文章目录
- 前言
- [1. 为什么需要索引](#1. 为什么需要索引)
- [2. 索引底层数据结构演化](#2. 索引底层数据结构演化)
-
- [2.1 二叉搜索数(BST)](#2.1 二叉搜索数(BST))
- [2.2 平衡二叉树(AVL)](#2.2 平衡二叉树(AVL))
- [2.3 红黑树](#2.3 红黑树)
- [2.4 Hash 表](#2.4 Hash 表)
- [2.5 B树](#2.5 B树)
- [2.6 B+ 数(InnoDB使用)](#2.6 B+ 数(InnoDB使用))
-
- [为什么 InnoDB 选择 B+ 树?](#为什么 InnoDB 选择 B+ 树?)
前言
在数据库中,随着数据量增长,查询效率会急剧下降。
例如:
sql
SELECT * FROM user WHERE id = 1;如果没有索引,数据库只能进行全表扫描(Full Table Scan),逐行匹配数据,当数据达到百万级甚至千万级时,查询性能会显著下降。因此,数据库引入了索引机制。
索引的本质:
帮助数据库快速定位数据的数据结构。
1. 为什么需要索引
索引在数据库中扮演着"目录"的角色。想象一本没有目录的厚书,你要找某个知识点只能一页页翻,而有了目录,直接定位到章节即可。
具体来说,索引带来的好处有:
- 大幅提升查询速度 :对于
WHERE、JOIN、ORDER BY、GROUP BY等操作,索引能减少扫描的数据量,从全表 O(n) 降到 O(log n) 甚至更低。 - 减少磁盘 I/O:数据库数据存储在磁盘上,没有索引时可能产生大量随机 I/O;索引结构(如 B+ 树)能将随机 I/O 转为顺序 I/O,或大幅减少 I/O 次数。
- 唯一性约束:唯一索引可以保证表中某列(或列组合)的值不重复。
- 辅助排序与分组:索引本身已经有序,可以避免额外的 filesort 操作。
当然,索引也有代价:
- 占用额外的存储空间。
- 增、删、改数据时需要同步维护索引,降低写入性能。
- 不合理的索引可能被优化器忽略,甚至拖慢查询。
因此,索引需要根据查询模式合理设计,并非越多越好。
2. 索引底层数据结构演化
2.1 二叉搜索数(BST)
BST的特点:
- 每个节点的左子树中,所有节点的值都小于该节点
- 每个节点的右子树中,所有节点的值都大于该节点
- 左右子树本身也是 BST
这一规则保证了"左小右大",使得每次比较都能排除一半的候选范围,所以BST的效率非常高。
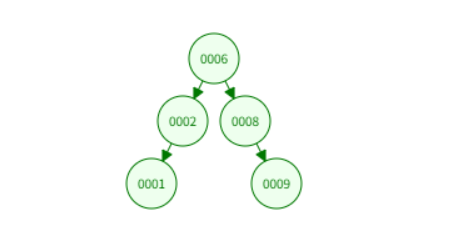
但BST存在一个致命问题:
如果插入顺序是1、2、3、4、5,树就会变为:
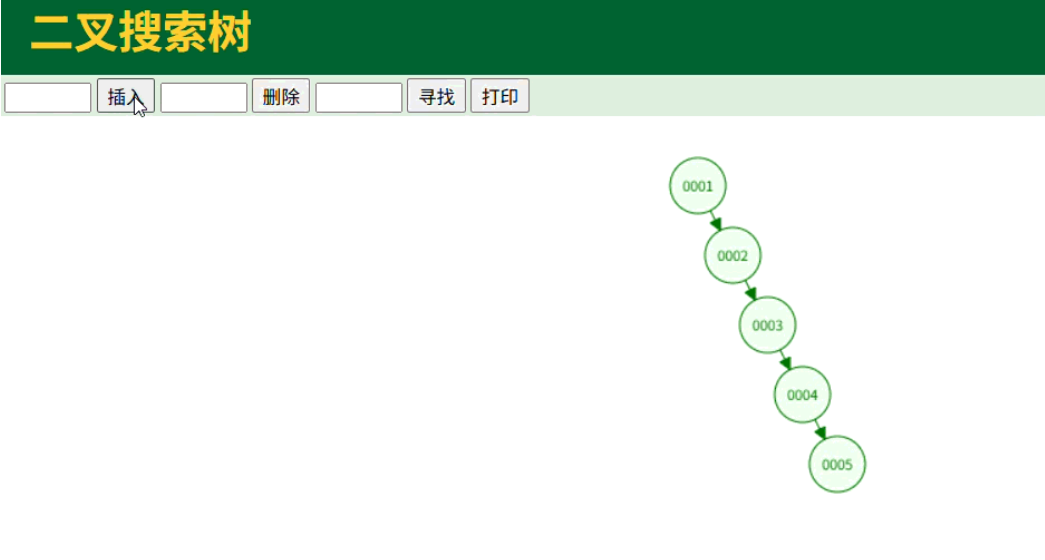
这时查找数据只能全部遍历,复杂度变为O(n),性能崩了。
2.2 平衡二叉树(AVL)
