1.写在前面
在数字化技术深度落地的2026年,大数据与AI也已摆脱独立发展的技术孤岛,形成数据为基、AI为核、双向赋能、闭环进化的深度耦合格局,成为数字化转型的核心底层支撑。传统大数据体系聚焦海量数据的采集、存储、清洗与离线统计,解决的是"数据存得下、算得完"的基础问题,但长期面临数据价值挖掘低效、人工运维成本高、场景适配僵化的行业痛点;而大模型与AI技术的爆发,恰好补齐了大数据"有数据、无智能、难落地"的短板,让海量沉淀的数据真正转化为可落地的业务价值与决策能力。与此同时,AI是大数据的进化引擎,彻底重构了传统大数据的处理链路,替代人工完成智能数据清洗、特征挖掘、异常检测、任务调度与价值洞察,让大数据开发、数仓运维、数据治理从"人工驱动"转向"智能自治"。
随着智能体技术迭代升级,大数据与AI的融合进入全新阶段,行业不再满足于简单的模型调用与数据可视化,而是追求全流程自动化、长期自我迭代、场景自适应的数据智能体系。传统大数据开发依赖人工写脚本、调参数、盯任务、排异常,重复冗余工作多、迭代效率低、经验难以沉淀复用。而Hermes Agent这类自进化智能体的出现,完美衔接大数据与AI的融合痛点,打通了"数据处理---智能分析---经验沉淀---自主优化"的全闭环,让大数据体系真正具备自主学习、自主运维、自主升级的能力,标志着大数据行业正式迈入AI自治、越用越强的全新发展阶段。
本文将介绍基于Hermes Agent+Gemma大模型实现企业级text2sql Skill的落地。
2.Hermes Agent
https://hermes-agent.nousresearch.com/
Hermes Agent 是由 Nous Research 开发的开源自托管 AI 智能体框架。它是一个运行在你自己服务器或本地机器上的 AI 智能体,它不依赖任何云服务商的托管平台,所有数据和计算均由你完全掌控。你可以通过命令行、消息平台(Telegram、Discord 等)或 API 接口与它交互,让它帮你完成从日常问答到复杂自动化的各类任务。与一次性对话式 AI 不同,Hermes Agent 具备跨会话持久记忆和自我学习能力:每次对话结束后,它会自动提炼有用的技能和用户偏好,在下次对话中直接调用,越用越聪明。
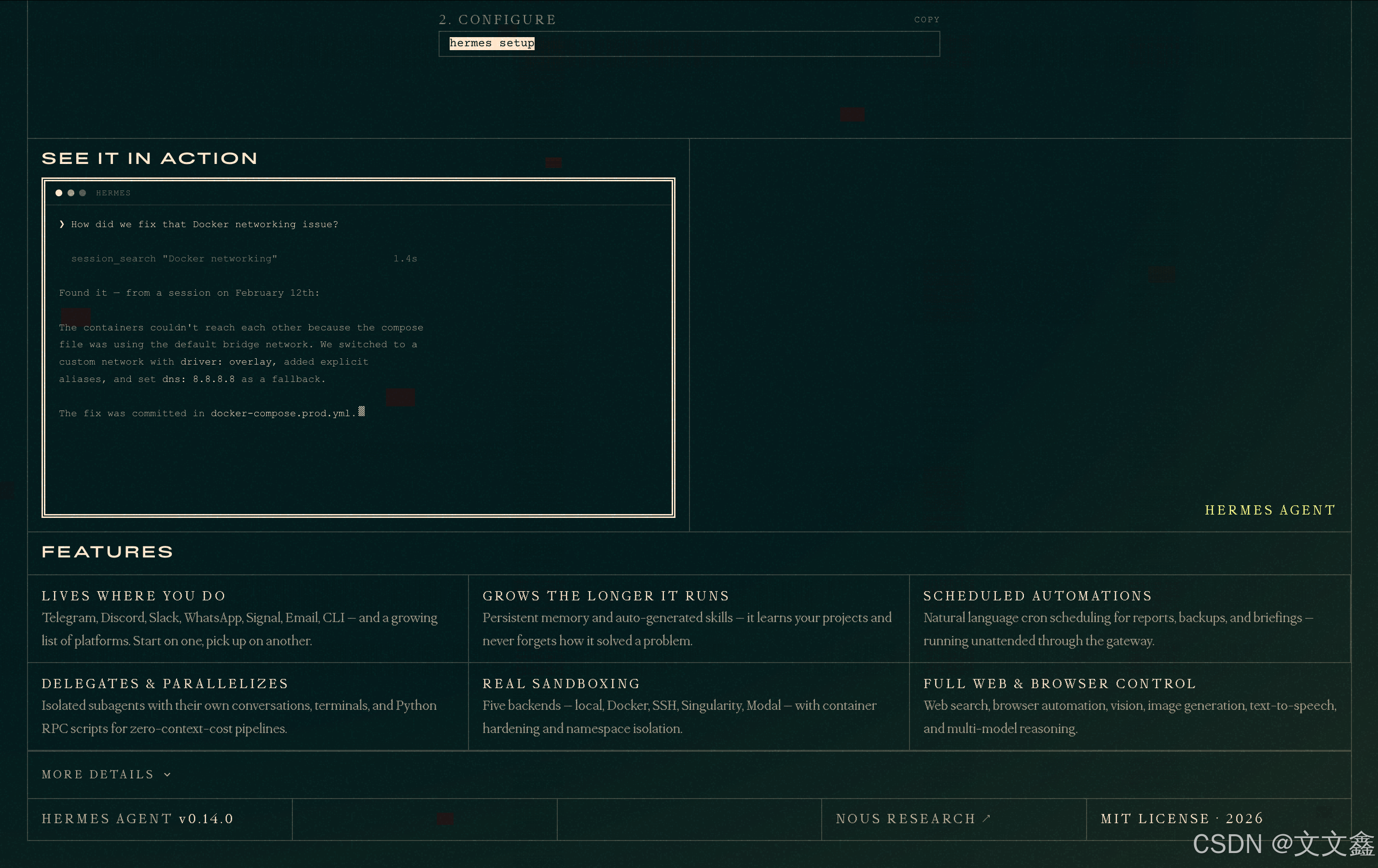
2.1 Hermes本地部署
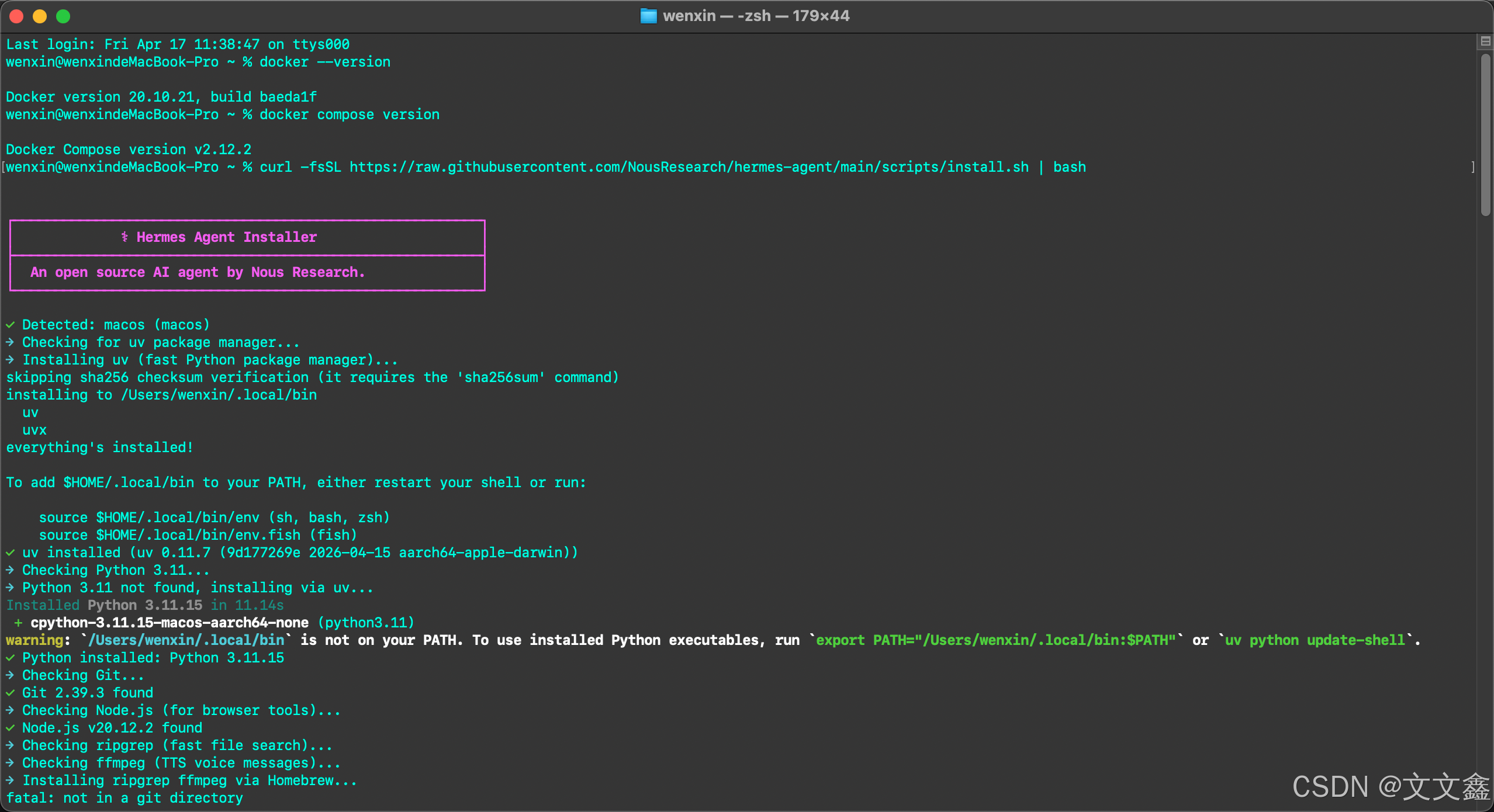
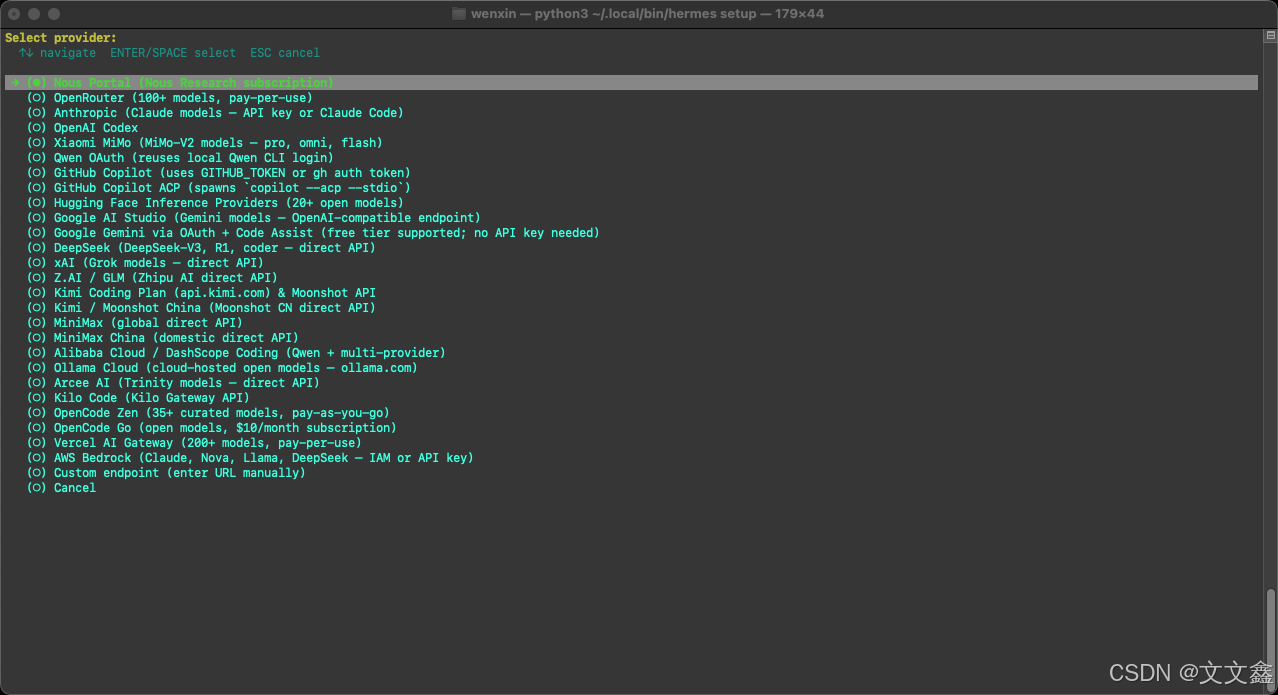
Herems Agent一键安装部署

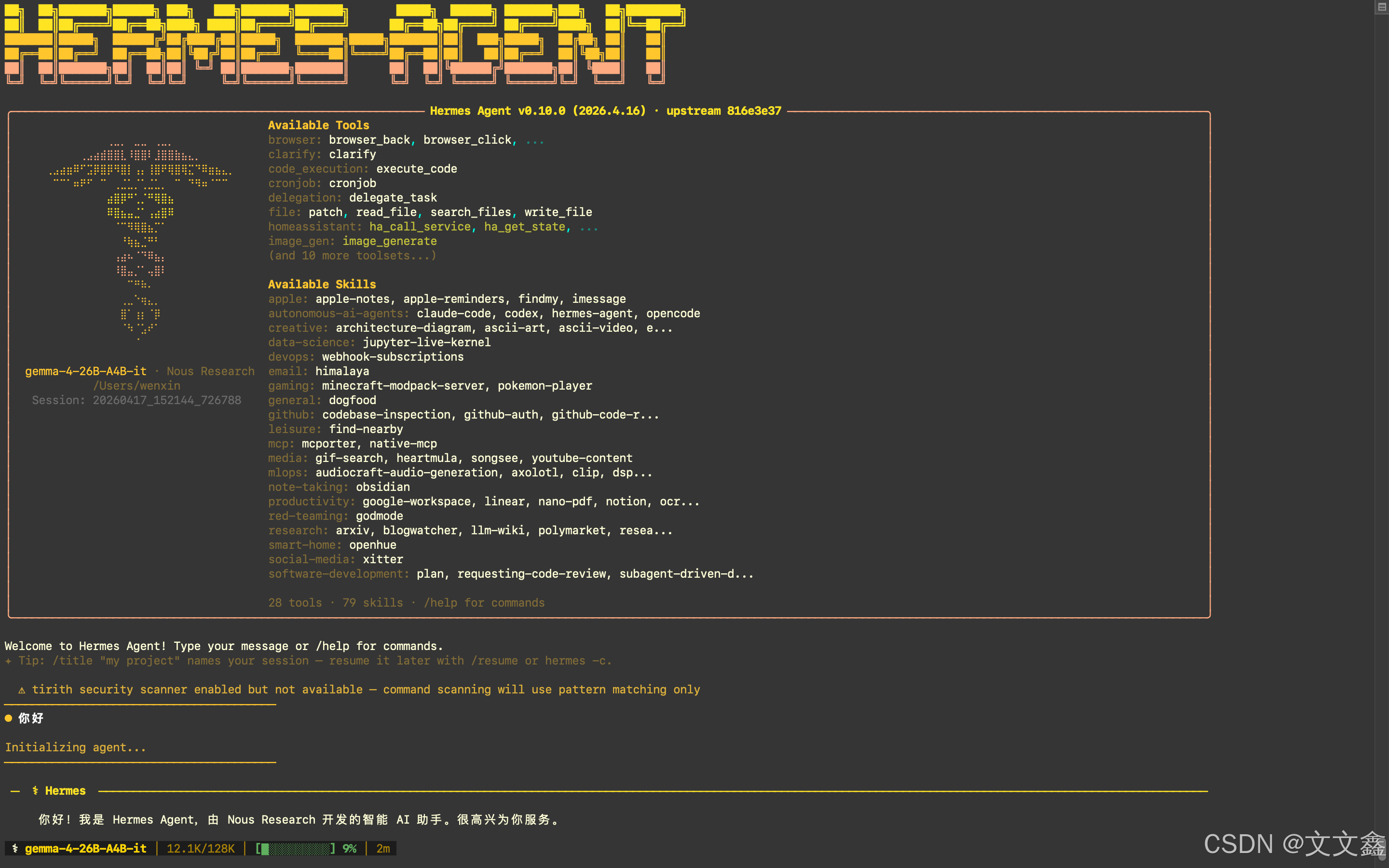
3.Agent Skills
3.1 什么是Agent Skills
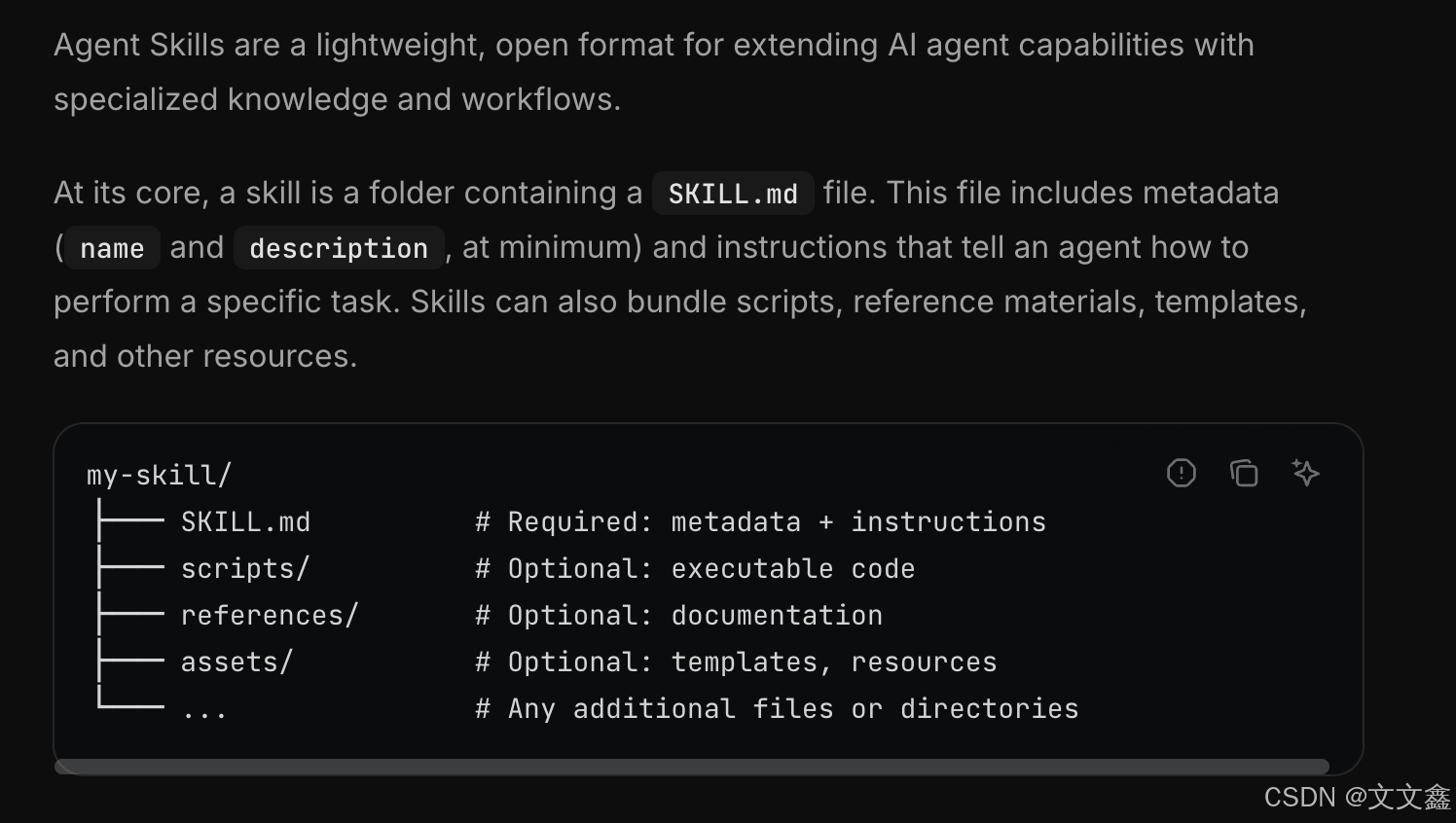
说白了,Agent Skills 是运行在 AI 智能体上的标准化可复用能力单元,它是给智能体编写的 "业务手册 + 操作流程 + 异常预案" ,把一组连续的指令、工具调用、执行逻辑、排错经验封装成独立技能,让 Agent 可以像人类一样 "学会一项工作",并反复复用。
不同于单次 Prompt 指令,Skill 是持久化、结构化、可迭代、可共享的能力模板,遵循统一规范(agentskills.io 标准),不绑定大模型与运行环境,一次编写 / 自动生成,全场景复用。
