RoPE是什么
RoPE(Rotary Position Embedding,旋转位置编码)是 Transformer 架构中用于注入位置信息的一种方法。它由苏剑林等人提出,目前是 Llama、GPT-NeoX、Falcon 等绝大多数开源大模型的事实标准。
简单来说,RoPE 的核心思想是:通过复数域的旋转变换(Rotation)来编码位置,让模型在计算注意力时能"感知"到 token 之间的相对距离。
一、RoPE 解决了什么问题?
在标准的 Transformer 中,Self-Attention 本身是置换不变(Permutation-Invariant) 的。也就是说,如果不告诉模型单词的位置,"猫 追 狗"和 "狗 追 猫"对它来说可能没有区别。
RoPE 的使命 :在计算 Query 和 Key 的内积(即注意力分数)时,将绝对位置 信息编码进去,使其能自然地推导出相对位置关系。
二、RoPE 的工作原理(直观理解)
RoPE 不直接修改词向量,而是通过修改 Query 和 Key 向量 的计算方式来注入位置信息。
1. 核心机制:旋转
RoPE 将词向量的每一维(或每两维)看作复平面上的一个点。对于位置为 m的 token,将其对应的 Query 或 Key 向量旋转 mθ角度。
-
旋转操作 :在二维复平面上,旋转操作等价于乘以一个复数
。
-
数学表达 :对于位置 m 的向量
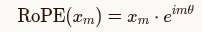
(在实际实现中,是分块对向量的每两维进行旋转)。
2. 注意力分数的"相对性"
RoPE 的巧妙之处在于,当计算 Query(位置 m)和 Key(位置 n)的点积时:
由于旋转操作的性质,点积结果只依赖于相对位置 (m−n),而与绝对位置无关。
这意味着模型学到的注意力模式是相对位置敏感的,这比学习绝对位置更符合语言逻辑(例如,一个词通常只关心它前后几个词)。
三、RoPE 的关键特性
| 特性 | 说明 | 优势 |
|---|---|---|
| 相对位置编码 | 注意力分数仅依赖 m−n | 泛化能力强,支持长文本外推 |
| 可扩展性 | 无需学习参数,直接计算 | 支持无限长度(理论上) |
| 线性注意力兼容 | 可分解为相对位置项 | 适合优化推理速度 |
| 长文本友好 | 相比正弦编码,对长上下文衰减更慢 | Llama 3 等模型支持长上下文的基础 |
四、RoPE 在 LLM 中的实际应用
1. 主流模型的选择
-
Llama 系列(1/2/3):均采用 RoPE。
-
GPT-NeoX、Falcon、Baichuan:广泛使用。
-
非 RoPE 阵营:GPT-3 使用学习式位置编码,BERT 使用绝对位置编码。
2. 外推(Extrapolation)问题
RoPE 在训练时有一个固定的"上下文窗口"(如 2048)。当推理时输入长度超过这个窗口,直接计算会导致效果下降(因为旋转角度太大,模型没见过)。
- 解决方案 :通常需要通过 NTK-aware 缩放 或 YaRN 等技巧来扩展上下文长度,而不是直接外推。
五、与经典位置编码的对比
| 编码类型 | 代表模型 | 核心思想 | 缺点 |
|---|---|---|---|
| 绝对位置编码 | BERT, GPT-2 | 每个位置学一个向量 | 无法泛化到训练外的长度 |
| 正弦位置编码 | 原始 Transformer | 预设正弦函数 | 外推性能一般 |
| 相对位置编码 | T5, RoPE | 编码相对距离 | 实现稍复杂 |
| RoPE | Llama, GPT-NeoX | 旋转操作 | 目前综合最佳实践 |
六、总结
-
RoPE 是什么 :一种通过复数旋转来编码位置信息的技术。
-
它做了什么 :让 Attention 计算能天然捕捉 token 之间的相对距离。
-
为什么重要:它是现代 LLM(如 Llama)能处理长文本、并具备强大泛化能力的底层支撑之一。
如果你看代码,RoPE 通常体现在 apply_rotary_pos_emb这样的函数中,它会在计算 Q、K 之前,对它们进行旋转变换。
怎么理解: 将词向量的每一维(或每两维)看作复平面上的一个点
这个描述确实有点抽象,但我们可以用一个非常直观的"时钟模型"来彻底搞懂它。RoPE 的核心其实不是数学魔法,而是一种几何变换。
一、降维理解:把词向量想象成"时钟指针"
我们先忘掉高维空间,假设词向量只有 2 维 [x, y]。在几何上,这可以完美对应复平面上的一个点,或者更直观地,想象成钟表上的一根指针。
-
词向量 = 指针的长度和初始角度(代表这个词的"含义")。
-
位置 m = 你要把指针拨动多少格。
RoPE 的操作 :对于第 m个位置的词,就把它的指针顺时针旋转 m * θ度。
举个例子:
-
词
"apple"在位置 1:旋转 1 格。 -
词
"apple"在位置 2:旋转 2 格。 -
词
"apple"在位置 3:旋转 3 格。
同一个词在不同位置,指针的指向是完全不同的。模型通过最终指针的指向来同时理解"词义"和"位置"。
二、为什么旋转能解决位置问题?