AVL 是第一种字平衡二叉搜索树,它规定任意节点左右子树高度差(平衡因子)不能超过1,从而实现树的平衡。在每次插入或删除操作后,会从受影响的节点向上回溯,检查平衡因子(左高 - 右高)。若平衡因子绝对值大于 1,则通过旋转操作恢复平衡:左旋、右旋、左右双旋、右左双旋。
AVL 的特点:
- 查询效率稳定:严格平衡使得树高保持在 O(log n),查找、插入、删除均为 O(log n)。
- 适合读多写少的场景:因为维持平衡的旋转成本较高,频繁插入删除会导致多次旋转。
- 每个节点存储一个高度值或平衡因子,额外占用少量空间。
AVL虽然解决了 BST 的退化问题,但仍然是二叉树。当数据量巨大(千万级)时,树高约为 log₂(10⁷) ≈ 24 层,查询一个数据可能需要 24 次磁盘 I/O,每次 I/O 都很慢。数据库索引需要更"矮胖"的结构,以减少 I/O 次数。因此 AVL 并未被主流数据库采用为索引结构。
2.3 红黑树
红黑树也是一种自平衡二叉搜索树,但它不追求 AVL 那样的"绝对平衡",而是保证从根到叶子的最长路径不超过最短路径的 2 倍,从而近似平衡。在每次- 插入或删除后,通过变色和旋转(左旋/右旋)来恢复规则。
红黑树的五条规则:
- 每个节点是红色或黑色。
- 根节点是黑色。
- 所有叶子节点(NIL 空节点)是黑色。
- 红色节点的两个子节点必须是黑色(即不能有连续的两个红色节点)。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点(黑高一致)。
红黑树 vs AVL:
| 特性 | AVL | 红黑树 |
|---|---|---|
| 平衡性 | 严格(高度差 ≤1) | 松散(最长路径≤2倍最短路径) |
| 查询性能 | 更快(更矮) | 稍慢(略高) |
| 插入/删除性能 | 多次旋转,较慢 | 变色+少量旋转,较快 |
| 适用场景 | 读多写少 | 读写相当,如 Java HashMap、Linux CFS |
为什么数据库不用红黑树?
红黑树仍然是二叉树,树高较高,I/O 次数多。此外,红黑树不擅长范围查询------需要中序遍历回溯,效率低。因此它只适用于内存中的数据结构(如 TreeMap、TreeSet),不适合磁盘索引。
2.4 Hash 表
Hash 表(散列表)是另一种常见的数据结构,通过哈希函数将键映射到数组中的某个位置,实现 O(1) 的等值查询。
Hash 索引的特点:
- 查询极快:只需一次哈希计算 + 一次定位,等值查询复杂度 O(1)。
- 不支持范围查询 :哈希映射是随机的,数据在物理上无序,无法进行
< > BETWEEN等操作。 - 哈希冲突:不同键计算出相同哈希值,需要通过拉链法、开放寻址法等解决,冲突多了性能下降。
- 不支持排序 :无法利用索引做
ORDER BY。 - 无法利用前缀查找 :对