3.2 为什么需要Agent Skills
智能体(Agents)的能力日益增强,但往往缺乏可靠完成实际工作所需的上下文信息。技能通过将程序性知识以及公司、团队和用户特定的上下文打包成可移植、版本控制的文件夹来解决这一问题,智能体可以根据需要加载这些文件夹。这为智能体提供了:
领域专业知识:将专业知识------从法律审查流程到数据分析流程再到演示文稿格式化------转化为可重复使用的指令和资源。
可重复的工作流程:将多步骤任务转化为一致且可审计的程序。
跨产品复用:构建一项技能后,即可将其应用于任何与该技能兼容的智能体。
4. 基于Hermes Agent+Gemma大模型实现企业级text2sql Skill的落地
4.1 Text2SQL的核心
Text2SQL Skill的核心就是让自然语言直接生成可执行SQL的智能能力单元。是面向大数据、数仓、数据分析场景的核心技能之一:将用户输入的自然语言问题,自动理解、解析、映射为合法、高效、可直接运行的结构化查询语言(SQL),并支持执行、校验、优化与结果解释,实现 "零代码自助取数"。它不是简单的模板匹配,而是一套完整的智能数据查询闭环,让不懂SQL的业务人员、甚至程序员都能直接与数据库对话,大幅降低数据获取门槛,提升大数据分析效率。
- 意图理解:把 "人话" 翻译成数据库能懂的语言
Text2SQL 最核心的思想是语义解析与意图识别。
接收用户自然语言:"过去 7 天各渠道订单金额总和"
Agent 自动理解:时间范围、统计指标、聚合维度、数据源表
输出目标:标准、可执行的 SQL 查询语句
它不依赖关键词硬编码,而是基于大模型理解业务语义,真正实现自然语言到数据库查询的无损转换。 - 元感知:自动读取表结构,不依赖人工配置
Text2SQL Skill 会主动获取数据库元信息:
表名、字段名、字段类型
主键、外键、关联关系
索引、分区、数据量级
基于真实库表结构生成 SQL,避免字段不存在、语法错误、关联错误,保证生成的 SQL 100% 可运行。 - 逻辑推理:自动处理聚合、分组、过滤、排序、join 等复杂逻辑
它不是简单拼接语句,而是具备逻辑推理能力:
自动判断是否需要 GROUP BY / ORDER BY
自动处理多表关联 JOIN
自动加过滤条件 WHERE、时间限制、去重 DISTINCT
自动使用合适的聚合函数 SUM/AVG/COUNT/MAX/MIN
复杂业务问题也能生成正确、高效、符合数仓规范的 SQL。 - 闭环执行:生成 → 校验 → 运行 → 解释 → 可视化
Text2SQL Skill 是端到端自治能力,完整流程:
理解用户问题
读取库表结构
生成最优 SQL
语法检查、风险检查
执行 SQL(Hive/MySQL/Doris/ClickHouse)
返回结果并自动解释数据含义
支持生成图表 / 报表
真正实现一句话取数,无需人工干预。
4.2 Hue Rest API实现元数据信息自动同步SKILL
markup
---
name: hue_metadata_sync
description: 数仓元数据自动同步Skill,动态获取Hive库下所有表信息,自动拉取字段与注释,自动Unicode转中文,输出标准JSON格式,为text-to-sql提供完整实时元数据
tags: [metadata, hue, hive, 元数据, 表结构, 字段同步, 自动同步, text2sql]
---