关键点在于 Query 和 Key 的点积(匹配度)。
继续用时钟类比,Attention 计算的是两个指针的"重合度"或"夹角"。RoPE 的巧妙之处在于:
-
绝对位置被抵消 :旋转操作是线性的,当计算 Query(位置 m)和 Key(位置 n)的匹配度时,旋转角度差正好是
(m - n) * θ。 -
只剩相对位置 :点积结果只与
m - n(相对距离)有关,而与 m 或 n 的绝对数值无关。
这就是 RoPE 的精髓:通过绝对位置的旋转操作,在注意力分数中自然诱导出相对位置关系。
三、高维向量的"分块旋转"
你提到的"每一维(或每两维)"是因为高维向量无法直接旋转。
-
实际做法 :将 4096 维的向量拆成 2048 组
[x1, x2]。 -
每组独立旋转:对每一组二维坐标分别应用上述的"时钟旋转"操作。
-
旋转角度递增:为了让模型感知不同频率的位置信息,每一组使用的旋转基数 θ 是不同的(高频维度转得快,低频维度转得慢)。
四、几何直觉 vs 数学公式
| 概念 | 几何直觉(时钟模型) | 数学表达(复平面) |
|---|---|---|
| 词向量 | 指针 [x, y] |
复数 x + iy |
| 位置编码 | 拨动指针 m * θ度 |
乘以 |
| 内积 | 看两个指针的夹角 | 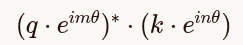 |
| 结果 | 夹角取决于 m-n |
结果取决于 m-n |
一句话总结:RoPE 不是给向量"加"位置信号,而是通过"转"它,让不同位置的同一个词在向量空间中指向不同方向,从而让 Attention 机制能捕捉到相对距离。
RoPE(旋转位置编码)在**复平面(复数空间)**下的数学表达
你看到的这个公式,是 RoPE(旋转位置编码)在**复平面(复数空间)**下的数学表达。它描述了 Query 和 Key 在注入位置信息后计算内积(即注意力分数)的过程。
一、符号拆解

二、公式的物理含义:为什么这么算?
这个公式描述了一个**"先旋转,后匹配"**的过程:

关键推导(为什么只剩相对位置?)
利用复数运算的性质  ,我们可以将公式展开:
,我们可以将公式展开:
最终结果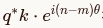 表明,注意力分数仅依赖于原始向量的内积 q∗k和相对位置差 (n−m)。绝对位置 m和 n在计算过程中被抵消了。
表明,注意力分数仅依赖于原始向量的内积 q∗k和相对位置差 (n−m)。绝对位置 m和 n在计算过程中被抵消了。
三、从复数回到现实:代码里实际怎么算?
在代码实现中(如 PyTorch),我们并不直接操作复数,而是将高维向量拆成二维分组,对每一组进行实数域的旋转矩阵运算。
复数公式的实数等价形式:
对于向量的任意一个二维分量 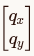 ,旋转操作等价于乘以一个 2x2 旋转矩阵:
,旋转操作等价于乘以一个 2x2 旋转矩阵:
代码视角(伪代码):
python
# q, k 是原始向量 (d_model 维)
# pos 是位置索引
# freqs 是预设的旋转频率基
def apply_rope(q, k, pos):
# 1. 将 q, k 拆分为 (x1, x2, x3, x4, ...) 的二维组
q_pairs = reshape(q, (-1, 2)) # [d_model/2, 2]
k_pairs = reshape(k, (-1, 2))
# 2. 为每一组计算旋转角度 (cos, sin)
cos = cos(pos * freqs) # freqs 不同组不同
sin = sin(pos * freqs)
# 3. 对每一组应用旋转矩阵
for i in range(len(q_pairs)):
q_x, q_y = q_pairs[i]
q_pairs[i] = [q_x * cos[i] - q_y * sin[i],
q_x * sin[i] + q_y * cos[i]]
# 同理处理 k_pairs
# 4. 重新展平,得到旋转后的 Q_rope, K_rope
return reshape(q_pairs), reshape(k_pairs)总结
-
你看到的公式:是 RoPE 在复数域的优雅表达,证明了注意力分数只依赖相对位置。
-
实际理解 :在代码和实数域中,它就是对向量的每一对数字 (x,y)做了一次二维旋转。
-
最终效果:同一个词在不同位置,其向量在向量空间中的"朝向"不同,从而让模型感知到位置。