM聚类结果图、聚类类别分布图和 AIC/BIC 图。
3.3 完整实验代码
以下代码为本次实验完整实现代码,包含数据读取、标准化处理、GMM建模、PCA可视化、评价指标计算、结果图片保存和CSV结果保存等步骤。
python
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.mixture import GaussianMixture
from sklearn.metrics import adjusted_rand_score, normalized_mutual_info_score, silhouette_score
# 1. 创建结果保存文件夹
output_dir = "GMM_Iris_Result"
os.makedirs(output_dir, exist_ok=True)
# 2. 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 四个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y_true = iris.target # 真实类别标签,仅用于结果评价
feature_names = iris.feature_names
target_names = iris.target_names
# 转换为 DataFrame,方便查看和保存结果
df = pd.DataFrame(X, columns=feature_names)
df["true_label"] = y_true
df["true_name"] = df["true_label"].map(lambda i: target_names[i])
print("鸢尾花数据集前5行:")
print(df.head())
print("\n数据集基本信息:")
print("样本数量:", X.shape[0])
print("特征数量:", X.shape[1])
print("类别名称:", target_names)
# 3. 数据标准化
# GMM对数据尺度比较敏感,因此先进行标准化处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4. 使用 PCA 降维到二维,方便画图展示
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print("\nPCA两个主成分解释的方差比例:")
print(pca.explained_variance_ratio_)
# 5. 构建并训练高斯混合模型
# n_components=3 表示将数据划分为3个高斯分布成分
# n_init=10 表示模型进行10次初始化并选择较优结果,提高稳定性
gmm = GaussianMixture(
n_components=3,
covariance_type="full",
random_state=42,
n_init=10
)
y_pred = gmm.fit_predict(X_scaled)
df["gmm_cluster"] = y_pred
# 输出每个聚类簇的样本数量
print("\n各聚类簇样本数量:")
print(df["gmm_cluster"].value_counts().sort_index())
print("\nGMM聚类结果前10行:")
print(df[["true_name", "gmm_cluster"]].head(10))
# 6. 聚类效果评价
ari = adjusted_rand_score(y_true, y_pred)
nmi = normalized_mutual_info_score(y_true, y_pred)
silhouette = silhouette_score(X_scaled, y_pred)
print("\n聚类评价指标:")
print("ARI调整兰德指数:", round(ari, 4))
print("NMI标准化互信息:", round(nmi, 4))
print("轮廓系数Silhouette Score:", round(silhouette, 4))
# 7. 绘制真实类别分布图
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_true, s=50)
plt.title("True Labels of Iris Dataset")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.colorbar(label="True Label")
plt.tight_layout()
true_label_path = os.path.join(output_dir, "01_true_labels.png")
plt.savefig(true_label_path, dpi=300)
plt.show()
# 8. 绘制 GMM 聚类结果图
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_pred, s=50)
plt.title("GMM Clustering Results on Iris Dataset")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.colorbar(label="GMM Cluster")
plt.tight_layout()
cluster_path = os.path.join(output_dir, "02_gmm_clustering_result.png")
plt.savefig(cluster_path, dpi=300)
plt.show()
# 9. 绘制真实类别与聚类结果对比图
plt.figure(figsize=(8, 6))
markers = ["o", "s", "^"]
for cluster_id in np.unique(y_pred):
plt.scatter(
X_pca[y_pred == cluster_id, 0],
X_pca[y_pred == cluster_id, 1],
s=60,
marker=markers[cluster_id],
label=f"GMM Cluster {cluster_id}"
)
plt.title("Comparison of GMM Clustering Results")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.legend()
plt.tight_layout()
compare_path = os.path.join(output_dir, "03_gmm_cluster_comparison.png")
plt.savefig(compare_path, dpi=300)
plt.show()
# 10. 使用 AIC/BIC 指标辅助判断聚类数
n_components_range = range(1, 8)
bic_scores = []
aic_scores = []
for n in n_components_range:
model = GaussianMixture(
n_components=n,
covariance_type="full",
random_state=42,
n_init=10
)
model.fit(X_scaled)
bic_scores.append(model.bic(X_scaled))
aic_scores.append(model.aic(X_scaled))
plt.figure(figsize=(8, 6))
plt.plot(list(n_components_range), bic_scores, marker="o", label="BIC")
plt.plot(list(n_components_range), aic_scores, marker="s", label="AIC")
plt.title("AIC and BIC for Different Number of Components")
plt.xlabel("Number of Components")
plt.ylabel("Score")
plt.legend()
plt.tight_layout()
bic_path = os.path.join(output_dir, "04_aic_bic_selection.png")
plt.savefig(bic_path, dpi=300)
plt.show()
# 11. 输出每个样本属于各类别的概率
probabilities = gmm.predict_proba(X_scaled)
prob_df = pd.DataFrame(
probabilities,
columns=["Cluster_0_Probability", "Cluster_1_Probability", "Cluster_2_Probability"]
)
result_df = pd.concat([df, prob_df], axis=1)
result_csv_path = os.path.join(output_dir, "05_gmm_iris_result.csv")
result_df.to_csv(result_csv_path, index=False, encoding="utf-8-sig")
print("\n每个样本属于各聚类的概率前5行:")
print(prob_df.head())
print("\n程序运行完成!")