# 元数据自动同步与维护(Hue)
## 适用场景
- 不需要配置表名单,脚本**自动获取库下所有表**
- 自动拉取表注释、字段名、字段类型、字段注释
- 自动把 \uXXXX Unicode编码转为正常中文
- 生成标准结构化JSON元数据文件,供text-to-sql使用
- 支持定时全量同步,保证元数据实时准确
## 前置信息收集
无需用户输入,全自动执行:
1. 调用Hue接口获取**库下所有表**
2. 循环调用接口获取**每张表的列信息**
3. 自动解析、转码、组装JSON
4. 输出到统一元数据文件
## 前置依赖
1. **Hue认证信息**
脚本内自动获取Token
2. **元数据输出文件**
路径:/Users/wenxin/.hermes/skills/hue-metadata-sync/assets/metadata.json
3. **Hue接口调用脚本**
路径:/Users/wenxin/.hermes/skills/hue-metadata-sync/scripts/hue_metadata_sync.sh
## 执行步骤
### 1. 获取Hue Token
自动登录,获取有效token
### 2. 获取库下所有表(动态,非写死)
调用接口返回所有表名+表注释
### 3. 循环拉取每张表的字段详情
自动遍历所有表,获取extended_columns
### 4. Unicode自动转中文
自动把 \u8ba2\u5355\u8868 → 订单表
### 5. 按标准JSON结构组装
库名 + 表名 + 表注释 + 字段数组(databases/name/type/comment)
### 6. 写入元数据文件
输出标准JSON数组到指定文件,给text-to-sql直接使用Hue Rest Api调用脚本
bash
#!/bin/bash
set -e
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 固定配置
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
HUE_URL="https://hue.******"
USERNAME="wenxin"
PASSWORD="******"
DATABASE="dw"
OUTPUT_JSON="/Users/wenxin/.hermes/skills/hue_metadata_sync/assets/metadata.json"
LIMIT_TABLES=20
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 获取Token
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "获取 Hue Token..."
TOKEN_RES=$(curl -s -X POST "$HUE_URL/api/token/auth/" \
-H "Content-Type: application/json" \
-d "{\"username\":\"$USERNAME\",\"password\":\"$PASSWORD\"}")
TOKEN=$(echo "$TOKEN_RES" | grep -o '"access":"[^"]*"' | cut -d'"' -f4)
if [ -z "$TOKEN" ]; then
echo "Token 获取失败"
