大家好,我是程序员小青蛙,今天介绍进程地址空间和fork的使用

目录
- [
fork()进程创建基础](#fork() 进程创建基础) - [
fork()内核工作流程与执行逻辑](#fork() 内核工作流程与执行逻辑) - [进程地址空间:虚拟地址 vs 物理地址](#进程地址空间:虚拟地址 vs 物理地址)
- 写时拷贝(COW)核心原理
- [
fork()用法与失败原因](#fork() 用法与失败原因) - 复习要点速记
一、fork() 进程创建基础
fork() 是 Linux 中创建新进程的核心系统调用,定义如下:
#include <unistd.h>
pid_t fork(void);返回值规则
- 父进程:返回子进程的
pid(大于 0) - 子进程:返回
0 - 出错:返回
-1
核心作用
从已存在的父进程中,创建一个新的子进程。新进程与父进程代码完全相同,但拥有独立的地址空间。
二、fork() 内核工作流程与执行逻辑
1. 内核在 fork() 时做了什么?
当进程调用 fork() 后,内核会执行以下关键操作:
- 为子进程分配新的内存块和内核数据结构(如
task_struct、mm_struct) - 将父进程部分数据结构内容拷贝至子进程
- 将子进程添加到系统进程列表中
fork()返回后,调度器开始调度子进程
2. 执行流程:为什么 before 只打印一次?
示例代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void) {
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ((pid = fork()) == -1) {
perror("fork()");
exit(1);
}
printf("After: pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}运行结果
Before: pid is 43676
After: pid is 43676, fork return 43677
After: pid is 43677, fork return 0关键解释
fork()之前 :只有父进程在执行,所以printf("Before...")只打印一次。fork()之后 :父子进程都从fork()返回点开始执行,所以printf("After...")会打印两次。- 父子进程谁先执行,完全由操作系统调度器决定。
三、进程地址空间:虚拟地址 vs 物理地址
1. 什么是进程地址空间?
进程地址空间,本质是操作系统为每个进程构建的虚拟地址模型 ,也叫线性地址空间。
- 对进程来说,它 "以为" 自己独占了整个内存(32 位系统是 4G 空间),但实际上只是操作系统画的一张 "大饼"。
- 它由内核数据结构
struct mm_struct管理,定义了代码段、数据段、堆、栈等区域的范围。
2. 32 位系统地址空间布局(经典模型)
从低地址到高地址,依次为:
| 区域 | 说明 |
|---|---|
| 正文代码段 | 存放程序的机器指令,只读 |
| 初始化数据段 | 存放全局初始化变量(如 int g_val = 0) |
| 未初始化数据段(BSS) | 存放全局未初始化变量,程序加载时清零 |
| 堆(heap) | 动态内存分配区域(malloc/free),向上增长 |
| 共享库 / 内存映射区 | 存放动态库(如 libc)和文件映射数据 |
| 栈(stack) | 存放局部变量、函数调用栈帧,向下增长 |
| 命令行参数 / 环境变量 | 程序启动时传入的参数和环境变量 |
| 内核空间 | 1G 大小,存放操作系统内核代码与数据,用户态不可直接访问 |
3. 为什么需要虚拟地址空间?
- 安全隔离:防止进程越界访问物理内存,避免非法操作。
- 地址透明:编译器只需要按虚拟地址编译程序,不需要关心物理内存的实际布局。
- 进程独立:每个进程的虚拟地址空间相互隔离,互不干扰。
- 内存管理优化:支持分页、换入换出,让程序 "用比物理内存更大的地址空间"。
Linux下对程序地址空间进行分析查看
cpp#include <stdio.h> #include <unistd.h> #include <stdlib.h> int g_val = 0; int main() { pid_t id = fork(); if(id < 0){ perror("fork"); return 0; } else if(id == 0){ //child printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val); }else{ //parent printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val); } sleep(1); return 0; }我们发现我们发现,输出出来的变量值和地址是一模一样的,很好理解呀,因为子进程按照父进程为模版,父子并没有对变量进行进行任何修改。可是将代码稍加改动:
cpp#include <stdio.h> #include <unistd.h> #include <stdlib.h> int g_val = 0; int main() { pid_t id = fork(); if(id < 0){ perror("fork"); return 0; } else if(id == 0){ //child,子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取 g_val=100; printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val); }else{ //parent sleep(3); printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val); } sleep(1); return 0; }我们发现,父子进程,输出地址是一致的,但是变量内容不一样!能得出如下结论:
变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
但地址值是一样的,说明,该地址绝对不是物理地址!
