一、RNN及其变体概述
1.RNN基本概念
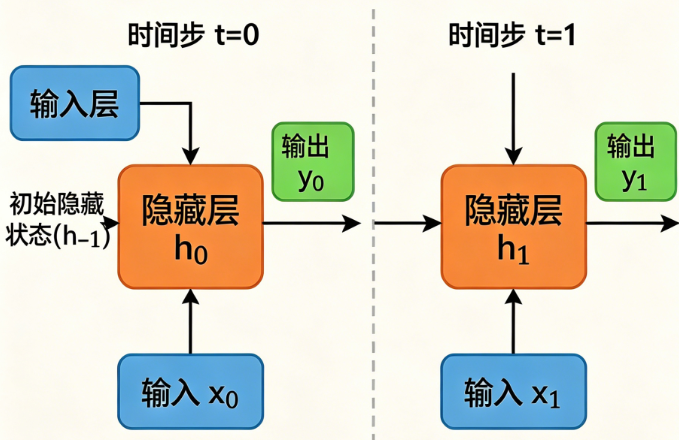
循环神经网络RNN (Recurrent Neural Network),专门以序列数据为输入,通过网络内部结构设计有效捕捉序列之间的关系特征,一般以序列形式进行输出。
为什么叫"循环"神经网络?核心在于它的循环机制 ------上一个时间步的隐藏层输出,会作为下一个时间步的隐藏层输入。这就好比人类读书,不是孤立理解每个字,而是带着前面句子的理解去读下一句。
RNN网络结构由输入层、隐藏层、输出层组成:
- 每个时间步的输入有2个:数据端输入 + 上一时间步的隐藏层输入
- 每个时间步的输出 有2个:数据端输出 + 本时间步的隐藏层输出
2.RNN模型分类
2.1 按输入输出形式分类
| 类型 | 输入 | 输出 | 典型用途 |
|---|---|---|---|
| N vs N | N个序列 | N个序列 | 写诗、写对联 |
| N vs 1 | N个序列 | 1个值 | 情感分类、意图识别 |
| 1 vs N | 1个值 | N个序列 | 看图说话 |
| N vs M | N个序列 | M个序列 | 机器翻译、文本摘要(seq2seq架构) |
其中 N vs M(seq2seq)应用最广泛,编码器将输入序列编码成中间语义张量C,再由解码器解码生成输出序列。
2.2 按内部构造分类
传统RNN → LSTM → Bi-LSTM → GRU → Bi-GRU
二、传统RNN详解
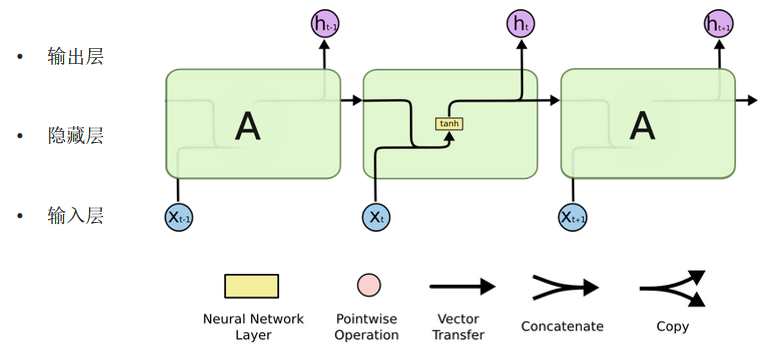
1.RNN内部结构
RNN的隐藏层内部使用tanh激活函数 ,作用是将值压缩在 -1和1之间,帮助调节流经网络的值,防止数值爆炸。
每个时间步的隐藏状态计算公式:
ht=tanh(Wih⋅xt+Whh⋅ht−1+b)h_t = \tanh(W_{ih} \cdot x_t + W_{hh} \cdot h_{t-1} + b)ht=tanh(Wih⋅xt+Whh⋅ht−1+b)
其中 xtx_txt 是当前输入,ht−1h_{t-1}ht−1 是上一时间步的隐藏状态,两者分别乘以权重矩阵后相加,通过tanh激活输出当前隐藏状态。
2.RNN模型API
PyTorch中通过 torch.nn.RNN 调用,核心参数共9个:
python
import torch
import torch.nn as nn
def dm01_rnn_for_base():
# 参数A:nn.RNN(输入特征维度, 输出特征维度, 隐藏层个数)
rnn = nn.RNN(5, 6, 1)
# 参数B:input [单词个数, 批次数, 输入特征维度]
input = torch.randn(1, 3, 5)
# 参数C:hidden [隐藏层个数, 批次数, 输出特征维度]
h0 = torch.randn(1, 3, 6)