exit 1
fi
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# Unicode转中文
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
unicode2cn() {
if [ -z "$1" ]; then
echo ""
return
fi
python3 -c "import sys, json; print(json.loads(f'\"{sys.argv[1]}\"'), end='')" "$1" 2>/dev/null || echo ""
}
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 获取库下所有表
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
get_all_tables() {
local token="$1"
local resp=$(curl -s -X POST "$HUE_URL/api/editor/autocomplete/$DATABASE" -d 'snippet={"type":"hive"}' \
-H "Authorization: Bearer $token")
echo "$resp"
}
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 获取单表字段信息
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
get_table_columns() {
local token="$1"
local table="$2"
local resp=$(curl -s -X POST "$HUE_URL/api/editor/autocomplete/$DATABASE/$table/" -d 'snippet={"type":"hive"}' \
-H "Authorization: Bearer $token")
echo "$resp"
}
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 主流程
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
main() {
echo "=== 开始同步 Hue 元数据 ==="
echo "✅ Token 获取成功"
echo "[" > "$OUTPUT_JSON"
first=1
tables_json=$(get_all_tables "$TOKEN")
table_count=$(echo $tables_json | grep -Eo '"name": "[^"]*"' | wc -l)
echo "✅ 库中总表数量:$table_count"
echo "⚠️ 测试模式:仅同步前 $LIMIT_TABLES 张表"
# 临时文件保存匹配结果
tmpfile=$(mktemp)
echo $tables_json | grep -Eo '"name": "[^"]*", "comment": (null|".*?")' > "$tmpfile"
count=0
while read -r table_line || [ -n "$table_line" ]; do