LIKE 'abc%'无效,因为哈希是对完整键值计算的。
2.5 B树
B 树也称 B- 树,全称为 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 Balanced(平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构
B-树的特点:
- 每个节点 既存索引键,也存完整数据
- 节点内键值有序排列
- 所有叶子节点在同一层,保持绝对平衡
- 一个节点可以有多个子节点,M阶B树,最多M个子节点
- 非叶子节点的键值将子树分隔开,遵循左小右大
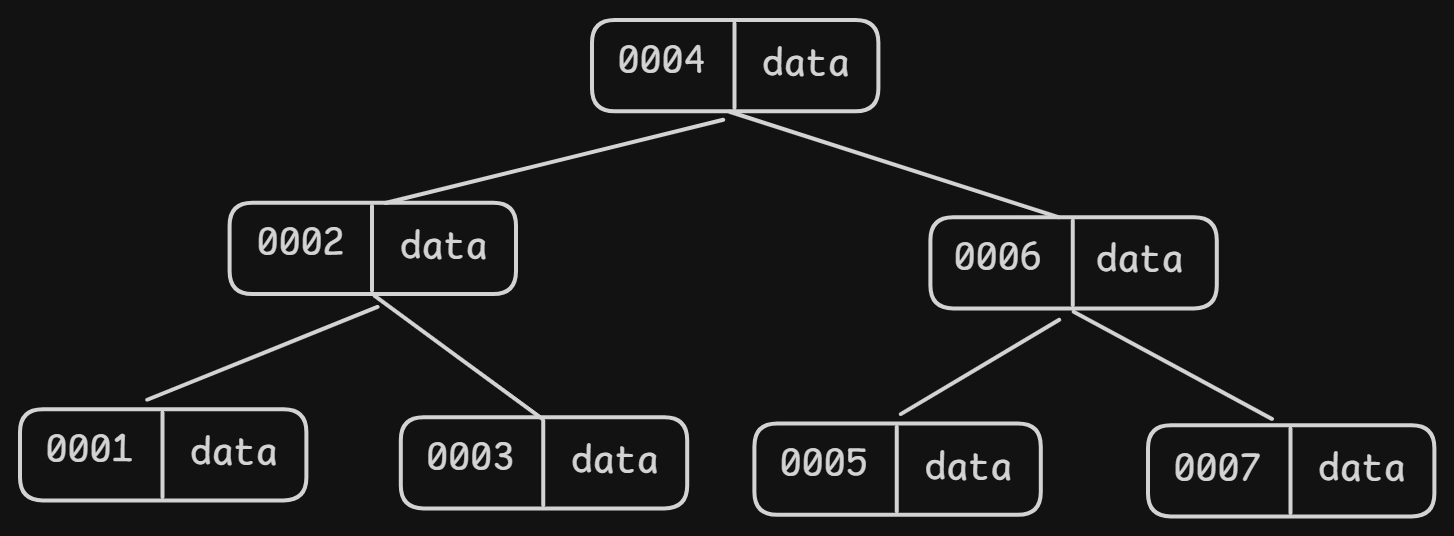
查找过程:从根节点开始,每层做二分查找,一旦命中就立刻返回,不需要走到叶子节点。
2.6 B+ 数(InnoDB使用)
MySQL 与 B+ 树没有直接关系,和 B+ 树有直接关系的是MySQL的默认存储引擎InnoDB,而 InnoDB 默认使用B+ Tree。除 InnoDB 外MySQL还支持其他存储引擎,如MyISAM。
!\[Pasted image 20260521151328.png]
B+ 树的特点:
- 所有数据存储在叶子结点,非叶子节点只存键值
- 叶子节点通过双向链表连接,范围查询效率极高
- 非叶子节点的键会在叶子节点中重复出现
- 树高通常只有3~4层,I/O 次数极少
!\[Pasted image 20260521165701.png]
查询过程:从根节点出发,递归向下经过内部节点,到达叶子节点完成查找。
!\[B+树查找.gif]
B树与B+树的对比:
| 对比维度 | B树 | B+树 |
|---|---|---|
| 数据存储位置 | 所有节点存储数据 | 只有叶子节点存数据 |
| 非叶子节点 | 存键 + 数据 | 只存键,占用空间小 |
| 叶子节点链表 | 没有 | 双向链表连接 |
| 查找路径 | 命中即返回,路径不固定 | 必须到叶子节点,路径固定 |
| 范围查询 | 需要中序遍历,效率低 | 直接走链表,效率极高 |
| 等值查询 | 最好情况根节点命中,更快 | 固定走到叶子,稍慢 |
| 树的高度 | 相对较高 | 相对较矮 |
| IO 次数 | 较多 | 较少 |
| 稳定性 | 不稳定,层数不同 | 稳定,都到叶子 |
为什么 InnoDB 选择 B+ 树?
- 磁盘 I/O 更少:非叶子节点不存数据,一个磁盘块可存储大量键,分叉因子极大,树高通常 3~4 层,千万数据也只需 3~4 次 I/O。
- 范围查询高效 :叶子链表使得
BETWEEN、>、<、ORDER BY等只需遍历叶子节点,无需回溯。 - 全表扫描更友好:直接遍历叶子链表即可,相当于顺序读磁盘。
- 数据存储稳定:所有数据都在叶子,查询任何记录的 I/O 次数相同,性能可预测。