# 数据形状:input[1,3,5] + h0[1,3,6] → output[1,3,6], hn[1,3,6]
output, hn = rnn(input, h0)
print('output-->', output.shape) # torch.Size([1, 3, 6])
print('hn--->', hn.shape) # torch.Size([1, 3, 6])输入输出形状对应关系:
| 参数位置 | 形状 | 说明 |
|---|---|---|
| input | [时间步, 批次, 特征维度] |
输入序列 |
| h0 | [隐藏层数, 批次, 隐层维度] |
初始隐藏状态 |
| output | [时间步, 批次, 特征维度] |
所有时间步的输出 |
| hn | [隐藏层数, 批次, 隐层维度] |
最后一个时间步的隐藏状态 |
3.RNN的优缺点
优点:
- 内部结构简单,对计算资源要求低
- 在短序列任务上性能和效果都表现优异
缺点:
- 长序列文本特征提取效果差 ------过长的序列导致梯度计算异常,发生梯度消失或爆炸
三、LSTM模型
1. LSTM基本概念
LSTM (Long Short-Term Memory,长短时记忆结构)是传统RNN的变体。与经典RNN相比,LSTM能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。
为什么能缓解?因为LSTM引入了门控机制。
2. LSTM内部结构
LSTM的核心是细胞状态(Cell State) ,可以理解为一条"记忆传送带",信息沿着它传递,门控决定增加或删除信息。
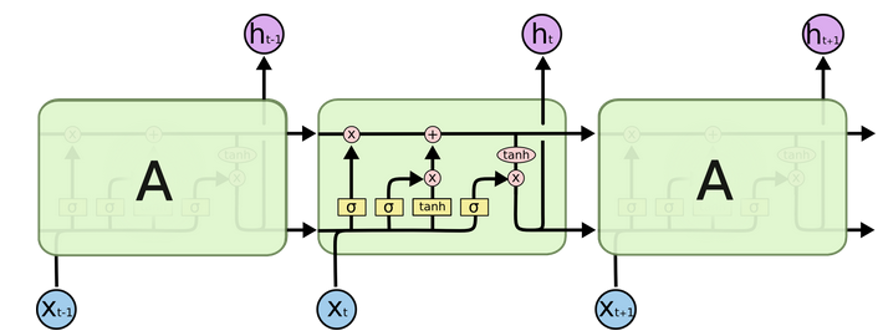
LSTM有3个门 + 1个细胞状态:
| 门 | 作用 | 说明 |
|---|---|---|
| 遗忘门 | 决定从上一个细胞状态中丢弃哪些信息 | sigmoid输出0~1,0完全遗忘,1完全保留 |
| 输入门 | 决定对内部细胞状态要使用多少新信息 | 配合tanh生成候选记忆 |
| 输出门 | 决定细胞状态的哪部分将输出 | 控制输出什么信息 |
工作流程:
- 遗忘门 :读取 ht−1h_{t-1}ht−1 和 xtx_txt,输出0~1之间的值给细胞状态 Ct−1C_{t-1}Ct−1
- 输入门 :生成候选记忆 C~t\tilde{C}_tC~t,决定更新哪些信息到细胞状态
- 更新细胞状态
- 输出门:决定输出什么版本的细胞状态信息
3.LSTM模型API
python
def dm02_LSTM():
# 参数A:nn.LSTM(输入特征维度, 输出特征维度, 隐藏层个数)
lstm = nn.LSTM(5, 6, 2)
# 参数B:input [时间步, 批次数, 特征维度]
input = torch.randn(1, 3, 5)
# 参数C:h0 [隐藏层数, 批次数, 隐层维度]
h0 = torch.randn(2, 3, 6)
# LSTM还需要细胞状态 c0
c0 = torch.randn(2, 3, 6)