if [ $count -ge $LIMIT_TABLES ]; then
break
fi
echo "✅ table_line: [$table_line]"
# 提取表名
table_name=$(echo "$table_line" | sed -E 's/.*"name": "([^"]+)".*/\1/')
echo "✅ table_name: [$table_name]"
# 提取注释
if echo "$table_line" | grep -q '"comment": null'; then
table_comment=""
else
enc=$(echo "$table_line" | sed -E 's/.*"comment": "([^"]+)".*/\1/')
table_comment=$(unicode2cn "$enc")
fi
echo "✅ table_comment: [$table_comment]"
echo "→ [$((count+1))] 同步表:$table_name"
# 字段解析(适配你接口的 extended_columns 结构)
col_json=$(get_table_columns "$TOKEN" "$table_name")
col_arr=$(echo "$col_json" | python3 -c "
import sys, json
try:
data = json.load(sys.stdin)
columns = data.get('extended_columns', [])
result = []
for col in columns:
name = col.get('name', '')
typ = col.get('type', '')
comment = col.get('comment', '')
result.append({
'name': name,
'type': typ,
'comment': comment
})
print(json.dumps(result, ensure_ascii=False), end='')
except Exception as e:
print(f'[]')
")
# 写入JSON
if [ $first -eq 1 ]; then
first=0
else
echo "," >> "$OUTPUT_JSON"
fi
echo "{\"database\":\"$DATABASE\",\"name\":\"$table_name\",\"comment\":\"$table_comment\",\"columns\":$col_arr}" >> "$OUTPUT_JSON"
count=$((count+1))
done < "$tmpfile"
rm -f "$tmpfile"
echo "]" >> "$OUTPUT_JSON"
echo ""
echo "=== ✅ 同步完成 ==="
echo "✅ 同步表数量:$count"
}
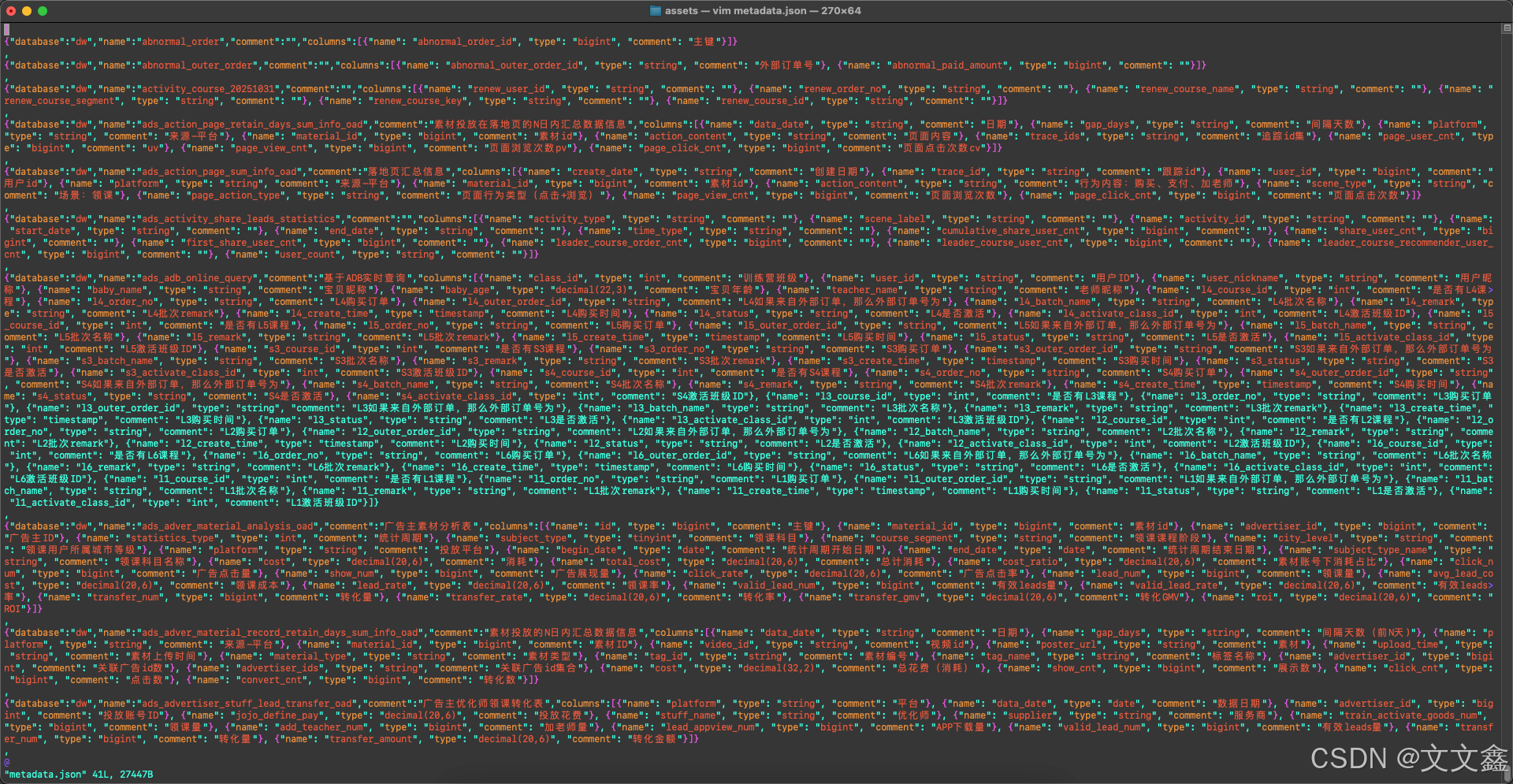
main元数据信息拉取结果
4.3 Text2SQL SKILL
markup
---
name: text2sql
description: Text-to-SQL 智能提数 Agent,对接公司Hue,支持自然语言自动生成 Hive SQL或者presto SQL、自动执行与结果格式化,严格遵循数据安全与审计规范