print("结果文件已保存到文件夹:", output_dir)
print("生成的图片包括:")
print("1. 真实类别图:", true_label_path)
print("2. GMM聚类结果图:", cluster_path)
print("3. 聚类结果对比图:", compare_path)
print("4. AIC/BIC选择聚类数图:", bic_path)
print("5. 聚类结果CSV文件:", result_csv_path)3.4 测试结果与结果分析
修改后模型的主要评价结果为:ARI=0.9039,NMI=0.8997,轮廓系数=0.3742。ARI和NMI均接近1,说明GMM聚类结果与鸢尾花真实类别之间具有较高一致性;轮廓系数相对不高,说明部分类别之间仍存在一定重叠,这与鸢尾花数据集中 Versicolor 和 Virginica 两类样本特征接近的情况一致。
|--------------|--------|--------|--------|
| 模型设置 | ARI | NMI | 轮廓系数 |
| 未设置 n_init | 0.5165 | 0.6571 | 0.4751 |
| 设置 n_init=10 | 0.9039 | 0.8997 | 0.3742 |
从修改前后对比可以看出,加入 n_init=10 后,ARI和NMI明显提高,说明模型结果与真实类别之间的一致性增强。轮廓系数有所下降,并不代表模型整体变差,因为轮廓系数主要反映空间距离结构,而ARI和NMI更能直接反映本实验中"聚类结果是否接近真实三类结构"的目标。
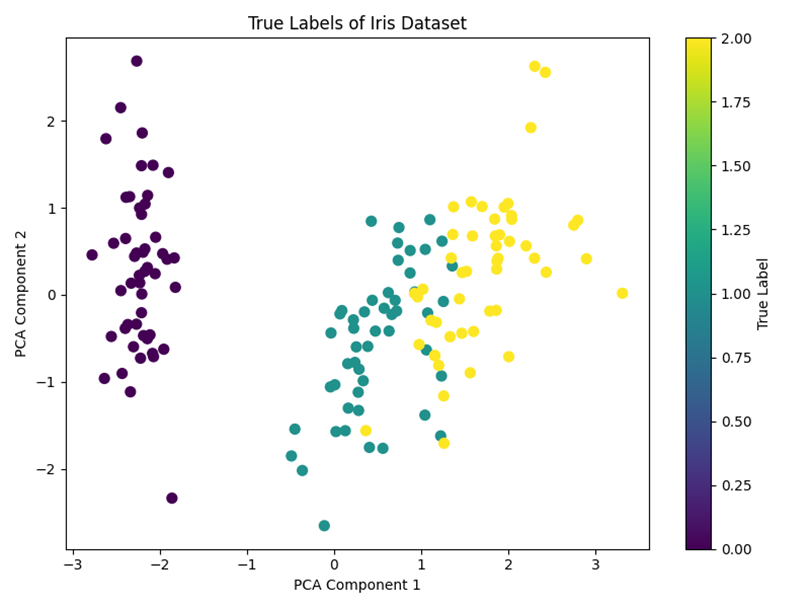
图1 真实类别分布图
该图展示了鸢尾花数据集在PCA降维后的真实类别分布情况。左侧类别与另外两类之间区分较为明显,说明该类别具有较强的特征辨识度;右侧两类样本之间存在一定交叉,表明部分类别边界并不完全清晰。