在Linux地址下,这种地址叫做虚拟地址
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理
OS必须负责将虚拟地址转化成物理地址。
进行解释为什么要有虚拟地址和物理地址


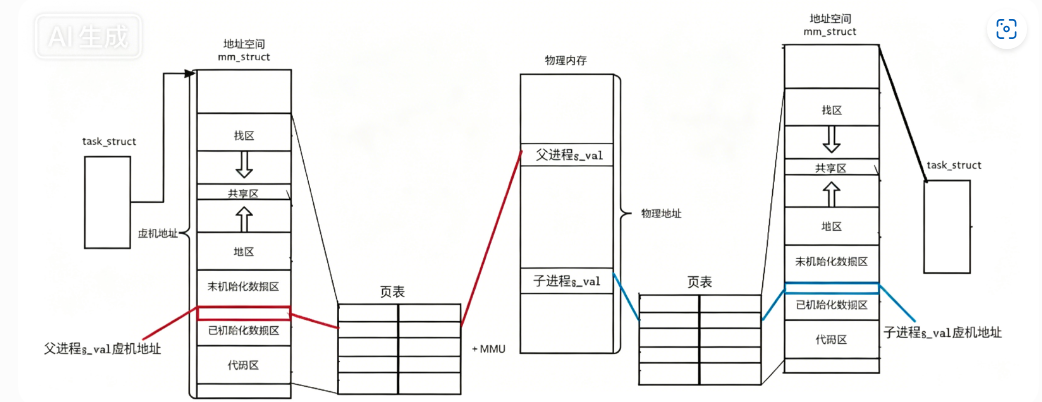
四、写时拷贝(COW)核心原理
1. 基本概念
写时拷贝(Copy-On-Write, COW)是 fork() 的核心优化机制:
fork()创建子进程时,父子进程共享同一份物理内存(代码段、数据段、堆、栈),内核会将这些内存标记为 "只读"。- 当父进程或子进程尝试修改共享内存时,操作系统会触发写时拷贝,为修改方分配新的物理内存,并拷贝数据。
- 之后,父子进程的虚拟地址虽然相同,但会映射到不同的物理地址。
2. 实验验证:父子进程地址相同但值不同
实验代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0; // 全局变量
int main() {
pid_t id = fork();
if (id < 0) {
perror("fork");
return 1;
}
else if (id == 0) { // 子进程
g_val = 100; // 子进程修改变量
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { // 父进程
sleep(3); // 让子进程先执行
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}输出结果
child[3046]: 100 : 0x80497e8
parent[3045]: 0 : 0x80497e8关键结论
- 父子进程输出的虚拟地址完全相同,但变量值不同。
- 原因:子进程修改
g_val时触发了写时拷贝,操作系统为子进程分配了新的物理内存,父子进程的虚拟地址通过页表映射到了不同的物理地址。
五、fork() 用法与失败原因
1. 常规用法
- 进程复制与任务分离:父进程复制自己,让子进程执行不同的代码段。例如,父进程等待客户端请求,生成子进程处理请求。
- 执行新程序 :子进程从
fork()返回后,调用exec()系列函数,加载并执行一个全新的程序。
2. 调用失败的原因
- 系统中存在太多进程,超出了系统限制。
- 实际用户的进程数超过了限制(可通过
ulimit -u查看 / 修改)。
六、总结
fork()返回值:父进程返回子进程pid,子进程返回0。fork()执行逻辑:fork()前父进程执行,fork()后父子进程并行执行。- 写时拷贝:共享内存,修改时复制,是
fork()高效的关键。 - 虚拟地址空间:进程看到的都是虚拟地址,通过页表映射到物理地址。
- 进程独立性:虚拟地址空间隔离 + 写时拷贝,保证进程互不干扰。