tags: [text2sql, hue, hive, presto, sql, 大数据, 数据查询]
---
# Text-to-SQL 智能提数(Hue)
## 适用场景
- 用户用自然语言查询数据,无需手动写 SQL
- 需通过公司 Hue 平台查询,统一身份认证,禁止直连数据库
- 需生成合规、可执行的 Hive SQL,并通过接口执行
- 需保证生产环境下的 SQL 性能、安全与口径准确性
## 前置信息收集
生成 SQL 前,必须先向用户确认以下关键信息:
1. **时间范围**:明确的起止日期(如 2026-04-01 至 2026-04-20)
2. **维度字段**:分组/筛选维度(如城市、用户类型、渠道)
3. **业务指标**:需要的指标(如 GMV、订单量、UV、转化率)
4. **业务口径**:特殊定义(如"GMV 指已支付订单金额")
5. **输出格式**:表格、列表还是汇总结论
若用户描述模糊,必须基于 `schema_reference.md` 中的标准口径,并明确说明假设条件。
## 前置依赖
1. **元数据文档**
路径:`/Users/wenxin/.hermes/skills/text-to-sql/references/schema_reference.md`,包含:
- 数据库/表名
- 字段含义与注释
- 分区键与分区规则
- 业务口径与表关联关系
2. **Hue 接口调用脚本**
路径:`/Users/wenxin/.hermes/skills/text-to-sql/scripts/hue_api_client.sh`,已封装认证信息,可直接调用 Hue 查询接口。
3. **查询模板**
路径:`/Users/wenxin/.hermes/skills/text-to-sql/assets/query_template.sql`,包含常用查询模板与最佳实践。
## 执行步骤
### 1. 解析用户意图
从用户提问中提取关键信息:
- 时间范围 → 转换为分区过滤条件
- 维度字段 → 对应 GROUP BY 字段
- 业务指标 → 对应聚合函数
- 特殊要求(如去重、过滤条件)
### 2. 匹配元数据
- 读取 `/Users/wenxin/.hermes/skills/text-to-sql/references/schema_reference.md`,选择最合适的表
- 校验所有字段是否存在,口径是否匹配
- 识别分区键(默认使用 `dt` 作为日期分区)
- 按文档中的关联关系处理多表 JOIN
### 3. 生成合规 Hive SQL 或者 Presto SQL
必须严格遵守以下规则:
- **必须带分区过滤**:如果表有分区字段dt,必须使用分区过滤,`WHERE dt BETWEEN 'YYYY-MM-DD' AND 'YYYY-MM-DD'` 或者 `WHERE dt = 'YYYY-MM-DD'`
- **禁止 SELECT ***:必须显式列出所有字段
- **禁止全表扫描**:如果表有分区字段dt,必须包含分区条件
- **使用标准业务口径**:与元数据文档保持一致
- **禁止危险操作**:不生成 DROP/DELETE/UPDATE/ALTER 语句
- **聚合字段必须别名**:如 `SUM(gmv) AS total_gmv`
### 4. SQL 校验与格式化
- 校验语法正确性
