Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse

论文地址:https://arxiv.org/abs/2410.21333
项目页面:https://github.com/JiayiGeng/CoT_overthinking
学术交流:922230617 或加 CV_EDPJ
目录
[1. 核心问题:什么时候 "一步步思考" 反而让 AI 变笨?](#1. 核心问题:什么时候 “一步步思考” 反而让 AI 变笨?)
[2. 怎么找这类任务?](#2. 怎么找这类任务?)
[3. 找到了三类 "AI 一思考,人类就发笑" 的任务](#3. 找到了三类 “AI 一思考,人类就发笑” 的任务)
[4. 结论:什么时候要小心使用 CoT?](#4. 结论:什么时候要小心使用 CoT?)
[5. 局限性与未来工作](#5. 局限性与未来工作)
1. 核心问题:什么时候 "一步步思考" 反而让 AI 变笨?
让 AI 像人一样 "一步步思考"(Chain-of-Thought, CoT),通常能提高它的解题能力,尤其在数学和逻辑题上。很多新模型甚至默认开启了这个功能。
但这篇论文问了一个相反的问题:有没有一些任务,你用 CoT,AI 的表现反而更差?
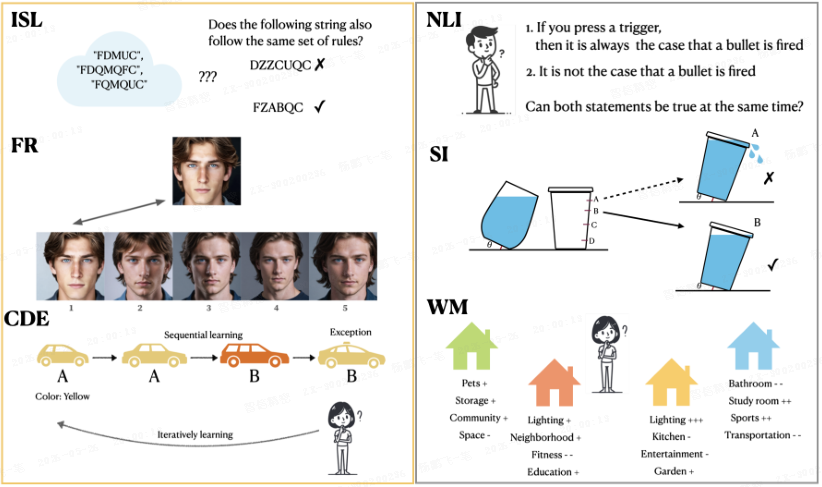
图 1. 评估因思维链(CoT)导致性能下降的任务。
左图:
- 隐式统计学习(ISL):判断字符串是否由某种人工语法生成。
- 人脸识别(FR):从一组具有相似描述的图像中识别人脸。
- 带例外数据的分类(CDE):在存在例外情况时学习标签。
右图:
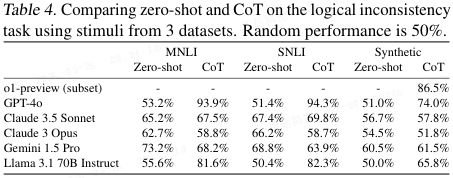
- 自然语言推理(NLI):识别逻辑不一致性。
- 空间直觉(SI):倾斜水杯。
- 工作记忆(WM):整合特征以做出决策。
人类在所有任务中,当进行语言性思考(verbal thinking)时均表现出性能下降,而大型语言模型(LLM)和大型多模态模型(LMM)在前三个任务中也显示出类似的效果。
2. 怎么找这类任务?