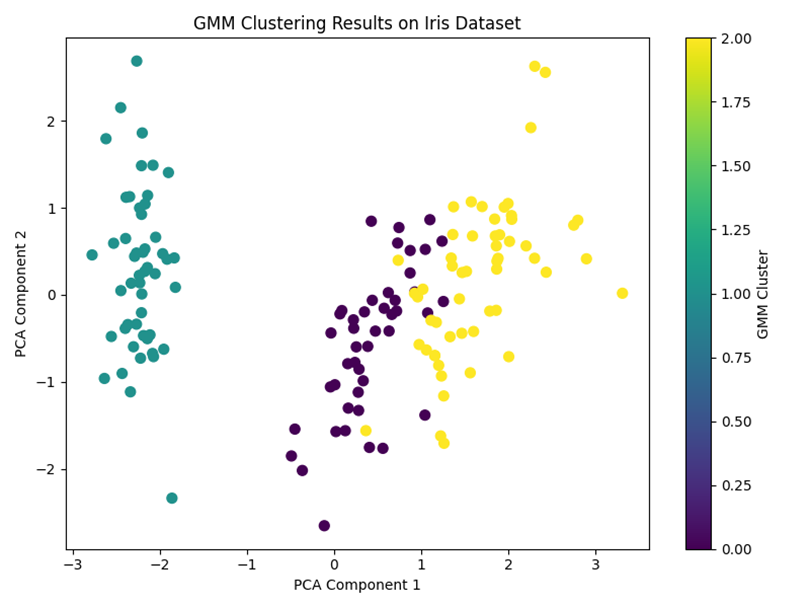
图2 GMM 聚类结果图
该图展示了高斯混合模型对鸢尾花数据集的聚类结果。不同颜色表示模型自动识别出的不同聚类簇。整体来看,GMM能够较好识别数据中的主要类别结构,但在右侧两个类别相互接近的区域仍存在少量样本交叉。
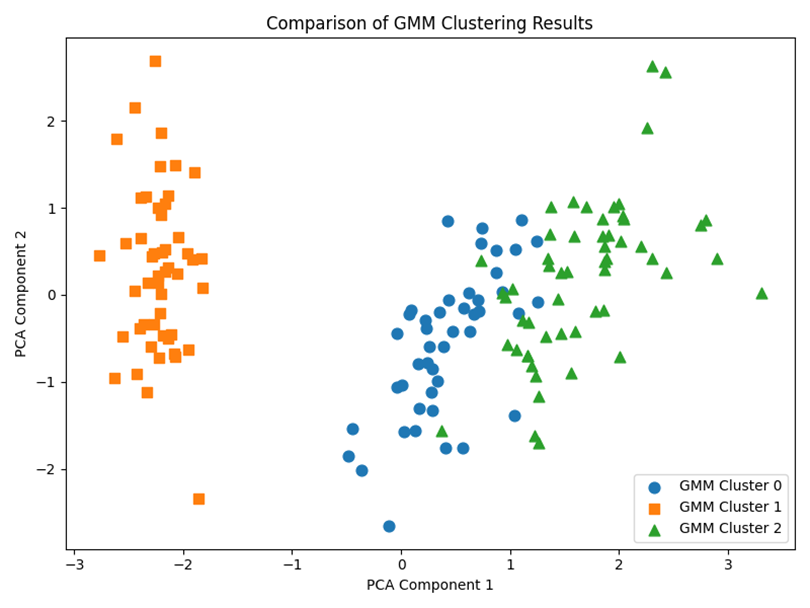
图3 GMM 聚类类别分布对比图
该图进一步展示了不同聚类簇在二维空间中的分布位置。三个聚类簇整体形成了较为明显的分布区域,左侧聚类簇与其他类别区分较清楚,右侧两个聚类簇之间存在一定过渡区域。
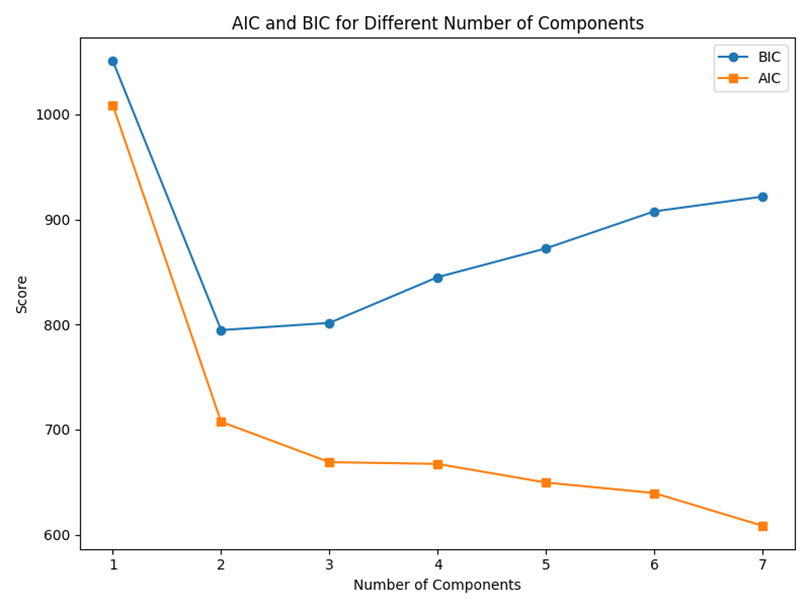
图4 AIC/BIC 聚类成分数选择图
该图展示了不同聚类成分数量下AIC和BIC指标的变化情况。AIC和BIC用于衡量模型拟合效果与复杂度之间的平衡。结合鸢尾花数据集本身包含三类真实样本的特点,本实验最终将GMM聚类成分数设置为3。
3.5 问题分析与改进
本实验中需要重点关注的问题是:GMM聚类结果可能受到模型初始化方式的影响,并且聚类结果不一定与真实类别完全一致。未设置 n_init 时,模型只进行单次初始化,容易受到初始参数影响,导致ARI和NMI相对较低。
造成这一问题的原因主要包括三点:第一,鸢尾花数据集中 Versicolor 和 Virginica 两类样本特征较为接近,类别边界存在重叠;第二,GMM属于无监督学习,模型训练过程中并不知道真实类别标签;第三,GMM通常通过EM算法估计参数,而EM算法对初始值具有一定敏感性。
针对上述问题,实验中采取了以下改进:一是使用ARI、NMI和轮廓系数等指标进行综合评价,而不是直接比较聚类编号和真实编号;二是通过PCA可视化图对真实类别和聚类结果进行对比;三是在GMM模型中加入 n_init=10,使模型进行多次初始化并选择较优结果,从而提高聚类结果的稳定性。