- 校验性能风险(如无过滤条件的大表 JOIN)
- 格式化 SQL,添加注释说明口径与分区
- 补充业务口径说明
### 5. 通过 Hue 接口执行
- 调用 `/Users/wenxin/.hermes/skills/text-to-sql/scripts/hue_api_client.sh` 执行 SQL
- 自动携带认证 Token(由脚本处理)
- 设置 30 秒超时,避免长查询阻塞
- 处理异常(如 SQL 报错、权限不足、超时)
### 6. 结果格式化输出
固定输出格式
- 先打印解析出的SQL并且格式化,而且需要有注释
- 打印查询结果,格式化,添加制表符将字段和数据对齐Text转SQL执行脚本
bash
#!/bin/bash
set -e
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 固定配置
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
HUE_URL="https://hue******"
USERNAME="wenxin"
PASSWORD="**********"
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 输入参数
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USER_QUESTION="$1"
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 步骤1:生成SQL
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "🤖 正在根据问题生成 Hive SQL:$USER_QUESTION"
SQL=$(cat <<EOF
$USER_QUESTION
EOF
)
echo "✅ 压缩后的SQL:$SQL"
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 步骤2:获取Token
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "🔐 获取 Hue Token..."
TOKEN_RES=$(curl -s -X POST "$HUE_URL/api/token/auth/" \
-H "Content-Type: application/json" \
-d "{\"username\":\"$USERNAME\",\"password\":\"$PASSWORD\"}")
TOKEN=$(echo "$TOKEN_RES" | grep -o '"access":"[^"]*"' | cut -d'"' -f4)
if [ -z "$TOKEN" ]; then
echo "❌ Token 获取失败"
exit 1
fi
echo "$TOKEN_RES"
echo "✅ 获取Token成功:$TOKEN"
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 步骤3:执行SQL
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "🚀 执行SQL:$SQL"