# 数据形状:input[1,3,5] h0[2,3,6] c0[2,3,6]
# → output[1,3,6], hn[2,3,6], cn[2,3,6]
output, (hn, cn) = lstm(input, (h0, c0))
print('output-->', output.shape)
print('hn--->', hn.shape)
print('cn--->', cn.shape)LSTM输出比RNN多一个 cn(细胞状态),这是LSTM独有的。
4.LSTM优缺点
优势:
- 门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸
- 在更长的序列问题上表现优于传统RNN
缺点:
- 内部结构相对较复杂,训练效率在同等算力下较传统RNN低很多
四、GRU模型
1.GRU基本概念
GRU(Gated Recurrent Unit)门控循环单元,也是传统RNN的变体。与LSTM一样,GRU能捕捉到长序列之间的语义关系,缓解梯度消失或爆炸现象。
GRU的结构比LSTM简单,比RNN复杂,是LSTM的简化版本。
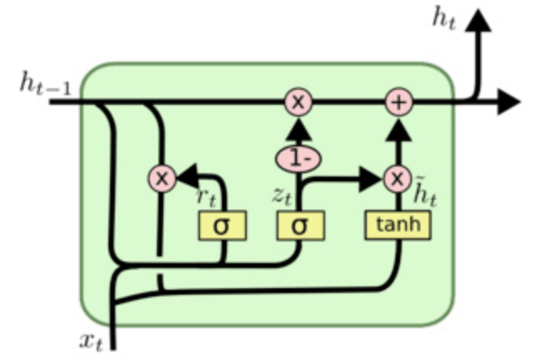
2.GRU内衣部结构
GRU有2个门(比LSTM少一个):
| 门 | 作用 |
|---|---|
| 更新门 | 控制前一时刻的隐藏状态,有多少信息需要被保留到当前时刻(值越大,保留的过去信息越多) |
| 重置门 | 控制前一时刻的隐藏状态,有多少信息需要被忽略(即决定了如何将新输入与过去的记忆结合) |
3.GRU优缺点
优势:
- 和LSTM作用相同,能有效抑制梯度消失或爆炸,效果优于传统RNN
- 计算复杂度相比LSTM要小
缺点:
- 仍然不能完全解决梯度消失问题
- RNN结构本身的不可并行计算弊端依然存在,这在数据量和模型体量逐步增大的未来是RNN发展的关键瓶颈
五、总结
| 知识点 | 一句话总结 |
|---|---|
| RNN循环神经网络 | 循环机制:上一时间步隐藏层输出作为下一时间步输入 |
| RNN输入输出分类 | N vs N、N vs 1、1 vs N、N vs M(seq2seq) |
| 传统RNN缺点 | 长序列导致梯度消失或爆炸,短序列任务表现优异 |
| LSTM核心 | 门控机制(遗忘门、输入门、输出门)+ 细胞状态 |
| LSTM优势 | 有效缓解长序列梯度问题,但训练计算量大 |
| GRU核心 | 2个门(更新门、重置门),比LSTM更简单 |
| GRU优势 | 效果接近LSTM,计算复杂度更小 |
| Bi-LSTM | 双向处理,将正向和反向结果拼接 |
| RNN共同局限 | 不可并行计算,是未来发展的瓶颈 |
三者关系可以这样理解:RNN是基础但有致命缺陷,LSTM用门控修补缺陷但计算复杂,GRU是LSTM的简化版,在效果和效率之间取得平衡 。实际项目中,优先选择LSTM或GRU,除非是短序列任务或对实时性要求极高的场景。