作者用一个巧妙的思路:去心理学里找 "人类一用心思考,反而做得更差" 的任务。然后看看在这些任务上,AI 用 CoT 是不是也一样 "翻车"。
这个想法挺合理:如果某项任务,连人类这种 "原生大脑" 用语言去思考都会搞砸,那对 AI 这种 "语言模型" 来说,强制它一步步用语言推理,很可能也是帮倒忙。
3. 找到了三类 "AI 一思考,人类就发笑" 的任务
作者确实找到了三类任务,在这些任务上,用 CoT 会让最先进的模型(如 GPT-4o、Claude 3.5)表现显著下降。
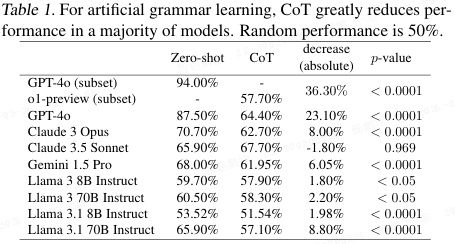
第一类:隐式统计学习(就是 "凭感觉" 找规律)
-
人类表现:比如给你看一堆符合某种隐藏规则的字符串,你下意识能判断新字符串对不对,但让你说出规则,你反而说不对了。强行让你用语言解释,你的直觉判断力会下降。
-
AI 表现(表 1):一模一样。让 AI 不思考直接判断,准确率还可以;一旦让它 "一步步思考",它试图把隐藏规则用语言表述出来,反而会出错。GPT-4o 用了 CoT 后,准确率绝对下降了 23.1%,而带内置推理的 o1-preview 相比 GPT-4o 的基础版,准确率暴跌 36.3%。
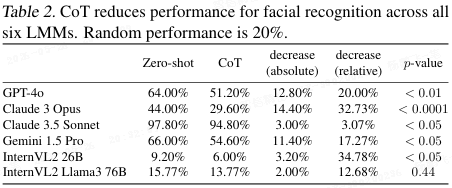
第二类:人脸识别(视觉任务被语言干扰)
-
人类表现 :让你看一张脸,然后认另一张是不是同一个人。如果你认脸之前,先用语言详细描述一下这张脸的特征(眼睛、鼻子、头发),你的识别准确率反而会下降。这叫 "言语遮蔽效应(verbal overshadowing)"。
-
AI 表现(表 2):情况相同。让多模态模型(能看图能读文)看人脸,然后回答。如果用 CoT,要求它先描述再判断,所有测试模型的准确率都下降了。语言成了视觉的干扰项。
第三类:有例外的规则(一概括就错)
-
人类表现:给你看一些例子,大部分符合某个简单规则,但有少数例外。让你一边看一边总结规律,你会发现,越想总结个通用规律,就越记不住那些例外,学习效果反而更差。
-
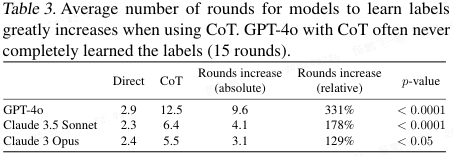
AI 表现(表 3):结果更夸张。AI 用 CoT 后,会陷入 "过度概括" 的坑。比如正确标签是 A, A, B, A, B...,它学了前两个 A,就猜测 "全是 A",然后把第三个 B 当噪声忽略,导致一直学不会。GPT-4o 本来 3 轮就能学会,用了 CoT 后,平均需要 12.5 轮,效率降低 4 倍。
**也有 AI "不翻车" 的任务:**当然,不是所有让人类 "多想就错" 的任务,AI 都会错。作者也找到了三类不对应的情况:
-
逻辑题(表 4):人类不学逻辑学会被绕晕,但 AI 逻辑知识很强,所以 CoT 这里有效。
-
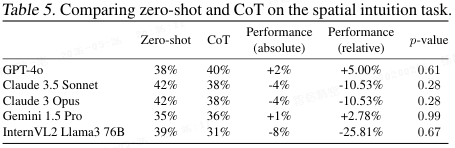
物理直觉题(如判断倾斜杯子里的水量)(表 5):人类用语言思考不灵,但 AI 本来就没有 "身体直觉",所以 CoT 的影响是中性的,不好不坏。
-
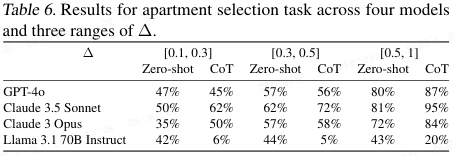
多属性决策(如需要记很多信息的题)(表 6):人类工作记忆有限,想多了会乱,但 AI 的 "上下文记忆" 很强,所以 CoT 不会让它变差,甚至可能更好
4. 结论:什么时候要小心使用 CoT?
这篇文章给了很实用的建议:在遇到以下三类问题时,不要默认开启 CoT,否则可能适得其反:
-
需要凭 "感觉" 或 "直觉" 找模式的任务(比如隐式统计规律)。
-
依赖视觉细节的判别任务(比如人脸、图片细节比对)。
-
大部分情况符合一个简单规则,但总有少数例外的任务。
在这些场景下,直接让 AI 回答(Zero-shot),效果反而更好。
5. 局限性与未来工作
本文面临几个局限性。
- 首先,虽然将六个任务扩展到了更大的规模,但与人类实验相比,每个任务的覆盖范围仍然有限。未来工作可以进一步扩展这些数据集,或探索心理学文献中更多的任务类型。
- 其次,模型的提示工程可能影响结果。虽然采用了标准的 CoT 提示格式,但不同的提示变体可能产生不同的效果。特别是对于 o1-preview,无法移除其内置的推理时推理,因此使用 GPT-4o 作为 zero-shot 比较基准,但这可能不是完美的对照。
- 第三,本文的启发式方法主要基于任务特性的定性分析。未来工作可以尝试开发更定量的指标来预测 CoT 何时会降低性能,例如测量任务刺激的 "言语可编码性" 或 "规则例外程度"。
- 最后,随着模型能力的快速演进,今天观察到的效应可能在未来模型上发生变化。本文提供的框架和基准可以作为持续评估的起点,帮助社区在 CoT 的使用上做出更明智的决策。