EXEC_RES=$(curl -s -X POST "$HUE_URL/api/editor/execute/presto" \
-H "Authorization: Bearer $TOKEN" \
-d "statement=$SQL")
OP_ID=$(echo "$EXEC_RES" | grep -o '"history_uuid": "[^"]*"' | cut -d'"' -f4)
if [ -z "$OP_ID" ]; then
echo "❌ SQL执行失败:$EXEC_RES"
exit 1
fi
echo "✅ 请求体:$EXEC_RES"
echo "✅ 查询ID:$OP_ID"
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# ✅ 步骤4:轮询查询状态,直到 available
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "🔄 等待查询执行完成..."
while true; do
STATUS_RESP=$(curl -s -X POST "$HUE_URL/api/editor/check_status" \
-H "Authorization: Bearer $TOKEN" \
-d "operationId=$OP_ID")
# echo "运行状态返回体:$STATUS_RESP"
# 提取状态
CURRENT_STATUS=$(echo "$STATUS_RESP" | sed -n 's/.*"status": "\([^"]*\)".*/\1/p' | head -1)
echo "➡️ 当前状态:$CURRENT_STATUS"
if [ "$CURRENT_STATUS" = "available" ]; then
echo "✅ 查询已完成!"
break
fi
sleep 2
done
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 步骤5:获取结果
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo "📥 获取查询结果..."
RESULT=$(curl -s -X POST "$HUE_URL/api/editor/fetch_result_data" \
-H "Authorization: Bearer $TOKEN" \
-d "operationId=$OP_ID&rows=100")
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 输出结果
# ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
echo -e "\n==================== 查询结果 ===================="
echo "$RESULT"
echo "====================================================4.4 Text2SQL SKILL测试
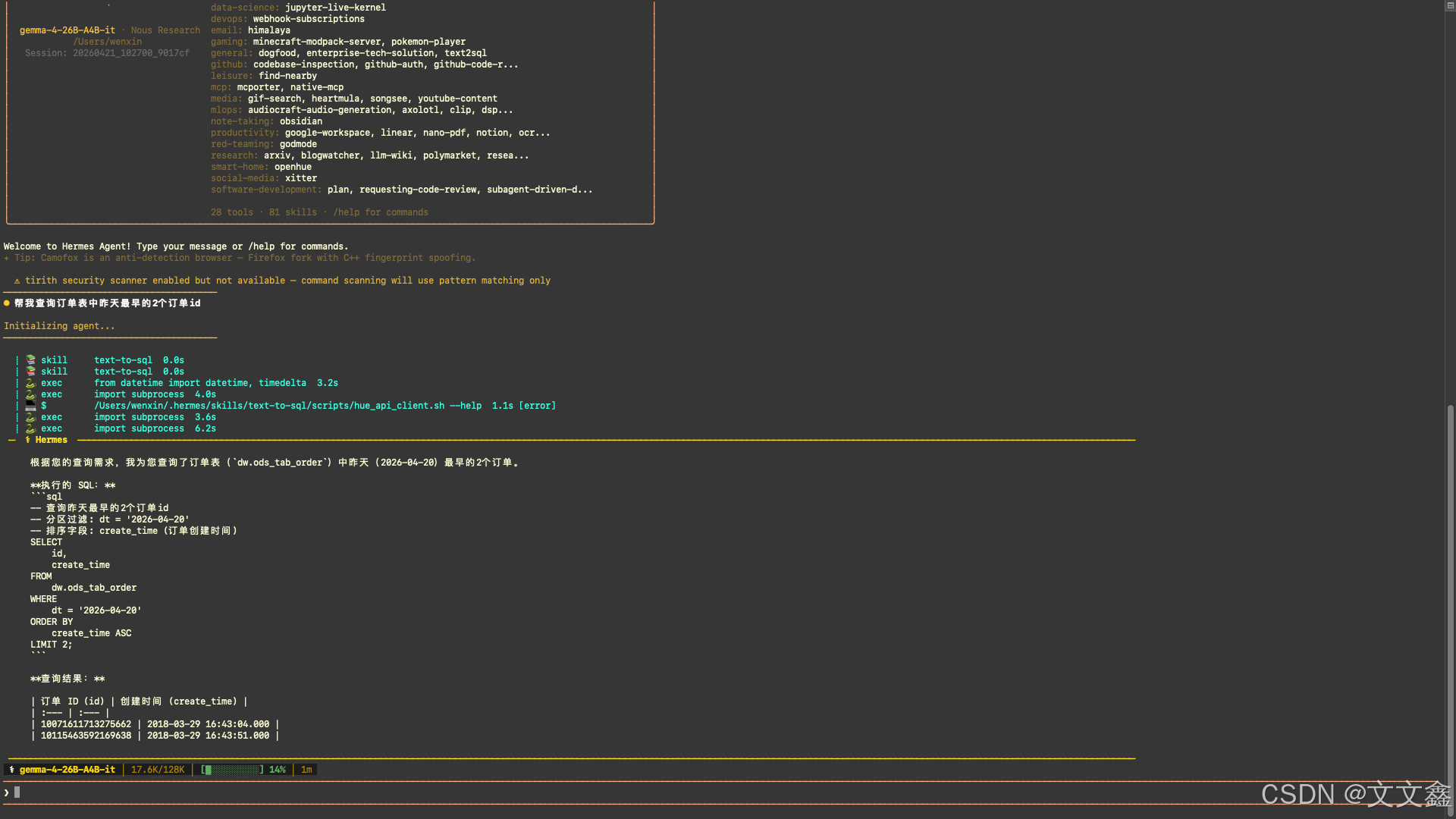
查询一张元数据信息中有的表
查询一张元数据信息没有的表
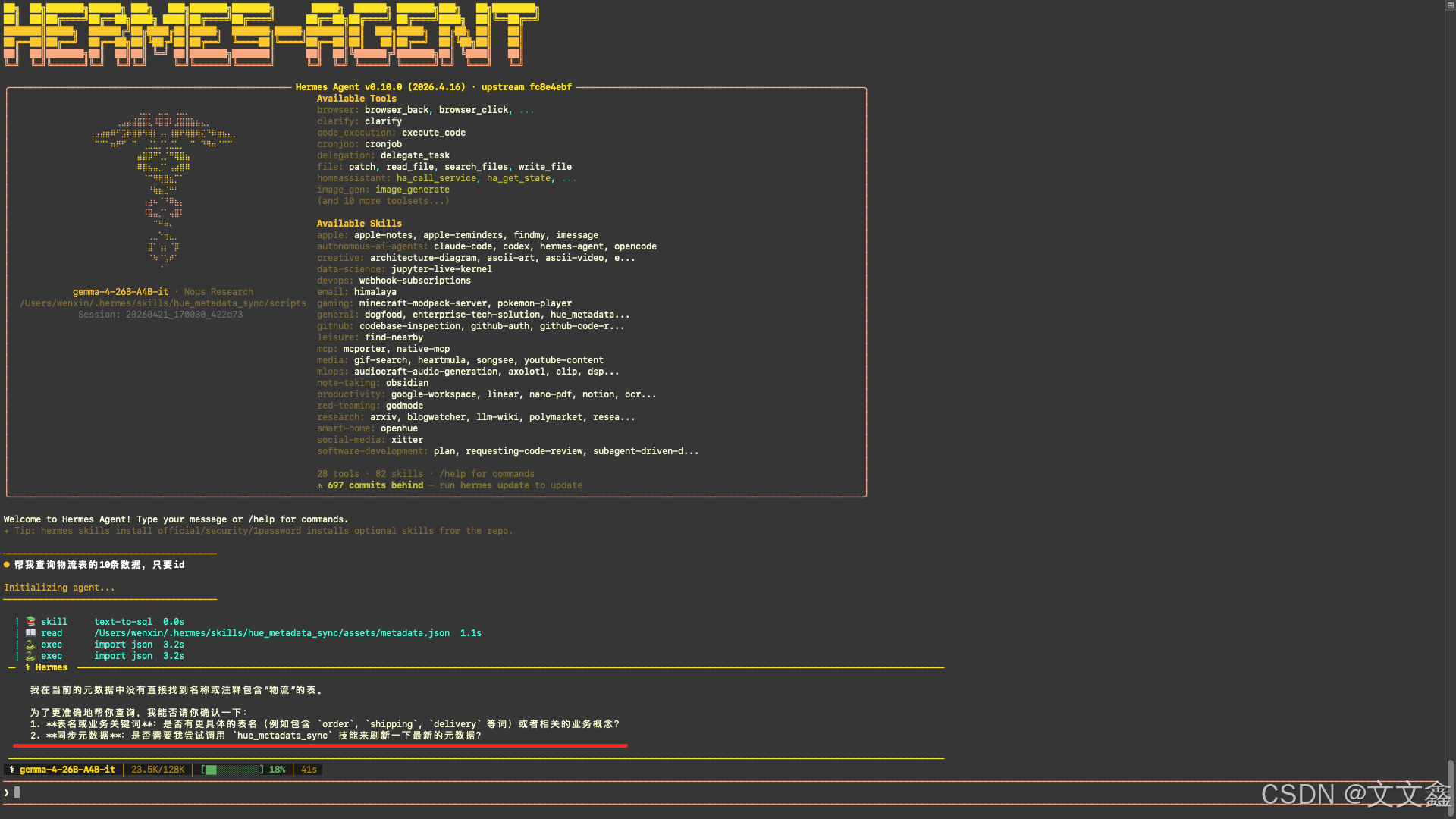
元数据维自动护SKILL 被调用
